Computer Science and Application
Vol.06 No.11(2016), Article ID:18889,9
pages
10.12677/CSA.2016.611077
Deep Learning on Improved Word Embedding Model for Topic Classification
Yingying Zhou, Lei Fan
School of Information Security Engineering, Shanghai Jiao Tong University, Shanghai

Received: Oct. 18th, 2016; accepted: Nov. 6th, 2016; published: Nov. 9th, 2016
Copyright © 2016 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



ABSTRACT
Topic classification has wide applications in content searching and information filtering. It can be divided into two core parts: text embedding and classification modeling. In recent years, methods have brought out significant results using distributed word embedding as input and convolutional neural network (CNN) as classifiers. This paper discusses the impact of different word embedding for CNN classifiers, proposes topic2vec, a new word embedding specifically suitable for Chinese corpora, and conducts an experiment on Zhihu, a representative content-oriented internet community. The experiment turns out that CNN with topic2vec gains an accuracy of 98.06% for long content texts, 93.27% for short title texts and an improvement comparing with other word embedding models.
Keywords:Topic Classification, Deep Learning, Convolutional Neural Network, Word Embedding

基于改进词向量模型的深度学习文本主题分类
周盈盈,范磊
上海交通大学信息安全工程学院,上海

收稿日期:2016年10月18日;录用日期:2016年11月6日;发布日期:2016年11月9日

摘 要
主题分类在内容检索和信息筛选中应用广泛,其核心问题可分为两部分: 文本表示和分类模型。近年来,基于分布式词向量对文本进行表示,使用卷积神经网络作为分类器的文本主题分类方法取得了较好的分类效果。本文研究了不同词向量对卷积神经网络分类效果的影响,提出针对中文语料的topic2vec词向量模型。本文利用该模型,对具有代表性的互联网内容生成社区“知乎”进行了实验与分析。实验结果表明,利用topic2vec词向量的卷积神经网络,在长内容文本和短标题文本的分类问题中分别取得了98.06%,93.27%的准确率,较已知词向量模型均有显著提高。
关键词 :主题分类,深度学习,卷积神经网络,词向量

1. 引言
文本主题分类将文本按照潜在的主题进行分类,在内容检索和信息筛选中应用广泛,涉及语言学、自然语言处理、机器学习等领域。文本主题分类的核心问题包括文本表示、分类模型等。
传统的文本表示方法主要基于词袋模型,该方法认为文档是无序词项的集合。词袋模型存在数据稀疏问题,并且丢弃了词序、语法等文档结构信息,对分类效果的提升存在瓶颈。传统的文本分类模型以词袋为输入特征,并基于一定的模型假设。其基本思想是,假设数据分类服从某种概率分布,利用贝叶斯理论获得最佳的分类器。由于对于数据附加了额外的假设,因此,一旦假设不成立则会严重影响模型准确率。
近年来,对文本分类问题的改进研究主要集中于深度学习。针对深度学习的分类模型,文本表示可使用Mikolov等人提出的分布式词向量 [1] 方法。该方法针对词袋模型中语义信息丢失的问题,利用语言神经网络将字典空间映射为词向量空间。分析表明,对于空间距离相近的词项,其语义或词性也具有强关联性。在分类模型方面,以分布式词向量作为模型的输入特征,循环神经网络、递归神经网络、卷积神经网络等深度学习模型都可应用于文本分类。其中,Kim等人于2014年提出的卷积神经网络(CNN) [2] [3] [4] [5] 在文本主题分类中具有较高的准确率,在MR数据集 [6] 中的分类准确率达81.5%。
本文主要研究基于卷积神经网络的文本分类方法,并通过改进词向量空间模型提高分类的准确性。针对中文语料的特点,提出了改进的词向量模型topic2vec,并通过对比实验,研究不同词向量作为卷积神经网络的输入特征,对分类准确率的影响,其中,利用 topic2vec的卷积神经网络在长短语料中分别取得98.06%,93.27%的准确率,较其他词向量如word2vec [1] 、GloVe [7] 和随机词向量都有提高。实验表明,对于中文语料而言,利用卷积神经网络进行文本主题分类是有效的,且将topic2vec作为原始特征的模型分类效果优于其他词向量。
本文的结构如下:第二章介绍文本分类的相关工作。第三章介绍topic2vec模型的原理及文本分类模型的结构。第四章介绍实验设定和实验结果,并对实验结果进行讨论。第五章为总结。
2. 相关工作
深度学习是文本分类的主流方法,取得比较好的效果。其核心是卷积神经网络作为分类器,同时使用词向量模型作为文本表示。
2.1. 卷积神经网络
基于卷积神经网络的文本分类模型是一个有监督的三层网络模型,由输入层、隐层和输出层构成,通过后向传播算法 [8] 进行参数优化。输入层为一组大小相等的文档矩阵,矩阵第n行对应文档第n个词项的向量表示;隐层通过一组不同大小的卷积核(filter)对文本进行自上而下的卷积运算,提取一组特征向量,并从每个特征向量中选取最大项(max-pooling [9] ),组成特征地图;输出层通过Softmax分类器 [10] 计算文档落在各个主题下的概率并输出最终分类结果。模型结构如图1。
模型的训练使用极大似然估计,即求出一组参数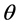 ,使得目标函数最大化
,使得目标函数最大化
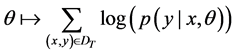
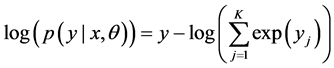
其中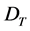 为训练集,K为主题数,
为训练集,K为主题数,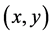 为训练文档及其对应的正确主题分类标号。模型采用随机梯度下降法(SGD)优化上述目标。令学习率为
为训练文档及其对应的正确主题分类标号。模型采用随机梯度下降法(SGD)优化上述目标。令学习率为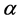 ,在每一轮迭代中,随机选取一组样本
,在每一轮迭代中,随机选取一组样本 ,并用下式进行一轮梯度迭代
,并用下式进行一轮梯度迭代

Zhang等人 [3] 分别利用word2vec、GloVe、word2vec+GloVe作为CNN模型的输入特征,并在不同英文数据集下进行实验。实验结果表明,对于不同数据集,word2vec和GloVe的分类效果各不相同,因此,词向量的选择直接影响模型的性能。
2.2. 分布式词向量
词向量是深度学习模型的输入特征,根据向量之间的相关性,可分为随机词向量和分布式词向量。随机词向量将词项随机表示为两两正交的单位向量,由1个1和W-1个0组成,其中W为字典长度,其构造方式简单,但词项之间的关联关系则被完全割裂,并可能造成维数灾难。分布式词向量则将词项表示为一个几十到几百维的稠密型实值向量,并可通过向量空间距离考察词项之间的语义相似度,其中,最具代表性的是word2vec。对于长度为N的文档,word2vec考察每个词项 的c个上下文,其目标函数为极大对数似然
的c个上下文,其目标函数为极大对数似然
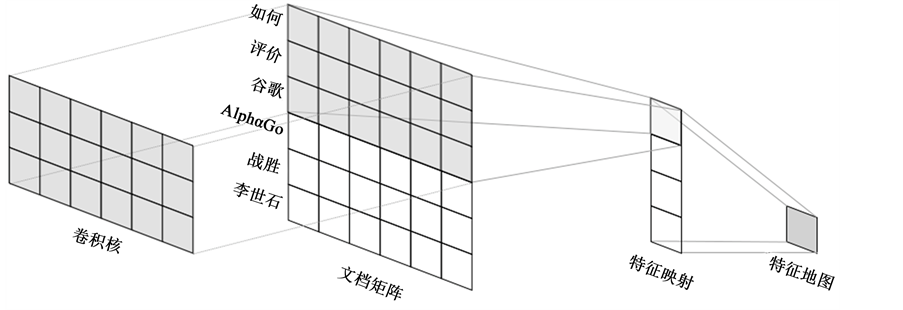
Figure 1. Text classification model based on convolutional neural network
图1. 基于卷积神经网络的文本分类模型

通过随机梯度下降法求解目标函数可得词向量。其中,词项上下文的条件概率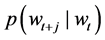 由Softmax函数给出
由Softmax函数给出
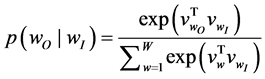
由于word2vec仅考察目标词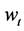 的局部上下文,因此损失了语料中全文性的关联信息,主题模型可以体现语料的全文关联性信息。
的局部上下文,因此损失了语料中全文性的关联信息,主题模型可以体现语料的全文关联性信息。
2.3. 主题模型
主题模型 [11] 是无监督的文本聚类模型。模型由文档、词项、主题三个维度构成,通过模拟文档的生成过程,对文档在各主题下的概率分布矩阵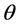 和各个词语在各主题下的概率分布矩阵
和各个词语在各主题下的概率分布矩阵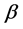 进行参数估计。假设
进行参数估计。假设 服从先验分布
服从先验分布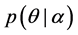 ,接着随机为文档分配一个主题
,接着随机为文档分配一个主题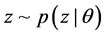 ,并随机生成一个单词
,并随机生成一个单词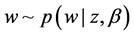 。假设语料库D大小为M,第d篇文档长度为
。假设语料库D大小为M,第d篇文档长度为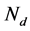 ,则语料库的目标函数为
,则语料库的目标函数为
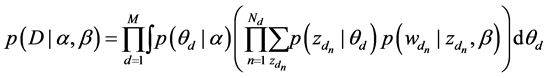
将主题数设置为词向量的维度,得词项的稀疏主题分布向量,并可作为字典在向量空间的映射,通过向量空间距离考察词项的在全局语料范围内的主题相似度。
3. 基于深度学习的文本分类模型
现有的分布式词向量,都直接沿用了比较上下文对单词建模的方法,缺少了在全局文档中对主题特征的刻画,针对这一局限性,本章提出topic2vec词向量模型,并将其作为卷积神经网络的输入特征。
3.1. topic2vec词向量表示
word2vec等分布式词向量使用固定大小的滑动窗口对文档中每个词项的上下文进行统计,并给出词在向量空间中的映射。此类模型仅从局部文档考察词项的语义,并不统计词在全局文档中的主题信息。一般而言,词向量中保留越多的语义信息,深度学习模型对语料的特征学习效果更好。
topic2vec词向量模型主要基于这个猜想,设分词后的中文语料库为D,取语料库中所有独立词项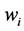 ,建立字典
,建立字典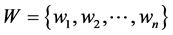 ,其中n为不同词项的总数。为了在词向量中加入适量的主题信息,引入主题分布向量
,其中n为不同词项的总数。为了在词向量中加入适量的主题信息,引入主题分布向量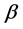 对词项的主题属性进行预训练。
对词项的主题属性进行预训练。
算法1通过伪代码描述了主题分布向量的生成过程。假设分词的主题分布均匀,使用Dirichlet分布 [12] 作为词项的先验主题分布,即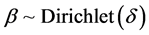 。遍历语料库D中每个文档
。遍历语料库D中每个文档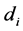 ,以及
,以及 中的每个词项
中的每个词项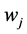 ,第一步,考察当前文档
,第一步,考察当前文档 中除去当前词
中除去当前词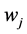 后的其他所有词项,根据它们的主题分布进行投票表决,生成文档
后的其他所有词项,根据它们的主题分布进行投票表决,生成文档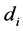 在词项
在词项 下的主题
下的主题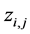 ;第二步,根据当前主题
;第二步,根据当前主题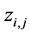 ,更新文档
,更新文档 的主题分布
的主题分布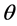 以及当前词项
以及当前词项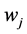 的主题分布
的主题分布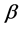 。Blei等人 [11] 证明,重复以上遍历,当循环次数I足够大时,模型收敛。最后对两个统计矩阵进行归一化,得到词项的主题分布概率矩阵
。Blei等人 [11] 证明,重复以上遍历,当循环次数I足够大时,模型收敛。最后对两个统计矩阵进行归一化,得到词项的主题分布概率矩阵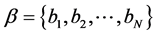 。
。
Algorithm 1. Topic model
算法1. 主题模型
由模型可知,对任意词项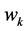 ,对应主题分布向量
,对应主题分布向量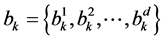 ,其中
,其中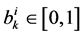 ,且
,且 ,因此,当N足够大且主题分布均匀时,
,因此,当N足够大且主题分布均匀时,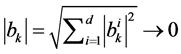 ,词项的主题分布矩阵
,词项的主题分布矩阵 是稀疏的。
是稀疏的。
算法2通过伪代码描述了词向量topic2vec生成的具体过程。第一步,对词项的邻近上下文进行考察,基于滑动窗口内的语义信息构造维数为d的word2vec词向量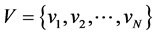 ;其中N为字典空间的维度dim(W);第二步,通过主题模型获取词项在全局文档范围内的d维稀疏主题分布向量
;其中N为字典空间的维度dim(W);第二步,通过主题模型获取词项在全局文档范围内的d维稀疏主题分布向量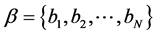 ;第三步,将两组词向量进行线性加权求和,即
;第三步,将两组词向量进行线性加权求和,即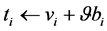 ,其中
,其中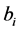 的共享权重
的共享权重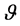 为词向量空间V的平均L2范数,通过对向量空间中的词项进行微小位移,同一主题下不同词性的词项经过调整后距离更近,并生成新的词向量空间
为词向量空间V的平均L2范数,通过对向量空间中的词项进行微小位移,同一主题下不同词性的词项经过调整后距离更近,并生成新的词向量空间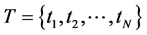 。
。
由上述算法可知,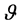 是词向量在主题维度的偏移程度。对任意词项
是词向量在主题维度的偏移程度。对任意词项 和
和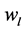 ,用余弦距离表征它们的语义相似度
,用余弦距离表征它们的语义相似度
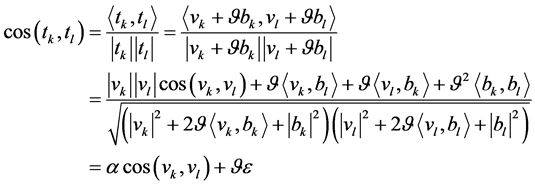
其中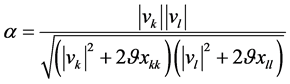 ,
,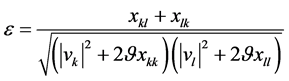 ,
,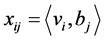 。为了保留词向量在局部上下文中的语法信息,同时引入全局文档范围内语义信息,取
。为了保留词向量在局部上下文中的语法信息,同时引入全局文档范围内语义信息,取 ,即词向量空间V的平均L2范数。此时,
,即词向量空间V的平均L2范数。此时,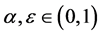 ,
,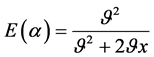 ,
,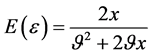 ,
,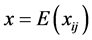 。
。
3.2. 文本分类模型
利用topic2vec作为卷积神经网络的输入特征,得到改进的文本分类模型,模型结构如图2。
模型首先对文本进行数据清洗、分词、构建字典并完成词项到topic2vec的映射,接着将原始文本表示为对应词向量的级联,并在文末进行空格填充,以保证每个文档的输入矩阵高度相等

Figure 2. Text classification model based on topic2vec
图2. 基于topic2vec的文本分类模型
Algorithm 2. topic2vec
算法2. topic2vec

对于高度为N,维度为d的文档矩阵M,卷积层用宽度恒定为d,高度h可变(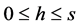 )的滑动窗口W对文档矩阵M进行自上而下的扫描,W每次可扫过的h个相邻的词向量,记为
)的滑动窗口W对文档矩阵M进行自上而下的扫描,W每次可扫过的h个相邻的词向量,记为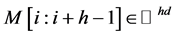 ,通过自上而下对窗口进行滑动,i可取
,通过自上而下对窗口进行滑动,i可取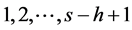 。定义卷积核
。定义卷积核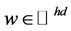 为一个长度为hd的权值向量。将w与W中的局部文档矩阵进行卷积,得到一个特征响应
为一个长度为hd的权值向量。将w与W中的局部文档矩阵进行卷积,得到一个特征响应

其中 为共享偏置,ReLU为修正线性单元。对文档完成一周窗口滑动可得一组特征映射向量
为共享偏置,ReLU为修正线性单元。对文档完成一周窗口滑动可得一组特征映射向量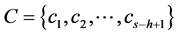 。通过改变滑动窗口的高度h和卷积核w,同一文档可以通过卷积层生成一组特征映射向量
。通过改变滑动窗口的高度h和卷积核w,同一文档可以通过卷积层生成一组特征映射向量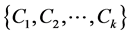 。
。
由于滑动窗口的高度不尽相同,卷积得到的特征映射向量也有各自不同的维度,因此,为了对特征映射向量进行正则化,模型通过表决层(max pooling)从每个特征映射向量中挑选出最大项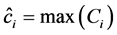 ,并将其余项丢弃,生成最终的特征地图
,并将其余项丢弃,生成最终的特征地图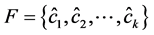 。此时,特征地图的维度k由滑动窗口个数和每个窗口对应的卷积核个数共同决定,皆为用户指定的模型超参数。
。此时,特征地图的维度k由滑动窗口个数和每个窗口对应的卷积核个数共同决定,皆为用户指定的模型超参数。
模型输出层的节点个数K即为主题个数,通过Softmax分类器 [6] 对每个文档的特征地图进行归一化,并给出文档落在第i个主题下的概率
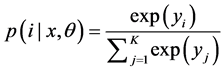
其中x为输入文档,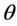 为模型参数,包括词向量和网络中的参数。
为模型参数,包括词向量和网络中的参数。
4. 实验分析
本文实验主要以具有代表性的中文网络文本最为研究对象。知乎作为国内知名的社会化问答社区,截至2014年8月有活跃用户数有350万,具有较为完备的标签与分类机制,是理想的文本主题分类语料来源。
4.1. 实验设置
实验数据集采集自知乎,包括8个主题45063个精华提问及高票回答,话题涉及计算机、体育、经济、美食、教育、医疗、人际传播和艺术。以分词为文本长度的最小单位,统计各个文本的长度分布,如图3所示。
在数据预处理中,本文采用Stanford Core NLP 3.5.0 [13] 进行分词,并过滤掉文本中出现的超链接、标点符号、日期及停用词等无效信息。经过预处理后的实验语料平均长度为359,字典长度为116432,取词向量维度为300。表1给出了分词后的实例。
实验使用两个语料,“短语料”为数据集中所有标题信息,“长语料”为标题、问题详情、和高票回答的组合信息。“短语料”提供了话题的精简信息,词项少但涵盖关键词的比例较高,“长语料”提供了话题的全部信息,内容丰富但干扰项多。图4给出了两个语料的长度分布。
使用完整长语料作为词向量的训练集,并分别在两组语料上进行主题分类实验,考察分类模型在短文本和长文本中的分类效果。实验在配备Intel Core i7处理器,内存8GB的OS X EI Capitan操作系统下进行,卷积神经网络的训练使用Python的深度学习框架theano [14] 。
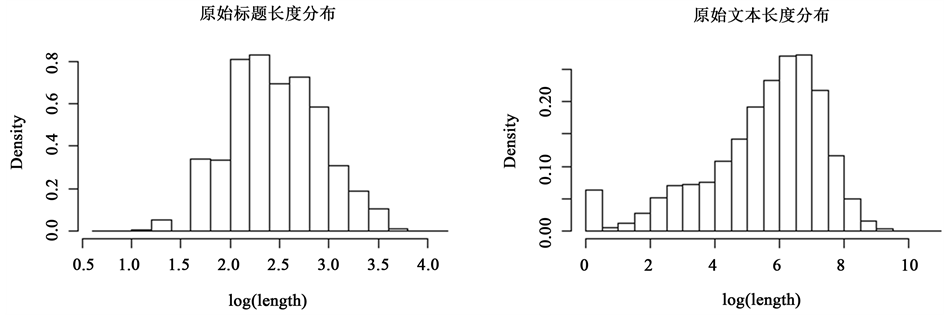
Figure 3. Length distribution of Zhihu raw dataset
图3. 知乎原始数据集文本长度分布

Table 1. Example of data preprocessing
表1. 数据预处理示例
4.2. 实验结果
对词向量的评价主要基于两个方面的考量:词向量的语言学特征和词向量作为分类模型的初始特征对模型效率的影响。
在评价词向量的语言学特征方面,本章选取了5个词项,考察它们在向量空间中的最邻近词项及语义相关性。表2比较了word2vec和topic2vec得到的最邻近词项:
由表2可知,利用word2vec训练得到的邻近词项具有词性相同、实体种类相近的特点,例如“苹果”与“香蕉”等;而topic2vec则能够找到同一主题下的强关联词,例如“乔布斯”与“苹果”,topic2vec可以更好地体现人类对词语的理解。
在将词向量作为特征提高模型性能方面,本章对长语料和短语料分别进行分类实验,并以不同词向量作为输入特征进行对比,这些词向量包括:随机词向量(rand)、word2vec、GloVe和topic2vec。将实验数据随机分成10组进行交叉验证。实验结果如下:
由表3可知,较于主题模型算法,CNN具有准确度高、鲁棒性好等优势。此外,影响CNN分类结果的主要因素包括文本长度和词向量的选择。对于长文本,topic2vec的平均准确度为0.98,word2vec的平均准确度为0.96,随机正交词向量的准确度为0.90;对于短语料,topic2vec和word2vec的平均准确度较为接近,为93.27%和91.54%,GloVe的准确度为69.72%。正交词向量则为67.17%。对于长语料,topic2vec的平均准确率为98.06%,word2vec、GloVe和随机正交词向量则分别为95.71%、92.4%、89.95%。由此可见,通过训练词向量,将词语之间的词性和语义关系表达为词向量之间的空间距离,这在CNN的分类过程中具有一定的积极影响。
Figure 4. Length distribution of Zhihu preprocessed dataset
图4. 知乎预处理后数据集文本长度分布
Table 2. Nearest terms of 2 types of word embedding
表2. 两种词向量得到的最邻近词项
Table 3. Classification accuracy of CNN under different word embeddings
表3. 不同词向量下的CNN文本分类准确率
5. 总结
本文研究了基于深度学习的文本分类,以及不同词向量输入对神经网络性能的影响,提出了一种改进的词向量表示方法Top2vec。通过实验数据表明,该方法对长短语料分类准确率均有提高。
基金项目
上海市科委基础研究重点项目(13JC1403501)。
文章引用
周盈盈,范磊. 基于改进词向量模型的深度学习文本主题分类
Deep Learning on Improved Word Embedding Model for Topic Classification[J]. 计算机科学与应用, 2016, 06(11): 629-637. http://dx.doi.org/10.12677/CSA.2016.611077
参考文献 (References)
- 1. Mikolov, T., Sutskever, I., Chen, K., Corrado, G., et al. (2013) Distributed Representations of Words and Phrases and Their Compo-sitionality. Advances in Neural Information Processing Systems, 3111-3119.
- 2. Kim, Y. (2014) Convolutional Neural Networks for Sentence Classification.
- 3. Kalchbrenner, N., Grefenstette, E. and Blunsom, P. (2014) A Convolutional Neural Network for Modelling Sentences. Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, 655-665.
- 4. Johnson, R. and Zhang, T. (2015) Semi-Supervised Convolutional Neural Networks for Text Categorization via Region Embedding. Advances in Neural Information Processing Systems, 919-927.
- 5. Zhang, Y. and Wallace, B. (2015) A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification.
- 6. Pang, B. and Lee, L. (2005) Seeing Stars: Exploiting Class Relationships for Sentiment Categorization with Respect to Rating Scales. Proceedings of the ACL. http://dx.doi.org/10.3115/1219840.1219855
- 7. Pennington, J., Socher, R. and Manning, C.D. (2014) Glove: Global Vectors for Word Representation. Proceedings of the Empiricial Methods in Natural Language Processing. http://dx.doi.org/10.3115/v1/d14-1162
- 8. Rumelhart, D.E., Hinton, G.E. and Williams, R. (1988) Learning Representations by Back-Propagating Errors. Cognitive Modeling, 5, 3.
- 9. Boureau, Y.L., Ponce, J. and Le Cun, Y. (2010) A Theoretical Analysis of Feature Pooling in Visual Recognition. Proceedings of the 27th International Conference on Machine Learning (ICML-10), 111-118.
- 10. Hinton, G.E. and Salakhutdinov, R.R. (2009) Replicated Softmax: An Undirected Topic Model. Advances in Neural Information Processing Systems, 1607-1614.
- 11. Hoffman, M., Bach, F.R. and Blei, D.M. (2010) Online Learning for Latent Di-richlet Allocation. Advances in Neural Information Processing Systems, 856-864.
- 12. Blei, D.M., Ng, A.Y. and Jordan, M.I. (2003) Latent Dirichlet Allocation. Journal of Machine Learning Research, 3, 993-1022.
- 13. Manning, C.D., Surdeanu, M., Bauer, J., et al. (2014) The Stanford CoreNLP Natural Language Processing Toolkit. ACL (System Demonstrations), 55-60.
- 14. Bergstra, J., Breu-leux, O., Bastien, F., et al. (2010) Theano: A CPU and GPU Math Compiler in Python. Proceedings of the 9th Python in Science Conference, 1-7.