Software Engineering and Applications
Vol.06 No.02(2017), Article ID:20184,7
pages
10.12677/SEA.2017.62003
A Survey of Distributed File System
Zhennan Du, Chongjun Zhu
College of Computer Science, National University of Defense Technology, Changsha Hunan

Received: Mar. 27th, 2017; accepted: Apr. 10th, 2017; published: Apr. 14th, 2017

ABSTRACT
The file system is an important part of the computer system. With the development of personal computer and network technology, the generation of distributed file system has effectively solved the problem of infinite growth of massive information storage. This paper summarizes the origin of the distributed file system and comprehensively analyzes and organizes the architecture of several typical distributed file systems by consulting a large number of documents.
Keywords:Distributed File System, Storage Technology
分布式文件系统综述
杜振南,朱崇军
国防科学技术大学计算机学院,湖南 长沙
收稿日期:2017年3月27日;录用日期:2017年4月10日;发布日期:2017年4月14日

摘 要
文件系统是计算机系统的重要组成部分,随着个人计算机和网络技术的发展,分布式文件系统的产生有效解决了无限增长的海量信息存储问题。本文通过查阅大量文献,概述了分布式文件系统的起源并综合分析整理了几种典型分布式文件系统的体系架构。
关键词 :分布式文件系统,存储技术

Copyright © 2017 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
随着科学技术的发展以及云计算、P2P等技术的普及,全球数据量呈现爆炸式的增长,尤其是大数据时代的到来,通过互联网,用户制造了海量的数据。2017年1月22日中国互联网络信息中心发布的《第39次中国互联网络发展状况统计报告》中指出:我国2016年全年共计新增网民4299万人,增长率为6.2%,其中,手机网民规模达6.95亿,占比达95.1%,增长率连续3年超过10%。手机网民最常使用即时通信APP:2016年,网民在手机端最经常使用的APP应用前三位分别是微信、QQ、淘宝,无论是微信、QQ、微博等社交通信软件还是淘宝、京东等电商软件,其图片的上传、分享与展示所产生的数据量都达到了指数级。传统的存储系统无法满足呈爆炸性增长的海量数据存储需求,为解决信息存储容量、数据备份、数据安全等问题,分布式文件系统应运而生,如今已得到广泛应用。使用分布式文件系统时,用户不必考虑底层的存储设备以及实现细节,系统会将用户的数据进行存储、归档、备份,实现对数据的使用、共享以及保护的目的。
本文阐述了分布式文件系统的概念和发展历程,结合近年来分布式文件系统的应用情况,对几种典型分布式文件系统的概念、特点、体系架构进行研究,旨在帮助学习研究人员进一步了解分布式文件系统。
2. 分布式文件系统概述
本地文件系统只能访问与主机通过I/O总线直接相连的磁盘上的数据。当局域网出现后,各台主机间通过网络互连起来。如果每台主机上都保存一份大家都需要的文件,既浪费存储资源,又不容易保持文件的一致性。于是就提出文件共享的需求,即一台主机需要访问其它主机的磁盘。这直接导致了分布式文件系统的诞生。
2.1. 分布式文件系统的概念
分布式文件系统(Distributed File System,DFS)是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连文件系统管理的物理存储资源。分布式文件系统基于客户机/服务器(C/S)模式而设计,通常一个网络内可能包括多个可供用户访问存储资源的服务器。同时,分布式文件系统的对等特性也允许一些系统在扮演客户端的同时扮演服务端。例如,用户可以发布一个允许其他客户机访问的目录,一旦被访问,这个目录对于其他客户机来说就像使用本地驱动器一样。
2.2. 分布式文件系统发展历程
分布式文件系统的发展主要经历了四个阶段 [1] :
第一代分布式文件系统(1980~1990)
早期的分布式文件系统一般以提供标准接口的远程文件访问为目的,更多地关注访问的性能和数据的可靠性。早期的文件系统以NFS (Network File System)和AFS (Andrew File System)最具代表性,它们对以后的文件系统设计也具有十分重要的影响。
第二代分布式文件系统(1990~1995)
这一时期的分布式文件系统主要需求是广域网和大容量。XFS (Extended File System)、Tiger Shark并行文件系统及Frangipani等分布式文件系统应运而生。其中,XFS借鉴了当时对称多处理器的设计思想,解决了广域网上缓存和减少网络流量的难题。后来出现的Tiger Shark文件系统则是专门针对规模比较大的多媒体应用。它做的创新主要集中在预留资源和针对资源优化的调度策略,保证了访问的高性能。
第三代分布式文件系统(1995~2000)
这一阶段,网络技术的发展和普及极大地推动了分布式文件系统的研究与应用,出现了许多优秀的分布式文件系统,如General Parallel File System (GPFS)等。数据容量、性能和共享的需求使得这一时期的分布式文件系统管理的系统规模更庞大、系统更复杂,更多的先进技术也得以应用到系统中实现,如分布式锁、缓存管理技术、Soft Updates技术、文件级的负载平衡等。
第四代分布式文件系统(2000年后)
随着SAN (Storage Area Network and SAN Protocols)和NAS (Network Attached Storage)两种体系结构逐渐成熟,研究人员开始考虑如何将两种体系结构结合起来,以充分利用两者的优势。另一方面,基于多种分布式文件系统的研究成果,人们对体系结构的认识不断深入,网格的研究成果等也推动了分布式文件系统体系结构的发展。各类应用对于分布式文件系统的要求也越来越高:如大容量、高性能、可扩展性、高可用性、可管理性等。
2.3. 分布式文件系统的优势
相对于传统存储方式,分布式文件系统具备如下优势:
一是节约成本。分布式文件系统使用大量廉价的设备存储数据,对于企业,减少了购买昂贵存储服务器的成本,分布式文件存储技术的应用,使得企业对设备的维护以及管理成本大幅度降低。
二是方便管理。分布式文件系统在设计时就考虑了数据的管理,特别是海量数据的管理,通过使用虚拟化技术,可以方便的完成数据的备份以及迁移等操作。
三是扩展性好。支持线性扩容,当存储空间不足时,可以采用热插拔的方式增加存储设备,扩展方便。
四是可靠性强。分布式文件系统包含冗余机制,自动对数据实行备份,在数据发生损坏或丢失的情况下,可以迅速恢复。
五是可用性好。用户只需要拥有网络就可以随时随地的访问数据,不受设备、地点的限制。
3. 典型分布式文件系统介绍
3.1. Google文件系统
Google文件系统(Google File System,GFS)是Google公司为了存储海量搜索数据而设计开发的面向搜索引擎的分布式文件系统,为大量用户提供高可靠、高性能、良好扩展的数据存储服务 [2] 。主要用于大型的、分布式的、需要对大量数据进行访问的应用。它对硬件要求不高,只需运行在廉价的普通硬件上即可为大量用户提供总体性能较高的服务。在Google搜索引擎中,最大的分布式存储系统集群中已经广泛的在Google内部进行部署,能够同时支持数百个客户端的访问,是处理整个WEB范围内难题的一个重要工具。
GFS架构
一个GFS由一个master和多个chunk servers组成,并且能够被多个客户访问。master在GFS中处于中心位置,存储整个文件系统的元数据,包括命名空间、访问控制信息、文件到chunk的映射信息以及任意chunk的位置信息。文件被master分成了固定大小的chunk,chunk servers在本地的磁盘上存储chunk。为了保证数据的可靠性,GFS中实行冗余数据机制,对于每个chunk,存储3份冗余数据,这样即使其中某一个chunk servers死机后,仍可通过访问其他chunk servers来获得数据。master可通过心跳消息与各个chunk servers保持同步,侦听各个chunk server的状态,并获取chunk位置信息。图1是GFS的基本架构。
3.2. Lustre
Lustre是一个大规模的、安全可靠的,具备高可用性的集群文件系统,Lustre名字是由Linux和Clusters演化而来,它是由SUN公司开发和维护。该项目主要的目的就是开发下一代的集群文件系统,可以支持超过10000个节点,数以PB的数量存储系统。因为其超强的计算能力和开源,所有通常用于超级计算机,Top 100的60%超级计算机都使用该文件系统 [3] 。
Lustre架构
Lustre是一个面向对象的文件系统。主要由三个部分构成:元数据服务器(Metadata Servers,MDS),对象存储服务器(Object-Based Storage Servers,OSSs)和客户端,Lustre使用块设备来作为文件数据和元数据的存储介质,每个块设备只能由一个Lustre服务管理。Lustre文件系统的容量是所有单个OST的容量之和。客户端通过POSIX I/O系统调用来并行访问和使用数据。图2是Lustre的基本架构。
3.3. Hadoop分布式文件系统
Hadoop是一个分布式系统基础架构,由Apache基金会所开发 [4] 。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。Hadoop的一个核心子项目就是Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是一个基于Java的文件系统。HDFS有高容错性的特点,并且设计用来部署在低廉的硬件上;而且它提供高传输率来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS放宽了POSIX的要求,可以流的形式访问文件系统中的数据。
HDFS架构
HDFS文件系统采用主从系统结构 [5] ,一个提供元数据服务的Namenode节点和若干个提供数据存储的Datanode节点构成一个HDFS集群,分布式文件系统将元数据和应用数据分别存储在Namenode及Datanode中,各个服务器之间通过RPC协议进行通信。HDFS命令空间是分层次的文件及目录结构,Namenode维护命名空间树及文件块与Datanode之间的映射文件,Datanode负责存储实际的数据。Datanode与Namenode之间通过心跳信息进行通信,在通信中报告自己的运行状况。图3是HDFS的基本架构。
3.4. Fast分布式文件系统
Fast分布式文件系统(Fast Distributed File System, FastDFS),是由余庆根据MogileFS的设计思想改进而来的类GFS“键值对”的轻量级开源分布式文件系统,目前只支持LinuX等UNIX系统。FastDFS是专门针对互联网应用(存储海量小文件)量身定做的系统,其主要功能包括:文件的存储、文件的同步、文件的访问等。它通过C语言实现,为文件的存取访问设计了专用的应用程序接口,因此可以为其定制客户端,目前客户端已经有了PHP、Python、JAVA等版本,已经有多家公司使用FastDFS来搭建存储平台及应用,如UC、支付宝、赶集网等大容量存储应用。
FastDFS架构
FastDFS中只有两个角色,跟踪服务器Tracker Server和存储服务器Storage Server [6] 。

Figure 1. The architecture of GFS
图1. GFS基本架构
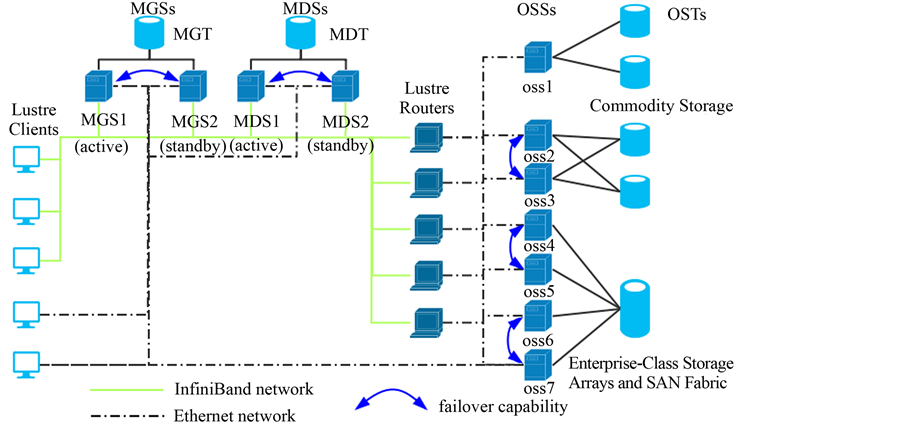
Figure 2. The architecture of Lustre
图2. Lustre基本架构
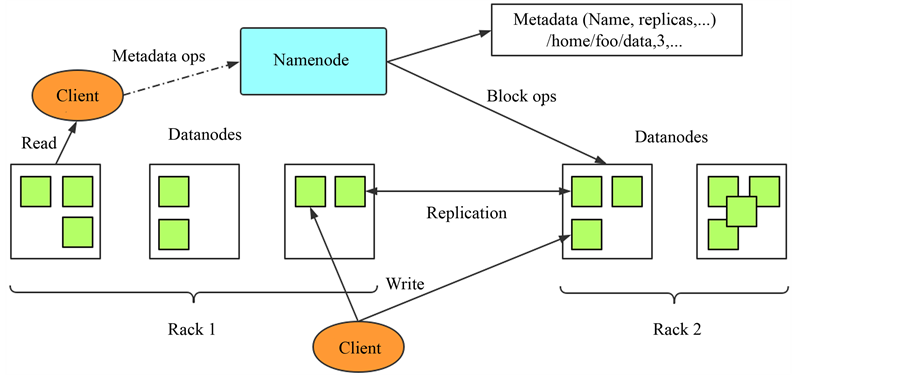
Figure 3. The architecture of HDFS
图3. HDFS基本架构
Tracker Server是FastDFS中心节点,它的任务是收集Storage Server的状态信息、调度客户端请求和负载均衡。Tracker Server将收集的存储服务器状态信息存储在内存中,并且记录分组的信息,但是没有记录文件的任何索引信息,所以需要占用很少的内存。当收到Client和Storage Server发来的请求时,Tracker Server在记录的分组和Storage Server信息中寻找需要的信息,然后做出应答。Storage Server直接通过本地操作系统中的文件系统来存储文件,存储文件时直接存储整个文件,而不会对文件进行分块存储,客户端上传的文件和Storage Server上的文件一一对应,图4是FastDFS基本架构。
3.5. 淘宝文件系统
淘宝文件系统(Taobao File System,TFS)是淘宝内部使用的分布式文件系统,承载着淘宝主站上所有的图片、商品描述等数据存储。TFS的设计初衷是为了解决淘宝网站海量小文件的存储问题,在淘宝开发人员的努力下,TFS文件存储系统完全解决了淘宝海量小文件存储的问题。TFS文件存储结构也采用了块的概念,TFS文件存储系统中的块的大小默认64 M,但是可以根据需求更改配置项更改块的大小。
FastDFS架构
TFS文件存储系统分为两部分NameServer节点和DataServer节点,采用主从式架构,由两个NameServer节点和若干个DataServer节点组成,两个NameServer节点分别为一主一备,提高系统的安全性 [7] 。
NameServer节点负责管理和维护block和DataServer的相关信息,包括DataServer加入、退出、心跳信息,block和DataServer对应关系的建立和解除。DataServer节点负责实际数据的存储和读写,正常情况下,每一个block都会在多个DataServer节点上存在,也就是说每一个文件都有多个备份,确保了数据的可靠性。在DataServer节点上,block都是以主块+扩展块的形式存在的,一个block对应一个主块和多个扩展块。扩展块的应用是为了在文件大小发生变化时,如果主块的存储空间不够的话可以将数据放到扩展块里面。DataServer内部为每一个block保存了一个与该block对应的索引文件(index),在DataServer启动时会把自身所拥有的block和对应的index加载到内存。图5是TFS基本架构。

Figure 4. The architecture of FastDFS
图4. FastDFS基本架构
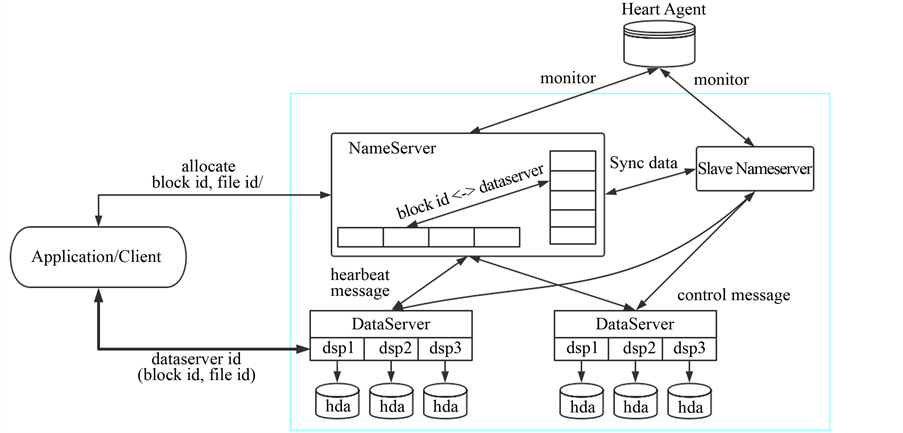
Figure 5. The architecture of TFS
图5. TFS基本架构
4. 结束语
随着计算机和网络技术的进一步发展,越来越多的应用需要磁盘容量更大、处理速度更快、扩展性更高的分布式文件系统,在这种需求拉动下,越来越多的优秀的分布式文件系统出现在大众面前,根据各类应用的不同需求提供不同的服务,它们在数据存储、数据管理、数据共享、安全性、稳定性、可用性和扩展性方面也各有所长、各具特色,深入探析各类分布式文件系统的优势和特性,整合资源取长补短,在互联网+、人工智能等新的领域中发现更大价值。
文章引用
杜振南,朱崇军. 分布式文件系统综述
A Survey of Distributed File System[J]. 软件工程与应用, 2017, 06(02): 21-27. http://dx.doi.org/10.12677/SEA.2017.62003
参考文献 (References)
- 1. 韩增曦. 分布式文件系统FastDFS的研究与应用[D]: [硕士学位论文]. 大连: 大连理工大学, 2014.
- 2. 周子涵. 基于FastDFS的目录文件系统的研究与实现[D]: [硕士学位论文]. 成都: 电子科技大学, 2015.
- 3. 白铖. 一种分布式文件系统的设计与实现[D]: [硕士学位论文]. 成都: 电子科技大学, 2015.
- 4. 周小玉. HDFS分布式文件系统存储策略研究[D]: [硕士学位论文]. 成都: 电子科技大学, 2015.
- 5. 胡军杰. 云平台下分布式文件系统评测技术研究[D]: [硕士学位论文]. 哈尔滨: 哈尔滨工业大学, 2014.
- 6. 王波. 基于FastDFS的轻量级分布式文件系统的设计与实现[D]: [硕士学位论文]. 沈阳: 东北大学信息科学工程学院, 2013.
- 7. 翟猛. 基于TFS的分布式文件存储平台研究与实现[D]: [硕士学位论文]. 天津: 河北工业大学, 2014.