Computer Science and Application
Vol.1 No.3(2011), Article ID:382,4 pages DOI:10.4236/csa.2011.13029
XML Query Technology Research Based on Node-Set
College of Information Science and Engineering, Shenyang University of Technology, Shenyang
Email: niulq@sut.edu.cn; dianxiaoke@163.com; zsncjr@sina.com
Received: Oct. 16th, 2011; revised: Nov. 1st, 2011; accepted: Nov. 22nd, 2011.
ABSTRACT:
XML query languages take complex path expressions as their core. According to the long path expression, especially Production of a large amount of intermediate results; the larger price can be spent on joining operation of indexical nodes. This paper put forward a model which supports projection operation; choose operation and high efficient structure connection in node set. Meanwhile, this model provides path query processing with more choices.
Keywords: XML Path Query; Structural Join; XML Query Pattern
基于节点集的XML查询技术研究
牛连强,董世超,张胜男
沈阳工业大学信息与工程学院,沈阳
Email: niulq@sut.edu.cn; dianxiaoke@163.com; zsncjr@sina.com
摘 要:
复杂路径表达式查询是XML查询的核心研究内容。针对长路径表达式,尤其是在查询中间结果较多,节点索引的连接操作代价较大的情况下,提出了一种基于节点集的索引方式。该方式支持节点集间的投影操作、选择操作以及高效的结构连接,从而实现数据的快速查询并形成基于节点集的XML查询模式。同时该模式为XML基于路径的查询处理提供了更多的选择。
收稿日期:2011年10月16日;修回日期:2011年11月1日;录用日期:2011年11月22日
关键词:XML路径查询;结构连接;XML查询模式
1. 引言
随着XML应用的日益广泛,XML数据管理和查询问题也引起了人们的普遍关注,并成为研究的热点。尽管XML有其各种不同的表示和用途,但其本质仍然是基于层次的数据结构,并可映射为相应的XML关系树或者XML关系图[1]。当前已有学者提出了多种XML查询语言,例如Xpath、Xquery等,这些查询都将路径表达式[2]作为其研究的重点,通过节点等价、路径等价等技术,得到比原始文档小得多的索引树,进而通过索引树的遍历得到查询结果。基于路径的索引技术可以很好地支持简单路径表达式的查询,但是对于正则路径表达式,效果不太理想。目前被广泛采用和接受的是分解连接查询[3],其执行策略的基本思想是首先定位所要查询的节点集,然后在节点集之间加入结构连接从而形成新的XML关系树。由于在查询过程中需要进行大量节点之间结构连接的操作,因此高效的结构连接算法是实现XML查询的关键。本文侧重于研究如何获得合理的节点集,如何在结构连接的基础上加入一些基本的关系操作从而提高查询的效率。结合关系树模型,本文提出了以最大相关节点集为主要操作对象的查询模式,该方法充分利用集合的基本操作,增大了基本查询片段的粒度,从而减少了产生的部分中间结果。同时在提高结构连接效率基础上引入选择、投影等操作,实现相关节点集的筛选连接操作,形成查询路径获得查询结果。
2. 关系树模型
XML是层次化数据结构,采用当前比较成熟的层次化数据模型DOM (Document Object Model)对XML模式进行建模,即将XML层次结构转化为一棵有向的XML关系树。DOM主要描述文档本身的结构和内容,同时为了增加通用性,DOM同时支持DTD和XML Schema两种XML模式语言。
在XML关系树中,规定树中节点的方向为自顶向下,节点之间存在父子,兄弟、祖孙联系,将这种XML关系树称之为SLT树[4]。在SLT树中定义两种节点,一种为数据节点,它包括元素、元素的属性以及属性的取值;一种为结构节点,它主要包括元素之间先后顺序,元素之间的继承关系等。图1为一个SLT实例,树中每一个节点都有两个属性:max_occr和min_occr,max_occr表示为出现的最高频率,min_occr表示为最低频率。
DTD example:
<! ELEMENT Company(employees,wages)>
<ATTLIST Company name CDATA
#REQUIRED>
<! ELEMENT employees(employee)*>
<! ELEMENT forms (form)*>
<! ELEMENT wages (position,wage)+>
<!ELEMENT employee (work_id,position?)>
<! ELEMENT work_id (#PCDATA)>
<! ELEMENT position (#PCDATA)>
<! ELEMENT wage(#PCDATA)>
在SLT树中,还需要定义以下三个概念:
1) 路径:从一个节点i到另外一个节点j所经过树的分支称为i到j的路径,其中路径上两个相邻节点只能为父子或者子父关系,不能为兄弟或者祖孙关系。
2) 度数:一个节点的度数为SLT树中从根节点到目标节点Max_occr的值大于1的节点个数。例如在图1中,comment的度数为1,其路径为(companyemployees-employee)其中对应的Max_occr为(1, 1, more)。
3) 相关节点集:相同度数的节点构成相关节点集,但是相同度数的节点不一定在同一个相关节点集中。图1中,(comments, forms)为一个相关节点集。
4) 最大相关节点集:相关节点集的最大集合称之为最大相关节点集。图1中,(wenjuan, name, comments, forms)则为一个最大相关节点集。
3. XML查询处理
3.1. XML查询树构造
XML查询树的构造采用如下步骤:
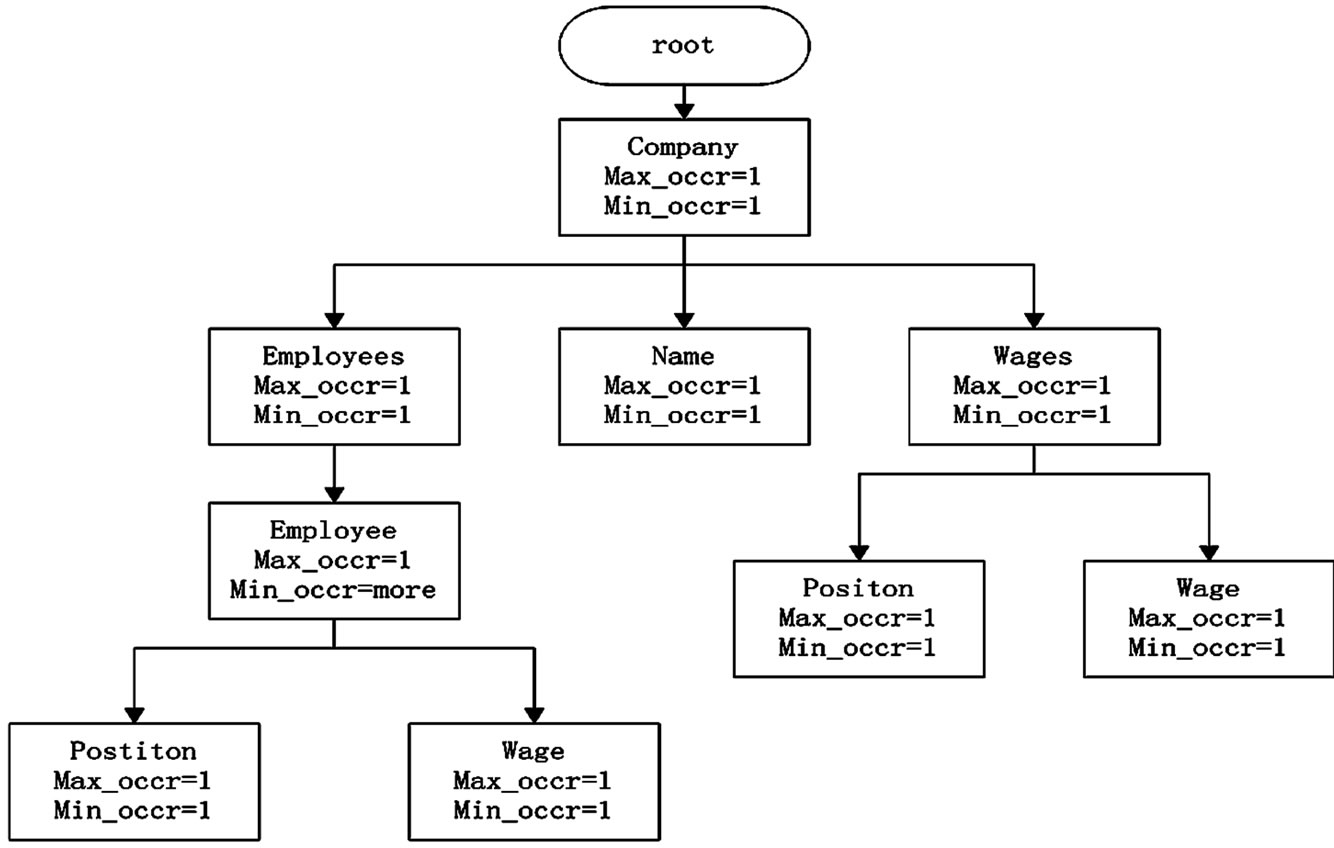
Figure 1. An example of SLT
图1. SLT实例
1) 对SLT树进行手工节点划分;
2) 将SLT划分成若干个最大相关节点集;
3) 由最大相关节点集构成一棵新的树,称之为Node树。
例如对图2中的SLT树进行划分,获得A、B、C,3个最大相关节点集:
A = (company, name, employees, wages)
B = (employee, position, wage)
C = (wages, wage, position)
3.2. 结构连接
XML路径查询是利用其XML生成树各枝节之间的关系进行查询,在查询过程中,可能产生多余的枝节,这样将导致查询效率的下降,消耗大量的时间和空间。以目标节点为导向的查询主要是通过利用查询树中的目标节点来避免中间枝节的传递[5],而基于最大相关节点集的查询则不同,它是通过节点之间的联系,即通过查找相关节点集来代替路径查询中的路径遍历,以查询尽量少的节点来获得查询结果。在查询过程中,由于XML已经转化为Node树,则查询过程即是利用最大相关节点集构造一棵新的Node树的过程,查询结果则为构造后的Node树的叶子节点。
当前存在的结构连接算法主要有:归并连接算法[6]和非归并连接算法[7],其中归并连接算法又包括直接归并连接算法和基于缓存的归并连接算法[8],归并连接算法的基本思想是:设参加连接的两个关系表为Alist和Dlist,首先对Alist中的第一个节点a1,在Dlist中顺序搜索到可能与节点a1连接的第一个节点,称为扫描始点,然后在Dlist中从扫描始点开始顺序扫描,对满足begin < a1.end条件的所有元组dj再判断是否满足连接条件。若满足,则产生连接结果节点对(a1.dj);继续对Alist中的第二个元组a2重复上面的步骤,直到listA或listD中元组连接完毕。直接归并连接算法缺点是可能存在重复的元组,从而导致重复扫描,最坏的情况下效率很低。
基于缓存的归并连接算法[9]是对于直接归并连接算法的一种改进,即在其对比的过程中加入队列或者栈等数据结构进行元组的比较,查询效率较高,但是要利用额外的空间。
本文利用归并连接思想,对最大相关节点集进行扩充,即在最大相关节点集中加入最大相关节点集的父节点。对于包含根节点的最大相关节点集,则再次加入根节点,以此来表明该最大相关节点集是Node树中的根节点;对于其他最大相关节点集则是加入其根结点。例如扩充后的最大相关节点集B为(employees, employee, position, wage)。其结构连接如下,对于Node节点A和B进行连接,首先利用B中的节点与A中的节点进行匹配,如果匹配成功,则通过匹配成功的节点进行连接,如果未能匹配成功,则说明A、B节点在Node树中非父子或者子父关系,即构造失败。
在对其进行结构连接时,结构结构连接的实现是在其各个最大相关节点集之间进行的,首先获取结构
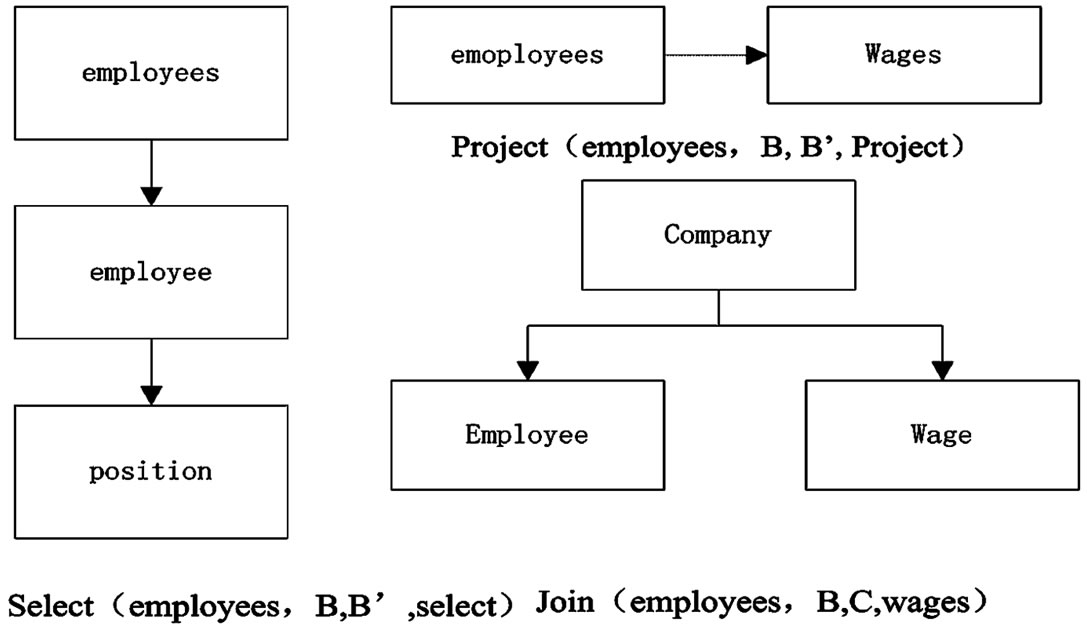
Figure 2. All kinds of node operation
图2. 各种节点操作
连接的两个最大相关节点集A和B,选取B中的一个节点去匹配A中的节点,如果匹配成功则A、B节点连接成功;如果匹配不成功,则选择B中的其他节点进行匹配。若B中所有节点都未能匹配成功,则连接失败。如要结构连接的是兄弟节点或者祖孙节点,则需要在结构连接过程中利用其他的节点,称之为桥梁节点。其思想为首先找到叶子节点,然后与上层节点,或者其父节点匹配;接着其父节点再进行上层匹配,重复匹配上层节点,最终得到根节点,则连接成功。
其上算法为:
F-SNode Struct_link算法:
If (!Node){
For (F in Node and S in Node)
If (F.node == S.node)
{F&S;Node.add (F, S)}
Else{printf (“Node can not link”);}}
B-B’ Node or G-G’ Node结构连接:
If (!Node){
For (B in Node and B’ in Node)
If (C in Node)
{C.node = B.Node;C&B;
Node bc = Node.add(B, C);
C.node=B’.Node;C&B’;
Nodebc’=Node.add(C,B’);
Node.add(bc,bc’)
}
Else{printf(“C Node not exsit”);
}
}
3.3. XML查询
当前XML查询主要是通过路径的遍历来完成的,而在查询过程中可能会产生一些无效的路径查询操作[10]。而基于相关节点集的查询利用其逆向查询,获得查询路径得到查询结果,在查询的过程中减少了部分中间结果。使得查询效率得到一定的提高。
设有四元组(r, s, s’, v),其中s和s’为最大相关节点集,r为s的根节点,v为相关操作,利用其相关操作实现其目标节点的选择,然后在目标节点选择后加入投影、选择、结构连接等操作实现数据的查询。
3.3.1. 选择(select)
选择操作(select)是指在查询的过程中,利用其查询的目标节点定位到其所在的最大相关节点集,在其定位的最大相关节点集合中进行节点的操作。在四元组中选择操作的具体实现为:在Node树中,选择要查询的是最大相关节点集B中的position节点,利用选择操作选择该节点,则B中只剩余该最大相关节点集中的根节点和其position节点。对于剩余的节点结合进行连接,获得一个Node树中的单分支,进行多次选择获得多个分支,提供其查询过程中的各个路径分支。实现上述操作的四元组为:Select (employees, B, B’, select)如图2。
3.3.2. 投影(Project)
投影操作是指在XML层次中对于某一些属性值,即XML生成的Node树中,投影某些Node节点,对于Node树上的节点进行多节点的操作。在Node树中,为了获得同一层次的信息,可以利用投影操作。例如在Node树中,利用投影操作,获得某层次的某些节点集合。例如在对于上边给定的Node树中选择其第二层次的所有节点进行投影操作,其实现如下: Project (employees, B, B’, Project)如图2。
3.3.3. 连接(Join)
连接操作,该操作是查询的关键,主要是查询某个节点时通过利用逆向方式获得连接路径,而最后获得所要查询的节点位置。例如为了获得查询的整个路径,主要是利用连接操作通过对于各个不同相关节点集合中的连接,对于Node树进行裁剪获得一棵新的Node树而该树则为XML查询的路径生成树。例如在给定的Node树下查询employees中某部门和wages下工资相结合的内容,连接实现查询的操作为Join (employees, B, C, wages)如图2。
4. 实验示例
基于以上理论,在最大相关节点集的基础上,对其单个或者多个最大相关节点集进行操作。简单来说,对于单个相关节点集利用选择操作,获得某些节点而对于多个最大相关节点集的操作则是先进行选择、投影操作,利用获得的一些相关节点进行利用最大相关
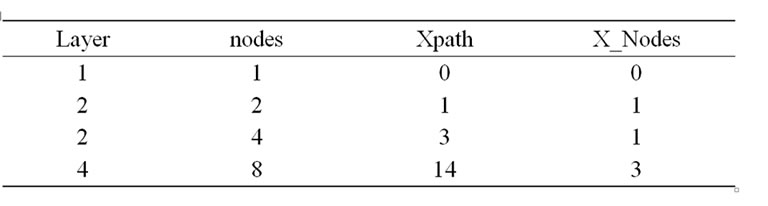
Table 1. Comparison times of query node
表1. 查询所需节点比较次数表
节集的连接操作,实现路径的逆向连接。最后获得所需要的查询路径。从而生成以最大相关节点集为基础的XML查询技术。
以下我们将以图1中给出的DTD文档作为源模式文档,通过将其文档转化为SLT树再对其生成的SLT树划分得到一个Node树,将该文档分割为问卷的元素信息和格式信息,元素的类型需要根据元素类型中的选项给出,而对应的题号通过匹配相应类型得到。在目标模式文档中,希望得到的是题号为X的节点,则利用其最大相关节点集的XML查询方式,利用上边定义的四元操作实现如下:首先生成最大相关节点集如下,
A = (company, name, employees, wages);
B = (employees, employee, position, wage);
C = (wages, wage, positon);
获得题号为X则通过对最大相关节点集进行查询获得B’ = (employee, wage),通过结构连接操作,将B’与其上层父Node节点进行连接通过共有的company节点进行匹配连接,获得其路径为company-employeesemployee则查找成功,若没有匹配结果则查找失败。
同时通过对于不同层次的XML查询连接进行试验比较,通过对路径查询和基于最大相关节点集的查询比较,对于层次较少或节点较少的XML其比较次数和效率基本相同,但是对于多枝节或者是层次较多的XML来说,利用最大相关节点集的比较次数要明显小于利用路径查询进行直接归并连接的次数,XML不同查询方式下次数比较对比如表1。
其中layer表示XML层次,nodes表示XML转化后生成SLT树后的节点数,Xpath则是表示路径查询过程中节点的比较次数,X_Nodes则表示本文所将的最大相关节点集的XML查询方式。通过比较可以看出,在层次单一,节点较少的情况下两者的比较次数基本相当,但是随着层次和节点的增加,其比较次数在传统的XML路径查询方式中将会变的越来越多,从而导致效率的下降,而对于基于最大相关节点集合的节点比较虽然也是逐渐增加但是明显要小于传统的XML路径查询过程中的比较次数。而在进行XML查询的过程中基于路径的查询相当于对于XML生成树的遍历,如何以最快的速度获得要查询的XML内容即在XML生成树上的节点则是查询的关键,要实现以最快的速度获得要查询的内容,比较次数越少则实现的效率相当来说就会越高。所以通过基于最大相关节点集合的想法可以在很大程度上减少比较的次数,缩短遍历的路径从而提高查询的效率。
5. 总结
如何减少路径查询过程中的计算是XML路径查询的关键问题。本文结合最大相关节点集的概念,提出了逆向路径查询的方法。该方法在进行查询连接的过程中通过扩展最大相关节点集的思想,实现利用最大相关节点集进行连接。连接的过程中通过减少大量的中间枝节提高了查询的效率。同时在进行查询的过程中加入选择、投影运算减少在确定其目标节点的前提下其它无用节点的影响,提高其命中效率。本文的查询工作主要是针对层次结构明显同时查询节点之间有密切联系的XML进行查询,而对于匹配不成功的处理方式和对于松散的,联系不密切的查询将是下一步的主要工作。
参考文献 (References)
[1] 张澎, 徐红云, 王鲁达等. 一种基于XML的树型代数[J]. 计算机仿真, 2008, 5(25): 147-151.
[2] 沈剑沧, 鲍培明. XML查询方法的设计与研究[J]. 计算机工程, 2007, 21(33): 63-65.
[3] 孔令波, 唐世渭, 杨冬青等. XML数据的查询技术[J]. 软件学报, 2007, 6(18): 1400-1418.
[4] 杨文军, 李涓子, 王克宏. 基于关系树模型实现数据转换[J]. 计算机科学, 2004, 11(31): 114-117.
[5] 王静, 孟小峰, 王宇. 以目标节点为导向的XML路径查询处理[J]. 软件学报, 2005, 5(16): 828-837.
[6] 门爱华, 周立柱, 张亚鹏. XML数据库结构连接算法之分析[J]. 计算机科学, 2007, 6(34): 136-139.
[7] 孔令波, 唐世渭, 杨冬青等. XML数据的查询技术[J]. 软件学报, 2007, 6(18): 1400-1418.
[8] 陶世群, 富丽贞. 一种高效非归并的XML小枝模式匹配算法[J]. 软件学报, 2009, 4(20): 795-803.
[9] 王国仁, 乔百友, 韩东红. 基于分片的XML快速结构连接算法[J]. 计算机学报, 2008, 1(31): 78-90.
[10] M. Fernadez, W.-C. Tan and D. Suciu. SilkRoute: Trading between relations and XML. Computer Network, 2000, 33(1-6): 723-745.