Advances in Psychology
Vol.2 No.4(2012), Article ID:2887,9 pages DOI:10.4236/AP.2012.24026
The Mechanism Underlying Chinese Orthographic Decomposition
1Department of Psychology, Fo Guang University, Yilan County
2Department of Psychology, National Taiwan University, Taipei
Email: cmcheng@ntu.edu.tw
Received: Jul. 28th, 2012; revised: Aug. 14th, 2012; accepted: Aug. 26th, 2012
ABSTRACT:
Chinese Orthographic Decomposition refers to a sense of uncertainty about the writing of a well-learned Chinese character following a prolonged inspection of the character. An implicit test using a lexical-decision task, in which 2-character words were discriminated from 2-character pseudo-words, was used to detect the orthographic decomposition. An index designated as β was developed to measure the rate of decomposition. Results of this study show that repeated presentations of a character consisting of 2 radicals (the LR-character) resulted in a larger value of β than did those of a character consisting of a single radical. However, the value of β for a LR-character was independent of the pro-nounceableness and meaningfulness of its constituent radicals. These results suggest that Chinese orthographic decomposition is due to the absence of a direct link between the orthography and the sound pattern of Chinese characters.
Keywords: Orthographic Decomposition/Satiation; Chinese-Character Processing; Reading and Writing of Chinese
汉字的解体及其机制
郑昭明1,2,赖惠德1
1台湾佛光大学心理系,宜兰县
2台湾大学心理系,台北
Email: cmcheng@ntu.edu.tw
摘 要:
“汉字的解体”是指,持续的注视一个熟悉的汉字之后,会产生一种“愈看愈不像”的奇怪感觉。本研究使用一个词汇判断的作业,观察汉字解体的现象并探索其发生的机制。一个指标β用以指示解体率。实验比较“独体字”与“合体字”的解体率与观察一个“形声字”的解体率是否与字与其“声旁”的语音相似性及与其“义旁”的语意相似性有关。结果显示,合体字的解体率大于独体字的解体率,但独体字仍然解体。“形声字”的解体率与“字–声旁”的语音与“字–义旁”的语意相似性无关。此结果表示,一个汉字的解体与此字注视之后是否触发字与其组成部件的字汇地址无关。解体的另一可能原因是意符的汉字其“字形”与“语音”的连结不是依据一套“形–音”对应的关系、而是“强记”而学会的。因此,其收录的语音不能用来结合注视之后的支离的视觉讯息成为原始的字形,最终造成解体的感觉。
收稿日期:2012年7月28日;修回日期:2012年8月14日;录用日期:2012年8月26日
关键词:汉字的解体/餍足;汉字的讯息处理;汉字的书写与阅读
1. 引言
当代汉字阅读的研究(Cheng & Lan, 2011; Cheng & Wu, 1994; Ninose & Gyoba, 1996, 2002)发现了一个“汉字字形解体”(Chinese orthographic decomposition)的现象,此现象是指,对一个熟悉的汉字的书写产生不确定的奇怪感觉。此现象亦称为“汉字字体的餍足”(Chinese orthographic satiation),因为它只有在持续的注视一个汉字之后,才会产生。譬如,一位母语为汉语的人被要求去观看一个熟悉的汉字如“动”者,经由多年的使用,此观看者能立即的认得此字是一常用的汉字。但是当持续的注视一段时间(通常约20秒或更短)之后,此观看者开始对此字怀疑它是否由“重”与“力”所组成。
汉字解体的经验不只发生在对单字的阅读,也发生在一般语文脉络下的阅读。譬如,当被要求连续的阅读并判断一系列以“动”为首的双字刺激如“动能”、“动泰”与“动作”是否为合法的词时,一个人亦能经验到重复字“动”的解体而使其在系列末尾判断刺激时,较为困难(Cheng & Lan, 2011)。
Cheng与Wu(1994)首先在一个实验里,要求汉语为母语的参与者对一个呈现在计算机屏幕上的目标汉字持续的注视,一直到感到此字“愈看愈不像”或“不确定此字的书写是否是正确”时,即刻按下计算机键盘上一个指定的反应键。解体的时间是从“目标字呈现”到“反应出现”的时间距离。他们发现,相较于独体字如“木”者,一个由左右或上下两部件所组成的合体字如“动”者产生较快的解体时间。但是,字的“笔划数”与“使用频次”对解体时间不产生作用。
Cheng与Wu(1994)亦观察“形声字”(如“指”)的解体。每一形声字由一“声旁”与一“义旁”所组成,前者被认为是携带“字音”的地方;后者被认为是携带“字义”的地方。他们发现,形声字与其声旁具相异发音时,比具相同发音时产生较快的解体时间。但是,形声字与其义旁的语意相似性则对解体不产生作用。
Ninose与Gyoba(1996)要求日语为母语的参与者(亦为汉字的使用者)观察一个“适应汉字”(adaptation character)25秒之后辨识一个“目标汉字”。适应与目标汉字可能共有相同的字形结构(如两者都是左右合体字)或不具相同的结构(如适应字是左右合体字,而目标字是上下合体字)。适应与目标汉字可能共享相同的部件或不共享部件。结果发现,适应与目标汉字共享相同的结构与大小时,目标汉字的辨识时间有显着的延长(其实验1)。大小不同时,相同结构与部件造成辨识时间的延长;但是相同结构、不同部件不造成辨识时间的延长(其实验2)。Ninose与Gyoba(2002)亦发现,适应与目标字均为合体字且相同时,造成辨识时间的延长,但独体字不造成时间的延长。
2. 汉字解体的可能原因
直至目前为止,文献从未报导,持续注视一个物体、人脸或英文字会造成类似汉字解体的现象。譬如,重复呈现一个英文字会造成此字主观与暂时性的语意丧失(如Kounios et al., 2000; Smith & Klein, 1990)。因此,持续的注视英文所造成的是一种语意的丧失,而非字形的解体。基于此理由,作者认为,汉字解体可能与汉字特殊的意符(logographic)结构有关。
不像拼音字体由几个字母组成一个字,用以代表一个语音,藉语音再代表一个外界的事或物,一个汉字,是设计用来直接代表一个外界的事物、事件或思想(见徐慎的《说文解字》)。有些汉字是由几个交叉的笔划所组成,象征外界的事物(即“象形字”如“山”、“木”)或指称一个事件或概念(即“指事字”如“上”、“下”)。其它的字是由两个以上的象形字、指事字与/或部件所组成,以代表一个事物、行动或思想(即“会意字”,如“止”“戈”为“武”,或“形声字”,如“江”,其声旁为“工”;义旁为“水”)。
此外,不像英文存在着一套相当严谨的“拼写–声音”的对应关系(spelling-sound correspondence)(见Coltheart, 1978),合体汉字缺乏一套严谨的“组字–声音”的对应规则,亦即在中文的“形–音”对应关系是间接的。譬如,一个形声字与其声旁可能是语音相同的(如“指”与其声旁“旨”均念为“zhi”)或语音相异的(如“诣”念为[yi],而其声旁“旨”念为“zhi”)。同样的,一个形声字与其义旁可能是语意相似的(如“指”与其义旁“手”是语意相似的)或语意相异的(如“拐”与其义旁“手”是语意相异的)。
如此,大部分的合体汉字的组成部件都各自有其自己的“字汇地址”(lexical entry)。根据以上的看法,作者认为,持续的注视一个合体字将会导致此字与其部件的字汇地址的激发。此“多项字汇地址的激发”(activation of multiple lexical entries, AMLE)可能是造成文字解体感觉的原因,因为从语文理解的观点来看,一个字只能触发一个字汇地址,才能达到理解的目的。
以上AMLE假说预测,虽然持续的注视一个英文字,也会导致此字视觉讯息如其词素(morpheme)的分析,但这些组成的词素其语音是字音的一部分、其意义是字义中的一部分。譬如,英文字如chairman虽然由两自由词素chair与man所组成,但两词素的语音是字音的一部分、其意义是字义其中的一部分。相同的,raindrop与其组成的词素rain与drop亦具同样的关系。如此,持续的注视英文字不会造成多项字汇地址的激发,因此不会造成英文字的解体。
在英文里,有某些字根(root)是自由词素(如shipment的ship),其它的字头(prefix)或字尾(suffix) (shipment的ment)皆为“捆绑词素”(bound morpheme)。这些词素只携带“语法的意义”(grammatical meaning),而无自己的字汇与其地址。因此,持续的注视这类字,也不造成解体。英文字如tenant的ten- 看似自由词素,因为有一独立的英文字ten,但tenant源自于拉丁字tenere(即to hold),ten- 的意义不在英文字ten的意义之中,因此,tenant的ten- 在英文字tenant里是一捆绑、而非自由词素。
3. 研究目的
本研究旨在使用Cheng与Lan(2011)所发展的“内隐测验”(implicit test),观察汉字解体是否如AMLE看法所预测的一致。此假说的一项预测是,合体字由两个以上独体的象形、指事或部件所组成,将比独体字本身容易解体。此假说的另一预测是,一个形声字如其声旁与义旁在语音与语意上与字相异时,将比与字相似时容易造成解体。
字形解体的内隐测验
Cheng与Lan(2011)所发展的内隐测验,是用来客观的研究汉字的解体,以避免以前的研究使用主观报告的缺点(Cheng & Wu, 1994; Lee, 2007)。主观报告容易受到暗示与期许的影响,因此用来研究解体,有其限制。譬如,Cheng与Wu(1994)研究的参与者持续的注视一个字,可能并不产生解体,但因为被期望如此做,最终按下反应键。
此外,以前的研究(Cheng & Wu, 1994; Ninose & Gyoba, 1996, 2002)所报告的解体可能被认为是全有或全无,这可能是由于使用主观报告或适应法的结果。一个字不会被认为是解体,除非经过一段时间之后产生主观感受的解体与其作用。因此,以上方法的使用,不允许观察解体的程度随时间增加,如有的话,的现象,这与解体忽然从无到有,是不同的。
此内隐测验是一“词汇判断”的作业,比对两种刺激在“词汇判断时间”(lexical-decision time, LDT)上的差异。其中之一是双字刺激具相同的首字(如“收入”、“收受”与“收练”共有首字“收”),其中一半是合法的词,另一半是“同音假词”(如假词“收练”与“收肺”,不具意义,但分别与合法词“收敛”与“收费”同音)。这些刺激随机的安排在一个想象的矩阵空间里,如图1所示。此种矩阵称为“首字相同矩阵”。
另一种双字刺激的首字与第二字均彼此互异。其中一半是合法的词(如“动荡”与“强制”),另一半是“同音假词”(如假词“投守”与“领曲”与合法词“投手”与“领取”同音)。这些刺激亦随机的安排在一个想象的矩阵空间里。此类矩阵称为“首字相异矩阵”。
每一刺激矩阵呈现于计算机屏幕上供参与者注视,参与者被要求对矩阵的刺激从左上至右下对每一出现的刺激进行词汇判断。图2呈现六种“矩阵种类”(首字相同与相异矩阵) ד矩阵里的刺激位置”(如上半与下半位置)对LDT的交互作用。

Figure 1. An example of a same-initial stimulus matrix
图1. 一个首字相同的刺激矩阵
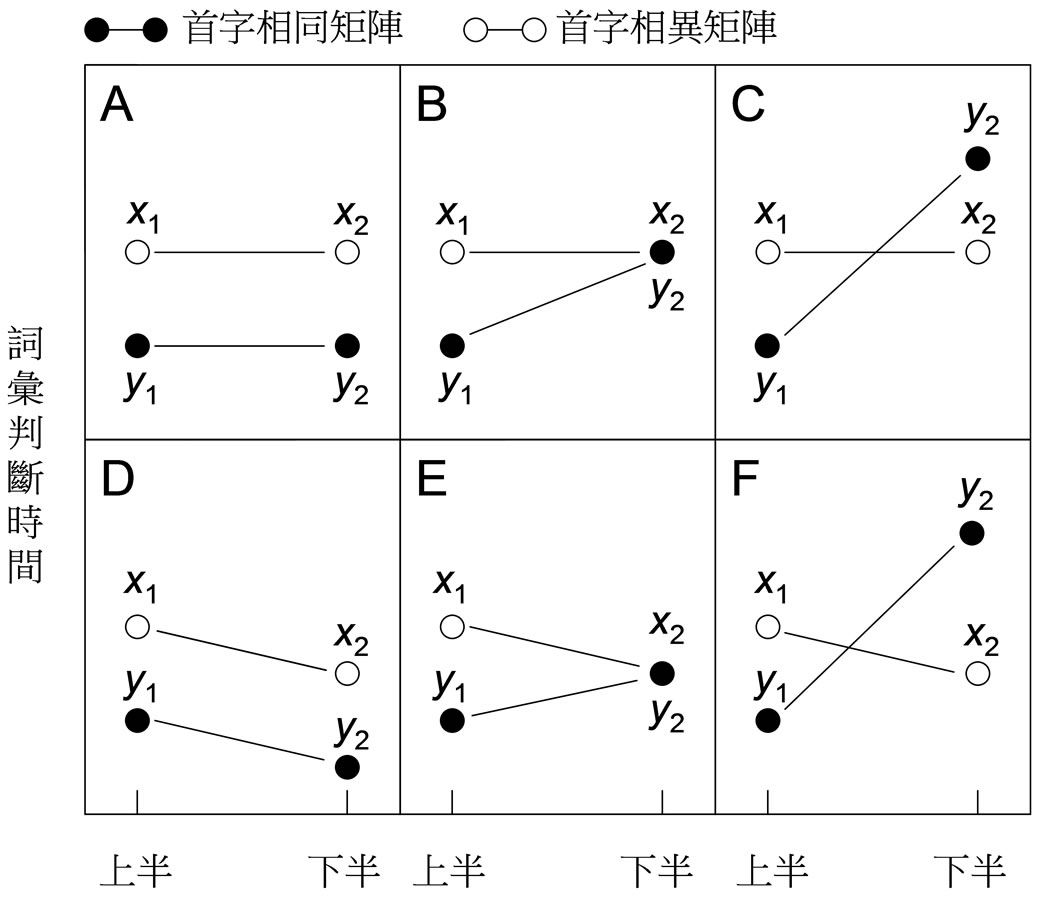
Figure 2. Mean LDT on upper-half and lower-half stimuluspositions in same-initial and differential-initial stimulus matrices
图2. 首字相同与首字相异刺激矩阵里上半与下半位置之 词汇判断时间
图2的方格A表示没有任何练习或进行性效果使得下半比上半位置的LDT较短或较长。但是,首字相同比相异造成较短的LDT,因为注视首字相同的词比注视首字相异的可省去一段时间。方格A表示词汇判断并无涉入文字解体的问题。
方格B与C的结果与方格A的相同,唯一的例外是,在首字相同矩阵里,下半位置刺激的LDT比上半刺激位置的要长,这是由于,在首字相同矩阵里,随着刺激的继续出现将造成首字的重复出现而解体,使此位置的词汇判断困难,增长了一段LDT。相对的,在首字相异矩阵里,由于没有任何一字重复,所以无文字的解体发生。
方格D与方格A相同,唯一的不同是,在首字相同与相异矩阵里,由于练习或进行性的效果,使得下半比上半刺激位置的LDT为短。但在方格D里,并无解体涉入到词汇判断之中。方格E与F等两者与方格D相同,唯一的不同是,方格E与F呈现解体对LDT的影响效果,使得此效果凌驾进行性的效果之后,显现下半比上半刺激较长的LDT。如此,在此词汇判断作业中,解体可从“矩阵种类” × “刺激位置”的交互作用如图2的方格B、C、E或F可以看出。
解体率
Cheng与Lan(2011)亦发展了一个指标,β,用以指示同一字增多注视一次所能引起解体的程度,称为“解体率”。每一参与者对每一字体的解体率是由此参与者对首字相同与相异矩阵里所有位置的合法词(不包括同音假词)所产生的LDT数据中去估计。现假设一参与者对一个首字相同矩阵第i区段(1 ≤ i ≤ n,此处n为一个矩阵里的刺激分成n个区段呈现)里所有合法词所产生的LDT的平均值为yi,则yi可从一个对应的首字相异矩阵的第i区段的平均值xi以下列的方式预测:
 (1)
(1)
此处α表示,相对于首字相异矩阵,在首字相同矩阵里由于注视相同的首字所节省的时间。β为解体率。Cheng与Lan用最小平方法(method of least square)解等式1的α与β,得
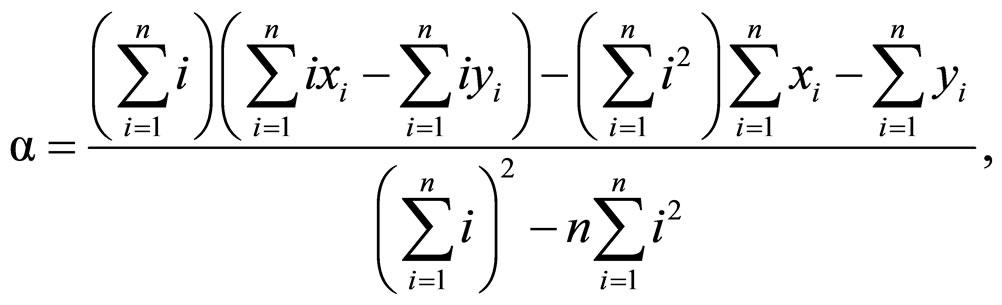
与
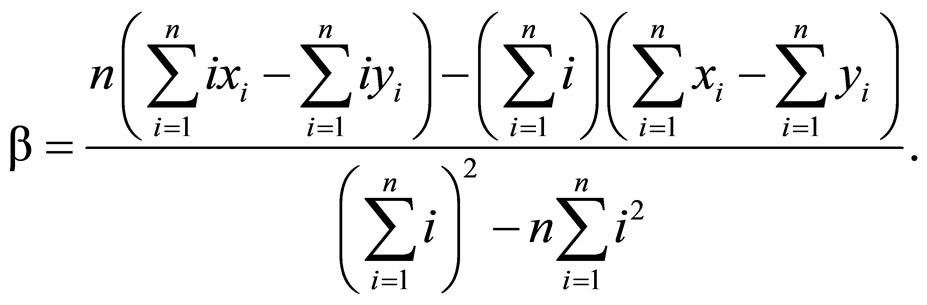 (2)
(2)
理论上,当等式2的β值为零时,无解体发生;大于零时,有解体发生。β值愈大,解体程度愈高。方格A与D里无解体发生,β值为零。方格B与E的β值为 ,方格C与F的β值为(x1 − y1) − (x2 − y2) = (x1 − y1) + (y2 − x2)。
,方格C与F的β值为(x1 − y1) − (x2 − y2) = (x1 − y1) + (y2 − x2)。
Cheng与Lan(2011)使用以上的内隐测验观察左右合体与独体字的解体,他们发现,不管字体为何,“刺激矩阵的种类” × “刺激位置”的交互作用如图2的方格F所示。但是,左右合体字的β值大于独体字的β值。根据Cheng与Lan,以上的结果不能使用“字邻”(orthographic neighborhood) (Coltheart, Davelaar, Jonasson, & Besner, 1977)的概念予以解释。
4. 实验1
实验1重复Cheng与Lan(2011)的实验2,以确定以上所提的内隐测验可用来有效的测量汉字解体。但是,与Cheng与Lan所使用的左右合体字不同,实验 1所使用的左右合体字其组成的部件皆为自由的部件,有其字汇的地址。第二,实验观察AMLE假说对汉字解体的预测。AMLE假说预测,左右合体字为首字的词汇判断对LDT将产生显着的“矩阵种类” × “刺激位置”交互作用以及显着大于零的β值。相反的,以独体字为首字的词汇判断所产生以上的交互作用将不呈显着的程度,而且β值亦不显着的大于零。
4.1. 方法
4.1.1. 参与者
二十四名台湾大学选修普通心理学课程的学生,自愿参与实验以获取额外的课程点数。参与者性别不拘,因为Lee(2007)曾发现,汉字解体的时间不因性别而异。
4.1.2. 实验材料
实验从Liu,Chuang,与Wang(1975)的词频常模 选出30个列表的双字词。每一列表有30个词具相同的第一组成字。其中的一半可变化成为“同音假词”(homophonic pseudo-words)。方法是一个词(如“推想”)的第二组成字(“想”)改换以另一同音字(如“享”),使其结果形成为一个无意义的假词(如“推享”),但与原来的词同音。一个探索性的研究指出,这些词皆为与参与者等同程度的大学生所熟悉的字与词。
每一列表的刺激随机安排在一个想象的5(行) × 6(排)矩阵空间里,形成一个“首字相同”的矩阵。如此,总共有30“首字相同”的矩阵。这些矩阵称为“首字(左右合体)相同”矩阵。
相对于以上的“首字(左右合体)相同”矩阵刺激,实验准备了30个“首字(左右合体)相异”矩阵。每一矩阵的刺激由以上30个列表的双字刺激、每列表取一刺激所组成、因此每一矩阵刺激亦由15个不同的双字词与15个不同的“同音假词”(homophonic pseudo-words)所组成,但其首字与第二组成字均彼此互异。由于首字(左右合体)相同与相异矩阵共享相同来源的刺激,以上一个“相同”与一个“相异”矩阵有半数的词与假词是相同的,其它一半相异。所有列表的刺激均出现在以上两种矩阵各一次。依照以上安排,所有刺激变项如词的使用频次、笔划数与词在同首字词的频次排列等在两种矩阵里是匹配的。
依照以上方法,实验也制造了两组、每组30个首字相同与30个首字相异的矩阵,其刺激首字为独体字。因此,这两组矩阵分别称为“首字(独体)相同”与“首字(独体)相异”矩阵。
以上的四组矩阵各组随机分为两子组、每子组15矩阵。
4.1.3. 实验设计与程序
每一参与者接受四子组的刺激矩阵,分别为“首字(左右合体)相同”,“首字(左右合体)相异”,“首字(独体)相同”与“首字(独体)相异”矩阵。四种矩阵的呈现顺序就每一参与者而言完全是随机决定的。一半的参与者接受四子组的刺激矩阵,其它一半的参与者则接受其它四子组的刺激矩阵。由于每子组有15矩阵的刺激,每一参与者于横跨四子组之后总共接受了60矩阵900双字刺激的测试。
4.2. 结果与讨论
4.2.1. 正确LDT
实验首先收集每位参与者对四种刺激矩阵里每一刺激区段(五连续刺激位置构成一个区段)对词的正确LDT的中数值(median)。由于一个区段的LDT是一种反应时间,倾向于偏态的分配,因此使用“中数”比“算数平均数”较能适当的代表个别参与者在每区段反应的“中央倾向”(central tendency)。
图3呈现24位参与者在每一矩阵里每一刺激区段的LDT的算数平均数与SEM。所使用的ANOVA是Chern与Cheng(1999)所发展的GANOVA程序(适合自动处理各种不同因子设计的变异数与简单主要效果的分析的程序)。对LDT进行ANOVA分析的结果显示,字体(左右合体与独体)对LDT不产生效果,
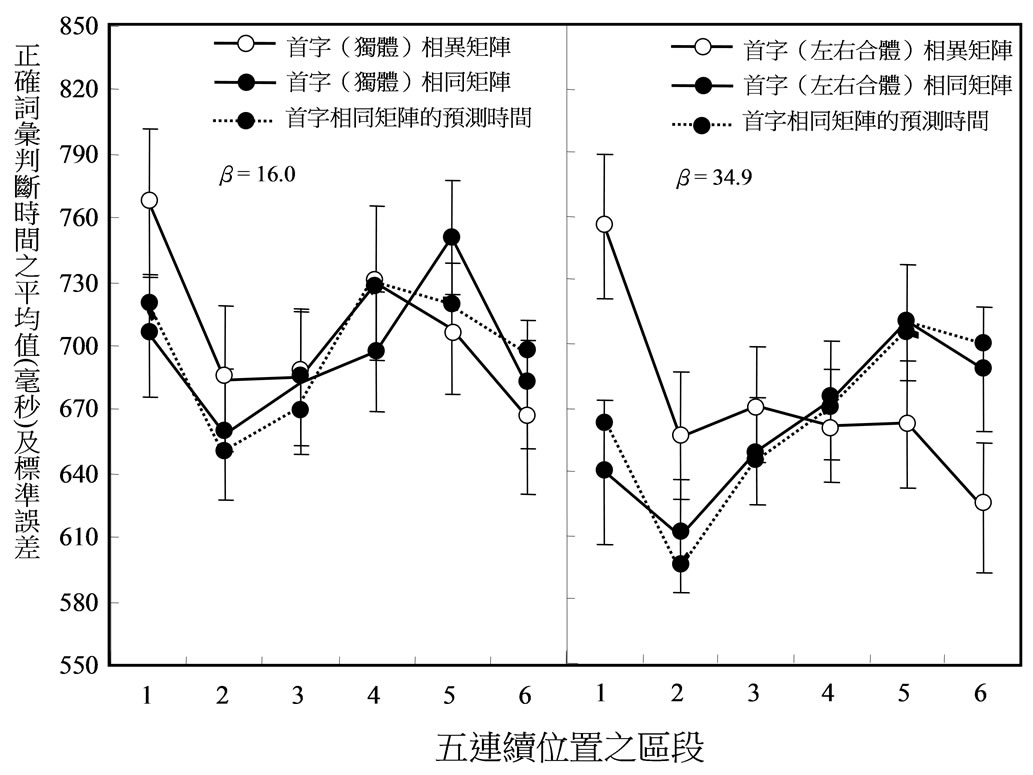
Figure 3. Mean LDT for words in same-SN, different-SN, same-LR, and different-LR matrices in experiment 1
图3. 实验1里首字(独体)相同、首字(独体)相异、首字(左右合体)相同与首字(左右合体)相异矩阵的平均词汇判断时间
F(1, 23) = 2.5,MSE = 69361.8,p = 0.13。首字相同与相异矩阵在LDT上的差异也未达到显着的程度,F(1, 23) = 1.7,MSE = 8998.5,p = 0.21。区段(六个区段)产生主要的效果,F(5, 115) = 8.0,MSE = 7747.7,p < 0.01,主要是由于一个矩阵里下半比上半区段产生较短的LDT,显示练习的效果对LDT的影响。
两变项交互作用达到显着程度的只有“刺激矩阵的种类”(首字相同与相异矩阵) ד区段”的交互作用,F(5, 115) = 10.0,MSE = 6004.5,p < 0.01,主要是由于词在首字相同比在相异矩阵里有较短的LDT,发生在第一区段,F(1, 138) = 29.0,MSE = 6503.5,p < 0.01,与第二区段,F(1, 138) = 4.8,MSE = 6503.5,p = 0.02,但却有较长的LDT发生在第五区段,F(1, 138) = 7.6,MSE = 6503.5,p = 0.01,与第六区段,F(1, 138) = 5.9,MSE = 6503.5,p = 0.02。此结果指示,一个字的持续注视导致了字形的解体。
由图3可以看出,以左右合体字为首字的“矩阵种类” × “区段”的交互作用比以独体字为首字的的交互作用更为显着。但是,“矩阵种类” × “区段”× “字体”的三变项的交互作用只达到边缘的程度而已,F(1, 138) = 2.0,MSE = 4885.4,p = 0.08。
4.2.2. 解体率
由于本实验的每一刺激矩阵的词汇判断分成六个区段、因此一个“首字相异”与其对应的“首字相同”矩阵六个区段LDT的平均值可以用六个配对值(x1, y1), (x2, y2),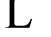 ,与(x6, y6)表示。因此,等式2的α与β可改写为公式(3)。
,与(x6, y6)表示。因此,等式2的α与β可改写为公式(3)。
对每一参与者的资料计算α与β值,结果发现,以左右合体字与以独体字为首字的矩阵,其α值分别为132.0与66.6,两者具显着的差异,F(1, 23) = 4.6,MSE = 1070.2,p = 0.04;其β值分别为34.9与16.0,两者亦具显着的差异F(1, 23) = 5.5,MSE = 785.3,p = 0.03。此结果表示,以左右合体比以独体字为首字的矩阵,不但造成上半区段较大LDT的节省,也造成下半区段较长的LDT,亦即较大的解体率。但是,独体字的β值16.0仍旧显着的大于零,F(1, 23) = 6.6,MSE = 463.3,p = 0.02。此结果表示,虽然独体字只由单一部件所组成,仍造成解体。
利用每一参与者的α与β值,可从区段i的首字相异的LDT值(xi)估计首字相同的LDT值(yi)。图3显示,首字相同矩阵的LDT估计与观察值无显着的差异,在左右合体字为首字的情况下,x2(4) = 1.3,p > 0.05,在独体字为首字的情况下,x2(4) = 3.6,p > 0.05。
实验1的结果指出,解体率比“刺激矩阵的种类”× “区段”的交互作用更能显现左右合体字与独体字在解体程度上的差异。本实验发现,左右合体字的β值显着的大于独体字的β值。此发现与Cheng与Wu(1994)的发现是一致的。此发现亦支持AMLE假说的预测,即一个字有其组成的自由部件者比无组成部件者容易解体。但本实验却发现,独体字的解体率显着的大于零,此结果表示,独体字仍会解体。这与AMLE假说的预测不符。
5. 实验2
AMLE假说的第二个预测是,一个形声字如其声
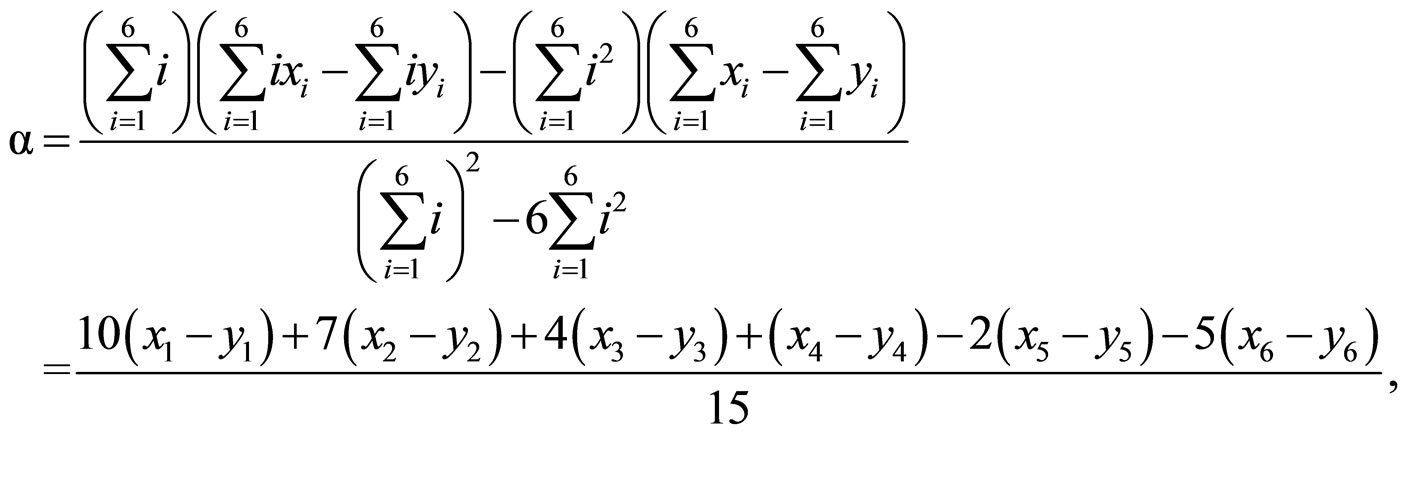
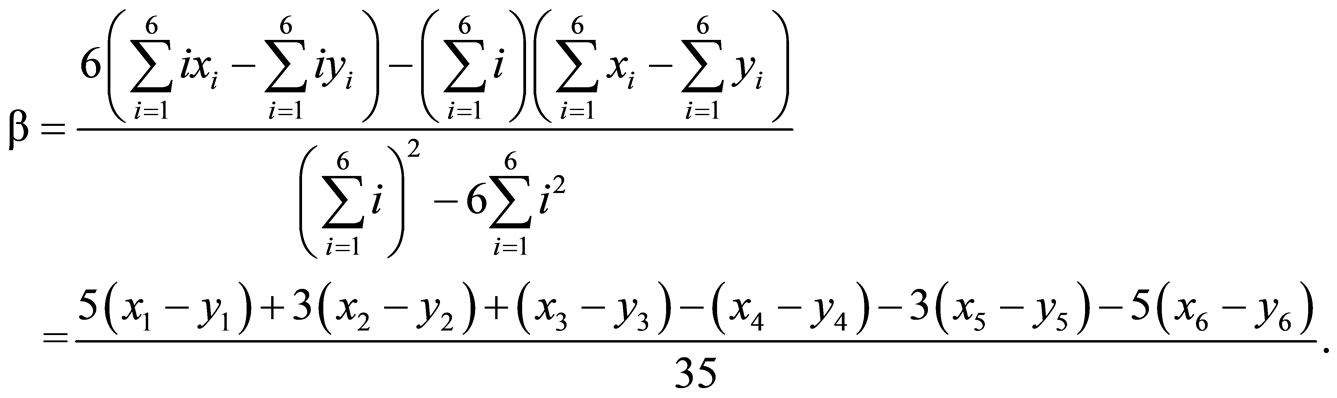 (3)
(3)
旁与义旁在语音与语意上与字相异将比与字相似容易造成解体。因此,实验2观察一个形声字的解体是否与“字–声旁”的语音相似性以及“字–义旁”的语意相似性有关。本实验操弄“字–声旁”的语音与“字–义旁”的语意相似性,每一相似性变异在“相似”与“不相似”两个层次。
5.1. 方法
5.1.1. 参与者
三十二名台湾大学选修普通心理学课程的学生,自愿参与实验以获取额外的点数。
5.1.2. 实验材料,设计与程序
实验材料,设计与程序与实验1的相同,唯一的不同如下。
材料为120个列表的双字刺激、每一列表由15个不同的双字合法词与15个不同的双字“同音假词”所组成。每一列表的词与假词共相同的首字。假词的制作方法与实验1的相同。每一列表的刺激随机的安排在一个想象的5(行) × 6(排)矩阵。如此,形成了120“首字相同”的矩阵,其中30矩阵其刺激的首字与其“声旁”语音相似、与其“义旁”语意相似,这些矩阵称为“首字(音似–义似)相同”矩阵。其它,依首字与其“声旁”的语音与其“义旁”的语意相似性,可分为30“首字(音异–义似)相同”、30“首字(音似–义异)相同”与30“首字(音异–义异)相同”矩阵。
相对于以上的“首字相同”矩阵刺激,实验准备了120个“首字相异”矩阵,其中,有30“首字(音似–义似)相异”、30“首字(音异–义似)相异”、30“首字(音似–义异)”与30“首字(音异–义异)相异”矩阵。每一“首字相异”矩阵的制作方法实验1的相同。
以上八种矩阵各自随机分为两组、每组15矩阵。一半的参与者接受各种矩阵一组的刺激。其它一半的参与者则接受其它四组的矩阵刺激。
5.2. 结果与讨论
5.2.1. 正确LDT
实验首先收集每位参与者对四种“首字相同”矩阵以及其对应“首字相异”矩阵里每一区段(五连续刺激位置构成一个区段)对词的正确LDT的中数值(median)。图4与5呈现32位参与者在每一矩阵里每
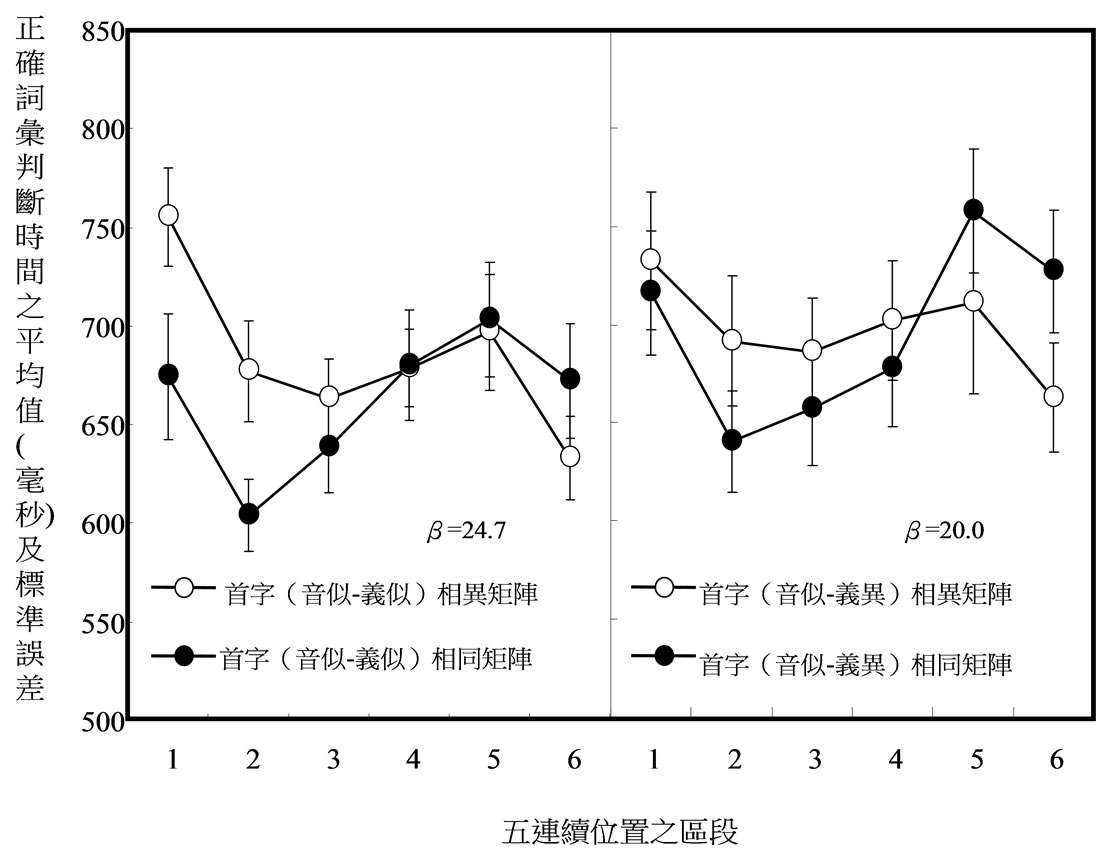
Figure 4. Mean LDT for words as a function of orthographic structure (PS-SS and PS-SD characters), type of stimulus matrices (same-initial versus different-initial stimulus matrices), and block of stimulus positions (six blocks) in experiment 3 in which words were discriminated from homophonic pseudo-words
图4. 在实验2区辨词与同音假词的作业中,首字(音似–义似)相同、首字(音似–义似)相异、首字(音似–义异)相同、首字(音似–义异)相异矩阵的平均词汇判断时间
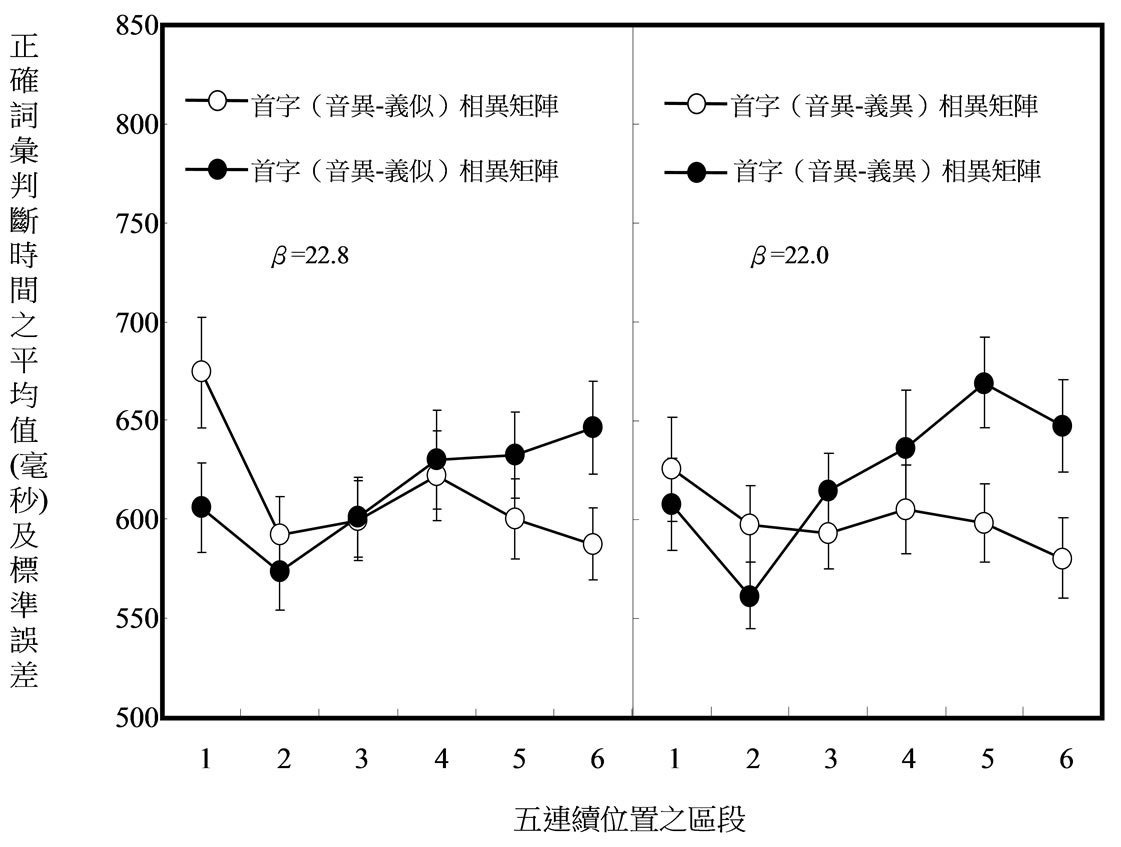
Figure 5. Mean LDT for words as a function of orthographic structure (PD-SS and PD-SD characters), type of stimulus matrices (same-initial versus different-initial stimulus matrices), and block of stimulus positions (six blocks) in experiment 3 in which words were discriminated from homophonic pseudo-words
图5. 在实验2区辨词与同音假词的作业中,首字(音异–义似)相同、首字(音异–义异)相异、首字(音异–义异)相同、首字(音异–义异)相异矩阵的平均词汇判断时间
一刺激区段的LDT的算数平均数与SEM。对正确LDT进行ANOVA分析的结果显示,语音相似性产生主要效果,F(1, 31) = 27.4,MSE = 73492.1,p < 0.01;首字(音似)的词比首字(音异)的词造成较长的LDT。首字(义似)的词与首字(义异)的词在LDT上的差异未达显着的程度,F(1, 31) = 0.9,MSE = 49060.6,p = 0.3524。首字相同与相异矩阵在LDT上的差异未达到显着的程度,F(1, 31) = 1.4,MSE = 15287.7,p = 0.2389。区段(六个区段)产生主要的效果,F(5, 155) = 15.5,MSE = 8190.3,p < 0.01,主要是由于一矩阵里下半比上半区段产生较短的LDT,这显示本实验的作业,与实验1的相同,涉入了练习的效果。
两变项交互作用达到显着程度的只有“刺激矩阵的种类” × “区段”的交互作用,F(5, 155) = 20.0,MSE = 5756.1,p < 0.01,主要是由于词在首字相同比相异矩阵里有较短的LDT,发生在第一区段,F(5, 155) = 20.0,MSE = 5756.1,p = 0.000,与第二区段,F(1, 186) = 13.1,MSE = 9783.7,p = 0.0004,但却有较长的LDT发生在第五区段,F(1, 186) = 10.0,MSE = 9783.7,p = 0.0018,与第六区段,F(1, 186) = 21.4,MSE = 9783.7,p < 0.01。
三变项交互作用达到显着程度的只有“首字与其义旁的语意相似性” × 区段 × 矩阵种类三者的交互作用,F(5, 155) = 2.4,MSE = 3588.4,p = 0.0379。此交互作用有两变异来源。其中之一是,在“语意相似”矩阵里,首字相同比相异矩阵里有较短的LDT发生在第一,F(1, 372) = 21.4,MSE = 8352.9,p < 0.01,与第二区段,F(1, 372) = 8.0,MSE = 8352.9,p = 0.005,但却有较长的LDT发生在第六区段,F(1, 372) = 9.2,MSE = 8352.9,p = 0.0026。
其二,在“语意相异”矩阵里,首字相同比相异矩阵里有较短的LDT发生在第二,F(1, 372) = 7.3,MSE = 8352.9,p = 0.007,但却有较长的LDT发生在第五,F(1, 372) = 13.2,MSE = 8352.9,p = 0.0003,与第六区段里,F(1, 372) = 16.4,MSE = 8352.9,p = 0.0001。“首字与其音旁的语音相似性” × “首字与其义旁的语意相似性” × 区段 × “矩阵种类”四者的交互作用未达显着的程度,F(5, 155) = 0.7,MSE = 5655.8,p = 0.604。
5.2.2. 解体率
计算β值发现,“首字(音似–义似)”、“首字(音异–义似)”、“首字(音似–义异)”、“首字(音异–义异)”矩阵的β值依次为24.7,22.8,20.0与21.5。变异数分析β值发现,“首字(音似)”与“首字(音异)”的β值的差异未达显着的程度,F(1, 31) = 0.0,MSE = 503.6,p = 0.964。“首字(义似)”与“首字(义异)”两者的β值亦未达显着的差异,F(1, 31) = 0.4,MSE = 637.1,p = 0.5092。“首字与其音旁的语音相似性”ד首字与其义旁的语意相似性”交互作用对β值的影响未达显着的程度,F(1, 31) = 0.2,MSE = 551.4,p = 0.6772。
6. 一般讨论
6.1. 解体是逐渐累积或全有全无?
过去的研究(Cheng & Lan, 2011; Cheng & Lin, 2012)与本研究使用Cheng与Lan的隐式测验,都一致的发现,在最初的区段里,首字相异比相同矩阵造成较长的LDT,反之,在最后的区段里,首字相同比相异矩阵造成较长的LDT(例:图3)。前者可理解为,因为相同的首字关系,对首字相同的词判断比对首字相异的词判断,可省下一段阅读的时间。后者可理解为,在“首字相异矩阵”里,由于进行性的效果,LDT随区段而减短。反之,在“首字相同矩阵”里,随着刺激的继续出现将造成首字的重复出现,如此,首字在下半区段时形成解体而使此区段的词汇判断困难,因此增长了LDT。因此,两种矩阵在后半区段的时间差异是因解体所增加的时间。以图3为例,所增加的时间随区段的增加而增加。因此,汉字的解体是逐渐累积,而非全有全无的。
图3,LDT似乎在第五区段达到高峰,然后在第六区段呈下降的趋势。此结果并不表示解体的程度从第五区段下降到第六区段,而是表示解体的程度可能在第五区段,已达到高原,而持续到第六区段,不再继续上升。因此,与时序的效果共同作用的结果,使LDT在第五区段达到高峰,然后在第六区段呈下降的趋势。
6.2. 字与其组成部件的关系对解体的影响
实验1发现,左右合体字的β值显着的大于独体字的β值。此结果支持AMLE假说的预测。但是独体字的β值显着的大于零,表示独体字仍旧解体。此结果不支持AMLE假说的预测。实验2发现,“字–音旁”的语音相似性与“字–义旁”的语意相似性对左右合体字的解体无关;相似与不相似均造成解题;呈解体率的不同。此结果亦不支持AMLE假说的预测。
直至目前为止,汉字解体的研究都发现,解体的现象相当的稳固,不受许多变项的影响,Cheng与Wu(1994)发现,虽然左右与上下合体字的解体的速度比独体字的快,独体字的解体仍发生。Cheng与Lan(2011)与本研究使用隐式测验亦得到相同的结果。Cheng与Wu也发现,字的笔划数、使用频次与语意透明度对解体的时间不产生作用。Lee(2007)观察解体的时间与形声字部件的排序(声旁在左边或右边)、性别(男性或女性)与眼球的刺激(双眼或单眼刺激)的关系。结果发现,解体时间不因这三变项的变异而异。Cheng与Lan发现,一个字的解体率不受此字与其音旁的语音相似性的影响。Cheng与Lin(2012)研究一个汉字组成部件的捆绑性(boundness)对字解体的影响。他们比对字的“自由的部件”(如“指”与“记”的部件)与“捆绑的部件”(如“拜”、“后”的部件)对字解体的影响。结果是,字组成部件的捆绑性(boundness)对字的解体没有影响。基于以上的结果,汉字字形的解体是一个相当强韧的现象,独立于一个字与其组成部件的许多关系、字形的结构、呈现的形式、参与者变项以及其它变项的影响。
6.3. 另一个可能的解释
检视汉字与英文字视知觉的脑侧化(brain lateralization)研究可以发现,汉字的知觉处理是右脑优势(见Cheng & Yang, 1989; Yang & Cheng, 1999),而英文字的知觉处理是左脑优势的(如Gross, 1972; Hellige & Cox, 1976)。这些结果的启示是,汉字是以“整体–完形”的方式处理,英文字是以“系列–分析”的方式处理。
其次,汉字是意符的文字,它的特色是,一个视觉的汉字作为一个整体的完形与其声音的连结不是依据一套“组字–声音”的对应关系,因为汉字缺乏这样的对应关系。它的连结是强记得来的。一个明显的结果是,持续的注视一个字,导致一个字音的收录与组成部件或笔划等视觉讯息的分析。但是字音的收录不能结合这些支离的部件或笔划等视觉讯息,使其回复原来字被收录的完形。譬如,“动”是由两个水平排列的部件“重”与“力”组成,以“重”为左手边、“力”为右手边部件,两者以一空格相隔。如此的空间设计并不等于两个部件的总和。换言之,“动”的声音,“dong”,不能用来结合它的组成部件成为原来的整体。基于同样的理由,持续的注视一个象形或指事字将导致字音的收录与笔划的分析,但此字音不能用来结合它的组成笔划成为原来的整体。此看法预测,汉字的解体普遍存在于所有的汉字。此看法将是未来解体研究的一个可能的架构。
在另一面,英文有一相当严谨的“拼写–声音的对应关系”(见Coltheart, 1978; Coltheart et al., 1977)。虽然持续的注视一个英文字亦将导致一个字音的收录与其组成词素的分析,但是,如此发生在后知觉阶段的视觉讯息分析与知觉阶段的系列分析的处理一致。如果后者不导致字体的解体,前者亦将不会导致字体的解体。甚者,英文的语音可用来结合词素成为原来的字形。譬如,注视raincoat导致语音“renkot”的收录与词素rain与coat的分析。“renkot”可用来结合rain与coat成为raincoat的形式,而无解体的现象发生。
7. 结论
汉字解体的研究才刚开始,以上所提的两种有关解体的机制,有待进一步实征研究的澄清。这些研究包括,在相同的实验派典之下,进行汉字与英文字解体的对比研究与汉字繁体与简体解体的对比研究。根据郑昭明与陈学志(1992)与Cheng与Chern(1993)的分析,简体字从繁体字简化有下列的规则:1) 部首或部件简化(如“農”简化为“农”;“業”简化为“业”); 2) 以同音字取代全字(如“才”取代“纔”;“干”取代“幹”);3) 以同音字取代部件(如“亿”取代“億”;“毕”取代“畢”);4) 取字的部分(如以“厂”为“廠”;“习”为“習”);5) 以简单的部件取代复杂的部件(如“認”简化为“认”;“隊”简化为“队”);6) 去部首(如“硃”简化为“朱”;“係”简化为“系”)以及7) 重复省略(如“棗”简化为“枣”;“聶”简化为“聂”)。以上不同简化的规则是否会造成解体程度上的差异,值得观察。
8. 致谢
本研究在国家科学委员会专题计划Grant 97- 2410-H-431-008-MY3支助下完成,特此感谢。作者亦要感谢二位评审者对本文初稿的评审意见与修改的建议。
参考文献 (References)
郑昭明, 陈学志(1992). 汉字的简化对中文读写的影响. 姚荣松(编),中国文字未来. 台北: 海峡交流基金会.
Cheng, C. M., & Chern, H.-J. (1993). Effects of character simplification on Chinese reading and writing. Proceedings of the National Science Council: Humanities and Social Sciences, 3, 82-95.
Cheng, C.-M., & Lan, Y.-H. (2011). An implicit test of Chinese orthographic decomposition. Reading and Writing: An Interdisciplinary Journal, 24, 55-90.
Cheng, C.-M., & Lin, S.-Y. (2012). Chinese orthographic decomposition and logographic structure. Reading and Writing: An Interdisciplinary Journal, 1-21.
Cheng, C.-M., & Wu, S.-J. (1994). Character decomposition in Chinese. In H. W. Cheng, J.-T. Huang, C.-W. Hue, & O. J. T. Tzeng (Eds.), Advances in the study of Chinese language processing, Vol. 1 (pp. 1-30). Department of Psychology, National Taiwan University.
Cheng, C.-M., & Yang, M.-J. (1989). Lateralization in the visual perception of Chinese characters and words. Brain and Language, 36, 669-689.
Chern, H.-C., & Cheng, C.-M. (1999). ANOVA and trend analysis statistical program for cognitive experiments. Research in Applied Psychology, 1, 229-246.
Coltheart, M. (1978). Lexical access in simple reading tasks. In G. Underwood (Ed.), Strategies of information processing (pp. 151- 216). San Diego: Academic Press.
Gross, M. M. (1972). Hemispheric specialization for processing of visually presented verbal and spatial stimuli. Perception & Psychophysics, 12, 357-363.
Hellige, J. B. (1978). Visual laterality patterns for pure versus mixedlist presentation. Journal of Experimental Psychology: Human Perception and Performance, 4, 121-131.
Kounios, J., Kotz, S. I., & Holcomb, P. J. (2000). On the locus of the semantic decomposition effect: Evidence from event-related brain potentials. Memory & Cognition, 28, 1366-1377.
Lee, N.-C. (2007). Perceptual coherence of Chinese characters: Orthographic decomposition and disorganization. Unpublished Master’s Thesis, Edinburgh: University of Edinburgh.
Liu, I.-M., Chuang, C.-J., & Wang, S.-C. (1975). Frequency count of 40000 Chinese words. Taipei: Lucky Press.
Ninose, Y., & Gyoba, J. (1996). Delays produced by prolonged viewing in the recognition of Kanji characters: Analysis of the “Gestaltzerfall” phenomenon. Japanese Journal of Psychology, 57, 227- 231.
Ninose, Y., & Gyoba, J. (2002). Analysis of the responsible factors for the delay effect produced by prolonged viewing in the recognizing Kanji characters. Japanese Journal of Psychology, 73, 264-269.
Smith, L. C., & Klein, R. (1990). Evidence for semantic satiation: Repeating a category slows subsequent semantic processing. Journal of Experimental Psychology: Learning, Memory, and Cognition, 16, 852-861.
Xu, S. (100). Shuowen. Taichung: Water-Like Bookstore.
Yang, M.-J., & Cheng, C.-M. (1999). Hemisphere differences in accessing lexical knowledge of Chinese characters. Laterality, 4, 149- 166.