Computer Science and Application
Vol.1 No.3(2011), Article ID:372,6 pages DOI:10.4236/csa.2011.13019
An Approach of Knowledge Extraction Restrained by Ontology
Dalian Hengyi Technology Incorporated Company, Dalian
Email: ligj@hengyi.ln.cn
Received: Sep. 1st, 2011; revised: Sep. 25th, 2011; accepted: Oct. 9th, 2011.
ABSTRACT:
In terms of knowledge view, an approach of knowledge extraction restrained by ontology is proposed in this paper. At first, translate a domain ontology into a model expressed by Alloy language and use the form of solution space to express the recognized entities and the recognized entity-relations which can be got when applying named entity recognition technology and entity relation extraction technology to coarse text block in turn. And then translate every solution of solution space into an assertion sentence which will be included in Alloy model. Next, reduce solution space by applying Alloy analyzer to the Alloy model. At last, a whole knowledge instance will be obtained.
Keywords: Knowledge Extraction; Ontology; Alloy
一种基于本体约束的知识抽取方法
李国杰*,许登峰
大连恒宜科技有限公司,大连
Email: ligj@hengyi.ln.cn
摘 要:
从知识的角度出发,提出一种基于本体约束的知识抽取方法:将领域本体中蕴含的逻辑信息转换为一个Alloy语言表示的模型,将命名实体识别和实体关系抽取的成果映射为解空间,接着将解空间里的每一个解转化为Alloy语言表示的断言语句,然后使用Alloy分析器来约简解空间,最终得到一个具有明确语义的完整知识实例。
收稿日期:2011年9月1日;修回日期:2011年9月25日;录用日期:2011年10月9日
关键词:知识抽取;本体;Alloy
1. 引言
在信息抽取领域,命名实体识别方法可以为实体赋予正确的语义,实体关系抽取则可以明确两个实体间的关系语义。但从知识的角度来看,无论是命名实体识别还是实体关系抽取都属于“小粒度”(知识片段)的抽取,抽取结果并非独立完整的知识实例。命名实体识别和实体关系抽取的成果只有经过知识合成才能成为独立完整的知识实例。但由于知识体系的复杂性和多样性,合成“知识片段”往往是非常困难的。此外,传统的信息抽取主要采用基于规则的方法,这种方法会导致在抽取信息时因无法克服不同的信息项满足同一或具有包含关系抽取规则时无法确定信息项类型的问题。
本体是共享的、规范化的概念模型,是对某一领域中知识结构的系统描述,因此从知识的角度来看,领域本体是知识抽取最有效的工具之一。但从目前来看,基于本体信息抽取和知识抽取的研究工作对领域本体的利用非常有限,且主要集中在一些信息本身格式和信息上下文格式的利用;而领域本体中蕴含的逻辑知识以及推理能力很少被利用,因此这类方法在抽取结构比较复杂的知识时抽取效果就明显下降了。
本文研究的思路是:将领域本体中蕴含的逻辑知识转换为一个Alloy语言表示的模型,在完成命名实体识别和实体关系抽取的基础上,使用约束逻辑求解方法(Alloy分析器)来对领域内的信息进行更为精确的定位,最终得到一个具有明确语义的知识实例。本文的组织如下,第二节给出两个引例,明确本文要解决的问题;第三节介绍相关的概念;第四节是本文的重点,介绍知识抽取的算法;第五节是实验;最后是相关工作和结论。
2. 本文要解决的问题
2.1. 两个引例
本小节通过两个简单的案例来直观地阐述本文要解决的问题。假设有文本片段:“周恩来总理出生于1898年3月5日,逝世于1976年1月8日”。使用命名实体识别技术可以将“1898年3月5日”和“1976年1月8日”标识为一个“日期时间”实体类型的实例,但不能确定“1898年3月5日”和“1976年1月8日”是“出生时间”还是“逝世时间”。使用实体关系抽取技术可以确定“(周恩来,1898年3月5日)”是“出生(人物,时间)”关系的实例,“(周恩来,1976年1月8日)”是“逝世(人物,时间)”关系的实例。通过确定实体的关系,“1898年3月5日”和“1976年1月8日”两个实体就有了更为明确的语义。
但在某些情况下,二元实体关系抽取的结果也不能保证实体的语义完全明确。假设有文本片段:“英华公司2008年实现销售收入20.1亿元,而2009年则达到22.3亿元”。使用命名实体识别技术可以将“英华公司”、“2008年”、“20.1亿元”、“2009年”和“22.3亿元”分别标识为“组织”、“日期”、“销售收入值”、“日期”和“销售收入值”实体类型的实例;进一步,使用实体关系抽取技术可以确定“(英华公司,20.1亿元)”和“(英华公司,22.3亿元)”是“销售收入(组织,销售收入值)”的两个关系实例。显然,这两个关系实例的语义由于缺乏日期实体支持而变得模糊。
笔者认为,使得一个实体具有明确语义的关键在于能够确定该实体在领域中的“位置”。如果使用领域本体来描述一个领域里的规则,那么知识抽取的问题就转换为:在领域本体中找到一个最合适的概念作为实体的类型。
2.2. 相关概念
首先我们给出同问题描述相关的几个概念。
定义1:本体O是一个五元组, O = {C, R, HC, Rel, Ao}[1],其中C是概念的集合;R是非分类关系的集合;HC ⊆ C × C是分类关系的集合;Rel: R→C × C是一个函数,表示两个概念之间的特定关系;Ao是公理集,通常使用逻辑语言来表示。表示本体的语言有多种,本文中提到的领域本体是使用OWL DL表示的本体。
为了描述问题的方便,我们引入约定1。
约定1:使用O.C、O.R、O.HC、O.Rel和O.Ao来表示本体O的相应元组;∀c ∈ O.C使用instconc (c)表示c的所有实例,即实体;∀r ∈ O.Rel使用instrela (r)表示r的所有实例,即实体对。
基于领域本体约束的知识抽取方法是在命名实体识别和实体关系抽取的基础上完成的,因此我们首先给出命名实体识别和实体关系抽取的定义及其相关约定。
定义2:命名实体识别主要是要识别出文本中出现的专有名词和有意义的数量短语的实体类型。命名实体识别中的实体类型同领域本体中的概念在语义上是一致的。
一般来说,在进行命名实体识别时往往会使用一套实体识别规则。为了描述问题的方便,我们引入约定2。
约定2:对于一个给定的领域本体O, ∀c ∈ O.C都对应一个抽取规则集c.PAT, ∀I ∈ instconc (c)使得∃p ∈ c.PAT,概念实例i满足抽取模式p。称i是c的实例,记为instofconc(i, c)。
定义3:实体关系抽取是指从文本语料中自动识别出具有语义关系的实体对。实体关系抽取中的实体关系同领域本体中的Rel元组在语义是一致的。
一般来说,在进行实体关系抽取时往往会对应着一套抽取规则。为了描述问题的方便,我们引入约定3。
约定3:对于一个给定的领域本体O, ∀r ∈ O.Rel都对应一个抽取规则集r.PAT, ∀I ∈ instrela (r)使得∃p ∈ r.PAT关系实例i满足抽取模式p。称i是r的实例,记为instofrela (i, r)。
2.3. 问题的一般形式
图1所示的是一个非正式的领域本体O的示意

Figure 1. A diagram about ontology O
图1. 领域本体O示意图
图,已知:① c1, c2, c3, c4, c5, c6 ∈ O.C; ② r1 (c1, c2), r2 (c4, c5), r3 (c1, c3), r4 (c5, c6) ∈ O.Rel, r1 (c1, c2) 表示c1和c2存在语义关系 r1, r2 (c4, c5)、r3 (c1, c3)和 r4 (c5, c6)的含义类似; ③ (c1, sc1), (c4, sc1), (c2, sc2), (c5, sc2) ∈ O.HC, (c1, sc1)表示c1是sc1的子概念,(c4, sc1)、(c2, sc2)和(c5, sc2)的含义类似; ④ instconc (c1) ∩ instconc (c4) ≠ ∅ ∧ instconc (c2) ∩ instconc (c5) ≠ ∅; ⑤ instprop (r1) ∩ instprop (r2) ≠ ∅。
对于两个实体e1和e2,如果∃p1 ∈ c1.PAT,使得e1满足抽取模式p1,那么有e1 ∈ instconc (c1)成立。类似地,如果∃p2 ∈ c4.PAT,使得e1满足抽取模式p1,那么有e1 ∈ instconc (c4)成立。如果∃p3 ∈ c2.PAT,使得e2满足抽取模式p3,那么有e2 ∈ instconc (c2)成立。∃p4 ∈ c5.PAT,使得e2满足抽取模式p4,那么有e2 ∈ instconc (c5)成立。
从上述分析可以得出结论1) e1 ∈ instconc (sc1)和结论2) e2 ∈ instconc(sc2),但无法具体确定e1和e2所属的概念。进一步,如果∃p5 ∈ r1.PAT,使得(e1, e2)满足抽取模式p5,那么有(e1, e2) ∈ instrela(r1)成立,那么就可以确定e1 ∈ instconc (c1),e2 ∈ instconc (c2)。但如果同时又有∃p6 ∈ r2.PAT,使得(e1, e2)满足抽取模式p6,那么有(e1, e2) ∈ instrela (r2)成立,这样e1和e2所属的概念仍不明确。
但如果有实体e3,且已知① e3 ∈ instconc (c3);② (e1, e3) ∈ instreal(r3);③ O.Ao中有规则 e1 ∈ instconc(sc1) ∧ e3 ∈ instconc (c3) ∧ (e1,e3) ∈ instreal(r3) → e1 ∈ instconc (c1); ④ O.Ao中有规则 e1 ∈ instconc(c1) ∧ ((e1, e2) ∈ instrela(r1) ∨ (e1, e2) ∈ instreal(r2)) → e2 ∈ instconc(c2); 那么进而可以确定e1 ∈ instconc (c1)和 e2 ∈ instconc (c2)。
从图1我们可以得到一个启示:在经过命名实体识别和实体关系抽取之后,我们可以借助本体中已有的规则和本体提供的逻辑推理机制来进一步缩小实体所属概念的范围。下面我们将围绕这一思想给出基于领域本体约束的知识抽取算法。
3. Alloy语言与基于本体的知识抽取方法
基于领域本体约束的知识抽取流程如图2所示。因为流程中用到了Alloy语言和Alloy分析器,因此我们首先对Alloy语言和Alloy分析器作简要的介绍。
3.1. Alloy语言与Alloy分析器[2-4]
Alloy语言是基于关系逻辑的结构化建模语言,用于对具有复杂结构和行为的系统进行建模。Alloy语言用于描述的对象是原子和元组(原子序列)。下面通过一个简单的例子简要地介绍Alloy语言。如图3所示:

Figure 2. An approach of knowledge extraction restrained by ontology
图2. 基于领域本体约束的知识抽取方法
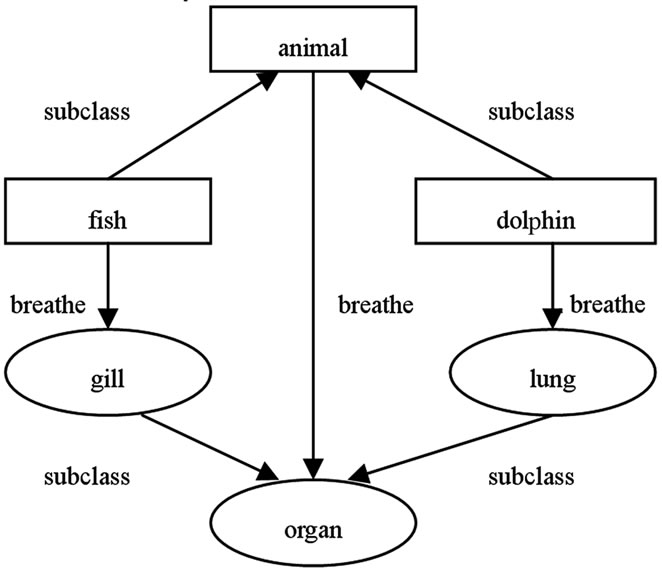
Figure 3. A case about animal
图3. 一个描述动物呼吸的案例
fish和dolphin都是animal的子类,fish用gill呼吸,dolphin用lung呼吸,gill和lung都是organ的子类,animal使用organ呼吸。可以使用Alloy语言(图4所示)来形式化地表示上述事实。在图4中,行1表示模型的名字是“animal”,“module”是Alloy语言中的关键字;行2表示“animal”集合是“Class”集合的子集,“sig”关键字用于定义一个集合;类似地,行3至行5分别定义了“gill”、“fish”和“breathe”集合,其中“gill”和“fish”是Class的子集,“breathe-by”是“Property”的子集;行6陈述事实(fact):“fish”是“animal”的子集;行7陈述事实:所有的“fish”用“gill”呼吸(breathe);行8表示lung是Class的子集;行9表示lung与gill的交集为空;行10表示dolphin是Class的子集;行11表示dolphin是animal的子集;行12表示所有的dolphin都用lung呼吸(breathe);行13陈述一个断言dolphinIsFish:dolphin是fish的子集;行14根据已知的事实和前提来验证断言dolphinIsFish的正确性。将图4的代码调入到Alloy分析器并设定相关的参数后,Alloy分析器输出对断言dolphinIsFish的验证结果。
3.2. 本体与Alloy[5]
以描述逻辑为基础的本体描述语言OWL DL所表达的本体信息可以用一个Alloy模型来描述。一个领域本体可以映射为Alloy语言的一个模型,本体中的概念可以映射为Alloy语言中的集合;本体中关系可以映射为集合间的关系;本体中的概念层次可以映射为Alloy语言中的子集关系;本体中的公理则完全可以用Alloy语言中的fact来陈述。
3.3. 基于领域本体约束的知识抽取方法
第一步:将OWL DL语言描述的本体转换为一个用Alloy语言表达的模型M*。
第二步:借助命名实体识别技术确定原始文本片段的初次解集。
记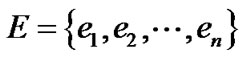 为原始文本片段中所有待识别的实体集合;∀e ∈ E使用命名实体识别技术可以得到e所有可能的实体类型,这些类型称为e的实体目标域。形式化地,我们给出实体目标域和初次解集的定义。
为原始文本片段中所有待识别的实体集合;∀e ∈ E使用命名实体识别技术可以得到e所有可能的实体类型,这些类型称为e的实体目标域。形式化地,我们给出实体目标域和初次解集的定义。
定义4:∀c ∈ O.C,称 e.c = {c|c ∈ O.C, instofconc (e, c)}为实体e的实体目标域。
定义5:称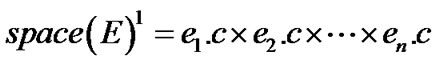 为E的初次解集。
为E的初次解集。
第三步:在实体关系抽取的基础上,使用图5所示的算法约简初次解集得到二次解集space (E)2。
定义6:∀ (ca, cb) ∈ O.R,称(e1, e2).r= {(ca, cb) | (ca, cb) ∈ O.R, instofprop ((e1, e2), (ca, cb))} 为实体对(e1, e2)的关系目标域。

Figure 4. A case for Alloy model
图4. Alloy模型示例

Figure 5. The algorithm for solving second answers set
图5. 求二次解集算法
第四步:将二次解集中的每一个解转换为Alloy模型下一组断言语句,然后将这组断言语句补充到M×;如果Alloy分析器输出每一个断言都是有效的,那么认为这组断言对应的解是一组有效解;否则是无效解。算法如图6所示。
4. 实验
4.1. 实验数据
为了验证算法的有效性,我们以人物讣告主题的文本片段作为实验对象。首先我们定义了如下的本体O,其中 C = {Person, Deceased Person, Relative, Age, Birth Date, Death Date, Death Address, Birth Address, Date, Address},Person代表“人”,Date代表“日期”,Address代表“地点”;Deceased Person代表“死者”,Relative代表“亲属”,Age代表“卒年”,Birth Date表示出生日期,Death Date代表死亡日期,Death Address代表死亡地点,Birth Address代表出生地点;
• O.R = {born in address, die at the age of, born in date, die in date, die in address, is related to};
• O.HC = {(Deceased Person, Person), (Relative, Person), (Birth Address, Address), (Death Address, Address), (Birth Date, Date), (Death Date, Date)};
• O.Rel = {born in address (Deceased Person, Birth Address), die at the age of (Deceased Person, Age), born in date (Deceased Person, Birth Date), die in date (Deceased Person, Death Date), die in address (Deceased Person, Death Address), is related to (Deceased Person, Relative)};
• O.Ao = {e1 ∈ instconc (Deceased Person) ∧ e2 ∈ instconc(Date) ∧ (e1, e2) ∈ instreal (born in date) → e2 ∈ instconc (Birth Date), e1 ∈ instconc (Deceased Person) ∧ e2 ∈ instconc (Date)∧ (e1, e2) ∈ instreal (die in date) → e2 ∈ instconc(Death Date), e1 ∈ instconc (Deceased Person) ∧ e2 ∈ instconc (Address) ∧ (e1, e2) ∈ instreal (born in Address) → e2∈instconc (Birth Address), e1 ∈ instconc (Deceased Person) ∧ e2 ∈ instconc (Address) ∧(e1, e2) ∈ instreal (die in Address) → e2 ∈ instconc (die Address), e ∈ instconc (Deceased Person) → e2 ∉ instconc (Relative), e1 ∈ instconc (Deceased Person)∧ e2 ∈ instconc (Deceased Person) → e1 = e2}
然后我们从Salt Lake Tribune(www.sltrib.com)和Arizona Daily Star(www.azstarnet.com)下载了30篇讣告进行测试。
4.2. 实验结果
从前三节的描述里不难发现,最终解集中解的数量越少,说明实验结果越精确;反之则实验的不确定性越高。理想化地,对于每次抽取结果,最终解集中解的数量应为1。而从实验结果(如图7所示)来看,只有6篇讣告最终解集中解的数量大于1,其余24篇都获得了明确抽取结果。因此,实验结果验证了新方法的有效性。

Figure 6. The algorithm for solving final answers set
图6. 求最终解集算法
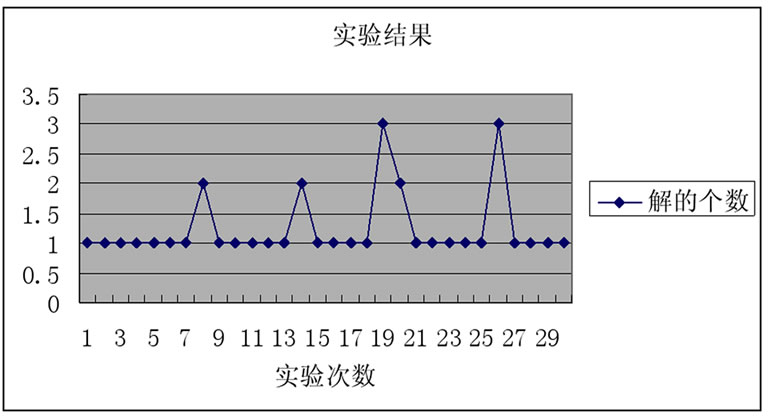
Figure 7. Experiment result
图7. 实验结果
5. 相关工作
[6]提出一种由Record Extractor、Constanst/Keyword Recognizer、Ontology Parser、Database-Instance Generator四大部件构成的信息抽取系统。系统的工作原理是首先使用Record Extractor从原始网页中提取含有待抽取信息项的记录条;然后使用Ontology Parser从领域本体中获取信息项的特征知识;根据信息项的特征知识和Constanst/Keyword Recognizer中包含的约束信息从记录条中抽取信息项,最后依使用Database-Instance Generator将信息项存到数据库中。系统的关键部件是Constanst/Keyword Recognizer和Ontology Parser,它们提供了信息抽取的规则,这些规则都是基于启发式或者预定义的语法格式抽取规则,因此该方法缺乏通用性。此后,[7,8]从不同的应用背景出发开发了各自的基于本体的信息抽取系统,但其指导思想同[6]相比基本一致。[7]以商务智能领域作为背景,在领域本体的支持下,使用基于语言学模式的的方法进行信息抽取。Kylin system[8]以Wikipedia pages中包含的信息作为抽取对象,利用WordNet中提供的概念以及概念间的关系来构造本体,使用最大熵模型和CRF来对语句中包含的信息进行识别。由于该系统使用统计的方法来进行信息抽取,因此对于缺乏足够训练样例的情况抽取效果较差。
6. 结束语
本文提出了一种基于本体约束的知识抽取的方法。不同于传统的基于规则的信息抽取方法,我们从知识的角度出发,将知识抽取转换为一个约束逻辑程序求解问题,不仅合成了已有的知识片段,获得了完整的知识实例,而且利用本体中定义的逻辑规则,克服了不同的信息项满足同一或具有包含关系抽取规则时无法确定信息项类型的问题。
参考文献 (References)
[1] L. Stojanovic. Methods and tools for ontology evolution. University of Karlsruhe, 2004.
[2] D. Jackson, I. Schechter and I. Shlyakhter. ALCOA: The alloy constraint analyzer. Proceeding of 22nd International Conference on Software Engineering (ICSE), 2000. ACM Press, 2000: 331- 347.
[3] D. Jackson. Micromodels of software: Modelling and analysis with Alloy. http://sdg.lcs.mit.edu/alloy/book.pdf.
[4] D. Jackson. Alloy: A lightweight object modeling notation. ACM Transactions on Software Engineering and Methodology (TOSEM), 2002, 11(2): 256-290.
[5] H. H. Wang. Reasoning support for Semantic Web ontology family languages using alloy. Multiagent and Grid Systems, 2006, 2(4): 145-155.
[6] D. W. Embley. Conceptual-model-based data extraction from multiple-record web pages. Data & Knowledge Engineering, 1998, 31: 227-251.
[7] H. Saggion, A. Funk, D. Maynard and K. Bontcheva. Ontologybased information extraction for business intelligence. Proceedings of the 6th International the Semantic Web and 2nd Asian Conference on Asian Semantic Web Conference, 2007, 6(3): 843- 856.
[8] F. Wu, R. Hoffmann and D. S. Weld. Information extraction from Wikipedia: Moving down the long tail. Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2008, 5(1): 731-739.