Advances in Applied Mathematics
Vol.3 No.04(2014), Article
ID:14299,8
pages
DOI:10.12677/AAM.2014.34024
Least Squares Fitting with B-Spline by Genetic Algorithm
School of Mathematics and System Science, Beijing University of Aeronautics and Astronautics, Beijing
Email: buaaliulian@163.com
Copyright © 2014 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



Received: Jul. 24th, 2014; revised: Sep. 2nd, 2014; accepted: Sep. 14th, 2014
ABSTRACT
In this paper, we propose genetic algorithm to obtain a good approximation for least squares fitting with linear and nonlinear B-spline, and four different two-dimensional airfoil data fittings are given to show that genetic algorithm solves this kind of problem feasibly and effectively.
Keywords:B-Spline Curve, The Least Squares Fitting, Genetic Algorithm

遗传算法求解B样条曲线最小二乘拟合问题
刘 莲,冯仁忠
北京航空航天大学,数学与系统科学学院,北京
Email: buaaliulian@163.com
收稿日期:2014年7月24日;修回日期:2014年9月2日;录用日期:2014年9月14日

摘 要
本文提出利用遗传算法对四组不同的二维翼型数据进行线性及非线性B样条曲线最小二乘拟合,发现遗传算法解决这类问题是有效可行的。
关键词
B样条曲线,最小二乘拟合,遗传算法

1. 引言
曲线拟合是用连续曲线近似地刻画或比拟平面上离散点组所表示的坐标之间函数关系的一种数据处理方法。其选择适当的曲线类型来拟合观测数据,并用拟合的曲线方程分析两变量间的关系。典型的拟合曲线有指数函数,对数函数,幂函数,贝塞尔曲线等。本文选取B样条曲线作为拟合曲线,因其具有几何不变性,凸包性,变差减小性,局部支撑性等众多优良性质[1] ,在当今计算机辅助设计等工业领域有着广泛的应用。
选择适当的参数使得拟合B样条曲线模型与实际的观测值在各点的残差的加权平方和达到最小,此类问题称为B样条曲线最小二乘拟合。传统方法是利用解析表达式逼近离散数据,通过求解未知变量的法方程,找到数据的最佳拟合曲线,但其不能灵活解决非线性曲线拟合[2] 。本文提出应用遗传算法解决此类问题。遗传算法是全局搜索收敛算法[3] ,不依赖于梯度信息,克服了容易陷入局部最优的缺点,以此成为主流优化算法之一。遗传算法在求解曲线拟合设计时,通过遗传基因实数编码[4] ,将原本函数优化问题转变为离散组合优化问题。同时遗传算法避免了求解未知量法方程,可以灵活应用在解决非线性曲线拟合问题。
本文分别利用遗传算法和最小二乘法对四组不同的二维翼型数据进行线性B样条曲线最小二乘拟合,并将其拟合误差进行比较。同时应用遗传算法解决类似的非线性B样条曲线最小二乘拟合问题[1] [5] 。发现遗传算法应用于解决这类问题是有效可行的。
2. 基于B样条曲线的最小二乘拟合
假定给定N+1个二维数据点 ,想找到一条已知曲线
,想找到一条已知曲线 去逼近给定的数据点
去逼近给定的数据点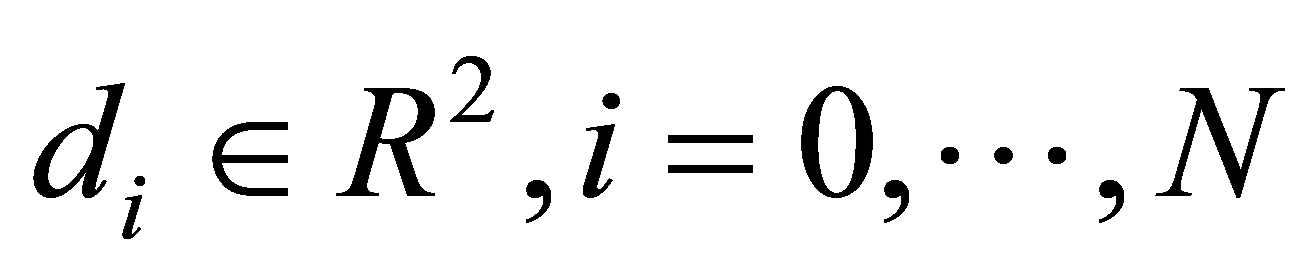 。假定与数据点
。假定与数据点 对应的参数值是
对应的参数值是![]() ,则B样条曲线数据拟合方程可以表示为:
,则B样条曲线数据拟合方程可以表示为:
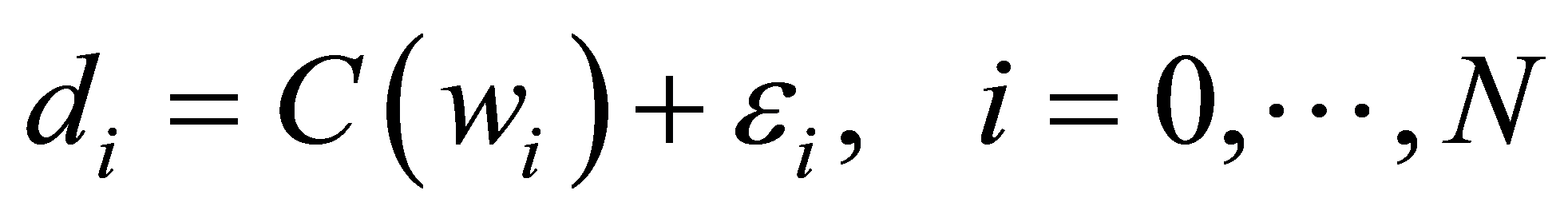 (1)
(1)
其中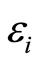 为数据点
为数据点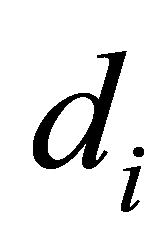 的拟合误差。
的拟合误差。
选择方程式(1)中的逼近曲线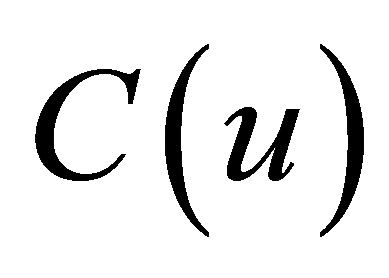 为B样条曲线函数[6] [7] 。一条k次B样条曲线可以表示为
为B样条曲线函数[6] [7] 。一条k次B样条曲线可以表示为
![]() (2)
(2)
其中![]() 是n+1个控制顶点,
是n+1个控制顶点,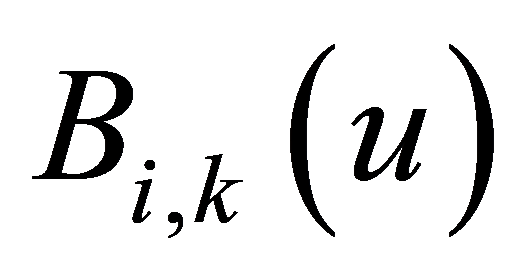 表示k次B样条基函数,其梯度定义由de Boor和Cox [1] 分别导出
表示k次B样条基函数,其梯度定义由de Boor和Cox [1] 分别导出
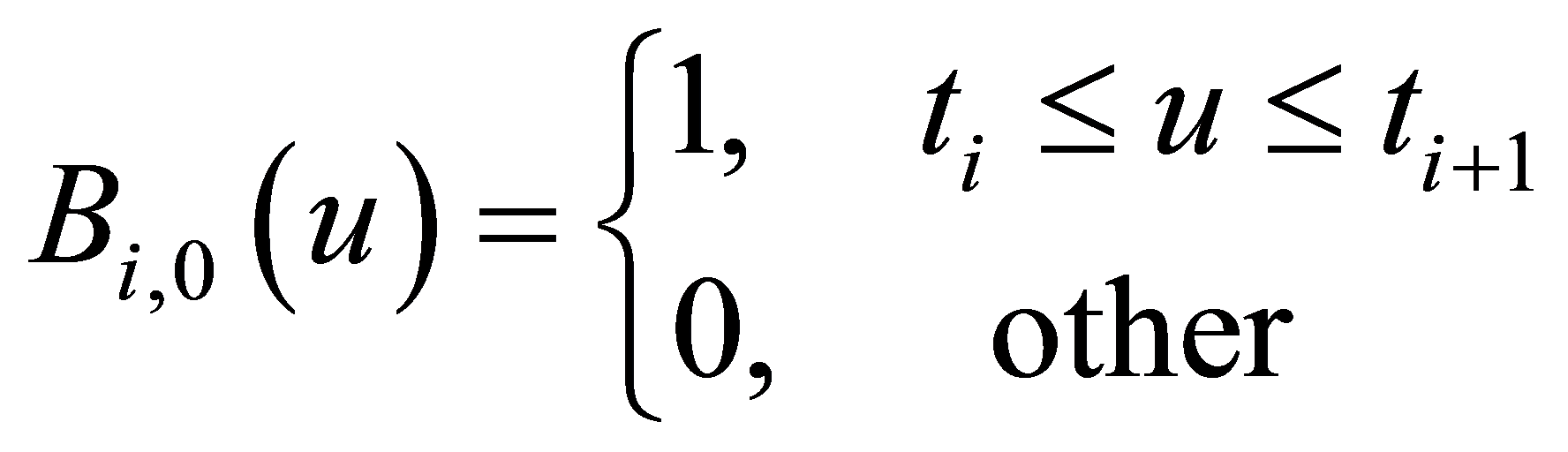 (3)
(3)
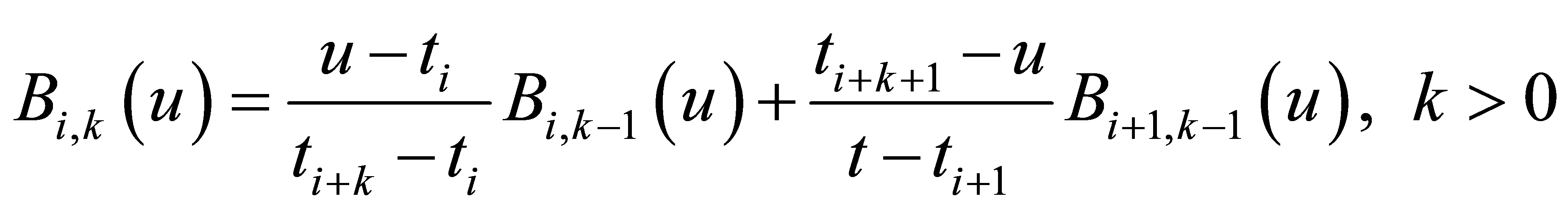 (4)
(4)
约定 。式中k表示B样条的幂次,
。式中k表示B样条的幂次,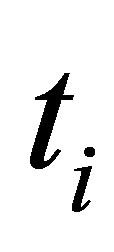 为节点。每一个基函数
为节点。每一个基函数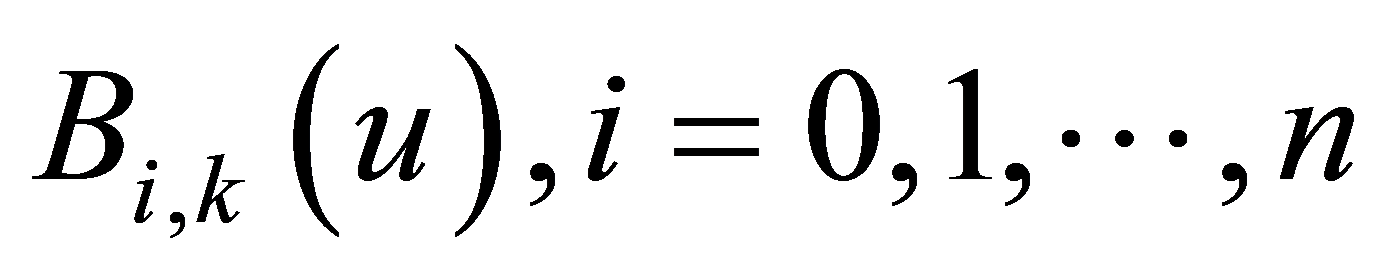 是由非递减的节点向量
是由非递减的节点向量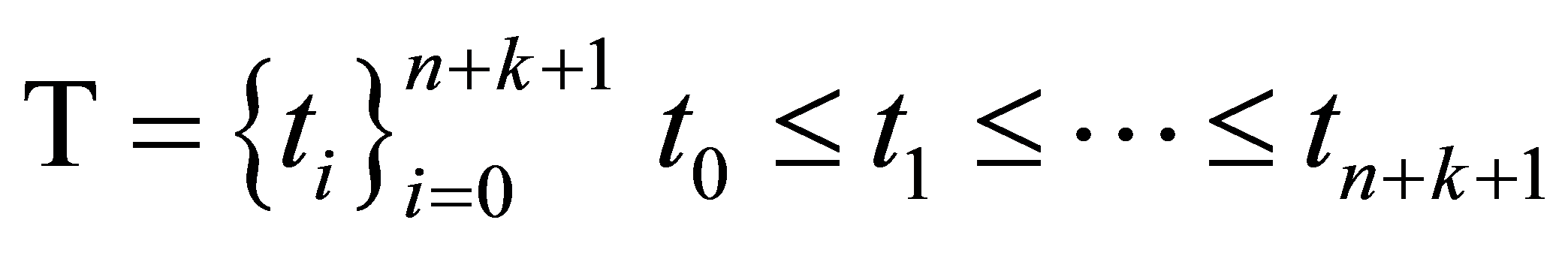 所决定的k次分段多项式。节点T为准均匀的,计算方法是
所决定的k次分段多项式。节点T为准均匀的,计算方法是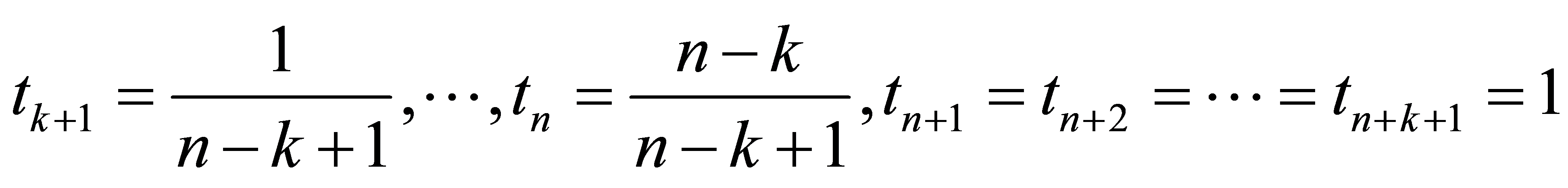
 。
。
根据方程式(2),(3)和(4),假定选取控制顶点![]() 作为未知变量,则B样条曲线数据拟合为
作为未知变量,则B样条曲线数据拟合为
线性拟合。假定选取控制顶点![]() 和节点向量
和节点向量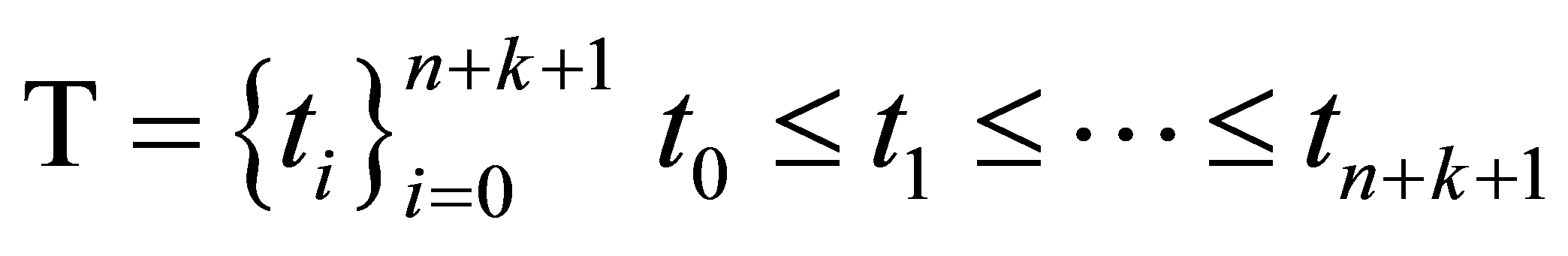 或者数据点
或者数据点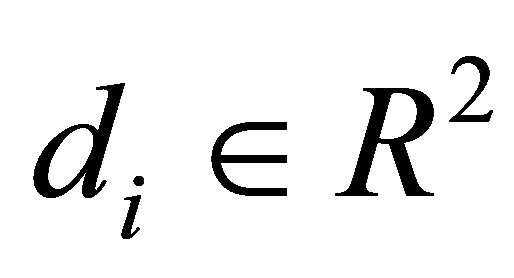 对应的参数值是
对应的参数值是![]() 为未知变量时,则B样条曲线数据拟合为非线性拟合。
为未知变量时,则B样条曲线数据拟合为非线性拟合。
最小二乘法[2] [8] 是通过最小化误差的平方和寻求数据的最佳函数匹配。根据方程式(1),逼近误差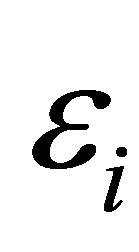 在平方
在平方
意义下可以表示为
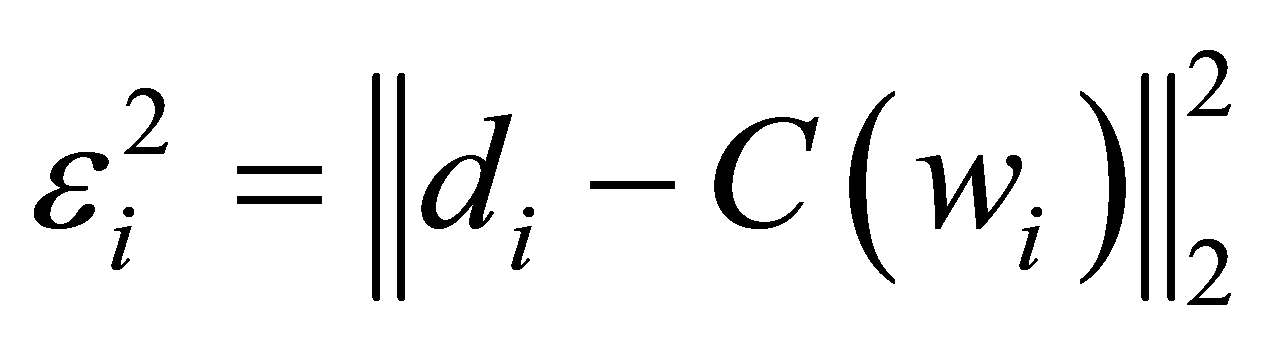 (5)
(5)
其中![]() 为平方范数,
为平方范数,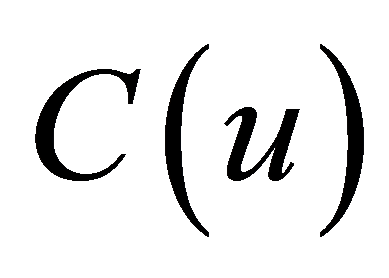 为表达式(2),(3),(4)所求。对方程式(5)求和,引进表达式
为表达式(2),(3),(4)所求。对方程式(5)求和,引进表达式
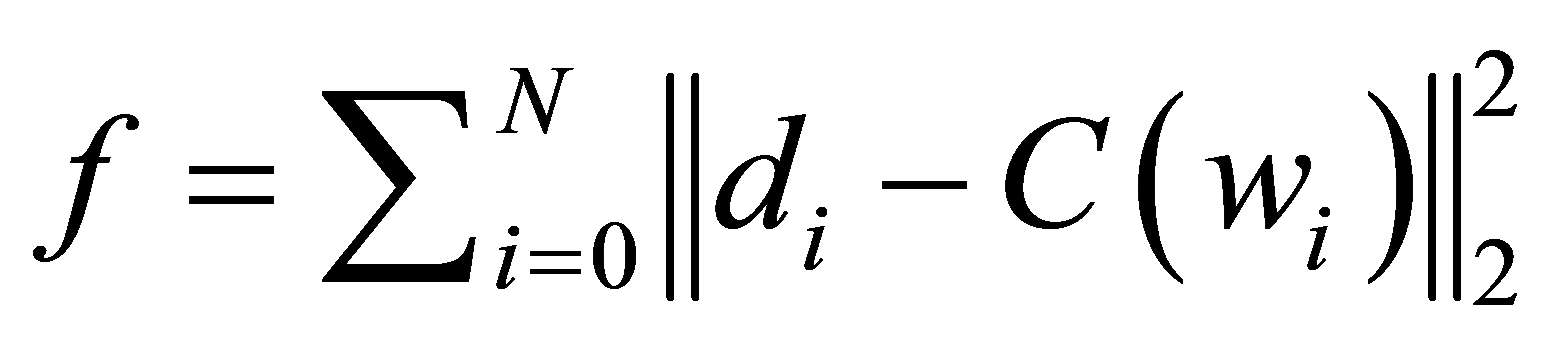 (6)
(6)
通过最小化表达式(6)中的误差平方和f来无限接近数据点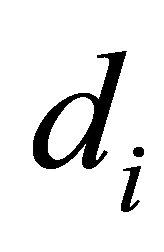 ,既要找到合适
,既要找到合适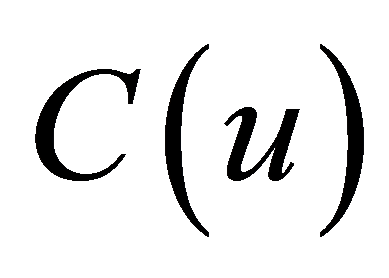 使得f达到最小。根据公式(1),在线性的情况下,选择控制顶点作为未知变量,则方程式(6)整理为
使得f达到最小。根据公式(1),在线性的情况下,选择控制顶点作为未知变量,则方程式(6)整理为
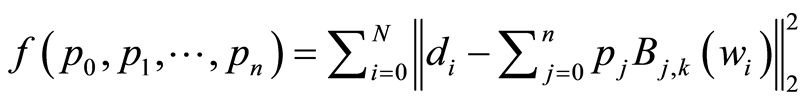 (7)
(7)
其中节点T选择准均匀的。方程式(7)表示为B样条曲线最小二乘拟合。对未知参数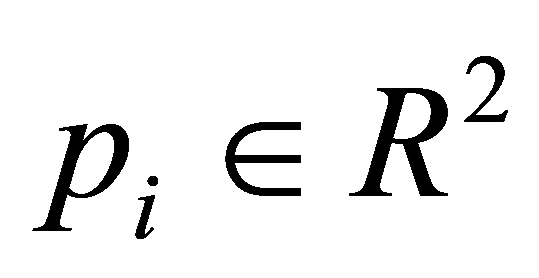 求偏导,式(7)可以整理为
求偏导,式(7)可以整理为
 (8)
(8)
式(8)为一个包含n+1个方程的线性方程组,求解出 就可以得到相应的B样条拟合曲线。参数
就可以得到相应的B样条拟合曲线。参数![]() 是通过点之间的位置关系进行估计,一般采用累加弦长法[1] [2] 进行估计,公式为:
是通过点之间的位置关系进行估计,一般采用累加弦长法[1] [2] 进行估计,公式为:
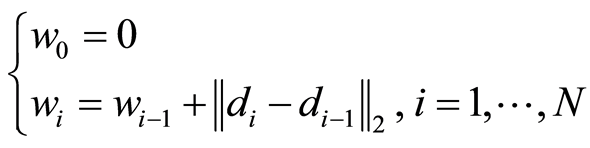 (9)
(9)
其中在累加弦长法中![]() 当成数据点
当成数据点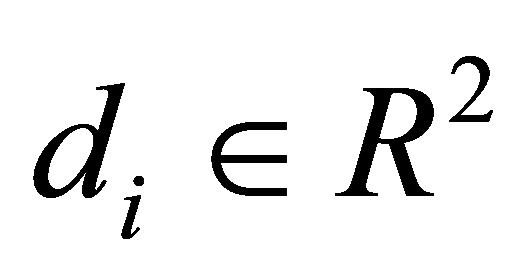 在B样条曲线上对应的参数值。
在B样条曲线上对应的参数值。
从式(8)可以看出,在线性的情况下,传统最小二乘法是通过求解未知变量的法方程来寻求最优数据匹配的。
那么在非线性的情况下,未知变量变为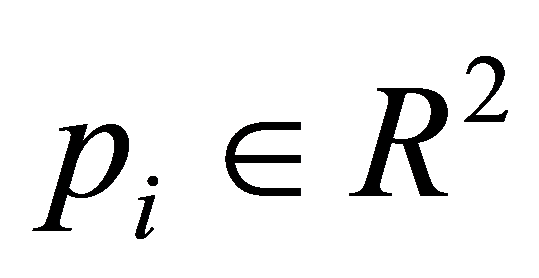 和
和![]() ,或者
,或者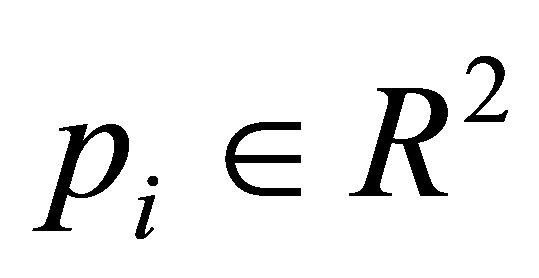 和T。发现梯度求解困难,甚至在尖点处是不存在梯度的。一般非线性拟合曲线是通过适当的变量替换成为线性曲线,从而用线性拟合进行处理,本质上还是线性拟合。但是变换关系不好确定,拟合的精度不高。
和T。发现梯度求解困难,甚至在尖点处是不存在梯度的。一般非线性拟合曲线是通过适当的变量替换成为线性曲线,从而用线性拟合进行处理,本质上还是线性拟合。但是变换关系不好确定,拟合的精度不高。
基于上面的种种不足,本文提出利用遗传算法解决线性及非线性B样条曲线最小二乘拟合问题。
3. 遗传算法求解B样条曲线最小二乘拟合
遗传算法(genetic algorithm, GA)求解科学研究和工程技术中各种组合搜索和优化计算问题的这一基本思想早在20世纪60年代初期就由美国Michigan大学的Holland教授提出,数学框架也于20世纪60年代中期形成。遗传算法是基于自然选择和群体遗传机理的随机搜索算法,模拟了自然选择和自然遗传过程中发生的繁殖、杂交和突变现象,具有全局寻优的优点,广泛的应用在各个领域内。
编码,适应度函数,选择,交叉,变异为遗传算法的几个基本步骤。种群规模SIZE,最大遗传代数MAX,选择概率 ,交叉概率
,交叉概率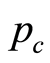 和变异概率
和变异概率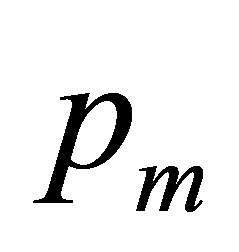 为遗传算法的几个重要参数,影响其收敛速度。在整个计算过程中,遗传算法当前遗传代数记为gen < MAX,种群累计最优值记为BEST,种群当前最优值记为bestnow,第i个个体的适应度记为
为遗传算法的几个重要参数,影响其收敛速度。在整个计算过程中,遗传算法当前遗传代数记为gen < MAX,种群累计最优值记为BEST,种群当前最优值记为bestnow,第i个个体的适应度记为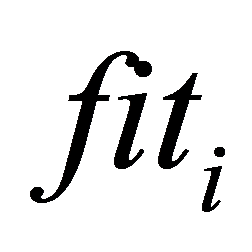 ,种群目标函数计算次数记为Q,且
,种群目标函数计算次数记为Q,且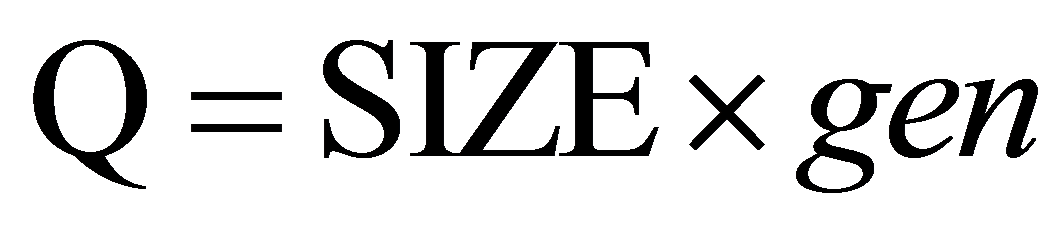 。
。
3.1. 适应度函数
遗传算法的适应度函数,即目标函数,决定着寻优的方向。引进参数L为方程组未知变量的个数。遗传算法在解决线性B样条曲线最小二乘拟合时,根据方程式(7),将适应度函数设计为:
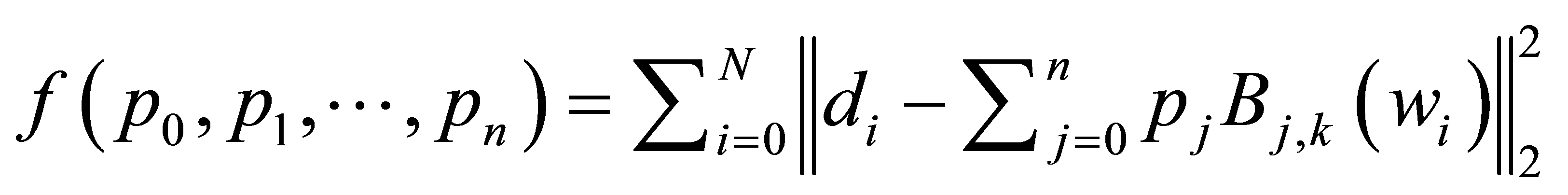 (10)
(10)
其中各种参数见第一节,节点T选择准均匀的,![]() 由方程式(9)所得,且L = 2n + 2。
由方程式(9)所得,且L = 2n + 2。
根据第一节的介绍,遗传算法在解决非线性B样条曲线数据拟合时,分为两种情况,
第一种情况为:选取控制顶点![]() 和节点向量
和节点向量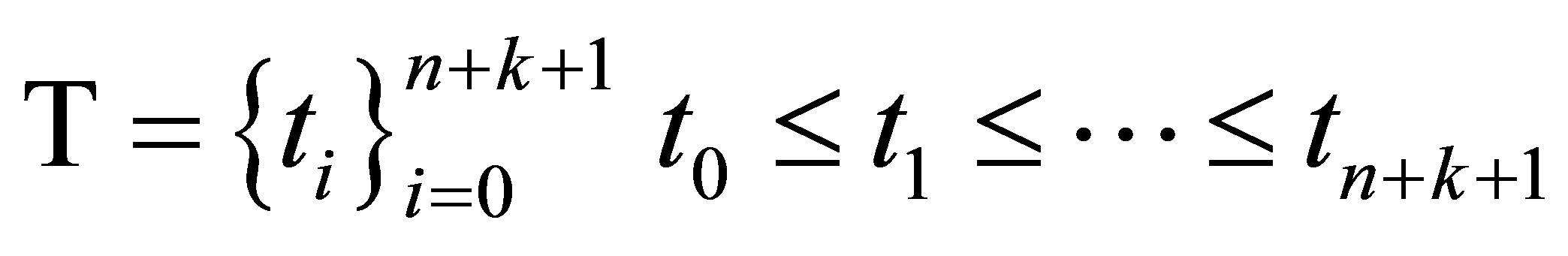 为未知变量,
为未知变量,![]() 由方程式(9)所得,此时L = 3n + k + 4,T为递增数列,则将适应度函数设计为
由方程式(9)所得,此时L = 3n + k + 4,T为递增数列,则将适应度函数设计为
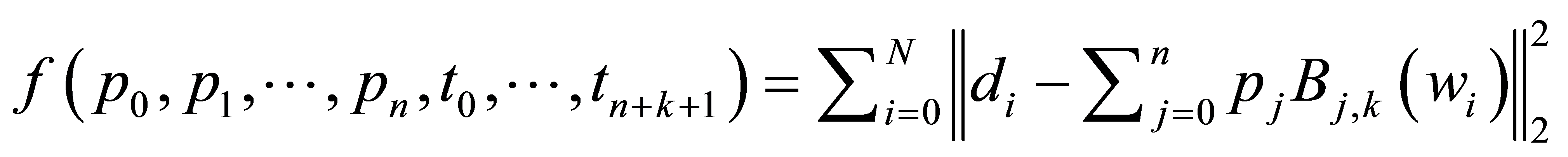 (11)
(11)
第二种情况为:选取控制顶点![]() 和数据点
和数据点 对应的参数值
对应的参数值![]() 为未知变量,节点T选择准均匀的,此时L = N + 2n + 3,则将适应度函数设计为:
为未知变量,节点T选择准均匀的,此时L = N + 2n + 3,则将适应度函数设计为:
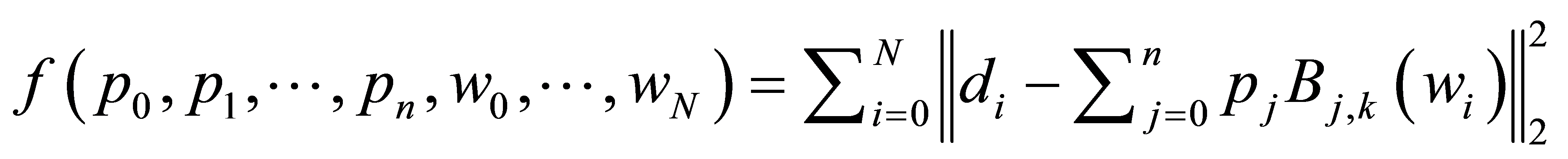 (12)
(12)
3.2. 遗传参数的选取
遗传参数SIZE和MAX能够影响遗传算法收敛速度。研究表明[4] 当Q达到一定的数量时,BEST变化很小,甚至是不再变化。那么选择恰当的Q,将避免过多的重复操作,提高收敛速度。本文数值实验部分选取的SIZE和MAX,是使BEST变化很小的临界值,通过多次调解SIZE和MAX大小获得的。
选择概率 表示的是第i个个体被选中复制的概率,其计算公式为
表示的是第i个个体被选中复制的概率,其计算公式为
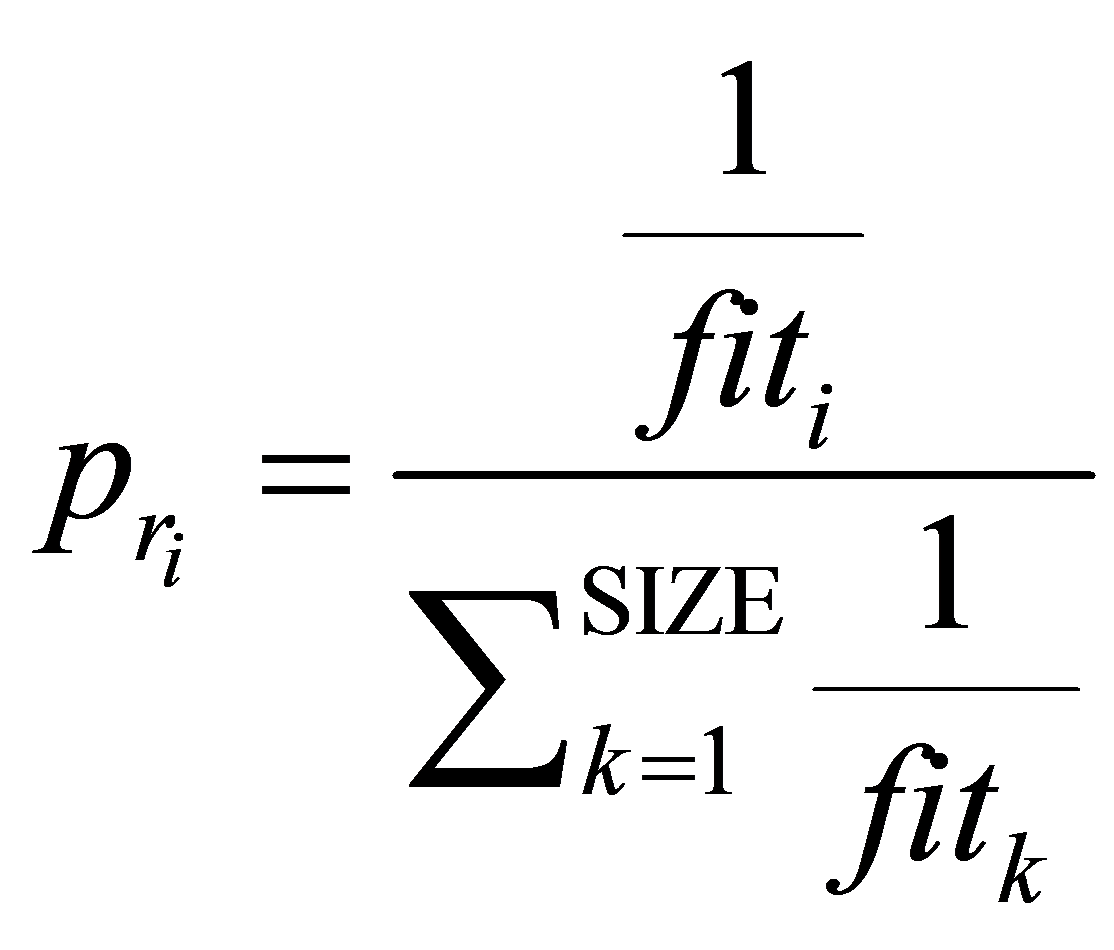 (13)
(13)
个体越接近最优值,则选中的几率会大。
交叉概率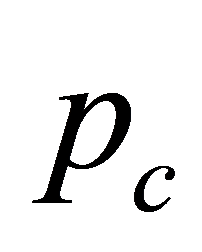 控制着交叉操作被使用的频度,一般取为0.4~0.9。如果
控制着交叉操作被使用的频度,一般取为0.4~0.9。如果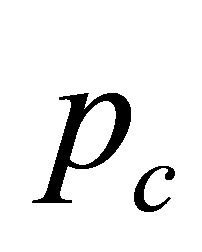 取得太小,会使基因遗传算法反应比较迟钝;取得太大容易破坏优良基因组合,不利于系统的稳定。
取得太小,会使基因遗传算法反应比较迟钝;取得太大容易破坏优良基因组合,不利于系统的稳定。
遗传算法进化前期,种群差异较大,需要扩大搜索空间,以此选择较大的变异概率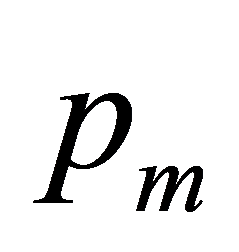 。在遗传算法进化的后期,众多个体趋向最优解,为了避免破坏已经形成的最佳组合,需要选择较小的
。在遗传算法进化的后期,众多个体趋向最优解,为了避免破坏已经形成的最佳组合,需要选择较小的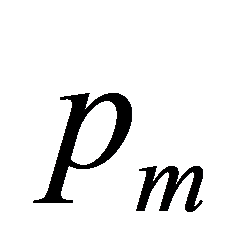 。因此,我们设计了自适应变异率,其计算公式为
。因此,我们设计了自适应变异率,其计算公式为
 (14)
(14)
可以看出随着迭代次数gen的增加,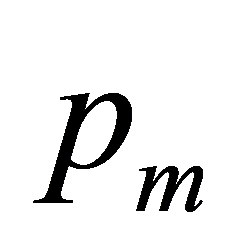 是逐渐变小的。
是逐渐变小的。
3.3. 实数编码
编码定义问题的解空间到染色体编码空间的映射,主要分为实数编码和二进制编码。而公式(10),(11)和(12),涉及到的未知变量较多,相应的二进制编码空间也较大,还要进行十进制与二进制的转换,这样大大降低了寻优速度,显然已经不能满足要求了,以此本文选取近几年比较流行的实数编码[4] 。
假定有L个未知变量,种群规模为SIZE,基因分布在[a, b]。则种群空间的每个个体(Individual)包含L个基因(gen)。实数初始种群空间(gen = 0)为:
从图1可以看出,在未知变量很多的情况,其种群空间也不大,并且可以精确到![]() 。每个基因值都有编号,以[Individual I, genj],0 < i £ SIZE,0 < j £ L标示。
。每个基因值都有编号,以[Individual I, genj],0 < i £ SIZE,0 < j £ L标示。
3.4. 选择,交叉,变异,精英保留机制
选择是根据适应度函数选择复制优质个体淘汰劣质个体,体现“适者生存”的原理。通过选择复制操作,将优良个体的基因传递给下一代。设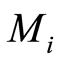 为
为 的整数部分,则选择操作在本文中步骤如下:
的整数部分,则选择操作在本文中步骤如下:
Step a. 已知图1的初始数据种群,计算种群个体的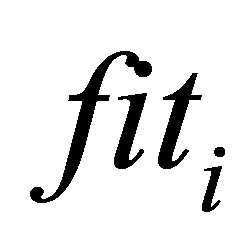 和
和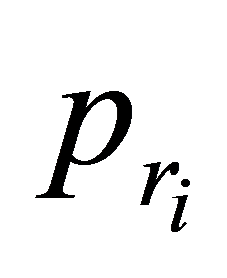 。
。
Step b. 将第i个个体复制 份,保存
份,保存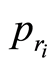 值最大的个体至bestnow。
值最大的个体至bestnow。
Step c. if![]() 则复制
则复制![]() 份的bestnow个体,否则跳出。
份的bestnow个体,否则跳出。
通过上面的3步,种群整体变优,父代初始种群(gen = 0)开始进化。
交叉是对随机选择两个个体以交叉概率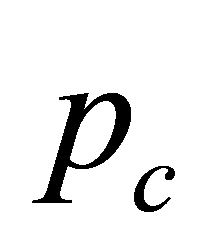 按某种方式相互交换其部分基因,从而形成两个新个体,进一步实现个体的进化。通过交叉操作,基因遗传算法能挖掘已有基因材料的潜力,使其搜索能力得到飞跃的提高。交叉有单点和多点交叉,本文选择多点交叉,根据其基因编号,交叉的位置随机产生,图2展示了多点交叉过程。
按某种方式相互交换其部分基因,从而形成两个新个体,进一步实现个体的进化。通过交叉操作,基因遗传算法能挖掘已有基因材料的潜力,使其搜索能力得到飞跃的提高。交叉有单点和多点交叉,本文选择多点交叉,根据其基因编号,交叉的位置随机产生,图2展示了多点交叉过程。
变异是个体染色体中的某些基因值以一定的变异概率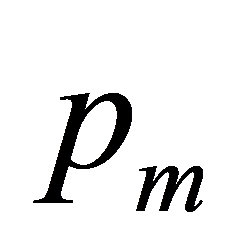 发生变化,使种群发生本质变化,形成新的物种。
发生变化,使种群发生本质变化,形成新的物种。
在实数编码中是产生一个[a, b]之间的随机数替换要变异的基因值。根据其基因编号,发生变异的位置是随机产生的,产生变异的种群个体数目用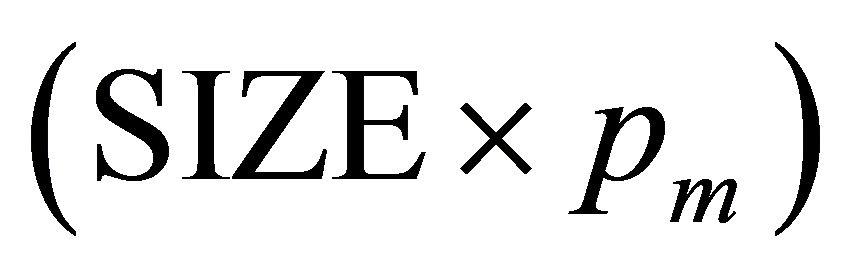 的整数部分来计算。
的整数部分来计算。
经过选择,交叉,变异操作,父代初始种群(gen = 0)完成进化,生成子代种群(gen = 1)。将新一代种群最优个体保存至bestnow,与BEST相比较,最优的保存至BEST。子代种群空间替换父代初始种群空间,开始新一轮的进化。经过MAX次迭代后,最优个体总是在BEST保留下来,这就是精英保留机制[4] 。可以看出精英保留机制可以防止最优值遗失,避免过多重复操作,提高收敛速度。

Figure 1. Real coding of [a, b]=[0, 1]
图1. 实数编码,[a, b]=[0, 1]
 (a) (b)
(a) (b)
Figure 2. (a) Before crossover, (b) After crossover
图2. (a) 为执行交叉操作之前,(b) 为执行交叉操作最后
3.5. 遗传算法工作流程
根据以上遗传算法的介绍,总结其工作流程为:
Step.1 给定SIZE,MAX, ,L,初始种群空间,
,L,初始种群空间,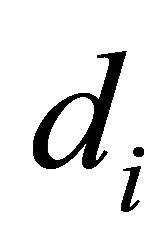 ,设定gen = 0,BEST = 0。
,设定gen = 0,BEST = 0。
Step.2 根据给定公式(1)~(14),必要时对T进行排序,计算个体i的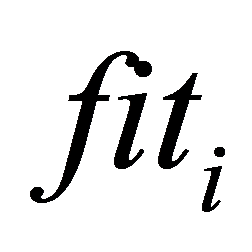 ,
,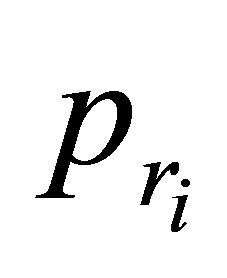 和
和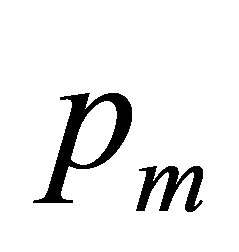 。
。
Step.3 选择操作,保存当前最优值至bestnow。
Step.4 if bestnow < BEST,BEST = bestnow,否则执行Step.5 Step.5 交叉,变异操作,生成新一代种群空间。
Step.6 gen = gen + 1,if gen < MAX,重复Step.2,否则结束。
4. 数值实验
本节选则四个不同的二维翼型数据作为被拟合数据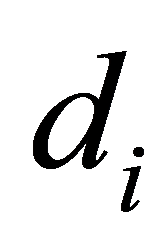 ,选择前三节介绍的方法进行B样条曲线最小二乘拟合,其中二维翼型数据是来自机翼横截面的边界数据,均匀分布在[0, 1]之间。
,选择前三节介绍的方法进行B样条曲线最小二乘拟合,其中二维翼型数据是来自机翼横截面的边界数据,均匀分布在[0, 1]之间。
选择的四组翼型数据为:NACA0012,NACA64A010,RAE2822和SC(2)0712。其中NACA0012和NACA64A010为x轴对称翼型,选择具有11个控制顶点的3次B样条曲线拟合,即n = 10,k = 3。RAE2822和SC(2)0712为非对称翼型,选择用具有13个控制顶点的3次B样条曲线拟合,即n = 12,k = 3。并且NACA0012,NACA64A010,RAE2822为封闭翼型,SC(2)0712为非封闭的。
拟合结果用翼型弦长为1时各数据点到拟合曲线距离的平均值和最大值,及平均误差和最大误差来衡量。图形中虚点为初始数据点,实线为拟合函数。下面分别展示数值实验结果。
4.1. 线性B样条曲线最小二乘拟合结果
在线性拟合部分,最小二乘法选择公式(7),(8)和(9),遗传算法的适应度函数选择公式(10),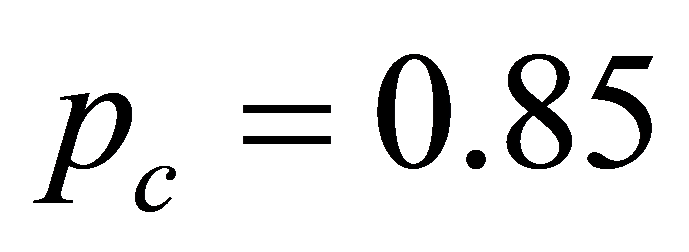 。图3为遗传算法的参数Q和拟合平均误差的关系图,从图中可以看出Q = 11000时,遗传算法收敛趋于稳定,甚至停止收敛。因此将遗传参数设计为SIZE = 50,MAX = 220,节点T为准均匀的,参数
。图3为遗传算法的参数Q和拟合平均误差的关系图,从图中可以看出Q = 11000时,遗传算法收敛趋于稳定,甚至停止收敛。因此将遗传参数设计为SIZE = 50,MAX = 220,节点T为准均匀的,参数![]() 根据公式(9)计算。表1展示线性B样条曲线拟合最终结果。图4为表1最小二乘法计算结果的图形展示,图5
根据公式(9)计算。表1展示线性B样条曲线拟合最终结果。图4为表1最小二乘法计算结果的图形展示,图5

Figure 3. Q and average error of fitness function is (10)
图3. Q与拟合平均误差关系图,适应度函数为(10)

Table 1. The average error of profile data fitting
表1. 翼型数据拟合的平均误差




Figure 4. Graph by least squares, from left to right is NACA0012, NACA64A010, RAE2822, SC(2)0712
图4. 最小二乘法结果图形展示,从左到右依次为:NACA0012, NACA64A010, RAE2822, SC(2)0712




Figure 5. Graph by genetic algorithm, from left to right is NACA0012, NACA64A010, RAE2822, SC(2)0712
图5. 遗传算法结果图形展示,从左到右依次为:NACA0012, NACA64A010, RAE2822, SC(2)0712
为表1遗传算法计算结果的图形展示。
从表1,图4及图5的对比可以看出遗传算法的计算结果非常接近最小二乘法的计算结果,实验证明遗传算法可以解决线性B样条曲线最小二乘拟合。
4.2. 非线性B样条曲线最小二乘拟合结果
图6为遗传算法选择适应度函数公式(11)时,参数Q和拟合平均误差的关系图。其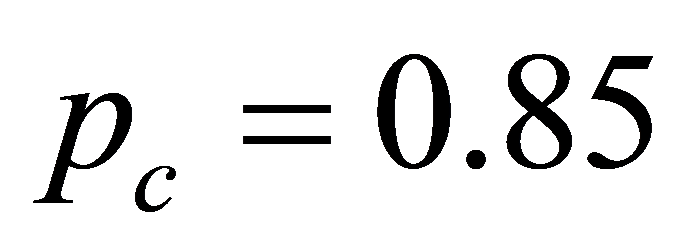 ,初始控制顶点选择表1中最小二乘计算的结果,初始节点T为准均匀的,参数
,初始控制顶点选择表1中最小二乘计算的结果,初始节点T为准均匀的,参数![]() 根据公式(9)计算。从图中可以看出当Q = 16000时,遗传算法收敛的非常慢,甚至停止收敛。因此将遗传参数设计为SIZE = 200,MAX = 800。表2是其数值试验最终结果。图8为表2结果的图形展示。
根据公式(9)计算。从图中可以看出当Q = 16000时,遗传算法收敛的非常慢,甚至停止收敛。因此将遗传参数设计为SIZE = 200,MAX = 800。表2是其数值试验最终结果。图8为表2结果的图形展示。
图7为遗传算法选择适应度函数公式(12)时,参数Q和拟合平均误差的关系图。其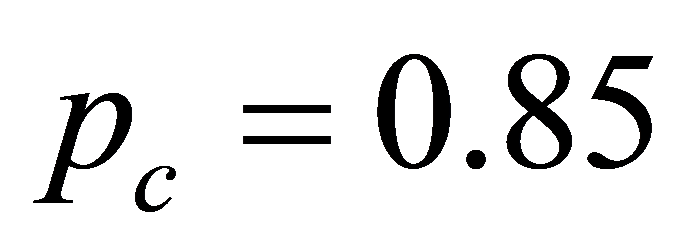 ,初始控制顶点选择表2的计算结果,初始参数
,初始控制顶点选择表2的计算结果,初始参数![]() 均匀间隔选取[0, 1]之间的点,节点T为准均匀的。从图中可以看出当Q = 800000时,遗传算法收敛的非常慢,甚至停止收敛。因此将遗传参数设计为SIZE = 200,MAX = 4000。表3是其数值试验最终结果。图9为表3结果的图形展示。
均匀间隔选取[0, 1]之间的点,节点T为准均匀的。从图中可以看出当Q = 800000时,遗传算法收敛的非常慢,甚至停止收敛。因此将遗传参数设计为SIZE = 200,MAX = 4000。表3是其数值试验最终结果。图9为表3结果的图形展示。
相对于表1,表2的结果更精确,拟合误差变小,图8显示误差变小。相对于表2,表3的误差精确到![]() ,精确度提高了一个量级,图9可以看出两者几乎重合。证明了遗传算法可以很好的解决非线性B样条曲线最小二乘拟合。
,精确度提高了一个量级,图9可以看出两者几乎重合。证明了遗传算法可以很好的解决非线性B样条曲线最小二乘拟合。
5. 结论
遗传算法作为全局随机搜索算法可以很好地解决线性及非线性B样条曲线最小二乘拟合问题。在解决线性B样条曲线最小二乘拟合问题时,其计算结果非常接近精确解,达到预期目标。在此基础上延伸到非线性B样条曲线最小二乘拟合问题,使得逼近精度提高一个量级。但是遗传算法在解决非线性B样条拟合数据问题上的计算效率还是比较低,“早熟”问题依然存在,将遗传算法与其他一些算法结合,比如拟退火法,神经网络等,将是未来的主要工作方向。

Figure 6. Q and average error, fitness function is (11)
图6. Q与拟合平均误差关系图,适应度函数为(11)

Figure 7. Q and average error, fitness function is (12)
图7. Q与拟合平均误差关系图,适应度函数为(12)




Figure 8. Graph of Table 2, from left to right is NACA0012, NACA64A010, RAE2822, SC(2)0712
图8. 表2的图形结果,从左到右依次为:NACA0012, NACA64A010, RAE2822, SC(2)0712
Table 2. Results of the nonlinear data fitting (a)
表2. 非线性数据拟合的结果(a)
Table 3. Results of the nonlinear data fitting (b)
表3. 非线性数据拟合的结果(b)




Figure 9. Graph of Table 3, from left to right is NACA0012, NACA64A010, RAE2822, SC(2)0712
图9. 表3的图形结果,从左到右依次为:NACA0012, NACA64A010, RAE2822, SC(2)0712
致 谢
在此我要特别感谢冯仁忠教授对我的悉心指导,感谢中国自然科学基金(基金编号:No.11271041)的资助。
参考文献 (References)
- [1] 施法中 (2001) 计算机辅助几何设计与非均匀有理B样条. 高等教育出版社, 北京.
- [2] Ma, W. and Kruth, J.P. (1995) Parametrization of randomly measured points for least squares fitting of B-spline curves and surfaces. Computer-Aided Design, 27, 663-675.
- [3] 王晓鹏 (2001) 遗传算法及其在气动优化设计中的应用研究. 博士论文, 西北工业大学, 西安.
- [4] 潘立登 (2009) 遗传算法及其工程应用. 机械工业出版社, 北京.
- [5] Dierckx, P. (1993) Curve and surface fitting with splines. Oxford University Press, Oxford.
- [6] 蒋尔雄, 赵风光, 苏仰峰 (2007) 数值逼近. 复旦大学出版社, 上海.
- [7] Powell, M.J.D. (1970) Curve fitting by splines in one variable. In: Hayes, J.G., Ed., Numerical approximation to functions and data, Athlone Press, London.
- [8] Anthony, H.M., Cox, M.G. and Harris, P.M. (1989) The use of local polynomial approximations in a knot-placement strategy for least-squares spline fitting. NPL Report, DITC, 148/89.