Computer Science and Application
Vol.08 No.07(2018), Article ID:25917,12
pages
10.12677/CSA.2018.87117
The Design and Implementation of a Malay Speech Synthesis System
Meifang Shi, Haoran Feng, Jian Yang*
School of Information Science and Engineering, Yunnan University, Kunming Yunnan

Received: Jun. 29th, 2018; accepted: Jul. 10th, 2018; published: Jul. 17th, 2018

ABSTRACT
Malay is widely used in Malaysia, Singapore and other Southeast Asian countries. Currently, there are about 200 million people using Malay. This paper studies the front-end text analysis method of Malay speech synthesis system, and the back-end speech synthesis method based on HMM. In front-end text analysis and processing, the collection and selection of Malay language data, text normalization, and automatic syllable division were researched and implemented; In the back-end speech synthesis section, the Malay Phonetic list determination, text annotation, context attributes and problem set design, HMM acoustic model training, and speech waveform generation were studied and implemented. Experimental results show that the front-end text analysis and processing method proposed and implemented in this paper can fulfil the requirements of back-end speech synthesis. The back-end speech synthesis system constructed in this paper can synthesize a complete Malay sentence.
Keywords:Malay Language, Speech Synthesis, Hidden Markov Model, Text Analysis, Acoustic Model
马来语语音合成系统的设计与实现
施梅芳,冯浩然,杨鉴*
云南大学信息学院,云南 昆明

收稿日期:2018年6月29日;录用日期:2018年7月10日;发布日期:2018年7月17日

摘 要
马来语广泛使用于马来西亚、新加坡等东南亚国家,目前使用人数约有2亿多人。本文研究马来语语音合成系统的前端文本分析与处理方法、以及基于HMM的后端语音合成方法。在前端文本分析与处理环节,研究并实现了马来语语料的收集与挑选、文本归一化、以及音节自动划分;在后端语音合成环节,研究并实现了马来语音子列表确定、文本标注、上下文属性和问题集设计、HMM声学模型训练、以及语音波形产生。实验结果表明:本文提出并实现的前端文本分析与处理方法可满足后端语音合成的要求,采用本文构建的后端语音合成系统可合成出完整的马来语语句。
关键词 :马来语,语音合成,隐马尔科夫模型,文本分析,声学模型

Copyright © 2018 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
随着信息科学的进步,语音合成技术在近几年得到了飞速发展。合成语音的自然度、可懂度等各种指标都得到了明显的改善,并被广泛的应用于导航、手机语音交互等实际系统中。
现如今,语音合成的应用主要集中在汉语、英语等常用语言,而小语种的研究相对缺乏。作为使用人数较多的马来语是东南亚地区一种重要的民族语言,因此研究马来语语音合成系统对中国与东南亚地区交流互动有积极的意义。
本论文主要研究了马来语语音合成系统的前端文本分析的方法和后端语音合成。从文本层面,通过规则、音节列表、正则表达等方法对马来语的文本进行分析和处理,完成了语料库构建、文本归一化、文本音节化等工作。在系统后端根据音子列表和上下文属性的信息设计问题集,利用HTS工具包进行模型训练,最后生成马来语的语音。
2. 马来语语音合成系统
2.1. 马来语简介
马来语是马来西亚联邦和文莱苏丹国的官方语言,同时也是新加坡的官方语言之一,属南岛语系印度尼西亚语族。马来语由5个单元音,3个双元音和26个辅音组成 [1] 。(此时不区分单元音e和é统一写成e)。其具体音素如表1所示。
2.2. 基于HMM的语音合成
基于隐马尔科夫(HMM)的语音合成方法在近几年来得到广泛的应用,这是一个在语音处理领域被广泛使用的概率模型,用来描述一个系统隐形状态的转移和隐形状态的表现概率。它在语音合成方向运用的基本方法是对语音的参数进行提取、建模,然后根据标注的数据进行自动训练,最后构建出一个合成系统。图1为其基本框架,主要包含训练与合成两个部分 [2] 。
在提取特征参数时主要是选取LSP作为本次实验的谱参数,通过对语音的基频、时长、谱参数进行训练得到后端声学模型。而在合成部分,则是对输入文本进行解析,同时将训练完成的模型进行参数估计,最后使用STRAIGHT合成器合成出所需要的语音。

Table 1. Malay phoneme list
表1. 马来语音素列表
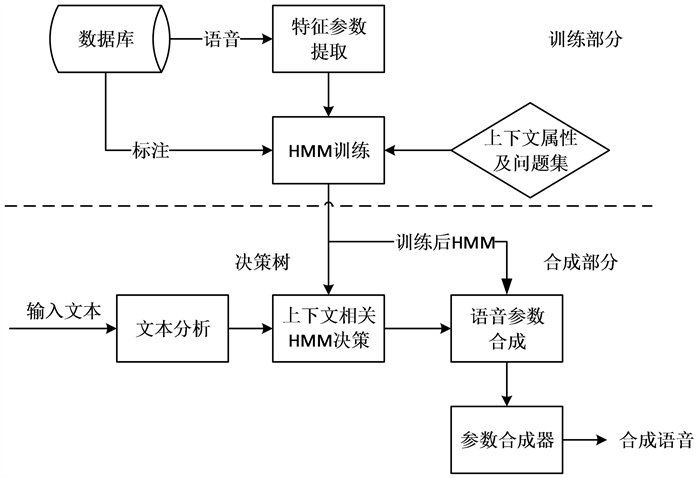
Figure 1. Framework of HMM-based speech synthesis system
图1. 基于HMM的语音合成系统框架
2.3. 马来语语音合成系统的设计与实现
在基于HMM的马来语语音合成系统的设计与实现过程中,主要包括语料的收集与挑选、文本归一化、文本音节化、文本标注、上下文属性及问题集设计和HMM训练与合成。基本流程如图2所示。
总的来说,语音合成的以上过程,可以归结为两个阶段:前端文本分析、后端语音合成。在语言、语法、语义层的处理工作可归结为前端的文本分析。而语音层面上的韵律生成和声学层面上的合成语音是属于语音合成的后端。
3. 马来语语音合成系统前端文本分析
在语音合成技术中,前端文本分析结果的质量直接影响着合成语音的可懂度和自然度,因此将前端文本分析作为语音合成系统的重要模块。
3.1. 马来语语料库构建
语料库是基于语料库进行语音合成的系统的重要组成部分。语料库的质量和覆盖的范围会影响合成语音的质量。马来语的语料库为后端的音子模型训练和语音合成提供数据准备,所以构建的马来语的语料库应该包含马来语的所有音子和常用词汇。
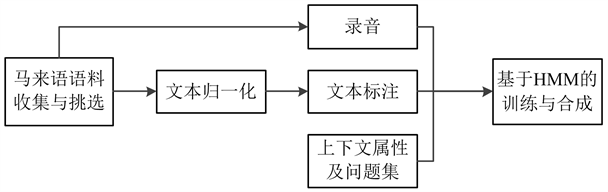
Figure 2. Basic flow of Malay speech synthesis
图2. 马来语语音合成基本流程
3.1.1. 原始语料的获取
在构建马来语的原始语料库时,为了获取不同风格的马来语文本,本文采用从马来语的网站和电子书上获取马来语的原始语料库的方法。网站的内容包括科技、新闻、生活、娱乐、体育等方面,保证了语料的多样性。在该过程中共收集了大小为380 MB的原始语料,约有3600万个单词。
3.1.2. 文本语料库的整理
从网站上下载的原始语料中不可避免的包含了很多不完整的句子、非法字符以及网页标签,并且各个网站之间存在转载和跳转等情况,导致语料的重复,所以需要对原始语料库进行整理,得到文本语料库。
3.1.3. 发音语料的挑选
发音语料库的挑选就是从文本语料中挑选出有代表性的句子,作为发音语料进行录音。在选取发音语料的过程中应该兼顾韵律和音段两个层次。
马来语是一种没有重音的语言,所以首先应该考虑的是音素在自然语流中出现的频率,再考虑韵律信息。韵律信息,在选取时主要体现在句子类型上。选取的句子长度为6~18个单词,构建的马来语的语料库应该包含马来语的常用词汇,所以挑选的马来语发音语料需包含文本中的高频词 [3] 。在整个选取过程中,要保证句子的最大信息量,所以选取的各个句子间的相似度要保证最低。
3.1.4. 发音语料的合理性
挑选出发音语料库后,需要对发音语料库进行评判来证明其合理性,并验证算法的可行性和稳定性。针对马来语语音合成的实际需求,马来语的发音语料库必须包含马来语的所有音素。此次选取语料采用随机算法,所以选取马来语发音语料的程序应该是稳定的,即多次挑选的结果的音素分布是相似的。
由图4可知,发音语料覆盖了马来语的34个音素,比较图3和图4可知,发音语料中34个音素的出现比例类似于文本语料库中的音素出现比例,说明该发音语料库在音素分布方面具有代表性,符合了发音语料库的标准。
为了验证算法的稳定性和挑选结果的可靠性,本次实验先后运行3次挑选程序,依次得到3个不同的“马来语发音语料库”,分别统计3个“马来语发音语料库”中音素出现的次数,画出其音素出现次数直方图,其结果如图5所示。
由图5可知,三个“马来语发音语料库”文本内容不同,但它们的音素出现次数直方图比较接近,说明语料挑选算法稳定。
3.1.5. 语音语料库的录制
挑选出发音语料后需进行录音,得到语音语料。在录制过程中始终保持适中的语速。该录音保存的格式为S48的声音压缩格式,根据实验的需要将其转换成PCM的格式。在格式转换完成之后,需要对该录音进行切分,将整段语音切分成单独的句子,其保存的格式为采样率是16 KHz的wav文件。
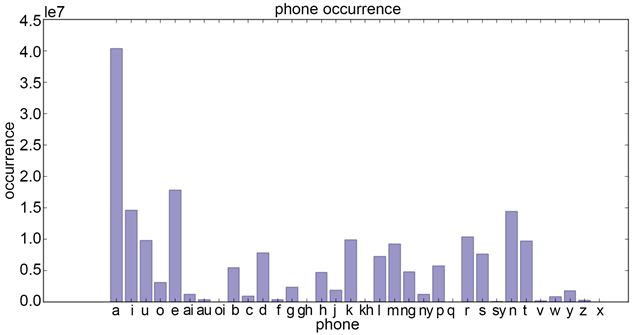
Figure 3. Phoneme distribution of Malay text corpora
图3. 马来语文本语料库音素分布

Figure 4. Phoneme distribution of Malay pronunciation corpus
图4. 马来语发音语料库音素分布
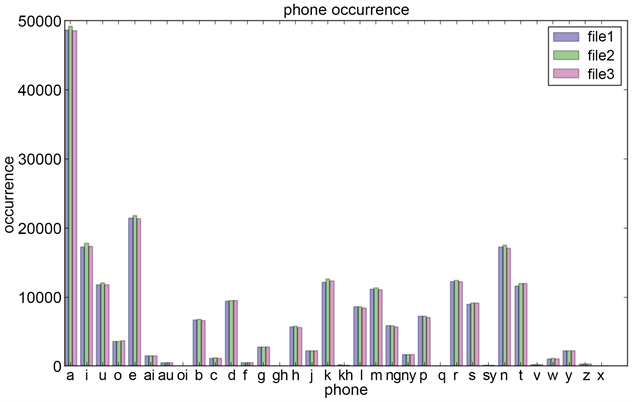
Figure 5. Comparison of the occurrence times of phonetic elements in 3 groups
图5. 3组发音语料音素出现次数比较
3.2. 马来语文本归一化
针对马来语而言,归一化过程就是将马来语文本中非马来语拼写的非规范文本转化为马来语写法的过程。例如若文本中出现阿拉伯数字“2”,应该将其转化为马来语写法“dua (二)”。
包含数字的文本称为非标准文本,文本中的数字称为非标准词。在马来语文本中数字在不同语境中其读法是不一样的,因此在马来语的归一化过程中应该根据不同的语境对读音进行判断,并确定正确的读法,最后将其转化为马来语的写法。所以马来语的归一化过程应该包括非标准词的识别,歧义判断,消歧处理,将非标准词转化为标准词。其过程如图6所示。
3.2.1. 非标准词识别
此次实验关注的是马来语中的数字字符的归一化。所以在非标准词识别中需要识别出马来语文本中的数字,即0~9阿拉伯数字。
3.2.2. 歧义判断
一般而言,数字有两种读法,一种是依次读数字串(例如,213,中文读“二一三”)即数码的读法,另一种是读其数值(例如,213,中文读“二百一十三”)。其中属于数码的情况比较少见,所以只需判断出数码的情况,其余情形默认为数值的读法即可。
结合经验判断和文本语料的实际情况,属于数码的情况一般包括:身份证号,电话号码,邮编和QQ号。这几类数码的特点如下:
l 身份证号:马来西亚的身份证号由12位数字组成。
l 电话号码:马来西亚使用的电话号码为10位,且以数字011、012、013、014、015、016、017、018、019之一开头。
l 邮政编码:马来西亚的邮编采用5位数字的形式。
l QQ号码:QQ号最少有5位且第一位不能为0。
采用正则表达式与关键字相结合的方法,对上述编号进行判断。除了电话号码外,很少有开头为0的10位数字串,所以电话号码的歧义判断无需添加关键字。数码的歧义判断的正则表达式与关键字的匹配情况如表2所示。
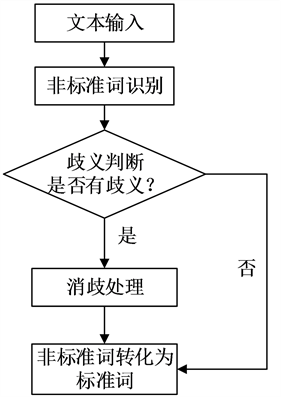
Figure 6. Process of Malay text normalization
图6. 马来语文本归一化过程
Table 2. Regular expressions and keywords of digital reading
表2. 数码读法的正则表达式与关键字
3.2.3. 消歧处理
在收集的语料中存在身份证号、电话号码、QQ号、邮编这几种数码读法的情况。如后期再发现数码读法的情况,则应该添加到规则中。除了例举的数码读法情况外,将出现的数字都视为数值的读法。
3.2.4. 数字字符转化为标准词
在歧义判断中,如果数字判定为数码的读法,则只需将数字逐位转化为马来语的写法。阿拉伯数字0~9的马来语写法如表3所示。
在歧义判断时,如果数字判定为数值的读法,则应按数值读法的规则进行转换。其转换规则如下:
l 当数值为0~9时,按数码的读法来读。
l 当数值为10时,读作“sepuluh”,当数值为11时读作“sebalas”。
l 当数值为十几(除了11)时,在几的读法后面加上belas,例如“2”的读音为“dua (二)”,则“12”的读音为“dua belas (十二)”。
l 当数值为几十的时候,则用“puluh”表示十的这个权重,当数值为几十几时,直接在几十的读音后面加上个位的几的数码的读音即可。例如“2”的读音为“dua (二)”,“3”的读音为“tiga (三)”,则“23”的读音为“dua puluh tiga (二十三)”。
l 权重百的读音为“ratus”,权重千的读音为“ribu”,百万的读音为“juta”,十亿的读音为“billion”。
l 数值的读法的规则和英文是一样的,每三位一起读。如“23,000”读作“dua puluh tiga ribu”即“二十三千”。
对马来语的归一化的正确率进行计算,得到此次马来语归一化的正确率为95.13%。达到了语音合成系统对前端文本处理的要求。
3.3. 马来语音节的自动划分
马来语是一种有明显音节结构的字母语言,因此,马来语的文本处理需将待处理的文本切分为音节序列,这个过程叫做音节划分。
马来语的音节结构有四种不同的组成形式,即元音(V),元音 + 辅音(VC),辅音 + 元音(CV),辅音+ 元音 + 辅音(CVC)。马来语的单词都是由以上的四种音节进行组合得到的。
本次实验采用基于音节列表的逆向最大匹配与规则相结合的方法实现马来语音节化。为了尽可能罗列马来语文本中可能出现的音节,首先人工音节划分马来语电子词典中的12379个单词,然后去重、汇总,得到个数为1840的音节列表。对这1840个音节进行长度统计,可知在马来语音节列表中,最长音节的长度为5个字母 [4] 。
综合以上的信息,此次基于音节列表的逆向最大匹配的音节化方案开始匹配时采用5个字母进行匹配。即首先从单词的最右端选取5个字母,用这5个字母与音节列表进行匹配。如果匹配成功则将这5个字母划为一个音节。如果这5个字母序列不存在于音节列表中,则去掉最左端的字母,用留下的4个
Table 3. Malay number table
表3. 马来语数字词表
字母与音节列表进行匹配。如此不断地重复去除最左端的字母和匹配的过程,直到留下的字母序列与音节列表相匹配为止。该音节化方案的结果有较高的正确率。但是音节化的结果中还存在一些错误,且这些错误存在规律。当11个特殊的音节在单词的中间或结尾时,音节划分就会存在错误。这11个特殊的音节为skan,kri,ste,sta,stik,klu,pli,spek,brik,bru,gla。其错误规律如表4所示。
从上表可以看出,这些错误的规律是:将上一个音节的最后一个字母错误的划分到下一个音节。所以为了提高音节化的正确率,当单词中出现这11个特殊的音节时,需对特殊音节在单词中的位置进行判断,当特殊音节位于单词的中间或结尾时,应将位于该音节序列的最左端的辅音字母划分到上一个音节,将剩下的字母序列划为单独的一个音节。这种划分音节的方法很大程度上提高了音节化的正确率。其音节划分的正确率如表5所示。
由上表的比较可以看出,本文提出的基于音节列表的逆向最大匹配与规则相结合的音节化方案,相较于基于音节列表的逆向最大匹配的音节化方案,正确率有了明显的提高,且音节化正确率为96.40%,已经基本能满足后端语音合成对数据正确率的要求,其错误率在可接受的范围之内。
4. 马来语语音合成系统后端语音合成
4.1. 马来语音子列表确定和文本标注
本文参考了汉语声韵母划分方法并请教了马来语专家,采用辅–元–辅音(CVC)的音节结构划分了鼻音音子10个,爆破音音子28个和VC结构构成的韵母音子47个,加上句间停顿sil与句中停顿sp,总计由121个马来语音子组成了音子列表 [5] ,如表6所示。
音子列表确定后,基于音频文件的时间信息和马来语文本语料,获取时间均匀划分的单音子lab文件与不带时间信息的三音子lab文件。本次实验利用HMM,以HTS工具包中HVite强制对齐工具来获取时间非均匀划分的音子文件从而完成文本标注工作。音子自动切分主要包含两个部分:数据准备和模型训练。在数据准备过程中包括产生文本信息、语音信息和音子信息。在模型训练过程中包括音子自动切分模型训练、HVite强制对齐和运用Praat软件进行人工校对。
本次实验结果选取了100句作为统计对象,通过Praat软件对比自动切分音子边界和手动切分音子边界,以公式(1)作为自动切分准确度的统计标准。
Table 4. Syllable division error regularity of 11 syllables
表4. 11个音节的音节化错误规律
Table 5. Malay phonetic division correct rate
表5. 马来语音节化正确率
Table 6. Malay phonon list
表6. 马来语音子列表
 (1)
(1)
其中N是句子音子总个数,n是手动切分和自动切分音子相一致的个数。据此统计,得到马来语音子自动切分准确率为65.88%,可以看出该准确率还是比较高的,确实可以减轻马来语语音合成系统中音子切分的工作量,降低整个系统的成本。
4.2. 上下文属性及问题集
马来语发音过程中,各音子之间存在协同发音的作用,又在上下文属性的影响下,同一音子单元可能存在发音变化的问题。依据上下文属性集合采用决策树聚类的方法减弱模型参数训练中过拟合的现象,便于合成时匹配相应的模型对音子进行建模,提高合成语音的鲁棒性 [6] 。所以,设计合理的上下文属性和问题集,需要总结不同参数各自具有的特征,归纳出相应的问题集。表7是本文设计的部分上下文属性,表8是部分问题集。
4.3. 声学模型的训练和合成
本次实验用于训练的马来语发音语料一共1000句,时长约为1.6小时,wav音频文件总计大小为204 MB,文本语料大小为554 KB,录音采样率为48 KHz,采样精度为16 bit的单声道wave格式,使用的工具包为基于windows10搭建的Cygwin环境下HTS-STRAIGHT-2.0。主要参数配置如下:
l 声学参数:采用24阶的LSP参数
l 建模单元:采用音子作为基本建模单元,8个元音、26个辅音、85个韵母结构音子(VC结构单元)、1个静音段sil、1个句间停顿sp,一共121个音子。
l HMM模型状态:采用从左至右无跳空结构的5状态模型。
l 在合成过程中,挑选100句语料作为待合成语句,其中训练集内50个语句,训练集外50个语句。
5. 实验结果与分析
在马来语语音合成系统训练和合成部分完成后,本次实验得到了合成出的100句马来语语音,并对其中一句进行示例分析,它的原始音频和合成音频语谱图及波形如下所示:
待合成语句:Anda harus sentiasa menjangkakan kos tersembunyi.
比较图7和图8,图9和图10可知,两段语音的波形能量和共振峰分布基本一致。为了对合成结果有直观的表示,本文请了三位测试者对100句合成语音中随机抽取的30句进行自然度的主观打分,最后取平均分为最后的得分,主观评分标准表如表9所示。
三位测评者对合成语音的可懂度和自然度的具体测评结果如表10所示。
由表10可知,测评者对合成语音打分的平均分在3.13分,处于可接受水平。总体而言,本论文所构建的马来语语音合成系统达到了预期设想目标。
Table 7. Partial context attribute set of Malay speech synthesis system
表7. 马来语语音合成系统部分上下文属性集
Table 8. Partial problem set of Malay speech synthesis system
表8. 马来语语音合成系统部分问题集
Table 9. Subjective evaluation score table
表9. 主观评测打分表
Table 10. MOS evaluation results
表10. MOS评测结果

Figure 7. Original speech spectrogram
图7. 原始语音音频语谱图

Figure 8. Synthetic speech spectrogram
图8. 合成语音音频语谱图

Figure 9. Original speech waveform
图9. 原始语音波形图

Figure 10. Synthetic speech waveform
图10. 合成语音波形图
6. 总结与展望
6.1. 总结
本文围绕马来语语音合成系统,完成了合成系统前端文本分析和后端语音合成。实现了马来语语料库的构建、文本归一化、马来语音节的自动划分、上下文属性集的设计、声学模型的训练、语音合成。实验结果表明,文本归一化的正确率达95.13%,音节划分的正确率达96.40%,均达到了语音合成的要求,为后端的合成提供了数据准备。在后端设计了马来语上下文属性集和问题集,结合校对后的标注文件进行声学模型训练。结果分析表明,合成语音的质量达到了一般水平,因此基于HMM的马来语语音合成系统是切实可行的。
6.2. 展望
本文设计并实现了马来语语音合成系统,虽然取得了一定的成绩,但仍有许多地方需要改进和完善:
l 在语料库构建时只考虑了音节和句子层面,没有考虑音节覆盖率和稀疏度的问题。在马来语归一化时,只考虑了数字没有考虑其他的特殊字符。
l 在马来语上下文属性集和问题集设计中仍有部分细节工作不足。
致谢
作为马来语专家,赵然老师为本文研究提供了大力支持,在此致谢。
基金项目
本文获国家自然科学基金项目(61262068)资助。
文章引用
施梅芳,冯浩然,杨 鉴. 马来语语音合成系统的设计与实现
The Design and Implementation of a Malay Speech Synthesis System[J]. 计算机科学与应用, 2018, 08(07): 1053-1064. https://doi.org/10.12677/CSA.2018.87117
参考文献
- 1. 苏莹莹, 赵月珍. 基础马来语[M]. 北京: 外语教学与研究出社, 2015: 263-266.
- 2. Zen, H., Masuko, T., Yoshimura, T., Tokuda, K., K.obayashi, T. and Kitamura, T. (2007) State Duration Modeling for HMM-Based Speech Synthesis. IEICE Transactions on In-formation and Systems, 90-D, 692-693. https://doi.org/10.1093/ietisy/e90-d.3.692
- 3. Tan, T.-S. and Sh-Hussain (2009) Corpus Design for Corpus-based Speech Syn-thesis System. American Journal of Applied Sciences, 6, 696-702. https://doi.org/10.3844/ajassp.2009.696.702
- 4. Ramli, I., Jami, N., Seman, N. and Ardi, N. (2015) An Improved Syllabification for a Better Malay Language Text-to-Speech Synthesis. Procedia Computer Science, 76, 417-424. https://doi.org/10.1016/j.procs.2015.12.280
- 5. Mustafa, M.B., Don, Z.M. and Knowles, G. (2013) Context-Dependent Labels for an HMM-Based Speech Synthesis System for Malay HMM-Based Speech Synthesis System for Malay. 2013 International Con-ference Oriental COCOSDA held jointly with 2013 Conference on Asian Spoken Language Research and Evaluation (O-COCOSDA/CASLRE), Gurgaon, 25-27 November 2013.
- 6. Tokuda, K., Toda, T., Yamagishi, J., et al. (2013) Speech Synthesis Based on Hidden Markov Models. Proceedings of the IEEE, 101, 1234-1248. https://doi.org/10.1109/JPROC.2013.2251852
NOTES
*通讯作者。