Software Engineering and Applications
Vol.
10
No.
06
(
2021
), Article ID:
47472
,
12
pages
10.12677/SEA.2021.106082
基于混合数据挖掘的大学生计算机技能 需求分析
林梦琪,曾 鑫,胡建鹏,张晓梅,李思远
上海工程技术大学,电子电气工程学院,上海
收稿日期:2021年11月12日;录用日期:2021年12月20日;发布日期:2021年12月27日

摘要
随着人工智能时代的到来,为了满足国家对信息化、专业化人才的培养要求,需要对大学计算机基础课程做出相应的改变。在本文中,我们从学生个人兴趣与社会就业需求两个角度出发,首先采用问卷调查的形式搜集学生对于目前计算机基础课程的态度和看法,通过情感分析技术对学生进行意图挖掘和倾向性分析;再从招聘网站上爬取数十万条与计算机技能相关的文本数据,通过自然语言处理提取有效内容并对计算机技能进行挖掘,得到了不同专业对计算机技能需要掌握的程度。本文以大量数据作为支撑,以数据挖掘与分析的方式为高校计算机基础教学改革提供了参考。
关键词
数据挖掘,网络爬虫,意图挖掘,倾向性分析,自然语言处理

Analysis of College Students’ Computer Skills Requirements Based on Mixed Data Mining
Mengqi Lin, Xin Zeng, Jianpeng Hu, Xiaomei Zhang, Siyuan Li
School of Electronic and Electrical Engineering, Shanghai University of Engineering Science (SUES), Shanghai
Received: Nov. 12th, 2021; accepted: Dec. 20th, 2021; published: Dec. 27th, 2021

ABSTRACT
With the advent of the era of artificial intelligence, in order to meet the national requirements for the cultivation of information and professional talents, it is necessary to make corresponding changes to the university computer basic courses. In this paper, we will start from two perspectives: students’ personal interest and social employment needs, first of all, use the form of questionnaire survey to collect students’ attitudes and views on the current computer basic courses, and excavate students’ intention and analyze their tendency through emotion analysis technology; then crawl hundreds of thousands of text data related to computer skills from the recruitment website, through natural language processing to extract effective content and computer skills to get the degree of computer skills need to be mastered by different majors. This paper, supported by a large amount of data, provides reference for the teaching reform of computer foundation in colleges and universities by means of data mining and analysis.
Keywords:Data Mining, Network Reptilian, Intention of Mining, Tendency Analysis, Natural Language Processing

Copyright © 2021 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
进入二十一世纪以来,在社会经济稳健发展的背景下,我国高校计算机基础教学水平已取得一定进步与发展。然而,传统的教学方式和旧式的教学内容并不能够满足社会需求,学生在学校所学到的知识与工作上需要用到的内容存在很大的差距。为了减少这种差距,满足日益严格的教学要求,高校计算机教学改革的重心应逐步从教学技术向课堂组织模式和教育理念进行转变 [1]。如今信息技术课程已在中小学普遍开设 [2],和大学计算机基础的教学没有本质上的区别,这使学生得不到层次上的提高。因此,在人工智能的背景下,计算机基础教学要采取怎样的方式与内容是当今社会亟待解决的问题。
随着科学技术不断提高,计算机逐步能够代替人脑去做许多繁琐重复的事,为人类的生活解决了许多难题。例如网络爬虫技术被越来越频繁地使用,可以借助它在短时间内自动地获取大量信息,节省了大量的时间;通过采用机器学习的方法,可以学习人的行为、模仿人去做一些复杂的事情,其中自然语言处理可以在海量的文本信息中学习,对文本进行分类等操作。这些技术手段需要基于大量的数据,然后对于某件事物得出最客观、真实的评价 [3] [4]。
各大高校对于计算机基础教学的方案往往是基于过去遗留下来的模式和老师自身的经验、喜好等,以这样的方式对计算机基础教学进行改革过于主观、不够有说服力。因此,本文提出了面向大学计算机技能需求的数据挖掘方法,在大数据时代下,利用时代的优势、以数据作为支撑,利用当前流行的计算机技术,为改革提供更加有力的分析结果 [5] [6]。
2. 研究方法
为了能够从不同维度为高校计算机基础教学改革提供帮助与参考,本文选择从不同层面对当前大学计算机技能需求进行深入的挖掘与分析。学生层面主要是为了调研同学们对于现在所学计算机课程的一些看法:通过情感分析和文本挖掘技术对调研结果进行意图挖掘与倾向性分析,深入探究学生内心的真实想法;社会层面是为了顺应目前的就业形势:利用爬虫的方式获得与就业相关的文本信息,通过自然语言处理进行技能挖掘与掌握程度划分,了解当前时代背景下,不同专业对于不同计算机技能的需求程度。具体研究方法与流程如图1所示。
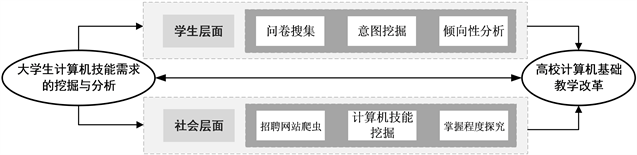
Figure 1. Data mining methods and procedures
图1. 数据挖掘方法与流程
3. 数据采集
文主要通过问卷调查和网络爬虫的方式进行数据采集。参与问卷调查的大学生一共有652名,调查对象均来自于上海工程技术大学的机械与汽车工程学院、化学化工学院、材料工程学院、航空运输学院、城市轨道交通学院以及多媒体设计学院。再通过对招聘网站使用爬虫技术,获得数十万条不同岗位的职位信息。
3.1. 问卷搜集
本次问卷调查在问卷星平台开展。如图2所示,问卷中含有17道客观题,涵盖了学生基本信息、对计算机技术的兴趣和使用习惯、以及对学校中计算机应用基础教学方式的看法,外加1道主观题,需学生填写对现阶段教学的意见或建议。
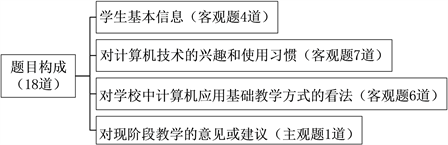
Figure 2. The topic composition of the questionnaire survey
图2. 问卷调查题目构成
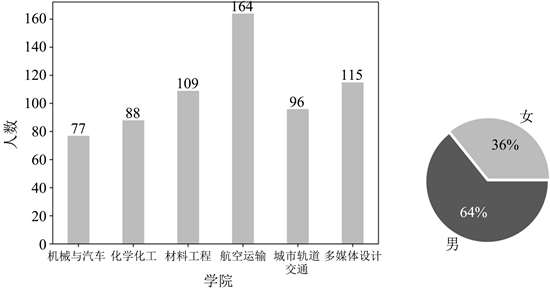
Figure 3. Statistical results of questionnaire survey
图3. 问卷调查统计结果
如图3所示,最终共收到649份有效问卷,均来自于上海工程技术大学六大学院,其中女生232名,男生417名。具体的统计结果将会在第3.1节中展示。
3.2. 招聘网站数据爬虫
网络爬虫可以根据预设的规则,在网页中自动、快速地抓取想要的信息或数据,对于需要获得大量信息的场景,这种方式效率高、效果好,能够节省大量的时间。在数据挖掘中也是十分常用的手段。本文为了探究社会对大学生就业过程中的计算机技能需求,决定采用网络爬虫的方式,对51job网站中的招聘信息进行爬取,爬取内容为招聘的职位名称以及职位要求。本文中的爬虫具体流程如图4所示。

Figure 4. Crawler process of the recruitment website
图4. 招聘网站爬虫过程
3.2.1. 防屏蔽策略
在抓取网页数据的过程中,短时间内快速大量地访问同一个网站,网站则会认为这是恶意的攻击,阻止继续进行访问。为了解决这类问题,爬虫中有一些防止被屏蔽的方式可以解决这类问题。
防屏蔽的策略有很多,本文主要采用了以下两种方式:
1) 浏览器伪装,由于服务器会对爬虫进行屏蔽,此时需要伪装成浏览器才能爬取。大部分反爬虫网站会对用户请求的Headers信息的“User-Agent”字段进行检测来判断身份,有时,这类反爬虫的网站还会对“Referrer”字段进行检测。因此可以在爬虫中构造这些用户请求的Headers信息,以此将爬虫伪装成浏览器,简单的伪装只需设置好“User-Agent”字段的信息即可。

Figure 5. Browser sends requests to the server
图5. 浏览器向服务器发送请求
如图5所示,在发送请求的过程中,若设置了“User-Agent”,那么服务器则会将请求方判断为浏览器,换句话说,“User-Agent”代表了浏览器的身份。
2) 代理服务器,在爬取数据的过程中,会自动的频繁地访问一个网站,如果在短时间内采用一个固定的IP,后台的管理人员会限制这个IP,禁止继续访问,甚至会封掉账号。可以采用代理服务器的方法,根据不同的IP进行访问,用代理去爬取想要的数据,这个方法可以很好地解决IP限制的问题。
通过这两种方式,很好的解决了大规模对同一个网站进行访问而导致访问被拒绝的问题。
3.2.2. 匹配策略
根据图4可知,在获取到response响应内容后,由于网站中存在大量无用的内容,需要对内容进行解析和匹配,主要方式有正则匹配和XPath表达式 [7]。其中XPath的运行效率更高,它是基于网页标签来匹配相关信息,更适合提取网页信息。
XPath解析原理:实例化一个etree的对象,将需要被解析的页面源码数据加载到该对象中;调用etree对象中的XPath方法结合XPath表达式实现标签的定位和内容的捕获。
因此,本文选用XPath表达式对响应获得的html进行解析,在海量的网页信息中,能够快速定位到某些特定的位置,对于51job网站中,职位名称和职位要求可以利用标签的属性值直接定位并提取,根据不同类型的岗位存入相应的文本中。通过爬虫的方式,最终共获得十万条招聘岗位信息。
4. 数据处理
本节通过对问卷调查中主观性的文本信息进行分析、处理和提取,以及对客观性数据进行统计和归纳,得到学生对计算机的兴趣点和对现阶段教学的意见建议;再利用自然语言处理中词频统计的方式,对招聘信息进行数据处理,间接挖掘出学生求职就业中需要掌握的计算机技能,并将不同技能进行了掌握程度划分,针对不同学院的同一项技能进行对比分析。
4.1. 问卷调查结果与分析
问卷主要包括17道客观题与1道主观题,其中客观题主要涵盖三个方面,分别是:学生基本信息、对计算机技术的兴趣和使用习惯、以及对学校中计算机应用基础教学方式的看法。下面会对这几个方面的客观题进行分析。
在学生的基本信息中了解到,他们均为00后,从出生就处于移动智能时代,小学便开始接触到计算机,因此他们均熟悉最基础的计算机操作。
在“你使用计算机时主要做些什么”的(多选)问题中,主要考察学生对计算机的使用习惯,可以得到:不论男生还是女生,使用计算机均以看视频为主,另外还会使用计算机进行聊天、学习和编程;在查资料这一选项中,女生的积极性明显要比男生高,而男生会比女生更爱玩游戏,不过在网购方面女生比男生略高。从使用习惯可以看出,无论是学习、娱乐还是生活,计算机都发挥着非常重要的作用,然而随着智能手机的普及,有些功能被手机所取代,学生使用电脑更倾向于看视频、查资料和编程等。具体数据如图6所示。
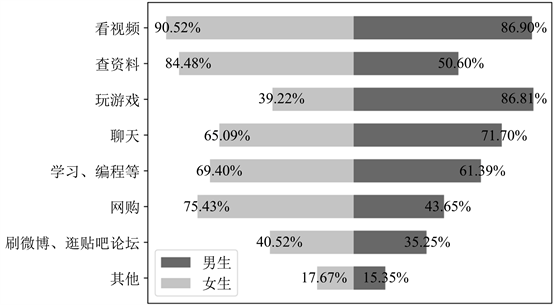
Figure 6. Questionnaire of mainly do when use a computer
图6. 问卷之使用计算机时主要做些什么
在“对计算机相关的应用技术的看法”相关的(多选)问题中,可以明显看出:学生对音视频剪辑、图像处理和人工智能新技术的内容十分感兴趣,最不感兴趣的是程序设计;觉得人工智能新技术、程序设计学习起来十分困难,最不困难的是office办公软件;专业中用到最多的是office办公软件、计算机软硬件基础知识和绘图。图7数据表明:随着抖音、快手等段视频软件的快速发展,学生也倾向于参与其中,以短视频或者图片的方式分享自己的生活,即使音视频剪辑和图像处理相关的技能在专业中不太会用到,学生也十分感兴趣,愿意主动进行学习;随着“工业4.0”、“中国制造2025”、“人工智能”、“无人驾驶”等概念的提出,学生们被前沿技术所吸引,并产生浓厚的兴趣,但是对其背后的底层原理产生畏难情绪,这也就导致了他们对程序设计方面的技能兴趣不高。
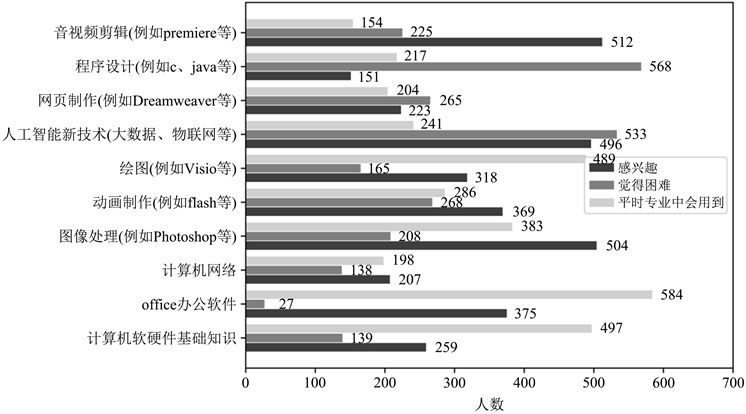
Figure 7. Questionnaire of view of computer related application technology
图7. 问卷之对计算机相关的应用技术的看法
如图8所示,在“对学校中计算机应用基础教学方式的看法”相关的问题中,提高实践能力的手段中,学生愿意通过真实、实际的项目来将理论变为自己的技能,网上学习的方式是学生最希望的。计算机技术的发展速度常令人应接不暇,知识的发展日新月异,而根据自己的兴趣在网上有选择地进行学习成为了当前最流行的方式。
4.1.1. 意图挖掘
针对问卷调查中唯一一道主观题,本文采用关键词提取的方式对学生回答的内容进行分类分析,设置不同类别的关键词进行文本内容的提取和匹配,自动生成分类结果,在文本信息中挖掘学生们对本校计算机应用基础课程的意图。
具体实现上,本文采用了NLP中最常用的中文分词组件jieba来进行关键词提取。Jieba (结巴)是百度工程师开发的一个开源库,其可以用来进行分词、关键词抽取与词频统计。本文利用其在关键词抽取方面的应用来对学生回答进行自动分类。利用jieba进行关键词抽取的算法流程图如图9所示,其中有两种不同的关键词抽取算法,分别为TextRank [8] 和TF-IDF [9]。
Figure 8. Questionnaire of views on the basic teaching methods of computer application in schools
图8. 问卷之对学校中计算机应用基础教学方式的看法
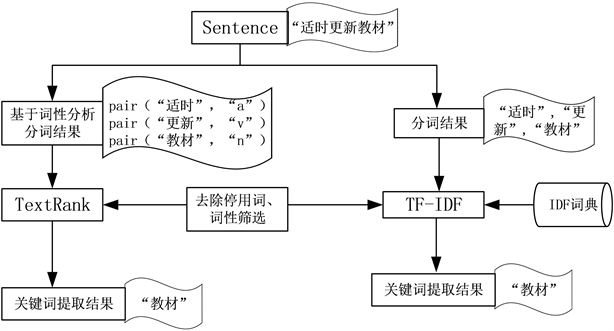
Figure 9. Keyword extraction process
图9. 关键词抽取流程
其中TF-IDF (词频–逆文本频率)是一种用以评估字词在文档中重要程度的统计方法。它的核心思想是,如果某个词在一句话中出现的频率即TF高,并且在其他句中出现的很少,则认为这个词有很好的类别区分能力。其计算公式为:
(1)
其中 与 分别由下式给出:
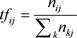 (2)
(2)
上式中分子为i词在j句中出现的次数,分母为j文档中所有字词出现的次数之和。
(3)
式中分子为语料库中的句子总数,分母为包含该词的句子数目。
TextRank是一种基于PageRank的关键词提取的算法。PageRank通过互联网中的超链接关系确定一个网页的排名,其计算公式是由一种投票的思想来设计的:如果我们计算网页A的PageRank值,那么我们需要知道哪些网页链接到A,即首先得到A的入链,然后通过入链给网页A进行投票来计算A的PR值。其公式为:
(4)
其中 为要计算PR值的网页, 为连接到 的网页,即他的入链。 为 的PR值, 为所有入链的集合, 为网页j中链接指向的网页的集合, 为其个数。d为阻尼系数,取值范围为0~1,表示从一定点指向其他任意点的概率,一般取值0.85。将上式多次迭代即可直到收敛即可得到结果。
TextRank算法基于PageRank的思想,利用投票机制对文本中重要成分进行排序。如果两个词在一个固定大小的窗口内共同出现过,则认为两个词之间存在连线。TextRank算法的得分定义为:
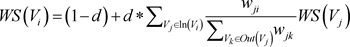 (5)
(5)
公式与PageRank的基本相同。多次迭代直至收敛,即可得到结果。
最终综合两种算法所得到的结果,将学生回答的内容分为6大类:实践、理论、软硬件更新、分专业和层次教学、实验报告、课程内容形式。统计结果如表1所示。

Table 1. Intentional excavation results
表1. 意图挖掘结果
根据表1所得到的意图挖掘结果可知:学生回答的内容中,匹配最多的是围绕着实践与课程内容的,其中与实践相关的基本都是希望能够增加一些实践的机会,可见学校在课程的设置上并没有太多与实践相关的内容;而对于课程内容方面,大部分学生认为目前设置的计算机基础课程枯燥并且过于基础,说明学校对于目前00后的计算机水平了解不足,教授重复的内容只会浪费时间,使教学的效率降低。除此之外,学校可以在开学初设置分层考试,根据不同学生的基础来分班教学,同时对于学生感兴趣的课程,可以开放选修课或者是设置线上课程,这样便可以满足大部分学生的需求。
4.1.2. 倾向性分析
除了对问卷中唯一一道的主观题进行意图挖掘,本文还采用情感分析 [10] 对该内容进行倾向性分析。情感分析主要基于情感词典和基于深度学习进行分类,但是由于主观题的内容篇幅不多,不足以放入深度学习网络模型中进行训练。因此选择情感词典的方式,并根据情感元素抽取来判断内容是消极、中立或者积极的态度。
情感元素抽取就是情感词抽取就是从文本中自动识别出情感词的方法。Tan等 [11] 提出一种基于有限状态机(Finite State Machine, FSM)的匹配方法。该方法框架图如图10所示。从图中看出,情感元素抽取过程分3个步骤。第一步:情感元素匹配,主要是将经过预处理的评论语料映射到特征词和否定副词的列表中,这些列表根据在元素评论中出现的顺序进行排序;第二步:情感元素抽取,将列表数据作为FSM的输入,根据上下文和情感词寻找特征意见(Feature-Opinion, F-O)对,并确定每对F-O对的情感极性;第三步情感元素过滤,利用规则筛选出正确的F-O对。

Figure 10. Subjective question emotion element extraction process
图10. 主观题情感元素抽取过程
本文通过情感元素抽取的方法,对649份问卷调查中的主观题进行实验,其中574份为有效回答,最终得到193条积极的回答,202条消极的回答以及179条中立的回答。积极的回答中,同学们表示对学校课程设置比较满意,并且认为老师很有耐心,教授的课程容易理解;而消极的回答中,学生则表达了“课程极度缺乏针对性和区分度”或者“上课内容十分单调”等描述;在中性的回答中,学生对课程提出了“多一些实践”、“更新软件”等建议。
4.2. 社会就业需求
为了了解社会层面中对于计算机技能的需求,本文通过爬虫的方式,最终共获得十万条招聘岗位信息。本文采用词频统计的方式,对招聘信息进行数据处理,间接挖掘出学生求职就业中需要掌握的计算机技能,为了深入地挖掘出更多信息,本文对该技能进一步统计和划分,提取技能之前的程度词,得到不同专业对不同技能的掌握程度。
4.2.1. 计算机技能挖掘
为了使招聘信息和问卷调查的受众群体相一致,我们对爬取到的信息进行了专业需求的分类,并删除了爬取结果为空的信息,各学院招聘信息统计结果如图11所示,共分成了与问卷调查中的六大学院相对应的六大类,相对应六个爬虫文件。
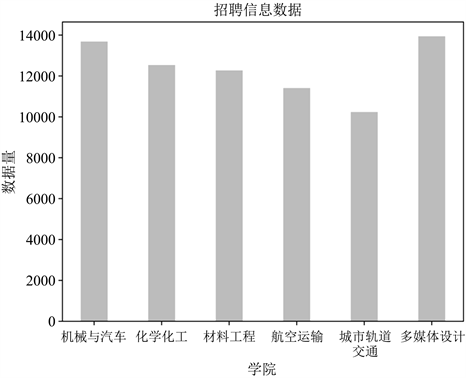
Figure 11. Recruitment information statistics of each college
图11. 各学院招聘信息统计
本文在网络爬虫过程中,利用XPath表达式匹配到的职位要求的内容十分丰富,涵盖了就业者需要具备的各项技能,为了只获得与计算机相关的技能,需要进一步对爬虫后的文本内容进行加工,因此,本文选择用正则表达式匹配出与计算机技能相关的语句,来筛选出所需要的信息。
本文采用Python编写代码,通过调用re模块实现匹配,主要使用了re.sub()和re.compile().findall()两个函数,用于匹配计算机技能相关的语句,并返回为一个列表,写入txt文本中。分别对六个爬虫文件重复该操作。由于这些内容是连贯的,中文文本之间每个汉字是连续书写的,需要特定的手段来获得其中的每个词语,为了能对计算机技能进行统计,本文选择先进行分词,再词频统计的方式。这里再次引入自然语言处理中的jieba库进行分词。
利用jieba库进行分词后,记录下每个词语在文本中出现的次数,如表2所示,列举出了六个类别中,出现频率较高的计算机技能。
Table 2. Statistical results of word frequency
表2. 词频统计结果
词频统计的结果可以发现:Office是每个岗位必备的技能,当然在问卷中学生均认为Office简单易学;除此之外对于不同的专业,有与专业相对应的软件需要掌握,而学校对于这些技能并没有开设相关的课程,说明学校的教学内容与社会就业需求尚有差距,学生仅凭学校所学的计算机知识并不能满足工作岗位的需要,若想要达到社会的要求,还需自学相关的内容。
4.2.2. 掌握程度分析
除了对招聘信息进行词频统计,为了深入挖掘社会对计算机技能的需求,本文将表2中计算机技能的掌握程度划分为精通、熟练、掌握、熟悉和了解五个级别,采用正则表达式对技能进行匹配,最终得到不同专业对不同技能的等级,由于不同专业需要掌握的计算机技能有所差距,因此本文只讨论六大类专业有所重合的部分,并进行对比,具体结果如图12所示。
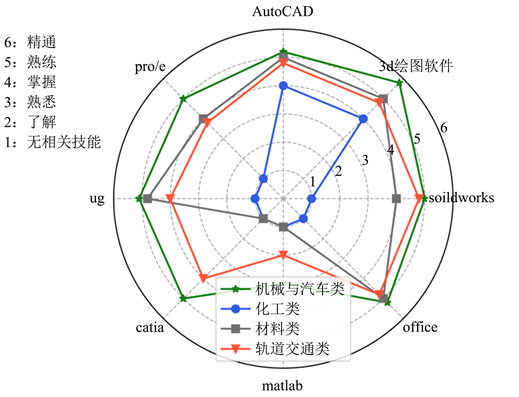
Figure 12. Computer skills
图12. 计算机技能掌握程度
从图12可以看出,Office是所有专业均需要熟练掌握的技能,而对于其他技能,掌握程度有所区别,例如3d绘图软件中,机械与汽车类要求精通,而材料类与轨道交通类要求熟练,化工类要求掌握即可;另外对于MATLAB,机械与汽车类需要熟悉,轨道交通类只需要了解。从这些结果可以看出,不同专业针对同一项计算机技能的掌握程度并不相同,针对某些技能甚至差距很大,因此学校在计算机教学的课程设置中,也应该进行划分,例如MATLAB对于机械与汽车类专业的学生来说,应该作为必修课,而对于轨道交通类展业的学生,可以设置成选修课供学生进行学习。
5. 总结
本文从数据挖掘与分析的角度出发,从学生层面和社会层面两个方面进行展开,通过对双方的数据进行处理和分析发现:随着人工智能时代的迅速发展,更多新技术涌现出来,除了学生们对计算机的兴趣逐渐广泛,社会就业中对应届生也有了更高的标准,然而,学生在学校中学习到的内容对于就业的要求来讲还远远不够。学校除了注重计算机课程中理论上的讲解,还需要加强实践和应用的比重,来提高学生对于技能的掌握程度;除此之外,由于不同学生的基础不同,学校可以设置分层考试,根据不同学生的计算机基础进行分班教学,避免教学内容与中小学重复,从而提高教学的质量和效率;另外可以对就业市场进行调研,根据现在的时代背景进行相应的调整,增加一些专业技能选修课,让学生在掌握本专业基础知识的程度上,可以根据自己的兴趣去选择不同的方向去发展。
基金项目
上海工程技术大学研究生科研创新项目(20KY0208)。
文章引用
林梦琪,曾 鑫,胡建鹏,张晓梅,李思远. 基于混合数据挖掘的大学生计算机技能需求分析
Analysis of College Students’ Computer Skills Requirements Based on Mixed Data Mining[J]. 软件工程与应用, 2021, 10(06): 779-790. https://doi.org/10.12677/SEA.2021.106082
参考文献
- 1. 于莉. 互联网+ 环境下的高校计算机专业课堂教改现状及建议[J]. 计算机教育, 2020(5): 86-88.
- 2. 黄凤英, 林龙镔. 信息化背景下的大学计算机基础教学改革探索[J]. 物联网技术, 2020, 10(11): 115-117.
- 3. 刘静, 王剑, 邢胜龙. 高校就业信息数据统计智能数据挖掘技术的应用[J]. 电子技术与软件工程, 2017(19): 150.
- 4. 周翠红. 数据挖掘中关联规则的研究及在高校教学质量评估中的应用[D]: [硕士学位论文]. 长沙: 中南大学, 2007.
- 5. 王硕鹏. 基于数据挖掘的毕业生就业信息管理决策模型研究[J]. 东北电力大学学报, 2019(5): 86-90.
- 6. 李继巧. 应用导向的高校计算机课程数据挖掘[D]: [硕士学位论文]. 广州: 广州大学, 2018.
- 7. Kouzis-Loukas, D. 精通Python爬虫框架Scrapy[M]. 北京: 人民邮电出版社, 2018: 10-22.
- 8. 冯勇, 屈渤浩, 徐红艳, 王嵘冰, 张永刚. 融合TF-IDF和LDA的中文FastText短文本分类方法[J]. 应用科学学报, 2019, 37(3), 378-388.
- 9. 李娜娜, 刘培玉, 刘文锋, 刘伟童. 基于TextRank的自动摘要优化算法[J]. 计算机应用研究, 2019, 36(4): 1045-1050.
- 10. 祝永志, 荆静. 基于Python的简单文本情感分析[J]. 通信技术, 2019(7): 1612-1619.
- 11. Tang, D., Wei, F., Qin, B., Zhou, M. and Liu, T. (2014) Building Large-Scale Twitter-Specific Sentiment Lexicon: A Representation Learning Approach. In: COLING 2014—25th International Conference on Computational Linguistics, Proceedings of COLING 2014: Technical Papers, (Association for Computational Linguistics, ACL Anthology), 172-182.