Computer Science and Application
Vol.07 No.12(2017), Article ID:23214,8
pages
10.12677/CSA.2017.712142
Analysis on Research Status of Web Service Discovery
Lijun Duan
School of Computer, Hubei University of Education, Wuhan Hubei

Received: Dec. 5th, 2017; accepted: Dec. 19th, 2017; published: Dec. 28th, 2017

ABSTRACT
Web service discovery is one of the main problems that need to be solved in Web service application, and is also a precondition for realizing service sharing and reuse. In this paper, we systematically analyzed the research status of Web Service discovery. We introduced the main forms of Web services and the main contents of Web service discovery, and made the classification for the existing methods. Based on the analysis of the principle and application of typical methods, we summarized the characteristics of each category and pointed out the problems in future research.
Keywords:Web Service, Service Discovery, Method, Analysis
Web服务发现研究现状分析
段丽君
湖北第二师范学院,计算机学院,湖北 武汉
收稿日期:2017年12月5日;录用日期:2017年12月19日;发布日期:2017年12月28日

摘 要
Web服务发现是Web服务应用中需要解决的主要问题之一,也是实现服务共享和重用的前提条件。本文对Web服务发现的研究现状进行了系统的分析。介绍了Web服务的主要形式和Web服务发现的主要内容,将现有方法进行了分类,通过分析其中典型方法的原理和应用情况,总结了每类方法的特点,指出了未来研究中面临的问题。
关键词 :Web服务,服务发现,方法,分析

Copyright © 2017 by author and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
Web服务是面向服务架构(Service-Oriented Architecture, SOA)和面向服务计算(Service Oriented Computing, SOC)等技术发展的有效实现。W3C将Web服务定义为一个由URI来标识的软件系统,它采用XML语言来定义其接口和描述其绑定。它的定义可以被其他软件系统所发现,这些系统通过Web服务自身所定义的方式与其进行交互,在这个交互过程中,两方通常使用互联网协议来传递基于XML的消息 [1] 。从Web服务的定义可以看出,只需要定义Web服务的接口就能实现其彼此间的互操作,而与它们具体的实现语言和内部数据结构无关。由于Web服务相比普通的应用和网页而言具有明显的优点,能有效推动应用资源的共享、复用和集成,所以越来越多的应用以Web服务的形式发布到网络上。但随着Web服务应用领域的普及,网络上的Web服务数量以指数级别增长,如何快速准确地在海量的服务资源中找到所需的特定Web服务就自然成为了Web服务技术研究中必须解决的问题之一,这就是通常说的Web服务发现(Web Service Discovery)问题。Web服务发现与传统的信息检索方法有较多相似之处,但它具有更高的技术复杂度,涉及的内容也更多,结果不确定性也更大。一般认为,Web服务发现是Web服务研究领域的一个非常重要的组成部分,更是实现服务共享和重用的前提条件 [2] 。
本文阐述了Web服务的主要形式和Web服务发现的主要内容,概括了近年来Web服务发现的研究现状,对典型的Web服务发现方法进行分析,旨在帮助学习研究人员进一步了解Web服务发现的研究进展,为后续研究工作的开展做好铺垫。
2. 服务发现概述
2.1. Web服务的形式
根据SOA架构设计规范,Web服务的体系架构可描述为图1所示。整个架构由服务提供者、服务消费者和服务注册中心三个部分组成。其中,服务提供者主要使用WSDL (Web Services Description Language)等语言来描述具体服务,并负责将Web服务发布给服务注册中心,供服务消费者调用。服务注册中心则使用UDDI (Universal Description, Discovery and Integration)等机制来管理和注册可用的Web服务描述信息,同时负责接收服务消费者的查询请求,检索到合适的候选服务后,服务注册中心建立起服务请求者和服务提供者之间的供求关系。服务消费者作为web服务的使用者向服务注册中心提出应用请求,在服务注册中心返还其检索结果后,通过SOAP (Simple Object Access Protocol)等方式与服务提供者进行通信,完成最终的服务调用。
2.2. 服务发现的主要内容
从Web服务的体系架构图可以看出,服务发现的主要任务就是将服务消费者提出的服务查询与服务提供者发布的服务描述进行对比,从而找出最合适的服务对象。具体来说,当服务消费者提出查询请求
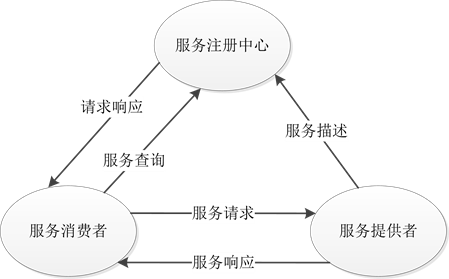
Figure 1. Architecture diagram of Web service
图1. Web服务体系架构图
(该请求可能是关于服务名称、服务的输入输出参数、服务的功能、服务QoS等方面的一个或者多个具体需求)后,依据具体算法对服务注册中心中存储的服务描述信息进行一一比较,此过程一般称之为服务匹配,然后按照一定的标准,将匹配后符合条件的服务列表返回给服务消费者,服务消费者从中做出选择后即可从服务提供者调用相关服务。
从此过程可得知,服务匹配是服务发现的关键,服务匹配依据的算法性能决定了服务发现的结果性能,服务匹配的对象和参数也会影响最终的结果。而这两个方面正是Web服务发现研究工作的两个主要切入点和研究焦点。
3. 典型Web服务发现方法
3.1. 基于规则推理的服务发现
由于服务注册中心只能支持基于关键字的Web服务检索,这种方式的检索条件过于简单,多数情况下无法准确表达用户的需求,因此其检索效率一般较低,检索结果精度也比较差。为解决此类问题,许多方法通过构建规则或者逻辑来描述服务请求,使其能更清晰准确地刻画出服务请求的具体内容,再基于这些规则或者逻辑来实现服务发现过程的自动推理。文献 [3] 通过语义规则来描述服务请求,基于本体来分解服务发布的描述信息,并提出了一个基于语义规则驱动的Web服务发现方法。该方法通过在语义规则上设立影响因子来调节和度量最终的服务匹配精度,判定最终的匹配结果。文献 [4] 基于本体和计算逻辑提出了一个推理引擎来解决服务发现问题。该推理引擎推理主要面向服务发布与服务请求之间的行为接口来建立推理规则和计划。为降低服务发现的复杂度,文献 [5] 在服务匹配之前增加了一个预处理环节,该环节中通过编程设定规则,在候选服务发布集内首先滤除无关的服务,从而缩小服务发现的范围,提高服务发现的准确度。为提高服务发现效率,文献 [6] 区别对待服务请求和服务描述,采用语义规则来刻画服务请求,对服务发布描述进行子类扩展,通过验证个体与集合关系来不断缩小服务匹配范围,提出了一种基于语义规则的分阶段语义Web服务发现方法。其核心思想是基于OWL-S本体规范给ServiceProfile的ServiceParameter属性扩展增加一个规则子类:Rule,如图2所示。
此类方法的性能主要取决于其规则与推理逻辑,理想情况下此类方法能够有效实现服务发现过程的自动化,取得比较满意的服务发现精度。但如何设计出有效的规则和合理的逻辑推理往往具有较高的难度,而且这些规则和逻辑一般比较复杂,在服务发现过程中的执行往往需要额外增加时间和计算方面的费用开销,致使方法的性能不能达到预期。
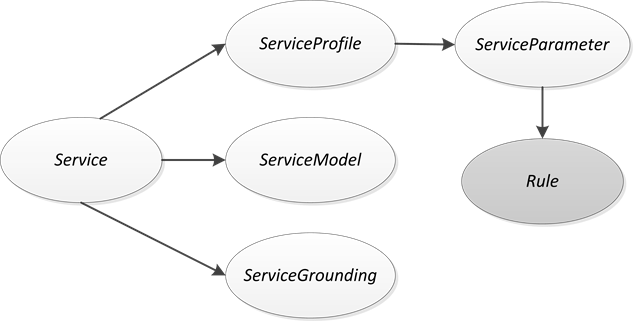
Figure 2. Extended OWL-S structure diagram
图2. 扩展后的OWL-S结构图
3.2. 基于增强语义的服务发现
相对于语法级别的服务发现,采用语义技术的服务发现方法能够提升服务发现过程中的自动推理能力,其结果的准确性普遍较高,因此许多方法通过增强Web服务以及服务请求中的语义信息来提高服务发现的性能。这类方法通常以本体为支撑技术,通过语义标注、语义扩展等典型手段,增加服务发现两端的语义信息来凸显服务发布方和服务请求方的功能属性,使两者的表述针对性更强,语义特征更加明显,从而提高服务匹配的精度。文献 [7] 中提出了一种基于功能语义标注的Web服务发现方法。该方法通过对领域本体进行扩展,定义了一个Web服务的领域功能语义模型,来实现Web服务描述的语义扩展;其在服务发现过程中,先对服务的功能进行语义相似度匹配,再对符合条件的服务再进行接口匹配。该方法还特别设计了一个功能语义标注算法来对对WSDL进行语义标注,其服务发现过程如图3所示。文献 [8] 则给出了一个基于语义自动标注的服务发现方法,其核心思想是综合利用多层本体概念以及一个改进的服务向量模型来标注和聚类服务,从而生产一个类似于UDDI的Web服务语义分类目录。该方法主要利用其定义的潜在语义索引来增强服务请求的语义,首先根据服务功能参数对语义分类目录中的Web服务进行初步过滤,再计算出对应的语义相似度进行匹配,最后得到一个排序的Web服务候选列表。文献 [9] 针对现有的Web服务体系结构普遍存在的不可扩展、语义信息不足等问题,设计了一种可扩展语义的Web服务体系结构,该方法中给出了相应的服务发布与服务删除算法、服务体系结构的动态调整算法,以达到提高系统的存储资源利用率和服务发现效率的目的。
此类方法一般将研究重点放在服务及请求的描述上,其方法原理相对简单,可操作性相对较强。但此类方法的性能依赖于本体的优劣,而本体的构建标准常常不统一,即使对同一领域建模,不同的本体其性能差别也会很大,而且建立和维护本体库的开销也比较大,因此,此类方法的实际应用效果往往达不到预期设计。
3.3. 基于服务质量的服务发现
前述的两类方法在其服务匹配中考虑的匹配对象几乎都是服务的输入、输出、前提条件和服务效果等参数,这些参数从本质上来说都属于候选服务的功能属性。服务发现过程中若只以服务的功能属性作为匹配对象,结果中往往会出现一批功能相似的候选服务,由于缺少功能属性外的参数依据,一般难以
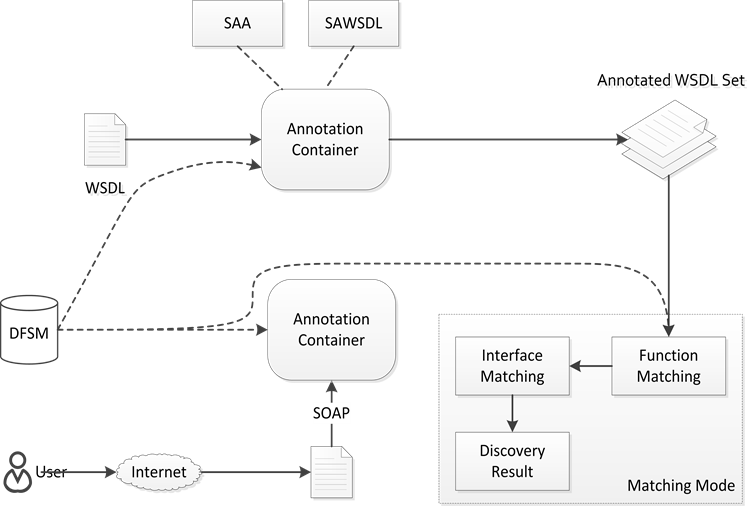
Figure 3. Service discovery process diagram
图3. 服务发现过程图
从中选择出最佳的服务。因此,在功能属性之外考虑非功能属性来实现Web服务发现就成为了一种必然的选择,其中基于服务质量(QoS)的服务发现又是其中的研究重点,它成为发现和选择候选服务的一个重要依据,用以更好地满足用户的需求。文献 [10] 设计并实现了一种用于支持非功能性web服务的QOS方法。该方法基于OWL-S扩展,并通过添加获取非功能参数所需的信息,来构建了一个QoS度量模型。实验结果表明,其提出的方法能提高服务发现的准确性。在文献 [11] 中,为找到最好的Web服务,作者提出了一个形式化的客户端请求消息结构和服务代理架构。首先,代理架构从客户端获取带有QoS要求的Web服务需求信息,然后它检索出功能相似的Web服务。再基于那些被代理所确认的QoS属性,代理将根据一个算法机制来对候选服务进行排名。类似的,文献 [12] 提出了一个两阶段的Web服务发现框架。第一个阶段是一种功能匹配方法,它评估给定的Web服务集之间的相似性,并根据用户的功能需求提供相关的服务。在此之后,基于从第一个阶段产生的相关服务的用户上下文和非功能性需求,计算二者的上下文信息之间的相似度。根据计算的相似度,返回一组同时能满足用户功能需求和非功能需求的服务。文献 [13] 设计了一种支持服务QoS差异度控制的Web服务发现模型,如图4所示。在该模型中,通过增加第三方监控Interceptor来保证数据的真实性,同时通过在服务使用者端和QoS认证中心处增加QoS属性本地规约验证机来控制需求端和发布端两者间对QoS的差异度,以此来达到为用户提供更优Web服务的目的。类似的研究也比较多 [14] [15] [16] ,重点都利用了QoS参数来改进服务发现的效果。
相对于前两类方法,基于服务质量的服务发现方法将研究重点置于服务匹配后的服务排序或者服务选择阶段,其服务匹配阶段的算法原理与前两者差别不大。因此,此类方法的服务发现精度往往高于前两者,但其计算开销和计算复杂度也比前两者要大。
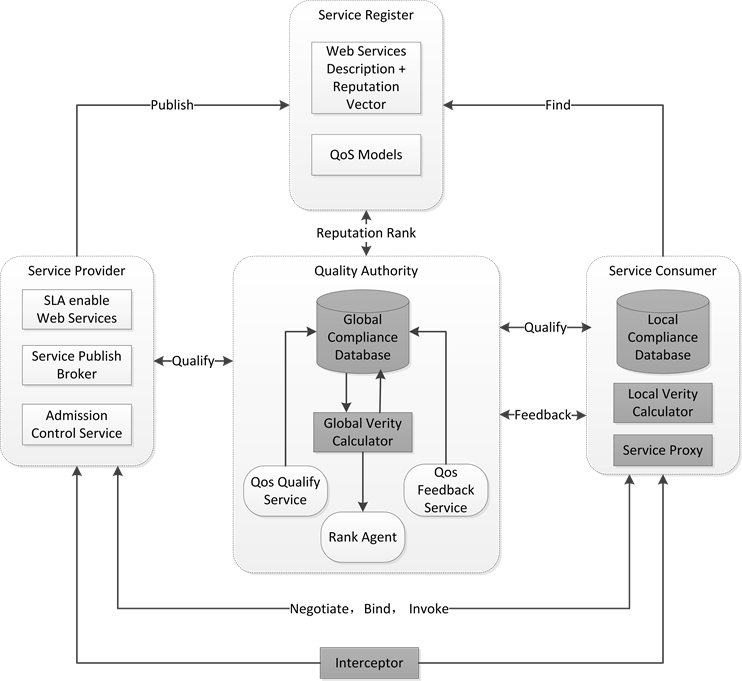
Figure 4. Web service discovery model supporting service QoS variance control
图4. 支持服务QoS差异度控制的Web服务发现模型
3.4. 基于图的服务发现
虽然在服务发现过程中增加语义信息会提高服务发现过程的自动性和结果的准确性,但由于大部分语义模型和方法只能适用于某些特定领域,应用的难度和复杂度都很高,而且这些方法通常在匹配过程中对匹配条件要求过于严格,致使结果的查全率往往偏低。为解决此问题,偏重于服务接口逻辑关系或服务参数间依赖关系的方法逐渐引起了重视,这类方法通常利用二分图等作为主要工具来分析问题。文献 [17] 在服务发现中引入聚类与二分图匹配技术,采用空间向量模型表示服务,设计专门的聚类算法对服务进行聚类,其服务发现过程中借鉴带权二分图最优匹配思想对服务的功能属性进行匹配。其二分图的权值根据概念间语义相似度计算得出。文中还讨论了如何构建满足最优匹配条件的带权二分图问题并给出了其解决方案。文献 [18] 为解决传统基于二分图匹配的服务发现算法查全率和查准率不高的问题,提出了一种扩展的二分图匹配的Web服务自动发现算法,利用松弛函数值扩展等价子图来寻找新的增广路径。文献 [19] 在计算服务功能属性的相似度时,考虑了输入输出参数之间的依赖关系,将服务的输入输出参数按照其依赖关系进行配对,同时用有向树表示对应的服务过程模型,给出了有向图的相似度计算方法,匹配过程中通过对树同构的判断和有向树中结点及边的相似度计算得到对应服务过程之间的相似度。文中设计了一个基于功能和过程计算的服务发现框架,如图5所示。此外,还有另外一些文献也提出了类似的方法 [20] [21] [22] 。
基于图的服务发现方法在匹配过程中对匹配条件要求较为宽松,方法的复杂度相对不高,相对前三种方法而言易于应用,能够达到较为理想的召回率和准确率,在服务发现效率方面的表现也不错。但此类方法在考虑服务质量QoS方面仍存在着不足。
4. 总结
从Web服务发现研究的趋势来看,研究方法的技术综合性越来越明显,特别是随着推荐算法和人工智能技术的发展,Web服务发现方法在查全率、查准率、检索效率和个性化需求方面的表现取得了较大的进展。但在大数据技术的驱动和影响下,Web服务发现方法面临的对象规模和算法复杂度都有层次性的提升,这也是未来Web服务发现研究中必须要考虑和解决的问题。

Figure 5. Service discovery framework based on function and process calculation
图5. 基于功能和过程计算的服务发现框架
基金项目
本文受到湖北省教育厅科学技术研究计划项目(B2015017)资助。
文章引用
段丽君. Web服务发现研究现状分析
Analysis on Research Status of Web Service Discovery[J]. 计算机科学与应用, 2017, 07(12): 1270-1277. http://dx.doi.org/10.12677/CSA.2017.712142
参考文献 (References)
- 1. W3C (2017) Web Services Architecture Requirements. http://www.w3.org/TR/wsa-reqs/
- 2. 张杨. 语义Web服务发现关键技术研究[D]: [博士学位论文]. 广州: 华南理工大学, 2014.
- 3. 王海, 范琳, 李增智. 基于语义规则的Web服务发现方法[J]. 计算机工程与应用, 2010, 46(28): 80-84.
- 4. Alberti, M., Cattafi, M., Chesani, F., et al. (2011) A Computational Logic Application Framework for Service Discovery and Contracting. International Journal of Web Services Research, 8, 1-25. https://doi.org/10.4018/JWSR.2011070101
- 5. Garcia, J.M., Ruiz, D. and Ruiz-Cortes, A. (2012) Improving Semantic Web Services Discovery Using SPARQL-Based Repository Filtering. Journal of Web Semantics, 17, 12-24. https://doi.org/10.1016/j.websem.2012.07.002
- 6. 田浩, 樊红. 基于语义规则的分阶段语义Web服务发现方法[J]. 计算机工程与设计, 2012, 33(5): 1806-1810.
- 7. 文俊浩, 涂丽云, 江卓, 等. 基于功能语义标注的Web服务发现方法[J]. 计算机应用研究, 2011(7): 2546-2549.
- 8. Paliwal, A.V., Shafiq, B., Vaidya, J., et al. (2012) Semantics-Based Automated Service Discovery. IEEE Transactions on Services Computing, 5, 260-275. https://doi.org/10.1109/TSC.2011.19
- 9. 牛小星, 王智学, 禹明刚. 可扩展语义Web服务体系结构设计与服务发现[J]. 系统仿真学报, 2016, 28(11): 2841- 2851.
- 10. Farzi, P., Akbari R. and Bushehrian, O. (2017) Improving Semantic Web Service Discovery Method Based on QoS Ontology. Proceeding of 2nd Conference on Swarm Intelligence and Evolutionary Computation, Kerman, 72-76. https://doi.org/10.1109/CSIEC.2017.7940175
- 11. Rangarajan, S. and Chandar, R. (2017) QoS-Based Architecture for Discovery and Selection of suitable Web Services Using Non-functional properties. EAI Endorsed Transactions on Scalable Information Systems, 4.
- 12. Samir, S., Sarhan, A., Algergawy, A. (2017) Context-Based Web Service Discovery Framework with QoS Considerations. Proceeding of 11th International Conference on Research Challenges in Information Science, Brighton, 146-155.
- 13. 何小霞, 谭良. 一种支持服务QoS差异度控制的Web服务发现模型[J]. 计算机科学, 2014, 41(8): 202-208.
- 14. 孙天昊, 刘洪辉, 马辉, 朱庆生. 基于并发协商的Web服务发现模型[J]. 北京理工大学学报, 2015, 35(9): 980- 984.
- 15. 江晓苏, 魏延, 邱炳发. QoS感知的Web服务个性化推荐[J]. 计算机技术与发展, 2015, 25(12): 85-90.
- 16. 王丹丹. 云计算中Web服务发现与组合技术研究[D]: [博士学位论文]. 北京: 北京科技大学, 2017.
- 17. 刘一松, 朱丹. 基于聚类与二分图匹配的语义Web服务发现[J]. 计算机工程, 2016, 42(2): 157-163.
- 18. 刘冰月, 张永. 基于松弛函数扩展的二分图匹配服务发现算法[J]. 计算机工程与设计, 2015, 36(9): 2427-2431.
- 19. 夏阳, 赵强, 黄潇. 一种基于图匹配的语义Web服务发现方法[J]. 小型微型计算机系统, 2013, 34(12): 2734- 2738.
- 20. 张进, 傅秀芬. 利用匹配关系图的Web服务发现方法[J]. 计算机工程与设计, 2015, 36(10): 2738-2742, 2774.
- 21. 王斌斌. 基于图优化的协同过滤Web服务推荐模型[D]: [硕士学位论文]. 南京: 南京大学, 2015.
- 22. 吴芳, 朱尚明. 基于功能划分图的Web服务组合规划和最优选择[J]. 计算机应用与软件, 2016, 33(9): 10-14, 19.