Advances in Applied Mathematics
Vol.
08
No.
12
(
2019
), Article ID:
33457
,
9
pages
10.12677/AAM.2019.812231
The Application of Fuzzy Mathematical Model in the Evaluation of Dual Selection Factors
Cheng Chen*, Zirong Liu
College of Science, North China University of Technology, Beijing

Received: Nov. 21st, 2019; accepted: Dec. 9th, 2019; published: Dec. 16th, 2019

ABSTRACT
In this paper, the single-factor evaluation method in fuzzy mathematics and mathematical models including fuzzy comprehensive evaluation decision model, near rule of fuzzy mode identification and AHP model are used to solve the problem of ranking the selection factors that affect candidates and recruiters in the process of career double selection.
Keywords:Single-Factor Evaluation, Fuzzy Comprehensive Evaluation Decision, Analytic Hierarchy Process

模糊数学模型在职业双选因素评价中的应用
陈呈*,刘紫荣
北方工业大学理学院,北京

收稿日期:2019年11月21日;录用日期:2019年12月9日;发布日期:2019年12月16日

摘 要
本文采用模糊数学中的单因素评价方法、模糊综合评价决策模型、模糊模式识别择近原则、层次分析模型等数学模型,解决了职业双重选择过程中影响应聘者和招聘人员选择因素的排序问题。
关键词 :单因素评价,模糊综合决策,层次分析,职业双选

Copyright © 2019 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
招聘单位选择录用应届毕业生时,一般会考量学生学历、态度、专业测评、实践经历、表达能力等因素,对应聘者进行打分并择优录取。本文以某单位以往的录用数据为例,使用单因素分析法,排出影响该单位招聘人员决策的因素次序。为求职者做出一定指导。同时,也根据求职学生对某4个单位的福利待遇、工作条件、劳动强度、晋升机会、深造机会等方面的评价打分,根据打分,采用层次分析法排出这些方面的对求职者做选择的影响程度的大小,从而得出求职者选择工作单位时的倾向程度。
2. 学生因素对招聘单位选择录用的影响
2.1. 建立单因素分析和模糊综合评价模型
根据已知招聘人员对往届应聘人员的各项评分数据如表1,我们需要分析并且确定合理的因素权重,通过对表1中五个因素的权重比较,得到各个因素对应聘人员找工作的影响程度大小排序。
步骤一:我们需要把A/B/C所对应的分数段进行赋值,其目的是研究数据的基本特点,将问题适当量化分析。
步骤二:再将数据分为具有积极结果的“应聘成功组”和具有消极结果的“应聘失败组”,对数据进行分类处理。
步骤三:单因素评价,得到影响应聘结果的评价票数映射。
步骤四:对“应聘成功组”求得无主观干预且仅以结果为导向的各个因素积极权重,对“应聘失败组”求得对应消极权重。
步骤五:建立模糊综合评价模型,并通过该模型得到上述过程中的综合权重分析,以此做出合理排序。在使用模糊评价模型时,需要分别将成功失败这两种积极结果和消极结果都考虑在内,于是要将两种结果下的数据分别作出单因素评价。消极结果与积极结果起相反作用,因此“失败组”得到的权重取倒数处理。解决问题的流程如图1。

Figure 1. Analysis and evaluation process
图1. 分析评价流程图

Table 1. Scores of candidates
表1. 应聘人员的各项评分
2.2. 对评分进行合理赋值
设主 权重均匀分配,已知 ,这里的 是指权重。故 ;由此可以得到赋值权重矩阵:
(1)
2.3. 建立单因素评价矩阵
1) 确定评判因素:
。
2) 确定判断集。
将各个因素评分分为 。
3) 根据已有数据,对因素集中的每一个因素进行单因素评判,各个因素所得票数结果如下表:
Table 2. Evaluation result of candidate successful personnel
表2. 应聘成功人员评价结果
Table 3. Evaluation results for candidates who have failed to apply
表3. 应聘失败人员的评价结果
4) 建立模糊映射:
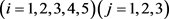
 其中
其中 是对
是对 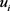 评价为
评价为 的票数,故得到下面的矩阵:
的票数,故得到下面的矩阵: (2)
(2)
 (3)
(3)
得到积极(消极)作用的权重分配如下:
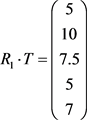 (4)
(4)
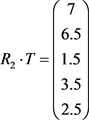 (5)
(5)
表3应聘人员均未能成功,所以并不能起到积极作用,故矩阵内元素取倒数,得到积极作用的权重分配如下:
 (6)
(6)
2.4. 模糊综合评价
将消极权重与积极权重根据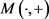 公式
公式 合成后得到:
合成后得到:
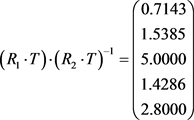 (7)
(7)
所得矩阵对应模糊集U中元素的权重,因此可得各因素对应聘人员找工作的影响程度从大到小排序为: 专业测评>表达能力>态度>实践经历>学历。经实际验证,所得大小排序与招聘单位要求相符。
3. 招聘单位因素对学生选择的影响
我们根据表4和表5数据,建立一个合理的评价排序模型,将福利待遇、工作条件、劳动强度、晋升机会、深造机会,这五种应聘人员用来评价用人单位的因素按照影响程度大小进行排序。在单因素评价的基础上,采用模糊优先关系排序,模糊模式识别的择近原则,进行模糊综合评价。将应聘人员对4个招聘单位的选择按照可能性大小进行排序。流程见图2。

Figure 2. Construction of analytic hierarchy process
图2. 构建层次分析模型流程
Table 4. The basic situation of the recruitment unit
表4. 招聘单位的基本情况
Table 5. The average score of each factor of the recruitment unit
表5. 招聘单位各因素平均得分
3.1. 简单推理比较
观察表4中的数据发现,工作条件与晋升机会的评价等级完全一致时,两者最终得到的平均分却不相同,因素平均分之比为7:8,因此我们分析而得,是各个因素在加权平均时,人为认定的权重不同,造成了这样的结果。需要注意劳动强度的评分高低与实际积极影响效果相反,即评分越高越不利于被应聘者选择。显而易见,同样评级下,晋升机会得分高于工作条件,说明晋升机会的认定权重大于工作条件。这属于人为主管干预权重的情况。
因此通过比较推理可得,晋升机会权重大于工作条件。
3.2. 单因素评价法
1) 得到单因素矩阵。
根据表5设矩阵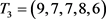 ,进行单因素分析可得因素与评价等级的矩阵
,进行单因素分析可得因素与评价等级的矩阵
 (8)
(8)
2) 确立模糊优先关系。
论域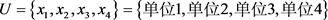 ,
, 表示
表示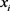 与
与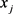 相比较时,
相比较时, 对于U上模糊集A比
对于U上模糊集A比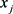 对于A的优越程度,或称
对于A的优越程度,或称 对
对 的优先选择比。
的优先选择比。
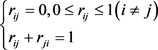
即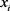 与
与 比较时,无优越记
比较时,无优越记 ,
, 与
与 相比较时若
相比较时若 比
比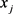 有长处,则
有长处,则 ,反之
,反之 ,
, 与
与 不分优劣则
不分优劣则 。
。
可以得到模糊优先关系矩阵
 (9)
(9)
通过模糊优先关系,可以设立评级赋值矩阵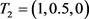
 (10)
(10)
矩阵(10)中元素与矩阵 中元素一一对应,因此,实际权重可以采用对应元素比的形式求得。所求得的值可以衡量认定的权重大小。求得向量:
中元素一一对应,因此,实际权重可以采用对应元素比的形式求得。所求得的值可以衡量认定的权重大小。求得向量: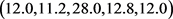 。
。
据此可以明显得到权重排序,劳动强度最大。然而其他四项因素差距不大,不能显著确认权重大小。所以模糊模式识别的择近原则。此时我们已经得到权重大小:劳动强度>晋升机会>工作条件。
3.3. 模糊模式识别
现在根据模糊模式识别的择近原则 [1] 评价福利待遇,工作条件,晋升机会,深造机会。由格贴近度公式 计算可得:
计算可得:

福利待遇和工作条件、晋升机会最接近,和深造机会较远。因为晋升机会权重大于工作条件,所以次序应为:晋升机会>福利待遇>工作条件>深造机会。
综上可得,招聘单位对应聘者最有影响力的几个因素排序为:劳动强度>晋升机会>福利待遇>工作条件>深造机会。
3.4. 层次分析模型的建立
3.4.1. 建立层次结构图
在建立层次分析模型前,容易建立层次结构图如图3。
3.4.2. 构造判断矩阵
根据表6所确立的权重,构造准则层相对于目标层的重要性判断矩阵如下:
Table 6. Reference
表6. 权重参考 [1]
 (11)
(11)
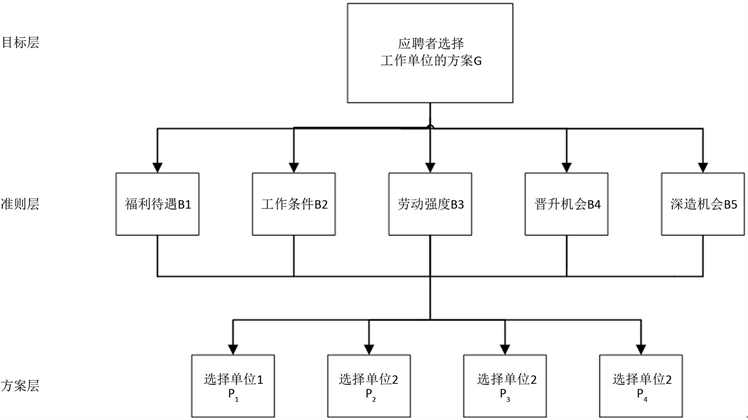
Figure 3. Schematic diagram of the hierarchy
图3. 层次结构示意图
方案层中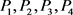 相对于准则层的重要性判断矩阵
相对于准则层的重要性判断矩阵

3.4.3. 层次单排序及其一致性检验
构造判断矩阵G之后,求出判断矩阵的最大特征值 ,再利用对应的特征方程
,再利用对应的特征方程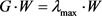 解出特征向量W,将W归一化,即为同一层次的各因素相对于上一层中某一因素的重要性权重。用来衡量判断矩阵不一致程度的数量指标称为一致性净值,记为C,定义为
解出特征向量W,将W归一化,即为同一层次的各因素相对于上一层中某一因素的重要性权重。用来衡量判断矩阵不一致程度的数量指标称为一致性净值,记为C,定义为 随机一致性指标
随机一致性指标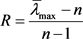
其中 为多个n阶随机正互反矩阵最大特征值的平均值。当随机一致性比例
为多个n阶随机正互反矩阵最大特征值的平均值。当随机一致性比例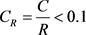 时,A的不一致性仍可接受,否则必须调整判断矩阵 [2]。
时,A的不一致性仍可接受,否则必须调整判断矩阵 [2]。
我们求得判断矩阵G的特征向量归一化后为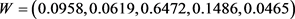 ,
,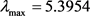 ,一致性指标
,一致性指标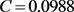 ,随机一致性比例
,随机一致性比例 。
。
对判断矩阵 可得
可得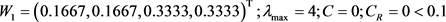 。
。
对判断矩阵 可得
可得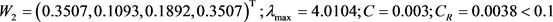 。
。
对判断矩阵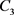 可得
可得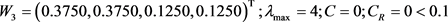 。
。
对判断矩阵 可得
可得 。
。
对判断矩阵 可得
可得 。
。
3.4.4. 层次总排序及其一致性检验
层次总排序为 。一致性检验
。一致性检验 。所以,最终单位1、2、3、4所占权重分别为0.3163、0.3232、0.1632和 0.1972。
。所以,最终单位1、2、3、4所占权重分别为0.3163、0.3232、0.1632和 0.1972。
根据权重排序可得求职者针对四个单位做出选择的可能性大小顺序为单位2>单位1>单位4>单位3。
4. 结论
根据表1、表4和表5这些已知数据可得,招聘单位在录用求职者时,最看重求职者的专业测评,其次顺序为表达能力、态度、实践经历和学历。求职者在选择单位时,最在意工作岗位的劳动强度,其次顺序为晋升机会,福利待遇,工作条件和深造机会。求职者针对已知四个单位做出选择的可能性大小顺序为单位2、单位1、单位4、单位3。
基金项目
2019年北方工业大学学生科技活动。
文章引用
陈 呈,刘紫荣. 模糊数学模型在职业双选因素评价中的应用
The Application of Fuzzy Mathematical Model in the Evaluation of Dual Selection Factors[J]. 应用数学进展, 2019, 08(12): 2006-2014. https://doi.org/10.12677/AAM.2019.812231
参考文献
- 1. 谢季坚, 刘承平. 模糊数学方法及其应用[M]. 武汉: 华中科技大学出版社, 2012.
- 2. 陈水利, 李敬功. 模糊集理论及其应用[M]. 北京: 科学出版社, 2009.