Operations Research and Fuzziology
Vol.
13
No.
06
(
2023
), Article ID:
78383
,
16
pages
10.12677/ORF.2023.136738
抽样惩罚下多人雪堆博弈模型的合作演化
周文鹏,丘小玲*
贵州大学数学与统计学院,贵州 贵阳
收稿日期:2023年10月7日;录用日期:2023年12月21日;发布日期:2023年12月29日

摘要
演化博弈中,惩罚已被证明是促进合作的关键机制,但其实施的有效性一直处于争论之中。在本文中,我们将抽样惩罚引入多人雪堆博弈模型中,基于愿景驱动规则,根据马尔科夫链的状态方程,推导出平稳概率分布,进而得出平均丰度、平均惩罚概率、平均惩罚成本的直观表达式,并且具体分析了它们受三个参数(惩罚强度、惩罚阈值、样本大小)的影响,同时结合具体案例研究了参数变化如何影响策略行为。研究结果表明,当惩罚强度相当大时,在低惩罚阈值和小样本情况下,合作水平可以得到有效提高。为了确定实施抽样惩罚的最优条件,我们观察惩罚概率和惩罚成本,我们研究发现,在一定的惩罚强度下,采用较低的惩罚阈值更有利于实施抽样惩罚,此时惩罚成本较低。
关键词
愿景驱动规则,雪堆博弈,抽样惩罚,合作

Cooperative Evolution of Multi-Player Snowdrift Game Model under Sampling Punishment
Wenpeng Zhou, Xiaoling Qiu*
School of Mathematics and Statistics, Guizhou University, Guiyang Guizhou
Received: Oct. 7th, 2023; accepted: Dec. 21st, 2023; published: Dec. 29th, 2023

ABSTRACT
Punishment has been proved to be a key mechanism to promote cooperation in evolutionary games, but the effectiveness of its implementation has been debated. In this paper, we introduce sampling punishment into the multi-player snowdrift game model. Based on the aspiration driven rule, we deduce the stationary probability distribution according to the state equation of Markov chain, and then get the intuitive expression of average abundance, average penalty probability and average penalty cost. Moreover, we analyze the influence of these three parameters (penalty intensity, penalty threshold and sample size). At the same time, how the parameter changes affect the policy behavior is studied with a case study. The results show that when the punishment intensity is quite large, the cooperation level can be effectively improved at low penalty thresholds and small sample sizes. In order to determine the optimal conditions for implementing sampling punishment, we observe the penalty probability and penalty cost. Our research finds that under a certain penalty intensity, a lower penalty threshold is more conducive to implementing sampling punishment, and the penalty cost is lower.
Keywords:Aspiration Driven Rule, Snowdrift Game, Sampling Punishment, Cooperation

Copyright © 2023 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
在自然界和人类社会中,合作无处不在。在竞争激烈的世界里,合作是一个难题。合作行为虽然有利于社会利益,但在一定程度上损害了个体利益,从而导致了合作的社会困境 [1] [2] 。演化博弈论为研究相互作用的个体之间的合作提供了一个强有力的工具,其中,两人博弈如囚徒困境和雪堆博弈受到了广泛的关注 [3] [4] 。由于实际上很难测量收益,因此雪堆博弈通常被认为是描述囚徒困境的良好且现实的替代方案。博弈不仅限于二元博弈,更多表现为多人博弈,为此发展出多人雪堆博弈 [5] 。合作机制是什么,如何促进合作一直是博弈论研究的焦点。迄今为止,关于合作行为的进化机制已经被提出了许多理论,如声誉 [6] ,奖励 [7] ,惩罚 [8] 和网络互惠 [9] 等。
其中,惩罚已被证明是促进合作的有效措施,在理论和实验上越来越受到关注。通过将其应用至演化博弈论中,可以有效减少搭便车者的收益,从而促进合作的演化。Xu等人通过引入代价高昂的惩罚来推广N人雪堆博弈,并证明了惩罚在复制动力学下的合作进化中发挥了积极作用 [10] 。Vasconcelos等人考虑了一个制度惩罚,发现制度惩罚能够显著提高合作水平 [8] 。最近,Xiao等人提出了一个抽样惩罚方法,每一轮博弈交互后,从种群中随机抽取一个个体样本,当样本中的背叛者数量超过一定阈值时,群体中的每个背叛者都将被处以罚款,他们据此探讨了公共物品博弈和集体风险的社会困境,他们发现,当惩罚强度相当大时,在低惩罚阈值和小样本情况下,合作水平可以得到有效提高 [11] 。
在有限种群中,成功策略的传播通常用马尔科夫过程来描述,通过更新规则进行策略更新,其中关于愿景驱动规则的研究引起了广泛关注。Du等人研究了愿景驱动更新规则下雪堆模型和公共资源分享模型,讨论了平均丰度随选择强度变化的趋势 [12] 。Wang等人通过结合模仿过程和愿望驱动规则来研究演化博弈论,他们发现,合作的比例与采用愿望驱动更新规则的个体的比例有关。进一步,他们在愿景驱动更新规则下研究了多人雪堆博弈的扩展平均丰度函数,研究表明可以通过改变相关参数来提高合作者的占比 [13] [14] 。
目前为止,在公共物品博弈和集体风险的社会困境中,抽样惩罚被研究,并被证明会影响合作水平,但并没有在多人雪堆博弈模型中给出衡量抽样惩罚有效性的参数的具体表达式,无法直观理解抽样惩罚如何影响合作行为。本文在混合均匀的有限种群中,将抽样惩罚引入多人雪堆博弈模型中,基于愿景驱动规则,根据马尔科夫链的状态方程,理论推导出平稳概率分布,进而得出平均丰度、平均惩罚概率、平均惩罚成本的直观表达式,为研究抽样惩罚如何影响行为提供了更直接的表达式,通过理论和数值分析结合的方式,发现在一定的惩罚强度下,采用较低的惩罚阈值更有利于实施抽样惩罚,且惩罚成本较低。最后,结合案例具体研究了参数变化是如何影响企业博弈行为的演化,为第三方机构如何设计最优惩罚力度提供了参考。
2. 数学模型
2.1. 多人演化博弈模型
考虑一个个体数量为N的混合均匀的有限种群,参加博弈的个体可以以某种驱动方式在A策略和B策略之间做出选择。我们定义整个种群中A类型的个体数为i (i定义为演化状态),则B类型个体数为 ,随着演化时间的推移,演化状态i也随之变化,此为个体按照某种策略更新规则进行不断重复博弈演化的动态过程。具体描述为,在规模为N的种群中随机选取一个焦点个体,然后在剩余 个个体中选取 个个体构成一个组,假设组中A类型个体数目为k,焦点个体和组相遇并发生博弈,博弈结束后,焦点个体根据所选取策略的收益进行评估,然后根据某种更新规则进行策略更新,此过程是不断重复的。由于该群组是随机抽选的,且A类型个体和B类型个体是随机的。
因此,我们可以将演化状态i下整个群体中A和B策略的平均收益 [15] 写为:
, (1)
, (2)
其中 为A类型个体的收益, 为B类型个体的收益, 。
2.2. 抽样惩罚下多人雪堆博弈模型
我们将多人演化博弈模型运用到雪堆博弈模型中,群组中所有人有一个共同铲雪任务,策略A为合作策略,即参与铲雪,策略B为背叛策略,不参与铲雪。当铲雪人数不为0时,则每个个体都获得收益b,其中铲雪成本c由铲雪者分担,此时背叛者没有贡献,不用负担任何成本,理性的参与者会选择背叛策略,根据以上可以写出 , 的具体形式:
, (3)
. (4)
为了促进合作,克服个体倾向于选择背叛策略的情况,我们引入一个机制进行激励,将一个外部机构作为施加惩罚的主体,在每轮博弈之后,该机构从整个群体中随机选择M (满足 )个个体作为样本,抽样服从超几何分布,样本中合作者个数为m,当在他们中发现 个背叛者满足 时,将会对群体中的每个背叛者施加β (β定义为惩罚强度且 )的罚款,否则背叛者不受惩罚。这里,δ (满足 )表示施加惩罚时的阈值。特别地,当 时,无论抽样结果如何,机构都会对所有背叛者进行惩罚;当 时,只有当样本中 (样本个体全为背叛者)时,惩罚才会起作用,从而导致高容忍度的惩罚。因此,在相互作用的组中具有A、B类型个体的收益 [11] 可以写成如下形式:
, (5)
, (6)
其中, , 为Heaviside函数,如果 , ,否则为0。这里 表示种群中合作者为i时对背叛者的惩罚概率。
2.3. 愿景驱动更新规则
与其他更新规则相比,愿景驱动更新规则不需要关注战略环境中的其他信息,而是一种更具自发性的机制。愿景水平 可以解释为个体对学习的满意程度,个体通过比较博弈的收益与愿景水平 进行新的决策,在该规则的驱动下,个体从A类型更新到B类型的概率 [16] 为:
, (7)
式(7)中当焦点个体的收益 低于愿景水平 时,则 ,反之则 。同理可知焦点个体从B类型更新到A类型的概率为:
. (8)
在有限种群中,成功策略的传播用离散时间步长的生灭过程来描述,因此系统的状态空间由合作者的数量来描述, 。可以推断出有三种情况发生:状态i可以以概率 增加,以概率 减少或者以概率 保持不变。马尔可夫过程的转移概率矩阵是三角的,即对角线上和次对角线上的元素都非零,由此可以得出一步转移概率可以表示为:
, (9)
, (10)
. (11)
2.4. 分析方法
2.4.1. 平稳概率分布的推导
根据以前的研究 [15] [17] [18] ,我们可以得出以下分析结果:
设 描述系统在时间t处于状态j的概率, 的主方程为:
, (12)
式(9)~(11)为无吸收态的马尔科夫链,根据遍历马尔科夫链的性质。因此,存在唯一的平稳概率分布 , ,其中
. (13)
结合式(12)和式(13)得 满足平衡方程:
, (14)
可推导出上式满足细节平衡条件:
. (15)
对上式进行归纳分析,当 时:
, (16)
其中 。由于 ,可得:
. (17)
由此,
. (18)
将式(18)代入式(16)进而可得平稳分布具体表达式:
(19)
其中 。
2.4.2. 合作者平均丰度XA
种群中合作者占比可用 表示, 为系统在时间 时合作者的状态,因此 为随机变量, 为其对应的平稳概率分布。可将合作者平均丰度定义为:
. (20)
反应了合作者在种群中的丰富度。我们考虑的愿景更新规则中,其存在着唯一的平稳概率分布 。因此,结合式(9)~(11),(19),(20)可得 直观表达式:
, (21)
. (22)
2.4.3. 平均惩罚概率Pf
抽样惩罚相对于全局惩罚,虽然降低了第三方机构工作量,但我们要关注对背叛者的惩罚概率 , 为系统在时间 时合作者的状态,因此 为随机变量, 为其对应的平稳概率分布。可将平均惩罚概率定义为:
. (23)
因此,结合式(9)~(11),(19),(23)可得 直观表达式:
, (24)
. (25)
2.4.4. 平均惩罚成本Cf
惩罚成本是衡量抽样惩罚方法有效性的一个量,定义惩罚成本为 , 为系统在时间 时合作者的状态,因此 为随机变量, 为其对应的平稳概率分布。可将平均惩罚成本定义为:
. (25)
因此,结合式(9)~(11),(19),(25)可得 直观表达式:
, (26)
. (27)
3. 具有抽样惩罚的多人雪堆博弈模型的演化动态
3.1. 合作者平均丰度XA受参数的影响分析
在多人雪堆博弈模型中,我们先取定基本参数: , , , 。 , , ,代入式(21),分别取值 可得到合作者平均丰度随选择强度 变化的基本曲线(如图1所示)。从图1中可以看出,在该模型中,当惩罚阈值 时,无论选择强度的大小,合作者平均丰度一直保持在1/2附近,此时种群中合作者和背叛者比例相当;当惩罚阈值 时,合作者平均丰度随选择强度增加而减小,当选择强度 时,选择强度 对平均丰度的影响也基本趋于稳定。以上表明低惩罚阈值(对背叛者的低容忍度)有利于促进合作。
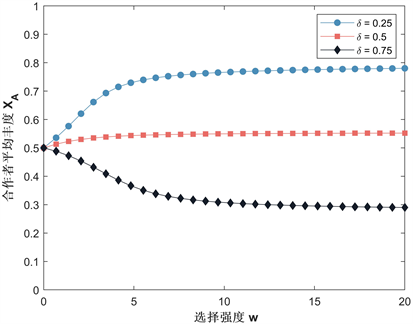
Figure 1. Curve of the average abundance with respect to the selection intensity
图1. 选择强度与平均丰度的变化曲线
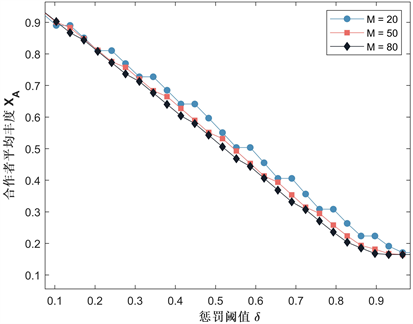
Figure 2. Curve of the average abundance with respect to the punishment threshold
图2. 惩罚阈值与平均丰度的变化曲线
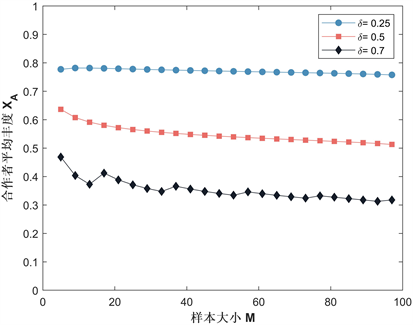
Figure 3. Curve of the average abundance with respect to the sample size
图3. 样本大小与平均丰度的变化曲线
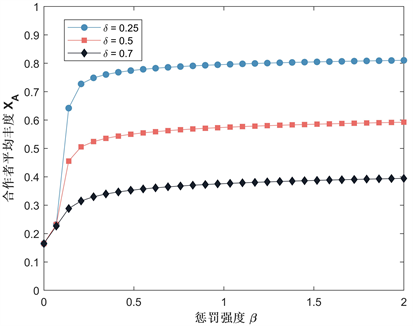
Figure 4. Curves of the average abundance with respect to the punishment intensity
图4. 惩罚强度与平均丰度的变化曲线
第三方机构如何调控参数以促进合作,分析三个参数(惩罚阈值δ,样本大小M,惩罚强度β)对合作者平均丰度的影响规律非常重要。以下我们分析各参数对平均丰度 的影响,当计算某个参数影响时(例如δ)其他参数(N, d, b, c, α, ω = 15)数值保持不变,计算其他参数时类推。
图2给出了平均丰度 与惩罚阈值δ的变化曲线,由图2可见,对于三个不同的样本量值,平均丰度随着δ的增加而降低。图3给出了平均丰度 与样本大小M的变化曲线,当固定惩罚阈值时,低样本量的合作者平均丰度要比高样本量高;当固定样本大小时,惩罚阈值减少,合作者平均丰度增加。图4给出了平均丰度 与惩罚强度β的变化曲线,对于三个不同的惩罚阈值水平下,我们可以看到,当β超过某一个点时,合作者平均丰度突然增加,然后稳定在某一个值,这种现象与δ的值无关,且随着惩罚强度的增加,合作者平均丰度也会随之增加。通过以上分析我们可得到以下结论:
结论1:惩罚阈值低时,意味着对背叛者的低容忍度促进了合作的演化;通过选取较小的样本,我们可以获得更高的合作,增加样本,平均丰度总体上衰减缓慢;通过增加惩罚强度β,可以增加合作的演化;且当惩罚强度超过某一阈值时,合作水平才会明显增加,然后稳定在某一个值。
3.2. 平均惩罚概率Pf受各参数的影响分析
接下来我们研究参数惩罚阈值δ,样本大小M,惩罚强度β对平均惩罚概率 的影响。我们先取定基本参数: , , , , , , , ,当计算某个参数影响时(例如δ),其他参数(N, d, b, c, α, ω)数值保持不变,计算其他参数时类推。我们将以上参数代入式(24),分别取值 可得到平均惩罚概率随惩罚阈值δ变化的基本曲线,如图5所示,对于三个不同的M值,平均惩罚概率总是随着δ的增大而减小。我们观察到平均惩罚概率在 时达到最大值,随后急速下降,这表明较小的δ值有利于实施抽样惩罚。图6给出了不同δ下平均惩罚概率随M变化的曲线,我们发现,随着M的增加,平均惩罚概率呈现下降趋势,这表明低样本大小下有利于实施抽样惩罚。进一步,我们研究了不同δ下平均惩罚概率如何受惩罚强度的变化,可以在图7中看到,平均惩罚概率随惩罚强度β单调减小,当β更小时,平均惩罚概率更高。通过以上分析我们可得到以下结论:
结论2:惩罚阈值低或者选取较小的样本,更有利于实施抽样惩罚,并且随着阈值或者样本的增大,平均惩罚概率随之减小;当惩罚强度更小时,平均惩罚概率更高,随着惩罚强度的提高,导致平均惩罚概率降低。
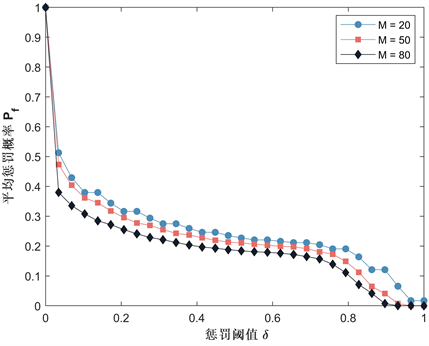
Figure 5. Curve of the average punishment probability with respect to the punishment threshold
图5. 惩罚阈值与平均惩罚概率的变化曲线
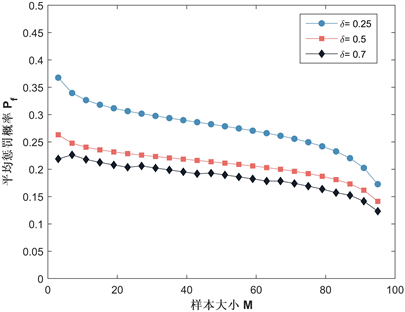
Figure 6. Curve of the average punishment probability with respect to the sample size
图6. 样本大小与平均惩罚概率的变化曲线
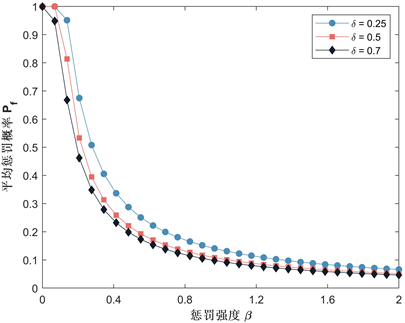
Figure 7. Curve of the average punishment probability with respect to the punishment intensity
图7. 惩罚强度与平均惩罚概率的变化曲线
3.3. 平均惩罚成本Cf受各参数的影响分析
在多人演化博弈中,第三方机构实施惩罚必须考虑成本因素,因此,接下来我们有必要研究参数惩罚阈值δ,样本大小M,惩罚强度β对平均惩罚成本 的影响。我们先取定基本参数: , , , , , , , ,当计算某个参数影响时(例如δ),其他参数(N, d, b, c, α, ω)数值保持不变,计算其他参数时类推。我们将以上参数代入式(26),分别取值 可得到平均惩罚成本随惩罚阈值δ变化的基本曲线,如图8所示,对于三个不同的M值,平均惩罚成本首先显著增加,然后随着δ的增加而开始降低,这与样本量的大小无关,从图8中可以看到低阈值和高阈值时 较小,因此,在实施抽样惩罚时,零容忍和高度宽容是最经济的。为了进一步研究样本量对平均惩罚成本的影响,我们在图9中描绘了平均惩罚成本随M的变化情况,样本量 时 下降较为明显,这是由于此时平均惩罚概率较低的原因(可参考图6)。最后,我们在图10中给出了平均惩罚成本 与惩罚强度β的变化曲线, 首先迅速增加,随后当β超过某一个点时又开始下降,这是由于惩罚强度的增高会导致背叛者受到巨额的罚款,进而促进合作,这将会降低必要的激励成本。通过以上分析我们可得到以下结论:

Figure 8. Curve of the average punishment cost with respect to the punishment threshold
图8. 惩罚阈值与平均惩罚成本的变化曲线
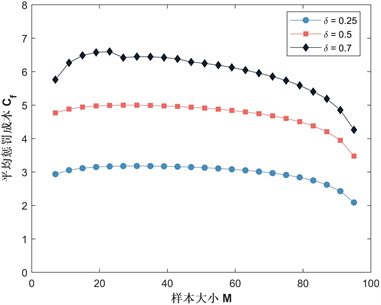
Figure 9. Curve of the average punishmentcost with respect to the sample size
图9. 样本大小与平均惩罚成本的变化曲线
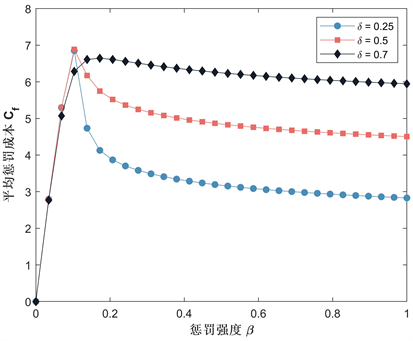
Figure 10. Curve of the average punishment cost with respect to the punishment intensity
图10. 惩罚强度与平均惩罚成本的变化曲线
结论3:在实施抽样惩罚时,零容忍和高度宽容是最经济的;样本量较大时平均惩罚成本也会相应变低;当惩罚强度超过某一个点时,平均惩罚成本会出现缓慢下降,这是因为群体中背叛者为避免强烈的惩罚而切换策略形成的。
4. 案例分析
本文以环境污染问题为背景进行案例分析,建立基于多人雪堆演化博弈的环境污染问题的模型,并将环保部门作为第三方机构,作为施加抽样惩罚的主体。假设有N个产污企业参加博弈,每个企业有两个策略可以选择,即合作策略(A)和非合作策略(B),这里A表示参与节能减排,B则相反。以下我们分析各参数对企业和环保部门的影响,先进行模型假设:
1) 所有企业决策行为遵循愿景驱动更新规则,所有企业有一个相同的愿景水平 ,它代表企业在博弈过程中所期望的价值。
2) 每次博弈时,一个焦点企业会与 个其他企业发生博弈,每轮博弈后,环保部门会在N个产污企业中抽选M个企业进行检查,假设样本中参与节能减排的企业为m,若样本中未参与节能减排的企业超过一定数值(即 ,δ为惩罚阈值),则对N个产污企业中的每个未参与节能减排的企业施加罚款β。
3) 节能减排的成本c在选择合作策略的企业中进行平摊。只有当合作策略的企业数量 时,所有企业才能获得收益b。以此,我们给出相应的收益矩阵:
表1中 为合作企业为i时对非合作企业的惩罚概率,由表1可得相应博弈收益的表达式为式(5)、(6)。由第3节结论我们知道施加惩罚且低惩罚阈值时有利于促进合作,以下我们尝试通过对相关参数的调控来提高环保部门施加惩罚的有效性并促进企业合作。为了与前文呼应,我们设定基本参数: , , , , , , , 。

Table 1. The payoff matrix of the company
表1. 企业的收益矩阵
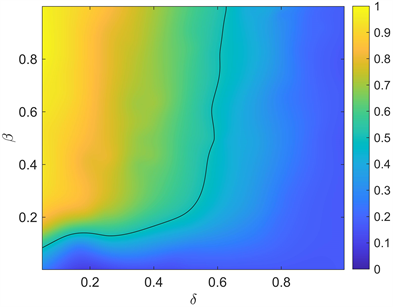 (a) M = 20
(a) M = 20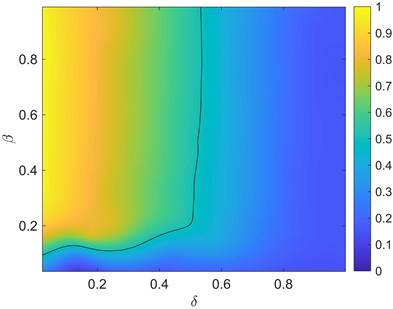 (b) M = 80
(b) M = 80
Figure 11. The influence of δ and β on the average abundance
图11. δ和β对平均丰度的影响

Figure 12. The influence of δ and β on the average punishment probability
图12. δ和β对平均惩罚概率的影响

Figure 13. The influence of δ and β on the average punishment cost
图13. δ和β对平均惩罚成本的影响
从图11(a)中,我们给出惩罚强度与惩罚阈值对平均丰度共同作用的相图,黑色分界线为平均丰度 线,可以看到,惩罚阈值高于某一个值时,选择节能减排的企业占比低于 ,这是由于对非合作企业高度宽容使得“搭便车”现象产生,为了增强合作企业占比,环保部门可以降低惩罚阈值δ (即对非合作企业降低宽容度),但罚款β不宜过低。当我们增加抽样样本至 时,得到图11(b),相对于图11(a),虽然可以看到选择合作企业高于 的区域变小,但这种变化较小,且在实际抽样中,我们希望抽样样本量不宜过大,因为这将增加环保部门工作量。图12中我们探讨δ和β共同作用对平均惩罚概率的影响,图中黑色分界线为平均惩罚概率 线,对非合作企业实施巨额罚款时,理性的企业会因为巨额的罚款而选择合作,从而使得惩罚概率降低,不利于抽样惩罚的实施。图13中给出δ和β对平均惩罚成本共同作用的相图,可以看到实施抽样惩罚时,罚款在0.2~0.8,惩罚阈值在小于0.4情况下,是相对经济的。在参数调控时,环保部门控制参数使得 , 且 较低时是比较理想的,为了满足这样的条件,我们结合图11~13,可以看到存在这样的区域,这样的参数调控是可以实现的。
以上模型分析所得结论不仅与常理相符,同时还为环保部门如何调控参数以提高抽样惩罚有效性提供了思路,这将有利于指导实际的管理和调控,进而增强企业节能减排的积极性。
5. 结论
本文基于愿景驱动更新规则,建立了抽样惩罚下的多人雪堆博弈模型,根据马尔科夫链的状态方程,理论推导出平稳概率分布,进而得出平均丰度、平均惩罚概率、平均惩罚成本的直观表达式,为多人雪堆博弈模型的实际应用提供了理论计算模型。具体分析了三个参数(惩罚强度β、惩罚阈值δ、样本大小M)对平均丰度、平均惩罚概率、平均惩罚成本的影响,这三个参数是可以被第三方机构调控的,进而通过参数调控以促进合作。以往的研究中只关注相关参数对合作行为的影响,但并未分析促进合作行为的机制 [12] [14] 。我们引入抽样惩罚,探讨了第三方机构如何设计最优惩罚力度使得惩罚效率提高,更加贴近现实,并得出了具有指导意义的结论。结论表明,当惩罚强度超过某一阈值时,低惩罚阈值和选取较小的样本,更有利于实施抽样惩罚,合作水平会明显增加,零容忍和高度宽容也是最经济的。本文以企业治污为例,通过数值分析了惩罚强度β、惩罚阈值δ是如何影响企业的合作行为演化,当调整参数使得惩罚强度超过某一阈值且惩罚阈值较低时,此时选择节能减排策略的企业比例大于1/2,促进了更多企业参与治污,从而使得节能减排政策落到实处,并且为环保部门进行参数调控给出参考。
基金项目
国家自然科学基金项目(12061020);贵州省科技厅科学基金(黔科合基础[2019]1123号:黔科合-ZK [2021]一般331);贵州省教育厅科学基金(黔科合KY字[2021]088号)。
文章引用
周文鹏,丘小玲. 抽样惩罚下多人雪堆博弈模型的合作演化
Cooperative Evolution of Multi-Player Snowdrift Game Model under Sampling Punishment[J]. 运筹与模糊学, 2023, 13(06): 7517-7532. https://doi.org/10.12677/ORF.2023.136738
参考文献
- 1. Boyd, R. and Richerson, P.J. (2009) Culture and the Evolution of Human Cooperation. Philosophical Transactions of the Royal Society of London, 364, 3281-3288. https://doi.org/10.1098/rstb.2009.0134
- 2. Van Veelen, M., García, J., Rand, D.G. and Nowak, M.A. (2012) Direct Reciprocity in Structured Populations. Proceedings of the National Academy of Sciences of the United States of America, 109, 9929-9934. https://doi.org/10.1073/pnas.1206694109
- 3. Smith, J.M. and Price, G. (1973) The Logic of Animal Conflict. Nature, 246, 15-18. https://doi.org/10.1038/246015a0
- 4. Sugden, R. (1986) The Economics of Rights, Co-Operation and Welfare. Blackwell, Oxford, UK.
- 5. Hauert, C. and Doebeli, M. (2004) Spatial Structure Often Inhibits the Evolution of Cooperation in the Snowdrift Game. Nature, 428, 643-646. https://doi.org/10.1038/nature02360
- 6. Milinski, M., Semmann, D. and Krambeck, H.-J. (2002) Reputation Helps to Solve the ‘Tragedy of the Commons’. Nature, 415, 424-426. https://doi.org/10.1038/415424a
- 7. Sasaki, T. and Unemi, T. (2011) Replicator Dynamics in Public Goods Games with Reward Funds. Journal of Theoretical Biology, 287, 109-114. https://doi.org/10.1016/j.jtbi.2011.07.026
- 8. Vasconcelos, V.V., Santos, F.C. and Pacheco, J.M. (2013) A Bottom-up Institutional Approach to Cooperative Governance of Risky Commons. Nature Climate Change, 3, 797-801. https://doi.org/10.1038/nclimate1927
- 9. Du, W.-B., Cao, X.-B., Zhao, L. and Hu, M.-B. (2009) Evolutionary Games on Scale-Free Networks with a Preferential Selection Mechanism. Physica A: Statistical Me-chanics and its Applications, 388, 4509-4514. https://doi.org/10.1016/j.physa.2009.07.012
- 10. Xu, M., Zheng, D.F., Xu, C. and Zhong, L.X. (2015) Coop-erative Behavior in N-Person Evolutionary Snowdrift Games with Punishment. Physica A: Statistical Mechanics and its Applications, 424, 322-329. https://doi.org/10.1016/j.physa.2015.01.029
- 11. Xiao, J., Liu, L., Chen, X. and Szolnoki, A. (2023) Evolution of Cooperation Driven by Sampling Punishment. Physics Letters A, 475, Article ID: 128879. https://doi.org/10.1016/j.physleta.2023.128879
- 12. Du, J., Wu, B., Altrock, P.M., et al. (2014) Aspiration Dynamics of Multi-Player Games in Finite Populations. Journal of The Royal Society Interface, 11, Article ID: 20140077. https://doi.org/10.1098/rsif.2014.0077
- 13. Wang, X.J., Gu, C.L., Zhao, J.H. and Quan, J. (2019) Evolutionary Game Dynamics of Combining the Imitation and Aspiration-Driven Update Rules. Physical Review E, 100, Article ID: 022411. https://doi.org/10.1103/PhysRevE.100.022411
- 14. 王先甲, 夏可. 多人雪堆演化博弈在愿景驱动规则下的扩展平均丰度函数[J]. 系统工程理论与实践, 2019, 29(5): 1128-1136.
- 15. Pena, J., Wu, B. and Traulsen, A. (2016) Ordering Structured Populations in Multiplayer Cooperation Games. Journal of the Royal Society Interface, 13, Article ID: 20150881. https://doi.org/10.1098/rsif.2015.0881
- 16. Xu, K., Li, K., Cong, R. and Wang, L. (2017) Cooperation Guided by the Coexistence of Imitation Dynamics and Aspiration Dynamics in Structured Populations. Europhysics Letters, 117, Article No. 48002. https://doi.org/10.1209/0295-5075/117/48002
- 17. Claussen, J. and Traulsen, A. (2005) Non-Gaussian Fluc-tuations Arising from Finite Populations: Exact Results for the Evolutionary Moran Process. Physical Review E, 71, Article ID: 025101. https://doi.org/10.1103/PhysRevE.71.025101
- 18. Liu, X., He, M., Kang, Y. and Pan, Q. (2016) Aspiration Promotes Cooperation in the Prisoner’s Dilemma Game with the Imitation Rule. Physical Review E, 94, Article ID: 012124. https://doi.org/10.1103/PhysRevE.94.012124
NOTES
*通讯作者。