Finance
Vol.
10
No.
04
(
2020
), Article ID:
36598
,
11
pages
10.12677/FIN.2020.104040
Modeling of Corporate Financial Distress Alarm in China
Hong Ren1, Yuzhi Zhang2*, Yifang Chu3
1Department of International Business, Nankai University, Tianjin
2College of Software, Nankai University, Tianjin
3School of Economics, Nankai University, Tianjin

Received: Jun. 30th, 2020; accepted: Jul. 14th, 2020; published: Jul. 21st, 2020

ABSTRACT
Financial distress alarm modeling is to diagnose the financial stress of enterprises and to release financial risk alarming signals. Early detection of corporate financial risk is conducive to the prevention of debt default or even enterprise fail. This paper takes 258 Special Treatment (ST) listed companies on China Stock Exchanges, for the period of 2015 to 2019, and another 258 non-ST Chinese enterprises in the same period as samples, analyzes the relevant financial data of the two company groups, and use Logistic regression model to build the financial distress alarm model for Chinese companies. The results showed that, the prediction accuracy of the model for the two years before the occurrence of ST in the sample, and the prediction accuracy of the expanded test sample are both above 80% level which indicates that the model is applicable for alarming the financial distress of Chinese companies. Furthermore, this paper used the model to analyze the financial risk status of Chinese listed companies under COVID-19.
Keywords:Financial Distress, Alarm, Corporate Financial Risk, Debt Default

中国企业财务危机预警模型研究
任 红1,张玉志2*,楚义芳3
1南开大学国际商务系,天津
2南开大学软件学院,天津
3南开大学经济学院,天津

收稿日期:2020年6月30日;录用日期:2020年7月14日;发布日期:2020年7月21日

摘 要
财务危机预警模型是诊断企业财务状况、发出财务风险信号的量化模型。及早发现财务风险,有利于调整企业的经营策略,防范企业发生债务违约、破产倒闭等财务危机。本研究选择2015年至2019年中国上市公司中258个ST企业,和另外258个对比企业(包括上市和部分非上市企业)为样本,分析两组企业的相关财务数据,采用Logistic逻辑回归模型,构建中国企业财务危机预警模型。模型对样本企业被特别处理(ST)前两年的预测(回测)准确率,以及扩大样本检验后的预测准确率,均达到80%以上,因此,模型可以用于对中国企业财务危机进行预警。进而,本文利用该模型,对新冠疫情下中国全部上市公司的财务风险做了预警分析。
关键词 :财务危机,预警,财务风险,债务违约

Copyright © 2020 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
自2014年首次发生债券实质性违约后,中国债券违约事件频发。发生债务违约,企业通常已经步入财务危机。如何利用企业的财务指标,对企业的财务危机进行预警,一直是一个重要的研究领域。随着大数据及信息高速处理技术的发展,利用丰富的企业财务信息和市场数据,对数据进行快速处理,可以帮助企业及时优化管理决策,调整经营策略,化解财务危机;在宏观经济政策层面,也可以利用对于企业群体财务状况的监测,适时出台相应的政策措施,从而降低经济整体的运行风险。
一般将企业无力支付到期债务或者费用,定义为企业处于财务危机,这实际上包括从资金管理的技术性失败,到企业破产清算,以及处于两者之间的各种情况 [1]。在实证分析中,我国许多学者将上市公司中被宣告特别处理的ST (Special Treatment)公司 [2],作为具有财务危机特征的企业进行研究。本研究沿用这一定义并采样。
财务危机预警模型是判断企业是否会发生财务危机的检测工具之一。西方经济学家于二十世纪三十年代起,逐渐开始对企业财务预警模型进行研究。早期,主要有Beaver提出的单变量模型 [3]。由于单变量模型很难对企业财务状况做出全面综合的衡量,学者们遂对多变量财务模型展开研究。在多变量财务预警模型中,比较具有代表性和影响力的主要有美国爱德华·阿特曼的Z-score计分模型 [4] [5];1980年,Ohlson首次将Logistic模型应用于财务危机预警的研究中 [6]。中国学者周首华等人于1996年提出了财务预测的F分数模型 [7]。2001年,吴世农用多种多变量分析方法进行建模分析,其研究结果表明,Logistic模型的判别方法比多元线性判别模型方法更加优越和稳健,尤其是对财务危机预警这种属于两分法的情况更加适合 [8]。
2. 数据准备
2.1. 样本的选取
本研究的出发点,是在债务违约频发背景下,对财务危机进行预警。在实证分析中,选取将ST公司作为发生财务危机的样本,原因如下:
· 首先,债务违约有多重表现形式,有的公司在债务违约发生前,可能采取一定的措施(如债务重组)规避违约,但公司实际上已经处于财务危机状态。如果单纯从债务违约的角度来定义财务危机,很可能导致财务预警模型的样本覆盖范围过小。
· 第二,很多发生债务违约的公司是非上市公司,发生债务违约前几年的财务数据披露不全。有许多企业发的是私募债,不对外公布财务数据,因此难以基于历史财务数据进行研究。剔除无法获取历史财务数据后剩余的公司样本较少,且不具有代表性。
· 第三,公司被证券交易所宣告特别处理,是由于其经营管理等方面出现了重大问题。根据《股票上市规则》,最近两个会计年度净利润为负值,最近一个会计年度的股东权益低于注册资本,每股净资产低于股票面值,或由于自然灾害等其他原因经营异常,证券交易所可以宣布公司进入特别处理(ST)。显然,ST类公司陷入财务危机的特征明显。
作为对照样本,在选择运营正常(非财务危机)的公司时,本研究遵循了以下原则:
· 处于同一行业。由于行业因素对公司经营发展的影响较大,不同行业各财务指标的解读也不一样。因此,在选择对照组样本时,选择和陷入财务危机的公司处于同一行业的公司。
· 数据时间一致。一般认为,财务预警模型的建模样本数据具有较强的时效性,本研究针对样本公司发生财务危机前一年的财务数据进行处理,故对照组的非财务危机公司也采用同一年的财务数据。
· 资产规模相近。为了避免公司资产规模因素对财务风险判断的影响,尽量选择和ST样本组公司资产规模相近的公司作对比。
另外,在选择建模所采样的非ST公司时,只选择未发生过债务违约的公司。由于我国债券市场存在债券实质性违约是从2014年开始,本研究选取了2015年至2019年被特别处理的A股市场258家ST公司作为样本组,并按照前述原则选择了另外258家非ST公司(包括上市和部分非上市企业)作为对照组。
全部样本数据来源于万得系统,本研究使用的数据,是所选择的ST公司被ST前两年的财务指标,对照组公司的数据年份相同。研究中,选取样本组被ST之前一年的财务数据构建模型;而选取样本组被ST之前两年的数据,计算模型的回判结果。例如,如果公司2019年被特别处理,则选用该公司2018年、2017年的年报财务数据进行回判分析。
2.2. 财务指标的选取
财务预警中所使用的财务指标主要指的是财务比率数据,用财务比率数据来比较、评价各公司的发展经营情况,可以基本排除公司规模差异因素所带来的影响。
对于财务比率的选取,目前尚没有一致的筛选方法。本研究参考了国内外代表性的Z值模型研究成果,将这些成果所选取的5个财务比率指标(见表1),作为本研究的第一批原始备选财务指标。除此之外,还根据国内外单变量和多变量财务预警模型中对财务指标的分析和研究,将广泛使用和具有较高区分度与代表性的财务指标,作为第二批原始备选财务指标。具体包括:盈利能力,股东获利能力,偿债能力,营运能力,现金流量能力,和资本结构六个方面共13个财务指标(见表2)。这样,原始备选的财务指标共18个。
Z值模型公式如下 [4]:

Table 1. Z-score model variables
表1. Z值模型财务指标
Table 2. Alternative financial variables
表2. 其他备选财务指标
原始备选的财务指标只是具有辨识财务危机的潜力,要用作建模的自变量,还需要做进一步的筛选:
首先,Z值模型之外的18个财务指标是从国内外研究成果中选取的,由于本研究覆盖全市场,因此需要剔除掉受行业因素影响较大的财务指标,包括营业收入/总资产、应收账款周转率、存货周转率、流动资产周转率(见表3)。
Table 3. Summary of financial indicators after preliminary screening
表3. 初步筛选后的财务指标
为检验上述14个财务指标的显著性,对其进行T值检验,剔除显著性不高的财务指标,检验结果如表4所示。T值检验发现:X9流动比率、X10速动比率、X13现金流量负债比率三个财务指标在样本中显著性不高,需要剔除。其余11个财务指标在样本中具有显著区别,表明变量能够较好解释企业是否具有ST风险。
Table 4. T-test results of sample data
表4. 样本数据均值T检验结果
*, ** or *** indicates a significance level at 10%, 5% and 1% respectively.
3. 中国企业财务危机预警模型
3.1. 基于Logistic的财务危机预警模型
在研究推进的过程中,我们首先尝试选择了与Z计分模型类似的多元线性判别模型——典则判别分析模型,通过尝试不同的财务指标自变量组合,利用样本数据建模并作回判分析,但是,即使是最优的自变量组合,其判别准确率仍然不高。有鉴于此,遂转而采用Logistic模型。
现实中企业的财务指标数据都不是正态分布的,而Logistic逻辑回归模型并不要求数据呈正态分布,是解决两分类问题适用的模型。该模型的基本原理如下:
首先,假设影响财务危机的财务指标自变量标识为 ,总判别因变量为Y,Y是二分变量,设:
其中bi为权数,表示对应自变量Xi对财务危机预警的贡献度,Xi是第i个财务指标(自变量),a为随机干扰常量。
设P为发生财务危机的概率,取值范围为0~1, 为不发生财务危机的概率,将比数 取自然对数, ,即对P做Logistic回归转换。以 为因变量,建立线性回归方程:
由上面两个公式可得:
在Logistic回归模型中,通过设定临界值,可预测事件发生或不发生的概率。该模型一般选择0.5作为分割点,如果P值大于0.5,则表示公司破产的概率较大,如果P值小于0.5,则表明公司财务正常的概率较大。
我们采用logistic判别模型,利用2015年至2019年258家ST和另外258家非ST公司的上述11个财务指标数据,利用被宣告特别处理前1年年报中的相关财务数据进行回归分析,将它们纳入模型中,观察不同组合的预测准确率。在筛选的过程中,同时考虑到模型中的财务比率不应违反其本身意义,比如在一般情况下,营运资本/总资产比率数值减少表明公司的资产流动性降低,在其他条件不变时,其发生财务危机的概率将上升,因此,其在模型中的系数应该是负号。通过尝试不同的财务指标自变量组合,最后得到一个预测准确率最高的模型:
式中:
营运资本 = 流动资产—流动负债,营运资本越多,表明公司的资产流动性越好,偿债能力越强。
这一指标反应了企业历史积累的利润和盈利能力。指标越高,代表企业盈利能力更强更稳定。
该比率反应公司运用全部资产所获得利润的水平,指标越高,表明公司投入产出水平越高,资产的使用效率越高,成本和费用的控制水平越高,和财务风险是反比关系。
这一指标反映了每股股票所具有的权益价值,指标越高,股东所拥有的每股资产价值越多,公司的抗风险能力越强。
在构建模型时,是在假设自变量之间不存在明显的多重共线性前提下,求出参数和系数的,因此,需要对变量进行相关性检验。从表5中可以看到,所有变量的VIF数值均小于5,这表明变量之间不存在明显的多重共线性,模型的可靠性高。
Table 5. Logistic model tolerance test
表5. Logistic模型容忍度检验
3.2. 模型分割点检验
在选择自变量组合时,作者是参照以往学者们的做法,将模型的判别标准设定为以0.5为分割点。为了检验上述模型的分割点,我们需要进一步做分割点检验。对于Logstic模型来说,不同的分割点会导致判别两组类别公司的准确率不同,即I类准确率和II类准确率。I类准确率是指将ST公司判别为财务危机公司,II类准确率是指将非ST公司判别为非财务危机公司。分割点的选择会影响到判别两组公司的准确率,如果分割点选得过高,容易将财务危机公司判别为非财务危机公司,降低I类准确率;如果分割点设定得过低,容易将非财务危机公司误判为财务危机公司,降低II类准确率。因此,在选取模型分割点时,应该考虑模型对两组公司的综合判别准确率,选择使模型综合判别准确率最优的数值作为分割点。
我们在0~1之间以0.05为间距设定不同的分割点,分析随着分割点的变化,Logistic模型判别两类公司的准确率及综合判别准确率的变化情况。
Table 6. Accuracy analysis of different segmentation
表6. 不同分割点准确率分析表
根据表6和图1所示,当P为0.5时,模型的综合预测准确率达到最高点,该Logistic模型的分割点设置为0.5是合理的。模型的判别标准为:P值大于0.5时,判定该企业具有财务风险;P数值小于0.5时,判断企业的财务状况正常。
3.3. 模型回判结果
为了验证Logistic财务预警模型的预测能力,我们将样本公司发生财务危机前两年的相关财务数据,代入上述Logistic判别模型中进行检验。
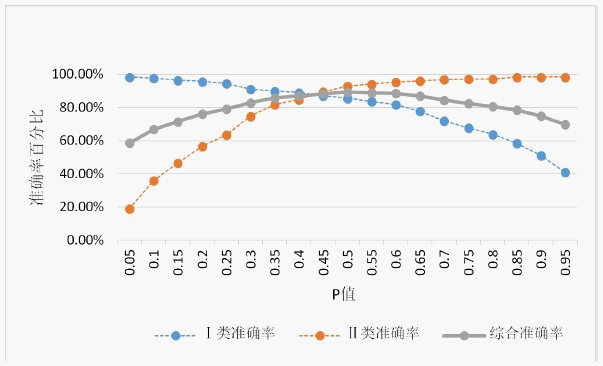
Figure 1. Accuracy analysis diagram of different segmentation
图1. 不同分割点准确率分析图
Table 7. The back test result of the previous year before special treatment
表7. Logistic模型对公司ST前一年的回判结果
将样本公司发生财务危机前1年的财务数据代入Logistic判别模型,从表7我们可以看到,在258个ST样本中,预测结果为ST的样本有221个,37个ST样本被预测为非ST,预测准确率为85.66%;而在258个非ST样本中,预测结果为ST的样本有18个,预测结果为非ST的样本有240个,预测准确率为93.02%。经加权计算,我们得到模型的综合预测准确率为89.34%。
进一步地,我们将样本公司发生财务危机前2年的财务数据代入Logistic判别模型,表8为公司发生财务危机前两年模型的判别结果:
Table 8. The back test result of 2 years before special treatment
表8. Logistic模型对公司ST前两年的回判结果
在发生ST的前2年,258个ST样本中,模型预测结果为ST的有178个,预测结果为非ST的样本有80个,预测准确率为68.99%。由于部分非上市公司前两年的财报信息未披露或披露信息不全,我们统计了所有可以查到模型所用财务指标信息的非ST公司共242个,其中预测结果为ST的样本有17个,预测结果为非ST的公司有225个,预测准确率为92.98%。二者相加,最终得到的预测综合准确率为80.99%。
综合上述回判结果,结论是:在公司发生ST的前两年,模型预测准确率均可以达到80%以上,且模型对财务危机发生的前1年的预测准确率,比前2年的预测准确率更高。logistic模型在区分ST和非ST企业上,具有很好的预测效果,因而总体上对预测企业财务风险,具有良好的实际应用价值。
3.4. 扩大样本检验
为了进一步验证上述Logistic模型的预测准确性,我们对模型进行扩大样本检验。截至本研究建模完成时,中国A股上市公司披露的最新财务报告为2019年年报。我们从现有3815个A股上市公司中剔除92个缺失模型自变量数据的样本,对3723个中国A股上市公司进行扩大样本检验,其中,有199个ST公司,3526个非ST公司。将扩大样本的2019年年报相关财务数据带入模型中进行计算,得到的最终检验结果如表9所示:
Table 9. Logistic model expanded sample test
表9. Logistic模型扩大样本检验结果
结果显示,在199个ST样本中(包含两个退市公司),预测结果为ST的样本有171个,28个ST样本被预测为非ST,预测准确率为85.93%。而在3524个非ST样本中,预测结果为ST的样本有392个,预测结果为非ST的样本有3132个,预测准确率为88.88%。通过加权计算,我们得到logistic模型的综合预测准确率为87.41%。
总的来看,我们所研发的Logistic财务预警模型,不仅适用于建模所针对的较小数量的样本公司,应用到中国上市公司及非上市企业,也具有相当高的预测准确率。模型对于我国利用大数据,动态监测企业的经营情况,对企业整体的财务危机状况进行预警,前瞻性地出台一些相关的经济政策,都具有重要的实用价值。
4. 新冠疫情下中国上市公司财务危机预警
2019年年底,在湖北省率先爆发新冠肺炎(2019-nCoV),目前疫情已波及至全球。此次疫情直接导致以社交接触为基础的经济社会活动陷入瘫痪,给实体经济带来了巨大冲击。根据国家统计局披露的数据,我国2020年第一季度GDP同比下降了6.8%。
企业层面受疫情冲击的影响也显而易见。鉴于上市公司一季报已经披露,我们将2020年第一季度财务报表的相关财务数据代入Logistic财务预警模型中,根据P值,判断2019年三季报、年报、2020一季报各期陷入潜在财务危机的公司的整体情况,从而反映中国上市公司受疫情的影响程度。
Table 10. Comparison of modeling results of Chinese listed companies in the recent three quarters
表10. 中国上市公司2019三季报、2019年报和2020一季报模型判别结果对比
如表10中所示,经统计,中国上市公司披露最近三个季报且不缺失模型所需数据的公司共有3704家。根据2019年第三季度数据计算,得出判别结果为具有财务危机特征的公司数量为416家,占比11.23%;根据2019年年报数据计算,得出判别结果为具有财务危机特征的公司数量为563家,占比15.20%;根据2020年第一季度数据计算,得出判别结果为具有财务危机特征的公司数量为702家,占比18.95%。
这3704家公司中,目前实际被ST的公司共199家(包含两家退市公司),占比约为6%。根据模型判断,已经有一部分非ST公司处于财务危机状态,或其财务状况呈现出类似于ST公司的风险特征。2020年第一季度较2019年第三季度,模型预测增加了286家ST公司,增加的公司比率上升了7.72%。由此可见,受新冠疫情影响,近半年中国上市公司的财务风险整体呈现出一定程度的恶化。
为了进一步获取中国上市公司整体财务风险上升的程度,我们对中国上市公司2020年一季度的P值和2019年三季度的P值数值的变动情况进行对比。
其中,P1为使用某公司2020年第一季度财报中财务指标数据所计算的P值,P0为使用同一公司2019年第三季度财报中财务指标数据所计算的P值。k值表示该公司在疫情下P值的增减情况。
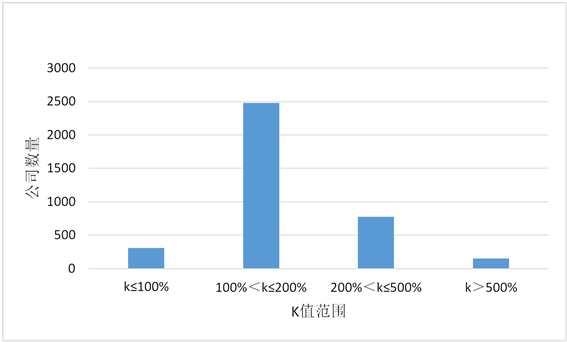
Figure 2. Comparison of k-value range of Listed companies in China
图2. 中国上市公司k值范围对比
由于Logistic模型中的自变量x1、x2、x5、x8均为财务风险的反向指标,即自变量数值越大,财务风险越小;而在函数公式中自变量与P值为反比关系,自变量越大,P值越小。因此,自变量数值增大,P值越小,财务状况越好,反之同理。即当P1 < P0时,k < 100%,表示财务状况转好;当P1 > P0时,k > 100%,表示财务状况恶化。如图2、表11所示,中国上市公司k值低于100%的只有8.32%,在100%-200%范围内占比达到66.85%,k值超出200%的接近25%,显然,大多数上市公司的财务风险都明显上升。
Table 11. Statistics of K-value range of listed companies in China
表11. 中国上市公司k值范围统计
5. 结语
经过建模、回测、扩大检验,以及针对在新冠疫情下,对中国上市公司中可能发生财务危机的潜在公司的预测,本研究有如下基本结论:
第一,中国公司的财务数据信息中,包含着比较充分的财务危机信息,中国公司的财务危机具有可预测性。上市公司财务信息质量的提高,给系统性的财务危机预警提供了可能。
第二,对本研究所建立的Logistic模型的验证表明,在样本企业发生财务危机的前两年,及扩大样本检验的情况下,模型预测准确率都在80%以上,模型具有较高的可靠性。Logistic模型在中国是适用的。这一模型可以先行试用于对于企业群体财务风险的预警。
第三,具体到特定的企业,由于企业个体自身的特殊性,除了利用Logistic模型对企业的财务风险状况进行诊断外,还需要结合行业特征、市场状况、公司个性等做进一步的深入分析。
基金项目
本研究获得中国科技部2018YFB0204304项目支持。
文章引用
任红,张玉志,楚义芳. 中国企业财务危机预警模型研究
Modeling of Corporate Financial Distress Alarm in China[J]. 金融, 2020, 10(04): 392-402. https://doi.org/10.12677/FIN.2020.104040
参考文献
- 1. 谷祺, 刘淑莲. 关于资本经营的几个问题[J]. 财会通讯, 1998(12): 41-47.
- 2. 陈静. 上市公司财务恶化预测模型的实证研究[J]. 会计研究, 1999(4): 31-38.
- 3. Beaver, W.H. (1968) Market Prices, Financial Rations and Prediction of Failure. Journal of Accounting, 5, 67-92.
- 4. Altman, E.I. (1968) Financial Ratio, Discriminate Analysis and the Prediction of Corporate Bankruptcy. Journal of Finance, 23, 589-609. https://doi.org/ 10.1111/j.1540-6261.1968.tb00843.x
- 5. Altman, E.I. (1993) Corporate Financial Distress and Bankruptcy: A Com-plete Guide to Predicting & Avoiding Distress and Profiting from Bankruptcy. 2nd Edition, John Wiley & Sons, Inc., New York.
- 6. Ohlson, J.A. (1980) Financial Ratios and the Probabilistic Prediction of Bankruptcy. Journal of Ac-counting Research, 9, 109-131. https://doi.org/ 10.2307/2490395
- 7. 周首华, 杨济华, 王平. 论财务危机的预警分析——F分数模式[J]. 会计研究, 1996(8): 8-11.
- 8. 吴世农, 卢贤义. 我国上市公司财务困境的预测模型研究[J]. 经济研究, 2001(6): 46-55.