Computer Science and Application
Vol.08 No.06(2018), Article ID:25678,9
pages
10.12677/CSA.2018.86107
The Research on an Attribute-Weighted Multi-Kernel Fuzzy Clustering Algorithm
Yun Kan, Zhenqiang Bao, Zhaoyue Zhang
College of Imformation Engineering, Yangzhou University, Yangzhou Jiangsu

Received: Jun. 7th, 2018; accepted: Jun. 22nd, 2018; published: Jun. 29th, 2018

ABSTRACT
Considering the problem of unsatisfactory clustering effect of single kernel function for multiple data sources or heterogeneous data sets, and taking into account the difference in importance of different attributes for different categories, this paper proposes an attribute-weighted multi-kernel fuzzy clustering algorithm (AWMKFCM)). The algorithm combines the multi-kernel fuzzy clustering algorithm with the attribute-weighted single-kernal fuzzy clustering algorithm. It not only can handle the problem that the single kernel function can not meet the clustering accuracy requirements of the clustering data set, but also can adjust the importance of each attribute dynamically to different categories according to the specific characteristics of different types in the clustering process. Clustering experiments show that the attribute-weighted multi-kernal fuzzy clustering algorithm has higher clustering accuracy than the attribute-weighted single-kernel fuzzy clustering algorithm and multi-kernal fuzzy clustering algorithm under the premise of a certain amount of running time and iterations.
Keywords:Fuzzy Clustering, Multi-Kernal, Attribute-Weighted
属性加权多核模糊聚类算法研究
阚云,包振强,张照岳
扬州大学信息工程学院,江苏 扬州
收稿日期:2018年6月7日;录用日期:2018年6月22日;发布日期:2018年6月29日

摘 要
针对多数据源或异构数据集,采用单个核函数的聚类效果不理想的问题,以及考虑到不同属性对不同类别重要性的差异,本文提出了一种属性加权多核模糊聚类算法(WMKFCM)。该算法将多核模糊聚类算法与属性加权核模糊聚类算法相结合,不仅能够处理单个核函数不能满足待聚类数据集聚类准确度要求的问题,而且能在聚类过程中根据不同类的具体特性动态调整各个属性对于不同类别的重要性。聚类实验表明,在牺牲一定的运行时间和迭代次数的前提下,相比于属性加权核模糊聚类算法和多核模糊聚类算法,属性加权多核模糊聚类算法具有更高的聚类准确度。
关键词 :模糊聚类,混合核函数,属性加权

Copyright © 2018 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
聚类算法作为一种无监督学习方法,为识别数据内在结构提供了一种有用的工具,是数据挖掘的重要研究内容之一。聚类分析的一般过程是,根据数据之间的相似性将数据划分到不同的簇集,结果使得同一簇中的数据具有较高的相似度,而不同簇间的数据具有较低的相似度 [1] [2] [3] [4] 。1974 年,Bezdek建立了模糊聚类理论 [5] 。模糊聚类分析采用隶属度函数表示样本间的亲疏程度,能够更加全面的体现数据集的结构 [6] 。2002年,Girolami将聚类与核方法相结合,首次提出了核聚类方法,为之后的核聚类研究奠定了基础 [7] 。2004年,伍忠东,高新波等将核方法的思想推广到模糊c-均值算法,构造了基于核方法的模糊核c-均值算法 [8] 。2009年,赵犁丰,李新等人针对多类样本数据,提出一种多核模糊聚类算法。通过选取子核函数及其参数构造多核函数,使得输入空间的样本经多核映射后增大不同类别样本间的差别,提高核函数的学习能力和泛化能力 [9] 。2011年,王栋将加权多宽度高斯核学习引入到聚类分析中, 提出了一种加权多宽度高斯核聚类算法 [10] 。
上述模糊聚类算法主要通过改进核函数来提高聚类效果。然而这些算法将所有特征或样本视为平等, 都未考虑待聚类数据集样本属性间的不平衡性的缺陷问题,从而降低了聚类性能。2012 年,蔡威提出了一种改进的属性加权核模糊聚类算法(WKFCM),该方法充分体现了各特征属性对聚类结果重要性的差异性,改进了当时模糊聚类算法的不足 [11] 。2017年,曹喆提出了一种基于样本和特征加权的模糊聚类, 同时考虑样本和特征的重要性对聚类的影响,建立了基于样本和特征的模糊聚类模型,并将核函数引入该聚类算法,建立了基于样本和特征加权的核模糊聚类模型 [12] 。然而上述加权模糊聚类算法均是采用单个核函数进行聚类,对于多数据源或异构数据集,聚类算法的聚类效果并不理想。
因此,本文对属性加权核模糊聚类算法进行改进,将该聚类算法与多核模糊聚类算法相结合,使其在聚类过程中,不仅能动态调整各属性对不同类别的重要性,而且通过将全局核函数和局部核函数线性组合,增强了核函数的泛化能力和学习能力,能更加准确的反映数据集的结构特征。
2. 属性加权多核模糊聚类算法
2.1. 混合核函数
不同的核函数会将输入空间的数据集映射到不同的特征空间,相似度度量矩阵就会不同,对于基于核的模糊聚类方法,核函数起着关键的作用。常见的核函数大致被分成两类,即局部核函数和全局核函数。局部核函数就是在数据点远离测试点时函数取值很小,比如高斯核函数就是最常用的局部核函数,具有较好的学习能力。而多项式核函数是一个典型的全局核函数,对离测试点相距较远的数据点也会从产生作用,但局部性较差,保证了良好的泛化能力。构造一个合适的核函数对于核模糊聚类的聚类结果具有重要影响。只使用一个核函数有时并不能满足待聚类数据集的需求,而不同的核函数结合起来使用,会有更好的特性,比如将具有局部核函数和全局核函数相结合,这就是混合核函数的基本思想 [13] 。
根据定理2-1如果 是一个有效的核函数(也称Mercer核函数),当且仅当输入数据集 对应的核矩阵是半正定和对称的。
设 是 上的核函数, ,根据定理2-1容易得出以下是核函数:
(1)
(2)
容易证明函数 也是核函数。
本文将学习能力强的高斯核函数和泛化能力强的多项式核函数进行线性组合构造了混合核函数,如下式所示:
(3)
并将该混合核函数用于以下的聚类算法中。
2.2. 算法理论
以往的聚类算法中,默认所有的特征属性在聚类过程中起着同等的作用,但实际上不同属性对各个类别的重要性并不相同。属性加权多核模糊聚类算法充分考虑了各特征属性对聚类结果贡献度的差异,在聚类过程中,根据不同类的具体特性动态调整各个属性对于不同类别的重要性。并引入混合核函数,将学习能力强的局部核函数和泛化能力强的全局核函数进行线性组合以此取代原来的单个核函数,以此处理单个核函数不能满足待聚类数据集的需求的问题。将该方法充分考虑了属性间的不平衡性,能够更真实的反映待聚类问题的真实情况。
设聚类样本集为 , ,样本集经过非线性变化 映射到高维核特征空间后
,
则WMKFCM模糊聚类算法准则为使以下目标函数最小:
(4)
S.t.
(5)
(6)
其中, 表示第k个属性对于第 类的重要程度,称为属性权值; 表示权重因子。
根据约束优化问题的Lagrange求解,用混合核函数推导结果如下:
(7)
(8)
(9)
将混合核函数代入,得以下公式:
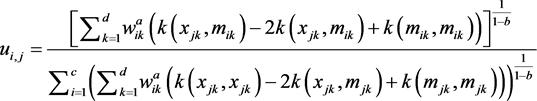 (10)
(10)
(11)
(12)
其中,k表示混合核函数。
2.3. 算法步骤
属性加权多核模糊聚类算法(WMKFCM)模糊聚类算法具体实现步骤如下:
Step 1设定初试迭代聚类参数:聚类类别数c、模糊加权指数b、属性权重因子a、混合核函数比例λ,高斯核函数参数 ,多项式核函数参数 ,迭代终止阈值ε和迭代次数I;
Step 2随机初试化
和 ;
;
Step 3根据上述推导公式,依次更新 和 ;
Step 4重复Step 3的计算,直到 ;
Step 5根据最大隶属度原则,由隶属度矩阵 确定最终聚类结果。
3. 实验及结果分析
为了测试属性加权多核模糊聚类算法(WMKFCM)的性能,本次研究将该算法与另外两种典型的求解大规模数据的聚类算法属性加权核模糊聚类和多核模糊聚类在同一数据集Haberman’s Survival数据集上聚类,并对比聚类性能。
Haberman’s Survival数据集,选自UCI机器学习数据库,该数据集包含306个样本,具备3种属性:手术时病人的年龄(Age of patient at time of operation),病人手术的年份(Patient’s year of operation),检测到正腋窝节点的数量(Number of positive axillary nodes detected)。一共分为2类:1——这个病人活了5年或更长(1—the patient survived 5 years or longer),如下图蓝色点,2——病人在5年内死亡(2—the patient died within 5 year),如下图1红色点。
将属性加权多核模糊聚类中的混合核函数比例系数的取值区间设为[0, 0.2 ,0.5,0.6,0.7,0.8,0.9,1]。其他参数设置相同。本次实验分别从聚类准确率,CPU运行时间,以及迭代次数三方面进行比对。其中聚类准确率的计算方式如下:
(13)
上式中,SS对记录属于相同的真实分组和相同的聚类;DD对记录属于不同的真实分组和不同的聚类;SD对记录属于相同的真实分组,但不同的聚类;DS对记录属于不同的真实分组,但相同的聚类。如下图2所示。
属性加权多核模糊聚类算法在Haberman’s Survival数据集中的运行结果如下表1所示。
如表1所示。当 的时候,此时聚类算法为属性加权核模糊聚类算法,核函数为多项式核函数;

Figure 1. The dataset of habarman’s survival
图1. Habarman’s Survival数据集
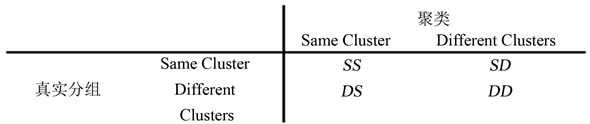
Figure 2. The chart of clustering accruacy
图2. 聚类准确图解释图

Table 1. The result table of attribute-weighted multi-kernel fuzzy clustering algorithm
表1. 属性加权多核模糊聚类算法运行结果表
当 的时候,此时聚类算法为属性加权核模糊聚类算法,核函数为高斯核函数。当 时,此时聚类算法为属性加权多核模糊聚类算法,核函数为混合核函数。
将上述数据用折线图的形式表示更为直观。如下图3图示。
如图所示,3(a)为聚类准确度与混合核函数关系图,3(b)为迭代次数与混合核函数比例关系图,3(c)为运行时间与混合核函数比例关系图。与属性加权核模糊聚类算法相比,属性加权多核模糊聚类的迭代次数和运行时间较高。但当混合核函数比例系数 的时候,其聚类准确度明显高于 时。其中,当混合核函数比例系数 的时候,属性加权多核模糊聚类算法的聚类准确度最高。由此可见,在牺牲一定的运行时间和迭代次数上,属性加权多核模糊聚类算法的聚类准确度要明显优于属性加权核模糊聚类算法。
如图4~6所示,属性加权多核模糊聚类算法相比于多核模糊聚类算法,其运行时间和迭代次数有一定的增长,但是其聚类准确度普遍优于多核模糊聚类算法。因此,在牺牲一定运行时间和迭代次数的前提下,属性加权多核模糊聚类算法的准确度优于多核模糊聚类算法。
将属性加权多核模糊聚类孙发与多核模糊聚类算法相对比,其他参数设置相同,实验结果如表2所示。将表2数据以折线图的形式表示更为直观,如图4~6所示。
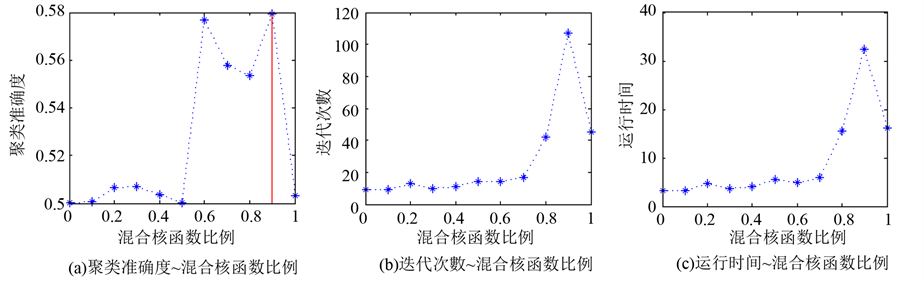
Figure 3. The result graph of attribute-weighted multi-kernel fuzzy clustering algorithm
图3. 属性加权多核聚类算法运行结果图
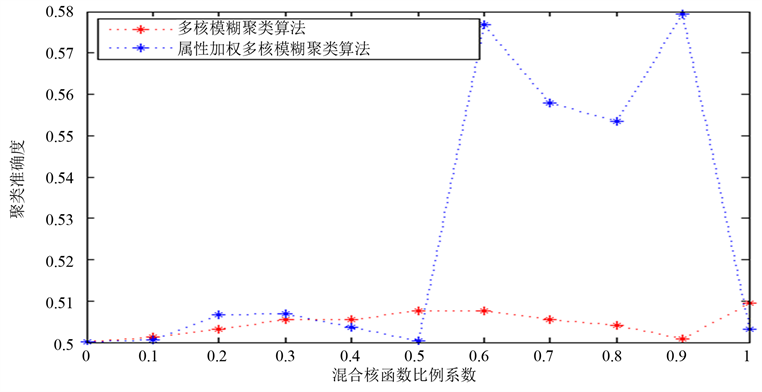
Figure 4. Contrast graph of clustering accruacy of multi-kernel fuzzy clustering algorithm and attribute-weighted multi-kernel fuzzy clustering algorithm
图4. 多核模糊聚类与属性加权多核模糊聚类准确度对比图
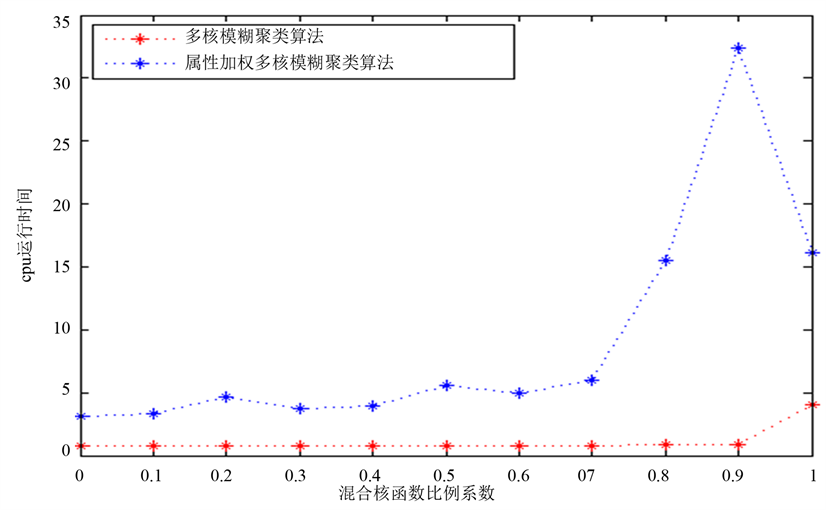
Figure 5. Contrast graph of CPU time of multi-kernel fuzzy clustering algorithm and attribute-weighted multi-kernel fuzzy clustering algorithm
图5. 多核模糊聚类与属性加权多核模糊聚类Cpu运行时间对比图
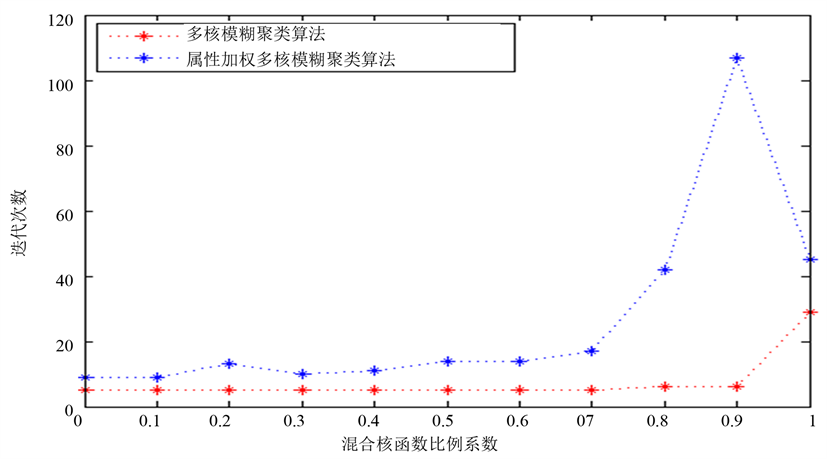
Figure 6. Contrast graph of the number of iterations of multi-kernel fuzzy clustering algorithm and attribute-weighted multi-kernel fuzzy clustering algorithm
图6. 多核模糊聚类与属性加权多核模糊聚类迭代次数对比图
4. 结束语
本次研究通过将多核模糊聚类算法与属性加权核模糊聚类算法相结合,提出了属性加权多核模糊聚类算法。通过多个核函数的线性组合以解决单个核函数不能满足待聚类数据集的需求,并且,充分考虑了各特征属性对聚类结果贡献度的差异,在聚类过程中,根据不同类的具体特性动态调整各个属性对于

不同类别的重要性。最后通过在数据集上进行测试,有效地证明了属性加权多核模糊聚类算法的可行性。
文章引用
阚 云,包振强,张照岳. 属性加权多核模糊聚类算法研究
The Research on an Attribute-Weighted Mul-ti-Kernel Fuzzy Clustering Algorithm[J]. 计算机科学与应用, 2018, 08(06): 961-969. https://doi.org/10.12677/CSA.2018.86107
参考文献
- 1. 孙吉贵, 刘杰, 赵连宇. 聚类算法研究[J]. 软件学报, 2008, 19(1): 48-61.
- 2. Ding, S., Zhang, J., Jia, H., et al. (2016) An Adaptive Density Data Stream Clustering Algorithm. Cognitive Computation, 8, 30-38. https://doi.org/10.1007/s12559-015-9342-z
- 3. Jain, A. (2010) Data Clustering: 50 Years beyond k-Means. Pat-tern Recognition Letters, 31, 651-666. https://doi.org/10.1016/j.patrec.2009.09.011
- 4. Du, M., Ding, S. and Jia, H. (2016) Study on Density Peaks Clustering Based on k-Nearest Neighbors and Principal Component Analysis. Knowledge-Based Systems, 99, 135-145. https://doi.org/10.1016/j.knosys.2016.02.001
- 5. 严峻. 模糊聚类算法应用研究[D]: [硕士学位论文]. 浙江大学, 2006.
- 6. Chen, M.S., Wang, W., et al. (1999) Fuzzy Clustering Analysis for Optimizing Fuzzy Membership Function. Fuzzy Sets and Systems, 103, 239-254. https://doi.org/10.1016/S0165-0114(98)00224-3
- 7. Girolami, M. (2002) Mercer Kernel-Based Clustering in Feature Space. IEEE Transactions on Neural Networks, 13, 780-784. https://doi.org/10.1109/TNN.2002.1000150
- 8. 伍忠东, 高新波, 谢维信. 基于核方法的模糊聚类算法[J]. 西安电子科技大学学报(自然科学版), 2004, 31(4): 533-537.
- 9. 赵犁丰, 李新, 王栋. 多核模糊聚类算法的研究[J]. 中国海洋大学学报(自然科学版), 2009, 39(5): 1047-1050.
- 10. 王栋. 基于加权多宽度高斯核函数的支持向量机聚类算法研究[D]. 中国海洋大学, 2011.
- 11. 蔡威. 模糊聚类在数据挖掘中的应用研究[D]. 兰州交通大学, 2012.
- 12. 曹喆. 样本和特征加权的模糊聚类算法研究[D]. 河北大学, 2017.
- 13. 樊淑炎. 核k-means优化方法研究[D]. 中国矿业大学, 2017.