Management Science and Engineering
Vol.
11
No.
04
(
2022
), Article ID:
59478
,
17
pages
10.12677/MSE.2022.114070
数据驱动的零售网络库存补货研究
许东东,汪达钦
东华大学旭日工商管理学院,上海
收稿日期:2022年11月22日;录用日期:2022年12月12日;发布日期:2022年12月26日

摘要
为了更科学的进行库存补货,越来越多的企业尝试对商品需求进行预测,但由于商业活动存在各种各样的可能性,例如竞争对手的商业行为并不能通过历史数据进行预测得到,商品销量预测结果往往不能准确匹配真实的商品销量。如何建立预测需求与真实需求之间的关系,并指导零售网络中各个节点进行科学备货成为企业关注的重点。且随着线上业务的快速发展,消费者的消费需求越来越多元化、个性化,对商品的配送时效要求越来越高。在这样的社会背景下,可以预见到消费者在面对商品缺货且无法尽快调货时选择放弃购买的情形。对于企业而言,这不仅是一次销售损失,更是对品牌忠诚度的重大影响。传统的库存补货策略显然无法适应当下企业的运营发展,本文在企业需求预测结果基础上,同时考虑纵向补货和横向调拨,构建数据驱动的零售网络库存协同补货模型,探究区域配送中心与多个线下门店间的库存协同补货问题,并设计改进粒子群优化算法对各线下门店的最高库存水平折算天数进行求解,实现补货成本、缺货成本、库存持有成本、横向调拨等成本之和的最小化。
关键词
横向调拨,库存决策,粒子群优化算法,零售网络

Research on Data-Driven Inventory Replenishment in Retail Network
Dongdong Xu, Daqin Wang
Glorious Sun School of Business & Management, Donghua University, Shanghai
Received: Nov. 22nd, 2022; accepted: Dec. 12th, 2022; published: Dec. 26th, 2022

ABSTRACT
In order to replenish stocks more scientifically, more and more companies try to forecast the demand for goods, but due to the various possibilities of business activities, for example, the business behavior of competitors cannot be predicted by historical data, and the results of goods sales forecasting often do not accurately match the real goods sales. How to establish a relationship between demand forecasts and real demand and to guide the scientific stocking of each node in the retail network has become a key concern for companies. With the rapid development of online business, consumers’ needs are becoming more and more diversified and personalized, and they are demanding more and more timely delivery of goods. In such a social context, it can be expected that consumers will choose to abandon their purchases when faced with a product that is out of stock and cannot be transferred as quickly as possible. For companies, this is not only a loss of sales, but also a significant impact on brand loyalty. This paper builds a data-driven collaborative inventory replenishment model for retail networks based on demand forecasting, considering both horizontal replenishment and lateral transfer, explores the collaborative inventory replenishment problem between regional distribution center and multiple offline shops, and designs an improved PSO algorithm to solve for the maximum inventory level converted days for each offline shop to minimize the sum of replenishment costs, out-of-stock costs, inventory holding costs and lateral transfers costs.
Keywords:Lateral Transfers, Inventory Decisions, PSO, Retail Network

Copyright © 2022 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
随着国家经济社会的快速发展与物质生活水平的不断提高,消费者不再仅仅关注商品价格是否合适,也更加看重零售企业提供的购物体验和售后服务。进一步地,为了保障消费者可以更迅速、更满意的购买到商品,销售预测的作用日益凸显,零售企业需要基于线下门店商品销售预测结果指导库存补货计划的制定。准确的商品销售预测能帮助零售企业进行更合理的补货规划,达到对库存的有效控制,企业成本与顾客服务水平的均衡,使整个零售网络达到全局优化。因此,考虑需求预测情况下的库存补货策略研究有较强的理论意义与实践意义。
此外,由于销售预测结果不可能与实际销售结果完全一致,线下门店发生缺货的情况在所难免,合理的库存调拨策略将有效降低库存不足带来的缺货损失。如果商品优先履约的线下门店发生缺货,可以按照成本、距离、服务水平等原则选择符合条件且在库库存大于设定临界值的线下门店对缺货线下门店进行横向调拨。横向调拨也凭借其灵活性高、响应速度快、可以很好的解决仅凭纵向补货带来的库存分布不均、服务水平不高等问题的优点,近年来受到了越来越多学者和企业的关注。然而,以下问题还值得进一步研究:如何基于历史预测销售数据、历史实际销售数据以及未来预测销售数据确定零售网络各节点的库存补货数量?在线下门店发生缺货时又该如何进行横向调拨?
2. 文献综述
对于库存控制策略的研究一直是学界和业界都十分关注的热点问题,国内外学者都进行了深入的研究。长期以来,库存控制模型总是基于历史需求分布进行研究,需要假设历史需求服从某种分布,再对分布的参数进行拟合 [1] [2] [3] [4]。然而这类方法在面对当下时变的需求时早已不合适,为了更科学的进行供应链库存控制,建立数据驱动的库存控制是非常必要的 [5]。近年来,随着机器学习和大数据的飞速发展,不少学者开始基于企业的实际运营数据,对企业存在的库存问题进行优化。Cao [6] 等研究了非平稳需求下的分位数预测方法,并将其作为数据驱动的方法应用到报童模型和多周期库存模型中。Wang [7] 等提出了一种两阶段的预测方案来解决库存控制问题,首先用LSTM模型对商品需求进行预测,然后采用 库存控制策略对库存进行优化,使得库存总成本最低。Praveen [8] 等为了消除预测需求与实际需求之间巨大差异导致的成本,提出了一个人工神经网络来更精准的预测需求,进而减小了库存成本,提高了供应链的总收益。王瑛 [2] 等建立了由核心制造企业主导的多级库存系统优化模型,采用合作预测的方式确定再订购点和订货批量,该模型可以有效降低供应链总成本。罗晓萌 [9] 等针对某大型网上超市需求预测精度不高的情况,基于时间序列法对未来需求进行预测,再降低预测误差的基础上提出基于 库存控制策略的库存系统,在保证一定服务水平前提下将系统总成本降至最低。
由于销售预测存在误差且需求存在波动性,仅凭借上级节点的周期性补货并不能应对时变的消费者需求,因此线下门店时常会发生缺货现象。不少国内外学者针对这一问题进行研究,提出横向调拨将有效降低缺货成本。Banerjee [9] 等比较了两种预防性调拨策略,一种是基于可用性调拨,指从可用库存水平高于预期库存水平的节点将库存调拨至可用库存水平低于预期库存水平的节点,另一种是库存均匀调拨,指将各节点的库存进行重新分配,使得各个节点的可供应天数相同,算法表明,两种策略均比不转运是的成本低。Feng [10] 等考虑在预防性横向补货无法实施的前提下,将纵向的应急性补货考虑到模型中,并用动态规划方法求解最佳的调拨时间和调拨量。上述文献主要讨论了在需求发生前进行库存横向调拨,另一些学者则研究了当库存节点发生缺货时进行应急性横向调拨。Alvarez [11] 等通过允许高级客户进行应急性横向调拨实现了差异化的服务。Purnomo [12] 等将应急性横向调拨加入到维修品库存控制策略中,建立了多级库存应急性调拨模型。霍佳震 [13] 等以服务水平为约束,库存成本和横向调拨成本最小为目标建立了零备件库存多点调拨的批量订货模型。徐小峰 [14] 等同时考虑了应急性纵向调拨和应急性横向调拨,对零售行业的二级库存系统进行建模,构建了纵向及横向综合库存调拨模型并求解了每日调拨方案。
综上所述,国内外学者针对数据驱动的库存补货问题和横向调拨问题已经取得了一定的研究成果。但是通过梳理后发现还存在以下不足之处:目前针对数据驱动的库存问题主要还是将需求预测得到的结果当作未来的真实需求进行库存规划,忽略了预测需求和实际需求间的误差。此外,对于库存调拨点如何选择的研究较少,目前针对横向调拨问题的文献还主要集中在库存系统内各节点库存是否完全共享、是否采用集中决策、预防性调拨和应急性调拨的对比等方向,对于库存调拨点选择的文章并不多。
受上述研究启发,本文考虑到各门店通过纵向周期性补货后库存分布不均、需求不平稳等问题,设计了可调拨库存最多点策略和距离最近点策略两种应急性横向调拨策略。基于此,以各线下门店最高库存水平折算天数为决策变量,以各线下门店可调拨库存量为约束,构建数据驱动的零售网络库存协同补货模型并设计改进粒子群优化算法进行求解。通过某家店零售企业的历史预测销量数据和历史实际销量数据进行仿真实验,验证了本文提出模型的有效性,可以为零售企业库存决策提供一些参考。
3. 问题描述及模型建立
3.1. 问题描述
本文主要考虑二级零售网络结构,在该二级零售网络结构中,主要包括一个区域配送中心与在该区域配送中心辐射范围内的若干线下门店。各线下门店会在每周初对未来几周的销售需求进行预测。区域配送中心主要负责向其关联的线下门店进行纵向补货,线下门店主要负责面向线上、线下的消费者进行履约。为了区分不同的决策过程,本文将区域配送中心向门店补货的过程称为“补货决策”,将各门店间的商品转运过程称为“调拨决策”。
纵向补货决策指区域配送中心向线下门店补货的过程,每T天进行一次。每次补货过程需要检查各线下门店商品的当前库存即在库库存和在途库存之和。基于当前库存与销量预测,再决定是否需要向区域配送中心提出补货请求,以及相应的补货量。每一个补货的请求都会形成一个补货订单,订单将在提前期后即发出的L天后抵达各线下门店,抵达时间为抵达日凌晨。例如,t天发出的订单将于 天凌晨抵达。
横向调拨决策指各线下门店间的商品转运过程,每天在满足需求后进行决策。每次横向调拨过程发生前需要检查各线下门店的在库库存与各线下门店提前期内的需求预测,若发生横向调拨,调拨量将在发出的当天满足消费者需求,不计入调入线下门店的期末库存。
纵向补货决策决定了库存在各个线下门店间的基础分布。如果线下门店备货充足,则消费者需求将优先从线下门店进行直接履约,时效性最快。如果区域配送中心纵向补货的商品数量不足,则容易出现线下门店缺货的情况,当发生缺货时,部分消费者愿意等待通过各线下门店间的横向调拨来解决当前的缺货问题,剩余消费者会选择放弃购买。当横向调拨也不足以弥补缺货时,无法被满足的消费者会选择放弃购买。通过零售网络库存协同补货可以有效缓解销量的波动与需求预测的不准确带来的缺货损失成本和库存持有成本。本模型库存补货示意图如图1所示。
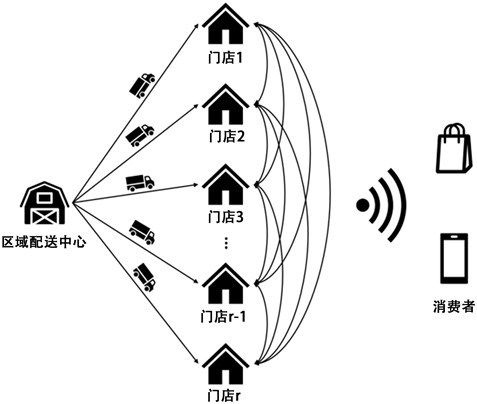
Figure 1. Inventory replenishment diagram
图1. 库存补货示意图
3.2. 模型假设
1) 补货假设:考虑区域配送中心的供应能力不受限制,即线下门店向区域配送中心发出的补货请求总能被满足;
2) 需求独立假设:考虑各线下门店的商品需求相互独立,互相间不存在影响;
3) 缺货假设:线下门店在本地库存无法满足需求时,一定比例的消费者会直接放弃购买,产生第一次缺货成本,剩余消费者愿意等待其他线下门店进行横向调拨,若横向调拨完成后仍无法满足消费者需求,则产生第二次缺货成本;
4) 库存策略假设:各线下门店均采用 库存策略,即当每个订货周期T,区域配送中心会检查各线下门店的当前库存,当各线下门店的当前库存低于再订购点s时,由上级向下级补货Q,使各线下门店的库存水平达到最高库存水平S,当前库存包括在库库存和在途库存;
5) 横向调拨假设:各线下门店间均采用不完全共享库存的横向调拨策略,即当线下门店库存小于再订购点 时,线下门店为防止本地库存无法应对补货提前期内的需求,该线下门店会不提供横向调拨,否则可以提供横向调拨。
3.3. 变量定义
根据以上的目标以及假设,定义变量如表1所示。

Table 1. Symbol description
表1. 符号说明表
3.4. 模型建立
在假设中规定,各线下门店的库存策略均遵循 库存策略,其中T为补货周期,s为再订购点,S为最高库存水平。与传统库存策略假设需求服从正态分布不同,本文考虑s、S与未来需求预测有关。通过查阅文献可以知道,s至少需要满足提前期内的需求,否则会造成缺货。但是若s过大,则会导致各个门店积压库存量较多,造成很高的库存成本。故将各线下门店的s分别确定为各线下门店提前期内的预测需求总和。而最高库存水平S及其折算天数可以基于历史预测数据及真实销量数据进行仿真,并通过改进粒子群优化算法求解得到最优解。
考虑在线下门店面临缺货时加入线下门店间横向调拨的过程,线下门店每天将按照“入库—分配订单—检查库存并横向调拨—检查库存并订货”的流程进行运转,这里重点说明检查库存并订货部分。若满足补货周期,区域配送中心给需要统计各线下门店当天在库库存量 和在途库存量 ,补货提前期内的预测需求和 ,最高库存水平折算天数内的预测需求和 ,然后判断在库库存量与在途库存量之和与 的大小,当在库库存量与在途库存量之和小于 时,门店向区域配送中心发出订货请求,订货量为 与当前库存之差;当在库库存量与在途库存量之和大于等于 时,说明当前库存可以满足提前期内的预测需求,因此无需订货。
为了方便下文模型构建,在计算纵向补货成本时引入0~1变量 ,在计算横向调拨成本时引入0~1变量 ,具体表达式如下所示:
(1)
(2)
表示当区域配送中心第t天检查线下门店i库存时,若线下门店i的当天在库库存量和在途库存量小于线下门店i提前期内的预测需求,且第t天满足补货周期,则区域配送中心会向线下门店i进行纵向补货,否则,不进行纵向补货。
用以判断第t天线下门店i是否向线下门店j进行横向调拨,若进行横向调拨,则 等于1,否则, 等于0。
若第t天区域配送中心会向线下门店i进行纵向补货,将产生固定补货成本和可变补货成本,其中可变补货成本与补货量和区域配送中心到线下门店i的距离有关,因此纵向补货成本为:
(3)
当线下门店 期初在库库存与当日到货不足以满足当日实际需求时,会有部分消费者会因为线下门店 缺货而放弃购买,比例为 ,产生第一次缺货成本为:
(4)
式中, 表示对a进行向上取整。
当线下门店发生缺货时,各线下门店间可以进行横向调拨,将产生固定横向调拨成本和可变横向调拨成本,其中固定横向调拨成本与横向调拨次数有关,可变横向调拨成本与横向调拨量和线下门店 到线下门店j的距离有关,因此横向调拨成本为:
(5)
在各线下门店在完成横向调拨后,若还有部分需求未被满足,此时会产生第二次缺货成本:
(6)
式中, 表示对a进行向下取整。
若线下门店在满足需求和进行横向转运后仍有库存剩余,则每日期末在库库存将产生库存持有成本:
(7)
综上,我们不难得到数据驱动的仓储网络库存协同补货模型:
(8)
协同补货模型需要满足以下约束:
(9)
(10)
(11)
(12)
(13)
(14)
在协同补货模型中,式(8)表示补货模型的目标函数,即总成本最小化;式(9)表示提前期内的需求预测之和;式(10)表示最高库存水平折算天数内的预测需求之和;式(11)表示线下门店的期末在库库存;式(12)表示线下门店在第t天订货前的在途库存;式(13)表示线下门店第t天的订购量即区域配送中心向门店的补货量;式(14)表示线下门店间横向调拨应满足发生横向调拨减少的调出门店的库存持有成本与调入门店的缺货成本之和大于等于横向调拨成本。
3.5. 调出调入门店及横向调拨量求解
当线下门店发生缺货时,部分消费者会选择直接放弃购买,对于剩余愿意等待的消费者,区域配送中心可以协调其他线下门店进行横向调拨以满足该门店需求,尽可能减小缺货带来的缺货成本。针对如何确定调出调入门店及横向调拨量,本文主要考虑两种横向调拨策略,以下将分别阐述可调拨库存最多点策略与距离最近点策略。
1) 可调拨库存最多点策略
当有线下门店发生缺货时,区域配送中心会统计出各线下门店的缺货量和可调拨库存量即在库库存与提前期内预测需求和的差值,将门店分为调入队列和调出队列,若缺货量大于零则为调入队列,可调拨库存量大于零则为调出队列。分别找到调入队列中缺货量最多的门店和调出队列中可调拨库存量最多的线下门店,缺货量最多的线下门店为当前调入门店,可调拨库存量最多的线下门店为当前调出门店,横向调拨量为最大缺货量和最大可调拨库存量两者间的较小值。计算横向调拨量是否满足成本要求,若横向调拨减少的缺货成本和库存持有成本大于等于调拨成本,则发生调拨,当前调入门店缺货量减少横向调拨量,当前调出门店期末在库库存减少横向调拨量,将缺货量或可用库存量为零的线下门店从调入队列或调出队列中删除。重复上述流程,直至所有调入门店的缺货量等于零,或者所有调出门店的可调拨库存量等于零,或者横向调拨减少的缺货成本和库存持有成本小于调拨成本。
2) 距离最近点策略
当有线下门店发生缺货时,区域配送中心会统计出各门店的缺货量和可调拨库存量即在库库存与提前期内预测需求和的差值,将门店分为调入队列和调出队列,若缺货量大于零则为调入队列,可调拨库存量大于零则为调出队列。分别找到调入队列中缺货量最多的线下门店和调出队列中距离该门店最近的门店,缺货量最多的线下门店为当前调入门店,调出队列中距离其最近的线下门店为当前调出门店,横向调拨量为最大缺货量和距离最近门店可用库存量两者间的较小值。计算横向调拨量是否满足成本要求,若横向调拨减少的缺货成本和库存持有成本大于等于调拨成本,则发生调拨,调入门店缺货量减少横向调拨量,调出门店期末在库库存减少横向调拨量,将缺货量或可用库存量为零的门店从调入队列或调出队列中删除。重复上述流程,直至所有调入队列门店的缺货量等于零,或者所有调出门店的可调拨库存量等于零,或者横向调拨减少的缺货成本和库存持有成本小于调拨成本。
4. 改进粒子群优化算法求解过程
标准粒子群优化算法只能处理变量仅具有简单上下界约束的优化问题,而对具有复杂约束的非线性规划模型无能为力。此外,标准粒子群优化算法存在收敛速度过快,易陷入局部最优解等问题。针对标准粒子群优化算法的缺点,本文对其进行了一系列的改进,并应用于求解第3章中建立的库存协同调拨模型中。
4.1. 算法设计
1) 约束处理与适应度函数设计
采用具有动态罚因子的罚函数结合原约束优化问题的优化目标作为适应度函数。
2) 惯性权重改进设计
作为对粒子群优化算法性能具有很大影响的重要参数,惯性权重w能够有效地控制算法在问题空间的搜索能力与整体的收敛速度。惯性权重的大小决定了粒子对当前速度继承的多少,较大的惯性权重有利于算法全局搜索能力的提高;而较小的惯性权重则会增强算法对局部的搜索能力,有利于算法的收敛。
在实际应用中,以Shi等 [15] 提出的线性递减惯性权重策略(LDW)应用较为广泛,即:
(15)
式中, 、 分别为w的最大取值和最小取值,一种典型的取值为 ,t为当前迭代次数,T为最大迭代次数。
然而,上述对惯性权重的更新策略也存在一些不足。首先,若算法迭代初期已经有粒子接近最优点附近,则希望算法能收敛于最优点,而惯性权重的线性递减会降低算法的收敛速度。其次,在迭代后期,已经递减至较小的惯性权重会使得群体的多样性下降,导致算法易陷入局部极值点。
针对上述问题,本文采用了一种自组织惯性权重更新策略,可使得惯性权重按幂律分布规律进行变化。在迭代初期,惯性权重的减小较为缓慢,从而促使粒子搜索更大的区域,提高算法的全局搜索能力;而在迭代后期,使得惯性权重减小加快,从而引导粒子对当前区域进行更精细的搜索。自组织惯性权重的定义如下式(16)所示:
(16)
式中, 、 分别为惯性权重w的初始取值和最终取值,t为当前迭代次数,T为最大迭代次数。
3) 速度更新公式改进设计
经典的粒子群优化算法的速度更新公式如式(17)所示。
(17)
式中, 是为正的学习因子,往往取值为常数。一种典型的取值为 。
针对学习因子的动态调整,本文采用了一种异步变值的策略 [11],即学习因子 在迭代过程中的变化保持不同步。该策略是为了确保迭代初期粒子具有较强的全局搜索能力,而在迭代后期又能加强粒子的收敛能力,使粒子最终能更加精确的收敛到最优解。故随着迭代的增加,个体学习因子 应递减,因为在迭代的初期,粒子需要较大的个体学习能力和较小的群体学习能力,从而让粒子拥有较强的全局搜索能力。而群体学习因子 则正好相反,随迭代的增加而递增,因为在迭代的后期,粒子需要的是更大的群体学习能力与较小的个体学习能力,使粒子能尽快向全局最优解逼近。采用了异步变值策略的学习因子 的取值方式如下式(18)所示:
(18)
式中, 分别为个体学习因子 的初始值和最终值, 分别为群体学习因子 的初始值和最终值。
4) 位置更新公式设计
此处,位置更新公式仍采用经典的方法,如式(19)所示。
(19)
5) 变异算子设计
为了使粒子群优化算法在迭代过程中能开拓不断缩小的群体搜索区域,使粒子能够跳出先前寻找到的局部极值,并提高种群多样性。本文引入遗传算法中常用的变异算子,以一定的概率初始化部分粒子。
在每次迭代中,对群体规模为 的粒子群,随机抽样 个粒子( 为变异随机抽样比,且 ),判断这些粒子的适应度值与当前群体的全局极值的相对距离的绝对值,即:
(20)
式中, 为第i个被随机抽样选中的粒子适应度值,Gbest为全局极值。
若 ( 为变异阈值,需要提前自行设定),则对粒子 进行均匀变异,产生l个服从 分布的随机数 ,若 ( 为变异率),则对 进行均匀变异。假设变异点 处的变量取值范围为 ,则变异后的 由式(21)确定:
(21)
式中,r为服从 分布的随机数。
采用上述变异算子,可以有效地增强算法突破局部最极值的能力,克服了迭代后期群体多样性衰减和算法收敛于局部最极值的缺陷。
6) 最大限制速度 设计
最大限制速度 是用来限制粒子的飞行步长,代表速度取值的上界。Shi和Eberhart通过大量实验,发现 能间接地影响粒子群优化算法的全局搜索能力,即 的取值无论太大或太小都会使算法性能下降。一般来说,对于粒子中第k维变量的最大速度 取值为该变量最大取值和最小取值差的10%~20%。
7) 收敛准则设计
此处,本文同样采用双重收敛准则:
a) 达到总的进化代数T。
b) 连续I代进化的最优个体适应度值保持不变。
在粒子群优化算法的迭代中,如若满足这两个收敛条件中的任意一个,都会停止算法运行,并输出最终结果。
4.2. 算法流程
根据上述算法设计,本文采用的改进粒子群优化算法具体执行步骤如下:
Step 1:参数初始化。
在初始范围内,随机产生各粒子的位置和速度并将每个粒子的当前位置设置为个体极值Pbest,将所有Pbest中最优个体的位置存储于Gbest中,并设置迭代次数 。
Step 2:粒子速度与位置更新。
首先按式(16)更新惯性权重,然后按式(17)更新学习因子。最后按式(18)和式(19)对粒子的速度与位置进行更新。
Step 3:适应度评估。
根据适应度函数,计算每个粒子的适应度值。
Step 4:个体极值与全局极值更新。
对每个粒子,将其适应度值与当前个体极值Pbest作比较,若较好,将其作为新的个体极值Pbest。比较当前所有Pbest和Gbest的值,更新Gbest。
Step 5:执行变异算子。
首先计算每个粒子的适应度值与当前的全局极值的相对距离的绝对值,对于该值小于变异阈值的粒子,按式(21)执行均匀变异。
Step 6:判断算法是否满足收敛准则。若满足则结束算法,否则更新迭代次数 并转入Step 2。
根据上述步骤,得到改进算法的算法流程图如图2所示。
5. 模型试验
5.1. 库存协同补货模型参数设置
为了验证数据驱动的库存协同补货模型有效性,使用某家电企业产品A过去一季度的历史预测销量和历史真实销量进行试验。设置各线下门店初始在库库存为提前期内需求预测之和的0.8倍,初始在途库存为零,其余库存优化模型参数根据实际销售情况进行合理设置,如表2所示。
区域配送中心及6个线下门店间的距离如下表3所示。
5.2. 结果分析
设种群规模 ,最大进化代数 ,初始惯性权重 ,最终惯性权重 ,初始学习因子 ,最终学习因子 ,最大限制速度 ,变异阈值 ,变异率 ,变异随机抽样比 ,连续进化不改变最优解的代数阈值 ,使用Python进行程序编写,利用粒子群优化算法对不考虑横向调拨的纵向补货模型、基于可用库存最多点调拨策略的协同补货模型、基于距离最近点调拨策略的协同补货模型进行求解,适应度函数变化曲线如图3~5所示。
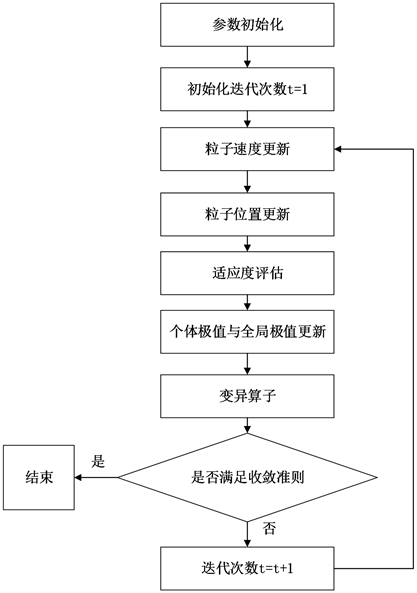
Figure 2. Algorithm flow diagram
图2. 算法流程图
Table 2. Model parameter setting
表2. 模型参数设置
Table 3. Distance setting between regional distribution centers and offline stores
表3. 区域配送中心及线下门店间距离设置
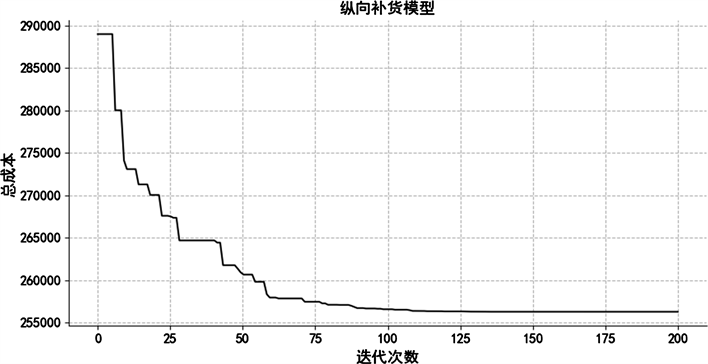
Figure 3. Horizontal replenishment model total cost convergence curve
图3. 纵向补货模型总成本收敛曲线
1) 不考虑横向调拨的纵向补货模型
从图3可知,在经过125次迭代后纵向补货总成本收敛曲线趋于平稳,不再有较大的波动,迭代200次所得到的各线下门店的最高库存水平折算天数为最优结果,求得纵向补货模型的最优总成本为256,281元。各线下门店的最高库存水平折算天数如表4所示。
Table 4. Horizontal replenishment model the maximum inventory level converted days
表4. 纵向补货模型最高库存水平折算天数
2) 基于可调拨量最多点策略的协同补货模型求解
从图4可知,在经过150次迭代后纵向补货总成本收敛曲线趋于平稳,不再有较大的波动,迭代200次所得到的各线下门店的最高库存水平折算天数为最优结果,求得纵向补货模型的最优总成本为238,319元。各线下门店的最高库存水平折算天数如表5所示。
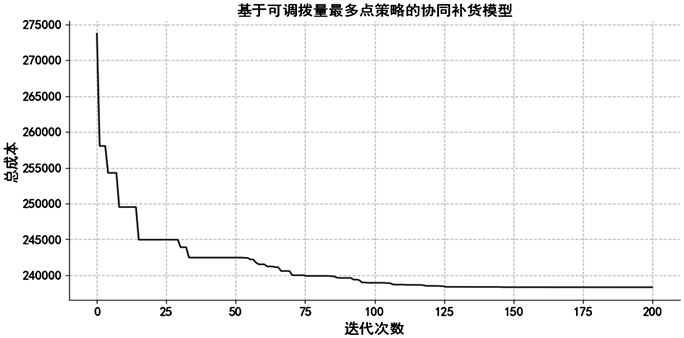
Figure 4. Maximum number of items available point strategy total cost convergence curve
图4. 可调拨量最多点策略总成本收敛曲线
Table 5. Maximum number of items available point strategy the maximum inventory level converted days
表5. 可调拨量最多点策略下最高库存水平折算天数
3) 基于距离最近点策略的协同补货模型求解

Figure 5. Nearest point strategy total cost convergence curve
图5. 距离最近点策略总成本收敛曲线
从图5可知,在经过110次迭代后纵向补货总成本收敛曲线趋于平稳,不再有较大的波动,迭代200次所得到的各线下门店的最高库存水平折算天数为最优结果,求得纵向补货模型的最优总成本为240330元。各线下门店的最高库存水平折算天数如表6所示。
Table 6. The maximum inventory level converted days under the nearest point strategy
表6. 距离最近点策略下最高库存水平折算天数
4) 成本分析
本节将从库存模型的各项成本对纵向补货模型、基于可调拨量最多点策略的协同补货模型、基于距离最近点策略的协同补货模型进行成本分析,以验证本文提出的两种数据驱动的协同补货模型的有效性。其中,纵向补货模型成本包括纵向补货成本、缺货成本和库存持有成本,协同补货模型包括纵向补货成本、缺货成本、库存持有成本和横向调拨成本,三个模型的各项成本细节如表7所示。
Table 7. Cost comparison of different models
表7. 各模型成本统计表
如表7所示,较纵向补货模型成本变化率列前者为基于可调拨量最多点策略的库存协同模型较纵向补货模型成本变化率,后者(括号内)为基于距离最近点策略的库存协同模型较纵向补货模型成本变化率。
基于可调拨量最多点策略的库存协同模型和基于距离最近点策略的库存协同模型的总成本分别为238,319元和240,330元,均低于纵向补货模型的总成本256,281元,且下降幅度均达到5%以上,可以证明本文提出的两个协同调拨模型可以有效降低企业的运营成本。通过对成本细节进行分析,可以发现总成本下降的主要原因是缺货成本及库存持有成本下降,降幅均达到了10%以上。产生的主要原因是在协同补货模型的最高库存水平折算天数明显小于纵向补货模型的最高库存天数,这也意味了企业可以纵向补货更频繁,减小每次补货的订货量,从而使库存持有成本降低。从横向调拨角度解读,线下门店间的横向调拨可以有效降低调出门店的库存持有成本和调入门店的缺货成本。两个库存协同模型的纵向补货成本均较纵向补货模型有所上升,产生的主要原因是协同补货模型中补货频次增加且满足了更多的线下门店需求,从而导致纵向补货固定成本及可变成本都有所增加。
5) 纵向补货及横向调拨分析
本小节将从库存模型的纵向补货、横向调拨次数和数量角度对纵向补货模型、基于可调拨量最多点策略的协同补货模型、基于距离最近点策略的协同补货模型进行分析,以验证本文提出的两种数据驱动的协同补货模型的有效性。
三个模型的纵向补货次数、订货量如表8、表9所示。通过粒子群优化算法求解得到纵向补货模型共补货63次,共计补货25,808单位商品;基于可调拨量最多点策略的协同补货模型共补货70次,共计补货26,099单位商品;基于距离最近点策略的协同补货模型共补货66次,共计补货25,980单位商品。协同补货模型的纵向补货次数和补货量都要大于纵向补货模型,补货次数的原因主要是因为协同补货模型的最高库存水平折算天数较高,库存周转率较低,且由于协同补货模型可以通过横向调拨将库存货物转运给缺货的线下店铺,使得自身库存水平更快降至再订货点。协同补货模型补货量较多的原因是通过横向调拨,可以满足更多的需求,因此也需要纵向转运更多的库存。
Table 8. Horizontal replenishment times of different models
表8. 各模型的纵向补货次数
Table 9. Horizontal replenishment quantity of different models
表9. 各模型的纵向补货订货量
通过求解,可以得到两个协同补货模型下各线下门店间的调拨量如表10和表11所示。可调拨量最多点策略下的调拨次数为30次,调拨量为686单位商品;距离最近点策略下的调拨次数为47次,调拨量为1373单位商品。距离最近点策略下的调拨次数与调拨量要显著大于可调拨量最多策略下的调拨次数与调拨量。通过对比两种库存协同补货模型,可以发现线下门店3和线下门店5的调入数量要明显小于其他线下门店,原因是因为线下门店3和线下门店5的需求波动相对较小且预测相对准确。
Table 10. Lateral transfers quantity under maximum number of items available point strategy
表10. 可调拨量最多点策略下调拨量
通过比较各线下门店的纵向补货量与横向调拨量,可以得出各线下门店的纵向补货量远大于横向调拨量,这也意味着需求主要依靠各门店的纵向补货来满足,横向调拨只是作为个线下门店缺货时的补充。
Table 11. Lateral transfers quantity under nearest point strategy
表11. 距离最近点策略下调拨量
6. 总结
本文以解决数据驱动的零售网络补货问题为出发点,针对库存补货环节开展研究。将一个区域配送中心和多个线下门店组成的库存系统作为研究对象,利用历史预测销量数据和历史实际销量数据,同时考虑纵向补货和横向调拨,以各线下门店最高库存水平折算天数为决策变量,以各线下门店可调拨库存量为约束,构建数据驱动的零售网络库存协同补货模型并设计改进粒子群优化算法进行求解。此外,考虑到各门店通过纵向补货后库存分布不均、需求不平稳等问题,设计了可调拨库存最多点策略和距离最近点策略两种横向调拨策略。力求通过更合理的库存补货方案为零售企业补货问题提供一定参考。
与之前的研究相比,本文主要的贡献有以下几点:1) 提出了两种库存横向调拨策略,提出了可调拨库存量最多点和距离最近点两种库存横向调拨策略,在库存纵向补货模型的基础上,考虑到现有横向调拨策略存在无效调拨的情况,构建了两种需要符合成本条件和在库库存大于设定临界值条件时才对缺货线下门店进行横向调拨的策略,填补了相关研究的空白。2) 构建了数据驱动的零售网络库存协同补货模型,针对销售预测误差和在库库存限制,进行零售网络库存补货优化。在二级零售网络结构中,将纵向补货和横向调拨进行协同考虑,以零售网络总成本最小为目标函数,以每个线下门店的最高库存水平折算天数为决策变量,最后利用改进粒子群算法进行求解。
文章引用
许东东,汪达钦. 数据驱动的零售网络库存补货研究
Research on Data-Driven Inventory Replenishment in Retail Network[J]. 管理科学与工程, 2022, 11(04): 565-581. https://doi.org/10.12677/MSE.2022.114070
参考文献
- 1. Wang, Y. and Shi, Q. (2019) Improved Dynamic PSO-Based Algorithm for Critical Spare Parts Supply Optimization under (T, S) Inventory Policy. IEEE Access, 7, 153694-153709.
https://doi.org/10.1109/ACCESS.2019.2948859 - 2. Yonit, B. and Opher, B. (2020) The residual Time Approach for (Q, r) Model under Perishability, General Lead Times, and Lost Sales. Mathematical Methods of Operations Research, 92, 601-648.
https://doi.org/10.1007/s00186-020-00717-7 - 3. 戢守峰, 曹楚, 黄小原. 基于CPFR的多产品分销系统库存优化模型[J]. 管理工程学报, 2008, 22(2): 98-101.
- 4. 周剑桥. 多约束单目标供应链多级库存控制模型及求解[J]. 控制工程, 2017, 24(3): 511-517.
- 5. Rego, J.R.D. and Mesquita, M.A.D. (2015) Demand Forecasting and Inventory Control: A Simulation Study on Automotive Spare Parts. International Journal of Production Economics, 161, 1-16.
https://doi.org/10.1016/j.ijpe.2014.11.009 - 6. Cao, Y. and Shen, Z.-J. (2019) Quantile Forecasting and Data-Driven Inventory Management under Nonstationary Demand. Operations Research Letters, 47, 465-472.
https://doi.org/10.1016/j.orl.2019.08.008 - 7. Wang, H., Fan, X., Zhang, Y., et al. (2020) Inventory Control Optimization via Neural-Nets Based Demand Prediction. 2020 Asia-Pacific International Symposium on Advanced Reliability and Maintenance Modeling (APARM), Vancouver, 20-23 August 2020, 1-6.
https://doi.org/10.1109/APARM49247.2020.9209515 - 8. Praveen, U., Farnaz, G. and Hatim, G. (2019) Inventory Management and Cost Reduction of Supply Chain Processes Using AI Based Time-Series Forecasting and ANN Modeling. Procedia Manufacturing, 38, 256-263.
https://doi.org/10.1016/j.promfg.2020.01.034 - 9. Banerjee, A., Burton, J. and Banerjee, S. (2003) A Simulation Study of Lateral Shipments in Single Supplier, Multiple Buyers Supply Chain Networks. International Journal of Production Economics, 81, 103-114.
https://doi.org/10.1016/S0925-5273(02)00366-3 - 10. Feng, P., Fung, R.Y.K. and Wu, F. (2017) Preventive Transshipment Decisions in a Multi-Location Inventory System with Dynamic Approach. Computers & Industrial Engineering, 104, 1-8.
https://doi.org/10.1016/j.cie.2016.12.005 - 11. Alvarez, E.M., van der Heijden, M.C., Vliegen, I.M.H. and Zijm, W.H.M. (2014) Service Differentiation through Selective Lateral Transshipments. European Journal of Operational Research, 237, 824-835.
https://doi.org/10.1016/j.ejor.2014.02.053 - 12. Purnomo, A. (2011) Multi-Echelon Inventory Model for Repairable Items Emergency with Lateral Transshipments in Retail Supply Chain. Australian Journal of Basic & Applied Sciences, 5, 462-474.
- 13. 霍佳震, 李虎. 零备件库存多点转运的批量订货模型与算法[J]. 系统工程理论与实践, 2007, 27(12): 62-67.
- 14. 徐小峰, 孙玉萍, 林姿汝. 缺货情形下轴辐式库存的纵横向协作调拨[J]. 运筹与管理, 2021, 30(10): 113-119.
- 15. Shi, Y. and Eberhart, R. (1998) A Modified Particle Swarm Optimization. 1998 IEEE International Conference on Evolutionary Computation Proceedings. IEEE World Congress on Computational Intelligence, Anchorage, 4-9 May 1998.