Computer Science and Application
Vol.
12
No.
04
(
2022
), Article ID:
49977
,
10
pages
10.12677/CSA.2022.124079
注意力机制引导的混合失真图像复原研究
龚敏学1,朱烨2,符颖1,2*
1成都信息工程大学,计算机学院,四川 成都
2四川省图形图像与空间信息2011协同创新中心,四川 成都
收稿日期:2022年3月1日;录用日期:2022年3月30日;发布日期:2022年4月6日

摘要
针对真实场景下多种混合失真组合的多任务图像复原,考虑到受不同退化机制影响的复原任务之间具有差异性和相似性,提出了一种由注意力机制引导的混合失真图像复原网络,该网络包含由任务驱动的操作层模块,利用注意力对不同退化机制的不同表现来解决混合失真这类多任务图像复原问题,从而更好地复原了受不同退化机制影响的图像。实验结果表明,相较于单任务复原模型,该方法对真实场景下混合失真组合图像的复原效果更佳。
关键词
混合失真图像,图像复原,注意力机制

Attention-Guided Image Restoration on Hybrid Distortion
Minxue Gong1, Ye Zhu2, Ying Fu1,2*
1School of Computer Science, Chengdu University of Information Technology, Chengdu Sichuan
22011 Collaborative Innovation Center of Graphics, Image and Spatial Information of Sichuan Province, Chengdu Sichuan
Received: Mar. 1st, 2022; accepted: Mar. 30th, 2022; published: Apr. 6th, 2022

ABSTRACT
Aiming at the multi-task image restoration of multiple hybrid distortion combinations in real scenes, considering the differences and similarities between image restoration tasks affected by different degradation mechanisms, an attention-guided hybrid-distorted image restoration network is proposed, which contains a task-driven operation layer module to solve the hybrid distortion multi-task image restoration problem by using the different performance of attention mechanism on different degradation mechanisms. The experimental results showed that, compared with the single-task restoration models, the proposed method has a better restoration effect on hybrid-distorted images in real scenes.
Keywords:Hybrid-Distorted Images, Image Restoration, Attention Mechanism

Copyright © 2022 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
图像复原,即从退化图像中复原真实清晰图像。传统方法通过对干净的自然图像进行建模来解决这个问题,研究人员根据统计学或基于物理学的模型设计图像先验,例如边缘统计 [1] [2] 和稀疏表示 [3] [4]。近年来,使用卷积神经网络的基于学习的方法已经被证明比以前依赖先验的传统方法效果更好,并提高了各种图像复原任务的性能水平,如去噪 [5] [6] [7]、去模糊 [8] [9] 和去雨 [10] [11]。
图像的退化机制(失真)有很多种类型,如高斯/椒盐噪声、失焦/运动模糊、JPEG压缩、雨滴和雾霾等。图像复原大致分为两种应用场景,一种是已知退化类型,比如照片编辑软件中实现的去模糊滤镜。另一种是包含混合失真类型的真实图像的复原,比如汽车自动驾驶中的应用。大多数现有研究都针对前一种情况,提出了很多单一任务的复原模型,在后者的应用上并不能取得良好的效果。在本文中,我们考虑后一种应用场景,处理真实场景下混合失真组合的图像复原问题。真实场景中的退化比我们想象的要复杂得多,目前处理这个问题的工作很少,下面主要介绍两项值得注意的研究工作:Zhang [12] 等人通过门融合网络实现图像超分和去模糊,该网络以低分辨率模糊图像作为输入,通过两个分支分别实现去模糊和超分,其中还加入了门模块自适应融合去模糊和超分辨率特征。Yu等人 [13] 提出了一个框架,其中多个轻量级CNN针对不同的图像退化机制进行训练,并通过深度强化学习的机制适应性地应用于输入图像。虽然他们的方法被证明是有效的,但仍存在一定的问题:一个是有限的准确性。与现有的针对单一任务的图像复原方法相比,该方法准确性提升不大;另一个问题是效率不高,它并行使用了多个小CNN,每个都需要预训练。
基于上述问题,本文提出了一个基于注意力机制的端到端的复原网络,该网络由特征提取模块、包含并行操作的基于注意力的操作层堆叠块,以及卷积输出层构成,使模型能够根据输入图像的不同退化类型选择适当操作进行图像复原。特征提取模块中引入了空洞卷积残差块,空洞卷积的使用主要是在原有卷积方式下增加了一个扩张率参数,增大感受野,较好地提取图像特征。空洞卷积比普通卷积核的叠加更能够提高多尺度的信息,所以应用于视觉任务时效果能优于普通卷积。采用跳跃连接,加强特征图的传递,并提升模型收敛速度。我们设计了一个能够并行执行多个操作(如不同参数的卷积和池化)的层,并为该层配备了一个注意力机制,对这些操作产生权重,目的是使注意力机制作为该层中这些操作的切换器。通过堆叠该层形成深层结构,通过梯度下降的方式进行端到端的训练。我们通过几个实验来评估方法的有效性。
本文的创新点包括以下两个方面:
1) 由于受不同退化机制影响的图像复原任务之间具有差异性和相似性,引入了由注意力机制引导的任务驱动操作层模块,以多个操作注意层堆叠形成深度网络,利用注意力对不同退化机制的不同表现来解决混合失真这类多任务图像复原问题。
2) 为了提高特征提取能力,增大感受野,同时减少参数量,避免细节信息丢失过多,在特征提取模块种引入了多尺度卷积组和空洞卷积残差模块。
2. 方法
本文提出的针对混合失真组合图像的复原网络结构如图1所示,它由三个部分组成:一个特征提取模块,一个基于注意力机制的任务驱动操作层的堆叠模块,以及一个输出层。

Figure 1. The network framework
图1. 网络框架图
2.1. 特征提取模块
特征提取模块由一个多尺度卷积组、一个空洞卷积残差块和两个标准残差块组成。由于多尺度的特征有利于图像相关任务,而CNN模型中的多尺度可以由卷积核的大小来体现,理论上更大的卷积核可以带来更丰富的信息,但不利于模型的训练。GoogLeNet [14] 在卷积层设计时,利用不同大小的卷积核对前一层网络的输出进行特征提取。受该研究工作的启发,本文设计了多尺度卷积组。在卷积核的选择上进行了多种组合测试,最终确定了3 × 3,5 × 5,7 × 7三种尺度的卷积核,同时对输入进行特征提取,然后拼接,进而组成新的特征图。每个标准残差块有两个卷积层,有16个大小为3 × 3的滤波器和ReLU激活函数层。空洞卷积残差模块是将残差模块中的卷积层替换成空洞率(dilated rate)为3的空洞卷积层,空洞卷积的使用主要是为了在参数量不变的情况下有效增大感受野。特征提取模块从一幅退化图像中提取特征,并将它们传递到操作注意层的堆叠模块。
2.2. 基于注意力机制的任务驱动操作层模块
基于注意力机制的任务驱动操作层模块是由多个操作注意层堆叠而成,而操作注意层是由一个操作层和一个注意层组成,由注意力机制对操作进行加权,具体结构见图2所示。操作层包含多个并行操作,比如不同参数进行卷积和池化。注意层以上一层生成的特征图作为输入,计算操作层并行输出的注意力权重。操作输出与它们各自注意力权重相乘,然后连接起来形成这一层的输出。我们的目的是让这种注意力机制根据输入作为不同操作的选择器,使网络适用于混合失真组合的图像复原,根据不同失真类型选择适当操作。
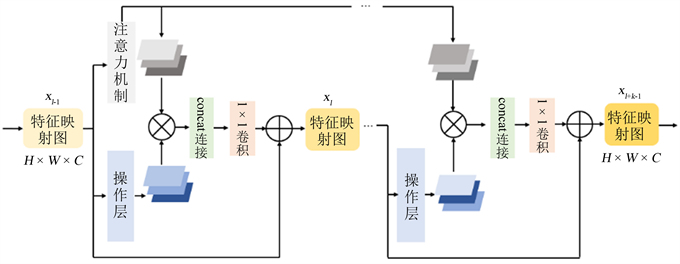
Figure 2. Attention-based task-driven operation block
图2. 基于注意力机制的任务驱动操作层模块
2.2.1. 操作注意力权重
本文用 表示第l-th个操作注意层的输出,其中H,W和C分别是它的高度、宽度和通道数,OP表示任意一个操作层中包含的一组操作,op表示单个操作。特征提取模块的输出作为任务驱动操作层模块中第一层的输入,用 表示。 , 是可学习的权重矩阵, 表示ReLU激活函数, 是输入x的一个包含通道平均值的向量,由下式可得:
(1)
是由注意层实现的映射,由下式得到:
(2)
如果使用完整特征图来生成注意力权重 ,计算量会很大,因此我们使用通道的平均值来生成注意权重。给定 ,通过下式计算每个操作的注意力权重:
(3)
在初步实验中发现,每隔几个操作注意层的第一层中生成注意权重,能够比在每一层中生成和使用注意权重使训练更加稳定。我们将多个操作的输出与上述计算的注意权重相乘。 表示第o-th个操作, 表示该操作的输出。我们将操作输出与注意力权重相乘,然后将其拼接起来,得到 ,如下式所示:
(4)
第l-th个操作注意层的输出由下式计算可得:
(5)
其中, 表示一个有C个滤波器的1×1卷积操作,这个操作使不同通道激活相互影响,并调整通道的数量。如图2所示,我们在每个操作注意层的输入和输出之间采用了跳跃连接。
2.2.2. 操作层
本文为操作层选择了8种操作:卷积核大小为1 × 1、3 × 3、5 × 5、7 × 7的可分离卷积,卷积核大小为3 × 3、5 × 5、7 × 7的空洞卷积,扩张率分别为1、6、12、18,兼具邻域和远距离的图像信息,以及感受野为3的平均池化。所有的卷积操作都使用C = 16的滤波器,之后是ReLU函数。同时,为了不改变输入和输出的大小,我们对每个操作中计算出的输入特征图进行了零填充。如图3所示,这些操作是并行执行的,并且它们在通道维度上是连接在一起的。操作输出和它们的注意力权重相乘然后连接起来形成这一层的输出以转移到下层。
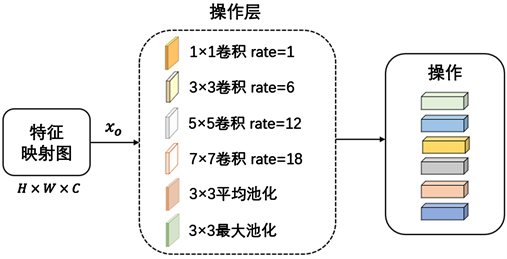
Figure 3. An example of the operation layer
图3. 操作层示例
2.2.3. 输出层
如前所述,本文的网络由三部分组成,即特征提取块、操作注意层的堆栈和输出层。对于输出层,我们使用一个内核大小为3 × 3的单一卷积层。如果输入/输出是灰度图像,滤波器的数量(即输出通道)为1,如果是彩色图像,则为3。
3. 实验
3.1. 实验配置
本文进行了几个实验来评估所提出的方法,在所有的实验中使用了一个具有40个操作注意层的网络。将每层的权重矩阵 、 的维度设置为T = 32,并在所有卷积层中使用16个卷积滤波器。在1.2.1节中提到的每隔几个操作注意层中,本文将四个连续的操作性注意力层视为一个群体(即k = 4)。使用复原后的图像和它们真值(Ground Truth)之间的 损失作为训练损失:
(6)
其中x是干净的图像,是y其退化版本,RN表示本文提出的复原网络,N是训练样本的数量,OWAN表示提议的操作注意网络。在我们的实验中,我们采用了Adam优化器,参数 ,,,同时采用了Loshchilov等人 [15] 提出的方法来调整学习率。我们对模型进行了100个epochs的训练,mini-batch设置为32,实验框架是PyTorch,本实验采用部署了英伟达RTX 2070SUPERx显卡的Linux服务器进行实验,并且配置了符合要求的加速平台和加速库。
3.2. 数据集与评价指标
本文提出的方法在DIV2K数据集和CSet8数据集上与其它经典的网络进行了比较。DIV2K数据集有800张高清大尺寸的图像,本文将其分为两部分,将前750张作为训练数据,剩余的50张图像用于测试。然后从这些图像中裁剪成63 × 63的小尺寸图像,分别得到249,344和3584张小尺寸图片组成的训练集和测试集。为了模拟真实复杂的退化场景,本文将高斯模糊、高斯噪声和JPEG压缩加入到图像中。高斯模糊和高斯噪声的标准差分别从[0, 5]和[0, 50]的范围内随机选择,JPEG压缩的质量从[10, 100]的范围内随机选择。根据其不同退化程度,本文将生成的退化图像分为三类:轻度(mild)、中度(moderate)和重度(severe)。训练只使用中度类别的图像,而测试则在所有类别上进行。CSet8是一个彩色图像数据集,包含8张256 × 256的彩色图像,本文将不同程度的高斯白噪声加入到图像中进行单一任务的测试。
对于不同网络生成的复原图像,需要将其与对应的清晰图像进行对比,用统一的标准定量评价模型的复原效果。峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)和结构相似度(Structural Similarity, SSIM)都是普遍用于评价图像的客观指标。前者通过均方差进行定义,一般取值范围为[20, 40],后者从亮度、对比度、结构三方面度量图像的相似性,取值范围为[0, 1],两张图像越相似,两个指标值越大,也即复原效果越佳。
3.3. 实验结果分析
3.3.1. 单一退化类型
如果真实图像确实只受到一种干扰,那么本文的混合失真图像复原算法对这特定的失真图像复原效果是否会好于单一失真图像复原算法,对这个问题的考察也很重要。为了证明本文方法的可扩展性以及鲁棒性,本文使用去噪常用的CSet8彩色图像数据集作为单一退化机制图像复原的验证数据集。所以,我们在经过噪声处理后的数据集上进行了测试,和一个自监督学习的端到端去噪网络Self2self [16] 进行对比,处理单一退化类型的图像复原问题。
如图4所示,图像上的细节放大在每张图像下方,随着噪声强度变大,可以看到,用Self2self复原的图像整体趋于平滑,去掉了图像中高频信息,图像反而变得模糊,影响了复原图像的视觉效果。

Figure 4. Examples of denoised images by Self2self and our method
图4. 去噪实验结果图
如表1和表2所示,对于不同程度的高斯白噪声,本文方法在两个客观指标PSNR和SSIM上的表现均优于无监督单一去噪网络Self2self。

Table 1. The experimental results
表1. 实验结果(PSNR)
Table 2. The experimental results
表2. 实验结果(SSIM)
3.3.2. 混合失真组合图像类型
本文在DIV2K数据集上评估了本文方法的性能,对包含有噪声、压缩和模糊这三种混合失真组合的图像进行复原,并与以前的方法进行了比较。如前文提到的DnCNN使用端到端的神经网络模型来进行加性高斯白噪声AWGN (Additive White Gaussian Noise,最基本的噪声和干扰模型)的降噪,首次使用残差学习来降噪。复原模型RL-Restore [13] 需要事先针对多种已知的退化水平和类型对一组CNN进行预训练,该方法对12个CNN模型在具有单一失真类型和水平的图像上进行训练,例如,高斯模糊、高斯噪声和JPEG压缩。本文方法不需要对模型进行预训练,并且只对单一模型以端到端的方式进行标准训练。这对真实世界的失真图像复原上的应用是有利的,因为很难事先确定真实图像具体遭受了哪些类型的失真。
图5~7分别展示了由本文方法、RL-Restore和端对端复原模型Owan [17] 所恢复图像的例子,以及输入图像和Ground Truth。从图5可以看出,对于退化程度为9%~11%的轻度退化mild类型,同样是针对混合失真图像复原的Owan处理得比较平滑,而RL-Restore复原图像中部分噪点未被去除。退化程度为12%~17%的moderate类型,边缘模糊程度加深,从对比图6中可以看出Owan复原了纹理细节,但颜色与清晰图像略有差别,RL-Restore复原的图像丢失了一些纹理细节。对于退化程度为18%~20%的重度退化severe类型,图像严重失真,纹理基本丢失,图像前景只剩隐约轮廓,图7可以看到,本文方法复原效果相对较好一些,背景颜色与清晰图像基本一致,其余方法部分复原图像前景背景模糊,未能有效区分,严重影响到了复原图像的视觉展示效果。

Figure 5. Examples of restored images by RL-Restore, Owan and our method
图5. 轻度退化图像复原实验结果

Figure 6. Examples of restored images by RL-Restore, Owan and our method
图6. 中度退化图像复原实验结果

Figure 7. Examples of restored images by RL-Restore, Owan and our method
图7. 重度退化图像复原实验结果
就客观评价指标而言,从表3和表4可以看出,本文所提出的方法对于三种不同退化类型的混合失真组合图像的复原任务在PSNR和SSIM方面的表现均优于现有的一些方法,取得了一定的提升。
Table 3. Results on DIV2K
表3. 实验结果对比(PSNR)
Table 4. Results on DIV2K
表4. 实验结果对比(SSIM)
4. 结束语
本文提出了一个面向真实场景下的图像复原网络,用于恢复具有未知比例和强度的混合失真组合的图像,它能够根据输入信号,在一个操作层中并行执行多种操作,并由注意力机制加权,根据输入的特征映射决定操作的选择/切换器,具有不同失真类型和强度的输入表现不同,从而起到合理分配计算资源的作用。这个具有注意机制的层可以堆叠形成一个深度网络,可以用梯度下降法进行端到端的训练。从对比实验结果可以看出,本文方法不仅适用于混合失真组合图像的复原,对单一任务的复原效果也优于其它方法。
但本文方法仍旧是基于监督学习的图像复原研究,需要依靠成对的清晰/退化图像数据集进行训练,而成对样本获取难度高、代价大,因此后期主要在无监督的非成对样本上进行研究工作。
基金项目
本文作者符颖得到省级项目基金资助:
四川省科技厅重点研发项目(2020YFG0453,8K超短焦光学镜头关键技术研究及应用);
四川省科技厅“新一代人工智能平台”重大专项(2019DZX0005,面向开放共享的云深度学习专用平台)。
文章引用
龚敏学,朱 烨,符 颖. 注意力机制引导的混合失真图像复原研究
Attention-Guided Image Restoration on Hybrid Distortion[J]. 计算机科学与应用, 2022, 12(04): 775-784. https://doi.org/10.12677/CSA.2022.124079
参考文献
- 1. Perrone, D. and Favaro, P. (2014) Total Variation Blind Deconvolution: The Devil Is in the Details. 2014 IEEE Confer-ence on Computer Vision and Pattern Recognition, Columbus, 23-28 June 2014, 2909-2916. https://doi.org/10.1109/CVPR.2014.372
- 2. Fattal, R. (2007) Image Upsampling via Imposed Edge Statistics. ACM Transactions on Graphics, 26, 95-es. https://doi.org/10.1145/1276377.1276496
- 3. Yang, J., Wright, W., Huang, T.S. and Ma, Y. (2010) Image Su-per-Resolution via Sparse Representation. IEEE Transactions on Image Processing, 19, 2861-2873. https://doi.org/10.1109/TIP.2010.2050625
- 4. Aharon, M., Elad, M. and Bruckstein, A. (2006) K-SVD: An Al-gorithm for Designing Overcomplete Dictionaries for Sparse Representation. Proc of the IEEE Transactions on Signal Processing, 54, 4311-4322. https://doi.org/10.1109/TSP.2006.881199
- 5. Xie, J., Xu, L. and Chen, E. (2012) Image Denoising and Inpaint-ing with Deep Neural Networks. Proceedings of the 26th Annual Conference on Advances in Neural Information Pro-cessing Systems, Lake Tahoe, 3-6 December 2012, 341-349.
- 6. Zhang, K., Zuo, W. and Zhang, L. (2018) FFDNet: Toward a Fast and Flexible Solution for CNN Based Image Denoising. Proc of the IEEE Transactions on Image Pro-cessing, 27, 4608-4622. https://doi.org/10.1109/TIP.2018.2839891
- 7. Zhang, K., Zuo, W., Zhang, L., Meng, D. and Zhang, L. (2017) Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. Proc of the IEEE Transactions on Image Processing, 26, 3142-3155. https://doi.org/10.1109/TIP.2017.2662206
- 8. Kupyn, O., Budzan, V., Mykhailych, M., Mishkin, D. and Matas, J. (2018) Deblurgan: Blind Motion Deblurring Using Conditional Adversarial Networks. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, 18-23 June 2018, 8183-8192. https://doi.org/10.1109/CVPR.2018.00854
- 9. Sun, J., Cao, W., Xu, Z. and Ponce, J. (2015) Learning a Convo-lutional Neural Network for Non-Uniform Motion Blur Removal. Proc of IEEE Conference on Computer Vision and Pattern Recognition, Boston, 7-12 June 2015, 769-777. https://doi.org/10.1109/CVPR.2015.7298677
- 10. Yang, W., Robby, T.T., Feng, J., Liu, J., Guo, Z. and Yan, S. (2017) Deep Joint Rain Detection and Removal from a Single Image. 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, 21-26 July 2017, 1685-1694. https://doi.org/10.1109/CVPR.2017.183https://arxiv.org/abs/1609.07769
- 11. Li, G., He, X., Zhang, W., Chang, H., Dong, L. and Lin, L. (2018) Non-Locally Enhanced Encoder-Decoder Network for Single Image De-Raining. Proceedings of the 26th ACM interna-tional conference on Multimedia, Seoul, 22-26 October 2018, 1056-1064. https://doi.org/10.1145/3240508.3240636
- 12. Zhang, X., Dong, H., Hu, Z., Lai, W.-S., Wang, F. and Yang, M.-H. (2020) Gated Fusion Network for Degraded Image Super Resolution. International Journal of Computer Vision, 128, 1699-1721. https://doi.org/10.1007/s11263-019-01285-y
- 13. Yu, K., Dong, C., Lin, L. and Loy, C.C. (2018) Crafting a Toolchain for Image Restoration by Deep Reinforcement Learning. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, 18-23 June 2018, 2443-2452. https://doi.org/10.1109/CVPR.2018.00259
- 14. Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., et al. (2015) Going Deeper with Convolutions. IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, 7-12 June 2015, 1-9. https://doi.org/10.1109/CVPR.2015.7298594
- 15. Loshchilov, I. and Hutter, F. (2016) SGDR: Stochastic Gradient Descent with Warm Restarts. 5th International Conference on Learning Representations, Toulon, 24-26 April 2016, arXiv preprint arXiv: 1608.03983.
- 16. Quan, Y., Chen, M., Pang, T. and Ji, H. (2020) Self-2-Self with Dropout: Learning Self-Supervised Denoising from Single Image. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, 13-19 June 2020, 1887-1895. https://doi.org/10.1109/CVPR42600.2020.00196
- 17. Suganuma, M., Liu, X. and Okatani, T. (2019) Atten-tion-Based Adaptive Selection of Operations for Image Restoration in the Presence of Unknown Combined Distortions. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, 15-20 June 2019, 9031-9040. https://doi.org/10.1109/CVPR.2019.00925
NOTES
*通讯作者。