Advances in Applied Mathematics
Vol.
08
No.
12
(
2019
), Article ID:
33590
,
10
pages
10.12677/AAM.2019.812237
Research on the Classification of Manufacturing Performance Evaluation in Guizhou Based on NaiveBayes Model
Mengqiu Kong1, Youfu Wu2
1School of Data Science and Information Engineering, Guizhou Minzu University, Guiyang Guizhou
2Guizhou Vocational and Technical College of communications, Guiyang Guizhou

Received: Nov. 28th, 2019; accepted: Dec. 17th, 2019; published: Dec. 24th, 2019

ABSTRACT
In this paper, NaiveBayes model is introduced into the classification of performance evaluation of manufacturing industry in Guizhou Province. 529 audited and unqualified financial statement data of manufacturing industry in Guizhou Province from 2014 to 2017 are collected. Combined with the standard value of enterprise performance evaluation published by the state, the performance factors of profitability, operation ability and solvency are quantified by sections. By constructing a series of variables, this paper establishes the financial ability classification model of enterprise performance evaluation, and explores the relationship between the performance evaluation content of manufacturing industry and other subjects of financial statements. Under the evaluation criteria of accuracy and AUC, the results of model training and empirical analysis show that the performance of NaiveBayes model is better than that of logistic regression model, BP neural network and binary SVM and decision tree.
Keywords:Profitability, Operating Capacity, Solvency, Financial Statements, NaiveBayes Model

基于NaiveBayes模型的贵州制造业绩效评价的分类研究
孔梦秋1,吴有富2
1贵州民族大学数据科学与信息工程学院,贵州 贵阳
2贵州交通职业技术学院,贵州 贵阳

收稿日期:2019年11月28日;录用日期:2019年12月17日;发布日期:2019年12月24日

摘 要
本文将NaiveBayes模型引入到贵州省制造业绩效评价的分类中,收集2014~2017年贵州省制造业529份经审计无保留意见财务报表数据,结合国家年度公布的《国家企业绩效评价标准值》,分别对盈利能力、营运能力、偿债能力三个方面财务能力下的绩效因子进行分段量化。通过财务报表科目构造一系列的变量,建立企业绩效评价的财务能力分类模型,探索制造业的绩效评价内容与财务报表其他科目之间的关系。在Accuracy和AUC评价准则下,通过模型训练和实证分析结果表明NaiveBayes模型的表现优于logistic回归模型,BP神经网络,二分类SVM以及决策树。
关键词 :盈利能力,营运能力,偿债能力,财务报表,NaiveBayes模型

Copyright © 2019 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
随着社会经济的飞跃发展,企业绩效评价的理论和方法探索已变成研究热点。王全在 [1] 运用因子分析提取公共因子,通过各因子的比重权数,分别计算2013年到2015年26家汽车制造业上市公司最终绩效得分值,最后以三年的绩效得分的几何平均值作为公司的综合财务绩效得分排名,最终得出各企业的综合能力情况并对排名靠后的企业提出相应的建议。陈姿颖 [2] 依据平衡计分卡原理并结合港口实际,选取绩效评价指标,运用K-MEANS算法对样本数据进行聚类,将港口经营绩效分为A、B、C三个等级,利用BP神经网络模型评价5家港务公司的经营绩效。褚淑贞 [3] 基于《国有资本金效绩评价规则》规定的效绩评价内容选取指标体系,利用BP神经网络学习算法通过样本数据建立仿真训练模型,得到15家上市企业的我国中成药上市企业的仿真结果排序与期望输出排序一致,证明BP神经网络模型对医药企业的绩效评价是有效的。朱和平 [4] 运用因子分析法选取影响公司绩效评价的因子,基于TOPSIS模型的因子得分结果的面板数据构建评价模型,利用聚类分析对TOPSIS评价结果进行系统聚类,客服了因子分析要求数据单一性的缺陷。
大多数研究基于几个固定的财务绩效评价内容角度或宏观的方法进行企业的绩效评价 [1] - [8],忽略了企业的财务绩效评价内容与财务报表其他科目之间隐藏的关系,以及这种关系对企业的资产结构产生的影响。本文从一个全新全面角度,通过大数据分析,利用年度公布国家《企业绩效评价标准值》,对盈利能力、营运能力、偿债能力三个财务绩效评价内容下的绩效因子进行分段量化,对某一能力下绩效因子量化得分加总处理后作为因变量,通过对绩效因子以外的报表科目加工构造一系列的变量,最后利用NaiveBayes (以下简称NB)模型 [9] 对制造业企业绩效评价的关键财务能力进行分类,探索制造业企业的绩效评价内容与财务报表其他科目之间的关系。为了阅读方便,我们在此先介绍NB模型。
2. NB模型
给定n维向量 ,拟分成m个类 。在条件X下,NB分类法预测 属于类 ,当且仅当
由贝叶斯定理
根据NB分类算法的类条件独立的假定
(1)
1) 式中 可由训练样本估计,为了预测X的属类标号,对于每个类 ,可以计算出 。若先验概率 未知,可假设 相同,此时最大化 即可。否则最大化 ,,其中D是训练样本总数, 是类 在D中的训练元组数。
NB分类法预测输入X的类 ,当且仅当
由此可得
即使 或 最大的类 为被预测的类标号。
3. 模型评价指标
为了能够客观地评价分类模型的性能,常采用的指标有精准率、召回率、准确率、F值和AUC值等。目前在制造业绩效评价领域里,模型评价体系并不完善,这里我们选用准确率和AUC值来对本文的二分类模型的建模效果进行评估比较。
3.1. 准确率(Accuracy)指标
本文重复进行N次试验,每次的实验结果用 来表示,采用N次实验结果中准确率最高的一次作为衡量模型的准确度:
准确率越高,模型的分类效果越好。本文 。
3.2. AUC指标
本文考察制造业绩效评价内容 的优或差,利用NB模型进行分类识别。若 为“优”的概率大于预先设定的阈值 ,,则将其判别为“1”,否则为“0”。 的取值由实际情况而定。由于我们需要对绩效评价内容 的优或差进行分类,相应地就产生了两个指标:真正例率(TPR)和假正例率(FPR),前者表示将 为“优”(或“1”)正确分类的概率;后者表示将 的“差”(或“0”)错误分类为“优”(或“1”)的概率。我们用下面的混淆矩阵来解释上述两个指标的计算(表1):

Table 1. Confusion matrix
表1. 混淆矩阵
上述两个指标的计算公式可表示为:真正例率(TPR) = TP/(TP + FN);假正例率(FPR) = FP/(FP + TN)。理想状态下,TPR应该接近于1,FPR应该接近于0,所以模型中我们希望TPR尽量大,FPR尽量小,这取决于我们预先设定的阈值 。实际上TPR与FPR具有同向变化关系,我们可以画出ROC曲线(图1)。

Figure 1. ROC curve
图1. ROC曲线图
模型效果越好,则ROC曲线越远离对角线,极端的情形是ROC曲线经过(0,1)点,即将“1”全部预测为“1”而将“0”全部预测为“0”。ROC曲线与FPR轴围成的面积称为AUC值,用来定量地评价模型的效果,AUC值越大,说明模型的分类效果越好。
4. 变量选取
4.1. 因变量的选取
基于相关研究 [1] [4] [5] [6] [9] [10] 的基础及《企业效绩评价操作细则》(修订)的规定并结合实际,选取盈利能力、营运能力和偿债能力下的财务绩效因子分别对其量化后作为因变量,基本情况如下表2:
Table 2. Description of dependent variables
表2. 因变量的情况说明
给绩效因子赋值为Y,设定一个固定值a (参照2016年《国家企业标准值》 [11] ),若
其中X是绩效因子的具体值。
Table 3. Profitability indicators
表3. 盈利能力指标情况
将盈利能力指标(表3)的绩效因子得分加总,记加总得分为x,x取值为0、1、2、3、4、5,若
其中y代表盈利能力指标值,y为“1”说明企业的收益和盈利情况较好。鉴于营运能力和偿债能力的处理方法与盈利能力相似,故在此不再一一赘述。
按样本数据的70%划分为训练集,30%为测试集,用决策树模型分类,结果如下:
Table 4. Classification accuracy and effect
表4. 分类准确率及效果
表4说明我们通过设定固定值,对财务指标的绩效因子进行加总得分的处理效果是可以的。从而得到因变量为0~1变量,y为“0”表示该项能力“差”,“1”表示其能力为“优”,这就挑选出财务绩效较好的样本(优质客户)参与下一步的企业绩效评价分类建模。
4.2. 解释变量选取及说明
为进一步探索制造业的绩效评价内容与财务报表其他科目之间的关系,通过财务报表科目构造一系列的变量,建立企业绩效评价的财务能力分类模型。由于数据的冗余变量和无关变量会对模型的训练时间、预测精度和简洁性会产生不利影响 [12],并且变量较多,故这里我们选择用基于距离相关性的DS-SIS的独立筛选方法达到降维的目的 [13],从构造72个变量中最终筛选出18个自变量进入模型,变量基本情况如下表5所示:
Table 5. Explanation and meaning in autovariation
表5. 自变量解释及含义
5. 实证分析
5.1. 数据来源
本文所用的数据来源于某商业银行2014~2017年贵州省制造业529份财务报表数据,这些财务报表均经过审计且是标准无保留意见的。原始数据共有38,088个记录,根据实际需要通过对财务报表中的某些科目进行加工构造了72个变量。
5.2. 数据预处理
将样本数据中为0或空值占比大于或等于9%的无关变量剔除,剩余54个变量,空值均采用均值补缺。然后选用基于距离相关性的DS-SIS的独立筛选方法进行降维 [13],最终筛选出18个自变量进入模型。
为了消除数据方向和量纲的差异性影响,采用Z-score
对数据进行标准化处理。处理后的数据按10折交叉划分为训练集和测试集。
5.3. 建模结果分析
分别以绩效评价内容的三个能力指标为因变量,18个变量作为自变量,通过NB分类算法建立模型。
Table 6. Classification results of NB model on profitability indicator test set data
表6. NaiveBayes模型对盈利能力指标测试集数据的分类结果
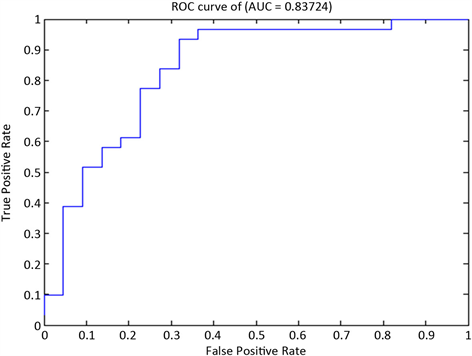
Figure 2. ROC curve of NB classification model on the profitability indicator test set
图2. NB分类模型在盈利能力指标测试集上的ROC曲线
在表6中,表明有2份盈利能力为“优”的财务报表,被误判为“差”,有5份盈利能力为“差”的财务报表,被误判为“优”,剩余46份财务报表的分类正确。模型的总体分类准确率为86.79%,AUC值为0.8374。
Table 7. Classification results of NB model on operational capacity indicator test set data
表7. NB模型对营运能力指标测试集数据的分类结果
表7中,52份财务报表参与测试,仅有1份盈利能力为“优”的财务报表,被误判为“差”,有5份盈利能力为“差”的财务报表,被误判为“优”,剩余46份财务报表的分类正确。模型的总体分类准确率为88.46%,AUC值为0.8679。
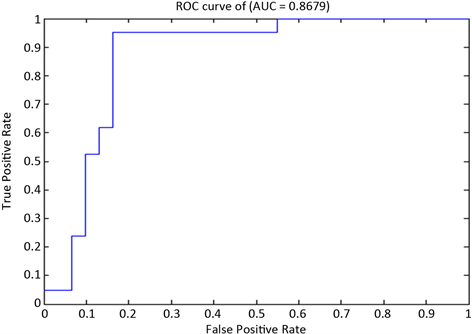
Figure 3. ROC curve of NB classification model on operational capacity indicator test set
图3. NB分类模型在营运能力指标测试集上ROC曲线
Table 8. Classification results of NB model on solvency indicator test set data
表8. NB模型对偿债能力指标测试集数据的分类结果
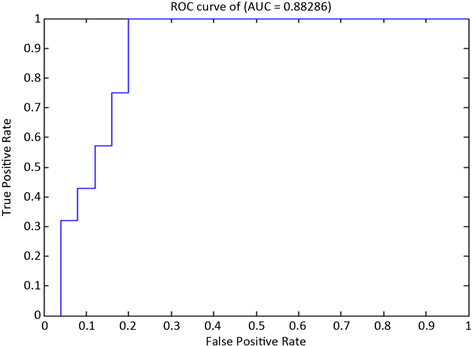
Figure 4. ROC curve of NB classification model on solvency indicator test set
图4. NB分类模型在偿债能力指标测试集上的ROC曲线
表8中,只有5份偿债能力为“差”的财务报表,被误判为“差”,剩余的48份财务报表被正确分类。模型的总体分类准确率为90.57%,AUC值为0.8829。
由此说明NB模型对制造业企业的三个财务能力分类效果较好,即绩效因子以外的报表科目通过构造加工后与关键的企业绩效评价内容之间存在较好的相关性,这些构造加工的变量可以作为衡量企业绩效的重要因素,从企业资产结构配置的合理性,能够更全面地对企业的财务绩效进行评价。
企业绩效评价模型中常用的模型有BP神经网络,logistic回归模型,本文首次将NaiveBayes分类模型应用于制造业的绩效评价分类,并与BP神经网络、logistic回归、支持向量机以及决策树模型进行比较,各模型均用MATLAB R2014a软件完成,运行的结果如下表9所示:
Table 9. Empirical results of each performance evaluation classification model
表9. 各绩效评价分类模型的实证结果
由上表可以看出:对于制造业企业绩效评价分类模型,logistic回归模型虽然本身较为稳定,但是建模结果是最不理想的,尤其盈利能力指标的分类,准确率比其他都低,仅为0.4906,但是模型AUC值大于0.5,说明该模型还是有意义的。决策树模型是有监督分类,属于机器学习的范畴,对样本数据不需要作何假设,但是当类别多时,可能会增加错误率。支持向量机和BP神经网络是人工智能和机器学习领域的方法,能够模拟数据间复杂的线性关系,但模型缺乏可解释性,从建模结果来看,支持向量机模型在acc和AUC指标上的表现仅次于朴素贝叶斯模型。朴素贝叶斯分类算法比较简单,拥有稳定的分类效率,由本文的建模结果分析可以说明朴素贝叶斯模型对于三个财务绩效指标的分类在acc和AUC值上的表现是最好的。
6. 结束语
本文首次将NaiveBayes模型应用于制造业企业的绩效评价分类,从建模结果来看,相比于其他几个评价模型,NaiveBayes分类模型的表现是最好的,该模型在实际应用中算法简单灵活,有较强的可操作性,能够更好地探索制造业企业的绩效评价内容与财务报表其他科目之间的关系。一方面促使企业优化自身的资产结构配置,避免盲目扩张;另一方面帮助银行等金融机构在进行客户选择、信贷投放时作为参考,以及从报表结构的合理性去识别粉饰的报表有借鉴作用,使得企业的绩效评价方法更为全面,以期为制造业企业的绩效评价机制带来新的思路与应用价值。
基金项目
贵州省教育厅高等学校人文社会科学研究项目资助。项目名称:大数据背景下贵州省制造业绩效评价研究(编号:2019dxs027)。
文章引用
孔梦秋,吴有富. 基于NaiveBayes模型的贵州制造业绩效评价的分类研究
Research on the Classification of Manufacturing Performance Evaluation in Guizhou Based on NaiveBayes Model[J]. 应用数学进展, 2019, 08(12): 2062-2071. https://doi.org/10.12677/AAM.2019.812237
参考文献
- 1. 王全在. 基于因子分析模型的汽车制造行业绩效评价研究[J]. 会计之友, 2017(23): 25-30.
- 2. 陈姿颖. BP神经网络在港口绩效中的应用研究[D]: [硕士学位论文]. 北京: 交通大学, 2015.
- 3. 褚淑珍, 杨佳欢. BP神经网络在医药企业绩效评价中的应用——以我国中成药上市企业为例[J]. 新药述评与论坛, 2015, 24(17): 1925-1929.
- 4. 朱和平, 郭佳佳. 基于TOPSIS方法的财务绩效发展评价研究——以无锡制造业上市公司为样本[J]. 会计之友, 2017(12): 57-63.
- 5. 何清, 陈晓芳. 基于社会经济综合效益的制造业绩效评价研究[J]. 财会通讯, 2012(16): 19-21.
- 6. 曾雄旺, 朱敏迪, 杨亦民. 上市农业产业化龙头企业财务绩效评价[J]. 会计之友, 2017(10): 73-77.
- 7. 杨小兰, 孙兴. 贵州省制造业信息化年度绩效评价指标体系研究与设计[J]. 科技情报开发与经济, 2009(5): 63-65.
- 8. 米妍, 谢瑞峰, 李洁. 资本结构与企业绩效相关性研究——基于中小板制造业上市公司实证分析[J]. 商业会计, 2017(22): 50-53.
- 9. 蒙肖莲, 杜宽旗, 杨毓. 企业财务危机预测的贝叶斯模型研究[J]. 数理统计与管理, 2011(6): 1039-1050.
- 10. 王润. 东阿阿胶股份有限公司财务报表分析[J]. 河北企业, 2018(8): 88-89.
- 11. 国务院国资委财务监督与考核评价局. 企业绩效评价标准值[M]. 北京: 经济科学出版社, 2016: 1-5.
- 12. 胡心瀚, 叶五一, 缪柏其. 上市公司信用风险分析模型中的变量选择[J]. 数理统计与管理, 2012, 31(6): 1117-1124.
- 13. Li, R., Zhong, W. and Zhu, L. (2012) Feature Screening via Distance Correlation Learning. Journal of the American Statistical Association, 107, 1129-1139.