Hans Journal of Data Mining
Vol.
12
No.
04
(
2022
), Article ID:
56469
,
14
pages
10.12677/HJDM.2022.124031
基于排名机制的领域Web网页发现
王安涛,李征宇,李贵
沈阳建筑大学,信息与控制工程学院,辽宁 沈阳
收稿日期:2022年8月22日;录用日期:2022年9月22日;发布日期:2022年9月30日

摘要
对很多Web数据集成应用来说,领域Web发现能力至关重要。从目前来看,现有的主题爬取策略依然有效,并随之产生了不少依据这些策略的主题爬虫,然而配置主题爬虫困难且费时,因此提出基于排名机制的领域Web网页发现算法,该算法在现有的主题爬取策略之上,利用给定的样本网页集,使用基于排名的方法,系统地结合多种Web网页发现策略,迭代发现并提取领域Web新网页。实验表明,该方法具有较高的网页准确率,验证了方法的有效性。
关键词
主题爬取,网页排名,领域Web网页发现

Domain Web Pages Discovery Based on Ranking Mechanism
Antao Wang, Zhengyu Li, Gui Li
School of Information & Control Engineering, Shenyang Jianzhu University, Shenyang Liaoning
Received: Aug. 22nd, 2022; accepted: Sep. 22nd, 2022; published: Sep. 30th, 2022

ABSTRACT
Domain Web discovery capabilities are critical to many Web data integration applications. From the current point of view, the existing focused crawling strategies are still effective, and many focused crawlers based on these strategies have been created. However, configuring focused crawlers is difficult and time-consuming. Therefore, a domain Web page discovery algorithm based on ranking mechanism is proposed. Based on the existing focused crawling strategies, the algorithm uses a given set of sample web pages, uses a ranking-based method, and systematically combines various web page discovery strategies to iteratively discover and extract new web pages in the domain. Experiments show that the method has high web page accuracy, which verifies the effectiveness of the method.
Keywords:Focused Crawling, Page Rank, Domain Web Pages Discovery

Copyright © 2022 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
互联网高速发展的今天,对于网页信息的获取,一种很自然的想法是使用通用的商业搜索引擎,如:谷歌(Google)、百度(Baidu)、必应(Bing)。我们主要使用基于关键字的搜索以及类似站点的相关搜索,这就要求我们需要阅读大量搜索引擎返回给我们的检索信息,来提取结果。显而易见,对于大规模的数据收集任务,这种信息获取的方式是复杂且低效的。并且对于通常具有特定检索目的、特定领域、特定背景的用户来说,通用搜索引擎返回的结果可能包含大量无用的网页信息 [1]。
为解决上述搜索引擎所出现的问题,近些年来也提出了不同的方法来解决这些问题:
1) 领域发现工具(Domain Discovery Tool, DDT) [2]:DDT旨在简化对于给定领域构造分类器的过程,以帮助用户发现相关网页。它提供了一个易于使用的界面,这个界面总结了搜索结果并且帮助用户创建查询计划。
2) 前后爬取(Forward and Backward Crawling) [3] 以及DEXTER [4]:它们均用于自动发现Web网页内容。由于它们依赖域分类器,所以它们需要适应不同域。
为了解决这些问题:提出了基于排名机制的领域Web网页发现算法框架DWDBRM (Domain Web pages Discovery Based on Ranking Mechanism),DWDBRM不依赖精确域分类器,该算法通过给出小部分有代表性的样本网页,就可以自动发现额外相关网页,这些网页不仅可以用于构造域分类器,而且可以充当主题爬取的种子网页集。它的主要贡献如下:
1) 自助领域发现需要精确域分类器,而该方法仅需要一组小样本有代表性的网页就可以自动发现相关Web网页,不需要精确域分类器;
2) 由于现有的各种独立网页排名方法适用于不同领域,并且存在效率和精度的差异,因此本文提出一种组合网页排名方法,组合多种独立排名函数,对网页进行排名;
3) 目前所做的发现工作均不支持多种搜索技术,因此本文在此框架中结合多种不同的搜索技术,主要做法是:在每轮迭代中使用multi-armed bandits-based [5] 策略来选择最佳搜索操作。实验表明,通过使用multi-armed bandits-based策略,我们的方法能够获得较高网页收获率(即相关网页或相关网站与检索的网页数量的比值)。
2. 相关工作
针对领域Web网页发现,已经提出过多种技术,这些技术大致可以分为两类:
1) 基本搜索发现技术(Search-based discovery techniques):该技术依赖于搜索引擎API (例如:Google、Bing、Baidu)来查找与给定关键字类似的Web网页。
2) 基本爬取发现技术(Crawling-based Discovery techniques):该技术通过自动下载和递归的方式利用已有的Web网页链接来爬取新网页。
2.1. 基本搜索发现技术
关键字搜索和相关搜索这两种基本搜索发现操作是通过搜索引擎API来实现的,然而大多数现存的搜索技术使用关键字搜索。
文献 [6] [7] 使用网页内容与Web链接结构来计算Web网页之间的相关性。文献 [8] 提出了一个使用相关反馈的系统来收集种子网页以自助主题爬取:它提交关键字给Bing搜索引擎,从结果页中提取关键字,按域的相关性分类,并且使用这些关键字来构建新的搜索计划。这些研究表明:提交多种短查询以及检索小部分结果页与提交长查询检索更多的结果页相比,短查询及检索小部分结果页这种方式可以获取更多相关网页。由于它们的系统都是基于关键字搜索的,因此它们都不支持其他搜索技术。文献 [4] 提出了一个发现管道,它使用关键字搜索来查找包含产品规格的网页(比如:相机和计算机),然而它们也使用反向(backward)搜索,不能应用于其他领域。
2.2. 基本爬取发现技术
向前爬取、向后爬取是两种基本的爬取操作:向前爬取的链接是从已发现的Web网页中提取。文献 [9] [10] [11] [12] 提出的方法都是在向前爬取的基础上来发现领域Web网页和网站。文献 [9] [10] [13] 最突出的方法是利用在线学习策略的主题爬取方法,使用两种分类器来集中搜索:1) critic分类器:将网页分为相关和不相关的两个域,但是该分类器需要大量的正实例和负实例来训练;2) apprentice分类器:是自动学习的,以在线学习方式,查找与域相关的网页最相关的链接。
向后爬取(或逆向爬取)通过反向链接来发现新网页,由于Web是单向的,它必须通过搜索引擎API来搜索之前的大规模的爬取结果。文献 [3] 提出了一种结合向前和向后爬取技术来查找双语网站的爬取策略,它使用了两个链接分类器,来训练访问过的网页内容以及它们的相关目标域,通过结合这两种技术来确定访问发现链接的次序。
综上所述,虽然这些技术可以用于查找特定领域的Web网页,但之前所做的工作均不支持多个不同的发现技术,并且大多数技术需要一个精确的域分类器,并且当分类器不准确时,会变得无效,而我们的方法不需要精确的域分类器,只需要小部分相关网页即可。
3. 问题及解决方案概述
3.1. 问题定义
定义1. 网页发现问题。D表示兴趣域,w表示一个网页,如果w与兴趣域相关,则称 。给定网页种子集S,使得 ,本文目标就是利用已发现网页w+且 ,来扩充网页种子集S。
定义2. 网页重要性排名问题。R表示Web网页的排名值,指定u表示单个Web网页;令Fu为u所指向的页面集,Bu为指向u的页面集; 为u所指向的链接数量,c为标准化系数,基本定义如下:
(1)
定义3. 网页相关性排名问题。在缺少识别D中网页模型的情况下,通过指定网页种子集S作为近似的排名任务问题:给出S,目标是发现与S类似的新网页。即,给定一组已发现的网页集D+,利用网页相关性排名方法,计算已发现网页w+与S的相似度分数来对D+中的网页w+进行排名,排名位置越靠前,则w+与集合S中的网页越相似, 的可能性就越大。
3.2. 框架概述
DWDBRM框架采用领域Web网页发现、领域Web网页排名这两种策略来执行迭代,从提交查询给搜索引擎开始,基于领域知识来对搜索结果进行评分,制定新的查询计划。DWDBRM框架如图1所示:
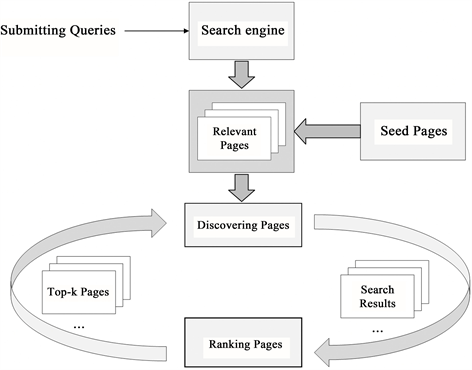
Figure 1. Architecture of DWDBRM
图1. DWDBRM结构
1) 该框架使用搜索引擎API来实现Web网页搜索操作。
2) 该框架由网页排名和网页发现两个主要部分组成。同时为了整合搜索引擎API以及排名方法,需要标准化输入输出这两个部分:网页发现部分最开始将具有代表性的相关网页种子集作为输入,执行搜索操作,执行完最开始的一轮迭代后,选取符合条件的新的上一轮迭代排名后的网页结果列表作为新的网页种子集输入,继续执行搜索操作,输出新发现的网页列表集;网页排名部分将上步网页发现部分发现的网页列表作为输入,输出对应的网页排名列表。
3) 该框架统一了多个搜索操作,并且可以公平地比较搜索操作在某些领域的有效性。并且本框架可以减少人工审查网页实例和标记网页实例来构建域分类器的工作量。
DWDBRM从种子网页集开始迭代搜索、排名以及选择最佳结果,基本算法框架与流程如算法1所示(其中KS为KeywordSearch,RS为RelatedSearch,FC为ForwardCrawling,BC为BackwardCrawling):
• 用一个参数PageSeeds调用该算法。我们称PageSeeds为事先准备的种子网页集。
• 算法开始阶段分别初始化爬取结果网页列表results、排名的结果网页列表RankedResults、先前排名的结果网页列表preRankedResults为空,初始化op操作为发现操作集operators中的任意一个操作,指定每次迭代的爬取网页数量条件(如:爬取5000个网页后,停止算法执行,返回最终的排名网页集RankedResults) (行2~行8)。
• 开始本轮网页爬取,爬取后得到临时搜索结果列表TempResults (行9),合并(不去重)结果列表results与TempResults (行10)。
• 传入评分系数 并结合网页重要性与网页相关性排名算法(见算法2)对上步results进行排名,得到每个网页的最终排名分数,返回最终网页排名结果列表RankedResults (行11)。
• 利用top-k查询机制,获取网页排名结果列表RankedResults中最好的具有代表性的前k个网页,作为下一轮迭代爬取的网页种子集(行12)。
• 接着select_op()函数(见算法3)对目前现有的发现操作集operators中的四种操作进行评分,更新操作评分,选择当前迭代中的得分最高者操作,并赋值给变量op,用于执行下一轮爬取,更新preRankedResults,接着跳回到行8,判断循环条件,执行下一轮迭代,否则执行(行15)。
• 迭代获取的网页数量达到设定值,终止迭代,返回最终排名网页列表RankedResults (行15)。
4. 基于排名与发现操作的网页爬取
本节分别给出基于组合排名函数策略的排名算法与基于multi-armed bandits-based策略的发现操作选择算法。
4.1. 网页排名
网页排名问题可以看作是信息检索中的常规排名问题,其中S代表网页种子集,网页相关性排名的目标是利用D+中新发现的网页w+与S的相似度来对D+中的网页w+进行排名;网页重要性排名的目标是将有价值的、重要的网页赋予高分进行排名。
4.1.1. 基于回归排名
该方法使用回归排名(Regression-Based Ranking)来学习排名函数,并计算每个网页w+在D+中的分数。因此需要使用正实例和负实例。选取负实例的具体做法是:从公共的Web网页库中随机选择网页来获得负实例。由于Web网页库相对于样本页面的数量来说比较大,因此减少了选择与该领域相关的Web页面的概率;训练分类器的具体做法是:利用网页种子集S、负实例拟合训练集,真实爬取的网页作为测试集,以此来预测分类概率,来计算排名分数。本文使用逻辑回归(logistic regression, LR)来进行回归排名,我们将相关类归为0类,不相关类归为1类,相关类计算公式定义如下:
(2)
其中 为线性预测器,参数wLR与参数b为逻辑回归模型的参数。
另外一种非常规的技术就是新颖性检测(Novelty Detection):该技术不需要正实例和负实例就可以对所属的类别进行预测,例如:考虑一个由p个特征描述的相同分布的n个观测值组成的数据集,通常来说,它将学习一个粗略地、紧密地边界来构造初始观测分布的轮廓,绘制并嵌入进p维空间中;如果观测值位于边界划分的子空间内,则这组观测值与初始观测值相同,可以划为相同类。否则,观测值是异常的,划为异常类。
本文分别使用sklearn提供的机器学习核心算法库linear_model、SVM中的LogisticRegression、OneClassSVM来进行网页的排名。
4.1.2. 基于相似度排名
基于相似度排名受k-最近邻算法启发,根据网页种子集S中的所有网页与新发现的网页的相似度的平均值计算出一个网页的排名分数。在网页 与 之间给出一个相似度函数 ,则 的网页分数计算如下:
(3)
考虑使用cos和Jaccard作为相似度函数,这些方法可以用于找出输入网页种子集S的不同排名优势,由于它们使用网页的不同表示,它们可以在排名任务中暴露出不同的排名特征。所以,我们为了计算cos和Jaccard相似度,cos使用网页关键字词频向量空间模型表示网页,Jaccard使用关键字是否存在关键字这种二元属性组成的二元向量表示网页。cos和Jaccard相似度函数可以作为Sim()函数,来分别计算上述Score分数,cos和Jaccard相似度函数计算公式分别如下:
(4)
(5)
其中 来分别代表网页 。
4.1.3. 基于贝叶斯排名
给出一系列属于类C的相关网页集,通过评估属于类C的项目的标准化概率来为新发现的网页打分。通过这种定义,把相关项目看成网页种子集S,类C看做兴趣域D,这样贝叶斯的分类策略可以直接应用到我们的排名问题中来。对应地,通过预测得到的概率,可以作为网页w+与网页种子集S的相似的分数,评分计算公式如下:
(6)
4.1.4. PageRank排名
PageRank,又称网页排名、PR,是Google公司所使用的对其搜索引擎搜索结果中的网页进行排名的一种算法。该算法与前几个算法思想不同,它是根据网页的重要性进行排名,即被越多网页所指向的网页,该网页的排名就靠前。PageRank算法计算公式如下:
(7)
其中 为Web网页对应的源排名向量。实验表明,对于刚开始的网页的爬取,由于爬取的网页数量较少,很难形成有效的PageRank分数,随着爬取的网页数量增加,排名效果会得到改善。
4.1.5. 基于组合函数策略的网页排名
有很多可供选择的排名函数,但不同的排名函数对同一个领域的网页排名结果各有差异,排名结果有好有坏,也就是说,使用不同的排名函数对同一个领域排名,所得出的排名结果不同。因此,为了更好的得出网页排名结果,采用组合排名函数策略,结合多种排名函数得出的网页排名结果列表进行网页排名的合并,实验表明,这种策略可以增强排名的鲁棒性、减少排名的方差。组合排名函数评分计算公式如下:
(8)
其中,F为以上小节种涉及到的回归排名、相似度排名、贝叶斯这三类排名函数列表, 指示w所属于的第i个排名函数所得出的该网页在排名列表的位置。R为PageRank排名得到网页排名的位置, 为评分系数,分数越小说明排名越靠前,越相关。实验发现,均值函数应用在本文房产领域表现好、速度快。网页排名算法框架与流程如算法2所示(本文评分系数 取0.2):
• 首先初始化combinedF_results,RankedResults为空,并对results进行去重处理得到n_results (行2~行3);
• 使用一系列的排名函数对爬取的结果网页列表n_results分别进行排名,得到各排名结果列表BS_rank_reuslts,LR_rank_reuslts,OneClass_reuslts,cos_results,jaccard_results (行4~行7),而后进行PageRank排名(行8);
• 遍历n_results中的每个网页,找到每个网页在各排名结果网页列表中的位置,并计算各网页的排名分数,根据评分系数 赋予网页重要性与相关性的分数权重,并将计算得到的某网页的排名分数加入到结果列表combinedF_results中(行9~行13);
• n_results遍历结束,根据排名分数对combinedF_results进行排序并赋值给RankedResults (行14);
• 返回RankedResults (行15)。
4.2. 网页发现操作
网页发现操作的目标就是发现新网页,因此可以利用现存的网页发现操作来爬取目标网页。实验测试了四种不同的发现操作,为了在算法框架中整合这些发现操作,本文输入部分采用标准化的网页种子集PageSeeds,输出部分采用标准化的利用top-k查询策略获取到的排名后的最相关的网页列表。
1) 向前爬取(Forward Crawling):该操作是通过输入网页的HTML文本内容提取的链接来发现新网页。一个需要注意的问题是:从输入网页中的正文文本提取的关键字有好坏之分,所以为了能够获取特定领域的关键字来生成更相关的网页的方法是:从元数据标签中提取关键字(即描述(description)、关键字(keyword)),这比从正文中提取的关键字噪声要小得多。在搜索相关网页时,对于每一个网页,利用描述、关键字标签(tag)提取、标记元数据,选择最频繁使用的标记作为搜索关键字候选。本文使用每个网页头部标签
2) 向后爬取(Backward Crawling):向后爬取采用反向链接搜索、向前爬取这两个操作来发现新的网页。反向链接搜索操作通过提交链接(link)给搜索引擎,并调用搜索引擎API来获取输入网页的反向链接。由于输入与特定域相关,发现的反向链接可能充当指向相关网页的中心,因此可以从中心网页提取的链接和向前爬取操作来发现新的额外地相关网页。
3) 关键字搜索(Keyword Search):关键字搜索使用搜索引擎API来搜索与关键字相关的网页。需要注意的问题是:关键字与域相关,但不能包含足够的信息来检索相关网页,例如关键字:产品(products)、物业(properties)、沈阳(Shenyang)、售卖(sale)都与房地产相关,但是从上下文来看,它需要构建发现额外相关网页的查询。为了解决这个问题,考虑将关键字与域的描述结合起来,来检索更多相关网页,这不需要增加额外的负担。比如:在房地产领域,给出房地产关键字作为种子关键字,对应的一些关键字条件是房地产产品、房地产物业、房地产沈阳、房地产售卖。
4) 相关搜索(Related Search):相关搜索操作以网页URL作为输入,并返回相关的网页列表,Google搜索API、BingAPI支持这个操作。根据这些搜索平台具有的数据性质以及它们的底层算法,结果可能会有很大不同。然而,这种搜索方式很适合发现相关网页。
发现操作选择
考虑在算法1的每次迭代中选择一个发现操作来最大限度地发现相关网页。从某些方面来说,使用不同的发现操作,可以多样化发现过程,最终可以提高相关网页的收获率。
为了解决这个问题,提出策略multi-armed bandits (MAB),特别是:UCB1算法 [5],一个在不同网页发现操作中的权衡策略,MAB被认为是解决开发勘探问题的有效手段,简单地说就是,选择有高积累的奖赏的强盗武器,惩罚那些过去过度使用的那些强盗武器(即,选择具有高收获率的网页操作,抛弃掉那些过度使用的高收获率的网页操作,在网页发现操作的选择中进行权衡)。为了实现该目标:我们需要定义两个变量 ,分别代表强盗手臂以及对应操作的奖赏(op代表发现操作, 代表本次迭代选择的发现操作发现新的相关网页的评分,发现的新相关网页越多, 值越大)。如果使用某种发现操作op返回了k个网页,那么对于此操作的奖赏 定义如下:
(9)
其中:
① 采用二进制值:
(10)
② 指示网页i在排名列表中的位置,i的标准奖赏是 ,len为排名列表的长度。
需要注意的是:虽然我们不知道新发现的网页相关性,但我们可以通过网页排名函数计算出的排名分数来近似它们。通过这种定义,如果i在网页列表的底部或者顶部,那么 将被分别赋值0或1。由于目标是最大化新的相关网页的数量,我们给先前迭代已经发现的网页赋值为0,而不管它所处的位置如
何。因此,i的奖赏被定义为 。
最后,我们把每一个发现操作模拟为一个强盗手臂。假定在每个时间t,当我们选择了四个操作中的一个操作,在 下发现了 个网页,根据算法UCB1,op在时间t的分数被定义如下:
(11)
其中: 为某个操作op在历次迭代中,计算出的平均值。
在这个等式中,n为所有操作的检索网页的总数量。在每次迭代中,算法选择得分最高的操作,来执行。
我们使用这些公式来计算 。在每一轮搜索后,重新计算分数并且选择高分发现操作进行下一轮迭代。采取这种策略,可以明显提高网页收获率。选择操作算法框架与流程算法3所示:
• 初始化Ii为0、 为0.0,当前迭代排名结果列表len为RankedResults.length (行2~行3);
• 循环遍历当前排名结果列表RankedResults中的每个link,如果在先前迭代产生的排名结果列表preRankedResults中的网页在新产生的排名结果列表RankedResults中再次出现,或者该网页在当前排名结果列表RankedResults的尾部,则Ii = 0,并计算 (行5~行7),否则继续执行第9行语句;
• 如果该网页处于排名结果列表RankedResults的头部,则Ii = 1,并计算 (行8~行9),否则执行第11行语句;
• 如果RankedResults中的网页不在先前的排名结果列表preRankedResults中,还有既不在preRankedResults的列表头部,也不在preRankedResults列表的尾部,则Ii = 1,并计算 (行12);
• RankedResults遍历结束,计算最终的 分数(行13);
• 传入相关参数(其中len为本轮迭代排名结果列表的长度(即n),len-preRankedResults.length为本轮迭代新发现的网站数量(即 )),然后将本轮迭代得到的当前操作评分进行更新(即计算 ) (行14);
• 找到目前为止评分最高的发现操作赋值给maxScore_op (行15);
• 返回评分最高操作maxScore_op (行16)。
5. 实验
为了验证本文提出的基于排名机制的领域Web网页发现算法框架的可行性和有效性,本文使用python语言实现算法框架设计。
实验数据选取具有代表性的商业地产网页:房天下、安居客、链家网等20多个种子网页作为种子网页集,使用Bing搜索引擎来完成部分网页发现工作。具体流程是:每轮迭代后,使用top-k查询机制生成新的种子网页列表集,然后利用种子网页列表集爬取新的相关网页,之后将爬取的网页列表与评分系数 作为相关排名函数的参数,进行网页排名,选择高分发现操作进行下一轮迭代,反复进行这个迭代过程,直到达到网页数量爬取条件,在达到网页数量爬取条件后,我们将得到的结果网页列表用于发现与排名的评估。
5.1. 评估方法
网页发现评估指标使用:网页/网站收获率(Harvest Rate, HR)对网页/网站发现方法进行评估,HR计算公式如下:
(12)
网页排名评估指标使用准确率(P@N)、平均数排名(Mean Rank)以及中位数排名(Median Rank)来对网页排名进行评估:
① P@N为在前N个排名结果网页列表中的相关网页数与前N个排名结果网页列表的比值,其计算如下公式:
(13)
② Mean Rank为排名结果相关网页列表中的相关网站的排名位置的平均值,其计算公式如下:
(14)
其中 为属于兴趣域D的发现的网站列表,n为相关网页列表长度。
③ Median Rank为排名结果网页列表中,在前N个相关网页中的第 个相关网页在结果排名列表中的位置,其计算公式如下:
(15)
5.2. 实验结果与分析
5.2.1. 网页发现评估
本文使用自适应主题爬取工具ACHE作为对照试验,验证本文发现操作算法(算法3)的有效性。ACHE的爬取策略主要是利用在线学习爬取策略来优先获取未被访问的链接,它可以用于主题爬取。由于ACHE是尽可能地爬取相关网页,因此ACHE爬取相关网站的数量会很少,我们施加限制条件:每个网站最多爬取20个网页;但这种限制,会导致某些相关网页丢失并且不会被爬取工具ACHE发现,甚至ACHE永远不会爬取它,这还会产生较低地网页收获率、链接用完提前停止运行的弊端。
本实验我们使用真实房地产数据来评估网页发现操作算法,为了使实验比较结果更加清晰,对于网站发现收获率的计算判断标准是:只有属于房产类,且网址以顶级域名结尾,才算是相关网站。另外,对于每种发现方法,爬取网页数量的目标是:results在检索10,000个网页停止(为便于计算,将爬取到的10,000个网页五等分,等分的每部分网页进行去重,并且去除第i + 1部分中i中已包含的旧网页,计算并保存每种爬取方法的网页/网站的收获率);采用关键字搜索、相关搜索、正向爬取、向后爬取来获得网页,网页收获率与网站收获率(为便于观察,纵轴值与横轴值的比值即为收获率)实验结果图分别如图2、图3所示:
实验开始时,在BANDIT方法中,我们赋予四种发现操作同样的高分分数,每种操作分别进行一轮迭代并分别评分,之后根据评分选择得分高者操作用于下一轮迭代。
从图2可以看出,在区间[0, 4000]向后爬取收获率优于其他方法,但整体上BANDIT收获率仅次于关键字搜索,除了关键字搜索,BANDIT性能要优于其他搜索方法。
从图3可以看出,关键字搜索相关网站在前期收获率较高,因为搜索引擎在前期会检索最相关的网页,随着爬取的网站数量越多,它很快会达到平稳状态;BANDIT充分利用了四种发现、爬取操作的优势,保持一种网页发现的稳定状态,发现新网页,而且性能要比各种搜索发现、爬取发现技术稳定。
综上所述BANDIT的网页发现、网站发现性能稳定,网页发现操作选择算法可行有效。
5.2.2. 网页排名评估
本实验组合排名函数的评分系数 取0.2,需要注意的是:由于每轮迭代爬取的网页数量较少,因此很难形成有效的PageRank分数,随着每轮迭代积累的爬取网页数量的增加,PageRank排名可以筛选出部分重要的网页并将其排在前列。
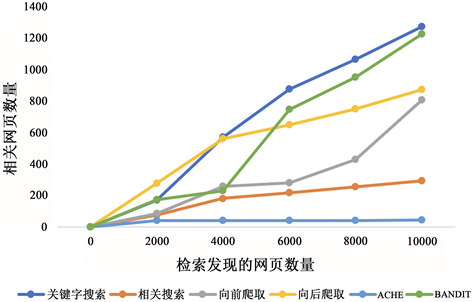
Figure 2. Web Pages harvest rate
图2. 网页收获率
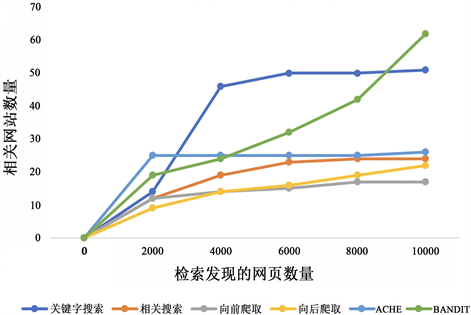
Figure 3. WebSites harvest rate
图3. 网站收获率
本文Naive Bayesian (以下简称NB)使用url长度、url域名长度、关键字计数等属性作为分类属性、OneClassSVM (以下简称OneClass)使用关键字词频、是否存在关键字这种二元属性等属性作为分类属性; logistic regression (以下简称LR)使用是否存在关键字这种二元属性作为分类属性。
五种相似性排名函数以及我们提出的CombinedFuntionRank函数(以下简称CombinedF)的排名评估指标P@N准确率、Mean Rank分数、Mean Rank分数,分别如下表1、表2所示(以下评估为对爬取后的10,000个结果网页列表results去重后得到的网页列表长度为4242的评估结果):
P@N值越大,表示相关网页的准确率越高。从表1可知:在N = 17、N = 35的情况下,我们提出的排名函数CombinedF具有较高的准确率,优于其他方法。

Table 1. P@N evaluation
表1. P@N评估
Table 2. Mean Rank and Median Rank
表2. Mean Rank与Median Rank
Mean Rank、Median Rank的值越小表示相关网页的位置越靠前,其中Median Rank的结果为从索引为0的网站开始算起,相关网页数n = 17的中间位置的结果;
从表2可以得知:我们提出的排名函数CombinedF在Mean Rank的排名位置平均值要差于Cosine、Jaccard方法,但优于其他方法,Cosine与Jaccard分数高的原因是:我们最初迭代选取的种子网页为一系列相关网站;在MedianRank中,我们提出的排名函数CombinedF在相关网页的中间位置与NB方法持平,除此以外,要比其他方法的位置要更靠前。
综上所述,我们提出的基于排名机制的Web网页发现算法框架DWDBRM是可行有效的。
6. 结论
本文提出了基于排名机制的Web网页发现算法框架DWDBRM,该算法系统地结合多种Web网页发现策略,迭代发现提取领域Web新网页。结合网页相关性以及网页重要性对网页排名,提高了爬取相关网页的准确率,最后通过实验,验证了本文所提算法框架的有效性可行性。
文章引用
王安涛,李征宇,李 贵. 基于排名机制的领域Web网页发现
Domain Web Pages Discovery Based on Ranking Mechanism[J]. 数据挖掘, 2022, 12(04): 320-333. https://doi.org/10.12677/HJDM.2022.124031
参考文献
- 1. 汤羽, 林迪, 范爱华, 吴薇薇. 大数据分析与计算[M]. 北京: 清华大学出版社, 2018.
- 2. Krishnamurthy, Y., Pham, K., Santos, A., and Freire, J. (2016) Interactive Exploration for Domain Discovery on the Web. ACM KDD Workshop on Interactive Data Exploration and Analytics (IDEA), 64-71. https://nyuscholars.nyu.edu/en/publications/interactive-exploration-for-domain-discovery-on-the-web
- 3. Barbosa, L., Bangalore, S., and Sridhar, V.K.R. (2011) Crawling Back and Forth: Using Back and Out Links to Locate Bilingual Sites. Proceedings of 5th International Joint Conference on Natural Language Processing, Chiang Mai, 8-13 November 2011, 429-437. https://aclanthology.org/I11-1048
- 4. Qiu, D.S., Barbosa, L., Dong, X.L., Shen, Y.Y., and Srivastava, D, (2015) Dexter: Large-Scale Discovery and Extraction of Product Specifications on the Web. Proc. Proceedings of the VLDB Endowment, 8, 2194-2205.
- 5. Auer, P., Cesa-Bianchi, N., and Fischer, P. (2002) Finite-Time Analysis of the Multiarmed Bandit Problem. Machine Learning, 47, 235-256. https://doi.org/10.14778/2831360.2831372
- 6. Dean, J. and Henzinger, M.R. (1999) Finding Related Pages in the World Wide Web. Computer Networks 31, 11, 1467-1479.
- 7. Murata, T. (2001) Finding Related Web Pages Based on Connectivity Information from a Search Engine. Poster Proceedings of 10th International Conference on World Wide Web (WWW), Hong Kong, 1-5 May 2001, 18-19. http://www10.org/cdrom/posters/frame.html
- 8. Vieira, K., Barbosa, L., Silva, A.S., Freire, J., and Moura, E. (2016) Finding Seeds to Bootstrap Focused Crawlers. World Wide Web, 19, 449-474. https://doi.org/10.1007/s11280-015-0331-7
- 9. Barbosa, L. and Freire, J. (2007) An Adaptive Crawler for Locat-ing Hidden-Web Entry Points. In Proceedings of the 16th International Conference on World Wide Web (WWW), New York, 8 May 2007, 441-450. https://doi.org/10.1145/1242572.1242632
- 10. Chakrabarti, S., Punera, K., and Subramanyam, M. (2002) Acceler-ated Focused Crawling through Online Relevance Feedback. In Proceedings of the 11th International Conference on World Wide Web (WWW), New York, 7 May 2002, 148-159. https://doi.org/10.1145/511446.511466
- 11. Chakrabarti, S., van den Berg, M., and Dom, B. (1999) Focused Crawling: A New Approach to Topic-Specific Web Resource Discovery. Computer Networks, 31, 1623-1640. https://doi.org/10.1016/S1389-1286(99)00052-3
- 12. Ester, M., Kriegel, H.-P., and Schubert, M. (2004) Accurate and Efficient Crawling for Relevant Websites. In Proceedings of the Thirtieth International Conference on very Large Data Bases (VLDB), Toronto, 31 August-3 September 2004, 396-407. https://doi.org/10.1016/B978-012088469-8.50037-1
- 13. Meusel, R., Mika, P., and Blanco, R. (2014) Focused Crawling for Structured Data. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management (CIKM), New York, 3 November 2014, 1039-1048. https://doi.org/10.1145/2661829.2661902