Journal of Image and Signal Processing
Vol.07 No.02(2018), Article ID:24421,11
pages
10.12677/JISP.2018.72010
DRU Image Semantic Segmentation Using Deep Neural Networks
Minghui Hu1,2, Jun Li2, Yanyan Shen1, Song Cao1,3, Shuqiang Wang1*
1Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, Shenzhen Guangdong
2Guilin University of Electronic Technology, Guilin Guangxi
3University of Science and Technology of China, Hefei Anhui

Received: Mar. 26th, 2018; accepted: Apr. 12th, 2018; published: Apr. 19th, 2018

ABSTRACT
Semantic segmentation of the distal radius and ulna images can extract the region of interest (ROI) for Ulnar radius, which counts a great deal for bone age recognition. In this work, we propose a fully convolutional network based model for semantic segmentation. Experimental results show that the proposed model can precisely segment the ulna and radius from distal radius and ulna images. We also discussed the influence of different network structures. For ulna, we get an accuracy of 97%, recall of 97%, IoU of 95%. For radius, we get an accuracy of 98.5%, recall of 98%, IoU of 96.6%.
Keywords:Image Segmentation, Radius and Ulna Distal Image, Fully Convolutional Network, Semantic Segmentation
基于深度神经网络的尺桡骨远端图像语义分割
胡明辉1,2,李俊2,申妍燕1,曹松1,3,王书强1*
1中国科学院深圳先进技术研究院,广东 深圳
2桂林电子科技大学,广西 桂林
3中国科学技术大学,安徽 合肥

收稿日期:2018年3月26日;录用日期:2018年4月12日;发布日期:2018年4月19日

摘 要
对尺桡骨远端图像进行语义分割可以提取出尺骨桡骨感兴趣区域(ROI),ROI提取对后期的辅助诊断分析非常重要。本文提出了一种基于深度全卷积神经网络的语义分割模型,并对尺桡骨远端图像进行像素级的语义分割。实验表明,该模型可以精准地从尺桡骨远端图像中分割尺骨、桡骨并识别其语义,并分析了几种典型网络结构对分割模型的影响作用。分割模型对尺骨的识别精度和召回率为97%,交并比(IoU)为95%;对桡骨识别精度为98.5%,召回率为98%,交并比(IoU)为96.6%。
关键词 :图像分割,尺桡骨远端图像,全卷积神经网络,语义分割

Copyright © 2018 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
图像分割是图像处理中的一项关键技术,图像分割是图像处理与计算机视觉领域低层次视觉中最为基础和重要的领域之一,它是图像进行下一步视觉分析和模式识别等的前提。图像分割的应用非常广泛,比如,在军事研究领域,通过图像分割为目标自动识别提供参数,为飞行器或武器的精确导航和制导提供依据;在遥感气象服务方面,通过遥感图像分析获得城市地貌,作物生长状况。云图中不同云系的分析,气象预报等也都离不开图像的分割;在交通图像分析方面,通过图像分割可以把交通监控获得的图像中车辆、行人等从背景中分割出来,来对交通状况进行估计。传统的图像分割方法包括基于区域的分割方法 [1] ,基于边界的分割方法 [2] ,基于图的分割方法 [3] 等。卷积神经网络(CNN) [4] 提出后,使用深度学习的方法便开始越来越多的应用于图像分割。S Oe,G Liu [5] 提出使用CNN的图像分割方法,来提取图像的纹理特征,W Shimoda,K Yanai [6] 使用CNN分割图像中不同类别的食物,可以对手机拍摄的照片进行分割、识别其中的食物,A Vetrivel等 [7] 使用CNN来分割卫星图像中被自然灾害(如地震)损害的区域,用于估计损害情况,Rahmat B等 [8] 使用CNN来分割出汽车的车牌图像,用于车牌识别。图像分割在医学领域也有很广泛的用途 [9] ,R Rouhi等 [10] 使用CNN分割良性或恶性的乳腺肿瘤来对乳腺癌的病情进行判断,Perfetti R等 [11] 使用CNN分割视网膜血管来进行一些疾病(如糖尿病)的诊断,Duraisamy M,Duraisamy S [12] 使用CNN从MRI图像中分割出肺部区域来辅助医生的诊断,Moeskops P等 [13] 使用CNN分割大脑的MRI图像为不同的功能区域,如白质、灰质、脑脊液等。但基于CNN的图像分割方法仍存在一些缺点,如分割效率低,分割精度差等,很多改进方法被提出。W Lotter等 [14] 提出使用多尺度CNN的方法,输入图像为不同尺寸的图像块使CNN有更广泛的感受野,改善了分割效果,LC Chen等 [15] 提出在CNN的后端加入条件随机场,很好的提高了分割精度,Lonjong等 [16] 提出了全卷积神经网络(Full Convolution Neural Network, FCN),可以进行像素级的分类,从而高效的解决了语义级别的图像分割(semantic segmentation)问题,图像语义分割需要对图像的每一个像素点进行分类,FCN也开始逐渐替代了CNN用于图像分割。Ronneberger O等 [17] 使用FCN分割生物图像,比如从一幅细胞图像中分割出不同类别的细胞,L Yang等 [18] 使用FCN分割人的衣服着装,用于改善网络购物的体验,Niemeijer J等 [19] 使用FCN分割城市交通图,用于自动驾驶汽车的场景理解。所以,使用FCN在医学图像分割方面也有很大的应用空间,我们提出使用FCN对尺桡骨远端(distal radius and ulna, DRU)图像进行分割。
评价个体生长发育通常是通过测定体格发育指标来衡量,如身高、体重、胸围,但人类生物学年龄(骨龄)则较体格发育指标更准确的反映个体生长发育水平。尺骨桡骨远端骨龄测定时一种很常见的骨龄测定方式。研究发现 [20] ,可以通过分析尺骨和桡骨远端的生长发育水平来判断骨龄,尺骨和桡骨远端不同的发育阶段有不同的形态,通过分析这些形态就可以识别尺骨和桡骨远端的发育阶段,进而到达测定骨龄的目的。
使用DRU图像进行骨龄分类与测定时,主要是利用了尺骨和桡骨远端的特征,如生长板的闭合程度,骨骺的生长情况等。对DRU图像进行分割就可以在原图像的基础上分割出只包含尺骨和桡骨远端部分的图像,精确的图像分割技术可以有效的提取ROI (region of interest),去除了其他的干扰信息,这样就会有利于对关键特征的提取,从而就能更好的对DRU图像进行分类和进行骨龄测定。
本文的贡献:
1) 首次提出使用FCN分割DRU图像,并达到较好的分割效果。
2) 通过实验对比不同的FCN结构和相同结构下不同数量的训练样本对分割精度的影响。
2. 方法描述
2.1. 全卷积神经网络与语义分割
在CNN中,全连接层用与特征图大小相同的卷积核把所有的特征图展开为一维的向量与下一层构成全连接,这种操作的坏处就在于其会破坏图像的空间结构,因此全卷积神经网络被提出来了。FCN与传统的CNN基本相同,但把CNN的全连接层换为卷积层,FCN的特点在于输入和输出都是二维的图像,并且输入和输出具有相对应的空间结构,最后一层卷积运算的特征图为热度图(heatmap)。FCN使用反卷积(deconvolution)操作来恢复FCN输出热度图的大小为输入图像大小,最后使用softmax层来预测输入图像每一个像素对应的类别。
传统的基于CNN的分割方法的做法通常是:为了对一个像素分类,使用该像素周围的一个图像块作为CNN的输入用于训练和预测,图像块的标签即为该像素的标签。但是,这种方法有几个缺点:一是存储开销很大。例如对每个像素使用的图像块的大小为10 × 10,则所需的存储空间为原来图像的100倍。二是计算效率低下。相邻的像素块基本上是重复的,针对每个像素块逐个计算卷积,这种计算也有很大程度上的重复。三是像素块的大小限制了感知区域的大小。通常像素块的大小比整幅图像的大小要小很多,只能提取一些局部的特征,从而导致分类的性能受到限制。
与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类不同,FCN可以接受任意尺寸的输入图像,采用反卷积对最后一个卷积层的特征图进行上采样,反卷积为卷积的逆过程,即把卷积的输入为反卷积的输出,反卷积的输入为卷积的输出。反卷积使特征图恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测,同时也保留了原始输入图像中的空间信息,最后在上采样的特征图上进行逐像素分类。采用逐像素计算Softmax分类的损失,相当于每一个像素对应一个训练样本。为了改善反卷积的效果,我们使用融合的方法,把全卷积后的特征图先进行一次反卷积,然后把它与前面卷积池化层输出特征图经过卷积后进行相加,然后再进行反卷积,这样操作的目的是综合利用网络浅层和深层所提取的特征。
与传统用CNN进行图像分割的方法相比,FCN有两大明显的优点:一是可以接受任意大小的输入图像,而不用要求所有的训练图像和测试图像具有同样的尺寸。二是更加高效,因为避免了由于使用像素块而带来的重复存储和计算卷积的问题。
根据以上分析,可得出FCN应用于图像语义分割的流程图(如图1)。
2.2. 网络结构
本文所使用的网络结构(如图2)中,不同的颜色表示不同的操作,相同颜色块的个数表示相同操作的次数。它以分类效果较好的CNN网络(VGG16) [21] 为基础进行改进,替换VGG16网络的全连接层为卷积层,并加入了反卷积、融合、裁剪等操作。并相应的改变输入输出,输入为图像数据和标签数据,输出也为二维的图像矩阵,且大小与输入图像和标签相同,输出图像矩阵的值对应为输入图像像素的类别,来达到像素级分类和语义分割的目的。
在这个网络中,输入图像经过多次卷积(还有池化)操作以后,得到的特征图越来越小,分辨率越来越低(粗略的图像),为了从这个分辨率低的粗略图像恢复到原图的分辨率,得到图像中每一个像素的类别,我们使用了上采样(反卷积)操作。例如经过5次卷积(和池化)以后,图像的分辨率依次缩小了2,4,8,16,32倍。对于最后一层的输出图像,需要进行32倍的上采样,才能得到原图一样的大小。
对第5层卷积池化的输出进行32倍的上采样来放大到原图大小,得到的分割结果不够精确,一些细节无法恢复。于是我们把第五层卷积池化的输出进行2倍的上采样后与第四层卷积池化的输出进行融合后再进行16倍的上采样;或者把上述操作后的输出再与第三层卷积池化的输出进行融合后再进行8倍的上采样,这样得到的分割结果就更精细一些了;或者再继续利用前面第二层、第一层卷积池化的特征。我们把对应的网络依次称为fcn32s、fcn16s、fcn8s、fcn4s和fcn2s。
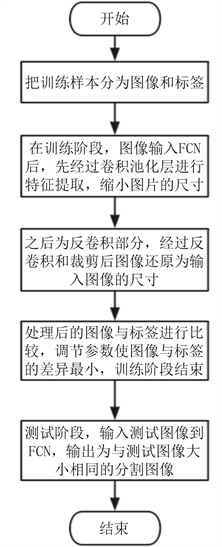
Figure 1. Image semantic segmentation flow chart
图1. 图像语义分割的流程图

Figure 2. Network structure diagram
图2. 网络结构图
3. 实验与分析
3.1. 实验数据
本论文使用的数据集为DRU的X光图像,并保存为.jpg格式,经整理并筛选后,可用的图像共有1189张,图3为单张DRU的X光图像。
3.2. 数据处理
使用DRU图像进行骨龄分类时,DRU图像的ROI为尺骨、桡骨部分,原始图像包含了很多非ROI部分,这些区域不但会影响分割精度,而且对骨龄分类来说是多余的信息。所以在进行图像分割前,需要对输入图像进行预处理,首先使用目标检测的方法检测出大致的只有桡骨和尺骨的区域块,最后把处理后的图像改变位统一尺寸,图4为预处理后的图像。
3.3. 数据标注
由于训练图像需要有标签才能提供给网络进行学习图像的语义信息,而且测试图像也需要标签来测试训练好的网络的分割精度,所以,需要对所用的图像进行标注(打标签)。我们使用Labelme [22] 作为图像标注工具。Labelme是一个开源的图像辅助工具,能够帮助用户创建定制化标注任务或可执行图像标注。
根据专业医生的指导意见,进行如下标注(如图5),使用连续的点描绘出尺骨、桡骨两块骨头,其中绿色点包围的区域分别代表尺骨和桡骨,其他区域为背景。
3.4. 图像分割评价指标
3.4.1. 精确度和召回率
在机器学习,自然语言处理,信息检索等领域,评估(Evaluation)是一个必要的工作,精确度和召回率(Precision & Recall)是广泛用于评估的两个度量值 [23] ,在说精确度和召回率之前,我们需要先需要定义TP,FN,FP,TN四种分类情况:
Figure 3. X-ray image of DRU
图3. DRU的X光图像

Figure 4. Images after preprocessed
图4. 预处理后的图像

Figure 5. Data annotation
图5. 数据标注
1) 伪阳性(FP):预测为阳性,真实值为阴性;
2) 真阳性(TP):预测为阳性,真实值为阳性;
3) 真阴性(TN):预测为阴性,真实值为阴性;
4) 伪阴性(FN):预测为阴性,真实值为阳性。
精确度:P = TP/(TP + FP),反映了被分类器判定的正例中真正的正例样本的比重;召回率,也称为True Positive Rate:R = TP/(TP + FN);反映了被正确判定的正例占总的正例的比重。由此可见,精确度是评估预测的结果中目标结果所占得比例;召回率,顾名思义,就是从关注领域中,召回目标类别的比例。
在分类时,当然希望预测结果精确度越高越好,同时召回率也越高越好,但事实上这两者在某些情况下有矛盾的。比如极端情况下,我们只预测出了一个结果,且是准确的,那么精确度就是100%,但是召回率就很低;而如果我们把所有结果都返回,那么比如召回率是100%,但是精确度就会很低。所以,在评价分类时要综合精确度和召回率两种评价指标。
3.4.2. 交并比(IoU)
在图像分割的评价体系中,有一个参数叫做IoU (交并比),即分割产生的分割图与标签图的交叠率。可以简单理解为:分割结果(Segmentation Result)与Ground Truth的交集比上它们的并集,即为分割的准
确率。IoU的计算公式如公式为: ,A、B分别代表分割结果与Ground Truth的集合,图6
为IoU的图解表示。
由上述图示可知,IoU的计算综合考虑了交集和并集,如何使得IoU最大,需要满足,更大的重叠区域,更小的不重叠的区域。理想情况下,IoU = 1,即分割图像与标签完全重合。
4. 实验结果
本文使用预训练模型来加快网络收敛速度和减少过拟合,即在ImageNet [24] 数据集训练好的VGG-16模型基础上进行微调(fine-tuning)。由于训练深度全卷积神经网络非常容易出现梯度爆炸导致loss变为Nan的现象,因此设置初始的学习率为 。为了防止深度全卷积神经网络求解时掉入局部极小值和防止过拟合,因此设置动量为0.99,衰减系数为0.0005,迭代次数设为20,000次,batch size设置为1。
本文使用的方法的实现是基于开源深度学习框架Caffe。由于DRU图像总共有1189张,我们设训练集占80% (951张),测试集占20% (238张),训练集和测试集的样本是从全部的图像中随机分配的。为了减少内存的占用,提高训练速度,对输入的DRU图像进行了归一化处理,即减去均值,再除以方差。
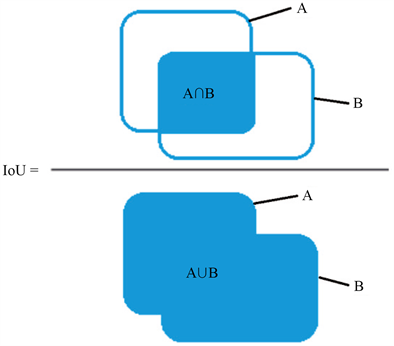
Figure 6. Graphical representation of IoU
图6. IoU的图解表示
图7显示了fcn8s网络训练时随着迭代次数的增加,损失函数的变化过程,网络训练过程中迭代100次所需的时间为48 s。
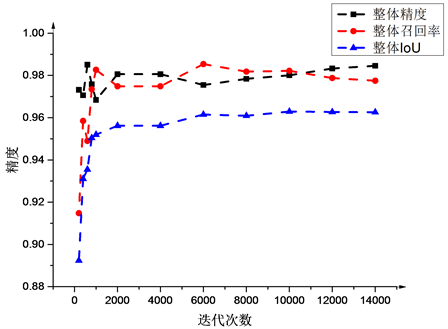
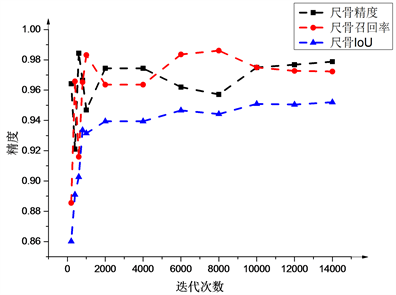
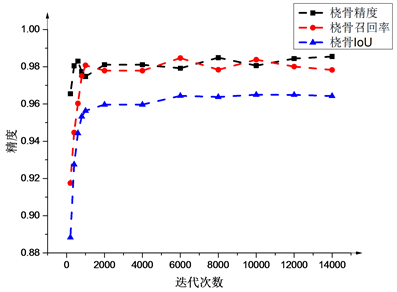
图8(a)~(c)显示了测试精度(整体测试精度、尺骨测试精度、桡骨测试精度)随着迭代次数增加的变化情况。
由于使用了预训练模型,网络在训练初期损失函数就下降的较快,测试精度也随着迭代次数的增加而上升,在迭代10000次后,损失函数和测试精度都趋于稳定,最后整体的测试精度和召回率为98%,IoU为97%;尺骨的测试精度和召回率为97%,IoU为95%;桡骨测试精度为98.5%,召回率为98%,IoU为96.6%。
为了测试不同网络结构对DRU图像分割精度的表现情况,图9显示了不同的网络结构:fcn2s、fcn4s、fcn8s、fcn16s、fcn32s,网络测试阶段的损失函数随着迭代次数增加的变化情况。
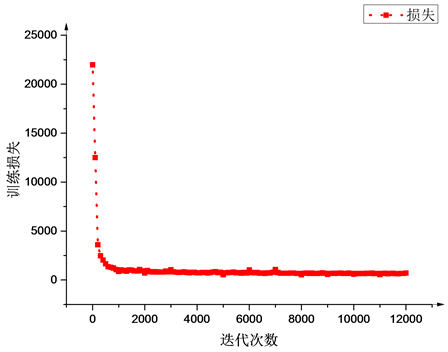
Figure 7. Train loss varies with the number of iterations increases
图7. 训练损失随着迭代次数增加的变化情况
 (a)
(a)
 (b)
(b)
 (c)
(c)
Figure 8. Test accuracy varies with the number of iterations increases
图8. 测试精度随着迭代次数增加的变化情况
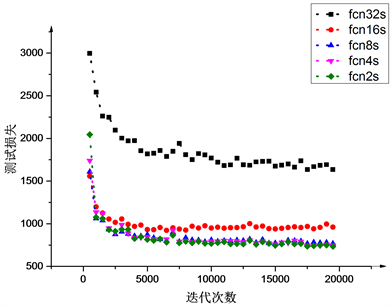
Figure 9. Test loss varies with the number of iterations increases
图9. 测试损失随着迭代次数增加的变化情况
5. 总结
本文实现了一种基于深度学习的DRU图像分割方法和系统,利用深度全卷积神经网络,对DRU图像进行像素级的分类,达到了很好的分割效果,训练好的网络能够从给出的测试图像中精确的分割出尺骨、桡骨部分,而且,对一些明暗不均匀、噪声较大的图像也能准确的分割。此外,对不同的网络结构进行对比实验分析得出了分割效果相对较好的网络结构,又用不同数量的训练样本来测试网络,结果发现网络在少量训练样本的情况下也能达到较好的分割精度。这是由于DRU图像相对简单,图像中包含的特征较少,网络在少量样本的情况下就可以很好的学习到DRU图像的特征。这同时也说明了网络具有很好的稳定性。
基金项目
本项研究受到深圳市科创委项目(JCYJ20160531184426303, KQJSCX20170331162115349, KJYY 20160608154421217)和广东省自然科学基金项目(2016A030313176)支持。
文章引用
胡明辉,李 俊,申妍燕,曹 松,王书强. 基于深度神经网络的尺桡骨远端图像语义分割
DRU Image Semantic Segmentation Using Deep Neural Networks[J]. 图像与信号处理, 2018, 07(02): 85-95. https://doi.org/10.12677/JISP.2018.72010
参考文献
- 1. 张新峰, 沈兰荪. 图像分割技术研究[J]. 电路与系统学报, 2004, 9(2):92-99.
- 2. 杨晖, 曲秀杰. 图像分割方法综述[J]. 电脑开发与应用, 2005, 18(3):21-23.
- 3. Felzenszwalb, P.F. and Huttenlocher, D.P. (2004) Efficient Graph-Based Image Segmentation. International Journal of Computer Vision, 59, 167-181.
https://doi.org/10.1023/B:VISI.0000022288.19776.77 - 4. Lecun, Y., Bottou, L., Bengio, Y., et al. (1998) Gradient-Based Learning Applied to Document Recognition. Proceedings of the IEEE, 86, 2278-2324.
https://doi.org/10.1109/5.726791 - 5. Oe, S. and Liu, G. (2000) Texture Image Segmentation Method Based on Multilayer CNN. International Conference on Tools with Artificial Intelligence, 31, 147-150.
- 6. Shimoda, W. and Yanai, K. (2015) CNN-Based Food Image Segmentation without Pixel-Wise Annotation. International Conference on Image Analysis and Processing, 9281, 449-457.
- 7. Vetrivel, A., Kerle, N., Gerke, M., et al. (2016) Towards Automated Satellite Image Segmentation and Classi-fication for Assessing Disaster Damage Using Data-Specific Features with Incremental Learning. GEOBIA 2016: Solutions and Syn-ergies, 14-16 September 2016.
https://doi.org/10.3990/2.369 - 8. Rahmat, B., Joelianto, E., Purnama, I.K.E., et al. (2013) CNN-Fuzzy-Based Indonesia License Plate Image Segmentation System. IEEE International Conference on Computer Science and Automation Engineering, Guangzhou.
- 9. Greenspan, H., Ginneken, B.V. and Summers, R.M. (2016) Guest Editorial Deep Learning in Medical Imaging: Overview and Future Promise of an Exciting New Technique. IEEE Transactions on Medical Imaging, 35, 1153-1159.
https://doi.org/10.1109/TMI.2016.2553401 - 10. Rouhi, R., Jafari, M., Kasaei, S., et al. (2015) Benign and Malignant Breast Tumors Classification Based on Region Growing and CNN Segmentation. Expert Systems with Applications, 42, 990-1002.
https://doi.org/10.1016/j.eswa.2014.09.020 - 11. Perfetti, R., Ricci, E., Casali, D., et al. (2008) A CNN Based Algorithm for Retinal Vessel Segmentation. 12th WSEAS International Conference on CIRCUITS, Heraklion, 22-24 July 2008, 152-157.
- 12. Duraisamy, M. and Duraisamy, S. (2012) CNN-Based Approach for Segmentation of Brain and Lung MRI Images. European Journal of Scientific Research, 81, 298-313.
- 13. Moeskops, P., Viergever, M.A., Mendrik, A.M., et al. (2016) Automatic Segmentation of MR Brain Images with a Convolutional Neural Network. IEEE Transactions on Medical Imaging, 35, 1252-1261.
https://doi.org/10.1109/TMI.2016.2548501 - 14. Lotter, W., Sorensen, G. and Cox, D. (2017) A Multi-Scale CNN and Curri-culum Learning Strategy for Mammogram Classification. In: Cardoso, M., et al., Eds., Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support. DLMIA 2017, ML-CDS 2017. Lecture Notes in Computer Science, Vol. 10553. Springer, Cham.
- 15. Chen, L.C., Papandreou, G., Kokkinos, I., et al. (2014) Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. Computer Science, 4, 357-361.
- 16. Long, J., Shelhamer, E. and Darrell, T. (2015) Fully Convolutional Networks for Semantic Segmentation. IEEE Conference on Computer Vision and Pattern Recognition, IEEE Computer Society, 3431-3440.
- 17. Ronneberger, O., Fischer, P. and Brox, T. (2015) U-Net: Convolutional Networks for Biomedical Image Segmentation. International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer, Cham, 234-241.
- 18. Yang, L., Rodriguez, H., Crucianu, M. and Ferecatu, M. (2017) Fully Convolutional Network with Superpixel Parsing for Fashion Web Image Segmentation. In: Amsaleg, L., Guðmundsson, G., Gurrin, C., Jónsson, B. and Satoh, S., Eds., MultiMedia Modeling. MMM 2017. Lecture Notes in Computer Science, Vol. 10132. Springer, Cham.
- 19. Niemeijer, J., Fouopi, P.P., Knake-Langhorst, S., et al. (2017) A Review of Neural Network based Semantic Segmentation for Scene Understanding in Context of the self driving Car. BioMedTec Studierendentagung.
- 20. Luk, K.D., Saw, L.B., Grozman, S., et al. (2014) Assessment of Skeletal Maturity in Scoliosis Patients to Determine Clinical Management: A New Classification Scheme Using Distal Radius and Ulna Radiographs. Spine Journal Official Journal of the North American Spine Society, 14, 315-325.
https://doi.org/10.1016/j.spinee.2013.10.045 - 21. Simonyan, K. and Zisserman, A. (2015) Very Deep Convolutional Networks for Large-Scale Image Recognition. In: International Conference on Learning Representations (ICLR).
- 22. Torralba, A., Russell, B.C. and Yuen, J. (2010) LabelMe: Online Image Annotation and Applications. Proceedings of the IEEE, 98, 1467-1484.
https://doi.org/10.1109/JPROC.2010.2050290 - 23. 李航. 统计学习方法[M]. 北京: 清华大学出版社, 2012.
- 24. Deng, J., Dong, W., Socher, R., et al. (2009) ImageNet: A Large-Scale Hierarchical Image Database. IEEE Conference on Computer Vision and Pattern Recognition, Miami, 20-25 June 2009, 248-255.
NOTES
*通讯作者。