Smart Grid
Vol.05 No.05(2015), Article ID:16196,10 pages
10.12677/SG.2015.55029
Research on Fast Recovery from Link Failures Based on Openflow in Smart Grid
Yuanfeng Huang1, Yu Zhao1, Bingbing Liao2, Yongbo Wang2
1Zhuhai Power Supply Bureau of Guangdong Power Grid Corporation, Zhuhai Guangdong
2Guangdong YTD Technology Development Co. Ltd., Guangzhou Guangdong
Email: 13902537756@139.com, 13825603652@139.com
Received: Oct. 2nd, 2015; accepted: Oct. 14th, 2015; published: Oct. 21st, 2015
Copyright © 2015 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



ABSTRACT
In this paper, we design and evaluate algorithms for fast recovery from link failures in a smart grid communication network, addressing all three aspects of link failure recovery: 1) link failure detection, 2) algorithms for computing backup multicast trees, and 3) fast backup tree installation. Firstly, we design link-failure detection and reporting mechanisms that use Openflow to detect link failures when and where they occur inside the network. Openflow is an open source framework that cleanly separates the control and data planes for use in network management and control. Secondly, we formulate a new problem, MULTICAST RECYCLING, which computes backup multicast trees that aim to minimize control plane signaling overhead. We prove that MULTICAST RECYCLING is at least NP-hard and presents a corresponding approximation algorithm. Lastly, two control plane algorithms are proposed that signal data plane switches to install pre-computed backup trees. An optimized version of each installation algorithm is designed that finds a near minimum set of forwarding rules by sharing rules across multicast groups, thereby reducing backup tree installation time and associated control state. We implement these algorithms in the POX Openflow controller and evaluate them using the Mininet emulator, quantifying control plane signaling and installation time.
Keywords:Smart Grid, Failure Recovery, Openflow
基于Openflow的智能电网网络链路故障恢复研究
黄远丰1,赵煜1,廖兵兵2,王勇波2
1广东电网有限责任公司珠海供电局,广东 珠海
2广东益泰达科技发展有限公司,广东 广州
Email: 13902537756@139.com, 13825603652@139.com
收稿日期:2015年10月2日;录用日期:2015年10月14日;发布日期:2015年10月21日

摘 要
本文设计了一种智能电网中的链路故障快速恢复算法,并对算法进行了验证。本文方法解决了链路故障恢复三个方面的问题:1) 链路故障探测,2) 计算备份多播树的算法,3) 快速备份树的建立。首先,本文设计了基于Openflow的链路故障探测和上报机制,来探测链路故障。Openflow是一种开源框架,将网络管理的控制和转发平面进行分离。其次,本文设计了多播回收机制,通过计算备份多播树来最小化控制信号的开销。本文证明了多播回收问题是一个NP难问题,并提出一种相应的算法来解决该问题。最后,本文设计了一种优化算法,通过在多播组之间共享规则来查找到接近最优的转发集合,同时降低了备份树和控制机制之间的时间开销。本文在POX Openflow控制器上使用Mininet仿真器评估了所提出的算法,量化了控制平面的信号和安装时间。
关键词 :智能电网,故障恢复,Openflow

1. 引言
电力通信网包括车载变电站集合,由电力变电站、发电机中心、电力负载汇聚点组成,集合中的组件通过输电线路来连接。电网的操作可以通过高频率电压以及现有的相量测量设备(PMUs)进行优化。
PMU器件具有严格的超低数据包延迟和丢包的问题。如果不能满足,PMU器件会丢失一个重要的电力事件,例如雷击,潜在的导致了不正确策略的级联制定,以及相应动作的发生。例如,闭环回路控制应用需要每个数据包8~16 ms的请求延迟[1] ,如果每个包并没有在规定时间窗内到达,会执行一个错误的操作。最坏情况下,会导致智能电网失效,诸如印度的智能电网失效 [2] 。
因此,具有敏感和互通要求的网络规定PMU数据必须提供严格的端到端数据保证 [1] 。为此,互联网的最佳服务模式并不适用于PMU器件的严格包转发策略和丢包率限制 [3] ,需要建立新的网络架构或者对现有的网络协议进行优化,文献 [1] [3] [4] 提出了高效的网内快速转发和链路交换机故障恢复机制。由于PMUs通过多个位置将数据分发到器件上 [1] ,因此多播需要在数据分发时对数据进行表示分发。
软件定义网络实现了交换机和路由器数据转发平面和控制平面的分离,实现控制平面的可编程,将转发规则可编程的写到交换机或路由器上。控制平面和数据平面的互通,包括消息转发规则,较为常用的是Openflow协议 [5] 。
本文使用Openflow定义了新的控制平面算法,并对算法进行优化,以实现对重要智能电网数据的分发,算法安装在网络交换机上。本文设计了网络链路故障的快速恢复算法,链路故障后,数据包不能从该链路进行转发。算法从三个方面对网络链路故障进行了恢复,分别为链路故障检测、预先计算备份多播树以及实现快速备份树的安装。
设计链路故障检测和上报算法Pcount,使用Openflow [5] 协议检测算法故障。网路内部检测可以降低算法发现故障并进行恢复的时间。但现有方法 [6] 主要针对端到端的包检测,导致了检测速度较慢。
设计一种经典的优化问题来计算备份多播树。本文定义了一个新问题,多播循环,在链路故障发生之前预先计算备份多播树,最小化备份树的安装时间。该问题优化不同于现有方法 [7] [8] 关注于最大化备份路径和主要路径之间的节点和路径脱节。
证明了多播回收问题是一个NP难问题,并提出了一种优化算法,BUNCHY。
提出MERGER,它是一种在多播模式下的Openflow应用,目的是降低转发状态。MERGER使用本地优化方法来创建一个近似最小集合,该集合通过对具有普通子节点的多播树进行转发规则的合并。
设计了两种算法——PROACTIVE和REACTIVE算法——来快速建立备份树。PROACTIVE预先建立备份树转发规则,并且在检测到链路故障之后触发这些规则,检测到链路故障后使用REACTIVE算法来建立备份树。
提供了一种算法执行原型,APPLESEED,使用POX模型,并使用Mininet验证了算法。PCOUNT、BUNCHY、MERGER、PROACTIVE和REACTIVE均在POX [9] 里执行,POX是一种开源Openflow控制器,每个算法使用Mininet仿真器 [10] 进行了验证。
本文组织结构如下,第二部分介绍相关工作,第三部分描述PMU器件需求,并介绍Openflow协议。第四部分描述算法,第五部分对所提算法进行仿真实验,第六部分总结全文。
2. 相关工作
Gridstat [1] 是一个出版订阅系统,是首个考虑实现智能电网数据分发系统的研究项目。Gridstat是构建在现有网络协议(例如IP,MPLS)上的overlay网络,主要关注制定PMU器件更加具有鲁棒性要求的网络协议。
现有工作大部分关注基于端到端的测量来检测包丢失 [6] ,要求多次检测来确定丢包率。本文算法PCOUNT提出了一种更快速准确的单一链路包检测方法,直接测量出网路内部的准确流量。
不同于多播的情况,预先计算备份树的创新点是MPLS快速重路由算法来重路由时间优先的单播IP流 [11] 。现有工作中计算备份树使用本地优化标准计算路径的方法,例如单一多播树特定条件,本文还考虑了网络标准,例如多个多播树的特定条件。此外,现有工作中并没有对最小化控制面板信号进行研究,本文在多播回环问题中,对该问题进行解决。备份路径或者备份树是通过计算与主路径脱节的最大节点来得出的 [7] [12] 。
3. 预言
3.1. PMU器件及其QoS需求
本文设计了算法对多播智能电网数据的可靠性,特别是PMU器件QoS要求的数据进行处理。参考文献 [13] 详细介绍了PMU器件的QoS要求细节。本文算法通过提供可靠的数据分发,使得PMU器件可以执行准确及时的操作。
3.2. 名词和假设
将通信网络建模为 ,这里的
,这里的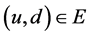 表示一条从
表示一条从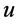 到
到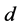 的链路,
的链路,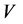 包括三种节点:能够发送PMU数据的节点(PMU发送节点),接受PMU数据的节点(数据接受节点),连接PMU发送节点和数据接受节点的交换机。我们假设
包括三种节点:能够发送PMU数据的节点(PMU发送节点),接受PMU数据的节点(数据接受节点),连接PMU发送节点和数据接受节点的交换机。我们假设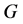 具有
具有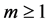 多播树来发送PMU数据。用
多播树来发送PMU数据。用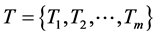 表示在
表示在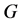 中的
中的 个多播树,
个多播树, 表示一个以
表示一个以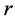 为根节点的多播树,
为根节点的多播树,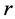 的直接相邻的边为
的直接相邻的边为 ,向量
,向量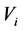 表示从
表示从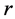 到每个
到每个 的链路。用
的链路。用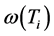 表示所有
表示所有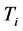 边的总权重。
边的总权重。
用 表示具有
表示具有 条边的第
条边的第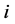 颗树,其中
颗树,其中 。对每个定向树
。对每个定向树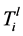 中的每条链路
中的每条链路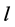 ,定义备份树
,定义备份树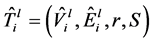 ,备份树是一个有向树,根节点是
,备份树是一个有向树,根节点是 ,根节点到每个
,根节点到每个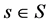 的链路是有向路径,例如
的链路是有向路径,例如 。
。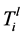 和
和 表示原始树和备份树。对每一个原始树
表示原始树和备份树。对每一个原始树 ,具有一个多播流
,具有一个多播流 ,数据接受节点
,数据接受节点 ,每个
,每个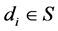 具有一个端到端包延迟需求,并且具有一个丢包率需求。
具有一个端到端包延迟需求,并且具有一个丢包率需求。
3.3. Openflow
Openflow是一个开源标准将交换设备的控制平面和转发平面进行了分离,并提供了一个可编程的控制框架 [5] 。所有Openflow算法和协议通过一个逻辑集中的控制器进行控制,同时网路交换设备根据本地转发规则进行包转发。
Openflow提供给了一个交换机流表,每个交换机使用对每个操作进行匹配的方法来对包进行操作 [5] :流表根据数据包的包头进行匹配,判断将该数据流进行转发还是丢弃。交换机对每个流实例保存数据。
Openflow并没有提供多播转发模式,因此需要设计多播模式,本文称之为Basic。Basic是一个多播IP地址来标记多播组,并使用这些地址来设定多播树交换机的流表。对每个多播树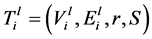 ,Basic在每个交换机
,Basic在每个交换机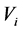 上安装一个流表。流表通过组的多播地址来匹配包,并将每个包的备份进行转发,相应出端口的交换机出口连接是
上安装一个流表。流表通过组的多播地址来匹配包,并将每个包的备份进行转发,相应出端口的交换机出口连接是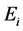 。
。
4. 问题描述
本文提出了一个算法集合,称之为APPLESEED,在链路故障时提高了多播树的鲁棒性,运行在一个Openflow控制器上,目标是最小化丢包率,保证满足端到端延迟的需求。APPLESEED由三部分组成:PCOUNT算法进行快速链路检测,快速安装并计算备份树,快速安装预先计算备份树。
4.1. 使用Openflow进行链路故障检测
本文提出了PCOUNT算法,使用Openflow来检测链路故障。网内检测可以降低丢包发生的时间。快速包检测对PMU器件来说是至关重要的,PMU器件对丢包率具有极高的敏感度。现有工作 [6] 大多关注于使用端到端的测量来评估丢包率,导致了检测时间超长。PCOUNT考虑当丢包了超过一定门限时,将该链路定义为失效。本文定义的一个链路是指:两个Openflow交换设备之间的端到端连接称之为一条链路。文章 [13] 中,详细介绍了PCOUNT算法检测多个交换机之间的丢包率。
对一个长度为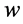 的时间窗口,PCOUNT评估一个链路
的时间窗口,PCOUNT评估一个链路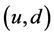 的丢包率,检测在链路
的丢包率,检测在链路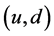 上的流
上的流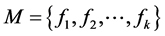 的丢包率,步骤如下:
的丢包率,步骤如下:
1) 安装规则来计算所有在节点 收到的标签
收到的标签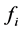 的包。对在节点
的包。对在节点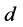 上的每个流
上的每个流 ,安装流表,使用标签模块在第二步的节点
,安装流表,使用标签模块在第二步的节点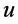 ,对流打标签。
,对流打标签。
2) 在节点 对所有流
对所有流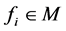 打标签。假设
打标签。假设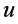 使用流表
使用流表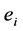 来匹配和转发流
来匹配和转发流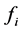 的包。首先,PCOUNT算法生成一个唯一的标签,然后,对每个流
的包。首先,PCOUNT算法生成一个唯一的标签,然后,对每个流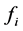 ,PCOUNT算法创建一个新的流表
,PCOUNT算法创建一个新的流表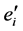 ,
, 是流表
是流表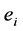 的备份,不同的是,
的备份,不同的是,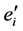 包括数据包dl_vlan区域的标签。
包括数据包dl_vlan区域的标签。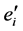 比
比 具有更高的Openflow优先级,来保证每个
具有更高的Openflow优先级,来保证每个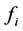 数据流均能被打上标签。
数据流均能被打上标签。
3) 在 时间窗口执行完之后,停止对节点
时间窗口执行完之后,停止对节点 打标签,同时对
打标签,同时对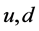 进行包统计。每个打标签规则在
进行包统计。每个打标签规则在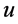 都是单独进行查询的,在
都是单独进行查询的,在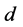 进行一个聚合查询。
进行一个聚合查询。
4.2. 计算备份树
APPLESEED预先计算一个备份树,当PCOUNT监测到一条链路故障时,预先计算的备份树对这条故障链路进行恢复。本文在这里提出了一个新问题多播回收,来计算备份树并且提出了相应的算法BUNCHY。
4.2.1. 多播回收问题
多播回收问题的目标是计算备份树来最大化初始树的边。回收初始树使用SDN控制器来保证初始树的转发规则安装到网络里,而不是新建立一套转发规则。在检测到链路故障时,备份树开始建立,并恢复之前的网络链路。
初始树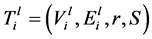 ,它的备份树是
,它的备份树是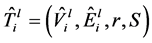 ,我们定义一个二进制向量
,我们定义一个二进制向量 ,对所有的
,对所有的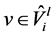 ,如果
,如果 具有相同的前向树
具有相同的前向树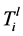 和
和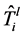 ,这时
,这时 。否则,
。否则,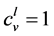 。对于
。对于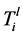 和
和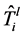 ,定义:
,定义:
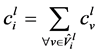 (1)
(1)
 是需要安装
是需要安装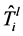 新规则的数量。
新规则的数量。
我们将多播回收问题定义为改进的斯坦纳树问题,称之为STEINER-ARBORESCENCE。对与根节点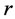 和
和 来说,用
来说,用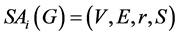 表示在
表示在 上计算斯坦纳树,根节点是
上计算斯坦纳树,根节点是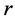 ,生成树是
,生成树是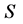 ,这里的
,这里的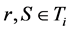 。
。
多播回收的输入是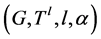 ,这里的
,这里的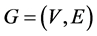 是一个有向图,
是一个有向图,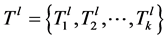 中的每个
中的每个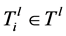 是使用
是使用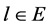 的初始树,这里
的初始树,这里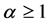 。对每个初始树使用
。对每个初始树使用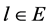 的输出是一个备份树。备份树的集合可以是
的输出是一个备份树。备份树的集合可以是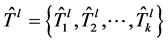 :
:
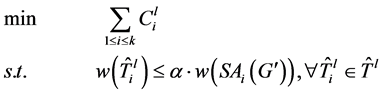 (2)
(2)
这里,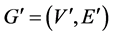 ,
, ,
,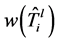 表示
表示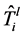 的节点权重之和。目标函数是最大化重使用的初始树的边,同时
的节点权重之和。目标函数是最大化重使用的初始树的边,同时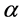 的约束是如何在最小化
的约束是如何在最小化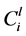 的同时生成的备份树的最大值。
的同时生成的备份树的最大值。
定理4.1. 多播回收问题是一个NP难问题
证明详见参考文献 [13] 。
4.2.2. Bunchy最优化算法
Bunchy是解决多播回收问题的简单最优化算法。对每个链路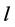 ,APPLESEED算法使用BUNCHY对每个初始树使用链路
,APPLESEED算法使用BUNCHY对每个初始树使用链路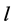 来计算备份树。
来计算备份树。
给定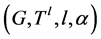 ,对每个
,对每个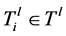 ,Bunchy通过两个步骤来计算
,Bunchy通过两个步骤来计算 。首先,生成一个
。首先,生成一个 的备份
的备份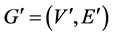 ,并且将
,并且将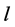 从
从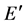 中删除。设定链路权重
中删除。设定链路权重 为0,设定
为0,设定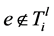 为1。然后,对
为1。然后,对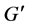 运行STEINERP-
ARBORESENCE优化算法,并且使用
运行STEINERP-
ARBORESENCE优化算法,并且使用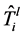 作为结果。如果
作为结果。如果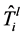 满足公式(2),将
满足公式(2),将 作为最优解,否则,返回错误。
作为最优解,否则,返回错误。
设定初始树的链路权重为0,在第一步中,STEINERP-ARBORESENCE优化算法不产生任何成本的使用初始树的链路,促进了初始树边的重使用。如果Bunchy算法在第二步骤中返回错误,则需要将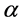 的取值调整的更大,或者生成一个新的多播树来满足树大小的限制。
的取值调整的更大,或者生成一个新的多播树来满足树大小的限制。
4.3. 安装备份树
安装备份树有两个步骤:首先,计算需要安装转发规则的交换机的数目,以及相应的需要生成的Openflow流表的个数。然后,控制器向相应的交换机发送安装信号,来安装转发规则。本文将介绍两种安装算法:PROACTIVE和REACTIVE。这两种算法均计算转发规则,来同时生成一个单一的备份树。初始树为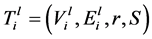 ,备份树为
,备份树为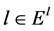 ,
,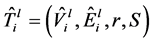 。
。
REACTIVE算法:首先确定需要新转发规则的节点。如果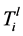 和
和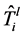 在节点
在节点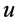 使用同一个输出链路,那么在节点
使用同一个输出链路,那么在节点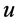 不需要安装新的转发规则。转发规则仅在
不需要安装新的转发规则。转发规则仅在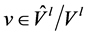 和每个
和每个 ,节点在
,节点在 和
和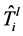 具有不同的输出链路。对每个节点,REACTIVE算法预先计算流表来匹配
具有不同的输出链路。对每个节点,REACTIVE算法预先计算流表来匹配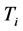 多播地址的包。最后,当
多播地址的包。最后,当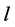 失效时,REACTIVE触发交换机来安装预先计算的转发规则。
失效时,REACTIVE触发交换机来安装预先计算的转发规则。
PROACTIVE算法:该算法在初始链路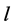 失效之前,计算并安装备份树流表。由于该算法仅触发单一节点的备份安装,因此故障恢复速度比较快。当由于转发操作错误引起的链路故障,该算法不能不加修改的安装备份。对一个节点使用该算法时,初始树和备份树的节点输出链路必须是不同的。
失效之前,计算并安装备份树流表。由于该算法仅触发单一节点的备份安装,因此故障恢复速度比较快。当由于转发操作错误引起的链路故障,该算法不能不加修改的安装备份。对一个节点使用该算法时,初始树和备份树的节点输出链路必须是不同的。
为了解决该问题,PROACTIVE算法对每个备份树指派了一个唯一的备份树id,表示为bid。每个备份树使用bid进行流表匹配和包转发,将bid值写入到dl_src区域。当备份树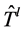 被触发时,
被触发时,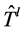 的根节点将bid的值写入到dl_src包头,表示这些包应该由
的根节点将bid的值写入到dl_src包头,表示这些包应该由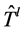 来转发而不是由
来转发而不是由 来进行转发。
来进行转发。
4.4. 优化多播树安装
Basic多播安装需要在每个多播树节点创建一个流表,使用多播树地址来匹配输入包。因此,一个交换机可能有多个流表实例来执行相同的转发操作。作为Basic的优化算法,我们提出了Merger算法,该算法计算Openflow转发规则的近似最小集合,通过在每个节点将流表中具有相同输出链路的规则进行聚合。MERGER算法降低了故障恢复的备份树安装规模。
5. 实验验证
本文使用POX控制器 [9] 来执行上述第四章节中的算法。POX控制器基于Openflow 1.0并且运行在Mininet 2.0.0版本 [10] 上。实验环境是使用Linux操作系统,具有2.33 GHz Intel(R) Xeon® CPU,15 GB RAM。Mininet的配置是运行在Oracle Virtal Box虚拟机上,并且安装了4 GB RAM和单核CPU。使用Mininet软件交换机,Open vSwitch,APPLESEED运行在VirtualBox VM上。
5.1. 链路故障检测器
本文运行两个模拟器来评估PCOUNT算法,首先,我们度量PCOUNT算法的丢包率,然后评估当PCOUNT监测到更多的数据流时交换机和控制器的性能。
丢包率评估的准确度:如图1所示PCOUNT测量链路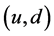 上的丢包率,我们生成
上的丢包率,我们生成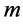 个多播组,每个
个多播组,每个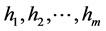 多播包向接受节点
多播包向接受节点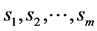 以每秒钟60个数据包的速率发送数据包。Basic算法使用多播模式,实现了从节点
以每秒钟60个数据包的速率发送数据包。Basic算法使用多播模式,实现了从节点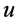 到
到 的
的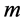 个流表。本文设定
个流表。本文设定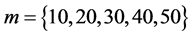 ,使用Minniet模拟器,通过节点
,使用Minniet模拟器,通过节点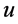 到
到 的数据包服从贝努利分布,丢包率为
的数据包服从贝努利分布,丢包率为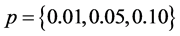 。
。
本文对PCOUNT算法丢包率的准确度进行了度量,优化了PCOUNT算法的检测器数据流参数,对丢包率实现了更为准确的度量。PCOUNT对每一个监测到的数据流进行计算,表明如果有失效的数据流发生了错误,该数据流是PCOUNT没有监测到的。本文使用一个实例来说明该算法,设定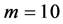 ,
,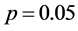 。
。
图2对比了PCOUNT链路丢包率函数为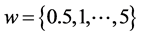 ,置信区间为95%,结果表明,每个数据流随机选取,监测到
,置信区间为95%,结果表明,每个数据流随机选取,监测到 的数据流有
的数据流有 ,对每个
,对每个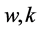 ,置信区间运行100次模拟。
,置信区间运行100次模拟。
PCOUNT估计丢包率是非常准确的,95%的置信区间,对所有的 ,有15%的丢包率,对于75个数据包的情况,80%的模拟运行,预计结果为5%的丢包率。
,有15%的丢包率,对于75个数据包的情况,80%的模拟运行,预计结果为5%的丢包率。
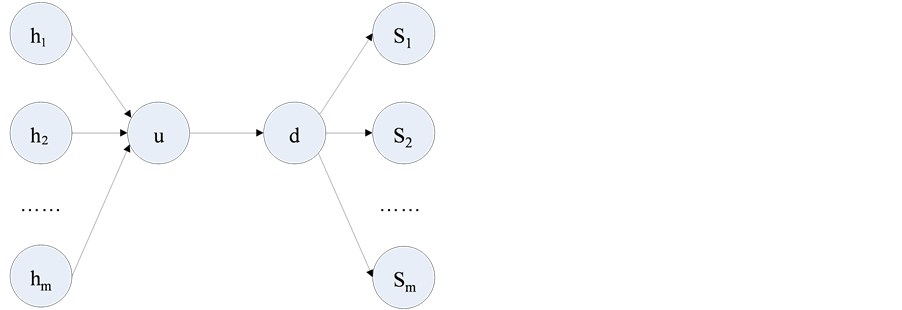
Figure 1. Topology with PCOUNT evaluation
图1. 使用PCOUNT评价的拓扑图
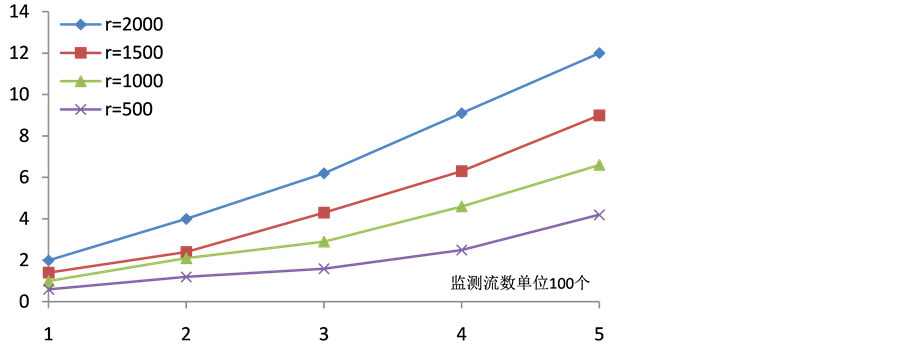
Figure 2. Comparison of execution time, confidence interval is 95%
图2. 执行时间对比图,置信区间为95%
执行时间:接下来验证PCOUNT算法在监测数据流的规模变大时,执行时间的变化情况。固定时间窗口为2秒钟,如图1所示,评估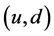 的丢包率。执行时间是指当PCOUNT算法发送第一个静态队列到PCOUNT算法计算出丢包率的时间。如果PCOUNT算法监测到在链路
的丢包率。执行时间是指当PCOUNT算法发送第一个静态队列到PCOUNT算法计算出丢包率的时间。如果PCOUNT算法监测到在链路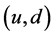 上集中
上集中 数据流的包丢失,该算法将向节点发送一个静态队列,并且发送一个集中数据流队列给节点。Mininet使用linux缺省的调度器,实现的是CPU多进程,保证了交换机为空时,多线程的处理PCOUNT请求。
数据流的包丢失,该算法将向节点发送一个静态队列,并且发送一个集中数据流队列给节点。Mininet使用linux缺省的调度器,实现的是CPU多进程,保证了交换机为空时,多线程的处理PCOUNT请求。
图2表明了算法的总体执行时间作为PCOUNT算法的数据流数目的一个输入,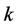 ,这里每个数据点的平均计算时间均通过超过50次的实验模拟得出。为了评估流表大小对队列执行时间的影响,本文在
,这里每个数据点的平均计算时间均通过超过50次的实验模拟得出。为了评估流表大小对队列执行时间的影响,本文在 和
和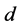 上设定了
上设定了 个流表项。算法的执行时间大部分都是在交换机上处理
个流表项。算法的执行时间大部分都是在交换机上处理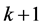 个静态队列的时候消耗掉的,执行时间根据
个静态队列的时候消耗掉的,执行时间根据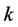 成倍数增长,在每个
成倍数增长,在每个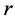 流表项之间都会产生一段较长的时间间隔。本文的实验结果表明,为了获得合理的执行时间,只监控少于75次的流就可以满足实验要求。
流表项之间都会产生一段较长的时间间隔。本文的实验结果表明,为了获得合理的执行时间,只监控少于75次的流就可以满足实验要求。
由于交换机在每次模拟之间是空闲的,因此,CPUs在软件交换机上所产生的能耗比硬件交换机模式下将更多 [14] ,本文的实验结果低估了处理时间。此外,PCOUNT算法执行贝努利试验会丧失部分优越性,原因是在所有流中的丢包率是均匀的,并且丢包的发生也是有规律的。同时,实验结果并没有统计和监测大规模流队列的丢包情况。因此,使用PCOUNT算法的实际效果应该比贝努利试验得到的效果更优越。
5.2. 备份树安装模拟器
在本部分,我们将模拟单一链路故障的情况,并且测量故障恢复时间,交换机存储开销,控制平面信号,以及PROACTIVE算法和REACTIVE算法在没有进行MERGER优化情况下的垃圾回收开销。由于篇幅限制,本文仅说明了控制平面的信号结果,并简单介绍了总体实验情况。实验的详细步骤和结果参见文献 [13] 。
设定:使用IEEE总线系统14, 30, 57和1184,以及基于IEEE总线系统的合成图。合成图的生成方法,参见参考文献[13] ,该文献中使用了IEEE总线系统作为一个临时模板生成具有相同度分布的合成图。
我们假设物理总线系统拓扑的网络总体沟通成本是可以全部检测到的,一个Openflow交换机安装在每个总线上,也安装在两个单向链路之间,每个方向上交换机的配置相同。设定PMUs器件测量电压和当前总线的相量,之后将测量结果发送给第一跳链接的交换机,之后通过Openflow交换机对PMU测量结果进行广播。
对每个总线系统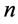 来说,我们生成了
来说,我们生成了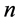 个交换机,
个交换机,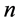 个节点的合成拓扑,并且将链路权重设定为1。
个节点的合成拓扑,并且将链路权重设定为1。
然后,随机生成 个多播组,每个组有
个多播组,每个组有 个随机终端节点,使用STEINER_ARBORESCENCE
个随机终端节点,使用STEINER_ARBORESCENCE
近似算法来生成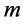 个初始树。BUNCHY算法中
个初始树。BUNCHY算法中 ,然后对每个初始树进行预先计算,对每个初始树链路生成一个备份树。之后,我们将一个随机链路
,然后对每个初始树进行预先计算,对每个初始树链路生成一个备份树。之后,我们将一个随机链路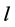 关闭,制造链路故障,触发REACTIVE算法和PROACTIVE算法,来设定备份树。对每个
关闭,制造链路故障,触发REACTIVE算法和PROACTIVE算法,来设定备份树。对每个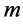 ,生成35个不同的有向树,3个随机的多播组集合。
,生成35个不同的有向树,3个随机的多播组集合。
本文对比了安装备份树的控制信号,在网络中安装备份树的信号是初始树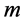 的函数。图3表明REACTIVE算法运行在BASIC和MERGER模式下的结果,使用基于IEEE总线系统57来生成有向拓扑图。实验结果的趋势可以用来说明整个网络的状况。
的函数。图3表明REACTIVE算法运行在BASIC和MERGER模式下的结果,使用基于IEEE总线系统57来生成有向拓扑图。实验结果的趋势可以用来说明整个网络的状况。
REACTIVE + LB计算出链路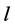 失效后需要安装的备份树
失效后需要安装的备份树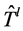 的最小个数,计算出
的最小个数,计算出 在每个节点出向链路的集合数目
在每个节点出向链路的集合数目 ,制定
,制定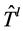 在
在 转发包的规则。将通过
转发包的规则。将通过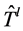 的节点数相加,并返回其下限值。
的节点数相加,并返回其下限值。
信令开销结果:PROACTIVE比REACTIVE的信令开销更小,甚至比REACTIVE + LB的开销也小。PROACTIVE通过使用故障链路给备份树的根节点发送一个控制信息来触发备份树。REACTIVE必须给多个交换机同时发送信号才能安装备份树。
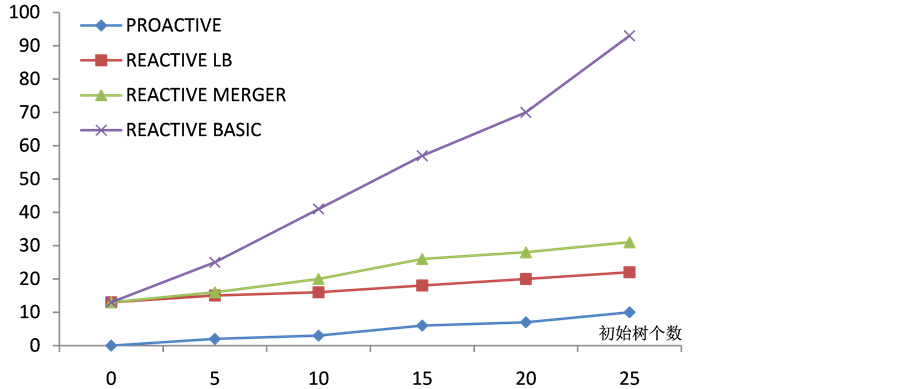
Figure 3. Control signal for triggering backup tree
图3. 触发备份树的控制信号个数
对REACTIVE而言,BASIC和MERGER之间的差距增加了备份树的数目,因为随着 的增长,MERGER可以重复使用备份树的转发规则。实验结果表明当
的增长,MERGER可以重复使用备份树的转发规则。实验结果表明当 时,MERGER由于重复使用了转发规则,将节省75%的开销。平均而言,MERGER仅需要LB算法25%的信令消息,这表明MERGER的本地优化并没有因为流的聚合而丧失优越性。
时,MERGER由于重复使用了转发规则,将节省75%的开销。平均而言,MERGER仅需要LB算法25%的信令消息,这表明MERGER的本地优化并没有因为流的聚合而丧失优越性。
其他实验结果:使用上述相同的实验设定,本文将 进行量化,
进行量化, 是PROACTIVE算法根据转发规则需要预先安装的备份树的数目,安装备份树的时间,垃圾回收开销。我们发现这三种评价指标的值与信号开销成正比。
是PROACTIVE算法根据转发规则需要预先安装的备份树的数目,安装备份树的时间,垃圾回收开销。我们发现这三种评价指标的值与信号开销成正比。
6. 总结
本文对智能电网数据多播的可靠性进行了研究,提出并设计了一种快速丢包监测和快速故障恢复方法,通过预先计算并安装备份树实现了快速的网络链路故障恢复。由于预先计算备份树的方法需要改变现有网络的交换机,因此,本文使用Openflow交换机来实现新的转发规则。
首先提出了PCOUNT算法,使用Openflow协议来预先监测网络内部丢包率。然后,设计多播回收算法来计算备份树,并且重利用多播树的边界规则来降低控制平面的信令。多播回收被证明是NP难问题,本文提出了一种近似算法来对该问题进行求解。最后,提出了PROACTIVE和REACTIVE算法,安装在Openflow交换机上来执行。为优化PROACTIVE和REACTIVE算法,本文提出了MERGER算法,将交换机上的转发规则进行合并,这些交换机必须是多播树的普通子节点。
Mininet模拟器表明当监视短期时间窗的小规模流时,PCOUNT算法的准确性。通过预先安装备份树,PROACTIVE算法的时间开销是REACTIVE算法的十倍,因为相比REACTIVE算法的控制信令发送机制,PROACTIVE算法必须为每个多播信令交换机安装备份树。最后,我们发现MERGER算法比PREACTIVE算法降低了2倍到2.5倍的控制平面信令开销。
文章引用
黄远丰,赵 煜,廖兵兵,王勇波. 基于Openflow的智能电网网络链路故障恢复研究
Research on Fast Recovery from Link Failures Based on Openflow in Smart Grid[J].
智能电网, 2015, 05(05): 242-251. http://dx.doi.org/10.12677/SG.2015.55029
参考文献 (References)
- 1. Bakken, D., Bose, A., Hauser, C., Whitehead, D. and Zweigle, G. (2011) Smart generation and transmission with co-herent, real-time data. Proceedings of the IEEE, 99, 928-951. http://dx.doi.org/10.1109/JPROC.2011.2116110
- 2. Yardley, J. and Harris, G. (2012) 2nd day of power failures cripples wide swath of India. http://www.nytimes.com/2012/08/01/world/asia/power-outages-hit-600-million-in-india.html?pagewanted=all&r=1&
- 3. Birman, K., Chen, J., Hopkinson, E., et al. (2005) Overcoming communications challenges in software for monitoring and controlling power systems. Proceedings of the IEEE, 93, 1028-1041. http://dx.doi.org/10.1109/JPROC.2005.846339
- 4. Bobba, R., Heine, E., Khurana, H. and Yardley, T. (2010) Exploring a tiered architecture for NASPInet. Innovative Smart Grid Technologies (ISGT), Gaithersburg, 19-21 January 2010, 1-8. http://dx.doi.org/10.1109/isgt.2010.5434730
- 5. McKeown, N., Anderson, T., Balakrishnan, H., et al. (2008) Openflow: Enabling innovation in campus networks. Computer Communication Review, 38, 69-74. http://dx.doi.org/10.1145/1355734.1355746
- 6. Caceres, R., Duffield, N., Horowitz, J. and Towsley, D. (1999) Multicast-based inference of network-internal loss characteristics. IEEE Transactions on Information Theory, 45, 2462-2480. http://dx.doi.org/10.1109/18.796384
- 7. Cui, J., Faloutsos, M. and Gerla, M. (2004) An architecture for scalable, efficient, and fast fault-tolerant multicast provisioning. IEEE Network, 18, 26-34. http://dx.doi.org/10.1109/MNET.2004.1276608
- 8. Pointurier, Y. (2002) Link failure recovery for mpls networks with multicasting. Master’s Thesis, University of Virginia, Charlottesville.
- 9. Mccauley, J. (2010) POX: A python-based Openflow controller. http://www.noxrepo.org/pox/about-pox/
- 10. Lantz, B., Heller, B. and McKeown, N. (2010) A network in a laptop: Rapid prototyping for software-defined networks. Proceedings of the 9th ACM SIGCOMM Workshop on Hot Topics in Networks, Article No. 19. http://dx.doi.org/10.1145/1868447.1868466
- 11. Rosen, E., Viswanathan, A., Callon, R., et al. (2001) Multipro-tocol label switching architecture. RFC 3031.
- 12. Luebben, R., Li, G., Wang, D., Doverspike, R. and Fu, X. (2009) Fast rerouting for IP multicast in managed IPTV networks. 17th International Workshop on Quality of Service, Char-leston, 13-15 July 2009, 1-5. http://dx.doi.org/10.1109/iwqos.2009.5201406
- 13. Gyllstrom, D. (2014) Making networks robust to component failures. Ph.D. Dissertation, University of Massachusetts, Massachusetts.
- 14. Rotsos, C., Sarrar, N., Uhlig, S., Sher-wood, R. and Moore, A. (2012) OFLOPS: An open framework for openflow switch evaluation. Proceedings of the 13th International Conference on Passive and Active Measurement, Vienna, 12- 14 March 2012, 85-95. http://dx.doi.org/10.1007/978-3-642-28537-0_9