Smart Grid
Vol.
11
No.
01
(
2021
), Article ID:
40580
,
12
pages
10.12677/SG.2021.111004
一种基于人机协同的窃电用户判别方法
韩雨1,刘沐灿2,刘剑锋1,朱虓2,何正民1,王红月1,郭崇慧2*
1北京科东电力控制系统有限责任公司,北京
2大连理工大学系统工程研究所,辽宁 大连
收稿日期:2021年1月21日;录用日期:2021年2月13日;发布日期:2021年2月24日

摘要
人工智能模型在窃电用户识别实际工业场景中应用时面临着高识别率与低成本之间的矛盾。对于训练完成的模型,通过设置模型判别阈值使其识别出更多窃电用户的同时也将导致更多非窃电用户被错误识别,造成现场排查成本的增加;反之,若追求较低的现场排查成本,那么只能识别出相对较少的窃电用户。针对此矛盾,本文提出了一种基于人机协同的窃电用户判别方法。在该方法中,电网公司首先根据自身特点与需求选取合适的模型判别阈值,然后结合模型判别依据与人工经验知识对模型初步判定结果进行筛查,最后只需对相对较少的用户进行现场排查,从而降低人力、物力成本。此外,电力公司可以根据模型从用户用电数据中学到的“知识”对自身领域知识进行补充,还可以对模型所使用的指标体系进行修正、改善。本文所提出的方法对于人工智能模型在窃电用户识别的应用方面具有一定的管理意义与实际应用价值。
关键词
人机协同,窃电用户判别,模型阈值,可解释机器学习
An Electricity Theft Users Distinguishing Method Based on Human-Machine Cooperation
Yu Han1, Mucan Liu2, Jianfeng Liu1, Xiao Zhu2, Zhengmin He1, Hongyue Wang1, Chonghui Guo2*
1Beijing Kedong Power Control System Co., Ltd., Beijing
2Institute of Systems Engineering, Dalian University of Technology, Dalian Liaoning

Received: Jan. 21st, 2021; accepted: Feb. 13th, 2021; published: Feb. 24th, 2021

ABSTRACT
There is a contradiction between high recognition rate and low cost in the real industrial condition of electricity theft users distinguishing when using artificial intelligence model. For a trained artificial intelligence model, there will be higher false alarm rate when the model discrimination threshold is set to identify more electricity theft users; on the contrary, only a relatively small number of electricity theft users can be identified if a lower on-site investigation cost is pursued. In the light of this contradiction, a human-machine cooperation method is proposed. In this method, the power grid company first selects the appropriate model discrimination threshold according to its own characteristics and needs, then combines the artificial experience and the model explanations to screen the preliminary judgment results of the model, and finally only needs to conduct on-site investigation for relatively few users, so as to reduce the cost of human and material resources. In addition, power grid companies can supplement their own domain knowledge according to the “knowledge” learned from the user electricity data. They can also improve the designing of features used in the model. The method proposed in this article has significance value of management and practical application of artificial intelligence model in distinguishing electricity theft users.
Keywords:Human-Machine Cooperation, Electricity Theft Users Distinguishing, Threshold Value of Model, Interpretable Machine Learning

Copyright © 2021 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
自第二次工业革命以来,电力已经成为国家经济、社会发展、人民日常生活中至关重要的能源。电力系统中电能生产与电能消费的平衡使得人民生活用电和地区生产用电能够得到持续、稳定的供应。然而,少数不法分子为了攫取经济利益,试图以不当手段窃取电力,从而对电网的正常运行产生严重的影响。这不仅会扰乱地区电网的正常调度,对地方经济的发展和企业经营管理以及供电秩序带来严重的威胁。用户私自改接线路还可能引发安全事故,危害自己及其他用户的生命财产安全 [1]。由于用电用户基数众大且窃电用户所采取的窃电手段种类繁杂,对其进行细致排查会耗费大量人力成本。
随着电网的智能化程度不断提高,远程用电信息采集系统的使用也越来越普及。远程用电信息采集系统中丰富、密集的电网数据使得基于大数据和人工智能的窃电行为检测、窃电用户识别成为可能 [2]。基于经加工处理后的电网数据,结合人工智能的方法,可以构建判别窃电用户的数学模型。近年来,已经有很多学者在反窃电技术的模型方面展开了大量的研究,使模型获得更高的判别精准度。但由于模型拟合偏差、数据分布差异、数据噪声等因素,所构建的任何人工智能模型都不是万无一失的。对人工智能模型自身局限的正确认识对于其实际应用有着重要的意义。在对窃电用户进行判别时,所使用的人工智能模型在正确识别出窃电用户的同时也一定会伴随着错误的识别,或者说模型所判定的每一个窃电用户都有可能是正常用户,所判定的每一个正常用户也都有可能是窃电用户。这并非意味着人工智能模型是无效的,而是说在使用模型时面临着模型识别出更多疑似窃电用户与其带来的更高排查成本之间的权衡。电网公司可以根据自身的目标与限制对模型采取合理的使用方案。此外,对于电网公司来说,模型如何针对某个用电用户给出判别结果以及模型基于哪些“知识”进行判别是非常重要的。前者的本质即机器学习模型对于单个样本进行判别的解释,后者的本质即机器学习模型对整个数据集的群体层面解释,这些都有助于模型使用者调整自身对模型的信任程度,补充领域知识以及修正、调整模型。
人工智能模型在窃电用户识别实际工业场景中应用时面临着高识别率与低成本之间的矛盾。对于训练完成的模型,通过设置模型判别阈值使其识别出更多窃电用户的同时也将导致更多非窃电用户被错误识别,造成现场排查成本的增加;反之,若追求较低的现场排查成本,那么只能识别出相对较少的窃电用户。针对此矛盾,本文提出一种人机协同判别窃电用户的方法。该方法的主要贡献如下:
(1) 本方法帮助电网公司根据自身需求对模型判别阈值进行设定,从而实现对窃电用户判别任务中高识别率与低成本之间的权衡。
(2) 本方法使模型使用人员与机器协同判别以提高识别率,节省人力、物力资源。借助机器对所有用电用户进行初步判别从而避免对所有用户进行人工筛查;模型使用人员借助模型判别依据对模型判别的疑似窃电用户进行进一步筛查,从而节省现场排查所消耗的人力、物力资源。
(3) 在本方法中,模型使用人员可以根据自身领域知识来优化、改善模型所使用的指标体系;还可以借助模型从大量数据中学到的“知识”来补充自身领域知识。
2. 相关工作
目前已有大量研究者针对大数据与人工智能在反窃电方面的模型、方法展开研究。在无监督学习方面,包雯莉等人建立了反窃电指标评价体系,运用K-Means聚类建立窃电嫌疑评判模型,然后抽取出典型用户以制定规则, 再根据规则来筛选嫌疑用户 [3]。张铁峰等人提出了一种基于K-means聚类的用电异常两阶段检测方法,并利用灰色分析对影响电力负荷的因素及影响程度进行分析 [4]。Choksi等人提出了一种基于特征的聚类算法,能够有效地对用户用电数据进行降维,描述负荷剖面和概率负荷变化评估,从而区分出用电异常用户 [5]。在有监督学习方面,秦娜首先对电力指标运用主成分分析法进行特征提取,在此基础上建立基于随机权神经网络(RVFLN)的用户窃电诊断模型 [6]。任关友等人基于反向传播神经网络,结合聚类分析相关技术,建立了一套基于负荷、电压、电流等指标的窃电行为检测模型 [7]。张承智等人基于实值深度置信网络,提出了一套用户侧窃电行为检测的模型方法 [8]。黄星知提出了基于双隐含层反向传播神经网络的窃电检测模型,分析了窃电指标与电能消耗量之间的关系 [9]。Wang等人则采用自回归综合移动平均模型(Autoregressive Integrated Moving Average mode l, ARIMA)和人工神经网络,提出了一套住宅电力负荷异常检测框架 [10]。李波等人利用用户的历史用电数据,结合粒子群算法和支持向量机,实现了用户用电的异常检测 [11]。王逸兮等人基于改进版支持向量机,提出了一套电力企业信息系统异常检测方案的优化方法 [12]。
大多数学者针对电力异常检测的算法展开研究,但几乎没有研究者对于窃电用户识别任务中人工智能模型所面临的高识别率与低成本之间的权衡进行讨论。本文借助机器学习的解释工具针对此问题提出解决方案。支持向量机、多层感知机和集成模型如随机森林、XGBoost等具有强大的线性与非线性拟合能力的模型能够在高维空间中更好地捕捉数据模式,但其对数据进行判别时所依据的模式都是无法被人们理解的。目前有大量研究人员围绕上述复杂的机器学习模型的可解释性展开研究。Goldstem等人提出的ICE (Individual Conditional Expectation)方法可以对有监督机器学习模型中每一个特征如何影响预测结果进行可视化 [13]。Ribeiro等人提出的LIME (Local Interpretable Model-agnostic Explanations)通过学习一个预测样本附近的数据从而对任何模型的预测结果进行解释 [14]。博弈论中用于按照联盟中所有玩家的贡献以尽可能公平的方式来分配收益的Shapley值 [15] 也被用于机器学习解释的研究中。Strumbelj等人将该思想应用于机器学习的解释中,提出了一种基于Shapley值的特征重要性计算方法,从而展示针对每个样本,其每个特征在多大程度上使模型倾向于某一个预测结果 [16]。这种方法计算所得的特征重要性可以针对单个样本预测结果给出解释,并且充分考虑了不同特征之间的相互作用对预测结果的影响。机器学习解释方法可以在一定程度上帮助人与机器进行交互。人通过理解机器如何针对每个样本做出判别可以调整对每次判别的信任程度,也可以通过对模型从大量数据中所学到的知识进行了解从而对模型进行修正、改善,还可以补充自身领域知识。
3. 人机协同窃电用户判别方法
3.1. 总体框架
在实际工业场景中,模型使用者在了解模型所面临的高识别率与低排查成本之间的矛盾后,结合自身情况与偏好,可以对模型进行更合理的运用。
本文提出的方法的具体流程如图1所示。模型使用方将用户用电相关数据作为输入(见①),根据对高识别率与低排查成本的权衡设置合适的模型判别阈值(见②),训练好的窃电用户判别模型可以对所有待测试的用户进行判别并得到每个待测试用户是窃电用户的疑似程度,结合给定阈值,可以得到模型判别的疑似窃电用户;工作人员结合自身经验知识与模型判别时产生的依据对模型判别的疑似窃电用户进一步筛查,最终得到数量相对较少的疑似窃电用户(见③)。此外,工作人员还可以根据模型从大量数据中学到的“知识”来丰富自身的经验知识(见④),也可以根据自身经验知识对模型所使用的指标体系进行进一步优化、改善(见⑤)。
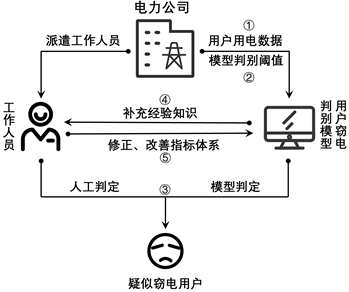
Figure 1. Flow chart of human-machine cooperation method for identifying electricity theft users
图1. 人机协同判别窃电用户方法流程图
3.2. 窃电用户判别模型构建
本文的窃电用户判别模型构建过程主要包括用户用电指标体系构建与判别模型构建两个部分。
3.2.1. 用户用电指标体系构建
科学、合理的窃电用户指标体系对于人工智能模型的正确判别来说至关重要。用电信息采集系统中用户用电数据时间跨度大、更新速度快且存在大量噪声与缺失值,故所设计的指标体系不仅需要能够真实反映用户用电行为的特点,还需使得具有上述特点的用电数据能够方便计算。本文所构建的指标体系主要基于用户用电数据中的电量、电流、电压时间序列数据获得,主要包括电量移动平均时间序列、电量移动平均差分时间序列、电压不平衡度时间序列以及电流不平衡度时间序列的统计学指标。
(1) 日冻结电量指标
对于每个用户的每日用电量时间序列 (下标T表示以天为单位的时间序列长度,下同),可以计算电量移动平均(取移动窗口长度n = 5)。对于第t天(t ≥ 5)的移动平均值计算方式如下:
(1)
根据每个用户的日平均电量移动平均,计算其第t天(t ≥ 6)的电量移动平均差分值 :
(2)
对于每个用户,我们得到日平均电量移动平均时间序列 及日平均电量移动平均差分时间序列 ,针对上述两个时间序列,分别计算均值、中位数、标准差、偏度及峰度五个统计量,最终每个用户得到十个关于电量的统计量特征。
(2) 用户电压、电流指标
根据每个用户每日96点电压示值,可得到每个用户的三相电压时间序列 , 与 。第t时刻的电压不平衡度可由下式计算得到:
(3)
之后,根据一天内各时刻的电压不平衡度,分别计算每个用户每日的三相电压不平衡度。
同理,根据每个用户每日96点电流示值,可计算每个用户的三相电流时间序列 , 与 。第t时刻的电流不平衡度可由下式计算得到:
(4)
之后,根据一天内各时刻的电流不平衡度,分别计算每个用户每日的三相电流不平衡度。
最后,由用户的电压、电流每日不平衡度的时间序列可以计算均值、中位数、标准差、偏度及峰度五个统计量,最终每个用户得到十个关于电压不平衡度和电流不平衡度的统计量特征。
经过上述计算,每个用户样本得到20个特征见表1。

Table 1. Features of electricity using behaviors
表1. 用户用电行为特征
3.2.2. 窃电用户判别模型构建
经过上述指标体系的构建过程,每个用电用户得到20个特征。根据用电用户特征矩阵与是否为窃电用户的标签数据可构建窃电用户的判别模型。本文采用常见的机器学习模型对用户用电数据进行建模,通过对比选取预测效果最好的模型。模型包括XGBoost (eXtreme Gradient Boosting,极度梯度提升树)、随机森林、决策树、支持向量机、逻辑回归以及多层感知机。在本研究中,首先使用分层抽样将整个数据集按照7:3的比例划分训练集与测试集。然后在训练集中使用网格搜索与交叉验证对每个模型的参数进行调整,以最大化预测准确率(Accuracy)为目标选取每个模型的最优超参数组合,然后使用该超参数组合在训练集上重新训练模型,使用测试集进行模型评估。
3.3. 模型判别阈值设定
机器学习模型在解决分类预测问题时,可以对每个测试样本输出一个之间的值,该值的大小代表模型在多大程度上倾向于判别其为正例样本或负例样本。若模型的阈值被设定为0.5,即表示当一个样本的预测值大于0.5时则判定其为正例,反之为负例。模型阈值其实可以根据电网公司的需求进行合理设定。选取一个小的阈值意味着倾向于将更多的样本判定为正例,提高窃电用户的识别率,但也将增大非窃电用户误识别率,从而耗费巨大的人力、物力成本;反之,较大的阈值,能够节省更多现场排查的成本,但却只能使模型获得相对较低的识别率。
3.4. 人工判别依据
传统的窃电用户判别任务通常由人对用户的用电数据进行分析,结合自身经验对用户是否存在窃电行为进行判别,这将耗费大量的人力资源。并且人工判别依赖于人的经验知识,其差异可能导致判别的不稳定性。此外,窃电用户所采用的窃电手段多种多样,造成的用电数据特点也有所差异,进一步加大了人工判别的难度。表2中简要总结了正常用户与窃电用户在几个用电指标上的差异。电量的移动平均及移动平均差分时间序列无法单独作为判定用户是否窃电的指标,而是在用户的三相电流不平衡度与三相电压不平衡度出现异常时进一步辅助判断。正常用户的每相电流间趋势相近,不平衡度较低,大多数在0.4以下,而窃电用户的三相电流间差异较大,不平衡度很大。其中有两种极端情况,第一种是用户三相电流为0,导致不平衡度计算结果为空;第二种是三相电流中有一相电流为0,导致不平衡度计算为1。三相电压也是判别用户是否窃电的重要依据。正常用户三相电压间趋势相近,大多数用户不平衡度小于0.1,而窃电用户的三相电压趋势不同,不平衡度较高。根据上述比较明显的差异以及工作人员本身的经验,可以对窃电用户进行判别。
Table 2. Basis of artificial distinguishing
表2. 人工判别依据
3.5. 模型判别依据
在本文中,模型判别依据指的是针对一个用户,其各个特征的取值在多大程度上使得模型倾向于判定其为窃电用户还是非窃电用户。本文使用基于Shapley值的方法对模型的判别结果进行解释,可以得到模型判别一个用电用户为窃电用户或正常用户的依据,而将模型对大量样本的判别依据进行汇总后,可以得到群体层面的解释,即模型从数据中学习到的“知识”。Shapley值是来自于博弈论的概念,其目的是将联盟的总收益以尽可能公平的方式按照成员的贡献进行分配。在使用Shapley进行机器学习解释的方法中,一个特征的Shapley值是其对最终判别结果的贡献量,第j个特征的Shapley值可以由下式计算而得 [16]:
(5)
其中S是模型所使用的特征的子集合,x为样本的特征向量,p为特征的数目。该求和在所有不含玩家i的特征子集上进行,所计算的每一项 中都对包含特征i与不含特征i的预测值差异进行计算,从而计算一个样本的特征对其预测结果在多大程度上使得模型倾向于判定其为窃电用户还是非窃电用户。
4. 实验结果及分析
本章首先对所构建的窃电用户判别模型效果进行评估,并展示如何基于电网公司的需求,对完成训练的模型的判别阈值进行设定;然后以一个正常用户与一个窃电用户为例,展示如何结合人的经验与机器判别的依据进行协同判定;最后展示模型从大量用户数据中所学到的“模型知识”。
4.1. 窃电用户判别模型评估
本研究采用来自我国某省用电信息采集系统采集的高压用户(大型专变用户、中小型专变用户)真实用电数据,其中共包括382个用户的相关数据,其中正常用户130户、窃电用户252户。数据集根据分层抽样划分为训练集和测试集,评估指标为准确率(Accuracy)、精准度(Precision)、召回率(Recall)以及F1分数(以0.5为模型阈值)。
Table 3. Comparison of model distinguishing performance
表3. 模型判定效果对比
实验结果如表3所示,XGBoost在准确率、精准度以及F1指标上都得到了最高分数,而在召回率指标上也接近由逻辑回归所得的最高值。故本文选择XGBoost模型进行后续分析。
根据所选模型对测试数据的预测结果绘制受试者操作曲线与精准度–召回率曲线如图2所示。
图2的两个曲线均展示了当设置不同的判别阈值时,模型对于预测样本为正例与负例的偏好。两条曲线分别表示预测结果的真正率与假正率之间的关系和精准度与召回率之间的关系。由图2(a)可以看到,真正率的提高可通过降低模型的阈值来实现,但这会导致假正率升高。而在图2(b)中可以看到,随着阈值的减小,精准度降低,召回率增高。总之,当取更小的模型阈值时,能够识别出更多的窃电用户,但相应会带来更大的排查成本。
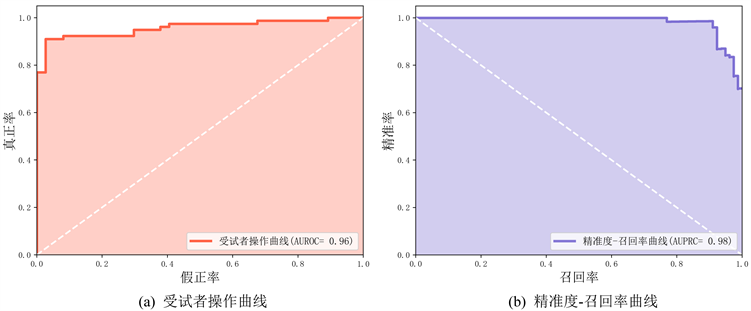
Figure 2. Receiver operating characteristic curve and precision-recall curve
图2. 受试者操作曲线与精准度–召回率曲线
当阈值取0.3,0.5与0.7时模型的各项评估指标对比见表4。以阈值取0.7为例,这意味着能够识别出约92%的真正窃电用户,且会将约13.5%的正常用户判定为窃电用户,而每识别出一个真正的窃电用户会需排查约1.07 (1/0.9351)个用电用户。电网公司可以根据自身情况进行合适的阈值选择。
Table 4. Comparison of model performance with different threshold values
表4. 不同阈值下的模型效果对比
4.2. 人机协同判别窃电用户
4.2.1. 单个用电用户判别
本文以一个窃电用户与一个正常用户的判别依据为例进行展示,以说明模型如何根据一个用户的用电数据特征给出一个预测结果;并根据用户指标时间序列,说明人工判别的依据。图3所展示的是由开源机器学习解释工具SHAP绘制的模型判定依据图。其中纵坐标展示的是用户用电数据的特征名称及取值,位置靠前的特征对于判定结果来说有着更大的重要性。图中的初始期望值表示对于整个数据集中的用户群体,若不考虑其特征上的差异,模型对所有用户做出的预测值为2.19;而考虑每个用户的特征差异后,模型最终可为每个用户计算一个模型预测值,图3(a)中预测值为−4.46意味着模型极倾向于判别该用户为正常用户,而图3(b)中的6.55则表示模型极倾向于判别用户为窃电用户。箭头中的数字表示每个特征对于一个判别结果的贡献量,所有特征的贡献量之和等于模型的预测值。图中红色的箭头表示一个特征使得模型倾向于判别该用户为窃电用户,且箭头上的数值越大,模型判别其为窃电用户的倾向越强;蓝色箭头则表示一个特征使得模型倾向于判别该用户为正常用户。在图3中,电压不平衡度标准差对于两个判别结果来说都是最重要的因素,图3(a)展示的用户的该指标取值为0.001远小于图3(b)用户的0.079,而由图4(b)的三相电压不平衡曲线也可以看出所展示的窃电用户相比于正常用户具有大幅的三相电压不平衡度波动。图4(a)用户各项指标都具有相对较小且稳定的取值,模型根据这些用户用电特点将其判定为正常用户。图4(b)用户的三项电流不平衡度在很多时刻出现了大于1的数值,这超出了该指标的正常取值范围(可能由于用户窃电造成电表异常,从而导致电流读数为负值),故由电流不平衡度计算的均值、标准差及偏度等统计指标特征都使模型在很大程度上倾向于判定该用户为窃电用户。电网公司工作人员可以根据用户用电行为的数据,结合模型所给出的判别依据与人的经验知识对模型判别的疑似窃电用户进行初步人工筛查,从而降低现场排查的成本。

Figure 3. Example of basis of model distinguishing in single level
图3. 模型判别依据示例
4.2.2. 窃电用户判别知识
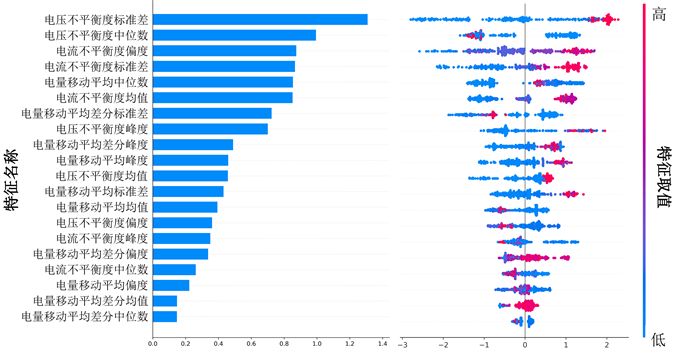
对所有用户判别依据进行汇总,可以得到模型学习到的“知识”。图5展示的是模型从用户用电数据集中所学习到的群体层面的模型解释。图5(a)展示了在本文所构建的窃电用户判别模型中不同特征的重要性,柱状图的长度表示所有用户的判别依据中某个特征的贡献度绝对值的均值,排序靠前的特征对于模型的判别具有更大的重要性。在图5(b)中,模型在判别每个用户时对每个特征计算的贡献度均以蜂群图的形式绘制出。针对某个特征,模型在对每个用户进行判别时计算所得该特征的贡献值都在图5(b)中对应行进行展示:每个圆点代表一个用户,其位置越靠左则说明该特征使模型倾向于判别其为一个正常用户,反之则倾向于判别其为窃电用户;每个圆点的颜色表示该特征取值的相对大小,红色表示该用户的该特征取值相对于所有用户的该特征取值较大,反之则小。以最重要的电压不平衡度标准差特征为例,该特征对于模型的平均贡献值约为1.3 (见图5(a));具有高电压不平衡度标准差取值(红色)的用户会更容易被模型判别为窃电用户,具有低电压不平衡度标准差取值(蓝色)的大部分用户更容易被模型判别为正常用户,而少量用户较低的电压不平衡度标准差取值使得模型更倾向于判别其为窃电用户,这与不同特征之间的相互作用有关。
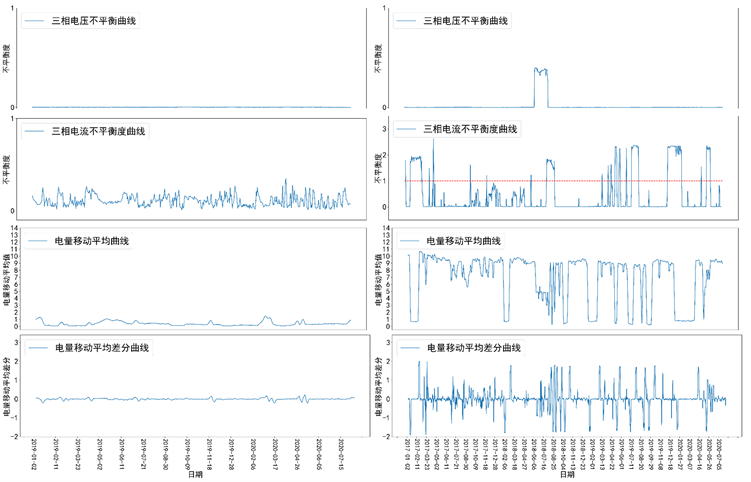 (a) 正常用户用电行为曲线 (b) 窃电用户用电行为曲线
(a) 正常用户用电行为曲线 (b) 窃电用户用电行为曲线
Figure 4. Time series visualization of electricity using behaviors
图4. 用户用电行为时间序列
通过对模型学习到的“知识”进行了解,相关工作人员可以获取一些原本可能没有发现的关于窃电用户的知识,也可以围绕模型判别中重要的特征设计更多的指标。
5. 结论
本文针对人工智能模型在窃电用户识别实际工业场景中应用时所面临的高识别率与低成本之间的矛盾提出了人机协同判别窃电用户方法。本文基于我国某省真实用电数据构建窃电用户判别模型,使用机器学习解释工具为每个用户的判别结果提供模型判别依据,辅助相关工作人员进行人工筛查,从而降低对疑似窃电用户进行现场排查时所消耗的人力、物力成本;此外,对所有判别依据进行汇总以得到模型学习到的“知识”,工作人员可以通过对这些“知识”进行分析以补充自身领域知识,也可以在了解模型所学到的“知识”的不足后修正、改善模型所使用的指标体系。本文所提出的方法相比于以往的关于窃电用户识别算法的研究更具有管理意义与实际应用价值,但仍有着一定的局限性。由于用户用电数据
 (a) 特征贡献度均值 (b) 贡献度取值
(a) 特征贡献度均值 (b) 贡献度取值
Figure 5. Basis of model distinguishing in the group level
图5. 群体层面模型判定依据
具有高维、复杂等特点,我们只能通过提取时间序列统计量特征对用户用电行为进行表示,但计算统计量本身会导致特征的含义变得不易被理解。在以后的研究中,可以使用能够处理时序数据的深度神经网络构建窃电用户辨别模型,并且使用深度学习解释工具直接对多个指标的时间序列数据中的异常时刻进行判别。本文为机器学习模型在窃电用户判别的任务中提供了一种具有管理意义与实际应用价值的新思路。
基金项目
大连市科技创新基金重点学科重大课题“大连智慧城市建设中基于大数据的智能决策理论方法及支持技术研究”( 2019J11CY020)。
文章引用
韩 雨,刘沐灿,刘剑锋,朱 虓,何正民,王红月,郭崇慧. 一种基于人机协同的窃电用户判别方法
An Electricity Theft Users Distinguishing Method Based on Human-Machine Cooperation[J]. 智能电网, 2021, 11(01): 27-38. https://doi.org/10.12677/SG.2021.111004
参考文献
- 1. 黄蔓云, 卫志农, 孙国强, 等. 基于历史数据挖掘的配电网态势感知方法[J]. 电网技术,2017, 41(4): 1139-1145.
- 2. 陈启鑫, 郑可迪, 康重庆, 等. 异常用电的检测方法:评述与展望[J]. 电力系统自动化, 2018, 42(17): 189-199.
- 3. 包雯莉. 反窃电指标评价体系及窃电嫌疑分析[D]: [硕士学位论文]. 上海: 上海交通大学, 2016.
- 4. 张铁峰, 张靖. 一种基于k-means的两阶段用电异常检测方法[J]. 电力科学与工程, 2018, 34(12): 25-31.
- 5. Choksi, K.A., Jain, S. and Pindoriya, N.M. (2020) Feature Based Clustering Technique for Investigation of Domestic Load Profiles and Probabilistic Variation Assessment: Smart Meter Dataset. Sustainable Energy, Grids and Networks, 22, Article ID: 100346.
https://doi.org/10.1016/j.segan.2020.100346 - 6. 秦娜. 基于数据挖掘的反窃电技术在某电网中的应用研究[D]: [硕士学位论文]. 北京: 华北电力大学, 2016.
- 7. 任关友. 专变用户用电特征分析与窃电识别研究[D]: [硕士学位论文]. 昆明: 昆明理工大学, 2018.
- 8. 张承智, 肖先勇, 郑子萱. 基于实值深度置信网络的用户侧窃电行为检测[J]. 电网技术, 2019, 43(3): 1083-1091.
- 9. 黄星知, 杨奕纯, 杨兰, 等. 基于BP神经网络的配电网防窃电降线损研究[J]. 电力科学与技术学报, 2019, 34(4): 143-147.
- 10. Wang, X.L. and Ahn, S.-H. (2020) Real-Time Prediction and Anomaly Detection of Electrical Load in a Residential Community. Applied Energy, 259, Article ID: 114145.
https://doi.org/10.1016/j.apenergy.2019.114145 - 11. 李波, 曹敏, 朱元静, 等. 基于网络特征与用户行为分析的联合窃电检测方法[J]. 武汉大学学报(工学版), 2019, 52(12): 1121-1128.
- 12. 王逸兮, 余铮, 查志勇, 等. 基于改进SVM的电力企业信息系统异常检测方案的优化[J]. 计算机与数字工程, 2020, 48(3): 567-570.
- 13. Goldstein, A., Kapelner, A., Bleich, J., et al. (2015) Peeking inside the Black Box: Visualizing Statistical Learning with Plots of Individual Conditional Expectation. Journal of Computational & Graphical Stats, 24, 44-65.
https://doi.org/10.1080/10618600.2014.907095 - 14. Ribeiro, M.T., Singh, S. and Guestrin, C. (2016) “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, 20-23 August 2006, 1135-1144.
https://doi.org/10.1145/2939672.2939778 - 15. Tucker, A.W. (1959) Contributions to the Theory of Games. Princeton University Press, Princeton.
https://doi.org/10.1515/9781400882168 - 16. Štrumbelj, E. and Kononenko, I. (2010) An Efficient Explanation of Individual Classifications Using Game Theory. Journal of Machine Learning Research, 11, 1-18.
NOTES
*通讯作者。