Modern Linguistics
Vol.
11
No.
05
(
2023
), Article ID:
66149
,
13
pages
10.12677/ML.2023.115288
混合研究视角下的演讲稿情感分析
——以外研社·国才杯全国英语演讲大赛冠军为例
汤慧桃
苏州大学外国语学院,江苏 苏州
收稿日期:2023年3月24日;录用日期:2023年5月19日;发布日期:2023年5月30日

摘要
本研究采用混合研究方法,以2021年外研社·国才杯全国大学生英语演讲大赛冠军决赛过程中的四篇演讲稿为例,进行情感值分句与分段统计、情感变化趋势分析、8类情绪词分类编码统计。研究结果显示,在四篇演讲稿中,正向情绪词明显多于负向情绪词;情感值的至高点出现在演讲的中后段;演讲结束时,情感值明显高于开头情感值。分段情感值波动较大,但总体呈上升趋势。量化与质性分析结果显示,8类情绪词各自占比与占比高低排序存在较大差异。
关键词
混合研究,演讲稿,情感分析,外研社·国才杯,英语演讲

Sentiment Analysis of Speech Drafts from the Perspective of a Mixed Method
—A Case Study of the Champion of “FLTRP Cup” English Public Speaking Contest
Huitao Tang
School of Foreign Languages, Soochow University, Suzhou Jiangsu
Received: Mar. 24th, 2023; accepted: May 19th, 2023; published: May 30th, 2023

ABSTRACT
From the perspective of a mixed method, this study takes 4 final speech drafts of the champion in the 2021 “FLTRP Cup” National English Speech Contest for college students as examples, and conducts clause and segment statistics of sentiment value, analysis of the dynamic process of the fluctuation of sentiment, and classification and coding statistics of 8 categories of sentiment words. The results showed that in the four speeches, positive words outweigh negative words; the peak of the sentiment value mostly appears in the middle or at the end of a speech; the sentiment value at the beginning of a speech is much higher than that of the end. The sentiment value fluctuates dramatically on the paragraph level but is generally on the increase. Quantitative and qualitative analysis results showed that the frequency and the ranking of frequency of the 8 categories of the emotion words vary significantly.
Keywords:Mixed Method, Speech Drafts, Sentiment Analysis, FLTRP Cup, English Speech

Copyright © 2023 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
情感分析(Sentiment Analysis)是指利用自然语言处理的文本挖掘技术,对带有情感色彩的文本进行抽取、分析和处理,从而发现潜在的问题以用于预测或改进(Yang et al., 2021) [1] 。目前,基于自然语言处理的情感分析技术逐渐应用于教育领域(张博、董瑞海,2022) [2] ,但尚无相关研究聚焦于英语演讲,英语演讲情感的重要性在一定程度上被忽视,自然语言处理视角下有关英语演讲情感的量化研究极其匮乏。同时,考虑到量化与质性研究各自的优缺点,本研究采用混合研究方法,使用国际编程软件R和国际质性分析软件Nvivo,以2021年外研社·国才杯全国大学生英语演讲大赛冠军决赛过程中的四篇演讲稿为例,统计了该选手四赛段演讲稿中单句与分段情感值、演讲情感变化趋势、8类情绪词分类占比,同时也对8类情绪词进行了编码统计。希望对该选手四赛段演讲稿中的演讲情感有一个辩证客观、全面的认识,以期在该选手的四篇演讲稿中找到可供广大英语演讲爱好者与备赛学生参考借鉴的演讲范式,从而增大演讲的号召力、感染力与影响力。
2. 文献综述
2.1. 情感分析
在过去近40年,自然语言处理领域逐渐出现10个研究热度较高的技术话题,包括情感分析、机器翻译、问答、语言模型、神经网络模型、语义表示、知识图谱、词对齐、条件随机场和词义消歧(清华大学人工智能研究院,2020) [3] ,如图1所示。其中,2003年以后,情感分析的研究热度迅速增长,其基于自然语言处理的数据挖掘技术被应用于提取和分析用户生成语言中的主观信息。
情感分析(Sentiment Analysis)是指利用自然语言处理的文本挖掘技术,对带有情感色彩的文本进行抽取、分析和处理,从而发现潜在的问题以用于预测或改进(Yang et al., 2021) [1] 。目前,基于自然语言处理的情感分析技术逐渐应用于教育领域(张博、董瑞海,2022) [2] 。
郑耀威在2020年的AAAI会议上,提出了新的分析方法,使用语法信息增强了语句多方面情感分类的效果(Zheng et al., 2020) [4] 。情感分析在教育领域的应用是,通过对学生的课程反馈、教师评价、课程论坛评论等文本信息进行分析,智能化预测学生对学校教育教学现状的态度、评估教师授课质量等等。例如,Heather Newman等人使用情感分析工具VADER分析学校教与学的评价信息,以研究学习环境对改善学生学习的体验,以及对教师教学的体验(Newman & Joyner, 2018) [5] 。Rajput等人基于情感分析指标,对某课程结束后学生提交的反馈报告进行多种方式的文本分析,使教师教学评估更加高效(Rajput et al., 2016) [6] 。因此,分析学生对学校政策、教学活动等事件的反馈与态度,可以使教育组织更加了解学生的需求,不断提高教学质量,提供更具个性化的教育环境。
2.2. 情感词库“Syuzhet”
情感词库“syuzhet”在Jockers指导下由内布拉斯加文学实验室(The Nebraska Literary Lab)开发。这个词库是一个10748 × 2的数据框,包括10748个情感词,有word (词)和value (情感值)两列,其中负面情感词为7161个,正面情感词为3587个。在R软件中调用情感词库“syuzhet”后得到以下结果,见图1。
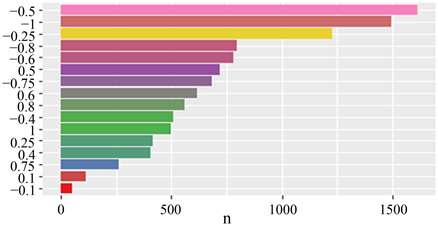
Figure 1. Sentiment value of different kinds of sentiment words in “Syuzhet”
图1. 情感词库“Syuzhet”各类情感词情感值
“Syuzhet”库的情感值有16类:−1.00、−0.80、−0.75、−0.60、−0.50、−0.40、−0.25、−0.10、0.10、0.25、0.40、0.50、0.60、0.75、0.80、1.00,因而“syuzhet”库的尺度范围很大。在各个情感值的分布中,包括情感词数量最多的三个类别是负面情感类,情感值在−0.5、−1和−0.25上的情感词数依次为1616、1493和1229。包括正面情感词数最多的三个类别是0.5 (719个)、0.6 (614个)和0.8 (561个)。包括情感词数最少的三个类别是0.75 (260个)、0.1 (113个)和−0.1 (52个)。
2.3. 情感词库“Nrc”
“Nrc”库,由Mohammad和Turney (2010) [7] 开发,包括8种基本情绪和两极情感(positive and negative)。这8种情绪是anger (愤怒)、fear (恐惧)、anticipation (期待)、trust (信任)、surprise (惊讶)、sadness (悲伤)、joy (喜悦)和disgust (厌恶)。该库是一个13901 × 4的数据框,有lang (语言)、word (词)、sentiment (情感)和value (情感值)四列,包括的情感词总数为13901个。
执行R命令得到各个情绪和情感类别上的情感词数见图2。
“Nrc”库包括的负向情感词和正向情感词分别为3324个和2312个,在8种情绪中,表示恐惧、愤怒、信任、悲伤和厌恶情绪词较多(依次为1476个、1247个、1231个、1191个和1058个),包含词数最少的三类情绪是期待(839个)、喜悦(689个)和惊讶(534个)。
但目前尚无相关研究证实使用R软件进行情感分析时,会考虑情感词所处的语境问题。情感词库“nrc”的两极情感(positive and negative)在情感的分类方式上有其局限性,在实际情况中并非所有情感都属于这两极,也会存在中立情感(neutral)。8类情绪词中最存在争议的是“surprise”(惊讶),R软件将“surprise”(惊讶)归于两极情感中的消极情感(negative)中,但其实在实际语境中,“surprise”(惊讶)可能属于两极情感中的消极情感(negative),也可能属于积极情感(positive),更可能属于中立情感(neutral),这启示研究者在对文本进行情感分析时,要将量化与质性研究相结合,即采用混合研究的方法,并将两种研究方法结果相比对,从而对文本中的情感情况有更为深刻、全面、客观的认识。
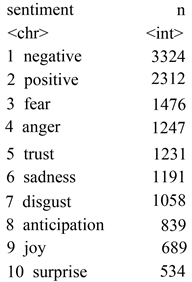
Figure 2. Numbers of different kinds of sentiment words in “Nrc”
图2. 情感词库“Nrc”各类情感词数量
2.4. 研究缺口与研究意义
尚无情感分析研究聚焦于英语演讲,英语演讲情感的重要性一定程度上被忽视。同时,自然语言处理视角下有关英语演讲情感的量化研究极其匮乏。基于演讲情感对演讲的号召力、感染力与影响力有着重大作用的现实情况,本研究使用国际编程软件R,利用R数据包syuzhet中的两个情感词库“syuzhet”和“nrc”,以2021年外研社·国才杯全国大学生英语演讲大赛冠军决赛过程中的四篇演讲稿为例,对该选手在决赛四赛段中的演讲情感进行情感值分句与分段统计学分析、8类情绪词分类统计与演讲情感变化趋势分析,同时针对R软件对情感分析处理可能存在脱离语境的问题,质性分析也必不可少,所以研究者使用国际质性编码软件Nvivo对该选手的四份演讲稿进行人为编码,并将量化与质性分析结果相对比,以期对该选手四份演讲稿中的演讲情感有一个全面、客观的了解。
3. 研究问题
1) 该选手四赛段演讲稿的描述性统计,情感值单句与段落分布是怎样的?
2) 量化与质性方法的研究结果显示,该选手四赛段演讲稿涉及到的情感词库中8类情绪词分布分别如何,有何相同与不同之处?
3) 从该选手的四赛段演讲稿中,可以得出哪些演讲情感运用启示?
4. 研究设计
1) 研究样本
本研究的研究样本是2021年外研社·国才杯全国大学生英语演讲大赛冠军决赛过程中的四赛段演讲稿(即四篇)。
四赛段主题分别为:
1. Red star over China (所有选手赛题相同)
2. What do you think about the idea that ‘Being good in business is the most fascinating kinds of art’? (为该选手抽到的赛题)
3. Job and fulfillment (所有选手赛题相同)
4. The story of us: The Cheesiness (所有选手赛题相同)
该选手的演讲主题分别为:
1. Red star over China
2. Art and business
3. Job and fulfillment
4. Benevolence
2) 数据收集
本研究的四份样本来源于外研社全国英语大赛官网(https://uchallenge.unipus.cn/),研究者通过购买官方备赛课程之一“演讲大赛视频集锦-2021”,获得了2021年外研社·国才杯全国英语演讲大赛决赛四个赛段的赛题,所有演讲者的演讲视频与电子演讲稿。
值得一提的是,该冠军选手在参加省赛时由于取得了第一名的成绩,直接晋级了决赛的第二赛段,所以在官网显示的决赛第一赛段演讲稿中,并没有查到该选手的演讲稿。由于省赛与决赛第一赛段的演讲主题相同,皆为“Red star over China”,所以研究者通过该选手所在大学的公众号找到了该选手参加省赛的演讲稿。
3) 研究方法
因为量化与质性研究各有其优劣势,所以本研究采取了混合研究方法。在本研究中,若只采用量化研究方法,利用R软件中的两个情感词库进行情感分析,往往会忽视不同类情绪词所处的语境,造成研究结果不够准确。若只采用质性研究方法,利用Nvivo软件进行情感分析,编码结果往往会带有较强的主观性。因此,经过综合考虑,本研究采用混合研究方法,希望对该选手四赛段演讲稿中的演讲情感有一个辩证客观,全面的认识。
4) 数据分析
4.1. 量化研究
1) 研究者先将四份演讲稿转化成txt格式,并导入R软件,将四份演讲稿分别命名为S1、S2、S3、S4。
2) 在R软件中执行相关命令,调用R软件中的数据包syuzhet。
3) 使用数据包syuzhet自带函数得到演讲稿的分句情感值和演讲稿分段的情感值变化趋势,四份演讲稿中的8类情绪词分布。
将四份演讲稿合并成同一份文档,名为S5,在R软件中使用上述方法,得到S5中8类情绪词分布,S5的量化研究结果将会与质性研究结果进行比较。
4.2. 质性研究
将四份演讲稿合并成同一份文档,名为S5,将S5导入国际质性分析软件Nvivo。
制定编码框架:在“nrc”情感词库的分类基础上进行改良,编码框架如见图3。
原来的“nrc”情感词库中,8类情绪词分别属于两级情感(positive and negative)。在新的编码框架中,新增了中立情感(neutral)作为一极情感,三个一级编码分别为“negative”、“neutral”、“positive”。一级编码“negative”下设5个二级编码:“anger”、“disgust”、“fear”、“sadness”、“surprise”,一级编码“neutral”下不设二级编码,一级编码“positive”下设4个二级编码:“anticipation”、“joy”、“surprise”和“trust”。考虑到“surprise”(惊讶)在三极情感中都有涉及,又因为一级编码中“中立情感(neutral)”下不设二级编码,所以“surprise”(惊讶)作为二级编码出现了两次。

Figure 3. Coding scheme of this research
图3. 本研究编码框架
5. 研究结果
5.1. 研究问题一:描述性统计,情感值单句与段落分布
5.1.1. 四赛段演讲稿的描述性统计
研究者将S1~S4导入R软件,通过调用R软件中的数据包“syuzhet”中情感词库“syuzhet”得出S1~S4的情感值描述性统计,见表1。

Table 1. Descriptive analysis of the sentiment value in S1~S4
表1. S1~S4的情感值描述性统计
表中统计四赛段演讲稿的句子总数、情感值均值(Mean)、情感值方差(Var)、情感值标准差(SD),从表中可以看出,四份演讲稿句子总数各异,S1句子数最少,为13个,S2句子数为22个,S3句子数最多,为26个,S4句子数为20个,由情感均值和方差可以看出,S3 (主题:Job and fulfillment)整体情感波动最小,情感值较为集中,S4 (夺冠之作,主题:Benevolence)情感波动最大,情感值最为离散。值得一提的是,作为夺冠之作,S4的情感波动最大,也最为牵动人心,一举奠定了该选手的冠军地位。这在一定程度上启示演讲者们在演讲时有意识地增大演讲情感的起伏波动,从而增大演讲的感染力和影响力。
5.1.2. 四赛段每句情感值与各赛段情感总值
在上表的基础上,研究者将情感值具化到每一个句子,得到演讲稿的分句情感值,并计算情感总值,并得到表2,包括S1~S4单句的情感值和S1~S4各自的情感总值。
Table 2. Sentiment value on the sentence level and sentiment value in total in S1~S4
表2. S1~S4单句的情感值与情感总值
从上表中可以看出,受到每份演讲稿句子数的影响,由于S1 (主题:Red star over China)句子数最少,只有13句,所以情感总值最小。S2 (主题:Art and business)情感总值最大,一定程度上可能与句子数较多有关。
5.1.3. 四赛段分段情感值变化趋势
研究者首先对S1~S4进行预处理,S1~S4的句子数分别为13、22、26、20,研究者将S1~S4各自进行预处理分段,保证四份样本各分段中的句子数相同,由于四份演讲稿的句子数并没有除了1以外的公约数,因此分段后只能保证各分段中的句子数近似相同,在本研究中,经过预处理分段后,S1~S4各文本各分段中句子数近似等于3。
在此基础上,研究者在R软件中得到演讲稿分段的情感值变化趋势,见图4。
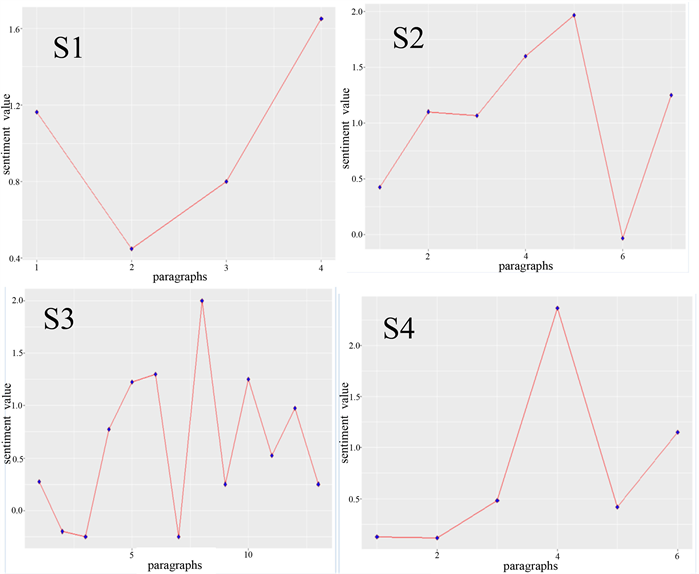
Figure 4. Fluctuation of sentiment value on paragraph level in S1~S4
图4. S1~S4分段情感值变化趋势
如上图所示,每张曲线图为S1~S4各自的分段数,纵轴为情感值。
观察S1~S4各自的情感变化趋势,可以发现S1的情感值经过断崖式下滑后,后期又呈现陡增趋势,S2的情感值则是先节节攀升,后陡降,后呈上升趋势。S3是四份演讲稿中情感值波动最为剧烈的,S4的情感变化趋势与S2大致相同,先是节节攀升,后陡降,最后呈上升趋势,相对于S2、S4的波动趋势稍微小了些。
通过观察S1~S4的情感趋势变化图,可以发现一些共性特征,情感值的至高点大都出现在演讲的中后段,演讲结束时的情感值明显高于开头情感值,S1~S4的情感值波动程度各异,虽然分段情感值波动较大,但总体呈上升趋势。这在一定程度上启示演讲者把握演讲开头与结束时的差异,将演讲情感的至高点留在演讲的中后段,但需注意保持演讲情感值总体上升的趋势。
5.2. 研究问题二:情感词库中8类情绪词分布
5.2.1. 量化视角下四赛段演讲稿情感词使用分布情况
研究者在R软件中调用“nrc”情感词库,得到四份演讲稿中的8类情绪词分布,得到以下结果见图5。
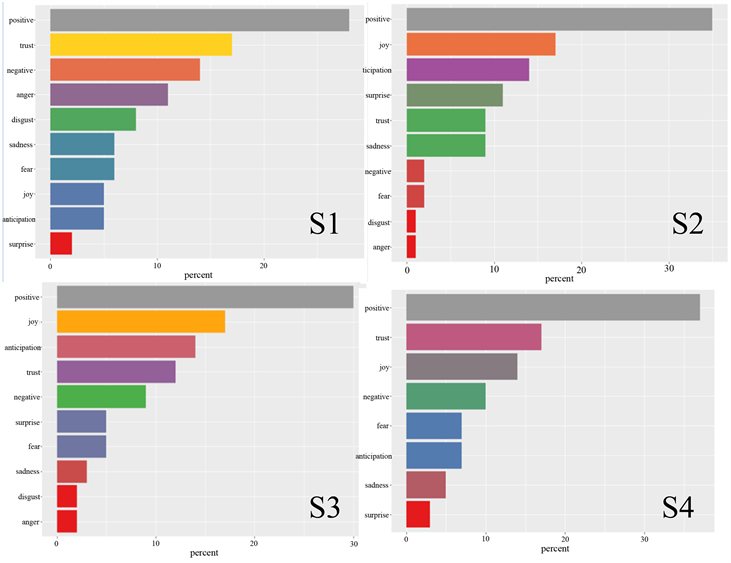
Figure 5. Distributions of 8 kinds of sentiment words in S1~S4
图5. S1~S4中8类情绪词分布
如上图所示,纵轴显示的是“nrc”情感词库中的两级情感(positive and negative)和八类情绪词,横轴显示的是各类情绪词所占的比例(鉴于情绪词“surprise”的特殊性,该类情绪词并不参与下列两级情感的讨论)。
对于S1,正向情感占比28%左右,负向情感占比14%左右,正向情感使用比例约为负向情感的两倍,在八类情绪词中,“trust”所占比例最高,达到17%左右,其次依次是“anger”、“disgust”、“sadness”、“fear”、“joy”、“anticipation”、“sadness”,“surprise”占比最低,仅有2%左右。所有正向情感中,“trust”所占比例最高,所有负向情感中,“anger”占比最高。
对于S2,正向情感占比35%左右,负向情感占比2%左右,正负向情感对比差距明显,在八类情绪词中,“joy”所占比例最高,达到17%左右,其次依次是“anticipation”、“surprise”、“trust”、“sadness”、“fear”,“disgust”和“anger”占比最低,仅有1%左右。所有正向情感中,“joy”所占比例最高,所有负向情感中,“sadness”占比最高。
对于S3,正向情感占比30%左右,负向情感占比9%左右,正向情感使用比例约为负向情感的三倍,在八类情绪词中,“joy”所占比例最高,达到17%左右,其次依次是“anticipation”、“trust”、“surprise”、“fear”、“sadness”,“disgust”和“anger”占比最低,仅有2%左右。所有正向情感中,“joy”所占比例最高,达到17%左右,其次依次是“anticipation”、“trust”、“surprise”、“fear”、“sadness”,“disgust”和“anger”占比最低,仅有2%左右。所有正向情感中,“joy”所占比例最高,所有负向情感中,“fear”占比最高。
对于S4,正向情感占比37%左右,负向情感占比10%左右,正向情感使用比例约为负向情感的三倍多,在八类情绪词中,“trust”所占比例最高,达到17%左右,其次依次是“joy”、“fear”、“anticipation”、“sadness”,“surprise”占比最低,仅有3%左右。所有正向情感中,“trust”所占比例最高,所有负向情感中,“fear”占比最高。
观察S1~S4的情感词使用分布情况,可以发现一些共性特征。正向情绪词明显多于负向情绪词,8类情绪词中属于“joy”与“trust”类别的使用次数最多,属于“anger”与“surprise”类别的使用次数最少。这说明该选手在演讲时表达的大多是积极正面的情感,例如欣喜(joy)、信任(trust)之情,这在一定程度上可能与该选手的演讲主题有关系,例如“Red star over China”(S1)、“Benevolence”(S4)等。四份演讲稿的情感词使用情况启示演讲者们使用尽可能多的正向情感词汇,传递正能量。
5.2.2. 四份演讲稿情感词使用:量化与质性研究对比
在本研究中,关于四份演讲稿情感词使用分布情况的量化与质性研究对比是在将4份演讲稿合并后进行的。
研究者将S1~S4合并成一个文档,名为S5,使用与上一节一样的研究方法得出S5演讲稿的情感词使用分布情况,见图6。
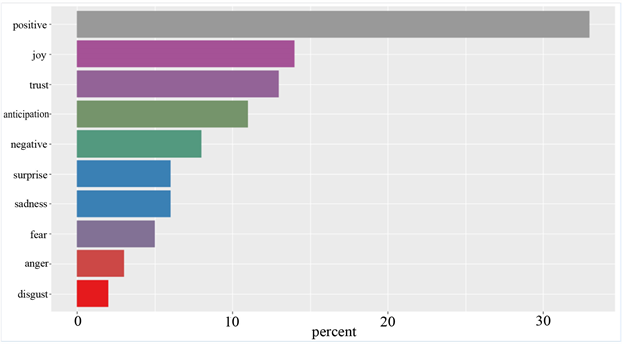
Figure 6. Distributions of 8 kinds of sentiment words in S5
图6. S5中8类情绪词分布
从S5可以看出,正向情感占比33%左右,负向情感占比8%左右,正向情感使用比例约为负向情感的四倍,在八类情绪词中,“joy”所占比例最高,达到14%左右,其次依次是“joy”、“trust”、“anticipation”、“surprise”、“sadness”、“fear”、“anger”,“disgust”占比最低,仅有2%。所有正向情感中,“joy”所占比例最高,所有负向情感中,“disgust”占比最高。以上即为四份演讲稿情感分析的量化结果。
接下来研究者将S5导入国际通用质性分析软件Nvivo,在制定的新的编码框架下,对S5进行单句编码得到以下结果见表3。
Table 3. Coding result on the single sentence level in S5
表3. S5单句编码结果
为保证研究的信效度,整个编码过程由研究者本人,另一位能够熟练操作Nvivo软件研究生M和研究者所在学院的一位专攻质性研究的副教授共同完成并校对。研究者本人和M先分开各自独立编码,编码结果完成后进行比对,重合率达到93%左右,针对存在的分歧,研究者本人和M先进行商讨,讨论后将编码过程中所有存在的分歧统一,得到统一的编码结果后提交给所在学院的一位专攻质性研究的副教授校对并提出修改意见,最终得出以上结果。
从表中可以看出,每一个一级编码和二级编码后都有两个括号,第一个括号内的数字是编码涉及的参考点数,第二个括号内的是该编码的覆盖率。在Nvivo软件中,参考点数相当于句子的编号,由于Nvivo会自动把属于同一编码的相邻的两个句子合并到同一个参考点里,因此存在同一参考点下有多个句子的情况。覆盖率指的是该编码下所有句子占总文本面积的比例。
考虑到同一参考点下可能有多个句子,因此参考点个数并没有太大的参考价值。同时,考虑到在不同编码下每个句子对应句长不同,因此统计每个编码下的句子数也没有实际意义。鉴于以上原因,在编码过程中,使用覆盖率来衡量三极情感与8类情绪词出现的比例与频率较为适合。
质性分析结果显示,一级编码中,积极情感(positive)占比最高,达到63.88%,中立情感(neutral)与消极情感(negative)占比大致相同,分别为17.67%与17.4%,积极情感(positive)与消极情感(negative)相比,呈现绝对性优势。这一点与量化研究结果一致,佐证了4份演讲稿积极情感的主导地位。
二级编码中,属于一级编码“positive”的4类情绪词中,“anticipation”占比最高,达到22.63%,其次是“joy”和“trust”,“surprise”占比最低,仅为0.41%。属于一级编码“negative”的5类情绪词中,“disgust”占比最高,达到6.20%,其次依次是“sadness”、“anger”、“surprise”,“fear”占比最低,仅为1.24%。从二级编码来看,每项积极情感词所占比例也是整体高于消极情感词的,量化分析结果再次得到佐证。
将R软件中情感词库“nrc”的量化分析结果与Nvivo软件质性分析结果进行对比,得到表4。
Table 4. Comparison of the distribution of 8 kinds of sentiment words between the results of quantitative and qualitative studies
表4. 8类情绪词分布的量化与质性研究对比
在此特别说明,在质性研究中,因为“surprise”(惊讶)作为二级编码出现了两次,所以“surprise”(惊讶)情感所占比例为两个二级编码覆盖率的总和。
上表显示,若以多级情感为比较尺度,由于量化分析与质性分析关于多级情感的分类标准不同,因此不同多级情感出现的比例数值本身不具备可比性。但关注量化分析结果本身和质性分析结果本身可以发现,量化分析中积极情感(positive)占比33%,消极情感(negative)占比8%,质性分析中积极情感(positive)占比63.88%,消极情感(negative)占比17.4%,积极情感(positive)和消极情感(negative)比值近似,两种结果都显示,积极情感(positive)明显多于消极情感(negative),再次佐证了演讲传播正能量的重要性与必要性。
若以8类情绪词为比较尺度,可以发现就数值本身而言,量化与质性分析结果存在较大差异。8类情绪词中,仅有“anger”一词两类研究结果是相类似的。关注量化分析结果本身和质性分析结果本身可以发现,两种研究方法下各类情绪词占比从高到低依次是:“joy”、“trust”、“anticipation”、“sadness”、“surprise”、“fear”、“anger”、“disgust”;“anticipation”、“joy”、“trust”、“disgust”、“sadness”、“anger”、“surprise”、“fear”。可见两种研究方法下各类情绪词占比高低排序也存在较大差异。关于以上两方面差异,究其原因,可能是因为质性研究受到较强主观性影响,在本研究中,即使编码通过多次讨论与校对,也依然无法完全规避这一问题。
5.3. 研究问题三:演讲情感运用策略启示
研究者分别利用R软件和Nvivo软件对该选手四赛段演讲稿展开量化与质性分析基于以上量化与质性分析结果,研究者总结出了一些有关演讲情感策略与启示,可供广大演讲爱好者与有志于参加该演讲大赛的学生备赛参考:
1) 使用尽可能多的正向情感词汇,传递正能量。
量化与质性研究结果都显示,正向情感与负向情感相比,呈现绝对性优势,但总体呈上升趋势。这也说明正向情感具有较强的感染力与影响力,能够为广大听众接受并欣赏。
2) 增大演讲情感的起伏层次,把握总体情感值向上趋势。
量化研究结果显示,S4 (夺冠之作,主题:Benevolence)情感波动最大,情感值最为离散,也最为牵动人心,一举奠定了该选手的冠军地位。其他三份演讲稿情感值波动程度各异,但都呈现分段情感值波动较大的特征,但总体呈上升趋势。说明演讲情感起伏层次较大的演讲更符合广大听众的心理需求,启示广大演讲爱好者在把握演讲情感时增大演讲情感的起伏层次,把握总体情感值向上趋势。
先抑后扬策略:将情感爆发点集中在中后半段。
量化研究结果显示,四赛段演讲稿情感值的至高点大都出现在演讲的中后段,演讲结束时的情感值明显高于开头情感值,启示广大演讲爱好者与备赛学生在演讲开头适度压制自己的演讲情感,将演讲情感高潮留到演讲的中后段,这种策略更能为广大听众接受,也可以对广大听众留下更为深刻的印象,从而增强演讲的感染力与影响力。
6. 结语
本研究采用混合研究方法,分别使用R软件和Nvivo软件,对2021年外研社·国才杯全国大学生英语演讲大赛冠军决赛过程中的四篇演讲稿展开量化与质性研究。研究结果显示,在四篇演讲稿中,正向情绪词明显多于负向情绪词;情感值的至高点出现在演讲的中后段;演讲结束时,情感值明显高于开头情感值。分段情感值波动较大,但总体呈上升趋势。量化与质性分析结果显示,8类情绪词各自占比与占比高低排序存在较大差异。
综合以上研究结果,研究者可以得出如下启示,供广大演讲爱好者与备赛学生参考:
1) 使用尽可能多的正向情感词汇,传递正能量。
2) 增大演讲情感的起伏层次,把握总体情感值向上趋势。
3) 先抑后扬策略:将情感爆发点集中在中后半段。
当然,本研究也有明显的局限性。演讲情感受到多个因素影响,包括既定演讲主题、选手演讲当天的心理状态等。鉴于诸多干扰变量的存在,提出一种可供参考的共性演讲范式会相对困难。未来研究可以下意识采取一些措施来规避或减少这些干扰变量的影响。
文章引用
汤慧桃. 混合研究视角下的演讲稿情感分析——以外研社?国才杯全国英语演讲大赛冠军为例
Sentiment Analysis of Speech Drafts from the Perspective of a Mixed Method —A Case Study of the Champion of “FLTRP Cup” English Public Speaking Contest[J]. 现代语言学, 2023, 11(05): 2121-2133. https://doi.org/10.12677/ML.2023.115288
参考文献
- 1. Yang, L.Y., et al. (2021) Exploring the Efficacy of Automatically Generated Counterfactuals for Sentiment Analysis. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Vol. 1, 1-6 August 2021, 306-316. https://doi.org/10.18653/v1/2021.acl-long.26
- 2. 张博, 董瑞海. 自然语言处理技术赋能教育智能发展——人工智能科学家的视角[J]. 华东师范大学学报(教育科学版), 2022, 40(9): 19-31.
- 3. 人工智能发展报告(2011-2020) [R]. 清华大学人工智能研究院, 2020.
- 4. Zheng, Y.W., Zhang, R.C., Mensah, S. and Mao, Y.Y. (2020) Replicate, Walk, and Stop on Syntax: An Effective Neural Network Model for Aspect-Level Sentiment Classification. Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, 34, 9685-9692. https://doi.org/10.1609/aaai.v34i05.6517
- 5. Newman, H. and Joyner, D. (2018) Sentiment Analysis of Student Evaluations of Teaching. International Conference on Artificial Intelligence in Education, Vol. 10948, Springer, Cham, 246-250. https://doi.org/10.1007/978-3-319-93846-2_45
- 6. Rajput, Q., et al. (2016) Lexicon-Based Sentiment Analysis of Teachers’ Evaluation. Applied Computational Intelligence and Soft Computing, 2016, Article ID: 2385429. https://doi.org/10.1155/2016/2385429
- 7. Mohammad, S. and Turney, P. (2010) Emotions Evoked by Common Words and Phrases: Using Mechanical Turk to Create an Emotion Lexicon. CAAGET’10: Proceedings of the NAACL HLT 2010 Workshop on Computational Approaches to Analysis and Generation of Emotion in Text, Los Angeles, CA, June 2010, 26-34.