Operations Research and Fuzziology
Vol.
13
No.
05
(
2023
), Article ID:
73382
,
14
pages
10.12677/ORF.2023.135458
含模糊数的政产学研创新联盟 博弈研究
杨梅*,李卓君,程贞敏#
贵州大学数学与统计学院,贵州 贵阳
收稿日期:2023年8月1日;录用日期:2023年9月29日;发布日期:2023年10月8日

摘要
为打破单一的绿色技术创新研究,多方参与下的绿色技术创新联盟已经成为我国实现绿色经济战略目标的一种新趋势。基于此,借助模糊理论和博弈论理论,本文构建了政府引导,企业、高校和科研院所共同推进下的绿色技术创新多方模糊博弈模型,给出了三角模糊博弈问题均衡解的判定定理,探讨了模糊环境下考虑声誉收益的各博弈主体的行为决策策略和维护联盟稳定性的主要因素,并利用数值模拟仿真,分析论证了模型的有效性。研究结果表明:声誉收益与联盟稳定性呈正相关;合理的政府激励策略较利于各方联盟的稳定性;而声誉收益和产品绿色度的提高在一定程度上能够促使博弈主体朝着最优策略的方向演进。
关键词
模糊理论,博弈论,绿色技术创新,声誉收益,最优策略

Research on the Game of Government-Industry-University & Research Innovation Alliance with Fuzzy Numbers
Mei Yang*, Zhuojun Li, Zhenmin Cheng#
School of Mathematics and Statistics, Guizhou University, Guiyang Guizhou
Received: Aug. 1st, 2023; accepted: Sep. 29th, 2023; published: Oct. 8th, 2023

ABSTRACT
To break the single research of green technology innovation, the green technology innovation alliance with multi-participation has become a new trend to realize the strategic goal of green economy in China. Based on this, with the help of fuzzy theory and game theory, this paper constructs a multi-party fuzzy game model of green technology innovation under the guidance of the government and the joint promotion of enterprises, universities and scientific research institutes, gives the judgment theorem of the equilibrium solution of triangular fuzzy game problem, discusses the behavior decision-making strategies of each game subject considering reputation benefits and the main factors to maintain the stability of the alliance under fuzzy environment, and analyzes and demonstrates the effectiveness of the model by numerical simulation. The results show that: reputation gains are positively correlated with alliance stability; Reasonable government incentive strategy is conducive to the stability of all parties’ alliances; The improvement of reputation income and product greenness can promote the game players to the optimal strategy to some extent.
Keywords:Fuzzy Theory, Game Theory, Green Technology Innovation, Reputation Income, Optimal Strategy

Copyright © 2023 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
绿色技术创新是引领绿色发展的第一动力,是推进生态文明建设的重要着力点。党的十九大报告前瞻性地提出,“构建市场导向的绿色技术创新体系”。为此,政府部门印发了有关指导意见文件,明确指出了政府应该整合多方资源,发挥各方的异质性功能,构建以政府为引导,企业、高校和科研院所(以下简称“学研方”)为主体共同推进的绿色技术创新联盟 [1] 。然而,我国企业与学研方的产学研合作多年来一直呈现发展缓慢的状态,这严重阻碍了我国科技创新能力的发展水平与提升速度。如何结合实际利用现代科技去分析和解决现阶段产学研事业发展难的问题显得至关重要。所以,运用绿色创新技术,结合新媒体去提高各方合作意愿无疑为新型产学研的发展开辟了一条新路径。
博弈论作为近年来研究模型问题的主要方法之一,越来越受到国内外学者的广泛应用与延伸研究重视。而政府作为重要博弈方之一,也逐渐被专家们加入到了博弈模型中。二十世纪末,外国学者Henry Etzkowitz和Loet Leydesdorff将政府作为一方博弈主体引入到演化博弈模型中,提出了政府、企业、高校之间的互动关系理论 [2] ,由此解释了博弈三方在经济联盟演化进程中的一种新型关系——“三重螺旋” [3] 。Fan等人观察到了政府的减税补贴政策对企业绿色生产模式的正向作用,证实了政府的支持有效促进了国家绿色生产监管政策的实施 [4] [5] [6] 。随后,国内学者柳键等人在绿色供应链的博弈中验证了政府补贴政策有利于企业的发展 [7] [8] 。张根明和张曼宁基于演化博弈模型分析,发现了产学研创新联盟稳定性与企业学习能力高低、声誉损失、惩罚金额等因素密切相关 [9] 。进一步地,陈恒等人 [10] 将政府作为博弈主体加入到绿色技术创新联盟研究中,并纳入绿色度变量假设,填补了既有文献对政府参与主体作用和绿色技术创新在政产学研研究缺乏关注的空缺。但不足的是,其尚未考虑异质性社会中声誉收益对绿色技术创新政产学研联盟中博弈主体策略选择的影响。徐岩和贺一堂等人通过利用随机微分方程理论构建了战略联盟随机演化博弈模型,结合数值仿真,分析了随机环境下各博弈主体在演化过程中成员行为稳定性的问题 [11] [12] 。
上述研究大部分是基于博弈论的方法讨论政府、企业和学研方联盟过程中影响联盟稳定性的一些关键性因素,如,政府激励措施、成本支出、产品绿色度等,以及分析不同情景下各方博弈主体的策略选择问题。而这些问题基本上都是采用定性的方法,其博弈模型是在期望收益为精确数的基础上讨论的。在经典博弈理论中,博弈方通过分析在采取不同策略时的收益,得到其最优策略。然而,由于人的认知水平的限制、信息的不完全性、系统的结构性和随机性波动等因素的影响 [13] ,使得人们事先无法对其作出准确的判断。因此,越来越多的学者开始专注于不确定情况下的博弈研究,也取得了一些成果。有部分文献通过结合博弈论和模糊理论,推广并简化了模糊数理论和博弈模型,并给出其均衡解 [14] [15] [16] 。郭嗣琮 [17] 和岳立柱等人 [18] 利用结构元理论对模糊矩阵博弈问题进行了细致地研究,给出了其存在均衡解的相关定理,简化了模糊博弈矩阵的求解。杨德艳等人通过结合三角模糊数与博弈理论建立了多目标模糊博弈模型,分析讨论了不同情形下各博弈方的决策策略 [19] [20] [21] 。随后,曲国华等人结合三角模糊理论和博弈论,分别构建了政府和公众参与下企业加入第三方国际环境审计的博弈模型,并分析了两类博弈策略选择的主要影响因素 [22] [23] 。
基于此,本文利用模糊博弈的方法,给出三方模糊收益矩阵,建立政企学研联盟的模糊博弈模型,通过对博弈均衡的分析和数值模拟的结果,讨论不同声誉收益对政企学研创新联盟的影响,以及不同情景下政府、企业、学研方的策略选择,最后给出相应的结果和针对性的优化建议。在极具高度不确定性的现实背景下,深度研究绿色技术创新联盟演化进程中声誉收益对各博弈方决策的影响以及破坏联盟稳态的主要因素,这对我国实现“双碳目标”,提高绿色技术创新,促进绿色经济发展有着不可言喻的意义,同时,也为后续的多方绿色技术创新联盟稳定研究奠定了坚实的理论基础,为各方博弈主体提供更为可靠的决策参考价值。
2. 三角模糊数的相关知识
定义1 模糊集是具有模糊概念所描述的属性的对象的集合。设A为模糊集,
, 是元素x到模糊集A的隶属度,其将x中的每一个元素x映射到一个区间 内的实数。
定义2 对于一个模糊变量 ,如果它的隶属函数为 ,即
(1)
其中, ,l和r分别为下界和上界;当 时, 。特别地,当 时,p退化为实数m,令 。则称 为三角模糊数。三角模糊数对应的隶属度函数如图1所示(见图1)。
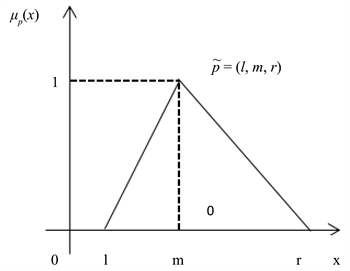
Figure 1. Triangular fuzzy numbers and their corresponding membership functions
图1. 三角模糊数及其对应的隶属度函数
定义3 任意两个三角模糊数 和 ,其三角模糊数运算规则如下 [24] :
加法:
减法:
乘法:
数乘:
除法:
其中, 分别表示模糊数的加法、减法和乘法运算。
定义4 任意两个三角模糊数 和 ,根据三角模糊数的比较规则 [25] ,则 的可能度为:
(2)
定义5 设任意k个三角模糊数 ,根据三角模糊数的比较规则 [25] ,则 的可能度为。
(3)
定义 6 基于可能度的最优纯策略解 [23] 。 为三角模糊矩阵,其中N是各博弈主体集合, 是博弈方i的策略集合, 是博弈方i采取策略j的得益函数。局势 为基于可能度 的最优纯策略解,满足充分必要条件 ,且需满足 。
定义7 单调矩阵 ,若 , 。则称 为 的投影矩阵 [18] 。
3. 考虑声誉收益的政产学研联盟模糊博弈模型
目前,既有的产学研绿色技术创新联盟已经不足以适应强干扰、高度不确定性的市场环境。有文献表明,政府干预可以弥补市场失灵,其可以通过法律、政策和其他手段改善由技术复杂性或者公众舆论等诱发的复杂多变的内外部环境 [6] ,进一步提高博弈方的合作意愿,维护联盟长久稳定,激发市场活跃度。根据利益相关者理论 [26] ,本文联盟的利益参与者为:政府、企业、学研方。因此,模型基本假设如下:
假设1 博弈的参与者政府、企业和学研方三方都是有限理性。
假设2 企业的策略为(合作,中途背叛)。企业选择合作的总成本和收益分别为 和 ,选择中途背叛的总成本为 和 ,其中, 。
假设3 学研方的策略为(积极研发,中途背叛)。学研方选择积极研发的总成本和收益分别为 和 ,选择中途背叛的总成本为 和 ,其中, 。
假设4 政府的策略为(监管,不监管)。政府选择监管的总成本和收益分别是 和 ,选择不监管的总成本和获得的收益分别为 和 ,其中, , 。
假设5 在政府的监督下,选择中途背叛的一方应赔偿 给被背叛的一方。例如,K表明学研方选择中途背叛,企业从一开始到学研方中途背叛期间所学到的知识、技术和思想等等价价值;也表明企业选择中途背叛,学研方从一开始到企业中途背叛期间获得的产品的半成品或灵感等等价价值。
假设6 企业与学研方选择继续合作带来的总绿色创新增值为 。假设企业在联盟过程的投入占比为 ,则学研方占比为 , ;企业占绿色创新增值的比例是 ,则学研方占比为 , ; 为合作生产的产品绿色度。
假设7 为推进国民经济发展,政府将对企业和高校采取一定的激励措施。政府对企业的激励为 ,对学研方的激励为 。
假设8 为了降低政府监管成本,增加各方博弈的总体收益,加入了媒体监管。关于各个博弈主体所获得的声誉收益,如下,当企业选择合作或中途背叛时,获得的声誉收益分别为 或 ;当学研方选择积极研发或中途背叛时,获得的声誉收益分别为 或 ;当政府选择监管或不监管时,其获得的声誉收益为 或 ,其中, 。
假设9 企业选择合作的概率为 ,选择中途背叛的概率为 ;学研方选择积极研发的概率为 ,选择中途背叛的概率为 ;政府选择监督的概率为 ,选择不监督的概率为 。
根据上述参数假设,构建了政产学研演化博弈的支付矩阵(见表1)。
4. 含三角模糊数的政产学研联盟博弈最优策略解分析
4.1. 含三角模糊数的政产学研联盟博弈的纯策略纳什均衡解分析
由表1 (见表1)的收益矩阵,可利用以下方法求解该问题的纯策略:
1) 根据三角模糊结构元方法,此三角模糊双矩阵博弈的求解步骤如下:
步骤1 模糊矩阵中的元素由三角结构元线性生成,由表1 (见表1)得出企业、学研方和政府的三角模糊矩阵 、 、 。
设E为三角结构元,即:
(4)
则模糊矩阵中的元素可以由上述三角结构元线性生成,即可表示为 。
步骤2 根据定义7,生成各自的投影矩阵 、 、 。
步骤3 根据经典双矩阵博弈的定义,将上述模糊矩阵博弈转化为经典矩阵博弈 进行求解。求得该问题的纯策略纳什均衡解。
步骤4 根据步骤3的纯策略纳什均衡解求得企业、学研方和政府的模糊收益。

Table 1. Payment matrix for each party
表1. 各方的支付矩阵
(注:以上参数均大于等于0,且均为三角模糊数。)
2) 基于可能度的纯策略纳什均衡解:
根据定义可计算出:
, (5)
, (6)
, (7)
, (8)
, (9)
, (10)
同理可得:
, , ,
, , ;
, , ,
, , ;
, , ,
, , ;
根据上述定义可得:
, (11)
, (12)
同理可得: , , , , , 。
根据定义5,当 时,可得出该博弈的最优纯策略。
4.2. 含三角模糊数的政产学研联盟博弈的混合策略纳什均衡解分析
根据表1 (见表1)中的收益矩阵,若当企业和学研方均选择背叛策略且政府选择监管时从政府获得的信息收益 ,即此时企业收益为: ,学研方收益为: ,联盟中不存在最优纯策略解。根据纳什均衡的存在性定理I [27] ,对于任意有限博弈至少存在一个纳什均衡,则该系统至少存在一个混合策略均衡解。
则企业平均期望收益为:
(13)
对上述效用函数求微分,得到企业策略最优化的一阶条件:
(14)
则有:
(15)
就是说,在混合最优策略下,局中人2以 的概率选择合作策略,以 的概率选择不合作策略。
则学研方平均期望收益为:
(16)
对上述效用函数求微分,得到学研方策略最优化的一阶条件:
(17)
则有:
(18)
则政府平均期望收益为:
(19)
对上述效用函数求微分,得到政府策略最优化的一阶条件:
(20)
则有:
(21)
则即有混合策略 。
现实世界是一个动态多变的有机体,其高度不确定性会在一定程度上影响联盟成员的策略选择。在此,借助三角模糊数理论,建立相对应的博弈模型,进而分析不确定环境下声誉收益对政产学研的实质性影响。因此,得出政府、企业和学研方合作的最优策略。
5. 数值模拟仿真
为了分析产品绿色度、声誉收益和政府激励等因素对政产学研联盟系统稳定的影响,本部分结合三角模糊数,分析论证相关参数对博弈主体策略选择的影响,以及讨论声誉收益与产品绿色度和政府激励之间的关系。相关变量取值如下(单位为百万元): , , , , , , , , , , , , , , , , , , ,按实际情况,政府比较注重声誉收益,学研方次之,企业较为看重经济收益,即 , , , , , 。基于上述假设和定义,根据三角模糊数的运算法则,可以计算出企业、学研方和政府博弈的收益值,如表2所示(见表2)。
Table 2. Income matrix of all parties
表2. 各方的收益矩阵
5.1. 纯策略的纳什均衡解分析
1) 根据三角模糊结构元方法,此三角模糊双矩阵博弈的求解步骤如下:
步骤1 模糊矩阵中的元素由三角结构元线性生成,由表2 (见表2)得出企业、学研方和政府的三角模糊矩阵 、 、 ,记
,
, .
设E为三角结构元,即:
则模糊矩阵中的元素可以由上述三角结构元线性生成,即可表示为 。 、 、 ,且 、 与 同序单调递增,从而可计算出 、 与 。
, , , , , , , .
其中, ,
同理可得 与 。
步骤2 生成各自的投影矩阵 、 、 为
, , .
步骤3 根据经典双矩阵博弈的定义,将上述模糊矩阵博弈转化为经典矩阵博弈
进行求解。纯策略纳什均衡解为(中途背叛,中途背叛,监管)。
步骤4 根据步骤3的解求得企业、学研方和政府的模糊收益分别为(10,12,13)、(14,15,17)、(20,25,32)。
2) 政企学研的三角模糊矩阵博弈基于可能度的求解过程:该三角模糊矩阵博弈满足纯策略纳什均衡
点存在的充分必要条件 。
参照基于可能度的纯策略最优解判定可得:
, , ,
, , ;
, , ,
, , ;
,
,
, , ,
, , ;
根据上式得:
同理可得:
, , , , , .
根据定义5,当 时,可得出该博弈的最优纯策略为(合作,积极研发,监管)和(中途背叛,中途背叛,监管)。
3) 两种方法中纯策略的纳什均衡最优解均有(中途背叛,中途背叛,监管),即这一均衡结果是最理想的。但是基于可能度的方法显示,(合作,积极研发,监管)也是该系统的纯策略纳什均衡最优解。形成这一结果的主要原因是政府获得的声誉收益无法补充政府给予其他博弈方的支持成本,但是由于政府比较在意声誉收益,这迫使其仍选择监管的策略。对于企业和学研方而言,他们选择中途背叛的最终收益可能在一定程度上可以弥补该策略带来的声誉损失,但凡声誉损失过大,他们将选择合作策略。但是当企业和学研方都选择合作的策略时,政府同时也会选择监管策略,因为此时政府获得的声誉收益是其所需要的,该部分收益也会减少政府的监督成本,会形成一个更好的社会效益。
5.2. 混合策略的纳什均衡解分析
根据上述的研究,若当企业和学研方均选择背叛策略且政府选择监管时从政府获得的信息收益 ,并且变更表2 (见表2)中的相关数据: , , , , , , , , , , , , ,其收益矩阵为如下(见表3):
Table 3. Benefit matrix for each gaming party
表3. 各博弈方的收益矩阵
此时无纯纳什均衡策略解。
由此,可以算出该问题的混合策略最优解为:
(22)
(23)
(24)
联立三式求解得: 。
则求得该问题的最优策略为: , , 。混合最优策略为: 。即企业以模糊概率 选择合作策略,以模糊概率 选择中途背叛策略;学研方以模糊概率 选择积极研发策略,以模糊概率 选择中途背叛策略;政府以模糊概率 选择监管策略,以模糊概率 选择不监管策略。
此时三方的模糊收益分别为:企业的收益为 ;学研方的收益为 ;政府的收益为 。
从上述均衡解和收益来看,此时企业选择合作的意愿较大,而学研方选择中途背叛策略的可能性更大,政府选择不监管的可能性也越大。因为此时企业选择合作带来的包括声誉收益在内的总收益要大于其选择中途背叛损失的包括声誉收益之内的总收益。此时若选择中途背叛,其声誉收益损失较大,且总收益较少,不值得。对于学研方而言,即使前期合作成本增加,选择积极研发的策略获得的声誉收益也增加,但是其选择中途背叛的总收益增加和损失的声誉收益减少,故其最终还是会偏向于选择中途背叛。对于政府而言,若减少政府参与联盟带来的声誉收益,增加其选择监管策略所获得的总收益,并且减少其选择不监管策略的总收益,其还是会偏向于选择不监管策略。因为此时若其选择监管策略,其将支付参与选择合作的博弈双方相应的激励成本,这将大大提高政府参与合作所需支付的总成本,从而会减少其参与联盟的总收益,故其更偏向于选择不监管策略。
5.3. 两种策略下的均衡解分析
在上述两种情况下,该问题的博弈均衡解分别为纯策略(中途背叛,中途背叛,监管),(合作,积极
研发,监管),和混合策略 , , 。影响系统均衡解稳定的主要原因如下:1) 声誉收益是否可以减少政府的
成本投入;2) 声誉收益是否会大程度上影响各方的最终受益。对于企业和学研方而言,选择(合作,积极研发)策略的收益会更高,但是此时由于政府需要给予企业和学研方高额的支持资金,这些成本在一定程度上消耗了政府选择监管带来的声誉收益,以至于政府最终获得的总收益较低,此时政府较偏向于选择不监管策略。对于企业、学研方和政府而言,总体的最优策略为(中途背叛,中途背叛,监管)。因为此时企业和学研方选择(中途背叛,中途背叛)策略所获得的收益可以填补选择中途背叛策略带来的其收益损失;政府出于声誉收益选择监管策略,这时政府既不需要给予企业和学研方相应的支持资金,又获得一些声誉收益,大大减少了其监管成本,从而增加其总收益。
6. 结论与讨论
为了克服现实环境中的不确定性,本文从模糊数学的角度出发,将三角模糊数与博弈论相结合,通过分析三方模糊收益矩阵,建立政产学研绿色创新联盟模糊博弈模型,提出了三角模糊矩阵博弈问题的基于三角结构元和可能度的纯策略纳什均衡解的判定定理,以及混合最优策略的求解方法,讨论了企业、学研发和政府在考虑声誉收益的联盟过程中的不同策略选择,推广了政产学研问题的应用。通过综合考虑政府的激励成本,产品绿色度,各方的声誉收益、总收益以及总成本等关键变量,将博弈结果分为纯策略纳什均衡和混合策略纳什均衡两类,并分析纯策略下的最佳均衡(中途背叛,中途背叛,监管)和(合作,积极研发,监管),讨论混合策略下的均衡结果和影响因素。在混合策略的最优均衡解的求解过程中,我们通过对比发现,声誉收益会在一定程度上降低政府的成本支出,平衡政府选择监管所支付的激励成本。同时,在降低各博弈方参与合作的成本和增加其中途背叛的获得的资金收益时,声誉收益和合作产生的绿色产品合作收益也在一定程度上影响各方策略的选择。利用三角模糊数代替确定数,该方法克服了传统博弈模糊型信息不完全及专家经验判断的模糊性问题,有效避免了信息的丢失,确保分析结果的准确性和客观性,更加合理地分析政产学研绿色创新联盟演化进程中的策略选择问题,使模型更加切合实际。
基于以上分析,为更好维持以政府为引导,企业和学研方共同推进的绿色技术创新联盟的稳定性,推动社会高质量发展,本研究结合数值仿真结果,提出如下建议。
第一,强化媒体作用,适度提高声誉收益。由于企业注重自身的经济利益,而政府和学研方注重社会利益,所以,政府应当适度利用新媒体流量功能减少政府严格监管的成本,为博弈三方博取更多的声誉收益,为绿色技术创新政产学研联盟的高质量发展搭建较为理想的合作平台,营造更为良好的市场环境。另外,政府部门应当在网络媒体畅通的信息渠道的帮助下,多方位宣传绿色技术创新联盟合作研发的技术产品,提高公众对绿色技术和产品的认知度,调动多方成员参与联盟的积极性。
第二,政府激励力度合理化。结合国情,政府制定与市场相适应的奖惩机制,以及较为合理的激励措施和力度,以此鼓励更多的企业和学研方参与联盟。适当加大控制各方参与联盟的成本和合作后选择中途背叛所需付出的损失,鼓励各方参与者提高其产品绿色度,发展绿色技术创新的新型社会,加快我国绿色技术创新发展,高质量发展国家绿色经济。
虽然本文在前人的基础上克服了收益模糊性带来的不确定性问题,但是,在三角模糊博弈问题的分析中,我们没有考虑不同风险偏好的决策者对于同一博弈问题的决策也许是不同的这一因素。同时,影响政企学研创新技术联盟稳定的因素还有很多,本文也没有全部考虑进去。而这些也是我们下一步需要继续探索和研究的问题。
基金项目
贵州省哲学社会科学基金资助项目(21GZYB11);贵州大学文科研究基金资助项目(GDYB2021024)。
文章引用
杨 梅,李卓君,程贞敏. 含模糊数的政产学研创新联盟博弈研究
Research on the Game of Government-Industry-University & Research Innovation Alliance with Fuzzy Numbers[J]. 运筹与模糊学, 2023, 13(05): 4561-4574. https://doi.org/10.12677/ORF.2023.135458
参考文献
- 1. 郭滕达, 魏世杰, 李希义. 构建市场导向的绿色技术创新体系: 问题与建议[J]. 自然辩证法研究, 2019, 35(7): 46-50.
- 2. Etzkowitz, H. and Leydesdorff, L. (1995) The Triple Helix—University-Industry-Government Rela-tions: A Laboratory for Knowledge Based Economic Development. EASSTR Eview, 14, 14-19.
- 3. Etzkowitz, H. and Leydesdorff, L. (2000) The Dynamics of Innovation: From National Systems and “Mode 2” to a Triple Helix of University-Industry-Government Relations. Research Policy, 29, 109-123. https://doi.org/10.1016/S0048-7333(99)00055-4
- 4. Chen, W.T. and Hu, Z.H. (2018) Using Evolutionary Game Theory to Study Governments and Manufacturers’ Behavioral Strategies under Various Carbon Taxes and Subsidies. Journal of Cleaner Production, 201, 123-141. https://doi.org/10.1016/j.jclepro.2018.08.007
- 5. Fan, R.G., Dong, L.L., Yang, W.G. and Sun, J.Q. (2017) Study on the Optimal Supervision Strategy of Government Low-Carbon Subsidy and the Corresponding Efficiency and Stability in the Small-World Network Context. Journal of Cleaner Production, 168, 536-550. https://doi.org/10.1016/j.jclepro.2017.09.044
- 6. Ma, Y., Wan, Z. and Jin, C. (2021) Evolutionary Game Analysis of Green Production Supervision Considering Limited Resources of the Enterprise. Polish Journal of En-vironmental Studies, 30, 1715-1724. https://doi.org/10.15244/pjoes/127304
- 7. 柳键, 邱国斌. 政府补贴背景下制造商和零售商博弈研究[J]. 软科学, 2011, 25(9): 48-53.
- 8. 朱庆华, 窦一杰. 基于政府补贴分析的绿色供应链管理博弈模型[J]. 管理科学学报, 2011, 14(6): 86-95.
- 9. 张根明, 张曼宁. 基于演化博弈模型的产学研创新联盟稳定性分析[J]. 运筹与管理, 2020, 29(12): 67-73.
- 10. 陈恒, 杨志, 祁凯. 多方博弈情景下政产学研绿色技术创新联盟稳定性研究[J]. 运筹与管理, 2021, 30(12): 108-114.
- 11. 徐岩, 胡斌, 钱任. 基于随机演化博弈的战略联盟稳定性分析和仿真[J]. 系统工程理论与实践, 2011, 31(5): 920-926.
- 12. 贺一堂, 谢富纪. 产-学研协同创新的随机演化博弈分析[J]. 管理评论, 2020, 32(6): 150-162.
- 13. 米传民, 方志耕. 基于区间数大小不能直接判定的灰矩阵博弈的策略优超及其最优解研究[J]. 中国管理科学, 2005, 13(6): 81-85.
- 14. 闫怀志, 胡昌振, 谭惠民. 基于模糊矩阵博弈的网络安全威胁评估[J]. 计算机工程与应用, 2002, 38(13): 4-5, 10.
- 15. 黄龙生. 模糊信息静态伯特德双寡头博弈分析[J]. 中南民族大学学报(自然科学版), 2005, 24(1): 98-100.
- 16. 吴诗辉, 杨建军, 郭乃林. 三角模糊矩阵博弈的最优策略研究[J]. 系统工程与电子技术, 2009, 31(5): 1231-1234.
- 17. 郭嗣琮. 基于模糊结构元理论的模糊分析数学原理[M]. 沈阳: 东北大学出版社, 2004: 65-66, 81-82.
- 18. 岳立柱, 闫艳, 仲维清. 基于结构元方法的模糊矩阵博弈求解[J]. 系统工程理论与实践, 2010, 30(2): 272-276.
- 19. 杨德艳, 柳键. 基于模糊数的政府与绿色制造商博弈分析[J]. 运筹与管理, 2016, 25(1): 85-92.
- 20. 黄晓玲, 洪梅香. 零售商主导的模糊供应链博弈——考虑销售努力的情形[J]. 运筹与管理, 2020, 29(1): 57-68.
- 21. 南江霞, 魏骊晓, 李登峰, 等. 具有联盟优先关系的模糊合作博弈的目标规划求解模型[J]. 中国管理科学, 2022, 30(7): 231-240.
- 22. 曲国华, 刘雪, 李月娇, 等. 政府监管与企业加入第三方国际环境审计的模糊博弈分析[J]. 中国管理科学, 2020, 28(1): 113-121.
- 23. 曲国华, 张志婕, 李春华, 等. 考虑公众参与第三方国际环境审计的三角模糊博弈分析[J]. 运筹与管理, 2023, 32(5): 145-152.
- 24. 姜艳萍, 樊治平. 三角模糊数互补判断矩阵排序的一种实用方法[J]. 系统工程, 2002, 20(2): 89-92.
- 25. Chang, D.Y. (1996) Applications of the Extent Analysis Method on Fuzzy AHP. European Journal of Operational Research, 95, 649-655. https://doi.org/10.1016/0377-2217(95)00300-2
- 26. Ma, Y., Wan, Z. and Jin, C. (2021) Evolutionary Game Analysis of Green Production Supervision Considering Limited Resources of the Enterprise. Polish Journal of Environmental Studies, 30, 1715-1724. https://doi.org/10.15244/pjoes/127304
- 27. 张维迎. 博弈论与信息经济学[M]. 上海: 上海人民出版社, 1996: 68-70.
NOTES
*第一作者。
#通讯作者。