Software Engineering and Applications
Vol.07 No.01(2018), Article ID:23898,7
pages
10.12677/SEA.2018.71005
Research on Meteorological Data Partitioning Strategy for Forest Fire Monitoring
Zhichang Wang
Institute of Satellite information Engineering, Beijing
Email: together0124@sina.com
Received: Feb. 9th, 2018; accepted: Feb. 21st, 2018; published: Feb. 28th, 2018

ABSTRACT
With the improvement of every kind of remote sensing instrument spatial resolution and spectral resolution, amount of the remote sensing image data for monitoring forest condition will accumulate with time and rapid growth. The traditional remote sensing image data storage systems generally use the SAN (storage area network) architecture. Faced with the increasingly extended remote sensing data amount, stored in SAN architecture has low storage efficiency, poor scalability, high expansion cost. To solve these problems, the best way is to transform the centralized management model of remote sensing image data into a distributed management model. On the basis of Hadoop platform, this paper studies the partitioning strategy of meteorological remote sensing data with the purpose of distributed computing of meteorological data. The experiment was carried out on the partitioning strategy of HDF data stored on HDFS by line segmentation. The result of the experiment is to get the conclusion that the storage efficiency is higher after the data partition.
Keywords:Hadoop, Storage Area Network, Partitioning Strategy
面向林火监测的气象数据分块策略研究
王志昌
北京卫星信息工程研究所,北京
Email: together0124@sina.com
收稿日期:2018年2月9日;录用日期:2018年2月21日;发布日期:2018年2月28日
摘 要
随着各式各样遥感仪器空间分辨率、光谱分辨率的不断提高,监测森林状况的遥感影像数据量会随着时间的积累而急剧増长。传统的遥感影像数据存储系统一般都采用SAN(存储区域网络)架构,面对当前日益増长的遥感影像数据,系统在存储方面存在存储效率较低,扩展性较差,扩展成本较高等问题。要解决这些问题,最好的方式就是将遥感影像数据的集中式管理模式转变为分布式管理模式。本文基于上述问题,以Hadoop平台为基础,以气象数据的分布式计算为目的,研究气象遥感数据的分块策略。实验采用对HDF数据按行分割的分块策略进行实验,并存储与HDFS之上,并通过实验结果得到数据分块后的存储效率更高的结论。
关键词 :Hadoop,存储区域网络,分块策略
Copyright © 2018 by author and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
由于我国卫星遥感技术日渐成熟,遥感影像数据已经广泛应用到生态、国防建设、社会服务等各行各业之中。我国各类遥感卫星的研制和发射已经进入了一个快速的发展期。据相关报道,我国卫星在轨运行总量超过了俄罗斯,在轨卫星总量跃居世界第二。为保护我国自然生态资源的可持续发展,我国将目前所研究的先进的卫星遥感技术,计算机技术应用于生态环境建设中。其中,林火监测是生态环境建设中非常重要的一部分。
目前大部分林火监测的数管平台中对于影像文件的管理方式是文件系统和数据库混合方式,影像文件存放在数据库外的文件系统中,数据库管理相应的元数据,同时记录影像的外部管理路径 [1] 。这种方式虽然保持了文件系统的读取效率,但也存在很多不足之处,不适宜进行分布式处理。同时,随着遥感技术的不断发展,气象卫星每天通过拍摄所产生的数据量越来越多,这些巨量的数据带来了存储、管理、处理与分析上的难题。如影像数据的存储速度受限,扩展成本高。具体如下:
1) 时效性问题:随着卫星的覆盖范围面越来越广,拍摄的精度越来越高,使得每天获得的遥感影像数据量非常庞大。传统的集中式管理方式对数据的存储和处理的时间大大增加。而在林火监测中,为了能更加快速处理即时发生的状况,对于数据处理的时效性要求越来越高,传统的遥感影像数据单机串行的处理方式已经达不到目前对于时效性的要求。我们需要找到一种并行的存储与处理方式,使得同样的遥感影像数据经过切分后存储在不同的存储节点上,并在相应节点上进行并行处理,从而缩短存储与处理数据的时间,满足当前林火监测对于时效性的要求。
2) 多源异构遥感数据管理问题:随着卫星应用范围越来越广,发射的卫星数量和种类不断增加,同时,卫星上载荷的种类也在不断增加,例如气象卫星(如风云三号卫星)的有效载荷包括可见光红外,微波湿度计,微波温度计,紫外臭氧垂直探测仪和中分辨率光谱成像仪等。这些载荷产生的数据的数据格式不同,元数据不同,处理方法也不同,这些不同加剧了气象遥感数据管理的复杂性。为了更好的对多源异构遥感影像数据进行统一的管理,需要研究较为通用的遥感影像存储组织方式,实现对多星多载荷遥感影像数据进行一体化管理。
3) 成本问题:随着遥感数据量的增加,数据存储所需要的存储设备的容量也需要扩大。传统的集中式管理模式采用盘阵进行存储,对数据的处理通过后台服务器完成。因为这些设备价格昂贵,扩容成本太高,所以需要找到更加廉价的方式来解决遥感影像数据量急剧增大导致的扩容问题。
本文以Hadoop的HDFS分布式文件系统作为气象数据的分布式存储平台,建立原型系统,研究分布式环境下气象遥感影像数据的划分及分块策略,并设计相应实验。
2. 基于Hadoop的气象遥感数据存储框架
2.1. Hadoop介绍
Hadoop是Apache Lucene创始人Dong Cutting所创建,Lucene是一个应用广泛的文本搜索系统库。Hadoop起源于开源的网络搜索引擎Apache Nutch,Nutch本身也是Lucene项目的一部分 [2] 。Hadoop主要包括Hadoop Common,Avro,Hbase,Chukwa,Hive,Pig,MapReduce,HDFS,ZooKeeper等组件。
2.2. 气象数据分布式存储平台框架
HDFS是Hadoop中提供高吞吐量的分布式文件系统,是GFS(谷歌文件系统)的开源实现,是分布式计算的底层。HDFS 具有高容错的特点,可以部署在相对便宜的硬件设施上,并且提供高吞吐量的数据读写。同时,HDFS通过增加数据节点来达到扩容和加快数据处理的目的。HDFS属于传统的层次文件组织结构,可以实现文件的删除、重命名、创建等操作。HDFS架构由一组特定的节点构建而成,其中包括NameNode、DataNode和Secendary NameNode节点。本文以HDFS为分布式存储平台,将气象数据存储于HDFS上,平台框架如图1所示。

Figure 1. HDFS storage structure
图1. HDFS存储架构图
其中,NameNode负责管理HDFS的空间名称和数据块映射信息,配置备份副本策略及响应客户端请求;DataNode主要存储实际的气象数据,并提交存储信息给NameNode节点;Secendary NameNode辅助NameNode并分担其工作量,在紧急情况下可辅助恢复NameNode,或者替代NameNode继续工作。
3. 气象数据分块研究
3.1. 气象数据分块策略研究
MapReduce是Google公司为解决大规模Web网页数据快速搜索而提出的一种分布式计算框架,Doug Cutting在这个基础上,使用Java语言实现MapReduce框架,并运行在由大量普通计算机组成的Hadoop集群中,能够对海量数据以高容错并且可靠的方式进行分布式计算。与传统分布式模型相比,开发人员只需熟悉MapReduce提供的分布执行接口,即使没有分布式开发经验也能够比较容易的编写计算程序。
MapReduce编程模型的核心是Map和Reduce函数,其运行思路为Map函数接受并处理来自HDFS或其他数据源的数据分片,并将处理之后的数据组织成中间键–值对格式。其中,键相同的键-值对将会被划分至同一个Reduce函数中进行处理。通过将Map和Reduce任务分发给各计算节点,从而实现大规模数据集的高并发处理。
遥感影像应用的基础是遥感影像存储与管理,在不同遥感影像应用中,遥感影像存储与管理方式具有较大的差异性,因此对当前遥感影像应用现状进行深入研究是很有必要的。将遥感影像数据按使用目的划分,可分为遥感影像数据共享服务、遥感影像地图服务及其他遥感影像应用(如森林灾害)。由于MapReduce (Hadoop分布式数据处理模型)移动计算的特点,并且MapReduce是一种应对数据密集型计算的编程模型,因此合理的划分数据和设计数据模型是提高MapReduce应用程序效率的最好方法,从而最大限度的提升整个分布式计算的效率 [3] [4] [5] 。
结合上述分析,我们首先以遥感影像地图服务为例,遥感影像通常采用分层分片的方式进行存储管理,瓦片大小决定HDFS中数据块的读取效率。如果对于遥感影像数据共享服务,主要只是为了提供数据查询和下载服务,并不会对存储的数据做修改,在这种情况下,则无需对原始数据做更多处理,只需要将数据采用默认的HDFS存储方式直接存储到HDFS中即可。对于需要通过MapReduce来提升计算效率的影像数据而言,需要通过不同的数据划分方式来提升系统的分布式计算性能。
3.2. 基于HDFS的气象数据分块算法
本文主要涉及的是气象数据,目的是为了对存储在HDFS上的气象数据进行分布式计算,提高处理速度。因为气象数据一般以HDF格式存储,故接下来研究HDF格式的遥感数据存储算法 [6] 。HDF的最新版本是HDF5,本文研究的气象数据都是HDF5格式,HDF5只有两种基本结构:组(group)和数据集(dataset),组包含0个或多个数据集。HDF5 的物理结构如图2所示。
对于气象数据,一般包括三个组:全局文件组,私有文件组和科学数据集。为了更好的对气象数据进行分布式计算,需要对HDFS默认的分块方式以及保存格式进行修改,使得分块后的文件是HDF格式存储的小文件,并且文件大小与HDFS设置的分块大小相等。因为MapReduce是以块进行处理的,所以将气象数据分成默认块大小可以提高计算效率。通过对全局文件组和私有文件组的部分属性修改,并对科学数据集采用按行分割的方式将HDF文件根据需要分成若干个HDF小文件,达到分块的目的。分块的算法可以通过HDFS提供的接口和HDF库接口实现。通过HDF库函数调取HDF文件中各个属性字段对应的数组,采用按行分割的方式对数组进行分块。利用HDFS的FSDataInputStream类获取分块后的文件,并通过write函数写入到HDFS之中。分块后文件按照HDFS默认的方式存储在各个DataNode节点上,文件信息保存于NameNode中。
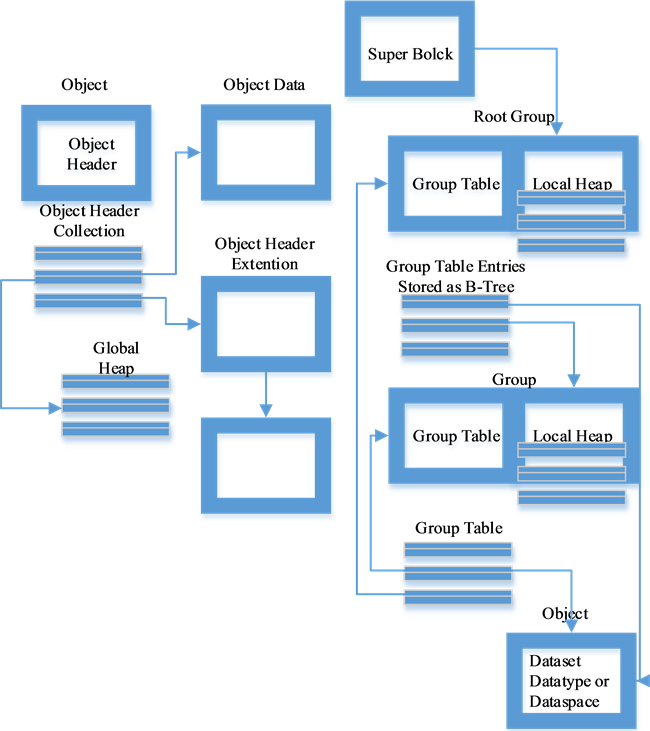
Figure 2. Structure of HDF5
图2. HDF5结构图
4. 实验测试与分析
4.1. 硬件环境
单机組采用的测试机是内存4GB,硬盘空间为500 g的硬件配置,在CentOS系统环境下运行,后台与服务器相连。并行组采用Hadoop集群方式,采用服务器虚拟机的方式,在虚拟机上设置7台同样配置的计算机节点,构建一个Hadoop集群的环境,分配其中两个节点分别作为主NameNode和备用NameNode,另外5个节点作为DataNode。
4.2. 软件环境
单机与服务器虚拟机上的操作系统均为CentOS-7-x86_64-DVD-1503-01,Eclipse版本为eclipse-jeemars-1-win32-x86_64,JDK为64位jdk-7u79-linux-x64.tar.gz。集群上Hadoop版本为2.7.3。
4.3. Hadoop集群环境搭建
1) 安装centOS7,使用的是CentOS-7-x86_64-DVD-1503-01.iso镜像,安装时选择工作站服务器模式,选择需要的软件包进行安装。
2) 安装java运行环境。首先是卸载系统自动安装的openJDK卸载OpenJDK:
3) 新建Hadoop账户用户和组均为Hadoop,密码为Hadoop,home目录为/Hadoop。
[root@dn3 ~]# useradd -d /home/Hadoop Hadoop
4) 设置ssh无密码登陆
5) 修改core-site.xml
6) 修改HDFS-site.xml
7) 修改mepred-site.xml
8) 安装zookeeper软件
9) 集群启动
启动zookeeper
[Hadoop@nn1 ~]$ /home/Hadoop/zookeeper/bin/zkServer.sh start
10) 启动所有Hadoop服务
[Hadoop@sbin]./start-all.sh
11) 启动名称节点
将nn1状态改为active
[Hadoop@nn1~]$ /home/Hadoop/Hadoop-2.7.3/sbin/Hadoop-daemon.sh
start zkfc
至此配置完成,在浏览器中打开172.16.3.111:5070,查看HDFS集群状况。
4.4. 实验结果
本文实验数据采用的是FY-3D红外高光谱大气探测仪L1数据和风云三号B星微波湿度计冰水厚度指数反演数据所构造的仿真数据,文件大小约900 M,约25 G。通过对上述数据进行单机文件存储以及集群文件存储的对比,并记录了相应的存储时间,如表1和表2所示(由于数据量比较大,故每一项只测试了三次,取平均值)。
4.5. 实验结果分析
可以看出,集群存储的速度总的来说是优于单机存储的(最少提速22.9%,最快可以提高123.2%)。因为多个节点可以同时进行存储。分块大小对存储速度影响不大,但是分块越大,磁盘寻址消耗时间越小(磁盘寻址消耗时间大约为10 ms)。随着节点增多,数据的存储速度加快,通过表格可以知道节点增多,存储速度的上升率在降低,最终会趋于交换机的最大速度(除去所以损耗和其他工作进程消耗后的速度)。

Table 1. Single machine storage speed
表1. 单机存储速度
Table 2. Cluster storage speed
表2. 集群存储速度
实际应用中,数据应该存在多个节点上,可以尽可能大的利用并行分布式所达到的效率,分块上来说应该具体根据所存文件大小而定,毕竟速率的影响不大,此时更要考虑网络稳定的问题。如果分块过大,在网络不稳定的情况下,更容易出现传输错误。
5. 结论
本文通过对Hadoop框架的学习,了解Hadoop的源码知识,利用实验室的服务器以及测试机完成Hadoop集群的搭建。同时,研究HDF气象数据的数据格式,并对数据进行分块,为后续分布式处理打下基础。最后,完成气象数据分块存储与单机存储的速度对比实验,并得到数据在分布式存储集群上存储效率更高的结论。
文章引用
王志昌. 面向林火监测的气象数据分块策略研究
Research on Meteorological Data Partitioning Strategy for Forest Fire Monitoring[J]. 软件工程与应用, 2018, 07(01): 46-52. http://dx.doi.org/10.12677/SEA.2018.71005
参考文献 (References)
- 1. 李洪双, 周政, 安鸿东. 浅析森林火灾的卫星化监测技术[J]. 黑龙江科技信息, 2010(7): 33.
- 2. 孟永伟, 黄建强, 曹腾飞, 等. Hadoop集群部署实验的设计与实现[J]. 实验技术与管理, 2015, 32(1): 145-149.
- 3. 谢毅. 海量遥感影像数据存储组织结构研究[D]: [硕士学位论文]. 开封: 河南大学, 2011.
- 4. 康俊锋. 云计算环境下高分辨率遥感影像存储与高效管理技术研究[D]: [博士学位论文]. 杭州: 浙江大学, 2011.
- 5. 赖积保, 罗晓丽, 余涛, 等. 一种支持云计算的遥感影像数据组织模型研究[J]. 计算机科学, 2013, 40(7): 80-83.
- 6. 王玲, 龚健雅. 基于HDF文件的组织方式与影像提取[J]. 测绘通报, 2003(4): 35-37.