Open Journal of Transportation Technologies
Vol.07 No.02(2018), Article ID:24116,12
pages
10.12677/OJTT.2018.72010
Research on High Speed Train Genealogical Data Warehouse System
Guangxin Wang1, Hao Gao2
1China Sifang Locomotive Co., Ltd., Qingdao Shandong
2State Key Laboratory of Traction Power, Southwest Jiaotong University, Chengdu Sichuan

Received: Mar. 1st, 2018; accepted: Mar. 15th, 2018; published: Mar. 22nd, 2018

ABSTRACT
A new generation of high-speed EMU pedigree development platform combines high-speed EMU pedigree theory to build an integrated platform for high-speed train design and manufacturing with eight sub-systems including the rapid design of high-speed train, virtual visualization, rapid process file generation and test verification. An important foundation for the eight sub-systems is the high-speed train pedigree data warehouse. In this paper, the research of high-speed EMU pedigree data warehouse technology was carried out; the framework of a pedigree data warehouse is established; the high-speed EMU pedigree data warehouse system is built, and an efficient data management platform is developed. It is an effective support for the smooth connection and efficient operation between subsystems of an integrated platform for high-speed EMU design and manufacture.
Keywords:High-Speed EMU, Pedigree, Data Warehouse, Data Management
高速列车谱系化数据仓库系统研究
王光新1,高浩2
1中车四方机车车辆股份有限公司,山东 青岛
2西南交通大学牵引动力国家重点实验室,四川 成都
收稿日期:2018年3月1日;录用日期:2018年3月15日;发布日期:2018年3月22日

摘 要
新一代的高速列车谱系化研制平台结合了高速动车组谱系化理论,构建了以高速列车快速设计、虚拟可视化、快速工艺文件生成及试验验证等八大子系统为核心的高速列车设计制造一体化平台。而八大子系统重要的基础支撑是高速列车谱系化数据仓库。本文对高速列车谱系化数据仓库技术开展研究,确定了谱系化数据仓库的框架,构建了高速列车谱系化数据仓库体系,开发了高效的数据管理平台。为高速列车设计制造一体化平台各子系统之间顺畅衔接和高效运转提供支撑。
关键词 :高速列车,谱系化,数据仓库,数据管理

Copyright © 2018 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 前言
我国高速铁路发展经过了技术引进、消化吸收和再创新的过程,已经形成了具有自主知识产权的中国标准动车组和初具规模的高速铁路路网。我国高速铁路还将继续快速发展,按照《铁路“十三五”发展规划》,到2020年,全国铁路营业里中高速铁路3万公里。高速铁路网覆盖80%以上的大城市,动车组列车承担旅客运量比重达到65%,在建成“四纵四横”主骨架的基础上,高速铁路服务范围进一步扩大,基本形成高速铁路网络 [1] 。
我国具有幅员辽阔,区域自然环境差异显著,地区人口密度差异大,铁路路网结构多样等特点。这对高速铁路的移动装备的研制提出更高的要求。同时我国提出的“一带一路”倡议和高铁走出去战略,使得高速列车研制平台的技术水平需要进一步提升。为此我国开展了高速动车组谱系化技术研究,在现有具有自主知识产权的高速动车组研制平台的基础上,构建能够实现需求多样化、设计制造一体化、技术体系可定制化、标准体系国际化的高速动车组设计制造一体化平台 [2] 。谱系化是现代化高速列车发展的趋势,列车的谱系化设计方法研究是谱系化高速列车的必然要求,也是高速列车设计领域的最前沿课题。
新一代的高速列车谱系化研制平台结合了高速动车组谱系化理论,构建了以高速列车快速设计、虚拟可视化、快速工艺文件生成及试验验证等八大子系统为核心的高速列车设计制造一体化平台。而八大子系统重要的基础支撑是高速列车谱系化数据仓库 [3] [4] 。高速列车设计制造一体化平台要实现高效运转,子系统之间顺畅衔接需要将所有数据、所有过程和整个流程进行数字化,并且拥有统一的数据仓库进行存储和管理。高速列车数据内容繁杂、涉及领域广泛、数据量庞大,目前仍是以分散、多源、异构、语义不一致等存在,没有达到为决策支持提供有效数据源的水平 [5] ,因此结合谱系化高速列车平台采用数据仓库技术、面向对象思想、空间数据库等关键技术将现有的多域高速列车数据有机地集成起来,并发挥其应有的共享作用 [6] ,进行相应的OLAP分析和数据挖掘等处理,最终以友好的界面显示给用户 [7] 。
2. 高速列车谱系化数据仓库框架
高速列车数据的具有繁杂性和多态性,包含多个领域和多个子系统,因此要求高速列车谱系化数据仓库是面向主题的、集成的、时变的、相对稳定的,并集合了高速列车空间数据和非空间数据,它可以将多个异种的、自治的、分布的信息源有机的组织起来,并提供对空间数据和非空间数据简便、有效的访问,为决策分析提供数据。
高速列车数据集成与应用框架从逻辑上可以划分为数据源层、数据导入层、数据仓库层、数据处理层和前端用户五层结构,其架构如图1所示。
2.1. 数据源层
数据源是整个高速列车数据仓库系统的数据源泉。这些数据均来自现有高速动车组研发平台、产品生产和使用阶段的测试数据、应用部门维护维修数据以及相关研究机构和学校研究成果报告等。由于高速列车系统的复杂性,数据的存储格式繁多、结构不统一。
2.2. 数据导入层
数据导入层实现高速列车原始数据向基础数据库的数据加载,对数据所进行的抽取、转换和清洗的过程,是数据仓库获取高质量数据的关键环节。由于高速列车数据仓库是面向用户需求的,高度集中的数据集合体,因此它的不可更新性和随时间变化性也不断凸显。这就需要有大量的、正确的、相关的、并且可以信任的数据去支持数据仓库的决策分析。
数据抽取是建设数据仓库的第一步。由于数据仓库所需信息量非常大,这就需要从不同的数据平台(包括各种数据源表、数据库和形式各异的数据文件等)上进行完全性或差异性的抽取。数据来源广泛,必然存在各种各样形式上或内容上不完全或错误的数据,即所谓的“脏数据”。在数据仓库中为了保证数据内容的准确性和数据格式的一致性,必然要对这些数据进行一致性的控制和清洗,即通常我们所说的数据清洗阶段。数据转换指对不同数据分区中经过清洗后的数据进行有选择性的组合和转换,如数据的格式化,关键数据的重新构建和数据总结,数据定位等,从而得到一致性的符合用户要求的数据;数据装载指将经过数据清洗后得到的一致性数据经过部分选择装载到指定的数据表或者目标数据仓库中,在这个阶段是可以进行外部人工干预的,以选择适合用户需要的数据。
数据导入时,只有通过质检的文件才可以加载到数据仓库中。数据质检主要完成数据的合法性检验,对检验结果给出错误提示,并保存质检日志,使得数据便于修改,通过配置或选择检验规则模板实现质检的通用性和可配置性。
高速列车数据仓库ETL的流程如下 [8] :将高速列车源数据抽取出并临时存放于数据准备区,在数据准备区中进行数据清理、转换、一体化,将转换后的标准数据装载到高速列车数据仓库。在数据准备区中进行的插入、修改、删除等操作时将同步更新高速列车数据仓库中的数据,更新采用增量更新模式。其过程如图2所示。
2.3. 数据仓库层
数据仓库层是整个高速列车数据仓库系统的核心部分,数据仓库中的数据包括:详细数据、历史数据、元数据和粒度数据。
1) 详细数据
详细数据是信息仓库的核心,存放大量数据。数据来自业务操作数据库,通过主题来组织,不是代表特定应用,而是代表整个企业。在数据仓库中数据粒度最低,当数据精确化时,其中的每一个数据实体都是一个快照、一个时刻,表示一个瞬间。一旦需要支持企业需求,数据随即进行更新。
2) 历史数据
历史数据是以前的有意义的数据,这些数据能够给企业带来延续的利益和价值。它包含巨大的数据量,主要用来分析和预测趋势,其中既包括旧数据(原始或汇总形式),又包括描述旧数据特征的元数据。对于高速列车而言,主要包括车辆设计图纸、参数、模型以及实验和仿真数据等。

Figure 1. High-speed train data warehouse architecture
图1. 高速列车数据仓库体系架构

Figure 2. Data import process schematic
图2. 数据导入过程示意
3) 元数据
元数据是数据仓库数据中最重要的部分,关于数据的数据。也称为数据仓库的结构,是所有数据的集成体现。数据仓库开发者使用元数据来管理和控制数据仓库的建立和维护。高速列车元数据库平台大体结构如图3所示。

Figure 3. High-speed train metadata platform
图3. 高速列车元数据平台
4) 粒度数据
粒度数据定义为数据仓库所保持的信息的概要程度。不同粒度表示为不同级别的汇总数据 [9] 。汇总数据是信息仓库的特点,所有的企业数据分类(按部门、地区、功能等)需要的信息都不同,同时有效的信息仓库设计是为不同风格提供的,轻量级汇总数据为整个企业组成部分服务。通过企业数据分类找到详细和汇总数据。但是它依旧比数据仓库中的详细数据少得多。高度汇总数据是企业执行的主要依据,它来自根据企业组成部分的轻量级汇总数据或来自当前详细数据。这一层的数据容量比其它任何一个都少,代表一个折衷的积累,用来支持各式的需要。通过高度汇总,执行者能够使用“钻取”到达逐步增加的详细层。
数据集市中存储的数据,是为了某个部门的决策支持系统而专门从整体性数据仓库筛选的,是整体性数据仓库中数据的一个子集。数据集市根据用户需求创建,它将高速列车数据仓库的原始粒度数据进行筛选、统计或插值计算后形成多维数据立方体,为OLAP、数据挖掘等应用提供数据支持。利用数据集市工具创建和更新数据集市,该工具将根据数据集市创建的主题类型、规则等从高速列车数据仓库中提取数据并通过统计计算后更新专题数据集市中的数据。
2.4. 数据处理层
数据处理层是进行高速列车数据的具体处理,调用查询、统计分析、OLAP、数据挖掘和预测预报等算法和函数,这些算法和函数通过JDBC,ADO.NET等数据访问引擎从数据仓库中提取要处理的海洋环境数据并进行具体计算,将计算结果以接口形式返给客户。由封装了查询、OLAP分析、聚类分析和因子分析等各种算法的组件具体实现。为保证计算速度,在这一层采用Web缓存技术、负载均衡技术以提升处理效率,但这些对客户均是透明的,客户只是觉得有一个具有超级空间计算能力的Web服务器。由于Oracle数据库将OLAP和数据挖掘和数据存储无缝地集成在一起,故从性能、安全和管理等方面达到了理想的效果。
3. 谱系化数据仓库构建
3.1. 数据仓库组成
将分别构建好的高速列车各组份相关的数据库,包括了需求数据库、需求元模型数据库、产品元模型数据库、过程元模型数据库、技术指标体系数据库以及相关的映射规则数据库、配置规则数据库等进行关联,实现数据库间的耦合关系,最终构建出相应的高速列车谱系化数据仓库用于支撑面向需求的高速列车快速设计,具体的数据仓库组成如图4所示。其中以高速列车产品结构树数据库为基础串联起其余相关的产品数据库,并通过映射规则库实现需求数据的快速转化形成高速列车设计的技术指标数据,再根据配置规则库对高速列车进行模块设计配置,最终形成满足需求的高速列车产品实例,上述的过程通过对过程元模型的实例赋值来实现高速列车定制流程的控制。
上述已经将相关的需求数据库、需求元模型库、产品元模型数据库已经过程元模型数据库进行了研究,此处进行其它数据仓库的组成部分的数据库研究和设计。具体如下:
结构树模板库主要是为了组建和存贮高速列车产品结构树,同时能够灵活的添加结构到任意的节点处,或对结构树上的任意节点进行删除与修改的操作,并且能够便于后续的其它数据进行关联或引用。根据高速列车产品结构树的自身特点,其主要分为三个部分,第一部分是层级数据,其主要是表示高速列车结构的主要层级,现整理的有六个层级。第二部分是单独的各个结构的数据,表示的是每一个结构,不包含之间的连接或拓扑关系。第三部分就是各个结构间的拓扑关系,表示各个结构之间的联系。
因此根据上述的分析,高速列车产品结构树数据表主要分为三个基础表单(图5):
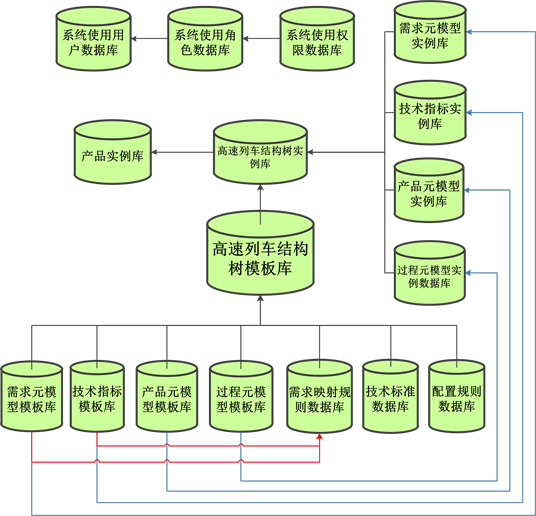
Figure 4. Pedigree data warehouse composition
图4. 谱系化数据仓库组成

Figure 5. High-speed train tree formation relationship
图5. 高速列车结构树形成的关系图
1) 层级字典表:表示的是高速列车各个层级的信息,包括了层级的名称,层级的编码、层级的备注,提供规范的数据字典。现有的层级共有六级,列车层级、车辆层级、组份层级、部件层级、子部件层级、零件层级。层级字典表应能够进行添加、删除和修改的功能,其中功能使用原则为当进行删除时候,若层级没被关联过结构节点则可以删除。
2) 结构树节点表:表示的是高速列车单个结构的数据表单,其主要包括了结构名称、层级ID、结构编码、结构来源、同时为了能够将后续中的其它数据挂靠到结构树的节点上,还应包含其它数据的引用ID,便于关联其它数据。即包含了需求元模型模板引用ID、产品元模型模板引用ID、技术指标模板引用ID、过程元模型模板引用ID、三维模型。
3) 结构树节点引用表:主要是对实际结构模板的引用,用于形成树结构,和实现结构模板的复用。包含被引用的结构模板的ID、父结构模板的ID。可以作为上一级结构模板的子节点,形成树状结构。
高速列车产品结构的编码现采用七级码,即由7位数字表示,其中每一位数字对应其所在的层级,并且每一层的产品码设置从1~9表示9个产品,其中如果为码位数字为0,表示在相应的层级补满码位,不代表具体的产品名称。每一层从父节点开始,从1进行编码。
3.2. 数据库组成
基于谱系化理论和数据仓库层级结构,形成了如下8大数据库作为底层支持 [10] 。
1) 结构树实例数据库
结构树实例数据库管理的是具体车型所对应的产品结构树,其构建的基础产品结构树的模板,即高速列车产品结构最大集合。当确定某种车型时候,结构树的节点能够自由删减得到相应车型的产品结构树。而实例的管理是采用结构树实例表进行统一的管理。
2) 需求元模型数据库
需求元模型主要组成包括了五部分,第一部分是高速列车需求数据项的信息(已经在需求数据库中建立好了),第二部分是需求数据的描述(已在需求数据库中建立好了),第三部分是属性与属性之间的关联关系;第四部分是需求数据项与属性之间的关联关系(已经建立好);第五部分是需求、属性与结构树之间的关系,即将需求属性以及需求项数据关联到不同的结构树节点上。前四部分在需求数据库中已经建立好了,因此需求元模型组建的主要就是描述需求数据项、需求属性与结构树的节点的数据关系。
3) 产品元模型数据库
产品元模型主要组成包括了四部分,第一部分是高速列车产品数据项的信息,即描述的是单个产品数据变量的信息,第二部分是产品属性分类的描述,第三部分是属性分类与产品数据项之间的关联关系;第四部分是产品数据项、属性分类与结构树之间的关系,即将产品护具项以及属性分类关联到不同的结构树节点上。
4) 技术指标数据库
技术指标数据库主要是为了形成高速列车技术指标模板库,并且能够按照给出分类以及结构树以的进行管理,分走形,承载,总体(车辆或者列车)等,然后按照定义的结构树名词在结构树上进行引用,因此基于上述的分析,技术指标数据库主要分为了三个基础表单:分类字典表、技术指标数据表、技术指标与属性引用表。
5) 高速列车映射规则数据库
基于通用的映射规则描述格式,并结合高速列车需求以及技术指标特点,即两者都是具有层级结构,并是以产品结构树为分层基础具体的关联关系如图。
6) 高速列车技术标准数据库
产品技术标准是一种以文件形式发布的统一协定,其中包含可以用来为某一范围内的活动及其结果制定规则、导则或特性定义的技术规范或者其他精确准则,其目的是确保材料、产品、过程和服务能够符合需要。为了在一定范围内获得最佳秩序,经协商一致制定并由公认机构批准,共同使用的和重复使用的一种规范性文件。
高速列车的设计、制造、运行过程中,会有许多的相关标准对其进行约束,具体的技术标准按照各地域的划分,可以分为各地区或各国家标准,例如欧洲标准,美国标准、日本标准、中国标准等。其中中国标准又分为国家标准、行业标准、地方标准和企业标准,并将标准分为强制性标准和推荐性标准两类。
7) 配置规则数据库
根据配置规则的数据特点,其数据表主要包括了三个部分,第一部分是结构树节点数据,规则按照其对应的对象进行关联。第二部分是配置规则基础信息。第三部分是验证方法的集合数据。
8) 角色权限管理数据库
角色权限管理数据库是由角色权限数据和权限管理数据组合成的。角色是为了完成各种工作而创造,用户则依据它的责任和资格来被指派相应的角色,用户可以很容易地从一个角色被指派到另一个角色。角色可依新的需求和系统的合并而赋予新的权限,而权限也可根据需要而从某角色中回收。权限管理通过对各级设计师人员进行授权、认证和审查的集中管理,达到对安全运维过程进行集中统一的控制,使操作行为和维护行为可以审计。
4. 高速列车谱系化数据管理平台开发
4.1. 高速列车数据管理软件系统
通过上述的高速列车谱系化数据仓库的分析,对构建出的相关数据库进行管理,研究和开发相应的数据仓库管理平台,该平台包含:产品结构树管理、需求元模型数据管理、技术指标体系管理、映射规则数据管理、技术标准管理产、产品元模型管理、配置规则数据管理、三维模型管理软件,如表1所示。
1) 产品结构树数据管理软件
针对现有的高速列车实例进行分析,收集和归纳出相关的产品结构层级和名称,保证此类数据的唯一性,将这些结构数据作为字典进行管理并约束后续的与之相关的各类数据。基于产品结构层级和名称构建出产品结构树的全集,并提供结构树数据的添加、修改、删除、查询等动态管理操作。
2) 需求元模型数据管理软件
将需求数据与产品结构树进行关联,将需求数据进行结构化分解得到相应的高速列车需求元模型。然后通过一定的计算机显示方法对需求元模型数据进行可视化的展示,包括了基于结构树的树状形式显示以及数据列表的显示等。结合产品结构树,可以方便的通过结构树中的结构查看出与之相关的所有需求数据信息。提供包括对需求数据数据进行添加、修改、删除以及更新等操作。使得需求数据拥有可扩展性以及动态性,并且可以使设计人员对需求数据数据进行监控以及维护。
3) 技术指标体系数据管理软件
将收集到的技术指标体系进行名称唯一化,构建出其名称字典进行技术指标体系构建的约束。基于名称字典将技术指标进行属性化分类得到技术指标全集,构建过程中对技术指标数据进行初始信息的填写。结合结构树,将技术指标分解关联到相关的产品结构树节点上,建立起技术指标体系。并能够提供技术指标体系数据的动态管理,包括了查询、增加、修改、删除等操作。

Table 1. High-speed train pedigree data warehouse management software list
表1. 高速列车谱系化数据仓库管理软件列表
4) 映射规则数据管理软件
高速列车设计人员可以依据自身的设计经验、设计知识以及设计标准和方法等,通过读取需求数据库中的需求数据、技术指标数据库中的技术指标数据以及产品结构树的数据,构建出需求到技术指标对应的映射规则。能够实现设计知识的存储、修改、增加等,并支持高速列车面向需求定制过程中的自动实现需求到技术指标的映射。
5) 技术标准数据管理软件
将收集到的产品技术标准按照规定的格式进行信息录入,并提供相应的文件上传和下载功能将技术标准文件传到文件数据库中保存或下载到本地进行查看。同时提供相应的技术标准信息新增、修改、查看、删除等动态管理功能。
6) 产品元模型管理软件
将产品数据与产品结构树进行关联,将产品数据进行结构化分解得到相应的高速列车产品元模型。然后通过一定的计算机显示方法对产品元模型数据进行可视化的展示,包括了基于结构树的树状形式显示以及数据列表的显示等。结合产品结构树,可以方便的通过结构树中的结构查看出与之相关的所有产品数据信息。提供包括对产品数据进行添加、修改、删除以及更新等操作。使得产品数据拥有可扩展性以及动态性,并且可以使设计人员对产品数据进行监控以及维护。
7) 配置规则数据管理软件
高速列车设计人员在进行产品设计的时候,通过读取配置规则库中的配置知识实现产品的快速设计。而配置规则是通过设计人员将自身的设计知识和配置知识进行总结后,通过固定的格式进行构建和管理,构建的过程中利用高速列车产品结构树以及产品元模型数据来建立出任意结构节点的配置规则,在模板级别以及实例级别构建出对应的选配参数来。在此基础上针对构建的选配参数以及非选配参数来建立相应的赋值规则。能够实现配置规则的存储、修改、增加等,并支持高速列车设计过程中的产品快速配置。

Figure 6. Product structure name management interface
图6. 产品结构名称管理界面
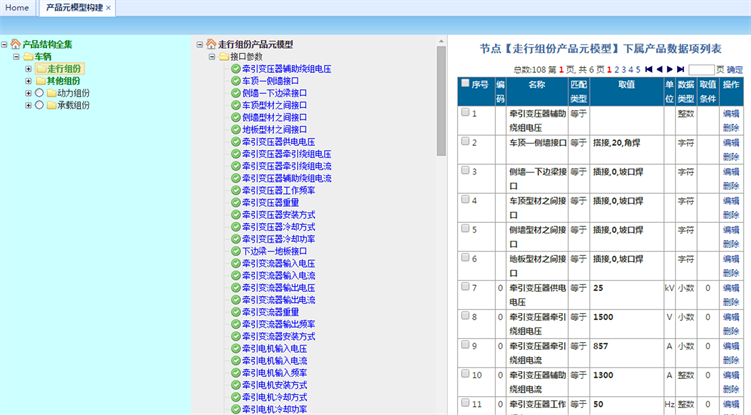
Figure 7. Product meta-model visual interface
图7. 产品元模型可视化界面
该系统需要包含:选配参数管理、选配参数赋值以及非选配参数赋值。配置规则管理系统的功能结构与功能列表如下表所示。
8) 三维模型数据管理软件
结合产品结构树以及产品元模型数据实例,将对应的高速列车三维模型与之关联上传到文件数据库中。按照产品结构树层级对产品实例的三维模型进行管理,提供查询、更新、导出、删除、修改等动态管理功能。
4.2. 高速列车数据管理平台界面开发
基于高速列车谱系化数据长裤框架,开发一系数据管理软件,并开发了友好的可视化界面,其中产品结构名称管理界面和产品元模型可视化界面如图6和图7所示。
5. 结论
本文基于高速列车谱系化相关理论,对谱系化数据仓库进行研究,确定了高速列车谱系化数据仓库基本框架,构建了数据仓库,并开发了相关软件系统和可视化操作界面,形成了完整的谱系化数据管理平台。本文开发的高速列车谱系化数据管理平台具有完善的层级功能、强大的数据管理功和数据处理能力以及友好的操作界面,能为高速列车谱系化研制平台提供了重要的基础支撑。
文章引用
王光新,高 浩. 高速列车谱系化数据仓库系统研究
Research on High Speed Train Genealogical Data Warehouse System[J]. 交通技术, 2018, 07(02): 79-90. https://doi.org/10.12677/OJTT.2018.72010
参考文献
- 1. 铁路局完成铁路“十三五”发展规划[J]. 城市规划通讯, 2015(2): 13.
- 2. 都青华, 邢海英, 李瑞淳, 等. 高速动车组谱系化技术研究平台初探[J]. 兰州交通大学学报, 2014, 33(6): 141-144.
- 3. 张卫华. 高速列车顶层设计指标研究[J]. 铁道学报, 2012, 34(9): 15-19.
- 4. 谢宇迪. 谱系化动车组转向架CAD/CAE集成分析的研究[D]: [硕士学位论文]. 北京: 北京交通大学, 2016.
- 5. 吴文龙. 谱系化动车组转向架构架参数化建模及分析[D]: [硕士学位论文]. 北京: 北京交通大学, 2015.
- 6. 李陆星. 谱系化动车组车体参数化建模及分析[D]: [硕士学位论文]. 北京: 北京交通大学, 2014.
- 7. 郑建智, 段占祺, 应桂英. 数据仓库和OLAP技术在卫生统计决策支持系统中的应用[J]. 中国卫生信息管理杂志, 2012, 9(3): 47-51.
- 8. 宋旭东, 刘晓冰. 数据仓库ETL任务调度模型研究[J]. 控制与决策, 2011, 26(2): 271-275.
- 9. 吕海燕, 车晓伟. 数据仓库中数据粒度的划分[J]. 计算机工程与设计, 2009, 30(9): 2323-2325, 2328.
- 10. 赵虹. 动车组维修决策系统数据仓库的研究与应用[D]: [硕士学位论文]. 北京: 北京交通大学, 2009.