Pure Mathematics
Vol.
10
No.
03
(
2020
), Article ID:
34510
,
18
pages
10.12677/PM.2020.103025
Research on Optimization of Alloy Ingredients Based on Yield Prediction
Heming Liao1, Dan Kong2, Jicheng Zhang3
1College of Mathematics and Systems Science, Shandong University of Science and Technology, Qingdao Shandong
2College of Geomatics, Shandong University of Science and Technology, Qingdao Shandong
3College of Electrical Engineering and Automation, Shandong University of Science and Technology, Qingdao Shandong
Received: Feb. 20th, 2020; accepted: Mar. 6th, 2020; published: Mar. 13th, 2020

ABSTRACT
This paper studies the optimization scheme of the “deoxidation alloying” batching arrangement of molten steel. Firstly, we wash the historical data collected during the early smelting of low-alloy steel grades to calculate the yield of element C and Mn. Secondly, we use principal component analysis method to reduce the dimensionality, and the indicators are simplified into four principal components. Furthermore, based on the variation coefficient method, a comprehensive evaluation model of the factors affecting element yield is established, then the element yield of C and Mn is predicted based on the LSMSVM algorithm: 200 sets of basic data are randomly selected as training samples while other 50 sets of basic data are used as prediction samples. Then we analyze the variances and errors. To improve the accuracy of predictions, we use BP neural networks to train the same data set. Finally, under the constraints of ensuring the quality of molten steel and commanding the minimum cost of the alloy as the objective function, an optimization model of alloy ingredients based on the yield prediction is established. With the help of genetic algorithm, allocation plans of alloy ingredients are specifically given to 10 boilers, which effectively reduce the cost of ingredients.
Keywords:Deoxidizing Alloying, Principal Component Analysis, LSSVM, BP Neural Network

基于收得率预测的合金配料优化研究
廖鹤明1,孔丹2,张继丞3
1山东科技大学数学与系统科学院,山东 青岛
2山东科技大学测绘科学与工程学院,山东 青岛
3山东科技大学电气与自动化工程学院,山东 青岛
收稿日期:2020年2月20日;录用日期:2020年3月6日;发布日期:2020年3月13日

摘 要
本文研究了钢水“脱氧合金化”配料安排的优化方案。首先,对低合金钢种前期冶炼采集的历史数据进行清洗,计算C、Mn元素的收得率;其次,应用主成分分析法对数据进行降维,将各项指标简化为四个主成分;进而,基于变异系数法建立C、Mn元素收得率影响因素的综合评价模型,并基于LSM-SVM算法对元素收得率进行预测,随机抽取200个基础数据作为训练样本,以50组基础数据作为预测样本进行预测并分析方差与误差;为提高预测的准确性,借助BP神经网络,对相同数据集进行训练。最后,在保证钢水质量的约束条件下,以合金使用的总成本最低为目标函数,建立基于收得率预测的合金配料优化模型,借助遗传算法,以10组锅炉为例给出具体的合金配料方案,有效降低配料成本。
关键词 :脱氧合金化,主成分分析,LSSVM,BP神经网络

Copyright © 2020 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution-NonCommercial International License (CC BY-NC 4.0).
http://creativecommons.org/licenses/by-nc/4.0/


1. 引言
钢材是国家建设必不可少的物资。炼钢过程中,为保证下一步顺利浇铸或精炼,“脱氧合金化”是重要的环节:向钢水中加入合金或金属,以调整钢种的元素含量,使之达到所炼钢种的成分规格要求。评判合金配料用量分配合理程度的最直观因素是合金元素收得率,因此,对特定环境下特定钢炉的炼钢过程中大量历史统计数据进行分析,建立模型,准确判断和控制元素收得率,求解该情况下最优化的合金配料分配量,有助于因地制宜地提高产品质量、降低成本、提升企业竞争力 [1]。
国内传统的炼钢过程控制中,常常采用分析法、估算法、手工计算,或凭借工作人员的经验 [2] 来安排“脱氧合金化”过程各合金配料的加入量,误差较大,无法因地制宜地确定加入合金的种类与用量。长此以往,由于缺乏实时精确的分配方案安排,导致“脱氧合金化”过程存在不必要的成本消耗与资源浪费。近些年来,国内外学者从多个角度开展了对炼钢过程中“脱氧合金化”合金用量配比的研究,现加料计算方法主要有线性规划 [3]、参考炉次法 [4]、回归分析 [5]、BP神经网络 [6] 等,但目前情况来看,仍然存在诸多问题,比如无法有效处理非线性约束、收敛速度太慢等。为了准确、经济地生产出成分波动小且性能稳定的钢种,研究“脱氧合金化”配料安排,实现当前炉次合金配料的自动优化与成本控制,具有重要实际意义。
本文的安排如下:第二部分,说明低合金钢种前期冶炼采集的历史数据来源,并对数据进行预处理;第三部分,根据合金收得率的定义,计算C、Mn元素的历史收得率,分析其变化趋势,同时结合数据分析出二者收得率的主要影响因素。第四部分,借助算得的历史收得率,根据收得率的影响因素、影响形式,预测两种元素的收得率,并进一步实现预测算法的优化,提高准确率。第五部分,考虑“脱氧合金化”的成本,保证质量的前提下,以最大限度降低合金钢的生产成本为目标,建立“脱氧合金化”成本优化模型,并针对不同炉号,给出合金配料的具体优化安排方案。
2. 数据来源及清洗
2.1. 数据来源
本文所使用数据来自2019年第九届MathorCup高校数学建模挑战赛D题:钢水“脱氧合金化”配料方案的优化 [7]。
数据分为两个附件,附件一为低合金钢种前期冶炼采集的历史数据,共包含1716条记录,每个记录有45个字段,这些字段包括炉号、钢种、转炉终点各类元素含量、转炉终点温度、连铸正样各类元素含量、加入合金配料种类及分量等信息;附件二包含16条记录,表示不同的合金配料,每个记录有10个字段,包括该合金配料中所含有元素的重量百分比以及各合金配料每吨的价格信息。
2.2. 数据清洗
第一步:剔除缺失数据:合金收得率指“脱氧合金化”时被钢水吸收的合金元素的重量与加入该元素总重量之比,因此,应结合两个附件的数据,根据定义计算C、Mn元素的收得率。附件一的数据中,炉号7A06618之后“转炉终点Mn”的数值皆未显示,炉号7A06059之后“连铸正样C”“连铸正样Mn”的数值皆未显示。因为缺失的这些数据会导致收得率计算公式无法执行,所以保留以上三项数据齐全的所有记录。
第二步:去除异常数据:去除转炉终点温度为零、转炉终点Mn含量为零、转炉终点C含量为零分别所在的记录。
将清洗后的数据保存,进行下一步分析。
3. 合金元素收得率的主要影响因素评价
数据清洗后,首先根据定义计算各炉号C、Mn元素的收得率;进一步采用主成分分析对数据进行降维,提取指标主成分;后基于变异系数法,建立元素收得率影响因素的综合评价模型,求解各主成分与收得率的闵氏距离,最终得到C、Mn元素收得率的主要影响因素。
3.1. 合金元素历史收得率计算
合金收得率定义为:脱氧化合金被钢水吸收的合金元素的重量与加入该元素的总重量之比。整理得合金元素收得率公式为:
(1)
其中, 代表合金元素收得率;i代表第i种元素( 分别代表C、Mn元素);k代表炉号;j代表第j种合金 ; 代表转炉终点元素含量(数值为重量百分比); 代表连铸正样元素含量(数值为重量百分比); 代表“脱氧合金化”前钢水净重;M代表“脱氧合金化”结束后钢水净重; 为第j种合金所含第i种元素的含量(数值为重量百分比); 为炉号k中加入的第j种合金配料的重量。
附件二显示,16种合金配料中有11种配料含有C元素。这11种合金配料含C的重量百分比如表1所示:

Table 1. Weight percentage of element C of each alloy ingredient
表1. 各合金配料含C元素的重量百分比
其余5种合金配料C元素含量为零,即: 。
将以上重量百分比数值代入公式(1),则公式(1)的分母部分可表示为:
将各炉号 的实际数据代入公式(1),最终得到810组炉号的C元素历史收得率,部分结果如下表2:
Table 2. Partial calculation results of historical yield of element C
表2. C元素历史收得率部分计算结果
同理,得到251组炉号的Mn元素历史收得率,部分结果如下表3:
Table 3. Partial calculation results of historical yield of element Mn
表3. Mn元素历史收得率部分计算结果
3.2. 主成分分析法归纳元素收得率影响指标
进一步寻找C、Mn收得率的主要影响因素。预处理后的数据集行列众多,应采用主成分分析方法,用一个新的、由原始变量集组成的新变量集做进一步分析,从而达到简化系统的结构、抓住问题实质的目的。主成分分析法是一种降维的统计方法,旨在将原始变量重新组合成一组新的相互无关的综合变量,根据实际需要取出几个较少的综合变量,以尽可能多地反映原来变量的信息。它借助一个正交变换,将其分量相关的原随机向量转化成其分量不相关的新随机向量,然后对多维变量系统进行降维处理,使之能以一个较高的精度转换成低维变量系统,再通过构造适当的价值函数,进一步把低维系统转化成一维系统。
借助SPSS软件,对预处理后的数据集进行主成分分析,过程如下:
Step 1:相关性检验:保留钢水净重、氮化钒铁FeV55N11-A、低铝硅铁、钒氮合金(进口)、硅铝钙、硅铝合金FeAl3OSi25、硅锰面(硅锰渣)、硅铁FeSi75-B、石油焦增碳剂、锰硅合金FeMn68Si18 (合格块)、碳化硅(55%)、硅钙碳脱氧剂、转炉终点温度十三项指标。利用SPSS软件中的Data Reduction-Factor命令,对以上变量进行主成分分析。
Table 4. KMO and Bartlett’s test
表4. KMO和Bartlett的检验
表4显示:KMO值为0.649 > 0.6;Bartlett球形度检验值为1889.202,卡方统计值的显著性水平为0.000,小于0.001,球形假设被拒绝。二者均说明各指标之间具有相关性,适合做进一步分析。
Step 2:提取主成分:
Table 5. Total variance explained
表5. 解释的总方差
由表5可知,成分1,2,3,4的特征值大于1,合计能解释66.076%的方差,因此提取成分1,2,3,4作为主成分。
Step 3:基于提取的主成分,得到成分矩阵:
Table 6. Composition matrix
表6. 成分矩阵
分析成分矩阵表6可知:
硅铁FeSi75-B、硅铁FeSi75-B、钒氮合金(进口)、碳化硅(55%)在第一主成分上有较高载荷,说明第一主成分基本反映了这些指标的信息;
钢水净重、石油焦增碳剂、低铝硅铁在第二主成分上有较高载荷,说明第二主成分基本反映了这三个指标的信息;
石油焦增碳剂、硅钙碳脱氧剂、硅铝钙、低铝硅铁在第三主成分上有较高载荷,说明第三主成分基本反应了这四个指标的信息;
石油焦增碳剂、锰硅合金FeMn68Si18、氮化钒铁FeV55N11-A、硅锰面(硅锰渣)在第四主成分上有较高载荷,说明第四主成分基本翻译了这五个指标的信息。
综上,四个主成分可以基本反映原始指标信息。
Step 4:结果保存与处理:
进一步,得到成分得分系数矩阵如下表7:
Table 7. Score coefficient matrix of 13 original variables under SPSS processing
表7. SPSS处理下13个原始变量的成分得分系数矩阵
分别分析表7各主成分对应指标的成分得分数值,保留成分得分系数大于0.2的指标。设钢水净重、硅铝合金FeAl30Si25、石油焦增碳剂、硅铁FeSi75-B、锰硅合金FeMn68Si18、转炉终点温度、钒氮合金(进口)、硅钙碳脱氧剂、碳化硅(55%)、硅铝钙、氮化钒铁FeV55N11-A、低铝硅铁、硅锰面(硅锰渣)分别为 ,用 分别表示四个简化后的主成分,由简化后的成分得分系数表可得:
(2)
以上处理步骤旨在对数据降维,在尽可能保留原始数据信息的情况下,将繁杂的指标简化为四个主成分——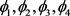 ,进行下一阶段分析。
,进行下一阶段分析。
3.3. 基于变异系数法的元素收得率影响因素综合评价
将预处理的数据各指标简化为四个主成分后,进一步基于变异系数法,实现对C、Mn的收得率主要影响因素的综合分析评价。
原理:变异系数法是一种客观赋权的方法,利用被评价对象指标的变异程度确定指标权重。在评价指标体系中,取值差异越大的指标越难实现目标值,说明其更能反映被评价对象之间的差距,应被赋予较大的权重 [8]。因此,变异系数法可以比较客观地反映指标数据的变化情况及其影响程度。
Step 1:为了消除各项评价指标数据量纲不同的影响,需要用各项指标的变异系数来衡量各项指标取值的差异程度。各项指标的变异系数公式如下:
其中 是第i项指标数据的标准差, 是第i项指标数据的平均值。
Step 2:得到各项指标总分:
Step 3:对各项指标总分进行归一化处理:
Step 4:求解各主成分闵氏距离。要用数量化的方法对事物进行分类,就要用数量化的方法定义样本之间的影响程度,其在数学中被定义为距离,常见为闵氏距离。两变量间闵氏距离公式如下:
对于两个样本类 ,可借下式度量其闵氏距离:
取 ,结合Step 3所得各指标归一化后的得分以及式(2)所示各主成分与指标的对应关系,借助MATLAB求得四个主成分与元素收得率平均值的闵氏距离
Table 8. Min’s distance of each principal component
表8. 各主成分闵氏距离
由表8可知:成分3对收得率影响最大,其主要反映钢水净重、石油焦增碳剂、硅钙碳脱氧剂、硅铝钙、低铝硅铁含量对元素收得率的影响;其次对收得率影响较大的是成分2,其主要反映钢水净重、石油焦增碳剂、低铝硅铁含量对收得率的影响;成分1和成分4对收得率的影响较小。综合上述解答,合金元素收得率的主要影响因素为:钢水净重、石油焦增碳剂、硅钙碳脱氧剂、硅铝钙、低铝硅铁。
4. 合金元素收得率的预测
分析得到元素收得率的主要影响因素后,基于LSM-SVM算法,建立收得率的预测模型,随机抽取200个炉号的基础数据作为训练样本,另取50组基础数据作为预测样本,进行预测,分析预测结果与实际值的方差与误差;为提高预测的准确性,借助BP神经网络,对相同数据集进行训练、预测,并分析效果。
4.1. 基于最小二乘支持向量机的预测模型
3.3建立的综合评价模型得到了C、Mn元素收得率的主要影响因素,现对收得率进行预测。由于二者收得率的影响因素众多,且无法用线性表达式简单推导出与收得率的关系.对于非线性分类与函数估计等问题,支持向量机SVM [9] 是一个很强大的方法。最小二乘支持向量机(LSSVM)是标准SVM的改进,应用最小二乘法思想,提高学习能力。
模型建立如下:
设训练样本集 ,其中 是输入数据, 为输出集。在权w空间中最小二乘支持向量机问题可以描述为:
(3)
式中, 表示 将输入空间映射为高维特征空间函数; 为超平面的权值向量;b为偏置量。通过最小正则化风险泛函获得 的解:
(4)
式中C为惩罚函数系数; 表示损失函数 。
最小化 ,带入 :
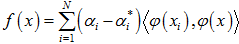 (5)
(5)
其中 称作核函数,它是对称的正实函数,满足径向基核函数: ;模型中的惩罚系数C和核宽 通过交叉检验获得 [2]。
模型求解:
首先从清洗后的数据集中随机抽取200条记录作为训练样本,结合MATLAB机器学习功能,对trianlssvm函数进行训练;另取20条记录为预测样本,进行预测。两种元素收得率预测值与真实值部分如表9所示:
Table 9. Comparison of predicted and true yield values of C and Mn based on LSSVM
表9. 基于LSSVM的C、Mn元素收得率预测值与真实值对比
分别分析两种元素收得率预测准确度。首先针对C元素:将预测值与该50组原有收得率进行对比。训练效果图如图1。
由C元素的LSSVM训练图可知,训练值在0.8附近上下波动,且图像趋于平稳。
真实值与预测值重合得越多,则意味着预测结果越准确。由图2可知,50个预测样本的预测值与真实值之间重合度不是很高,这说明预测结果存在一定偏差。为直观显示预测结果的准确度,本文进一步求出真实值与预测值之间的误差与方差,做出图像进行分析:

Figure 1. LSSVM training chart for yield prediction of C
图1. C收得率预测的LSSVM训练图

Figure 2. Comparison of true and predicted yield values of C
图2. C收得率预测的真实值与预测值对比图
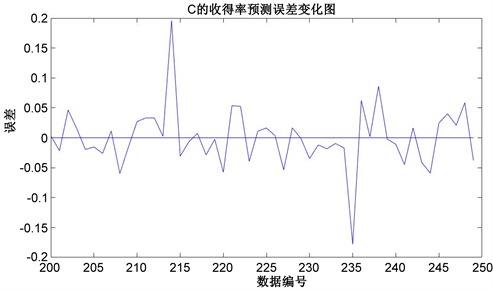
Figure 3. Error of C yield prediction
图3. C收得率预测误差变化图
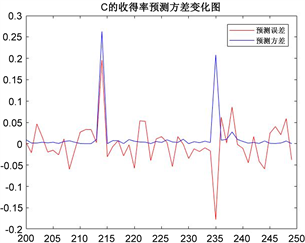
Figure 4. Variance and error of C yield prediction
图4. C收得率预测方差与误差图
由上图3、图4两图可知,50组对C收得率的预测结果实际值之间的误差、方差值在不断波动,二者的变化趋势大致相同,大部分误差在5%范围内波动;在第214,235个数据周围,误差和方差的数值绝对值同时急剧上升,达到最大误差接近0.2。
同理,做出对Mn元素收得率的收得率预测值训练结果以及与真实值的比较:

Figure 5. LSSVM training chart for yield prediction of Mn
图5. Mn收得率预测的LSSVM训练图
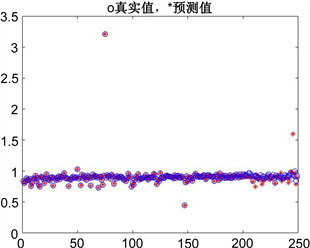
Figure 6. Comparison of true and predicted yield values of Mn
图6. Mn收得率预测的真实值与预测值对比图
根据图5、图6,Mn元素收得率的真实值与预测值有一定差距,但相比C的重合度要高,预测结果比C准确。
进一步求解Mn元素收得率真实值与预测值之间的误差与方差,做出图像并分析:
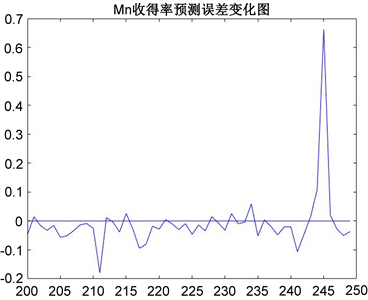
Figure 7. Error of Mn yield prediction
图7. Mn收得率预测误差变化图
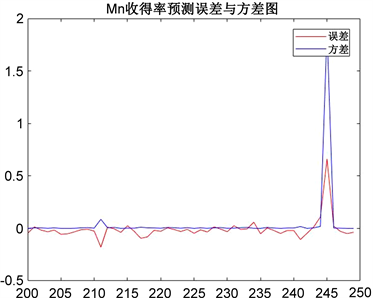
Figure 8. Variance and error of Mn yield prediction
图8. Mn收得率预测方差与误差图
由图7、图8可知,50组预测样本中,误差、方差值不断波动且变化趋势大致相同,大多在0.1内;在第245组样本周围,误差和方差的数值绝对值同时急剧上升,达到最大误差接近0.8。
4.2. 基于BP神经网络的预测模型
为提高4.1的元素收得率预测的准确性,本文选择BP神经网络,进行优化分析与预测。BP神经网络是一种按照误差逆向传播算法训练的多层前馈神经网络,即计算误差输出时按从输入到输出的方向进行,而调整权值和阈值则从输出到输入的方向进行。BP神经网络是应用最广泛的神经网络,适合处理影响因素复杂、变量关系难以归纳、推理规则不清楚的问题,对经验知识背景要求较低,只需给出对象的输入和输出数据,通过网络本身的学习功能找到输入与输出的映射关系 [10]。
4.2.1. BP训练算法描述
1) 初始化:给各连接权值及阈值赋予 之间的随机值。
2) 训练集样本向量 将各分量数据输入给输入层对应的5个神经元。
3) 由输入样本的特征向量
、输入层与隐含层的连接权
以及隐含层单元的阈值
,由
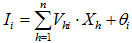 计算隐含层各单元的输入
,并计算对应的输出值
。
计算隐含层各单元的输入
,并计算对应的输出值
。
4) 由隐含层各单元的输出 、隐含层和输出层间的连接权
、隐含层和输出层间的连接权
 以及输出层单元的阈值
,用
计算各输出层规定输入,计算输出层各单元对应的输出
。
以及输出层单元的阈值
,用
计算各输出层规定输入,计算输出层各单元对应的输出
。
5) 借助 计算输出层单元的一般化误差。
6) 由隐含层和输出层之间的连接权、输出层单元的一般化误差
以及隐含层各单元的输出 ,用
计算隐含层各单元的一般化误差。
,用
计算隐含层各单元的一般化误差。
7) 由输出层单元的一般化误差 、隐含层各单元的输出 ,用权值调整公式 、 修正 以及输出层各单元的阈值 。
8) 由隐含层单元的一般化误差
、输入层各单元的输入
,用阈值调整公式
、
修正输入层与隐含层的连接权
以及隐含层各单元的阈值。其中,
为比例系数,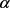 是惯性因子,以加速网络收敛。
是惯性因子,以加速网络收敛。
9) 顺次选取下一个样本,返回步骤2),直到训练集样本全部学习一遍。
10) 重新返回步骤2),直到网络的误差函数小于预先设定的值,即网络收敛大于预先给定的值。
4.2.2. 模型建立与求解
取4.1处理过程中用于训练的200组数据,同样作为BP神经网络的训练样本;以钢水净重、石油焦增碳剂、硅钙碳脱氧剂、硅铝钙、低铝硅铁含量为输入层,以元素收得率为输出层;隐含层层数以及各层神经元数量在测试中;激活函数选取tansig函数;选用Levenberg Marquardt训练算法;误差指标为MSE;设定Epoch为1000。利用MATLAB神经网络工具箱进行训练,效果图如下:

Figure 9. BPNN yield training diagram of C
图9. C收得率BPNN训练图
图9显示,第16次训练后6次训练内validation均未降低,为避免过拟合现象,训练终止。第16次的训练效果最好。
将4.1中50组预测样本作为BP神经网络的测试集,将各指标数据输入神经网络,输出两种元素收得率预测值,部分如下表10:
Table 10. Comparison of predicted and true yield values of C and Mn based on BPNN
表10. 基于BPNN的C、Mn元素收得率预测值与真实值对比
得到C元素收得率预测的误差与方差图,如图10:
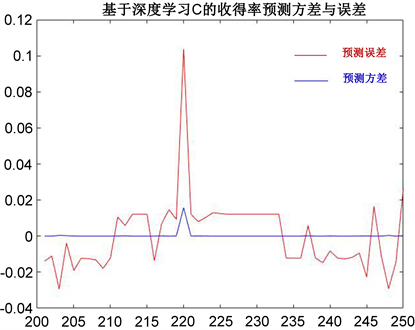
Figure 10. Variance and error of C yield prediction
图10. C收得率预测的误差与方差图
C的收得率预测方差与误差图可知,BP神经网络训练得到的预测值中,预测方差均在±0.02以内,有大幅降低;预测误差大多在±0.02附近波动,且误差最大值降至0.1。与3.1的结果相比,C元素收得率预测的准确性有较大幅度提升。
同理,得到Mn元素收得率预测的误差与方差图:
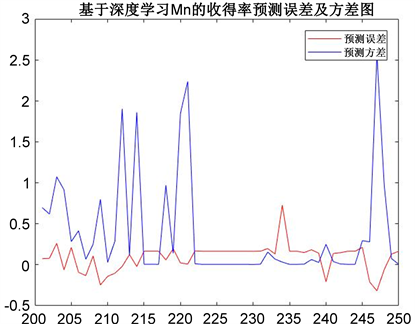
Figure 11. Variance and error of Mn yield prediction
图11. Mn收得率预测的误差与方差图
由图11可知,采用BPNN得到的Mn元素收得率预测值中,预测误差较小,误差最大值为0.6左右,与4.1的结果相近,因此两种方法对Mn元素收得率预测的效果相差不大。
5. 基于收得率预测的合金配料优化模型
5.1. 优化模型建立
通过对历史数据进行分析,建立不同钢种、不同钢号的元素收得率与各种因素的综合关系,在保证钢水质量的约束条件下,以合金使用的总成本最低为目标函数,建立模型:
设共有m种元素,在对钢种X的钢液进行“脱氧合金化”时,共有r种合金配料可以加入到钢水中,用于钢水各要求元素含量的调整。
决策变量:每种合金配料的投资量 。
目标函数:以加入合金所使用的总成本最低作为目标函数,即:
(6)
其中 为第i种合金料的单价; 是第i种合金料加入的质量。
由于投料量满足非负条件,即有:
(7)
钢种成分含量规范约束:不同钢号是按国家标准对具体钢产品取的名称,而对于不同的钢号,其主要合金元素的含量均应满足国家标准,即在一定内控区间内:
(8)
式中 为炉号k对应的钢种对于第i中合金元素的控制目标下限; 为炉号k对应的钢种对于第i中合金元素的控制目标上限; 为炉号k对应的第i种合金元素的收得率预测值。
5.2. 基于遗传算法的模型求解
随机选取10个炉号,通过MATLAB软件的遗传算法工具箱进行求解。得到优化前后各炉号所加合金料的配料安排、成本对比以及优化前后的成本落差图,如图12:
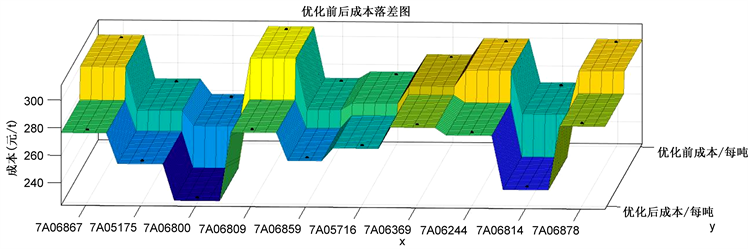
Figure 12. Cost difference before and after optimization of alloy batching of each furnace
图12. 各炉号合金配料优化安排前后成本落差图
成本落差图可以直观反映出优化前后成本的变化。由图12可见,优化配料安排前后,成本有较为明显的下降,因此设计算法优化配料方式对降低“脱氧合金化”成本有重要作用。
用 分别表示钢水重量、氮化钒铁FeV55N11-A、低铝硅铁、钒氮合金(进口)、钒铁(FeV50-A)、钒铁(FeV50-B)、钒铁(FeV50-B) (第二次)、硅铝钙、硅铝合金FeAl3OSi25、硅铝锰合金球、硅锰面(硅锰渣)、硅铁(合格块)、硅铁FeSi75-B、石油焦增碳剂、锰硅合金FeMn64Si27 (合格块)、锰硅合金FeMn68Si18 (合格块)、碳化硅(55%)和硅钙碳脱氧剂,得到如下被选取炉号优化后的配料安排表:
Table 11. Ten cases of steel furnace ingredients optimization schedule (furnace number omitted “7A0”)
表11. 十例钢炉配料优化安排表(炉号省略“7A0”)
由表11结果可知,对于不同环境(即不同炉号)下,不同合金材料的分配各不相同,但是上述十个安排中有共性之处:
不同炉号之间,钢水净重大致相同;硅锰面与锰硅合金FeMn68Si18的用量均较大且相近;石油焦增碳剂、钒铁(FeV50-B)的用量相近;低铝硅铁、硅铝合金FeAl3OSi25、硅铝锰合金球、硅铁(合格块)、锰硅合金FeMn64Si27 (合格块)基本不投入使用,成本高的矾铁配量均为0;氮化钒铁FeV55N11-A、钒氮合金(进口)、硅钙碳脱氧剂的用量小但差异较大;硅铝钙、碳化硅(55%)用量差异较大。
Table 12. Cost table before and after the optimization of ingredients
表12. 配料优化安排前后成本表
上表12数据结果可直观得出结论:优化后的配料方案最多可将“脱氧合金化”成本降低11.5%。
6. 结论
在信息处理、大数据技术迅猛发展的时代背景下,“脱氧合金化”等工业过程越来越需要模型的优化设计与大数据算法的实时处理。本文从数据分析的角度,研究了钢水“脱氧合金化”配料安排的优化方案。
为简化系统结构,本文采用主成分分析,初步将预处理后的数据集中复杂的指标转化为四个主成分,进一步基于变异系数法,求解各成分与收得率的闵氏距离,实现了收得率影响因素的综合分析。分析可得:影响收得率的主要因素为钢水净重、石油焦增碳剂含量、硅钙碳脱氧剂含量、硅铝钙含量和低铝硅铁含量。此方法较为灵活,可针对不同环境记录的历史数据值求得该环境中某特定合金元素收得率的主要影响因素。
本文采用两种方法对合金收得率进行预测:基于最小二乘法,建立支持向量机模型,从预处理后的数据集中随机抽取200条记录作为训练样本,结合MATLAB对trianlssvm函数进行训练;再抽取50条记录为预测样本,进行收得率的预测。结果发现:对C元素合金收得率的预测值而言,大部分预测误差在5%范围内波动,但误差最大值接近20%。后建立BP神经网络模型,对与LSSVM相同的200组数据为训练样本进行训练,对相同的50组数据进行预测。分析预测结果,发现C元素收得率预测的误差与方差相较第一种方法有较大幅度降低;而对Mn元素收得率的预测而言去,两种方法的预测效果相近。
基于收得率的预测,建立合金配料优化模型,在保证钢水质量的约束条件下,以合金使用的总成本最低为目标函数,借助遗传算法,以十组锅炉为例,给出具体的合金配料方案。优化后的配料方式最多可将“脱氧合金化”成本降低11.5%,证明了配料优化模型的有效性。
本文所建立的基于收得率预测的合金配料优化模型,很大程度上借助了钢水炼钢过程中的元素含量数据,由于客观条件的限制,全文的处理方式是宏观层面的,即未从理论上考虑“脱氧合金化”过程中的物理化学变化;同时,每个钢炉的各元素含量数据仅有始、末两类,无法分析反应的过程。后期可以再深入研究反应的微观原理,分析化学反应发生的条件,并在炼钢过程中详细、及时地记录各时间段的数据,以期实现对元素收得率的进一步精准控制。为得到实时、精确的配料安排,可以根据数据分析的思想、结论,研发相应软件,实现实时监控以及配料安排方案的快速精准制定。
文章引用
廖鹤明,孔 丹,张继丞. 基于收得率预测的合金配料优化研究
Research on Optimization of Alloy Ingredients Based on Yield Prediction[J]. 理论数学, 2020, 10(03): 172-189. https://doi.org/10.12677/PM.2020.103025
参考文献
- 1. 杨凌志, 王学义, 王志东, 王振祥. 基于收得率动态库的合金加料优化模型[J]. 北京科技大学学报, 2014, 36(S1): 104-109.
- 2. 韩敏, 徐俏, 赵耀, 林东, 杨溪林. 基于收得率预测模型的转炉炼钢合金加入量计算[J]. 炼钢, 2010, 26(1): 44-47.
- 3. 黄可为. 转炉合金最小成本控制模型[C]//中国金属学会. 2001中国钢铁年会论文集(下卷), 2001: 514-518.
- 4. 龚伟, 姜周华, 郑万, 陈念铀. 转炉冶炼过程中合金成分控制模型[J]. 东北大学学报, 2002, 23(12): 1155-1157.
- 5. 张辉宜, 周奇龙, 袁志祥, 刘志明, 周云. 样本自选择回归分析算法在转炉炼钢中的应用[J]. 钢铁研究学报, 2011, 23(12): 5-8.
- 6. 田卫红, 吴敏. 烧结配料优化控制专家系统[J]. 烧结球团, 2006, 31(1): 23-27.
- 7. 2019年MathorCup高校数学建模挑战赛赛题发布[Z/OL]. http://www.mathorcup.org/detail/2273
- 8. 吴爽. 基于变异系数法——灰色关联度法的生态工业园综合评价[D]: [硕士学位论文]. 成都: 西南交通大学, 2015.
- 9. 尹正文. 最小二乘支持向量机在蒸汽预测中的应用[D]: [硕士学位论文]. 昆明: 昆明理工大学, 2013.
- 10. 王莎. BP神经网络在股票预测中的应用研究[D]: [硕士学位论文]. 长沙: 中南大学, 2008.