Computer Science and Application
Vol.08 No.03(2018), Article ID:24211,10
pages
10.12677/CSA.2018.83033
Research on Particle Swarm Optimization Algorithm for Solving Cloud Computing Task Scheduling
Qing Wang, Xueliang Fu, Gaifang Dong, Shasha Zhao
College of Computer and Information Engineering, Inner Mongolia Agricultural University, Hohhot Inner Mongolia
Received: Mar. 6th, 2018; accepted: Mar. 20th, 2018; published: Mar. 28th, 2018

ABSTRACT
At present, task scheduling problem in cloud environment is a hot research topic, and particle swarm optimization algorithm (PSO) is an important intelligent algorithm to solve the task scheduling problem. According to the correlation, particle swarm Optimization algorithm (CPSO) and new adaptive inertia weight based particle swarm optimization algorithm (NewPSO) in solving this problem are easy to fall into the local optimal solution and poor searching ability, In this paper, the task execution time and cost as the goal, the random factor and the inertial weight are fused, and the Enhanced Particle Swarm Optimization (EPSO) is proposed. Simulation results show that under the same conditions, compared with PSO algorithm, CPSO algorithm and NewPSO algorithm, EPSO algorithm can reduce execution time and cost more effectively (including task execution time, time cost and virtual machine cost), and get a better scheduling solution.
Keywords:Task Scheduling, PSO Algorithm, Correlation, Execution Time, Cost Consumption
求解云计算任务调度的粒子群优化算法 研究
王晴,付学良,董改芳,赵莎莎
内蒙古农业大学计算机与信息工程学院,内蒙古 呼和浩特
收稿日期:2018年3月6日;录用日期:2018年3月20日;发布日期:2018年3月28日

摘 要
目前,云环境下任务调度问题是一个研究热点,而粒子群算法(Particle Swarm Optimization, PSO)是解决任务调度问题的重要智能算法。针对相关性粒子群算法(Correlation Particle Swarm Optimization, CPSO)和新的基于自适应惯性权重粒子群算法(New Adaptive Inertia Weight Based Particle Swarm Optimization, NewPSO)在解决该问题时易陷入局部最优解和寻优能力差的不足,本文以任务执行时间和代价为目标,将随机因子与惯性权重相融合,提出增强型粒子群算法(Enhanced Particle Swarm Optimization, EPSO)。仿真结果表明,在相同条件下,与PSO算法、CPSO算法和NewPSO算法相比较,EPSO算法能更有效的减少执行时间,降低代价消耗(包括任务执行时间,时间花费以及虚拟机花费),得到更优的调度方案。
关键词 :任务调度,粒子群算法,相关性,执行时间,代价消耗

Copyright © 2018 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
近年来,云计算以其独特的方式成为互联网发展的热门话题。云计算主要是利用虚拟化技术,将庞大的计算处理任务通过网络分成多个较小的子任务,再交给由多部服务器组成的庞大系统,经过计算后,将处理结果返回给用户 [1] [2] 。
在云计算中,任务调度策略直接影响到用户的任务执行效率以及云环境下资源的使用效率。在解决任务调度问题的研究领域里,群体智能优化算法越来越得到研究者的广泛关注,逐渐成为解决调度问题的新工具。1995年,Kennedy等提出PSO算法 [3] 。该算法的基本思想是粒子在寻优过程中,不仅考虑自身的局部认识,而且还要考虑种群的全局认识,即每个粒子是在充分利用这两个认知信息的基础上决定下一次的进化方向。由于PSO算法有参数少、易实现、收敛速度快等特性,已被广泛应用于各个领域。
文献 [4] 提出改进的粒子群算法优化神经网络及应用,通过采用动态惯性权重,提高粒子的多样性,一定程度上避免陷入局部最优。文献 [5] 提出一种基于种群多样性的粒子群优化算法设计及应用,通过种群多样性设计自适应惯性权重策略,实现粒子全局优化能力与局部开发能力的平衡,从而避免陷入局部最优解。文献 [6] 在传统惯性权重的基础上提出了新的基于自适应惯性权重的粒子群算法(New Adaptive Inertia Weight Based Particle Swarm Optimization,NewPSO),可以进一步调整粒子速度以平衡粒子全局与局部搜索,使算法避免了陷入局部最优。文献 [7] 提出基于动态加速因子的粒子群优化算法研究,通过引入动态的加速因子,提高全局搜索能力,改善粒子群算法的收敛速度及精度。文献 [8] 提出优化粒子群的云计算任务调度算法,解决了粒子群算法在寻优过程中没有考虑随机因子作用而造成全局优化能力不足的缺陷。
上述方法只考虑惯性权重或者只考虑随机因子,并没有有效避免陷入局部最优解,提高全局优化能力。因此本文将自适应惯性权重与随机因子相融合,并将改进后的粒子群算法运用到云计算任务调度问题中,得到时间与代价均优的调度策略。
2. 云计算任务调度问题描述
随着云计算技术的发展,关于大规模任务调度的研究 [9] 越来越重要。而云计算任务调度主要就是研究如何为用户提交的任务分配资源,换句话说就是将多个相互独立的多样化任务分配到云中规模庞大的虚拟资源上,满足用户QoS要求、任务完成时间最小以及负载均衡最高等目标,其调度规模如图1所示。
3. 标准PSO算法
PSO算法根据个体对搜索空间的适应度值大小对个体的优劣进行评价。假设有一种群,其粒子个数是m,粒子的维数是n,则有:第i个粒子的速度表示为 , , 。第i个粒子的位置表示为 , , 。第i个粒子的个体最优解表示为 , , 。整个种群的全局最优解表示为 。粒子速度和位置的更新方程如下:
(1)
(2)
其中,ω是惯性权重。c1和c2是加速系数,通常设为2 [10] 。r1和r2是[0, 1]区间内均匀分布的两个相互独立的随机数。要将PSO算法运用于云计算任务调度问题,需要对粒子进行编码。
3.1. 粒子编码、解码及其初始化
粒子编码方式有很多种,本文采用直接法。
假设有k个任务,t个资源,且k > t,当k = 5,t = 4时,编码序列(4, 3, 3, 2, 1)即为一个粒子,直接法编码规则是将每1个任务对应1个资源,例如,任务1对应资源4,任务2对应资源3,任务3对应资源3。
粒子解码目的是获取每个资源上运行的所有任务。例如,资源3上运行的所有任务有{2, 3}。定义矩阵 ,用来记录任务i在资源j上的执行时间,则资源j上完成所有任务的总执行时间是:
(3)

Figure 1. Cloud computing task scheduling model
图1. 云计算任务调度模型
其中,i表示资源j上执行的任务个数,n表示资源j上执行的任务总数。则系统完成所有任务的总时间是:
(4)
然后进行种群初始化。假设有k个任务,t个资源,s个粒子,且k > t。第i个粒子位置由向量xi表示,定义为 。其中, , , 。第i个粒子速度由向vi表示,定义为 。其中, , , 。初始化时产生s个粒子,每个粒子的位置和速度分别取 和 间的随机整数。
本文主要研究如何减少执行时间和代价,因此适应度函数是:
(5)
3.2. 目标函数
本文实验结果与其他算法比较的是执行时间和代价,因此将目标函数分别定义为:
(6)
(7)
其中,TaskTime是执行时间,FinishTime是任务调度结束时间,StartTime任务提交时间。Cost是代价,timecost是时间花费(任务总长度/虚拟机的处理能力),debt是虚拟机的花费。
4. 相关性PSO算法(CPSO)
将随机因子r1和r2设为两个相互独立的随机数,没有考虑粒子在寻优过程中对个体最优解pi和全局最优解pg认知的联系。因此,需要建立r1和r2之间的相关性。
线性相关系数是一种常见的相关性分析 [11] 方法,其计算公式如下:
由上式可知,要求随机变量x和y的相关系数r,必须知道期望与方差。但是,有些变量的期望与方差并不存在。而且,相关系数只能描述线性关系,不能描述非线性关系。Copula理论为分析变量之间的相关性开辟了一条新思路。
所以,可通过二元Copula函数刻画变量r1和r2之间的相关性。
二元Copula的相关知识
定义1 [12] :如果二元函数 ,满足下列两个条件:
(1)对于任意 , 且 ;
(2)对于 且 , ,有 ,则称函数C为一个Copula。
定理1 [12] :设随机变量x,y的联合分布函数为 ,其边缘分布函数分别为Fx,Fy,则存在一个Copula ,对任意 ,有:
(8)
由定理1可得以下推论。
推论1 [12] :如果 是一个Copula函数,Fx,Fy分别是随机变量x,y的分布函数,那么存在一个以Fx,Fy为边缘分布的联合分布函数H,满足对任意的 ,有:
(9)
定理1和推论1的作用是说明Copula函数的存在性及其生成方法。
Copula函数类型很多,使用较多且应用广泛的一个是Gaussian Copula,定义如下:
定义2 [12] :对任意 ,二元Gaussian Copula可定义为:
(10)
其中,f是标准正态分布函数,fp是二维正态变量的联合分布函数,f−1是f的逆函数。
设随机变量x和y满足 ,由推论1可知,它们的二元Copula函数实际上是x和y的联合分布函数。因此,用Copula函数研究随机因子r1和r2之间的相关性是可行的,具体定义如下:
(11)
其中,H是r1和r2的联合分布函数,C是相应的Copula函数。
定义3:在PSO算法基础上,由式(1)、(2)和(11)共同描述粒子运动轨迹的算法称为CPSO算法。
CPSO算法 [8] 具体实现过程如图2所示。其中,s是种群规模,r是虚拟机数量,t是任务数量,w是惯性权重,c1和c2是学习因子,x是迭代次数,r是相关系数。
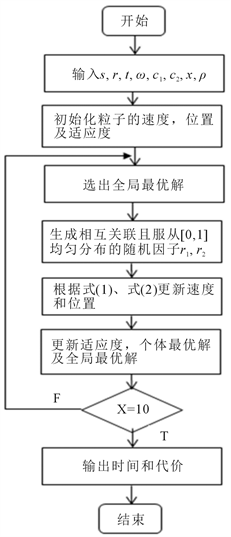
Figure 2. CPSO algorithm flow chart
图2. CPSO算法流程图
5. 新的自适应惯性权重粒子群算法(NewPSO)
通过每个粒子的适应度与全局最优值比较,可以更加准确地描述粒子所处的位置状态,成功值的计算方法如下所示:
(12)
其中, 是粒子i在第t次迭代过程中的成功值, 是粒子i在第t次迭代时的最优位置, 是全局最优值, 是粒子i在第t次迭代时最优位置的适应度。
Ps(t)是粒子群在第t次迭代时的成功率,表示本次迭代位置比上次好的粒子在粒子群中所占比重。其中, 表示所有粒子的成功值之和,n表示整个粒子群的粒子个数。
(13)
ω(t)是第t次迭代时的惯性权重,用于调整每次迭代时的粒子初速度。
(14)
通过与全局最优值的比较更加准确地得出 。精确的 可以提高粒子群的成功率(式(13))和惯性权重(式(14))的自适应性,因此算法可以更准确地调整粒子速度,以平衡粒子的全局与局部搜索能力,避免陷入局部最优。
定义4:在PSO算法基础上,且由式(1)、(2)和(12)、(13)、(14)共同描述粒子运动轨迹的算法称为NewPSO算法。
NewPSO算法 [6] 具体实现过程如图3所示。其中,r1和r2是随机因子,其它参数与上述4.2节中的参数含义相同。
6. 增强型粒子群算法(EPSO)
针对CPSO算法和NewPSO算法存在的缺点,本文提出在自适应惯性权重的基础上,适当融入随机因子之间的相关性,该算法称为EPSO算法。EPSO算法不仅能提高粒子群的寻优能力,还可以避免陷入局部最优。EPSO算法具体实现过程如图4所示。
7. 仿真实验与分析
7.1. 实验环境与参数
本文利用CloudSim构建云计算环境,Eclipse作为开发平台,将本文提出的EPSO算法与基本PSO算法、CPSO算法 [8] 以及NewPSO算法 [6] 进行对比分析。其中,算法参数见表1。
7.2. 实验结果与分析
本文从任务执行时间和代价两个方面与其他三个算法进行比较。其中,执行时间和代价即3.2节中提到的。
7.2.1. 执行时间
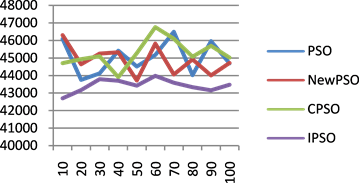
实验设置任务数从20到300变化,单个任务的负载量是30~3000内的随机值 [13] 。分别取20到100个任务,迭代100次的时间变化如图5所示,横坐标代表任务数量,纵坐标代表时间。当任务数量在

Figure 3. NewPSO algorithm flow chart
图3. NewPSO算法流程图
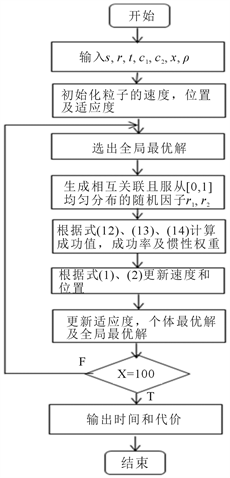
Figure 4. EPSO algorithm flow chart
图4. EPSO算法流程图

Table 1. EPSO algorithm parameters
表1. EPSO算法参数

Figure 5. Change of time with tasks
图5. 时间随任务的变化图
 (a)
(a)
 (b)
(b)
 (c)
(c)
 (d)
(d)
Figure 6. (a) 60-time change chart; (b) 100-time change chart; (c) 200-time change chart; (d) 300-time change chart
图6. 任务数为60的时间变化图;(b) 任务数为100的时间变化图;(c) 任务数为200的时间变化图;(d) 任务数为300的时间变化图
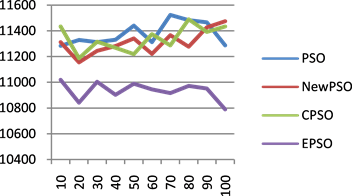
20到50时,四个算法并没有太大区别,当任务数量大于等于60,迭代次数相同的情况下,随着任务数量的增加,EPSO算法执行任务所花费的时间少于其他三个算法花费的时间,进一步说明EPSO算法适合海量任务的任务调度。图6(a)~(d)分别是任务数为60、100、200和300时,迭代100次的时间趋势图,其中横坐标代表迭代次数,纵坐标代表时间。由图可看出,与其他三个算法相比,EPSO算法的趋势较平缓,时间变化比较稳定。随着任务数量越多,EPSO算法的优势越显著。总之,相比其他三个算法,任务越多,EPSO算法越能在较短时间内找到最优解,提高全局优化能力。
7.2.2. 代价
分别取20到100个任务,迭代100次的代价,如图7所示,横坐标代表任务数量,纵坐标代表代价。当任务数大于等于60时,随着任务数量的增加,EPSO算法的代价消耗低于其他三个算法。图8(a)~(d)
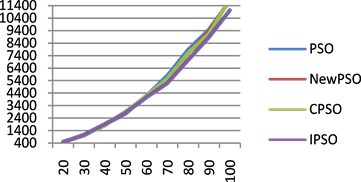
Figure 7. Change of cost with tasks
图7. 代价随任务的变化图
 (a)
(a)
 (b)
(b)
 (c)
(c)
 (d)
(d)
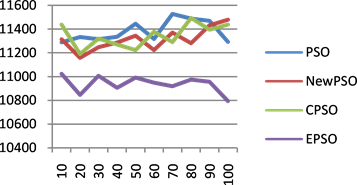
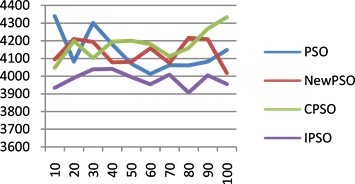
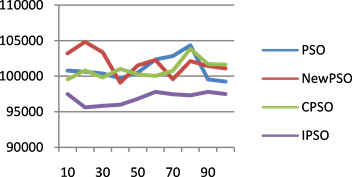
Figure 8. (a) 60-cost change chart; (b) 100-cost change chart; (c) 200-cost change chart; (d) 300-cost change chart
图8. (a) 任务数为60的代价变化图;(b) 任务数为100的代价变化图;(c) 任务数为200的代价变化图;(d) 任务数为300的代价变化图
分别是任务数为60、100、200和300时,迭代100次的代价消耗趋势图,其中横坐标代表迭代次数,纵坐标代表代价。由图可知,随着迭代次数的增加,EPSO算法的代价收敛趋于稳定,且低于其它算法。综上所述,与其他三个算法相比较,EPSO算法在寻优过程中找到全局最优解的同时,所消耗的代价最少。
8. 结论
本文在自适应惯性权重的基础上,加入随机因子的相关性,提出EPSO算法。EPSO算法可有效避免局部最优解,从而提高全局优化能力,获得时间与代价更优的调度方案。但是,本实验仅在模拟环境下实现,还需通过在实际的云计算平台上修改完善。
资助信息
国家自然科学基金(61063004, 61363006);内蒙古自然科学基金(2015MS0626, 2015MS0605, 2015MS0627);内蒙古教育厅高校研究项目(NJZC059);教育部留学人员基金([2014]1685);内蒙古自治区科技计划项目(穿透降水量GSM网络在线监测与数据传输系统的研制)。
文章引用
王 晴,付学良,董改芳,赵莎莎. 求解云计算任务调度的粒子群优化算法研究
Research on Particle Swarm Optimization Algorithm for Solving Cloud Computing Task Scheduling[J]. 计算机科学与应用, 2018, 08(03): 286-295. https://doi.org/10.12677/CSA.2018.83033
参考文献
- 1. Abadi, D.J. (2010) Data Management in the Cloud: Limitations and Opportunities. IEEE Data Engineering Bulletin, 32, 3-12.
- 2. Lee, Y.C. and Zomaya, A.Y. (2012) Energy Efficient Utilization of Resources in Cloud Computing Systems. Journal of Supercomputing, 60, 268-280. https://doi.org/10.1007/s11227-010-0421-3
- 3. Kennedy, J., Eberhart, R.C. and Shi, Y. (2001) Swarm Intelligence. Elsevier Science Press, Singapore, 202-210.
- 4. 何明慧, 徐怡, 王冉, 胡善忠. 改进的粒子群算法优化神经网络及应用[J/OB]. 计算机工程与应用, 2018, 1-9. http://kns.cnki.net/kcms/detail/11.2127.TP.20180205.1504.006.html
- 5. 韩红桂, 卢薇, 乔俊飞. 一种基于种群多样性的粒子群优化算法设计及应用[J]. 信息与控制, 2017, 46(6): 677-684.
- 6. 李学俊, 徐佳, 朱二周, 等. 任务调度算法中新的自适应惯性权重计算方法[J]. 计算机研究与发展, 2016, 53(9): 1990-1999.
- 7. 滕志军, 吕金玲, 郭力文, 王志新, 许恒, 袁丽红. 基于动态加速因子的粒子群优化算法研究[J]. 微电子学与计算机, 2017, 34(12): 125-129.
- 8. 谭文安, 查安民, 陈森博. 优化粒子群的云计算任务调度算法[J]. 计算机技术与发展, 2016, 7(26): 6-10.
- 9. Arfeen, M.A., Pawlikowski, K. and Willig, A. (2011) A Framework for Resource Allocation Strategies in Cloud Computing Environment. Proceedings of 2011 IEEE 35th Annual Computer Software and Applications Conference Workshops, 18-22 July 2011, Washington, DC, 261-266.
- 10. Netjinda, N., Sirinaovakul, B. and Achalakul, T. (2014) Cost Optional Scheduling in IaaS for Dependent Workload with Particle Swarm Optimization. The Journal of Supercomputing, 68, 1579-1603. https://doi.org/10.1007/s11227-014-1126-9
- 11. Embrechts, P., Mcneil, A.J. and Straumann, D. (2001) Correlation and Depend-ency in Risk Management: Properties and Pitfalls. Proc. of the Risk Management: Value at Risk and Beyond, Cambridge University Press, Cambridge, 176-223.
- 12. Nelsen, R.B. (2006) An Introduction to Copulas. 2nd Edition, Springer-Verlag, New York, 10-28.
- 13. Fard, H., Prodan, R. and Fahringer, T. (2013) A Truthful Dynamic Workflow Scheduling Mechanism for Commercial Multicloud Environments. IEEE Trans on Parallel and Distributed Systems, 24, 1203-1212. https://doi.org/10.1109/TPDS.2012.257