Computer Science and Application
Vol.
09
No.
02
(
2019
), Article ID:
28758
,
12
pages
10.12677/CSA.2019.92027
Amplification Method of Training Sample Set for Brain Computer Interface
Yuanzi Liu, Yan Wu, Zhaohua Lu, Qi Li*
School of Computer Science and Technology, Changchun University of Science and Technology, Changchun Jilin

Received: Jan. 15th, 2019; accepted: Jan. 25th, 2019; published: Feb. 1st, 2019

ABSTRACT
In order to improve the classification accuracy of EEG signals, a method based on sample capacity amplification was proposed in this research of brain-computer interface technology. This method doubled all the electrode data value in one session of EEG data and then trained them as samples together with the original data, and this method not only increased the sample capacity, but also further improved the convergence speed of the train and the reliability of the test. After amplifying the public sample capacity, the new data and the original data were trained and tested by Bayesian Linear Discriminant Analysis method under the paradigm of row and column flash of brain-computer interface, then data were projected on a straight line in two categories of data. The results showed that the projected points of each kind of new data after projection were closer than the original public data, the center points of the two categories were larger and also the classification effect was better than the original public sample data and the average accuracy has been significantly improved compared with the average accuracy of the original public data. These results reflected that this amplification method of training sample set for brain computer interface can significantly improve the classification accuracy of EEG signals. An example was given to verify the validity of the proposed sample amplification method, which provided a feasible solution to the problem of insufficient sample capacity.
Keywords:Brain-Computer Interface, Sample Capacity, Bayesian Linear Discriminant Analysis
用于脑机接口的训练样本集扩增方法
刘圆子,武岩,卢朝华,李奇*
长春理工大学计算机科学技术学院,吉林 长春

收稿日期:2019年1月15日;录用日期:2019年1月25日;发布日期:2019年2月1日

摘 要
在脑机接口技术研究中,为有效提高脑电信号分类正确率,提出了一种样本容量扩增方法。该方法将一组脑电数据的所有电极数据值增加一倍,然后与原始数据一起作为样本数据进行训练,这种方法不但增加了样本容量,而且进一步提高了训练的收敛速度及测试结果的可靠性。用贝叶斯线性判别法对脑机接口行列闪范式下公共数据扩增前后的样本进行训练和测试,在两种类别的数据中将数据在直线上进行投影。经研究发现投影后每一种样本扩增数据的投影点比原始数据的投影点更接近,两种类别的数据的类别中心点也更大,分类效果更好,平均正确率相比原始公共数据平均正确率有了显著性的提高。研究表明这种用于脑机接口的训练样本集扩增方法能显著提高脑电信号分类正确率。通过实例验证了所提出的样本扩增方法的有效性,为样本容量不足提供了可行的解决方法。
关键词 :脑机接口,样本容量,贝叶斯线性判别法

Copyright © 2019 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
科技进步给人们的日常生活带来了巨大的变化,不但方便了健康人群,同时也提高了残疾病患的生活质量。例如一些头脑健全但由于多种疾病引起的肢体瘫痪患者,他们无法与外界正常交流 [1] ,于是在过去几十年中,国内外众多研究者相继开始了脑机接口(brain-computer interface, BCI)技术的研究。与任何通信与控制系统一样BCI系统是由输入,输出及前者转换为后者的翻译算法几部分构成的一种全新人机交互方法 [2] ,而通用的BCI系统模型通常由数据采集和数据预处理(输入部分)、特征提取和分类识别(翻译算法)、控制接口及外围设备(输出部分)构成 [3] 。BCI系统通过实时提取反映大脑不同状态的脑电信号来实现控制,本文用到的目标脑电信号是性能较好的P300事件相关电位。BCI通过采集患者大脑皮层的脑电信号(electroencephalogram, EEG)输入计算机经过一系列预处理、特征提取和分类识别将其转化为可被外界设备识别的操作指令来确定患者的意图 [4] 。在这个过程中,对患者目标脑电信号P300的分类识别至关重要,但是通常采集到的患者脑电数据有限使得样本容量较小同时造成了P300分类正确率较低的问题 [5] 。针对此问题,本文列出了一种样本容量扩增方法,通过增加脑电信号中各电极的数据值形成新的一组数据与原始数据一起作为样本用Hoffmann等人 [6] 提出的贝叶斯线性判别方法(Bayesian Linear Discriminant Analysis, BLDA)进行训练和测试以达到提高分类正确率的目的。BLDA是一种有监督的线性分类器 [7] ,此方法的计算原理简单、稳健性较好并且具有良好的泛化能力,并且它还能解决噪声引起的过拟合问题 [8] ,因此本文我们用它来解决脑电信号的分类问题。脑电信号分类正确率的提高,不但对于实时在线脑电信号分类具有推动意义,而且使BCI系统对于肢体瘫痪患者对外界设备控制意图有一个更精确的识别,使得患者更有效的对外围设备进行操作和控制,进一步提高了残疾病患的生活质量方便了他们的日常生活。
2. 方法
2.1. 实验一
2.1.1. 行列闪范式
行列闪范式也被称为P300范式,它是由Farwell和Donchin于1988年提出的包含6 × 6字符矩阵的刺激范式 [9] ,范式中包括10个数字字符(0~9)和26个英文字母字符(A~Z),范式背景为黑色,如图1所示。实验中所有字符按行和列随机高亮由灰色变为白色,当包含目标字符的行列高亮时,称之为靶刺激且其出现概率为1/6;其他不包含目标字符的行列高亮时称之为非靶刺激且其出现概率为5/6。P300电位信号的识别能够使得目标字符得以正常输出。实验过程中,被试注视目标字符并默记目标字符高亮的次数,小概率的靶刺激会诱发出P300电位但是非靶刺激不会,实验通过采集被试的脑电信号进行分类识别,检测出诱发P300电位的行和列确定目标字符的坐标即可唯一确定目标字符。

Figure 1. The paradigm of row and column flash
图1. 行列闪范式
2.1.2. 样本容量扩增
本文中我们使用BCI Competition III中在行列闪范式下用BCI 2000采集的Data set II数据,其行列闪频率为5.7 Hz且每个目标字符重复15次,首先对采集的波形信号采样,在64个电极上使用240 Hz的采样频率,通过0.1 Hz至60 Hz的带通滤波器 [10] ,滤出最为相关的脑电信号。Data set II中包括IIIA和IIIB两个被试的公共数据,将IIIA和IIIB的64个电极上matlab数据值都增加一倍,其中Pz电极上的P300和非P300数据在前八个采样点的数据变化如表1所示。
所有数据值增加一倍后形成新的一组实验数据,与原始数据合在一起作为训练数据进行训练,扩增数目变化如表2所示。样本数据发生变化后,其生成的64个电极上的脑电信号波形也产生了对应的变化,其中Pz电极上样本数据增加前后P300和非P300的波形对比如图2所示。

Table 1. The comparison of data changes in the first ten sampling points on the Pz electrode
表1. 在Pz电极上前八个采样点的数据变化对比
Table 2. The comparison of the number of samples before and after amplification
表2. 每个被试样本扩增前后数目变化对比
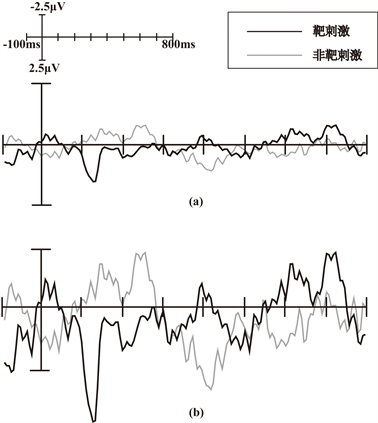
Figure 2. The comparison of target and non target stimulus waveform in Pz electrode before and after the sample data changed. (a) T he comparison of target and non target stimulus waveform before the sample data changed; (b) The comparison of target and non target stimulus waveform after the sample data changed
图2. Pz电极上靶刺激与非靶刺激数据值变化前后波形对比图。(a) 靶刺激与非靶刺激数据值变化前波形图;(b) 靶刺激与非靶刺激数据值变化后波形图
2.2. 实验二
2.2.1. 单闪实验范式
实验二作为验证实验,实验中我们不再使用行列闪范式而改为单闪范式,每个字符单独的随机进行闪烁,这样靶刺激出现的概率就会大幅度降低且目标字符闪烁时间间隔也会大幅度增加,这样就避免了传统行列闪范式中存在的“双闪”(同一个目标字符的行或列在短时间间隔内两次闪烁)问题,实验所用单闪范式如图3所示。
2.2.2. 样本容量扩增
我们在实验中采集了9名被试的脑电信号数据,经过预处理后保存为matlab格式。用本文提出的样本扩增方法进行样本扩增后样本数目变化如表3所示。样本数据发生变化后,其生成的各个电极上的脑电信号波形也产生了对应的变化,其中Pz电极上样本数据增加前后P300和非P300的波形对比如图4所示。

Figure 3. The paradigm of single flash
图3. 单闪范式
Table 3. The comparison of the number of samples before and after amplification
表3. 每个被试样本扩增前后数目变化对比
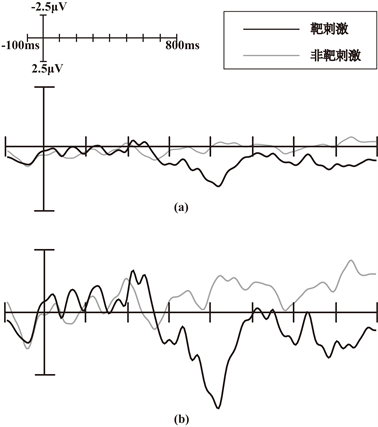
Figure 4. The comparison of target and non target stimulus waveform in Pz electrode before and after the sample data changed. (a) The comparison of target and non target stimulus waveform before the sample data changed; (b) The comparison of target and non target stimulus waveform after the sample data changed
图4. Pz电极上靶刺激与非靶刺激数据值变化前后波形对比图。(a) 靶刺激与非靶刺激数据值变化前波形图;(b) 靶刺激与非靶刺激数据值变化后波形图
3. BLDA分类
3.1. BLDA分类算法
贝叶斯线性判别(BLDA)算法是基于最小二乘法及贝叶斯线性回归方法的一种结合。BLDA主要是对需要分类的脑电数据投影方向作出假设,然后通过训练数据样本给出后验概率模型,得出的后验概率模型的均值向量即为求得的最优投影方向,以此实现脑电数据的分类。
3.1.1. 线性最小二乘回归
在线性回归方法中给定一个目标集 ,输入集为 ,输入的每一个向量为xi,其中 ,然后寻找一个权重向量ω使得输入向量xi与输出值相匹配,因此为使得目标值和实际输出值间的误差达到最小,使用最小二乘法进行计算,公式如下:
(1)
然后J(ω)对ω求取导数如下:
(2)
其中 , ,为避免回归过程中的过拟合问题需要加入一个正则化项,如下:
(3)
上式(3)又被称为岭回归准则函数,式子中 是单位矩阵,λ表示由交叉验证得到的正则化参数,由此可得ω权重向量为:
(4)
此时对于一个输入向量xi即可得到相对应的目标值,如下:
(5)
3.1.2. BLDA分类算法
脑电信号样本中无关信号(例如肌电信号、眼动信号等)的存在会干扰BLDA分类效果,假设这部分无关信号为n,目标集 与输入集 呈线性相关,假设一个高斯分布如下式(6):
(6)
在这个假设的基础之上,根据最小二乘法岭回归目标函数,来作为脑电信号集合概率分布指数,可得:
(7)
上式(7)中a是一个常数,J函数是最小二乘法岭回归准则函数。因此可把对于ω权重的分布分为误差和正则化项的乘积,如下:
(8)
在回归目标、输入向量及高斯噪声相关曲线的假设条件下,上式(8)中第一项可转换为ω似然函数,如下:
(9)
其中β是噪声的逆,在一定程度上视为一个常量。为增加分类模型泛化能力,因此添加偏置项,即ω的最后一项。为进一步运用贝叶斯理论,需对ω权重指定先验分布,如下:
(10)
上式(10)中 是 的对角矩阵,t是脑电信号特征向量的维度,ε设定为一个极其小的值,不用作任何假设分布。根据似然函数及先验分布,可以由贝叶斯计算出后验分布,如下:
(11)
后验分布也为高斯分布其均值m和方差b均满足以下条件:
(12)
由以上式子可计算出预测分布,有:
(13)
预测分布同样为高斯分布,其均值、方差满足以下式子(14):
(14)
由后验分布的均值和方差计算α和β参数,如下:
(15)
式子(15)中cii是方差矩阵对角线上i行i列的元素,mi是均值向量中第i个元素。重复以上式子直到参数α及β收敛达到最大似然解求得m,以此达到分类的目的。
3.1.3. BLDA对P300信号的识别
进行BLDA分类前需要对实验采集的脑电数据进行降采样的特征提取操作,来提取出信号波形特征。截取信号数据中靶刺激出现前100毫秒到靶刺激出现后800毫秒的波形段,降低采样频率同时降低采样点数目,以提取到更加契合脑电信号的特征向量。由于采样的通道数为64,因此每行或列的特征向量大小均为78 × 64。然后把提取到的信号特征放进BLDA进行训练得出算法模型来进行脑电信号的测试分类。对于分类器的结果,P300信号输出值为1,非P300信号输出值为0,然后根据每个P300的行列标签对应到相应的目标字符并输出。
3.2. 实验一数据分类结果
为控制BCI用户需要产生不同的大脑活动模式,而这些模式将会被系统识别分类并且转换成外界设备可识别的操作命令。在现有的大多数BCI中这种模式的转换依赖于分类算法,即一种旨在自动估计特征向量表示的数据类型算法,本研究中使用的分类算法是贝叶斯线性判别分析法(BLDA) [11] 。对每次的均值进行叠加,叠加均值的最大值对应的目标即是BLDA算法得出的分类结果 [12] 。在分类特征向量时,我们采用打乱全部字符顺序的方法进行训练,然后将测试数据分类识别正确率叠加平均。另外,根据正确率叠加次数的不同会产生不同的正确率,实验中我们设置了15个序列(序号1到12各随机高亮一次为一个序列)的叠加,产生15组分类正确率。我们分别对BCI原始数据和样本扩增后数据进行训练和测试,正确率对比如图5所示,BLDA对两名被试的扩增数据的分类均比对原始数据分类正确率高。从BCI Competition III公共数据平均分类正确率来看,实验的分类正确率均随着叠加次数的增加而增加。两名被试平均在叠加13次时达到70%以上的分类正确率,而在训练样本容量扩增后,叠加11次时达到了70%以上的分类正确率。
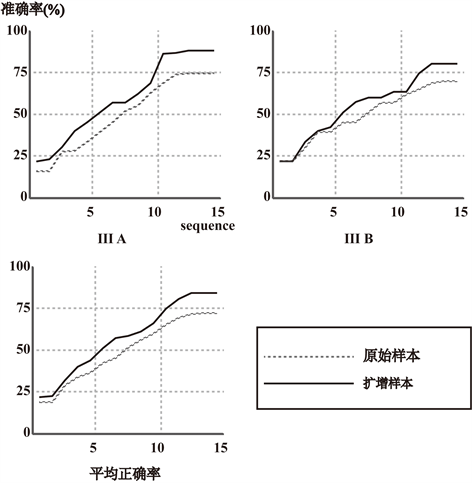
Figure 5. The comparison of BLDA classification accuracy between original sample and amplified sample
图5. BLDA对原始样本和扩增样本分类正确率对比
3.3. 实验二数据分类结果
用BLDA分别对原始实验数据和扩增样本数据进行训练和测试,每个被试数据产生15组分类正确率,其分类正确率对比如图6所示,BLDA对9名被试的扩增数据的分类均比对原始数据分类正确率高,实验二的实验结果验证了这种样本容量扩增方法的显著性效果。从验证实验数据平均分类正确率来看,实验的分类正确率均随着叠加次数的增加而增加。九名被试平均在叠加10次时达到80%以上的分类正确率,使用扩增后样本训练后能在叠加第6次时达到80%以上的分类正确率,并且在使用扩增样本训练后公共数据和验证数据分类叠加15次中每次叠加的平均正确率都高于原始数据的每次叠加结果,这充分展示了样本扩增方法的有效性。
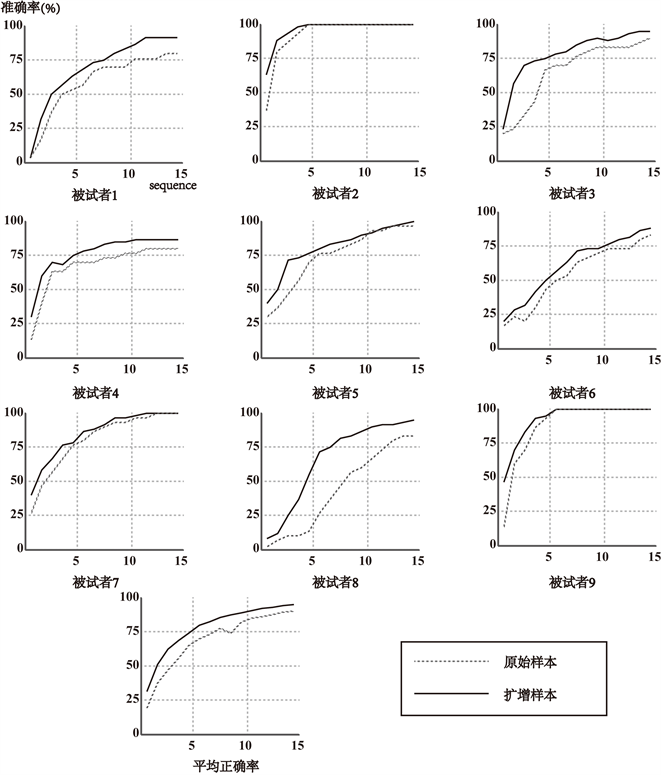
Figure 6. The comparison of BLDA classification accuracy between original sample and amplified sample
图6. BLDA对原始样本和扩增样本分类正确率对比
4. 讨论
根据两个实验的分类结果来看,样本扩增后的训练比原始数据的训练效果更好。从样本数据方面来说,增加原始数据的数据值一倍后的新数据与原始数据一起作为样本训练的时候数据平均值增加了一半,是原始数据平均值的1.5倍,同时训练得到的数据最大值和最小值也发生了变化,均是原始数据最值的1.5倍,如图7所示。其中a和c是用原始数据训练得到的靶刺激和非靶刺激数据最值在测试数据上对比情况,b和d是用扩增样本训练得到的靶刺激和非靶刺激数据最值在测试数据上对比情况。由图7可以看到,同一组测试数据在最值范围内的数据情况有很大的不同,使用扩增样本数据训练得到的最值间的采样点数据明显的多于用原始数据训练得到的最值间采样点数据,同时最值范围较大,落在范围内的样本点数据变多,使得靶刺激和非靶刺激的数据特征更加明显,有助于后续分类算法对靶刺激和非靶刺激的分类识别。
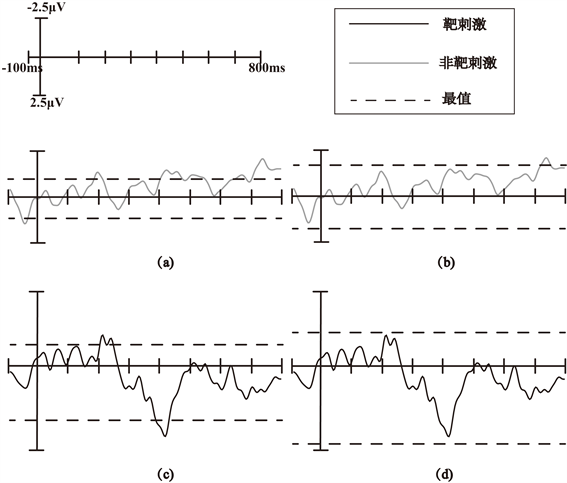
Figure 7. The comparison of the maximum values obtained before and after sample trained in Pz electrode on test data. (a) Representation of the maximum value obtained from training original samples on the test data of non-target stimulus; (b) Representation of the maximum value obtained from training amplified samples on the test data of non-target stimulus; (c) Representation of the maximum value obtained from training original samples on the test data of target stimulus; (d) Representation of the maximum value obtained from training amplified samples on the test data of target stimulus
图7. Pz电极上样本扩增前后训练得到的最值在测试数据上的表示对比图。(a) 训练原始样本得到的最值在非靶刺激测试数据上的表示;(b) 训练扩增样本得到的最值在非靶刺激测试数据上的表示;(c) 训练原始样本得到的最值在靶刺激数据上的表示;(d) 训练扩增样本得到的最值在靶刺激测试数据上的表示
BLDA是一种有监督的学习方法,也就是说它的数据集每个样本都有类别的输出。在两种类别的数据中BLDA将数据在直线上进行投影,投影后每一种数据的投影点尽可能的接近,而两种类别的数据的类别中心点尽可能的大才会使得分类效果较好。如图8所示,我们把目标样本和非目标样本用灰色和黑色表示,用BLDA将两种类别数据投影到一条直线上。从直观上可以看出,右图比左图的投影效果要好,因为右图的黑色和灰色数据较为集中,且两种类别之间的距离也更明显。从BLDA原理来看,假设我们的数据集 ,其中任意样本xi为第i个数据。我们定义 是第j类样本的集合, 是第j类样本的个数,而 是第j类样本的协方差矩阵, 是第j类样本的均值,J(w)是BLDA投影到直线w后的损失函数。
μj的表达式为:
(16)
∑j的表达式为:
(17)
J(w)的表达式为:
(18)
我们实验中所用到的是两类数据,一类是目标数据,另一类是非目标数据,因此我们需要将两类数据投影到一条直线即可。假设投影的直线是向量w,则对每一个样本xi在直线w上的投影为wTxi,我们把目标样本和非目标样本两种类别的中心点设为μ0和μ1,它们在直线w上的投影分别为wTμ0和wTμ1。从图8中可以看出,样本扩增后样本容量变大,数据平均值变大,由公式(16)可知样本均值向量μj值变大,两个类别数据的中心点μ0和μ1间距同时变大,这样使得两种类别的中心间距变大。样本数据均值变大,由公式(17)可知,协方差矩阵中的每个协方差数据值变小,说明同一类别数据的投影点更加接近。此时公式(18)中分母上每一个类别的方差之和变小,分子上两个类别各自的中心点间距的平方变大,相当于最大化了J(w),因此即可求出比原始数据更优的w。这种效果体现在分类正确率上就是BLDA对扩增后的样本训练和测试所得平均正确率均高于对原始数据的训练和测试正确率。
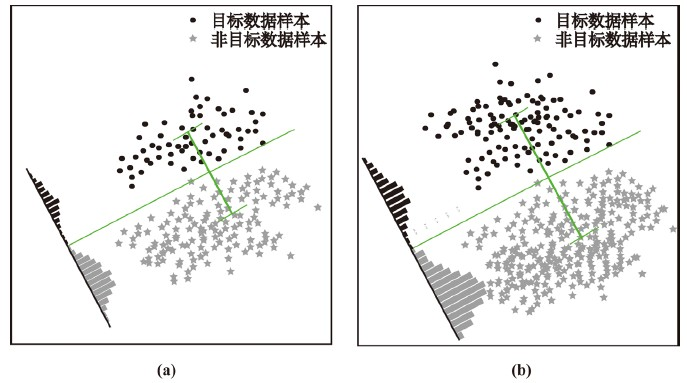
Figure 8. The comparison of BLDA projection results of sample points before and after amplified in straight line. (a) BLDA projection results of original sample points in straight line; (b) BLDA projection results of amplified sample points in straight line
图8. BLDA对扩增前后样本点在直线上的投影结果对比图。(a) BLDA对原始样本点在直线上的投影结果图;(b) BLDA对扩增样本点在直线上的投影结果图
5. 结束语
本文所提出的基于脑机接口技术的样本容量扩增方法,利用增加样本数据值后的新数据与原始数据一起作为训练数据,增加了样本数据的最值、均值,降低了样本数据点的离散程度,使得损失函数达到最大化,得出更优的BLDA投影直线,对测试数据分类时提高了平均分类正确率。把这种方法应用在实时分类上会使得BCI系统对于肢体瘫痪患者对外界设备控制意图有一个更精确的识别,同时让患者能够更有效的对外围设备进行操作和控制。在脑机接口技术方面,现有的分类算法准确率还是较低,不能达到实时准确分类的效果,所以在投入到实际应用中还是有一定的困难。因此未来可以从分类算法方面着手,寻求训练模型更加稳定、分类性能更好、准确率更高的脑电信号分类算法。
基金项目
国家自然科学基金(61806025);吉林省教育厅“十三五”科学技术项目(JJKH20190597KJ)。
文章引用
刘圆子,武 岩,卢朝华,李 奇. 用于脑机接口的训练样本集扩增方法
Amplification Method of Training Sample Set for Brain Computer Interface[J]. 计算机科学与应用, 2019, 09(02): 227-238. https://doi.org/10.12677/CSA.2019.92027
参考文献
- 1. Hoffmann, U., Fimbel, E.J. and Keller, T. (2009) Brain-Computer Interface Based on High Frequency Steady-State Visual Evoked Potentials: A Feasibility Study. International IEEE/EMBS Conference on Neural Engineering, Antalya, 29 April-2 May 2009, 466-469. https://doi.org/10.1109/NER.2009.5109334
- 2. Farwell, L.A. and Donchin, E. (1988) Talking Off the Top of Your Head: To-ward a Mental Prosthesis Utilizing Event-Related Brain Potentials. Electroencephalography & Clinical Neurophysiology, 70, 510. https://doi.org/10.1016/0013-4694(88)90149-6
- 3. BCI Competition III Data. http://www.bbci.de/competition/iii/
- 4. Mahanta, M.S., Aghaei, A.S. and Plataniotis, K.N. (2012) A Bayes Optimal Matrix-Variate LDA for Extraction of Spatio-Spectral Features from EEG Signals. International Conference of the IEEE Engineering in Medicine and Biology Society, 2012, 3955-3958. https://doi.org/10.1109/EMBC.2012.6346832
- 5. Hoffmann, U., Vesin, J.-M., Diserens, K. and Ebrahimi, T. (2007) An Effi-cient P300-Based Brain-Computer Interface for Disabled Subjects. Journal of Neuroscience Methods, 167, 115-125. https://doi.org/10.1016/j.jneumeth.2007.03.005
- 6. Birbaumer, N., Ghanayim, N., Hinterberger, T., et al. (1999) A Spelling Device for the Paralysed. Nature, 398, 297-298. https://doi.org/10.1038/18581
- 7. Li, M., Zhang, M. and Sun, Y.J. (2016) A Novel Motor Imagery EEG Recognition Method Based on Deep Learning. International Forum on Management, Education and Information Technology Application, 30 January 2016, 728-733. https://doi.org/10.2991/ifmeita-16.2016.133
- 8. Mason, S.G. and Birch, G.E. (2003) A General Framework for Brain-Computer Interface Design. IEEE Transactions on Neural Systems & Rehabilitation Engineering, 11, 70-85. https://doi.org/10.1109/TNSRE.2003.810426
- 9. 高楠, 卓晴, 王文渊. 一种新型的人机交互方式——脑机接口[J]. 计算机工程, 2005, 31(18): 1-3.
- 10. 董贤光. 基于卷积神经网络的脑电信号检测与脑机接口实现[D]: [硕士学位论文]. 济南: 山东大学, 2016.
- 11. Hoffmann, U., Garcia, G., Vesin, J.M., et al. (2005) A Boosting Approach to P300 Detection with Application to Brain-Computer Interfaces. 2nd International IEEE EMBS Conference on Neural Engineering, Arlington, 16-19 March 2005, 97-100. https://doi.org/10.1109/CNE.2005.1419562
- 12. Garrett, D., Peterson, D.A. and Anderson, C.W. (2003) Comparison of Linear, Nonlinear and Feature Selection Methods for EEG Signal Classification. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 11, 141-144. https://doi.org/10.1109/TNSRE.2003.814441