Statistics and Application
Vol.
09
No.
01
(
2020
), Article ID:
34065
,
10
pages
10.12677/SA.2020.91008
Confidence Interval Construction of Risk Ratio of Chronic Diseases Based on Gradient Statistics under Poisson Distribution
Haimiao Meng1, Huiying Jia2, Zhen Yan1*
1College of Mathematics and Statistics, Guangxi Normal University, Guilin Guangxi
2Department of Education, Guilin Normal College, Guilin Guangxi

Received: Dec. 31st, 2019; accepted: Jan. 14th, 2020; published: Jan. 21st, 2020

ABSTRACT
Combining the advantages of Poisson sampling and the characteristics of long occurrence period and low incidence of chronic diseases, the confidence interval of risk ratio under Poisson distribution is constructed by using gradient statistics. The advantage of this method is that it does not need to calculate Fisher information matrix and its inverse matrix, which greatly simplifies the calculation process compared with the score statistics method. At the same time, an example and Monte Carlo simulation are used. Compared with the traditional confidence interval construction method, the results show that the method based on gradient statistics can obtain better coverage probability and shorter interval length.
Keywords:Poisson Distribution, Gradient Statistics, Risk Ratio, Monte Carlo Simulation

Poisson分布下基于梯度统计量的慢性病风险比的置信区间构造
蒙海苗1,贾慧英2,晏振1*
1广西师范大学数学与统计学院,广西 桂林
2桂林师范高等专科学校教育系,广西 桂林

收稿日期:2019年12月31日;录用日期:2020年1月14日;发布日期:2020年1月21日

摘 要
结合Poisson抽样的优点以及慢性病发病周期长和发病率低的特点,利用梯度统计量的方法来构造Poisson分布下风险比的置信区间。该方法的优点在于不需要计算Fisher信息矩阵及其逆矩阵,与得分统计量方法相比,这大大简化了计算过程。同时,通过实例和蒙特卡洛模拟,与传统的置信区间构造方法进行比较。结果表明,基于梯度统计量的构建方法可以得到较好的覆盖概率和较短的区间长度。
关键词 :Poisson分布,梯度统计量,风险比,蒙特卡洛模拟

Copyright © 2020 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
在一些罕见疾病的研究过程中,往往需要用很长的一段时间来对研究对象进行跟进,由于在长期的跟进过程中有些研究对象可能会退出研究,从而导致在跟进过程中,研究对象的数量会时常发生变化。Poisson分布是一种常用的离散分布,它常常与单位时间上的计数过程相联系,用来描述单位时间内事件发生特定次数的概率。因此,根据Poisson分布的优点可以较好地解决上述问题。
在流行病学中,风险比指的是暴露组的发病率与非暴露组的发病率的比值。在一定的显著水平上,当风险比小于1时,说明某药物或处理对疾病治疗有效;当风险比与1无显著差异时,说明该药物或处理对疾病治疗无影响;当风险比大于1时,说明该药物或处理可能会对人体产生副作用,会导致其他疾病的产生,进而需要更进一步研究探讨。
在流行病学的研究中,对风险比的研究很普遍,Liu [1] 给出了基于Fieller定理的方法和基于F检验统计量的方法。Liu [2] 给出了Dalta方法,该方法运用泰勒展开原理,使得在已知单个随机变量的分布条件下,能够逼近随机变量函数的均值和方差。Tang [3] 等人给出了基于得分统计量的方法、基于似然比统计量的方法,对于小样本量时,用鞍点逼近的方法等。由于鞍点逼近的方法能够在保证区间覆盖率的前提下使得区间长度在所有的方法中是最短的。同时,得分统计量的方法也可以在覆盖率和区间长度之间取得很好的平衡。对于上述提出的几种方法,在计算过程中较为繁琐,例如,得分统计量方法需要计算Fisher信息矩阵及其逆矩阵,因此,对于参数检验问题,Terrell [4] 提出了一种新的检验统计量,这一新的梯度统计量可视之为WALD以及得分统计量的一种巧妙结合,明显优于WALD以及得分统计量,不需要计算Fisher信息矩阵及其逆矩阵。Lemonte [5] 等人认为梯度统计量、似然比统计量以及得分检验统计量在一阶渐近意义下是等价的,同时没有哪个统计量在二阶局部功效方面更优。此外,牛翠珍和范国良 [6] 基于梯度统计量得出负二项抽样下风险差的近似区间估计。
大多数的风险比置信区间的构造方法都是基于二项抽样和负二项抽样下的,相对而言,有关于Poisson分布和风险比研究的文献较少。白永昕和田茂再 [7] [8] 研究了基于Poisson抽样下慢性病发病率的置信区间的构造,Poisson分布下基于鞍点逼近的慢性病风险差的置信区间的构造。因此,本文利用梯度统计量的优点,研究基于梯度统计量的Poisson分布下风险比的置信区间的构造,并通过例子和模特卡洛模拟,将基于梯度统计量的方法与对数转换方法、得分统计量的方法以及似然比统计量方法进行比较。
2. 风险比置信区间的已有方法
假设 分别表示暴露组和非暴露组,对第i组中 个研究对象跟进并得到 例发病数。假设 服从参数为 的Poisson分布,其中 表示单位时间内的平均跟进对象, 和 ( )分别表示暴露组和非暴露组的发病率,从而随机变量 的分布函数为:
本文考虑暴露组和非暴露组发病率的比,即风险比 。从而关于风险比R和 的似然函数为
(2.1)
则对(2.1)的似然函数极大化,得到似然估计分别为
2.1. 对数转换方法
对数转换方法在一定程度上是Delta方法的改进。若用Delta方法估计风险比估计量 的渐近分布,只有在大样本量时 的分布才能非常接近正态分布 [9],Kata等人提出的对数变换方法 [10],认为在样本
量较小的情况下,变量 会更加接近正态分布,再对 运用Delta方法可以计算其均值为 ,方差为 ,从而得到
因此,得到对数转换方法下风险比R在渐近正态分布下的一个水平为 的渐近置信区间为
其中 , 是标准正态分布 分位点。
2.2. 得分检验方法
在大样本的情况下,得分统计量为
其中, 是得分函数, 是Fisher信息矩阵。在本文中,得分函数为
Fisher信息矩阵为
令原假设下 的限制极大似然估计为 ,求解以下方程就可以得到 :
解得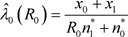 。
。
基于假设检验和置信区间的对偶关系,考虑如下假设检验问题:
对
则关于R和 的得分统计量渐近的服从自由度为1的卡方分布,即
因此,R的 的置信区间为
2.3. 似然比检验方法
与得分方法类似,似然比检验是一种构造参数检验的方法,基于假设检验和置信区间的对偶关系,在假设检验问题:
对
下,有似然比统计量为
考虑如下假设检验问题:
对
则有
其中
是
的限制极大似然估计。因此,R的一个置信水平为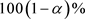 的置信区间为
的置信区间为
3. 基于梯度统计量的风险比的置信区间的构造
得分统计量方法,似然比统计量方法的计算过程比较复杂,特别是得分方法中需要计算Fisher信息矩阵及其逆矩阵,而本文提出的梯度统计量方法计算相对简便,不需计算Fisher信息矩阵及其逆矩阵。基于上述传统的构造置信区间的方法,下面对梯度统计量方法做具体阐述。基于假设检验和置信区间的对偶关系,在假设检验问题: ,引入梯度统计量方法。
Lemote [6] 等人论述的梯度统计量具有以下形式:
由上述式子可以知道,梯度统计量具有简单的表达形式,而且不涉及Fisher
信息矩阵及其逆矩阵。根据上述给出的 的定义可知得分函数为:
进而可以构造一个更加简单形式的梯度统计量为:
其中, ,。
根据上述的论述,可以构造出R的一个水平为 的置信区间为
4. 蒙特卡罗模拟
对于上述描述的四种置信区间方法,本文运用蒙特卡罗模拟从区间长度和覆盖率这两个方面来评价这四种方法构建的置信区间的表现。对于覆盖率,越接近于预先设定的水平,说明该方法越好;置信区间长度则通过平均区间长度来衡量,在覆盖率能控制的情况下,区间宽度越短越好。
设定样本量 ;非暴露组的发病率为 ;风险比的真值为 ;置信水平为 ;每种情形重复试验10,000次。如下表1到表5分别表示 ,置信水平为 下的模拟结果,表格中的数分别表示覆盖率和置信区间长度(括号中的数)。其中,用“FT”表示对数转换方法,“SC”得分检验方法,“LR”表示似然比检验方法,“GB”表示基于梯度统计量的方法。
从蒙特卡罗模拟的结果来看(见表1~5),当n较小 时, 从0.1增大到0.5的过程中,得分检验方法和梯度方法的区间长度与其他两种方法相比较短,覆盖率也越来越接近预先设定的置信水平,其中得分方法比梯度方法的表现稍好一些。对数转换方法和似然比方法,虽然得到较好的覆盖率,但在小样本量的情况下,这两种方法得到的区间长度相对较宽。当n较大时,这四种方法的区间长度都比小样本时短。此外,这四种方法的区间长度都随非暴露组的发病率的增大而减小。
当非暴露组的发病率一定时,随着样本量的增大,这四种方法的区间长度都逐渐减少,覆盖率也越来越好,这点在得分方法和梯度方法变现较为明显。
总之,似然比方法的覆盖率都非常接近预先设定的显著水平95%,梯度方法一般比预先设定的水平小。对数转换方法的覆盖率较好,但其区间长度很宽;似然比方法、得分方法、梯度方法的表现都不错,但似然比方法的区间长度不及得分方法和梯度方法的好,得分方法的覆盖率比梯度方法的稍好,从而在这四种方法中,得分方法的表现最佳。此外,如果考虑到计算过程的问题,梯度方法不需要计算Fisher信息阵及其逆矩阵,比得分方法的计算简便很多,因此,若是综合覆盖率,区间宽度以及计算过程,本文提出的梯度方法也有较好的表现。

Table 1. Coverage probabilities and Interval width with R 0 = 0.1 and α = 0.05
表1. 在 , 的覆盖率和区间宽度
Table 2. Coverage probabilities and Interval width with R 0 = 0.5 and α = 0.05
表2. 在 , 的覆盖率和区间宽度
Table 3. Coverage probabilities and Interval width with R 0 = 1 and α = 0.05
表3. 在 , 下的覆盖率和区间宽度
Table 4. Coverage probabilities and Interval width with R 0 = 2 and α = 0.05
表4. 在 , 下的覆盖率和区间宽度
Table 5. Coverage probabilities and Interval width with R 0 = 3 and α = 0.05
表5. 在 , 下的覆盖率和区间宽度
5. 实例分析
根据美国心脏病学会的新标准,对患高血脂的成年人,服用他汀类药物治疗和服用安慰剂两种情况下与未来得冠心病风险之间的关系进行了研究。根据研究数据可知,在288名服用他汀类药物的患者中有101人患有冠心病,在289名服用安慰剂的患者中有23人患有冠心病。即
根据这些数据,运用文中提出的四种风险比的置信区间构造方法,得到风险比R的95%置信区间,具体如下表6 (数据来源于Ann Marie N B [11])。
Table 6. 95% confidence interval of risk ratio R of statins and placebo
表6. 他汀类药物和安慰剂风险比R的95%置信区间
从表6可以发现,这四种方法构造的置信区间的区间长度相差不大,没有明显的差异,其中得分方法的置信区间最短,本文所提出的梯度统计量方法的表现也较好,与得分方法相差不大。此外,这四种方法的置信上限和置信下限都大于1,说明在5%的水平使用他汀药物治疗会使冠心病患者的比例增加。
6. 结论
本文主要介绍了在Poisson抽样下基于梯度统计量的风险比的置信区间的构造方法,通过蒙特卡罗模拟与三种传统的估计方法进行比较。在这四种方法中,得分方法的表现最佳,但梯度统计量方法在覆盖率和区间宽度上,与其他方法无显著差异。此外,梯度方法不需要计算Fisher信息阵及其逆矩阵,综合考虑这四种的方法的计算过程,梯度统计量方法简便很多。因此,若是综合覆盖率,区间宽度以及计算过程,本文提出的梯度方法也有较好的表现。
基金项目
国家自然科学基金项目(11901124, 11701109, 11861017);广西自然科学基金项目 (2018GXNSFAA138164)。
广西研究生教育创新计划项目(XYCSZ2017076);广西师范大学重点科研项目(2016ZD002)。
文章引用
蒙海苗,贾慧英,晏 振. Poisson分布下基于梯度统计量的慢性病风险比的置信区间构造
Confidence Interval Construction of Risk Ratio of Chronic Diseases Based on Gradient Statistics under Poisson Distribution[J]. 统计学与应用, 2020, 09(01): 63-72. https://doi.org/10.12677/SA.2020.91008
参考文献
- 1. Lui, K.J. (1995) Confidence Intervals for the Risk Ratio in Cohort Studies under Inverse Sampling. Biometrical Journal, 8, 965-971. https://doi.org/10.1002/bimj.4710370808
- 2. Lui, K.J. (1986) Statistical Estimation of Epidemiological Risk. Wiley, New York.
- 3. Tian, M., Tang, M.L., Ng, H.K., et al. (2010) Confidence Intervals for the Risk Ratio under Inverse Sampling. Statistics in Medicine, 27, 3301-3324. https://doi.org/10.1002/sim.3158
- 4. Terrell, G.R. (2002) The Gradient Statistic. Computing Science and Statistics, 34, 206-215.
- 5. Lemonte, A.J. and Ferrari, S.L.P. (2012) The Local Power of the Gradient Test. Annals of the Institute of Statistical Mathematics, 64, 373-381. https://doi.org/10.1007/s10463-010-0315-4
- 6. 牛翠珍, 范国良. 基于梯度统计量的逆抽样下风险差的置信区间构建[J]. 统计与信息论坛, 2014(8): 9-13.
- 7. 白永昕, 田茂再. 慢性病发病率置信区间的构造[J]. 高校应用数学学报A辑, 2016, 31(2): 136-142.
- 8. 白永昕, 田茂再. Poisson分布下基于鞍点逼近的慢性病风险差的置信区间[J]. 高校应用数学学报, 2017, 32(3): 253-266.
- 9. 钱政超, 张晨阳, 孟令宾, 田茂再. 二项抽样下基于鞍点逼近方法的流行病相对风险置信区间构造[J]. 数学的实践与认识, 2014, 44(21): 204-217.
- 10. Katz, D., Baptista, J., Azen, S.P. and Pike, M.C. (1978) Obtaining Confidence Intervals for the Risk Ratio in Cohort Studies. Biometrics, 34, 469-474. https://doi.org/10.2307/2530610
- 11. Ann Marie, N.B., Peterson, E.D., D’Agostino, R.B., et al. (2015) Hyperlipidemia in Early Adulthood Increases Long-Term Risk of Coronary Heart Disease. South China Journal of Cardiology, 131, 64-64.
NOTES
*通讯作者。