Modeling and Simulation
Vol.
12
No.
02
(
2023
), Article ID:
63078
,
12
pages
10.12677/MOS.2023.122137
基于HDBSCAN聚类算法的实例推理与规则 提取
亓凯航,仲梁维
上海理工大学机械工程学院,上海
收稿日期:2023年2月14日;录用日期:2023年3月20日;发布日期:2023年3月27日

摘要
针对复杂装配对象具有结构复杂、开发周期长、装配成本高等特点导致的装配工艺编制较慢、效率低的问题,为实现装配工艺重用,在规则提取过程中,利用Apriori关联规则算法提取出满足约束参数的强关联规则,作为知识检索的条件与结论放入规则库中;在实例推理过程中,提出基于DBSCAN聚类算法快速定位与目标装配对象相似的子实例集,即与目标对象最相似的簇,缩小实例检索的范围以提高匹配的效率。结果表明,该方法使检索范围缩小了50倍,实例匹配速度明显加快。
关键词
Apriori,HDBSCAN,规则提取,实例推理

Case Reasoning and Rule Extraction Based on HDBSCAN Clustering Algorithm
Kaihang Qi, Liangwei Zhong
School of Mechanical Engineering, University of Shanghai for Science and Technology, Shanghai
Received: Feb. 14th, 2023; accepted: Mar. 20th, 2023; published: Mar. 27th, 2023

ABSTRACT
Due to the complex assembly object’s complex structure, long development cycle and high assembly cost, the assembly process is slow and the efficiency is low. In order to realize assembly process reuse, in the process of rule extraction, the Apriori association rule algorithm is used to extract the strong association rules meeting the constraint parameters and put into the rule base as the conditions and conclusions of knowledge retrieval. In the process of case reasoning, the DBSCAN clustering algorithm is proposed to quickly locate the sub-instance set similar to the target assembly object, that is, the cluster most similar to the target object, and narrow the scope of instance retrieval to improve the matching efficiency. The results show that the retrieval range is reduced by 50 times and the case matching speed is greatly accelerated.
Keywords:Apriori, HDBSCAN, Rule Extraction, Case Reasoning

Copyright © 2023 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
在工艺设计阶段,工程师往往在编写复杂装配体的工艺文件与设备工艺卡时会耗费大量的时间,通常会借鉴以往工艺文件中相似的工艺内容,查询以往成熟的工艺方法,以及检索相应的装配工艺知识。这样人工的编写方式都会降低工艺工程师的工作效率,使得新产品的设计成本增高。而工艺重用可以通过在设计过程中调用以往的成熟工艺知识,在此基础上进行创新,以提高工程师设计效率。
装配工艺知识主要来自于企业制定的工艺标准、行业内部的规范以及相关专家的设计经验等等。大量的装配实例,都存储在企业的CAPP系统之中 [1],其中不仅含有规范化的工艺知识,而且还是广大工程师智慧与经验的结晶。但是这些实例并不是有序的规则,也不是结构化的信息,许多有价值的信息也隐匿在其中,设计人员在对这些知识的利用上有着较大的困难。
在对于型号多样的同类产品而言,装配件的结构大多相似。对这类产品进行装配工艺知识的重用 [2],可以避免许多无效的劳动,提高工程师的设计效率,使工程师把更多的精力花在对新装配件的工艺设计之上。实例推理技术可以借助装配对象内部的信息,使用相似度检索方法将与目标装配对象相似的装配对象实例匹配出来,复用相似对象的工艺知识,达到辅助工艺人员有效地进行产品工艺设计工作的作用。
2. Apriori算法基本原理
关联规则挖掘通常是指挖掘两个对象之间的关联信息,采用统计学习的方法来从大量数据之中提取出频繁项集,作为专家经验来二次利用。关联规则的基本概念主要有以下几个:
项集:指的是由多个元素组成的一个集合,其中元素之间应当是一个独立的个体,k个元素组成的项集即为k阶项集,k项集如式(1) [3] :
(1)
对象:包含同一个事务内,任意一个对象中可能包含一个或多个元素,对象之间互不相交,A对象,B对象的关系如式(2):
(2)
事务集:在关联规则中,每个项集都有其从属于的事务,而特定的事务一起组成了事务集,包含n个事务的事务集表示如式(3):
(3)
支持度:指的是某一项集的事务个数在事务集中所占的比例,如式(4):
(4)
置信度:指的是同时包含项集 和 这两个对象的事务个数在只包含 的事务个数中所占的比例,如式(5):
(5)
提升度:指的是项集和的置信度和的支持度之比,如式(6):
(6)
Agrawal提出了关联规则算法中最为经典的算法Apriori算法,该算法的核心思想为所有频繁项集的非空子集必定是频繁项集,所有非频繁项集的超集必定是非频繁项集 [4]。Apriori算法主要有四大步骤:
1) 确定最大项集阶数k,最小支持度min_support,最小置信度min_confidence,最小提升度min_lift。
2) 从1到k地逐层遍历,获取高于最小支持度的频繁项集并利用先验性质进行剪枝。
3) 从每一个频繁项集中提取出高于最小置信度的两个对象,分别作为条件对象和结果对象,形成关联规则。
4) 利用最小提升度来验证关联规则是否有效,若高于最小提升度,则判定为有效强关联规则。
其中,计算成本最大的是第二步频繁项集的获取,Apriori算法主要流程如图1所示。
首先对一阶候选项集进行计数,获取所有的一阶候选项集,之后判断并统计所有大于最小支持度的项集作为频繁项集。对于K阶候选项集的提出,主要是利用Apriori-Gen运算实现,其中包含了连接步和剪枝步,连接所有频繁项集生成K阶项集,然后利用先验定理排除含有K ‒ 1阶非频繁项集的K阶项集 [5]。之后判断并统计所有大于最小支持度的候选项集作为K阶频繁项集。
3. 装配工艺规则提取
3.1. 工艺规则库设计
规则库的结构不需要太复杂,主要按照条件表达式的结构,即“IF……THEN”的模式来构造,设计者只需按照输入条件进行模糊查询,系统会自动输出相关结论并给出相应概率,设计者就可以通过这种方式有选择地参考,从而优化新实例的装配工艺文件。这里选择关联规则算法Apriori是因为算法输出的是规则前项和规则后项,对应的就是规则库中的条件和结果,这也满足了人机交互问答系统的基本功能。
3.2. 具体方案设计与应用
由于提取的装配工艺信息主要是由工艺信息库,相关零件库与装配辅材库构成,由于字符串表示的信息很多,如果想要构建事务集则必须要对字符串进行分词处理,会出现信息冗余的情况,通过这种方法利用Apriori关联规则算法会提取出许多无用的规则项集,这不利于工艺知识的检索,因此,需要对工艺指令通过相关零件库与装配辅材库的帮助进行拆分。根据装配工艺信息的自身特点,可以将工艺指令拆分成五大部分,装配信息事务集 [6] 如下所示:
(7)
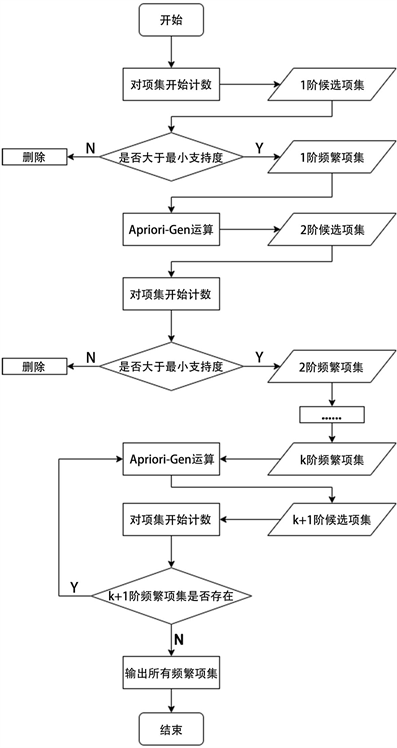
Figure 1. Flow chart of frequent item set fetching
图1. 频繁项集获取的流程图
对于工艺事务集 ,集合 代表了装配的基准集合, 为相关组件的集合, 为相关装配辅材的集合, 为工艺方法的类型, 为装配工艺指令对应的装配动作。对于对应工艺指令的各部分信息获取,主要提取流程如图2所示。
对于装配工艺信息库中的每一条装配工艺指令而言,其内部都蕴含着许多有价值的信息,因此需要使用不同的技术来提取每一条工艺指令中的不同类型的知识,将其组成一个完整的工艺事务集。其中,对于相关组件的提取,主要是通过相关部件库中组件信息与工艺指令中的组件名进行匹配得出。同样的,工具辅材库与工艺指令的辅材名称进行匹配,得出所需要的装配工具辅材信息。对于工艺方法的分类,这里使用一种分级加权的词袋模型构建方法 [7],结合K-means聚类方法获取。关于装配动作与装配基准做,则是通过和事先构建的词典进行匹配,若无法匹配得到,则取空值。
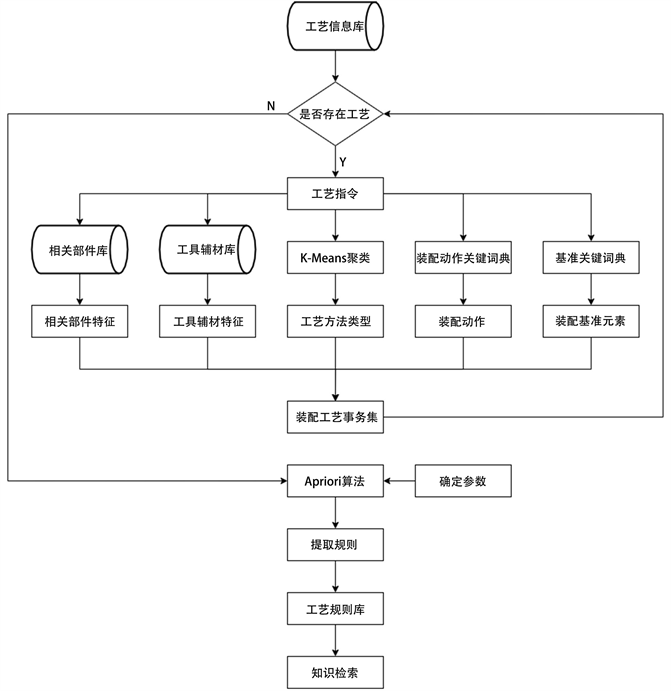
Figure 2. Flow chart of assembly process transaction set information acquisition
图2. 装配工艺事务集信息的获取流程图
简单处理导轨和卫星部分模块装配工艺事务集,作为Apriori关联规则算法的输入,设置最小支持度为0.04,最小置信度为1,最小提升度为2,同时筛选出规则后项为一个元素的规则,可以得到的如下所示的部分规则如表1所示。
支持度越高,证明关联元素在工艺信息库中的出现的频率越高,提升度越高,则证明规则前项与规则后项之间的关联性越大,置信度设置为1,因此在规则前项确定的时候,结果是必定会出现的,通过与规则前项输出类似的条件来查询结果,从而实现对工艺知识的检索,通过已有知识来优化工艺文件。
4. 基于HDBSCAN聚类算法的实例推理
4.1. HDBSCAN算法基本原理
HDBSCAN是由Campello,Moulavi和Sander开发的聚类算法。它是通过将DBSCAN转换为分层聚类算法来扩展DBSCAN,然后基于聚类稳定性 [8],使用了提取平面聚类的技术。

Table 1. The extracted association rules and indexes of assembly process
表1. 提取的装配工艺关联规则和指标
传统的DBSCAN的密度可达距离是不可变的,而HDBSCAN可以处理密度不同的聚类问题,同时它使用了互相可达距离度量这一定义,大大提高了算法的鲁棒性,在生成最小树之后,采用分层聚类的方法聚合簇,在后期有利用压缩聚类树的方式来筛选离群值,这些过程都是通过算法自动处理,而人工只需要处理的参数是最小簇的样本个数,一般默认即可。因此在超参数的选择上即不需要指定簇的个数K,也不需要指定密度可达距离以及密度可达数,这使得程序不需要通过贪婪搜索的方法来确定最优参数,大大减少计算成本。
HDBSCAN的基本原理 [9] 包括了以下五个步骤:
1) 根据密度变换空间
通过将每个样本点作为核心点,两两构建核心距离,即相互可达距离来分散低密度点,这使得低密度点与高密度簇的距离更远,聚类算法对噪声的鲁棒性更强,点到点的相互可达距离定位为式(8):
(8)
其中 是指在与核心点a距离最近的第k个样本点的彼此距离, 指在与核心点b距离最近的第k个样本点的彼此距离, 指的是a和b的距离,利用这种度量方法,可以让密集点之间保持相同的距离,而稀疏点可以被推开至远离核心点的地方,使得密度高的样本更容易聚在一起,而簇之间分隔的更远,同时这也让单链路聚类更加贴合,如图3所示。
2) 生成最小树
两个点可以确定一条边,而相互可达距离就是空间内样本点的边,这里也被定义为任意两个顶点间的权重。设定最小簇的样本点个数k,利用Prim算法可以确定最小树,如图4所示。
3) 分层构建簇的层次结构
对于每个最小树,这里采用与最小距离分层聚类方法相同的策略,通过对权值递增排序,对于最近的最小树进行合并,不停地迭代这个过程,一直合并至权值最高为止,如图5所示。
利用分层聚类的思路,可以将这个簇的聚合过程清晰地展现出来,之后需要确定一条水平线来切割簇,而这水平线就相当于DBSCAN中用来分隔不同簇的密度可达距离eps,eps的值永远是固定不变的,而HDBSCAN的水平线却可以在不同的密度下进行分割来选择合适的簇,这就是HDBSCAN的强大之处。

Figure 3. Mutually accessible distance
图3. 相互可达距离
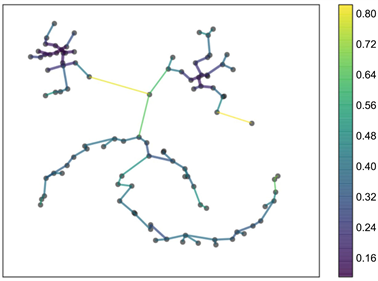
Figure 4. The minimum tree generated by Prim algorithm
图4. Prim算法生成最小树

Figure 5. The minimum tree generated by hierarchical clustering
图5. 分层聚类最小树
4) 压缩聚类树
利用水平线对上图所示的聚类集群进行拆分,这里又要确定最小簇大小k,遍历层次结构并在每次拆分时判断:是否存在拆分出来的新簇的大小会小于预先定义的k,如果存在,则将这些样本点标记为离群值点,这就是HDBSCAN的离群值处理方法。如果拆分的子集群不存在上述情况,则将该集群视为真正得集群进行拆分,遍历整个层次结构,可以得到如图6所示的树状图:

Figure 6. Hierarchical clustering minimum tree using plane segmentation clustering tree
图6. 利用平面切分聚类树
5) 提取簇
很多情况下集群应当具备更长的生命周期,而不是随着数据量的不断增加而被取代或是被合并,因此一般会选择一些面积较大的集群。在选择之前,会先考量簇的持久性,这里使用相互可达距离的倒数来度量,即 , 是当前集群拆分成功后并成为子集群的 值, 是指当集群拆分成较小的集群时的 值, 则是指该点被从集群中剔除时的 值。对于每一个集群,稳定性都可以定义为:
(9)
通过对树进行遍历,如果子集群的稳定性之和大于父集群,集群稳定性就等于其子集群稳定性之和,反之,则将集群以下的所有子类全部归并,不停迭代至根节点,当前选定的集群就是提取出来的平面簇,对于每个簇赋予其独一无二的标签,离群点则以标签-1表示。
以上就是HDBSCAN的工作原理,由于HDBSCAN也具有密度聚类的原理,因此数据集不变以及顺序不变的情况下,聚类得到的簇也不会发生改变,因此具有稳定性,对于数据集分布不均匀的装配实例库,最小簇大小也可以默认,不需要人为确定模型的任何参数,这可以大大节省技术人员的时间成本。
针对装配特征向量组成的数据集,各特征的数值分布并没有规则,其内部簇的密度也比较不均匀,使用HDBSCAN算法可以有效地解决簇密度不均和离群值问题,且在计算成本上由于不需要进行大量调参实验而变得较低。因此,这里选择HDBSCAN算法作为加速检索的核心算法。
4.2. HDBSCAN融合相似度算法实际应用
联合零件信息库,装配体结构库,装配体配合库生成的实例装配特征矩阵就是HDBSCAN中的目标数据集,该数据集并没有明确的类标签,因此符合无监督学习的应用场景,HDBSCAN在相似度算法中的具体应用流程如图7所示:

Figure 7. Flow chart of HDBSCAN accelerates search
图7. HDBSCAN加速检索流程图
HDBSCAN算法会提前根据原有的实例库特征矩阵进行聚类,构建一个类似分桶的具体特征,将所有的特征向量分为n个类别,这与分箱操作相类似,其中离群值会被分配到-1类,类别特征也会自动存储入实例库中,之后将获取到的新实例特征向量放入之前拟合完成的HDBSCAN算法中及进行预测,将其划分入相似度最高的类别之中,之后,只从实例库中取出该类别的所有实例进行相似度计算,这种方法大大地缩减了检索范围,除此之外,也让相似度匹配的对象更加具有针对性,提高匹配效率,减少冗余数据或无效计算。
这里将目标实例设置为SES0487DT-B10-00A前导轨组装,从实例库中取出500个实例样本,生成装配特征矩阵如图8所示:
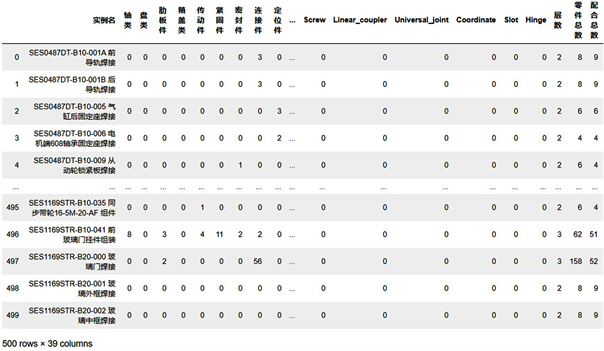
Figure 8. Assembly feature matrix of 500 assembly instances
图8. 500个装配实例的装配特征矩阵
利用HDBSCAN算法聚类,对于每个样本的向量标签如图9所示:
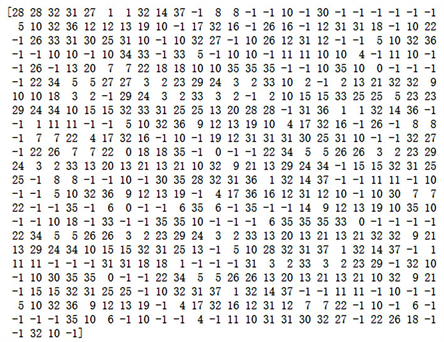
Figure 9. Cluster labels obtained by HDBSCAN
图9. 通过HDBSCAN分得的簇标签
统计标签个数输出标签对应标签个数的条形图如图10所示:

Figure 10. Statistics on the number of labels in each cluster
图10. 各簇的标签个数统计
从中可以发现该数据集中存在着大于120个不能被聚类的数据集的离群样本,即label = −1,占了非常大的比例,除此之外,其他簇的个数非常接近,说明聚类得到的簇有一定的持久性,之后就可以将新实例归并到其中的一个簇中,进行综合相似度的计算。
该数据集就变成了相似度计算的数据集如图11所示,检索范围整整缩小了50倍,实例匹配的速度也大大加快了,最终的综合相似度输出结果为表2。
可以发现簇聚集的质量很高,目标实例与实例库的相似度匹配获得的前6个实例的综合相似度较高,这也验证了即使在做了聚类操作之后,相似度匹配算法的精度并没有受到任何影响。
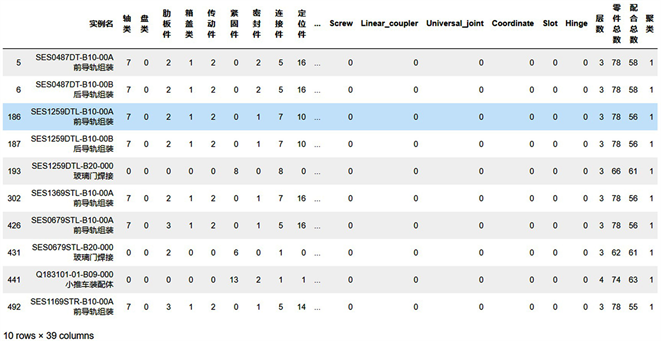
Figure 11. The retrieved similarity of the front guide rail with a threshold of 10
图11. 标签为“1”的簇内部装配特征集合
Table 2. System resulting data of standard experiment
表2. 阈值为10的前导轨相似度检索报告
5. 结论
本文分析了提高装配工艺重用效率的方法,首先介绍了Apriori关联规则算法的基本原理,并利用Apriori关联规则算法进行规则提取,作为知识检索的条件和结论放入规则库,以此提高知识检索的效率;针对工艺实例推理,提出了基于HDBSCAN聚类算法加速实例推理,通过缩小实例检索范围提高实例匹配的效率。通过验证表明,使用了Apriori关联规则算法和HDBSCAN聚类算法后,在不影响相似度匹配算法的精度的同时,数据集检索范围缩小了50倍,实例匹配的速度明显加快。
文章引用
亓凯航,仲梁维. 基于HDBSCAN聚类算法的实例推理与规则提取
Case Reasoning and Rule Extraction Based on HDBSCAN Clustering Algorithm[J]. 建模与仿真, 2023, 12(02): 1469-1480. https://doi.org/10.12677/MOS.2023.122137
参考文献
- 1. 曹勇. 基于数据挖掘的工艺知识发现与重用研究[D]: [硕士学位论文]. 济南: 山东大学, 2019.
- 2. 吴锐. 面向工艺重用的装配关键技术研究[D]: [硕士学位论文]. 长沙: 国防科学技术大学, 2008.
- 3. 何丽瑶. 基于Apriori及XGBoost算法的道路交通事故分析研究[D]: [硕士学位论文]. 苏州: 苏州大学, 2020.
- 4. Yu, H.F. (2021) Aprio-ri Algorithm Optimization Based on Spark Platform under Big Data. Microprocessors and Microsystems, 80, Article ID: 103528. https://doi.org/10.1016/j.micpro.2020.103528
- 5. 田春子, 张磊, 朱泽一, 邵晓康, 胡子悦. 基于Apriori和FP-Growth算法的学生行为分析研究[J]. 信息记录材料, 2020, 21(12): 156-159.
- 6. 张胜文, 陆贤磊, 程德俊, 方喜峰, 官威, 李群. 基于改进Apriori算法的装配工艺规则挖掘技术[J]. 船舶工程, 2020, 42(5): 108-112.
- 7. 崔晴洋, 梁小峰, 倪静, 李帅, 张生, 仲梁维. 基于卫星装配工艺的短文本聚类研究[J]. 软件工程, 2020, 23(4): 7-11.
- 8. 王继业, 邓春宇, 郑亚芹, 张玉天, 刘凤魁. 基于HDBSCAN动态跟踪客户用电行为模式[J]. 供用电, 2019, 36(1): 10-16.
- 9. 郗洋. 基于云计算的并行聚类算法研究[D]: [硕士学位论文]. 南京: 南京邮电大学, 2011.