Computer Science and Application
Vol.05 No.06(2015), Article ID:15485,8
pages
10.12677/CSA.2015.56025
Hardware Design of WLI Image-Zooming Algorithm Based on Zedboard
Shiyang Xu, Hang Dong, Hui Li
Department of Microelectronics and Solid-State Electronics, University of Electronic Science and Technology of China, Chengdu Sichuan
Email: 791608192@qq.com
Received: Jun. 4th, 2015; accepted: Jun. 22nd, 2015; published: Jun. 25th, 2015
Copyright © 2015 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



ABSTRACT
A novel zoom algorithm is researched and further realized by a FPGA board. The algorithm is of low complexity, low hardware requirements, and wonderful zoom result thanks to even-odd decomposition method. First, function of the algorithm was verified by MATLAB. Second, zoom results of pictures were evaluated using PSNR, time consuming, edge fuzzy grade, and impulse noise. Compared to the conventional algorithm in the time domain, the even-odd decomposition method has advantages on zoom quality and computational efficiency. Based on Zedboard, we wrote C program of WLI image zoom algorithm and used high level synthesis tool Vivado HLS to generate the IP from the program. Then, a software and hardware co-verification system was constructed including modules such as ARM processor, VGA controller. Finally, hardware design of the zoom algorithm using even-odd decomposition method was proved correct by experiments.
Keywords:Parity Decomposition, WLI Algorithm, High Level Synthesis, Software and Hardware Co-Verification System
基于Zedboard的WLI图像缩放算法的硬件设计
许世阳,董航,李辉
电子科技大学微电子与固体电子学院,四川 成都
Email: 791608192@qq.com
收稿日期:2015年6月4日;录用日期:2015年6月22日;发布日期:2015年6月25日

摘 要
本文选择了一种新颖的图像缩放算法进行FPGA硬件实现。该算法基于奇偶分解的思想,具有复杂度低、硬件需求小和缩放效果良好等突出优点。首先利用MATLAB对该算法进行了功能验证,然后用缩放耗时、PSNR、边缘模糊等级和脉冲噪声等指标评估基于该算法图像处理效果。与传统时域算法作对比,对比结果表明该算法在处理效果和运算速度上的优异性。基于Zedboard开发板,运用Vivado HLS高级综合工具将算法的C程序综合成硬件IP,并搭建了包含ARM处理器和VGA等模块的软硬协同验证系统。实验验证了图像缩放算法硬件设计的正确性和实用性。
关键词 :奇偶分解,WLI算法,高级综合,软硬协同验证系统

1. 引言
数字图像处理因其广泛应用于社会生活的各个领域,而成为了研究的热点。图像缩放是数字图像处理中的一项基本而又关键的操作,多数图像与视频帧都是以压缩的格式进行存储和传送,以降低存储资源的占用,提高数据传输的效率。针对不同的应用,用户通常需要不同分辨率的图像。例如,在图像数据传输过程中为节省带宽,则通常需要发送低分辨率的图像,而当接收到图像后,进行显示时又很希望看到高分辨率的图像。尽管存在各种数据压缩软件,但数据的压缩仍是有限的,而且数据的压缩很可能已经对图片造成了一定的损坏,并不能确保图片关键信息的保留。图像缩放算法有很多,总体可分为基于时域和频域两大类算法,在时域图像缩放方法中,主要有最近邻域算法、双线性插值算法和双三次线性插值等。虽然它们在改善图像缩放处理后的失真度上逐渐增强,但其不断下降的运算速度也成为了不容忽视的问题(特别在视频帧放大中,图片的切换频率限制了缩放算法的可执行时间)。
这些算法中,有的通过PC机上的MATLAB、C等高级语言实现,有的基于ARM等嵌入式处理器实现,而有的则是基于FPGA这类芯片进行硬件的实现。由于PC机和ARM属于多任务的操作系统,通过软件编程实现缩放算法是其常用的图像缩放处理手段。系统代码解析和串行执行,以及多任务的切换等因素会严重降低图像缩放效率和实时数据显示,频繁的图像缩放会给系统的正常运行造成相当大的负担。因此,本文重点研究第三种图像缩放实现方法,充分利用FPGA的并行运算、高集成度、可编程和低成本特性,编程实现缩放算法的硬件结构和IP生成,为进一步实现专用图像缩放处理芯片的开发和应用提供帮助,以释放处理器,提高图像缩放质量和效率。
在综合考虑图片处理效果、运算速度和硬件资源需求后,本文选择了由Hoon Yoo和Byong-Deok Choi共同提出的算法[1] ——基于奇偶分解的分段加权插值的图像缩放算法(简称WLI算法)进行硬件实现。
WLI算法借助于奇偶分解的理论,基于16个相关点实现了图像中新点值的确立。本课题基于Xilinx的全可编程器件Zedboard,利用vivado hls高级综合工具编写可综合的c程序,实现了WLI缩放算法的硬件IP设计,利用开发板实际缩放操作验证了硬件缩放的高效率和低时间耗用特征,并通过图像缩放的VGA对比显示实验对设计进行了验证。同时,设计实现的IP也可以为图像处理的SoC复用,降低SoC的开发难度。
2. 图像插值算法及MATLAB仿真
2.1. 传统插值算法 [2]
本文分别选取了最简单的、基于四个相关点的最近邻插值算法;有二阶线性运算参与的双线性插值算法;以及最复杂多浮点运算的双三次插值运算作为对比算法,通过多种图像质量和效率评价方法,来评估WLI算法的优劣性(具体算法实现参考 [2] 相关内容)。
2.2. WLI算法
WLI算法应用奇偶分解的思想,将一维缩放中相关的四个点进行奇偶分解(奇部和偶部的相关点值分解后的关系示例见图1)。从定义上分析,奇部向量在频域图像数据处理中是一个高通滤波结构,相比于偶部向量,它具有更强的噪声。而噪声和高频信号对该部分的影响往往会掩盖该部分对正确缩放的像素点取值的贡献,所以为尽量避免奇部向量中携带的噪声等参量对缩放质量造成损害,对它进行简单的线性化操作,得出公式(1)的处理方案。
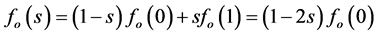 (1)
(1)
因为偶部向量对称的特性,其对缩放点的最终取值具有很大的影响度。直接的线性拟合虽然具有运算简单的特点,但正如图2所示,这会使得图片点值的变化太快,影响视觉效果。为使该部分的取值具有缓慢变化的特征,基于平滑曲线的原型方程是一个很好的选择,但曲线的复杂运算带来的资源耗用往往使算法缩放得不偿失。因此,引文对此部分的曲线公式进行分析讨论,巧妙的引入w参数完成了运算方法的降次和近似,如图2所示,最终得出同样是一次方程的拟合曲线图像插值计算公式(2)。
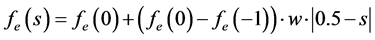 (2)
(2)
最终由图3表示出了WLI算法基本单元的信号流处理流程,通过串行移位得到四个相关点,利用加/减操作和移位操作分别得到奇部向量和偶部向量。在s参量的调节下,取w = 0.5时,仅通过两个乘法器便可实现最核心的操作,最后加和奇部和偶部,便得出最终的缩放结果。该结构仅包括6次加法和6次移位操作,并伴有3次延时和两个乘法操作,总体硬件资源耗用较少,延时也较低,具备硬件化条件。
2.3. 算法的MATLAB仿真及评估
运用MATLAB语言,编写程序实现缩放算法。将常用的几种算法 [3] 进行了缩放耗时 [4] 、PSNR (Peak Signal to Noise Ratio)比较以及边沿模糊度、脉冲噪声两种无参考图像评测,并对结果进行了比较分析。
PSNR [5] 也叫峰值信噪比,它是最普遍、最广泛使用的评鉴画质的客观测量方法,意指到达噪音比率的顶点信号,是衡量经过处理后的影像品质的客观方法,用MATLAB实现的计算公式如(3)所示。
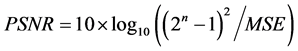 (3)
(3)
其中,MSE是原图像与处理图像之间均方误差。
边缘模糊度 [6] 是指阶跃边缘点占总边缘点的个数的比例值,其值越小说明图片边缘更清晰,图像质量越好。一般边缘点的检测是利用robel算子得到的,而在图像中根据相关函数也可以判断并统计出阶跃边缘点,由此便可计算出各个图像的比例值,使用不同算法对多个图片放大两倍后计算出的边缘模糊度结果如表1。
类似的,脉冲噪声 [6] 是指图像中噪声像素点占总像素点的个数比例,图像噪声点是指根据局部图片判断出的本不该出现的点值,即该区域有一定的取值范围,当超过该范围后即认为该点是噪声点。本文采用最小二乘法的预测模型进行容限计算,同时判断和统计总的噪声点个数,进而计算出不同图片的脉冲噪声值结果变化如图4所示。

 (a) (b)
(a) (b)
Figure 1. The module of the relative points for even-odd decomposition [1]
图1. 奇偶分解相关点示意图 [1]

Figure 2. The linear module of even part of WLI method [1]
图2. WLI算法偶部线性拟合示意图 [1]
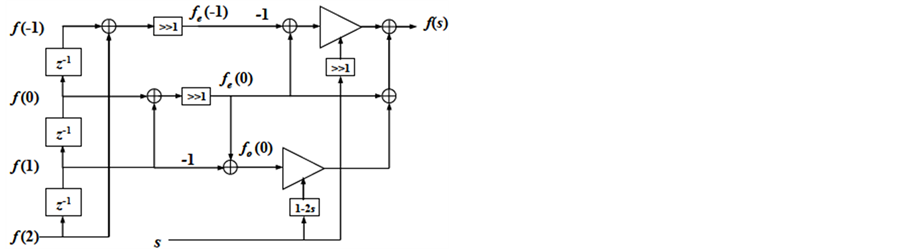
Figure 3. The basic data transmission structure of WLI method [1]
图3. WLI算法基本结构数据流处理结构 [1]

Figure 4. The impulse noise of magnified two times the pictures in different kind of methods
图4. 多种算法放大2倍的图片脉冲噪声对比

Table 1. The edge fuzzy grade of magnified two times the pictures in different kind of methods
表1. 多种算法放大2倍的图片边缘模糊度
根据MATLAB的相关仿真数据,得出WLI算法不仅具有高PSNR值,低耗时等特征,从表1和图4中的对比结果亦见,其边缘模糊度和脉冲噪声也相对较低,充分体现了该算法的优异性。
3. 硬件系统平台的搭建
针对Xilinx可编程器件开发板Zedboard [7] ,进行算法的硬件实现和IP生成,同时对软硬协同验证系统平台的设计和功能进行软件和硬件划分。如图5所示,上位机中计算机(PC)负责把新的图片数据传送到开发板,或者从开发板接收缩放后的图片数据,并打印各种处理信息和状态值。显示器显示不同算法的缩放图片直观效果。而下位机(Zedboard)则主要完成控制信息编码输入,软件或硬件图像缩放算法实现,以及内部模块间的图片数据传输等功能。其中,输入检测和控制信息生成、执行,以及对比软件缩放算法的实现等部分是分配给ARM处理器通过软件完成的。
3.1. ZEDBOARD的控制输入IP
该IP设计主要完成对5个按键以及2个开关状态的检测及编码,使产生8位编码数据,用以传送给XPS构建的子系统的8位GPIO,以axi_lite相关协议映射编码数据,从而将编码输入传送到了PS (Processing System: ARM处理器)部分,用以软件编程检测和处理。
该设计的实现原理如图6所示,通过计数模块Count实现按键状态的去抖检测,两个按键用于缩放算法选择,并用三个Led的二进制实时显示,另两个按键用于选择缩放倍数,一个按键用于录入状态与完成录入状态间的切换;两个开关则分别控制放大/缩小、显示使能。
3.2. WLI算法IP
3.2.1. Axi4接口
Axi4 [8] 是由Xilinx和ARM合作提出的便于全可编程器件内部ARM和FPGA之间数据的高速通信的总线标准。Zedboard内部使用Axi4,可细分为Axi_lite、Axi4、Axi_stream三大类,包含地址、数据和反馈通道。能实现ARM和FPGA内部的高速并行数据通信,并支持DMA (direct memory access)通信。
3.2.2. 符合Axi4接口的WLI算法IP
Vivado HLS是Xilinx针对其全可编程器件而推出的高级综合组件,该软件可以实现对C语言编写的程序的直接硬件化,并能很好的综合出符合Axi标准的IP [9] - [12] 。本文的设计采用这种设计方法,借助OpenCV的MAT的相关内容、要求,编写可综合算法程序,图7是WLI算法的实现流程。
映射策略确定新图中的一行在原图的行位置,通过每次缩放一行新图数据的基本策略,用四个数组(Bram存储)缓存与映射行相关的四行原图点值,从而实现算法的二维缩放。WLI子模块实现对一维4个相关点的算法缩放,通过先行后列的策略实现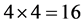 个相关点的图像缩放目的。
个相关点的图像缩放目的。

Figure 5. The structure of hardware system with zoom method
图5. 缩放算法硬件系统架构
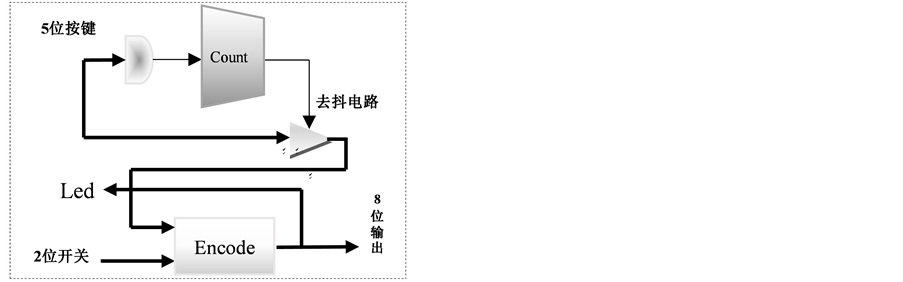
Figure 6. The structure of import controlling IP
图6. 控制输入IP结构框图
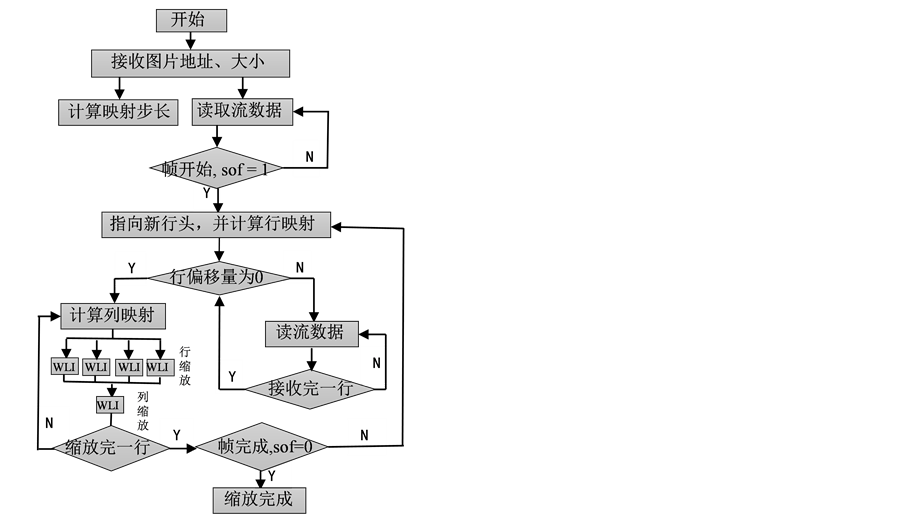
Figure 7. WLI method flow
图7. WLI算法流程
3.3. 硬件系统搭建
HLS综合出算法的硬件IP后,通过Planahead环境完成整个硬件系统的搭建。图8为系统结构示意图,该系统包括PS子系统、内存间以HP通道(DDR内存和FPGA间的高宽带、高速数据通道)直接进行数据通信的VDMA、GPIO等IP,以及自主设计的WLI算法IP和VGA显示IP [13] 。
4. 软硬协同验证实验
4.1. 软件原理
在硬件系统搭建完成以后,借助于Xilinx的SDK集成环境进行软件设计。图9是整个软件设计运行的流程图,主要分为初始化、原始图片选择接收存储、GPIO初始化、缩放倍数检测统计、按键状态检测判断和相应算法处理及对比显示等。
软件设计中,通过接收PC的选择信号,选择使用预定义的图片,或接收从PC传来的新图片。然后进入循环检测和缩放处理过程,便于演示。同时,通过显示使能控制端,可以再次更新PC的显示数据。而缩放显示模式不仅决定缩放的算法选择(软件或硬件),还决定显示模式(单一还是对比显示)。
当检测到GPIO为倍数录入状态时,应当进入倍数的检测和相应操作模式,由此可实现0.1精度的任意倍数图像缩放效果,并能够对基于不同缩放算法得到的图片进行对比显示。
4.2. 软硬件协同验证
通过SDK将编译好的bootloader程序、FPGA配置bit文件和裸机程序封装成boot.bin文件,以SD卡实现Zedboard的脱机演示系统。其验证实验的系统如图10所示,右图是双三次插值算法软件缩放结果,而左图则是WLI算法硬件缩放图。
各缩放算法在ARM裸机上缩放图片所耗用时间 [14] 的对比结果如图11所示。其中最近邻(Near)、双线性(Biline)、双三次(Bcubic)和CCI等为软件缩放算法,WLI算法为硬件实现算法。
尽管软件缩放算法在约667 MHz的Cortex A9处理器上运行,而通过FPGA硬件化的WLI算法的运行时钟仅为100 MHz,但图11的结果表明,其缩放耗时仍同最近邻算法相当(Near几乎被WLI覆盖了),可见在相同时钟条件下,其计算效率将会大幅提高,体现硬件实现的并行特征。

Figure 8. The structure of hardware system
图8. 硬件系统结构

Figure 9. Software flow diagram
图9. 软件处理流程图

Figure 10. The system of zoom picture in comparison
图10. 图像缩放对比显示演示系统
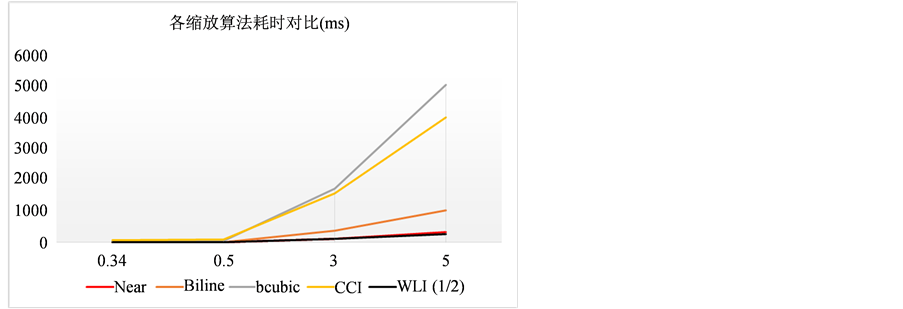
Figure 11. The time consuming result of image scaling algorithms in different times
图11. 各缩放算法不同倍数耗时对比
5. 结论
本文主要研究了时域图像缩放算法中比较常用的几种缩放算法,并基于一种称为WLI的图像缩放算法,在Xilinx的全可编程器件开发板Zedboard上实现了算法的硬件化,并构建了软硬协同验证系统,实现了脱机演示。
本文设计的IP实现了硬件图像缩放,并与基于软件实现的图像缩放具有相同效果,而计算效率提高了至少一个数量级,充分体现了硬件实现图像缩放的优异性和可行性。
致谢
感谢Byong-Deok Choi和Hoon Yoo提出WLI算法,电子科技大学微固学院微系统与芯片集成设计中心李辉副教授的支持和帮助,电子科技大学2013年大学生创新训练项目(图像的无损缩放算法研究与FPGA实现)的资助。
文章引用
许世阳,董 航,李 辉, (2015) 基于Zedboard的WLI图像缩放算法的硬件设计
Hardware Design of WLI Image-Zooming Algorithm Based on Zedboard. 计算机科学与应用,06,195-203. doi: 10.12677/CSA.2015.56025
参考文献 (References)
- 1. Choi, B.-D. and Yoo, H. (2009) Design of piecewise weighted linear interpolation based on even-odd decomposition and its application to image resizing. IEEE Transactions on Consumer Electronics, 55, 2280-2286.
- 2. 刘婧 (2009) 图像缩放算法的研究与FPGA设计. 硕士论文, 上海大学, 上海.
- 3. 李秀英, 袁红 (2012) 几种图像缩放算法的研究. 现代电子技术, 35, 48-51.
- 4. Wang, J. (2011) MATLAB三种程序耗时算法. http://wenku.baidu.com/view/4f125446336c1eb91a375d60.html
- 5. 心海 (2013) PSNR定义与计算. http://blog.sina.com.cn/s/blog_7e27bd1a0101alq5.html
- 6. Li, X. (2002) Blind image quality assessment. IEEE ICIP, 1, 449-452.
- 7. Xilinx (2014) Zynq-7000 all programmable SoC. Xilinx数据手册.
- 8. Xilinx (2011) Xilinx, AXI reference guide UG761 (v13.1) March 7. Xilinx数据手册.
- 9. 马建国, 孟宪元 (2011) FPGA现代数字系统设计. 清华大学出版社, 北京.
- 10. 仆居 (2013) AXI-Stream接口开发详细流程. http://blog.csdn.net/kkk584520/article/details/9290069
- 11. 何宾 (2011) 基于AX14的可编程SOC系统设计. 清华大学出版社, 北京.
- 12. 何宾 (2011) Xilinx all programmable Zynq-7000 SOC设计指南. 清华大学出版社, 北京.
- 13. 开源硬件社区 (2009) VGA驱动及实现. www.oshbbs.com
- 14. Cuter (2013) 如何在SDK中计算某段程序的执行时间. http://blog.chinaaet.com/detail/31789