Sustainable Energy
Vol.05 No.03(2015), Article ID:15456,6
pages
10.12677/SE.2015.53003
The Study of Short-Term Wind Power Generation Prediction Methods Based on Clustering Analysis in Wind Farm
Cun Dong1, Shuang Gao2, Ying Hao2, Yang Gao3
1State Grid Corporation of China, Beijing
2Beijing Institute of Technology, Beijing
3Shenyang Institute of Engineering, Shenyang Liaoning
Email: Correspondent_dong@163.com
Received: Jun. 2nd, 2015; accepted: Jun. 20th, 2015; published: Jun. 23rd, 2015
Copyright © 2015 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



ABSTRACT
In order to make full use of information contained from historical wind data, this paper proposed a short-term power prediction method based on clustering analysis according to the daily similarity property of wind speed and wind power. By the preprocessing of the original sample data, when calculating the Euclidean distance among the characteristic parameters, the history data which are similar to the NWP characteristic parameter of the prediction day are used as the training sample; the NWP information provided by the meteorological department is used as the characteristic parameter of the prediction day. This Euclidean distance is used to be the basis of the similarity measure. Finally, this paper uses the similar samples after clustering to establish the short-term prediction model which is using the NWP data as the input parameter, using the actual wind power generation as the target data. Testing by the actual wind farms, the prediction precision is improved obviously.
Keywords:Short-Term Wind Power Generation Prediction, Clustering Analysis, K-Means Clustering Method, Daily Similarity Property, Numerical Weather Prediction (NWP)
基于聚类分析的风电场短期功率预测方法研究
董存1,高爽2,郝颖2,高阳3
1国家电网公司,北京
2北京理工大学,北京
3沈阳工程学院,辽宁 沈阳
Email: Correspondent_dong@163.com
收稿日期:2015年6月2日;录用日期:2015年6月20日;发布日期:2015年6月23日

摘 要
为了充分利用历史风速数据所蕴含的信息,本文根据风速和风电功率的日相似性提出基于聚类分析的短期功率预测方法,通过对原样本数据进行预处理,选取与预测日NWP特征参数相似的历史日数据,以此作为建立模型的训练样本,将气象部门提供预测日的NWP信息作为预测日的特征参数,计算特征参数间的欧式距离,以此作为相似性度量的依据,最后利用聚类后的相似样本建立预测模型,以NWP数据为输入参数,实际风电功率为目标值,经过训练后得到聚类风电功率短期预测模型。经实际风电场测试,预测精度明显提高。
关键词 :短期功率预测,聚类分析,K均值聚类法,日相似性,数值天气预报(NWP)

1. 引言
风速具有明显特征区别,同时每天的风速随着日出日落的周期变化亦存在一定的规律,经大量研究发现,风速存在一定的日相似特性[1] 。为了充分利用历史风速数据所蕴含的信息,根据风速和风电功率的日相似特性提出基于聚类分析的短期风电功率预测方法,出发点在于利用样本预处理对改善预测结果的重要作用,最终目的在于提高预测精度。
采用聚类方法进行风电功率预测的关键是寻找聚类的依据,即获得不同类型样本划分的依据。目前,国内外针对风电功率短期预测及其预测精度提高方法的研究亦较多,但是采用相似日聚类方法作为预测前处理,以提高预测精度的方法还未见相关研究。风电功率变化趋势近似的日,存在某些共有的特征,可通过NWP信息变化趋势的基本一致性得到体现。
本文所提方法将聚类分析法应用于风电功率预测,通过对原样本数据进行预处理,提取与预测日NWP特征参数相似的历史日数据作为建模的训练样本。以预测日的NWP信息作为预测日特征参数,通过计算所获得特征参数的欧氏距离确定各类相似日数据,最后利用聚类后的相似样本建立功率预测模型,NWP数据作为模型输入参数,实际风电功率数据作为模型目标值,经过模型训练便能得到风电场短期功率多步预测模型。
2. 风电功率的日相似性
风电场风电机组实际输出功率的大小主要取决于当地风能资源情况,而风资源的特性主要是指风速的变化特性。风速是单位时间内空气在水平方向上移动的距离,主要受气象因素及地形、地表障碍物等因素的影响。地球自转产生的昼夜交替使得某些天的天气状况呈现某种程度的相似性,所以天气状况相似日的风电功率变化趋势十分近似。
图1是依兰风电场2012年1月至6月,部分日风速变化曲线族,图中横坐标表示风速采集时间点,

Figure 1. Some of the daily wind speed change curve
图1. 部分日风速变化曲线族
采集间隔为15 min,可以看出,其变化趋势存在一定的相似性,对应的风电功率亦呈现相似的变化趋势,如图2所示,图中横坐标表示与图1相对应的风电功率采集时间点,采集间隔同样为15 min。由于风电功率的变化趋势与该日的天气状况存在一定关系,对于某风电场来说,风电功率的日相似性可采用与其有密切关系的天气信息的日相似情况来判断。气象信息可通过预报的方式获得,根据其相似性查找预测时段的相近样本,作为建立短期预测模型的训练样本。聚类分析法是解决相似性样本查找的一种有效方法。
3. 相似日的聚类分析
聚类分析是将研究对象按照一定度量标准分成不同类别的统计分析技术 [2] 。聚类是属于无监督的分类方法,是一种探索性的分析,没有预先指定的类别。在机器学习领域,聚类是无指导学习。聚类分析被广泛应用于多个领域,包括模式识别、数据分析、图像处理、以及市场研究。在商业、网络以及生物应用等方面都发挥着重要的作用。
3.1. 聚类分析的基本步骤
运用聚类方法一般包括下列四个步骤 [3] - [5] :
1) 找出分类对象的特征;
一般,所研究的数据对象包含多种特征,其中具有代表性的特征能够帮助识别数据对象本身,这种特征属性是区分不同数据对象的标准,所以在进行聚类分析时,首先需将对象区别于其他数据的特点提取出来。
2) 确定分类对象的相似性;
聚类就是把特征属性相类似的数据对象划分到一类,特征属性不同的划分到另一类。所以衡量数据的相似性要有一个度量的标准。不同的标准得出的聚类结果可能是不同的。关于相似性的量度在2.3节中有介绍。
3) 提出达到分类的步骤或聚类算法;
聚类过程中的关键步骤之一是采用不同的方法对数据对象进行划分。主要的聚类分析方法有划分方法和层次方法。而硬聚类和模糊聚类是划分方法中比较常用的两种技术。
4) 对聚类结果做出评价。
评价聚类结果质量的好坏是没有客观标准的。可以根据实际情况选择更符合实际的聚类结果。
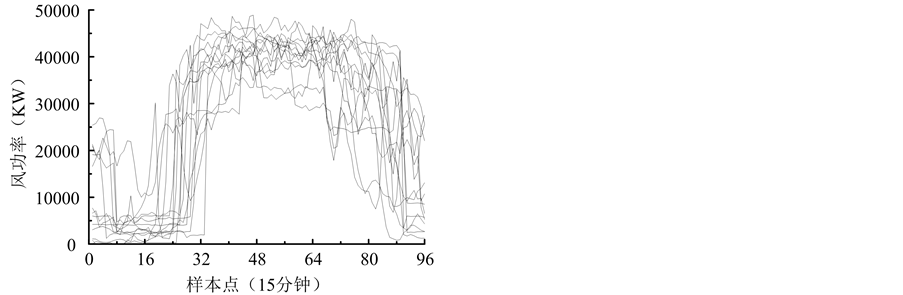
Figure 2. Some of the daily trend curve of the wind power generation
图2. 风电功率部分日功率趋势变化曲线族
3.2. 聚类分析的方法
传统的聚类算法包括五类:划分方法、层次方法、基于密度的方法、基于网格的方法和基于模型的方法 [6] - [8] 。划分方法和层次方法都是基于距离来判断相似度的,基于密度的方法是基于密度这一概念来判断相似度的。现代的聚类算法包括高维聚类分析方法和动态聚类算法两类。
K均值聚类法是动态聚类算法中最经典的一种,其基本思想是将每一个样本划分到离均值最近的类别中,它是以距离的远近为标准进行聚类的。
K均值聚类算法一般包括以下几个处理步骤:
1) 将所有数据分为K个初始类,选取K个样本点为初始聚类中心,记为 ,其中初始值
,其中初始值 ;
;
2) 按照最近邻规则将所有样本分配到各聚类中心所代表的K类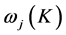 中,各类所包含的样本数为
中,各类所包含的样本数为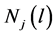 ;
;
3) 计算各类的均值向量,并将该向量作为新的聚类中心:
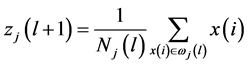 (1)
(1)
其中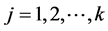 ,
,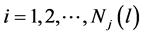 。
。
4) 若 ,表示聚类结果并不是最佳的,则返回步骤2),继续迭代计算;
,表示聚类结果并不是最佳的,则返回步骤2),继续迭代计算;
5) 若 ,迭代过程结束,此时的聚类结果就是最优聚类结果。
,迭代过程结束,此时的聚类结果就是最优聚类结果。
3.3. 相似性的量度
在开始对样本进行分组之前,必须定义相似性的量度。每一个样本必须与其他样本相比较,然后才能将非常“相似”的样本置于同一类中,不相似的样本则置于不同的类中。两个元素之间的相似性可用各种不同的方法来度量,主要有距离度量、相关性度量和信息量度量等方法。
常用的距离有明氏距离(Minkowski)、马氏距离(Mahalanobis)和兰式距离(Canberra)。
本文采用欧式距离度量不同日的风速趋势之间的相似程度。将每天作为一个数据对象,由一个7维向量表示,称为日NWP向量,表示为X = [Pav, Vmin, Vmax, Tmin, Tmax, Dsin, Dcos],其中的变量依次代表日气压平均值、日风速最小值、日风速最大值、日气温最小值、日气温最大值、日风向正弦平均值、日风向余弦平均值。由于日NWP向量中各分量的量纲不同,需要进行归一化处理,气压、风速和气温分别除以各自的历史最大值,风向正弦和余弦值均为归一化数值,不需再作处理。
距离定义为:
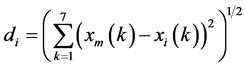 (2)
(2)
其中,di为预测日与历史样本i的欧氏距离。xm为预测日的日NWP向量,xi为历史数据的日NWP向量, ,n为样本数。
,n为样本数。
4. 基于聚类分析的短期风电功率预测模型
4.1. 模型结构
图3为基于聚类分析的短期风电功率预测模型的结构示意图。首先利用K均值聚类算法以日NWP向量距离最接近原则将历史样本分为K类,采用计算机编程自动搜寻预测日所属的分类,将各分类中的样本数据作为训练样本,利用神经网络建立预测模型。
对模型进行训练时,采用预测日所属分类样本的NWP气压、NWP风速、NWP气温、NWP风向正弦和NWP风向余弦等作为输入,模型的目标值为风电场输出功率。采用此模型进行预测时,只需将预测日的NWP信息输入模型便可得到风电功率的预测值。
4.2. 聚类计算与结果分析
采用黑龙江依兰风电场2012年1~2月的NWP数据和实测风电功率数据进行分析、建模和预测。数据分辨率为15分钟。选择2012年2月4日作为预测日,预测步长为96点。
选择2012年2月4日之前的20天历史数据做聚类分析,采用K均值聚类算法,得到准则函数与分类数K的关系曲线如图4所示,根据2.2节中介绍的确定最优分类数的方法,取准则函数曲线拐点处的K作为最佳分类数,得到K = 3。
在分类数K = 3的情况下,20个历史样本日所属类别情况如表1所示。其中,4天属于第3类,1天属于第2类,其他均属于第1类。由式(1)可计算出这三类的聚类中心(归一化)分别为:
第1类:[0.988 0.183 0.438 -1.130 -0.804 0.042 0.051];
第2类:[0.988 0.555 0.863 -1.151 -0.853 0.119 0.189];
第3类:[0.9930.047 0.268 -0.856 -0.551 -0.020 -0.125]。
预测当日和2012年2月4日的归一化日NWP向量为[0.981 0.340 0.801 -0.932 -0.579 0.113 -0.052],由式(2)可得与三类聚类中心的欧式距离分别为0.51、0.48和0.63,距离第2类聚类中心最近,所以预测日所属分类为第2类,属于第2类的样本为第19个样本日,2012年2月2日。
4.3. 聚类结果用于短期预测
以2012年2月2日NWP的气压、风速、气温、风向正弦和风向余弦作为输入,实测功率数据作为输出进行建模,数据分辨率为15分钟,训练样本数据个数为96,神经网络结构采用GRNN,窗口宽度参数s取值为0.15,模型结构见图3。
模型训练完成后,将预测日即2012年2月4日的NWP气压、NWP风速、NWP气温、NWP风向正弦和NWP风向余弦输入得到预测功率值。预测误差NMAE和NRMSE分别为10.67%和14.01%。
为了验证本文方法的先进性,将基于聚类分析的神经网络模型与持续模型进行对比,得到图5所示预测结果对比曲线。功率预测误差情况详见表2。

Figure 3. Short-term wind power generation prediction mode based on clustering analysis
图3. 基于聚类分析的短期风电功率预测模型
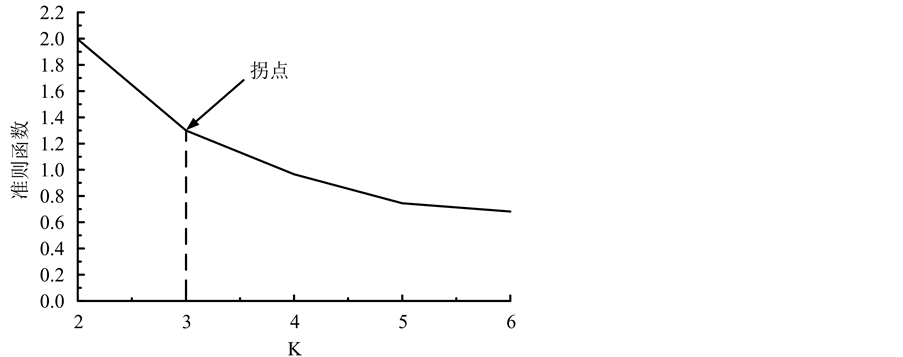
Figure 4. The diagram of the criterion function and the classification number K
图4. 准则函数与分类数K关系图

Figure 5. The comparison of the prediction curve from different prediction mode
图5. 各模型功率预测曲线对比

Table 1. The sample clustering table
表1. 样本所在聚类情况表
Table 2. The comparison of the prediction error from different prediction mode
表2. 功率预测误差
表2中标准绝对值平均误差(normalized mean absolute error, NMAE),标准均方根误差(normalized root mean square error, NRMSE)计算公式如式(3)、(4):
 (3)
(3)
 (4)
(4)
上述三式中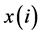 为样本真实值,
为样本真实值,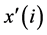 为样本预测值,
为样本预测值,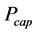 是风电场的额定装机容量,
是风电场的额定装机容量, 为预测样本个数。
为预测样本个数。
5. 结论
由于一年四季的风速特征具有明显区别,且每天的风速随着日出日落的周期变化也存在一定的规律,为了充分利用历史风速数据所蕴含的信息,本文分析了风电功率的日相似性,而对应的气象数据也具有相似性,气象数据是可以提前获取预报值的,这就为利用相似性这一特征进行风电功率短期预测提供了思路。经过实际风电场测试,验证了本文所提方法的有效性和先进性,具体结论为:
1) 对风电功率预测模型进行恰当的前处理能够有效的提高短期风电功率的预测精度;
2) 采用聚类分析方法对NWP数据进行分析可有效的对不同天气类型的日数据进行分类;
3) 将聚类分析方法与神经网络进行衔接可建立有效的短期风电功率预测模型,提高预测精度。
文章引用
董 存,高 爽,郝 颖,高 阳, (2015) 基于聚类分析的风电场短期功率预测方法研究
The Study of Short-Term Wind Power Generation Prediction Methods Based on Clustering Analysis in Wind Farm. 可持续能源,03,17-23. doi: 10.12677/SE.2015.53003
参考文献 (References)
- 1. 朱峰, 孙辉, 周玮 (2008) 基于相似日聚类的神经网络风速预测. 新能源发电, 中国高等学校电力系统及其自动化专业第二十四届学术年会论文集, 北京, 2008年10月24日, 2627-2630.
- 2. 殷君伟 (2013) K-均值聚类算法改进及在服装生产的应用研究. 硕士论文, 苏州大学, 苏州.
- 3. 李尤丰 (2009) 图像处理技术在硬度测量系统中的应用研究. 硕士论文, 南京理工大学, 南京.
- 4. 黄山山 (2011) 南京电信网厅用户行为分析系统的设计实现与应用. 硕士论文, 南京理工大学, 南京.
- 5. 古家声 (2012) 数据挖掘技术在寿险客户分析中的应用. 硕士论文, 华南理工大学, 广州.
- 6. 刘蕴 (2009) 基于启发式方法的集成生产-配送调度研究. 硕士论文, 天津大学, 天津.
- 7. 骆永健 (2010) 基于聚类的数据流异常检测算法的研究. 硕士论文, 哈尔滨工程大学, 哈尔滨.
- 8. 汪瑛 (2009) 数据挖掘在燃气系统中的应用研究. 硕士论文, 南京理工大学, 南京.