Journal of Sensor Technology and Application
Vol.04 No.04(2016), Article ID:18793,7
pages
10.12677/JSTA.2016.44014
A Data Processing Method for Avoiding Loss of Continuous Two Packets due to Packet Loss
Rongliang Yao, Yang Ren, Xiaoguo Zhang, Qing Wang
School of Instrument Science and Engineering, Southeast University, Nanjing Jiangsu
Received: Oct. 2nd, 2016; accepted: Oct. 20th, 2016; published: Oct. 26th, 2016
Copyright © 2016 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



ABSTRACT
When receiving message, the message often has the phenomenon of packet loss, and the packet loss of message will pollute the next message, which will lead to two invalid consecutive messages. In view of the above problems, in this paper, a new algorithm is proposed to detect the message content while reading the message content. Experiments show that the algorithm can effectively prevent the pollution of the next message due to the packet loss.
Keywords:Packet Loss Phenomenon, Packet Detection, Message Format

一种避免因丢包而损失连续两组报文的数据处理方法
姚荣亮,任阳,张小国,王庆
东南大学仪器科学与工程学院,江苏 南京
收稿日期:2016年10月2日;录用日期:2016年10月20日;发布日期:2016年10月26日

摘 要
在接受报文的时候,报文经常有丢包现象,一个报文发生丢包会污染下一个报文,会导致连续两组报文无效的现象。针对上述问题,本文提出一种在读取报文内容的同时也要检测报文内容的算法。通过实验证明该算法能有效防止因丢包而污染下一个报文。
关键词 :丢包现象,报文检测,报文格式

1. 引言
在信息技术领域中,电子设备的信息传输方式主要是以报文的方式进行发送与接收。由于工作场景、报文传输路径等客观原因导致报文在发送、传输、接收的过程中可能发生无码、丢包等现象。
2. 常见的报文处理方案
报文的读取技术主要分为两大块,分别是报文头识别和报文内容的读取这两大块技术。以往处理报文的常用的方法是,在获取的报文中先是检测是否含有可识别的报文头,一旦检测到可识别的报文头后,就读取报文头后面的报文内容,一直读到当所读取的报文内容的长度等于所设计的报文长度时候,就停止本段的报文读取。然后在重新匹配报文头,重复上面的操作 [1] [2] 。上面的方法主要缺点是:首先,上述方法没有检测报文内容的工作,所以不能确定所读取的报文内容否是有丢包现象 [3] [4] [5] 。其次,如果上一组报文内容有丢包现象,而没有及时处理,那么就有可能把下一组报文的报文头读取到报文内容中去,造成下一组报文没有完整的报文头,造成下一组报文的报文头匹配就无法进行,下一组报文内容就因为没有报文头而无法读取。
3. 改进方案
为了克服现有的技术中存在的问题,本文提出一种避免因发生丢包现象而损失两组报文的报文处理算法,能及时的发现在报文内容中是否有丢包现象。
一般发送的报文采用报文头标志的报文划分为以下几种类型:
1) 报文定长,有报文尾;
2) 报文定长,无报文尾;
3) 报文变长,有报文尾;
4) 报文变长,无报文尾 [2] 。
一种避免因发生丢包现象而造成连续两组报文损失的报文处理方法,对报文格式是报文头和固定长报文内容的报文或者报文格式是报文头、报文内容(固定长度或非固定长度)和报文尾的报文的处理方法,而对于报文格式是报文头加上变长的报文内容不作考虑(图1)。
3.1. 报文格式是定长报文内容和报文头
1) 对于已知报文格式是报文头和固定长度的报文时,假设获取的报文总长度为A*(m + n),A代表着获取得到的报文个数为A个,其中每个报文头长度为m,每个报文内容长度为n;
11) 对获取到的报文先进行报文头匹配,令首先匹配得到的可识别报文头尾第i = 1个报文头;
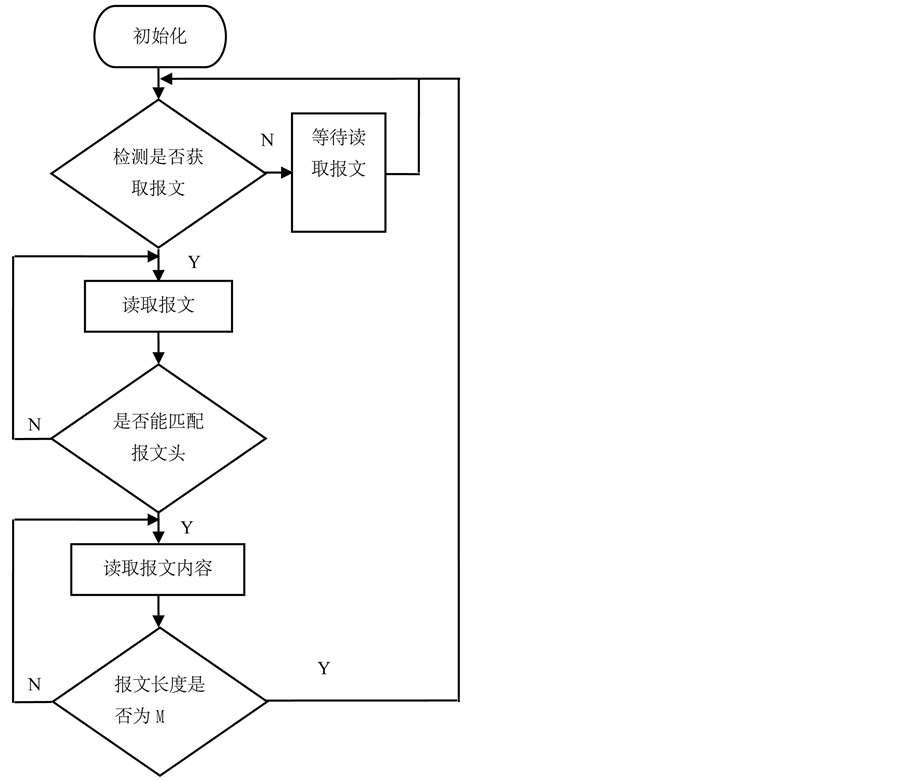
Figure 1. The past general flow chart for reading fixed-length message
图1. 以前固定长度报文的读取一般流程图
12) 预读取匹配到的第i个报文头后面长度为(n + m − 1)的报文内容,并同时对预读取的报文内容进行第i + 1个报文头检测,若未在预读取的报文内容中检测到完整可识别的第i + 1个报文头,则进行步骤13);若在预读的报文内中检测到可识别的第i + 1个报文头,则进行步骤14);
13) 把预读取的报文n后面的预读报文和后面获取的报文一起参加新的报文头匹配工作,匹配成功后令i =i + 1,重复步骤12),直至读取完成总报文的读取工作;
14) 令i = i + 1,重复步骤12),直至读取完成总报文的读取工作(图2)。
3.2. 报文格式中有报文尾
2) 对获取到的报文格式是是报文头、报文内容(固定长度的报文或非固定长度的报文)和报文尾组成的报文。
21) 对获取的报文进行报文头匹配,匹配成功后,令首先匹配得到的可识别报文头为第i = 1个报文头;
22) 读取第i个报文头后面的报文内容,在读取报文内容的同时检测在该报文中是否含有完整的报文尾,检测到完整的报文尾则进入步骤23),未检查到完整的报文尾就继续读取报文内容;
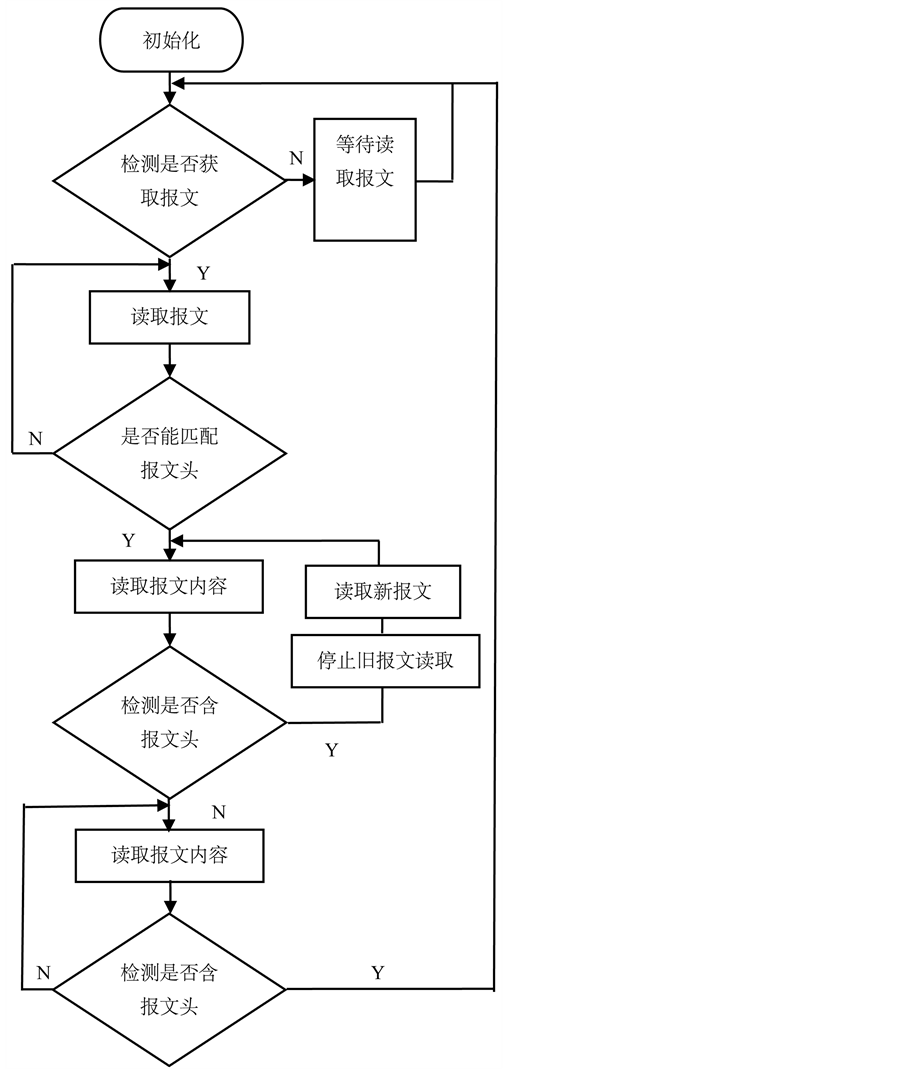
Figure 2. Flow chart for receiving the fixed-length message content
图2. 固定长度的报文内容的接收流程图
23) 匹配可识别的第i + 1个报文头,匹配成功后令i = i + 1,重复步骤22),直至读取完成整个总报文(图3)。
进一步说明的,上述报文头匹配是采用KMP [6] [7] 算法,对比普通的暴力字符串匹配算法,KMP算法是通过已经匹配成功的模式串子,然后移动找出最长的相同的前缀和后缀并使它们重叠,能够减少不必要的匹配次数,这样就能减少报文头的匹配时间和增加匹配效率。
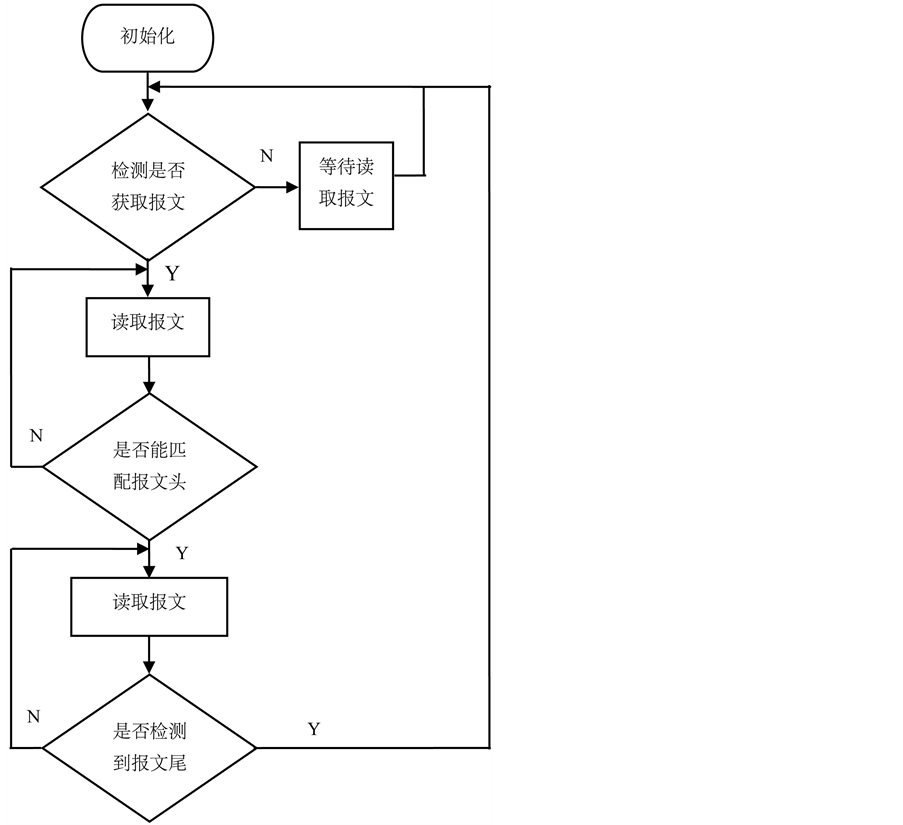
Figure 3. Flow chart for receiving message with packet tail
图3. 有报文尾的报文接收流程图
4. 实验及分析
某个定位设备,制定如下报文格式:
报文头:$GVPNG,
第一二三字节:时分秒
第五字节到第十二字节是:精度
第十三字节是:E代表east,W代表west
第十五字节到第二十字节是:纬度
第二十一字节是:N代表north,S代表south
1) 对于报文是由报文头和固定长度的报文内容组成时,其检测方法如下:
现在假设获取得到报文如下:
$GVPNG,112448,0121.4244422108E,21.24244428N, $GVPNG,054848,0144.21081E,24.544557S, $GV PNG,093231,0065.35566654E,89.3535 5599N
其中$GVPNG,是我们可识别的报文头,其长度为7个字节,报文内容长度n为21个字节,即一个报文的长度为28个字节,接收到的报文一共有3个报文。
用以前方法读取到的报文,只能读到2个报文内容,其中所读取的报文中第二个是无效报文。也就是只有1个报文是有效的。
用本文中的方法读取到有3个报文,其中第二个报文有丢包现象,其他报文都是有效报文。
用以前的处理方案读取报文的分析,第一个是被完全读取成功,第二个报文因发生丢包现象把第三个报文的报文头中的$G当成报文内容给读取了,在匹配第三个报文的报文头就无法匹配,所以第三个报文就因为没有完整的报文头读取。
用本文中的方案读取报文的分析,先匹配报文头,成功的预读取27个字节报文,并在预读取报文中没有发现完整的报文头,把预读报文内容第21个开始和后面一起参加下一个报文的报文头匹配,在第二个报文中当报文内容读取到了26字节后就检测到完整的报文头,那么停止预读报文内容,把检测到报文头后面的内容作为下一个报文的报文内容进行读取,之后向前面一样操作。
本文方法在报文接收的成功率比以前方法高,能够及时发现报文有没有发生丢包现象,及时停止丢包报文的读取,从而避免对下一组报文的报文头产生污染。
2) 对于报文格式是报文头、报文内容(固定长度报文内容或非固定长度的报文内容)和报文尾组成的报文。
$GPGSA,A,3,26,29,21,02,08,09,10,06,,,,,1.8,1.0,1.6*35\r\t$GPGSA,A,3,21,02,09,10,,,,,,,,,44.6,8.9,43.7*3C\r\t$GPGSA,A,3,26,29,21,02,08,09,10,06,,,,,1.8,1.0,1.6*35\r\t
在以前方法中是都是把有报文尾的报文内容固定长度和非固定长度分开读取,但是在本文中是把这两种报文的读取方法放到一起只要两种状态。接收到报文后就开始匹配报文头,一旦匹配成功,转入下一个状态读取报文内容,在读取报文的同时检查报文内容中是否含有报文尾,一旦检测到就重新匹配报文头。这样就可以在软件节简化很多。
5. 结论
本文提出了一种避免因丢包而损失连续两组报文的报文处理方法,该方法对于报文格式是报文头和固定长的报文内容所采用的步骤是在读取报文内容的同时检查在报文内容中是否包含完整报文头,这就可以检测出报文是否出现丢包现象,当检查到有丢包现象发生时就及时停止读取本段报文,然后将在检测到完整的报文头处所读取的报文内容作为下一个报文内容。对于报文格式是报文头、报文内容(固定长报文内容或非固定长报文内容)和报文尾采用的是在读取报文内容的同时检测是否含有报文尾,检测到就重新匹配报文头 [7] 。
本文提出的算法简单,在原有的程序上改动不是太大,但能及时的检测出丢包现象,防止对其他报文的读取产生不利影响。该方法既稳定又有效。
基金项目
“十二五”国家科技支撑计划(2013BAJ13B01)。
文章引用
姚荣亮,任阳,张小国,王庆. 一种避免因丢包而损失连续两组报文的数据处理方法
A Data Processing Method for Avoiding Loss of Continuous Two Packets due to Packet Loss[J]. 传感器技术与应用, 2016, 04(04): 117-123. http://dx.doi.org/10.12677/JSTA.2016.44014
参考文献 (References)
- 1. 谢刚. GPS原理与接收设计[M]. 北京: 电子工业出版社, 2009: 156.
- 2. 田立勤, 林闯. 报文分类技术的研究及其应用[J]. 计算机研究与发展, 2003, 40(6): 765-775.
- 3. Song, T., Li, D.-N., Wang, D.-S., et al. (2013) Memory Efficient Algorithm and Ar-chitecture for Multi-Pattern Matching. Journal of Software, 7, 1650-1665. (In Chinese)
- 4. Kaplan, E. (2006) Understanding GPS: Principles and Application. 2nd Edition, Artech House, Inc..
- 5. Kang, S., Song, I., Lee, Y., et al. (2006) Design and Implementation of a Multi-Gigabit Instruction and Virus/Worm Detection System. IEEE International Conference on Communications, Istanbul, 11-15 June 2006, 2136-2141.
- 6. 刘燕兵, 邵研, 王勇, 等. 一种面向大规模URL过滤的多模式配算法[J]. 计算机学报, 2014(5): 1159-1169.
- 7. 汤亚玲. KMP算法中next数组的计算方法研究[J]. 计算机技术与发展, 2009, 19(6): 98-101.