Computer Science and Application
Vol.06 No.11(2016), Article ID:19030,13
pages
10.12677/CSA.2016.611086
Research on Dynamic Clustering Algorithm Based on Spark Framework
Botao Zhang, Jianhua Li, Lei Fan
School of Information Security Engineering, Shanghai Jiao Tong University, Shanghai

Received: Nov. 4th, 2016; accepted: Nov. 21st, 2016; published: Nov. 24th, 2016
Copyright © 2016 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



ABSTRACT
In the era of big data, with the rapid growth of data size, the requirements of data processing increase constantly. It has put forward many effective algorithms for data stream clustering these years. However, with the continuous development of social technology, single machine environment has been difficult to meet the needs of data mining. Cluster environment is used more for information collection and data processing, the traditional clustering algorithm does not adapt well to the new processing requirements. This paper made some improvements from the data stream clustering algorithm D-Stream, used the big data processing framework Spark and designed a dynamic data clustering algorithm PDStream based on distributed architecture. The new algorithm is proved to be more efficient and able to perform dynamic clustering tasks under distributed architecture from the results of experiment.
Keywords:D-Stream, PDStream, Spark, Dynamic Clustering Algorithm

基于Spark的动态聚类算法研究
张伯涛,李建华,范磊
上海交通大学信息安全工程学院,上海

收稿日期:2016年11月4日;录用日期:2016年11月21日;发布日期:2016年11月24日

摘 要
针对数据流的聚类算法,近年来取得了有效的进展,出现了许多卓有成效的算法。随着信息采集技术的进步,需要处理的数据量越来越大,需要研究针对数据流的并行聚类算法。本文基于串行的数据流聚类算法D-Stream作出并行化改进,用通用的大数据处理框架Spark设计了一个基于分布式架构运行的动态数据聚类算法PDStream。实验结果表明,该算法具有更高的效率和良好的扩展性,能够实现分布式架构下的流数据动态聚类。
关键词 :D-Stream,PDStream,Spark,动态聚类算法

1. 引言
当今社会信息化的发展,在生物工程、新能源、企业医疗等新领域出现了海量的数据。由于这些数据持续不断产生,随着时间动态无限增长,近似呈现一种“流”的形态,因此此类数据被称为流数据。针对流数据进行数据挖掘是当前的热门课题。聚类作为数据挖掘领域的一个重要分支,一直以来倍受关注并得到了学者们广泛、深入的研究。它作为一种无监督的学习方式,在数据挖掘过程中能根据数据间的相似性将待处理对象划分为一个或若干个簇,在网络入侵检测、挖掘潜在客户和分析市场情况等方面具有重要应用。
针对流数据的聚类分析因其诸多特点变得相对困难,主要体现在三个方面:1) 低时空复杂度。数据流源源不断地产生且高速到达,它的海量、无限性要求算法不能够存储全部数据,每个数据项的处理也不能花费过长时间,算法在线处理速度应尽量和数据流的流速相匹配。2) 增量的处理新数据。由于流数据数量巨大,数据量未知,因此近乎不可能重复计算原有数据,算法必须能够在已有结果基础上增量处理新的数据。3) 正确、快速的处理离群点。数据流具有不断演化的特性,随着时间的推移数据流可能会不断地改变趋势,算法应能够清晰、快速地识别离群点,且对离群点做出正确的处理。
近年来,已经有许多优秀的流数据聚类算法诞生,他们有各自的处理要求和特点。CluStream [1] 算法是一个基于层次的流数据聚类算法,它首次将数据流的处理框架分为在线层和离线层,并引入聚类特征向量来表示聚簇,且采用预先定义的距离阈值来衡量数据项是否属于已知类。DenStream [2] 是一个基于密度的流数据聚类算法,该算法将满足一定密度阈值的数据点划分为一个簇,且能够发现球状簇,但该算法对输入参数敏感,参数的变化将严重影响聚类结果,且聚类过程中需要对每个数据对象进行邻域检查,因而计算时间复杂度较大。D-Stream [3] 是一个基于网格密度的算法,它将空间划分成一个个离散的网格,将进入系统中的数据映射到对应的网格中,然后操纵这些网格的信息,并将密度较大的相邻网格合并为一个聚簇。DENGRIS-Stream [4] 同样是一个基于网格密度的流数据聚类算法,但是它额外加入了滑动窗口,使得聚簇结果消除了历史数据的影响。ExCC [5] 是一个针对混合属性设计的算法,属性中包含数字和非数字,它对相邻网格的概念进行了重新定义,使得它适应非数字属性,并且依据数据流速的不同来决定消除历史数据的规模。FlockStream [6] 是一个基于密度的算法,它基于群体智能 [7] ,给每个输入数据指定一个代理,代理在一个提前定义好的虚拟空间中移动,当两个代理相遇则将他们合并为一个聚簇,该算法合并了在线层和离线层,在任何时间都可能生成新的聚簇。以上这些流聚类算法有各自适用的环境,在实际运用中需要针对业务的特点合理进行选择。
随着集群技术、并行计算与分布式计算的发展,Hadoop [8] 分布式计算框架和Spark [9] 内存计算框架等的广泛应用,为解决大规模流数据的实时挖掘带来了曙光。由于传统流聚类算法大都不适用分布式环境,本文提出了一种PDStream算法,它基于Spark中的Spark Streaming [10] 模块,对传统的数据流聚类算法D-Stream做出了相关改进,它保持了D-Stream算法的优越性,并在此基础上能够适应分布式环境。
2. 相关工作
2.1. 基于网格的流式聚类算法
假定数据空间 包含
包含 个维度,则
个维度,则 ,其中
,其中 表示第
表示第 维子空间。在D-Stream算法中,数据空间
维子空间。在D-Stream算法中,数据空间 划分为一个个网格,假定每个子空间
划分为一个个网格,假定每个子空间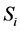 被划分为
被划分为 个部分,即
个部分,即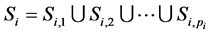 ,则整个数据空间
,则整个数据空间 可以划分的网格数为:
可以划分的网格数为: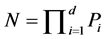 。
。
其中,网格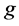 由
由 组成,
组成, ,网格
,网格 坐标定义为:
坐标定义为: 。
。
数据流中的数据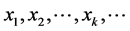 分别在时间
分别在时间 进入系统,数据
进入系统,数据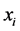 的时间戳为
的时间戳为 。其中每一个数据
。其中每一个数据 包含
包含 维数据,则数据
维数据,则数据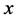 可以映射到网格
可以映射到网格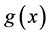 中,即
中,即
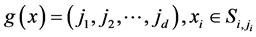
随着时间的推进,数据流输入的数据规模将非常庞大,历史数据的影响力依然存在。假定新数据的聚类更需要关心,历史数据的影响力需要逐渐变小,则有如下定义。
定义2.1:定义衰减系数 ,对于数据
,对于数据 ,它在时间
,它在时间 进入系统,则它在时间
进入系统,则它在时间 的密度系数为
的密度系数为

每个网格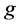 在时间
在时间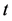 对应的密度系数为
对应的密度系数为 包含的所有数据
包含的所有数据 的密度系数之和,即
的密度系数之和,即

定义2.1定义了网格 关于时间
关于时间 的密度系数。对于每个时刻
的密度系数。对于每个时刻 ,如果网格
,如果网格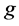 没有接受新的数据,则它的密度系数会进行衰减。如果网格
没有接受新的数据,则它的密度系数会进行衰减。如果网格 最后一次在
最后一次在 时刻接收了数据并更新了密度系数,在
时刻接收了数据并更新了密度系数,在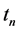 时刻
时刻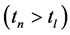 再次接收了一个数据,则密度系数
再次接收了一个数据,则密度系数 可被更新为
可被更新为
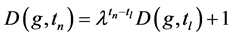
这样仅在网格接收新数据的时刻更新网格密度系数,节省了大量的计算时间,提高了效率。有了密度系数,对网格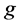 的密度进行划分是基于以下的观察:
的密度进行划分是基于以下的观察:
命题2.1让从0时刻到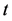 时刻到达的所有数据记录成为一个集合,则:
时刻到达的所有数据记录成为一个集合,则:
1) 
2) 
命题2.1表明系统中所有数据记录的密度总和永远不会超过 。由于存在
。由于存在 个网格,因此每个网格的平均密度不会超过
个网格,因此每个网格的平均密度不会超过 。基于这个观察,有以下定义:
。基于这个观察,有以下定义:
定义2.2在时刻 ,如果网格
,如果网格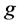 的密度系数满足:
的密度系数满足:
1) ,则网格
,则网格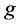 为稠密网格,它的status标签设为dense。其中,
为稠密网格,它的status标签设为dense。其中, 。
。
2) ,则网格
,则网格 为稀疏网格,它的status标签设为sparse。其中,
为稀疏网格,它的status标签设为sparse。其中, 。
。
3) ,则网格
,则网格 为过渡网格,它的status标签设为transitional。
为过渡网格,它的status标签设为transitional。
对网格的密度进行定义后,相邻的密度较大的网格将被合并到一个聚簇中,对于相邻网格有如下定义:
定义2.3考虑两个网格 和
和 ,如果存在
,如果存在 ,
, ,使得:
,使得:
1) ,
,
2) 
那么 和
和 被称为相邻网格,他们在第
被称为相邻网格,他们在第 维上相邻。
维上相邻。
2.2. D-Stream算法框架
D-Stream是一种典型的基于网格密度的聚类算法,它把空间区域 划分为一个个离散的网格,将新来的数据映射到对应的网格。这样不需要关心原始数据,只要对网格特征向量数据进行相关操作,最终得出聚类结果。D-Stream算法框架分为在线部分和离线部分,在线部分用于接收数据流,将数据对应的网格信息进行更新;离线部分定期取出在线部分的数据,通过聚类算法进行聚类和调整,最终将结果输出。
划分为一个个离散的网格,将新来的数据映射到对应的网格。这样不需要关心原始数据,只要对网格特征向量数据进行相关操作,最终得出聚类结果。D-Stream算法框架分为在线部分和离线部分,在线部分用于接收数据流,将数据对应的网格信息进行更新;离线部分定期取出在线部分的数据,通过聚类算法进行聚类和调整,最终将结果输出。
D-Stream在线部分负责接收数据流,更新数据所在网格的特征向量。对于每个网格的当前状态,在D-Stream算法中,有如下特征向量进行表示:
定义2.4网格 的特征向量为一个四元组:
的特征向量为一个四元组: ,代表含义分别为:
,代表含义分别为:
 :网格
:网格 最后接收到数据的时间。
最后接收到数据的时间。
 :即为
:即为 的值,记录网格
的值,记录网格 最后更新后的密度系数
最后更新后的密度系数
 :表示网格
:表示网格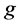 密度的划分,取值范围是
密度的划分,取值范围是
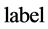 :表示网格的聚簇标签
:表示网格的聚簇标签
每当一个新数据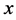 在
在 进入系统时,首先找到
进入系统时,首先找到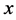 所属的网格
所属的网格 ,并更新网格
,并更新网格 加入数据
加入数据 后的特征向量:记录数据
后的特征向量:记录数据 的时间戳为
的时间戳为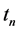 ,并依据
,并依据 更新网格
更新网格 的密度系数,同时将
的密度系数,同时将 更新为
更新为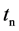 ,label依据
,label依据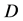 的值并对比阈值
的值并对比阈值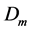 和
和 确定值为sparse、transitional或dense。这样,在线层完成了空间中网格特征向量的更新,为离线部分的聚类过程做好了准备工作。
确定值为sparse、transitional或dense。这样,在线层完成了空间中网格特征向量的更新,为离线部分的聚类过程做好了准备工作。
D-Stream算法的主要思想就是将密度较大的相邻网格连成聚簇,由于生成聚簇的计算量较大,实时维护一个聚类结果是相当困难的。基于这个事实,算法离线部分在每隔 时间,对聚簇结果进行一次维护。D-Stream的离线部分就是基于这个思想,考虑当前时间为
时间,对聚簇结果进行一次维护。D-Stream的离线部分就是基于这个思想,考虑当前时间为 ,在
,在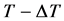 之前,算法已经维护了一个聚簇结果,而在
之前,算法已经维护了一个聚簇结果,而在 时间内,一批新的数据进入了系统,算法将这批数据对原有聚簇产生的影响增量地加入其中,产生新的聚簇结果。
时间内,一批新的数据进入了系统,算法将这批数据对原有聚簇产生的影响增量地加入其中,产生新的聚簇结果。
一个稠密网格长期不接受数据,可能会变成稀疏网格;一个稀疏网格接收一些新的数据,也可能升级为一个过渡网格或稠密网格,因此,一个关键点是决定离线部分生成聚簇的时间间隔 的长度,如果
的长度,如果 太大,那么数据流的动态变化不能很好地识别过来;如果
太大,那么数据流的动态变化不能很好地识别过来;如果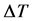 太小,则导致离线部分频繁计算从而增加了负载。因此,根据D-Stream [2] 中的描述使用以下命题来确定
太小,则导致离线部分频繁计算从而增加了负载。因此,根据D-Stream [2] 中的描述使用以下命题来确定 :
:
命题2.2:对任何稠密网格 ,从稠密网格成为一个稀疏网格所需的最少时间是
,从稠密网格成为一个稀疏网格所需的最少时间是 ;而对任何稀疏网格
;而对任何稀疏网格 ,从稀疏网格成为一个稠密网格所需的最少时间是
,从稀疏网格成为一个稠密网格所需的最少时间是 。
。
因此, 设置为
设置为 ,这样能够识别一个网格状态的任何变化。
,这样能够识别一个网格状态的任何变化。
2.3. Spark和Spark Streaming
Spark是加州大学伯克利分校的AMP实验室所开源的类似MapReduce的通用并行计算框架,它拥有MapReduce的优点,并且由于Spark将中间计算结果的读写操作都在内存中进行,从而不需要读写HDFS,也不负责数据的存储,这样能够更好地优化迭代MapReduce工作的负载。
Spark对于数据的处理是基于弹性数据集RDD,它是一个不可变的带分区的记录集合。Spark为RDD提供了两类操作:转换和动作,转换是对原有的RDD进行一些变换来生成一个新的RDD,而动作则是返回一个结果。一个job可以拆分成RDD经过一系列的变换操作得到最终的结果,也就是可以拆分成RDD组成的有向无环图DAG (如图1),并将这个DAG作为一个job提交给Spark执行。
Spark Streaming是一种构建在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力,它的基本原理是将输入数据流以时间片 为单位拆分成块,然后以类似Spark批处理的方式将每块数据作为RDD生成一个job进行处理,最终结果也返回多块。
为单位拆分成块,然后以类似Spark批处理的方式将每块数据作为RDD生成一个job进行处理,最终结果也返回多块。
Spark Streaming具有高容错性,每一批输入到RDD中的数据都会在内存中备份,当某个结点发生故障导致数据丢失时,Spark Streaming计算框架会找到备份的数据并在其他结点上重新计算得到最终的结果。
随着大数据的发展,人们对大数据处理提出了更高的要求。原有的批处理框架MapReduce由于其所有中间结果数据的读写都需要经过HDFS文件系统,因此启动一次job的代价很高,难以满足实时性要求。而Spark Streaming是Spark处理流式数据的框架,使用基于内存的Spark作为执行引擎,具有高速的执行效率和极低的延迟,对流数据的处理有极好的支持。
3. 分布式流聚类算法PDStream设计
结合Spark Streaming框架和D-Stream算法,本节提出一种基于分布式环境下的流数据聚类算法 PDStream。该算法将数据空间 划分为不同的块,对每个块运用D-Stream算法进行处理,得到该块的聚簇结果,最后将所有块的聚簇进行合并,生成最终的聚簇结果。
划分为不同的块,对每个块运用D-Stream算法进行处理,得到该块的聚簇结果,最后将所有块的聚簇进行合并,生成最终的聚簇结果。

Figure 1. Execution of spark job
图1. Spark Job执行过程
3.1. 相关定义
定义3.1数据空间 包含
包含 个维度,
个维度, ,而对每个子空间
,而对每个子空间 的一个连续子集
的一个连续子集 ,
, 可以组成一个较小的数据空间
可以组成一个较小的数据空间 ,该空间被定义为块。
,该空间被定义为块。
定义3.2 块 在
在 维空间中可以表示为
维空间中可以表示为 ,将每个子空间
,将每个子空间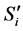 划分为
划分为 个部分,则整个块
个部分,则整个块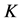 可以划分的网格数为
可以划分的网格数为 。设
。设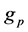 表示块
表示块 中的网格
中的网格 在第
在第 个维度的相邻网格数,
个维度的相邻网格数, 。若存在
。若存在 ,则
,则 是块
是块 的一个边界网格。
的一个边界网格。
定义3.3 若构成块 和块
和块 的第
的第 维子空间
维子空间 和
和 在第
在第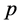 维上相邻,则块
维上相邻,则块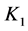 和块
和块 是相邻块。
是相邻块。
3.2. PDStream算法流程
在算法运行之前,将空间 划分为
划分为 个互不相交的块,即
个互不相交的块,即 ,
, ,
, 。对每个块
。对每个块 分别运行D-Stream算法。PDStream算法流程如算法1。
分别运行D-Stream算法。PDStream算法流程如算法1。
对于块 处理模块,运行D-Stream算法,它分为在线层和离线层。在线层
处理模块,运行D-Stream算法,它分为在线层和离线层。在线层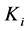 _online_component负责接收数据,保存网格的特征向量;离线层
_online_component负责接收数据,保存网格的特征向量;离线层 _offline_component每隔
_offline_component每隔 时间生成
时间生成 内部的聚簇。当所有块
内部的聚簇。当所有块 的聚簇生成完毕后,所有分块
的聚簇生成完毕后,所有分块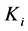 的聚簇结果需要进行合并,合并算法过程如算法2。
的聚簇结果需要进行合并,合并算法过程如算法2。
Algorithm 1. PDStream
算法1. PDStream
Algorithm 2. Merge sub-clustering
算法2. 合并分块聚簇
3.3. 基于并查集的优化
应当注意到,算法中经常涉及到将两个聚簇进行合并或者将某个网格合并到聚簇的操作。在实际代码编写中,每个网格需要设置它所属的聚簇标签,当需要将聚簇c1合并到c2中时,程序会将c1中所有的网格所属的聚簇标签修改为c2,当这样的操作一旦大量增加,将会成为算法的瓶颈。使用并查集可以对上述操作进行优化,避免大量的修改。并查集是一种森林结构,用于处理一些不相交集合的合并及查询问题,核心思想是用一个代表元素表示集合中的所有元素,即森林中每棵树的根结点表示该树的所有结点,并且进行查找操作时可以进行路径压缩,将查找路径中每个结点直接连接至该树的根节点,提高再次查找的效率。当需要将结点 和结点
和结点 合并至一个集合时,先找到结点
合并至一个集合时,先找到结点 的祖先结点
的祖先结点 和结点
和结点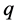 的祖先结点
的祖先结点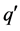 ,将
,将 变为
变为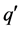 的孩子结点,这样就将两颗树代表的集合进行了合并,新树的根
的孩子结点,这样就将两颗树代表的集合进行了合并,新树的根 节点即为集合合并后的代表结点。
节点即为集合合并后的代表结点。
如图2,有三个块: ,
,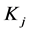 和
和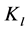 ,其中块
,其中块 中有聚簇c1、c2,
中有聚簇c1、c2, 中有聚簇c3、c4、c5,
中有聚簇c3、c4、c5,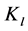 中有聚簇c6、c7。
中有聚簇c6、c7。
首先对于每个块内的聚簇,在森林F中生成自身结点进行初始化,表示每个聚簇自成一个集合。在进行相邻块聚簇的合并操作时,对于块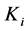 ,遍历它的右边边界网格时,发现聚簇c2和相邻块
,遍历它的右边边界网格时,发现聚簇c2和相邻块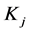 中的c3可以进行合并,于是在F中找到c2和c3,通过并查集的查找操作发现他们的祖先就是本身,并且并不属于同一个集合,则可将c2作为c3的孩子结点,表示聚簇c2和c3已经进行了合并,合并后的聚簇代表元为c3。在遍历块
中的c3可以进行合并,于是在F中找到c2和c3,通过并查集的查找操作发现他们的祖先就是本身,并且并不属于同一个集合,则可将c2作为c3的孩子结点,表示聚簇c2和c3已经进行了合并,合并后的聚簇代表元为c3。在遍历块 下方的边界网格时,再次发现聚簇c2可以和块
下方的边界网格时,再次发现聚簇c2可以和块 中的c6进行合并,于是在森林F中找到c2,将c6变为c2的孩子节点。再次查找c6的祖先结点时,通过路径压缩可以直接把c6变为c3的孩子结点。上述过程如图3所示。
中的c6进行合并,于是在森林F中找到c2,将c6变为c2的孩子节点。再次查找c6的祖先结点时,通过路径压缩可以直接把c6变为c3的孩子结点。上述过程如图3所示。

Figure 2. Clusters in blocks
图2. 块中生成的聚簇
下面给出算法伪代码。在分块合并前,需要将所有块中的聚簇以结点形式加入到F中,以此来对F进行初始化,伪代码如算法3。
初始化工作完成后,分属不同块的聚簇需要进行合并,下面给出将块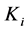 中的聚簇
中的聚簇 和块
和块 中的聚簇
中的聚簇 合并的过程(算法4)。
合并的过程(算法4)。
该算法的第一行调用了FindRoot函数,该函数可以查找一个节点所在树的根节点。在利用树结构递归查找根节点的同时,可以使用路径压缩技术进行优化,将该路径上的所有结点直接变为该树根结点的孩子。下面给出该函数伪代码(算法5)。
完成所有的合并操作后,F中树的个数即为最终形成的聚簇数,最后结合F将聚簇结果输出。

Figure 3. Use union find to merge clusters
图3. 并查集合并聚簇
Algorithm 3. Init (clusters_List)
算法3. 并查集初始化
Algorithm 4. Merge (p,q)
算法4. 合并聚簇(p,q)
Algorithm 5. Find Root (p)
算法5. 寻找树根(代表元)
4. 实验结果
PDStream算法运行在分布式环境下,该环境使用三台机器构建一个集群,机器的硬件环境为4核CPU处理器,16G内存,在集群无其他任务运行的条件下进行实验。Spark框架支持多种语言接口,我们使用java语言编写Spark Job,并提交到集群中运行。在下面进行的所有实验中参数设置保持一致: ,
, ,
,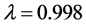 。
。
4.1. 实验数据
我们使用两份数据集进行实验。第一份是一个真实的数据集KDD-CUP 99 [11] ,由MIT林肯实验室在1998年美国国防部高级规划署建立了模拟美国空军局域网的一个网络环境,收集了9周时间的 TCP连接数据,仿真各种用户类型、各种不同的网络流量和攻击手段,使它就像一个真实的网络环境。这些原始数据被分为两个部分:7周时间的训练数据,以及2周时间的测试数据,这些数据可以测试聚类算法的准确度。林肯实验室主页上提供的数据集有500,000条连接记录,这个数据集中包含5个聚簇,每个聚簇代表着一类异常连接或正常连接记录,分别是DOS,R2L,U2R,PROBING以及NORMAL,每一条连接记录中包含42个属性。根据 [3] ,将其中的34个连续的属性作为聚类的输入,最终聚簇结果应当为5,我们将运行PDStream算法验证结果的正确性。
另一份数据集是人工生成的二维数据集,为了与D-Stream算法进行对比,我们模拟 [3] 中使用的人工数据集,数据量为85K,聚簇数量设置为4。这个数据集主要用来观察PDStream输出的聚簇结果是否准确,并且是否可以消除历史数据的影响。
4.2. 聚类的准确度
首先使用KDD-CUP 99作为实验数据集,将它分别运行单机运行D-Stream算法、单机运行PDStream算法、多线程运行PDStream算法。如图4,可以看出在单机情况下PDStream和D-Stream正确率保持一致,而在分布式多线程环境下,PDStream算法的正确率依然能够得到保证,并且可以从图中看出,随着线程的增加,准确度并没有明显提高,线程数为2的时候甚至会下降,这说明块的划分数目、划分方式以及聚簇的分布对算法结果有着很大的影响。
在人工数据集中,一台机器上以4个线程运行PDStream算法,数据量为85 K,以1 K/s的速率将数
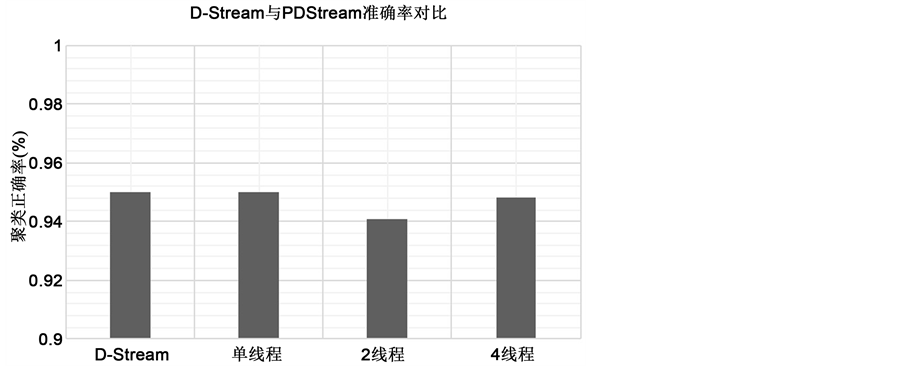
Figure 4. Accuracy comparison of D-Stream and PDStream
图4. D-Stream与PDStream准确率对比
据传入系统,数据集如图5所示,将区域分为4个聚簇。
为了验证算法可以显示聚簇随着时间动态变化的准确性,首先不加入衰减,输出最后的聚类结如图6所示,从图中可以清楚地看到数据形成了4个聚簇。
现在再次运行算法,并在其中加入衰减参数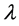 ,选取t = 10 s、t = 50 s、t = 85 s三个时间点来观察聚簇的生成情况,分别如图7、图8、图9所示。观察这几幅图可以发现,由于衰减的存在,数据流的聚簇结果会随着时间发生变化,消除了历史数据的影响。从图中还可以很直观地看到PDStream聚类算法能够得到当前时间正确的聚类结果,验证了算法的准确性。
,选取t = 10 s、t = 50 s、t = 85 s三个时间点来观察聚簇的生成情况,分别如图7、图8、图9所示。观察这几幅图可以发现,由于衰减的存在,数据流的聚簇结果会随着时间发生变化,消除了历史数据的影响。从图中还可以很直观地看到PDStream聚类算法能够得到当前时间正确的聚类结果,验证了算法的准确性。

Figure 5. Artificial datasets including four clusters
图5. 包含四个聚簇的人工数据集

Figure 6. Result of clustering without attenuation
图6. 无衰减下的聚簇结果

Figure 7. Result of clustering at t = 10 s
图7. t = 10 s时聚簇结果
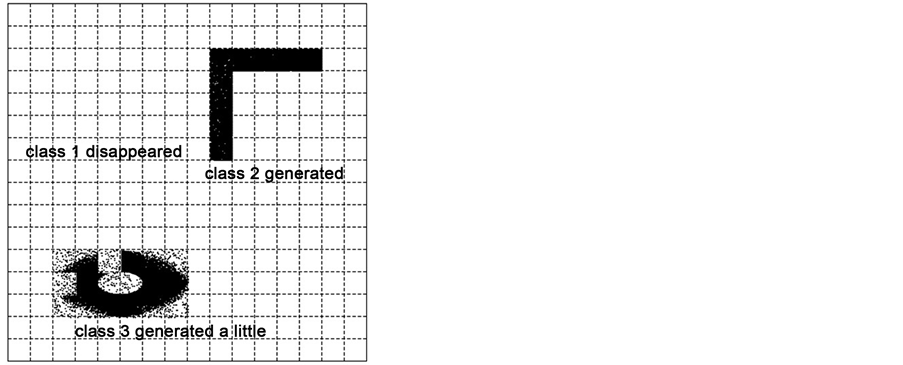
Figure 8. Result of clustering at t = 50 s
图8. t = 50 s时聚簇结果

Figure 9. Result of clustering at t = 85 s
图9. t = 85 s时聚簇结果
4.3. 性能表现
由于加入了基于并查集的优化,PDStream的运行效率较D-Stream得到了显著提升。在KDD-CUP 99数据集上分别运行单机运行D-Stream算法和PDStream算法,记录不同数据量下生成聚簇的时间,如图10所示。从图中可以看出,随着数据量的增多,PDStream在时间效率上的优势越明显。
观察多线程下PDStream的性能表现,在人工数据集中分别以单线程、2线程、4线程、8线程运行PDStream算法,统计不同数据量下聚簇的生成时间,如图11所示。
从图中可以看出,随着线程的增加,聚簇生成的时间明显缩短,在数据量达到85K时,2线程相比单线程运行时间上缩短了接近20%,而4线程缩短了40%,可见分布式环境下分块中运行聚簇算法使得效率得到提升。但由于本文所用的人工数据集聚簇较少,数据空间较小,并且随着线程数目的增加,块的划分数目变多,块之间聚簇的合并操作成了算法新的瓶颈,因此从图中可看出8线程较4线程环境下的时间效率并无提升,反而有所下降,可见针对不同规模的数据集,需要根据实际情况合理规划线程数,使得算法达到最理想的运行效果。

Figure 10. Efficiency comparison of D-Stream and PDStream
图10. D-Stream与PDStream效率对比
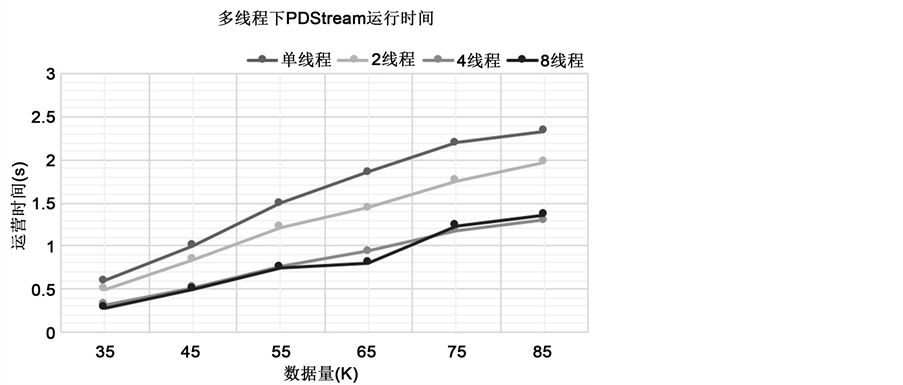
Figure 11. PDStream execution time in multithread
图11. 多线程下PDStream运行时间
5. 总结
本文设计了一种基于Spark Streaming的分布式流聚类算法PDStream,该算法在D-Stream的基础上,对数据集进行了分块并行处理,在聚类结果得到保证的情况下,加入了基于并查集的优化算法,极大地提高了算法的运行效率。实验结果表明PDStream在运行效率上相比D-Stream有较大的提高,并能适用于分布式环境,从而说明了PDStream算法的可行性。
基金项目
上海市科委基础研究重点项目(13JC1403501)。
文章引用
张伯涛,李建华,范 磊. 基于Spark的动态聚类算法研究
Research on Dynamic Clustering Algorithm Based on Spark Framework[J]. 计算机科学与应用, 2016, 06(11): 715-727. http://dx.doi.org/10.12677/CSA.2016.611086
参考文献 (References)
- 1. Aggarwal, C.C., Han, J., Wang, J., et al. (2003) A Framework for Clustering Evolving Data Streams. Vldb, 29, 81-92. https://doi.org/10.1016/b978-012722442-8/50016-1
- 2. Cao, F., Ester, M., Qian, W., et al. (2006) Density-Based Clustering over an Evolving Data Stream with Noise. Siam International Conference on Data Mining, Bethesda, 20-22 April 2006, 328-339.
- 3. Chen, Y. and Tu, L. (2007) Density-Based Clustering for Real-Time Stream Data. ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Jose, August 2007, 133-142.
- 4. Amini, A. (2012) DENGRIS-Stream: A Density-Grid Based Clustering Algorithm for Evolving Data Streams over Sliding Window. International Conference on Data Mining and Computer Engineering.
- 5. Bhatnagar, V., Kaur, S. and Chakravarthy, S. (2014) Clustering Data Streams Using Grid-Based Synopsis. Knowledge & Information Systems, 41, 127-152. https://doi.org/10.1007/s10115-013-0659-1
- 6. Forestiero, A., Pizzuti, C. and Spezzano, G. (2013) A Single Pass Algorithm for Clustering Evolving Data Streams Based on Swarm Intelligence. Data Mining & Knowledge Discovery, 26, 1-26. https://doi.org/10.1007/s10618-011-0242-x
- 7. Eberhart, R.C. (2001) Swarm Intelligence.
- 8. Hadoop, W.T. (2010) The Definitive Guide. O’reilly Media Inc Gravenstein Highway North, 215, 1-4.
- 9. Zaharia, M., Chowdhury, M., Franklin, M.J., et al. (2010) Spark: Cluster Computing with Working Sets. 10.
- 10. 夏俊鸾, 邵赛赛. Spark Streaming: 大规模流式数据处理的新贵[J]. 程序员, 2014(2): 44-47.
- 11. 张新有, 曾华燊, 贾磊. 入侵检测数据集KDD CUP99研究[J]. 计算机工程与设计, 2010, 31(22): 4809-4812.