Geographical Science Research
Vol.05 No.02(2016), Article ID:17681,19
pages
10.12677/GSER.2016.52012
Study on Relationship between Natural and Social Factors and Placenames Named in Yi Nationality Language in Yunnan Province
Wujun Xi
School of Geography and Tourism Management, Chuxiong Normal University, Chuxiong Yunnan

Received: May 6th, 2016; accepted: May 24th, 2016; published: May 27th, 2016
Copyright © 2016 by author and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



ABSTRACT
In order to explore relationship between natural and social factors and placenames named in Yi nationality language in Yunnan province, the paper used correlation analysis, automatic linear modeling and spatial regression analysis methods to analyze it, then these conclusions could be drawn as follows. 1) From the correlation analysis and regression analysis results, the importance of natural and social factors were arranged in descending order: the distance between placenames named in Yi nationality language and railway, elevation, the distance between placenames and road, the distance between placenames and agricultural land, the distance between placenames and main cities, the distance between placenames and water system, slope. 2) From the spatial regression analysis results, GDP, real GDP per capita, annual mean temperature, annual precipitation, education years’ per-capita, illiteracy rate, adult literacy rate and size of Yi population were negatively correlated to the number of placenames named in YI nationality language. The value- added of the primary industry, value-added of secondary industry, value-added of the tertiary industry, number of beds in medical institutions and total population were positively correlated to the number of placenames named in Yi nationality language. And the number of beds in medical institutions and annual precipitation passed the significance test, this indicated the counties and cities that had more placenames named in Yi nationality language had more beds in medical institutions, they had relatively good medical conditions, however, their annual precipitation was relatively little.
Keywords:Placenames Named in Yi Nationality Language, Natural and Social Factors, Correlation Analysis, Automatic Linear Modeling, Spatial Regression

云南省彝语地名与自然社会因子的 关系分析
席武俊
楚雄师范学院地理科学与旅游管理学院,云南 楚雄

收稿日期:2016年5月6日;录用日期:2016年5月24日;发布日期:2016年5月27日

摘 要
为探究云南省彝语地名与自然社会因子的关系,采用相关分析、自动线性建模、空间回归等方法进行不同侧面的分析。分析结果如下:1) 从相关分析与回归分析结果来看,各项自然社会因子重要性从大到小依次排列为:彝语地名与铁路距离、高程、彝语地名与道路距离、彝语地名与农用地距离、彝语地名与主要城市距离、彝语地名与水系距离、坡度。2) 从空间回归结果看,地区生产总值、人均GDP、年均温、年降水量、人均受教育年限、文盲率、成人识字率、彝族人口数量与彝语地名数量成负相关。第一产业增加值、第二产业增加值、第三产业增加值、医疗机构床位数、总人口与彝语地名数量成正相关。医疗机构床位数、年降水量通过显著性检验,表明彝语地名数量多的县市区医疗机构床位数相对也多,医疗条件相对较好;彝语地名数量多的县市区降水量相对较少。
关键词 :彝语地名,自然社会因子,相关分析,自动线性建模,空间回归

1. 引言
彝族主要分布于我国西南云贵川桂四省,四省共有3个彝族自治州,19个彝族自治县 [1] 。彝族人民在长期生产生活中产生了众多彝语地名,参照王冠雄研究 [2] 可以定义为彝语地名是用彝语命名的地名,用彝族人的思维方式命名、体现彝族文化内涵的地名,是彝人借以识别和称谓居地的地理实体的语言代号 [3] 。
国内近几年对地名进行空间分布研究的案例渐多 [4] - [10] ,但对地名空间分布影响因子或与地物关系的研究较少,对少数民族语地名研究的更少。地名空间分布影响因子或与地物关系的传统定性研究主要从经济、军事、行政、政治社会因素 [11] 、气候、民族文化、民族政策 [12] 等方面分析,定量研究主要有王法辉等采用回归及因子分析法对广西壮语地名的影响因子进行分析的案例 [13] 。
为进一步研究地名空间分布与自然社会因子的关系,本文使用相关分析、自动线性建模过程工具和空间回归方法对云南省彝语地名空间分布与自然社会因子的关系进行量化分析,以期得到更为清晰的认识。其中空间回归方法尚未发现有用于地名的研究。另外,因为彝语地名数据分为点状及面状数据(拥有彝语地名的县市图),自然社会因子数据也有点状及面状区分,故分为基于点数据的云南省彝语地名与自然社会因子的关系分析和基于面数据的云南省彝语地名与自然社会因子的关系分析,两部分分析内容并不相同。
2. 云南省彝族地名数据来源及认定
云南省彝语地名数据来源于《中华人民共和国地名词典——云南省》 [14] 中所列出县以上政区名、县以下镇名及重要居民点名2884条,经过筛选得到彝语地名288条,占9.99%。其中8条无法查到坐标,故参与后续分析的为276条彝语地名。彝语地名的认定包括以下几种情况:原为彝语,现依然为彝语的;原为彝语,后简化雅化的;原为彝语,后改名的。其中第一类数量占绝大部分。后两类数量较少。另外,在认定彝语地名时,对同一小区域部分2至3个类似名字的彝语地名,只保留行政级别最大一个,若是相同行政级别,则随机保留一个。例如大莫古乡和小莫古,保留大莫古乡,雨龙乡和雨龙街,保留雨龙乡等。
3. 技术路线
本研究技术路线图如图1所示。
4. 基于点状数据的云南省彝族地名与自然社会因子的相关分析
4.1. 相关分析自然社会因子及数据准备
4.1.1. 参与分析的自然社会因子
除地名本身数据的进一步处理外,此处分析包括海拔、坡度、彝语地名与道路的距离、彝语地名与铁路的距离、彝语地名与水系的距离、彝语地名与主要城市的距离、彝语地名与农用地的距离。
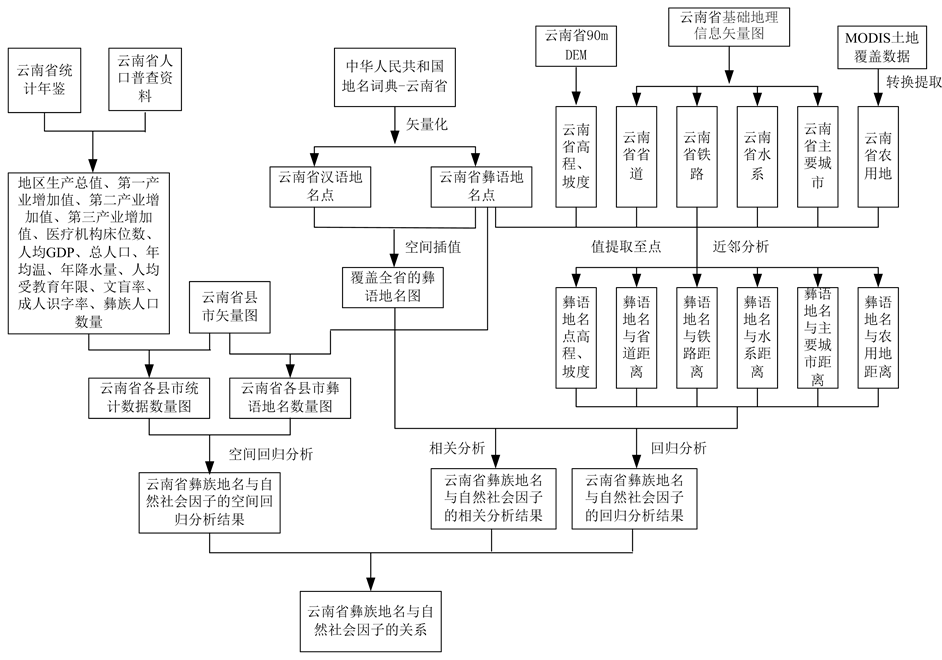
Figure 1. Technology roadmap
图1. 技术路线图
4.1.2. 数据准备
1) 地名数据的准备
因为要分析地名和其他自然社会因子之间的关系,彝语地名坐标数据显然不能直接使用。需要插值成一个铺满整个云南省的地名数据,才能从中使用彝语地名坐标位置来提取数据。简要处理过程为:a) 将《中华人民共和国地名词典——云南省》中所列出的汉语地名按照彝语地名处理方法加入坐标,并做为矢量图。b) 将汉语地名矢量图和彝语地名矢量图合并为汉彝地名图。c) 参照王冠雄方法 [2] 并适当调整,在图层属性表中建立新字段,彝语地名属性设为1,汉语地名设为0,为空间插值打下基础。d) 用克里金插值法对云南省彝语地名、汉语地名进行插值,得到覆盖全省的地名图(图2)。e) 然后用ArcGIS10.2(下同)中的值提取至点工具提取彝语地名点克里金值数据。
2) 海拔数据的准备
海拔数据直接提取自云南省90 mDEM数据(图3),该数据来源于中国科学院计算机网络信息中心地理空间数据云(http://www.gscloud.cn)。
3) 坡度数据的准备
坡度数据提取自以云南省90mDEM数据为基础得到的坡度图(图4)。然后用值提取至点工具提取彝语地名点坡度数据。
4) 彝语地名与道路距离的准备
道路数据来源于云南省省道矢量数据(图5)。在ArcGIS中使用近邻分析工具得到每一个彝语地名距离道路的最短距离。
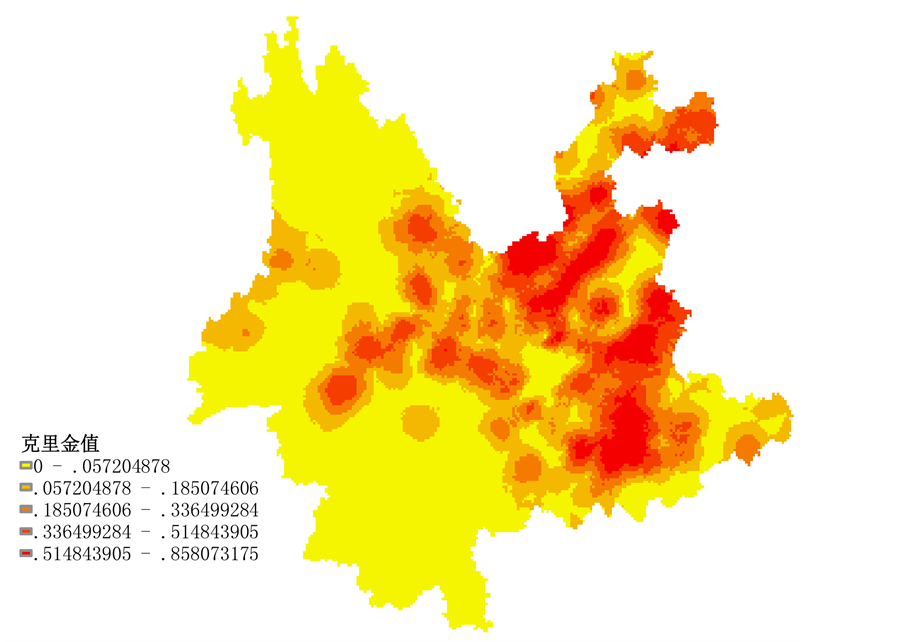
Figure 2. The kriging values of placenames named in Yi nationality language in Yunnan Province
图2. 云南省彝语地名克里金值

Figure 3. 90 m DEM of Yunnan Province
图3. 云南省90 m DEM
5) 彝语地名与铁路距离的准备
铁路网采用中国国家基础地理信息系统数据中的主要铁路文件,数据为1:400万国家基础地理信息系统数据。在ArcGIS中使用裁剪工具得到云南省铁路图(图6)。然后使用近邻分析工具得到每一个彝语地名距离铁路的最短距离。
6) 彝语地名与水系距离的准备
将云南省河流、湖泊、水库矢量图合并到一个空图层中即得到水系图(图7)。然后使用近邻分析工具得到每一个彝语地名距离铁路的最短距离。
7) 彝语地名与主要城市的距离
因为彝语地名形成时间较早,所以选择了云南省目前通过国务院认定的六大国家级历史文化名城(昆明、大理、丽江、建水、巍山和会泽)作为主要城市。接着从云南省省市区县政府矢量图中导出主要城市图(图8)。然后使用近邻分析工具得到每一个彝语地名距离主要城市的最短距离。
8) 彝语地名与农用地距离的准备
农用地数据采用美国宇航局(NASA)提供的MODIS卫星的三级数据土地覆盖类型产品。简要处理过程如下:a) 下载NASA目前提供的最新2013年500 m三级数据土地覆盖类型产品,云南省需要2景影像才能覆盖。该产品采用五种不同的土地覆盖分类方案,信息提取主要技术是监督决策树分类。五个分类方案如下:IGBP的全球植被分类方案、美国马里兰大学(UMD格式)方案、基于MODIS叶面积指数/光合有效辐射方案、基于MODIS衍生净初级生产力(NPP)方案、植物功能型(肺功能)方案。本研究选用最

Figure 4. The slope of Yunnan province
图4. 云南省坡度
常用的IGBP的全球植被分类方案,其第12类为农用地。b) 使用MRT软件将2景影像重投影,并将按照IGBP的全球植被分类方案得到的数据导出为GeoTIFF格式。c) 使用ArcGIS中的合并工具将2景GeoTIFF格式的影像拼接为一幅影像,并裁剪为云南省土地覆盖图。d) 将云南省土地覆盖图由栅格数据转为矢量数据(图9)。e) 提取农用地数据得到云南省农用地图(图10)。
然后使用近邻分析工具得到每一个彝语地名距离农用地的最短距离。
将彝语地名克里金值、彝语地名海拔、彝语地名坡度、彝语地名与道路的距离、彝语地名与铁路的距离、彝语地名与水系的距离、彝语地名与主要城市的距离、彝语地名与农用地的距离分别导出到EXCEL,得到云南省彝语地名与自然社会因子的相关分析数据表(因为内容太多,故在文中略去)。

Figure 5. The provincial highway in Yunnan Province
图5. 云南省省道

Figure 6. The railway in Yunnan Province
图6. 云南省铁路

Figure 7. The water system in Yunnan Province
图7. 云南省水系
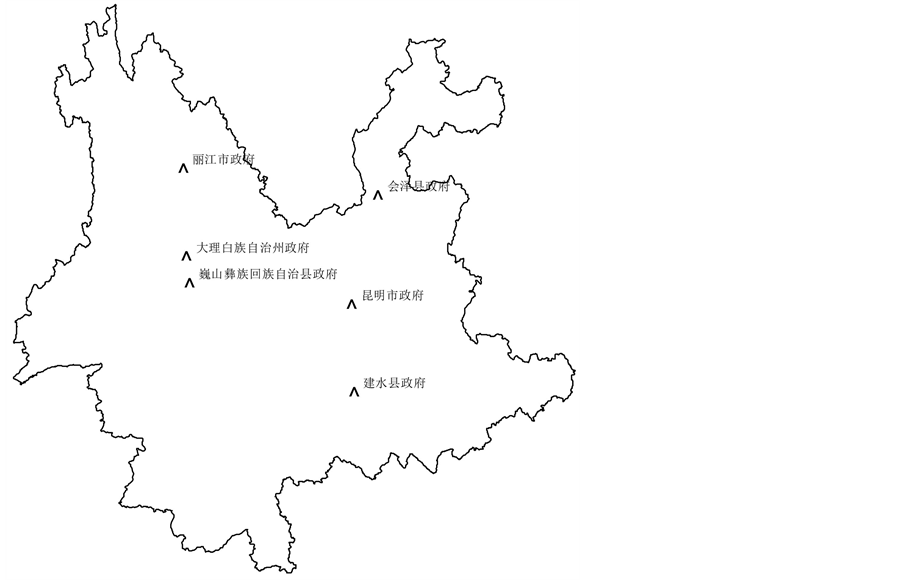
Figure 8. The main cities inYunnan Province
图8. 云南省主要城市
Figure 9. The land cover inYunnan Province
图9. 云南省土地覆盖图

Figure 10. The agricultural land inYunnan Province
图10. 云南省农用地图
4.2. 云南省彝族地名与自然社会因子相关分析
任何事物的变化都有其他事物是相互联系和相互影响的,用于描述事物数量特征的变量之间自然也存在一定的关系。衡量事物之间相关程度的强弱并用适当的统计指标表示出来,这个过程就是相关分析 [15] 。
连续变量的相关指标一般采用积差相关系数,又称为Pearson相关系数来表示其相关性的大小。但由于Pearson相关系数适用条件较高,要求x,y都要服从正态分布,有时难以满足。此时可以选择秩相关系数,即Spearman相关系数。它是利用两变量的秩次大小进行相关分析的,对原始变量的分布不作要求,属于非参数统计方法。因此它的适用范围较Pearson相关系数要广得多。即使原始数据是等级资料也可以计算Spearman相关系数,但统计效能比Pearson相关系数要低一些 [16] 。
将彝语地名克里金值分别与彝语地名海拔、彝语地名坡度、彝语地名与道路的距离、彝语地名与铁路的距离、彝语地名与水系的距离、彝语地名与主要城市的距离、彝语地名与农用地的距离在SPSS20中一一进行Spearman相关分析,得到以下结果(表1~7)。
从表1中可见,彝语地名及其与铁路距离的相关性呈现为负相关,但是关系较弱,为−0.255,且在置信度(双测)为0.01时,相关性是显著的。说明铁路附近彝语地名数量较少,而远离铁路则彝语地名数量较多。
从表2中可见,彝语地名及其与道路距离的相关性呈现为正相关,但是关系较弱,为0.201,且在置信度(双测)为0.01时,相关性是显著的。说明道路(省道)附近彝语地名数量较多,而远离道路则彝语地名数量较少,彝语地名具有一定的道路可达性。
从表3中可见,彝语地名及其与水系距离的相关性呈现为负相关,但是关系微弱,为−0.076。说明水系附近彝语地名数量相对较少,而远离水系则彝语地名数量相对较多,彝语地名未体现出驱水性,也从侧面表明彝族居住环境并未拥有较大水域。
从表4中可见,彝语地名及其与农用地距离的相关性呈现为负相关,但是关系微弱,为−0.055。说明农用地附近彝语地名数量相对较少,而远离农用地则彝语地名数量相对较多,也从侧面表明彝族居住环境并未拥有较大农用地。

Table 1. Correlation analysis result of placenames named in Yi Nationality Language and the distance between placenames and railway
表1. 彝语地名及其与铁路距离的相关分析结果
**在置信度(双测)为0.01时,相关性是显著的。
Table 2. Correlation analysis result of placenames named in Yi Nationality Language and the distance between placenames and road
表2. 彝语地名及其与道路距离的相关分析结果
**在置信度(双测)为0.01时,相关性是显著的。
Table 3. Correlation analysis result of placenames named in Yi Nationality Language and the distance between placenames and water system
表3. 彝语地名及其与水系距离的相关分析结果
Table 4. Correlation analysis result of placenames named in Yi Nationality Language and the distance between placenames and agricultural land
表4. 彝语地名及其与农用地距离的相关分析结果
Table 5. Correlation analysis result of placenames named in Yi Nationality Language and the distance between placenames and main cities
表5. 彝语地名及其与主要城市距离的相关分析结果
Table 6. Correlation analysis result of placenames named in Yi Nationality Language and elevation
表6. 彝语地名及其与地名点高程的相关分析结果
**在置信度(双测)为0.01时,相关性是显著的。
Table 7. Correlation analysis result of placenames named in Yi Nationality Language and slope
表7. 彝语地名及其与地名点坡度的相关分析结果
从表5中可见,彝语地名及其与主要城市距离的相关性呈现为正相关,但是关系微弱,为0.006。说明彝语地名一定程度上相对靠近主要城市。
从表6中可见,彝语地名与地名点高程的相关性呈现为正相关,但是关系较弱,为0.216,且在置信度(双测)为0.01时,相关性是显著的。说明一定范围内高程越高彝语地名数量较多,而高程越低则彝语地名数量较少,表明彝语地名分布在相对较高的地方。
从表7中可见,彝语地名与坡度的相关性呈现为负相关,但是关系微弱,为−0.005。说明彝语地名一定程度上相对集聚于坡度较低的地方。
为增强数据分析的适应性,采用了Spearman相关系数进行分析,导致了相关系数较小。所以虽然以上相关分析的相关系数较小,但也表明了彝语地名与各项自然社会因子的关系。总体来看,正相关关系从强到弱的3个因子依次是高程、彝语地名与道路距离、彝语地名与主要城市距离,负相关关系从强到弱的4个因子依次是彝语地名与铁路距离、彝语地名与水系距离、彝语地名与农用地距离、坡度。从相关系数数据大小来看,与彝语地名关系最大的因子分别是彝语地名与铁路距离、高程、彝语地名与道路距离。
5. 基于点状数据的云南省彝族地名与自然社会因子的回归分析
回归分析可以用来考察两个或多个连续变量间的联系,但与相关分析相比,反映的是不同的侧面,通过回归方程解释变量间的关系显得更为精确 [16] 。回归分析绝不仅是简单地拟合出回归方程,随后还有残差分析、共线性诊断等一系列复杂的模型诊断操作需要进行。如果再考虑到分类变量的哑变量化、曲线直线化、缺失值的处理等问题,已使得回归分析变得过于复杂,超出使用者能力范畴。为减轻使用者负担,SPSS推出了自动线性建模过程工具,从而将各种最新的智能分析和自动分析技术以最为简明易懂的形式提供给用户 [17] 。利用该过程,用户可以采用几乎完成自动的方式进行自变量的预变换、筛选、模型优化、检验等工作。自变量也可以是连续、有序、无序等任何一种测量尺度,系统会自动选择相应的转换方式/算法来加以分析 [16] 。
通过比较传统数据标准化、然后多元回归分析和自动线性建模两种方法的计算结果,发现后者更佳,故采用自动线性建模过程工具进行后续分析。
回归分析使用的数据为相关分析中使用的同一数据。将数据导入SPSS20中使用自动线性建模过程工具进行回归分析,得到以下结果。
从图11可以看出,因子重要性从大到小依次排列为:彝语地名与铁路距离、高程、彝语地名与道路距离、彝语地名与农用地距离、彝语地名与主要城市距离、彝语地名与水系距离、坡度。
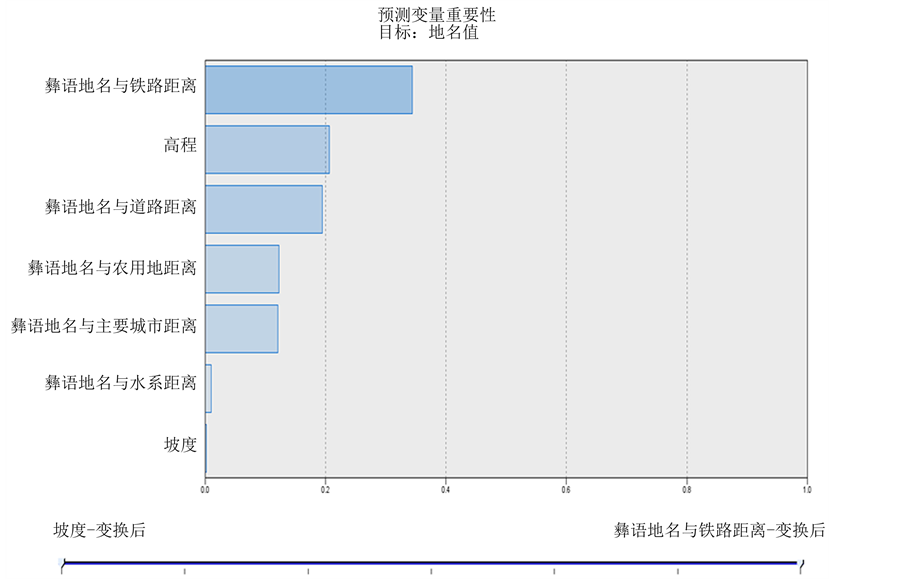
Figure 11. The importance of regression analysis variables
图11. 回归分析预测变量重要性
残差的直方图将残差分布与正态分布相比较,平滑线代表正态分布。残差频数越靠近此线,则残差分布越接近于正态分布。从图12中可以看出回归分析残差分布良好,接近正态分布。
残差的P-P图将残差分布与正态分布相比较,对角线代表正态分布。残差的观测累计概率越靠近此线,则残差分布越趋近于正态分布。从图13中可以看出,点线分布接近,接近正态分布。
具有较大Cook’s距离值的记录在模型计算中影响较大,此记录可能会歪曲模型准确度,因此需要去除,不纳入分析。从图14中可以看出,共有8个离群值,占276条记录的2.90%。Cook’s距离值分布于0.018到0.041。
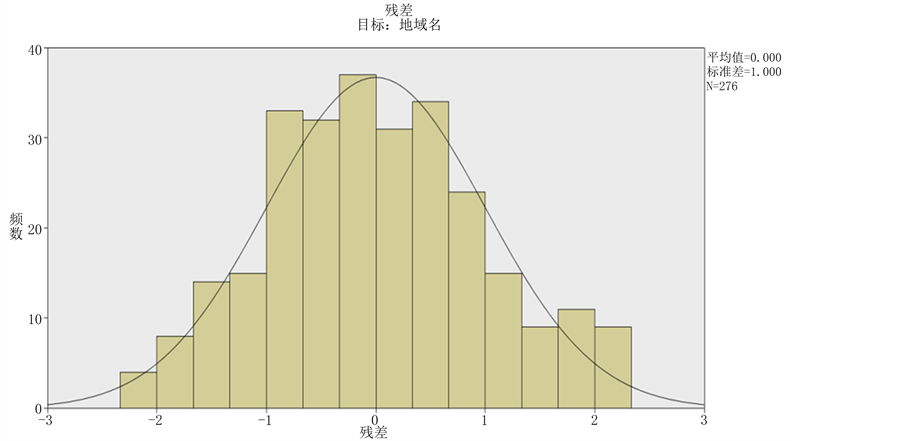
Figure 12. The residual error histogram of regression analysis
图12. 回归分析残差直方图
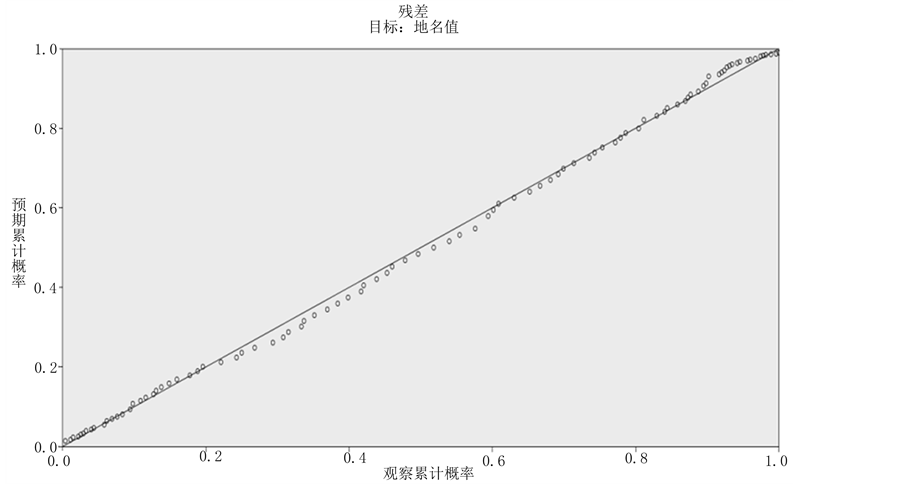
Figure 13. The residual error p-p diagram of regression analysis
图13. 回归分析残差p-p图

Figure 14. The outlier of regression analysis
图14. 回归分析离群值
效应由线宽表示,线越宽则效应越大,线越细则效应越小。从图15中可以看出,因子效应从大到小依次排列为:彝语地名与铁路距离、高程、彝语地名与道路距离、彝语地名与农用地距离、彝语地名与主要城市距离、彝语地名与水系距离、坡度。
图16中,系数大小由线宽表示,线越宽则系数越大,线越细则系数越小。蓝色表示系数为正,橙色表示系数为负。可以看出,系数绝对值大小排列顺序与图15中效应顺序一致。其中系数为正的有高程、彝语地名与道路距离、彝语地名与主要城市距离,系数为负的则是彝语地名与铁路距离、彝语地名与农用地距离、彝语地名与水系距离、坡度。
从图17中可以看出,彝语地名与铁路距离、高程、彝语地名与道路距离、彝语地名与农用地距离、彝语地名与主要城市距离、彝语地名与水系距离、坡度7个因子重要性分别为0.344、0.206、0.195、0.123、0.121、0.010、0.001。
6. 基于面状数据的云南省彝族地名与自然社会因子的空间回归分析
6.1. 空间回归分析自然社会因子及数据准备
由于现实中大量自然社会因子是面状数据,为了使得分析更为完整,需要对面数据进行空间回归分析。采用的数据分别来源于2014年云南省统计年鉴和2010年云南省人口普查资料。其中来源于2014年云南省统计年鉴的主要指标有2013年地区生产总值、2013年第一产业增加值、2013年第二产业增加值、2013年第三产业增加值、2013年医疗机构床位数、2013年人均GDP、2013年总人口、2013年年均温、2013年年降水量。来源于2010年云南省人口普查资料的主要指标有2010年人均受教育年限、2010年文盲率、2010年成人识字率、2010年彝族人口数量。以上指标主要考虑了经济、教育、医疗、人口、气温、
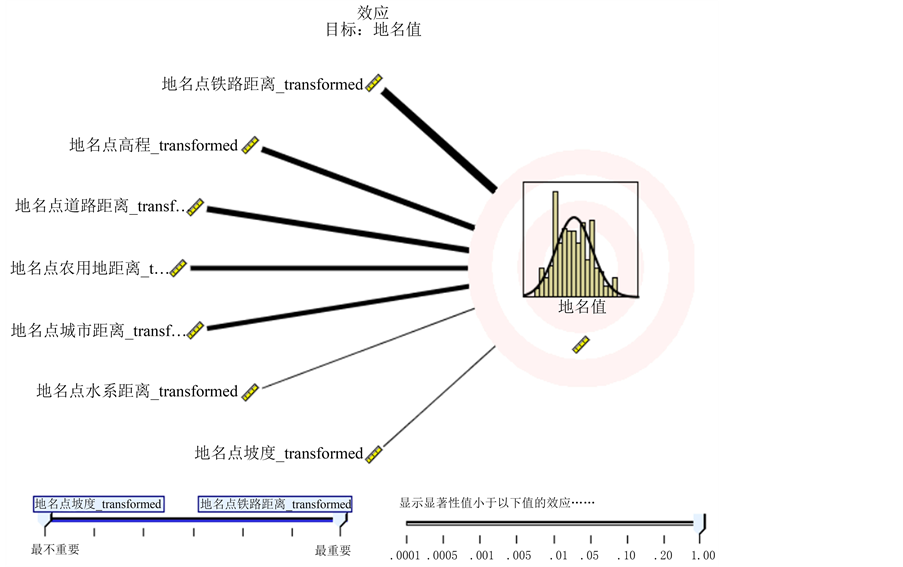
Figure 15. The effect diagram of regression analysis
图15. 回归分析效应图
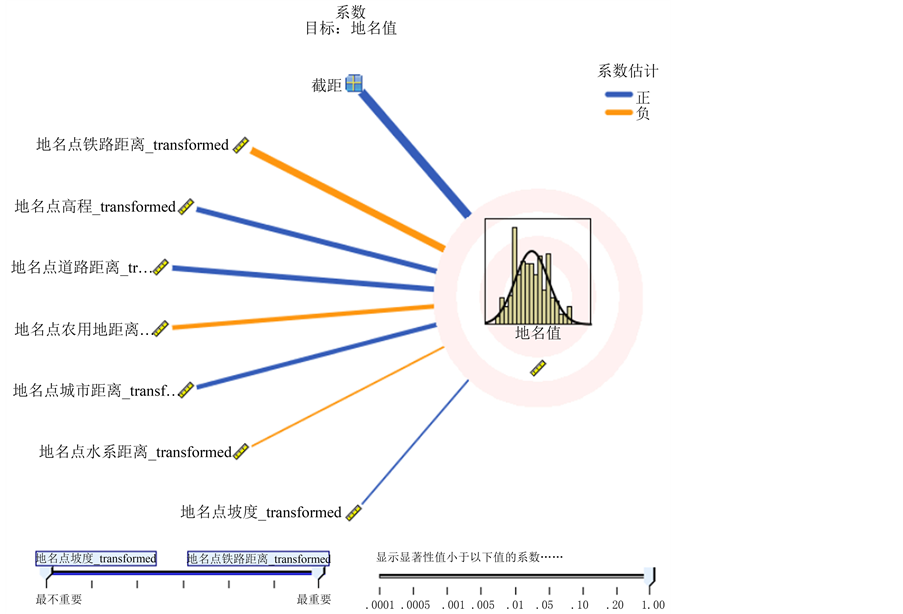
Figure 16. The coefficient of regression analysis
图16. 回归分析系数图

Figure 17. The coefficient of regression analysis and it’s importance
图17. 回归分析系数及重要性值
降水等方面。另外把各县市拥有的彝语地名数量做为一个指标,则一共是14个指标。将以上指标数据分别做为各县市的属性,这样得到14个面状图层数据(因篇幅限制,图形不再呈现)。
6.2. 云南省彝族地名与自然社会因子的空间回归分析
以彝语地名数量作为因变量,以2013年地区生产总值、2013年第一产业增加值、2013年第二产业增加值、2013年第三产业增加值、2013年医疗机构床位数、2013年人均GDP、2013年总人口、2013年年均温、2013年年降水量、2010年人均受教育年限、2010年文盲率、2010年成人识字率、2010年彝族人口数量作为自变量,运用空间回归模型分析云南省彝语地名与自然社会因子的关系。
空间回归模型包括空间滞后模型和空间误差模型两种。空间回归模型考虑了周边邻近单元对模型本身的影响,从而将空间滞后值纳入回归方程:
 (1)
(1)
式中,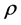 表示
表示 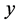 的空间滞后值的回归系数(滞后变量系数);
的空间滞后值的回归系数(滞后变量系数);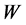 表示空间单元的空间权重矩阵;
表示空间单元的空间权重矩阵;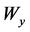 表示空间滞后值 [18] 。
表示空间滞后值 [18] 。
空间滞后模型(LM-lag)又称混合回归-空间自回归模型。这个模型考虑了因变量的空间相关性,即某一空间对象上的因变量不仅与同一对象上的自变量有关,还与相邻对象的也因变量有关。滞后变量系数表示相邻空间对象之间存在扩散或溢出的空间相互作用,其大小反映空间扩散或空间溢出的程度。如果滞后变量系数显著,表明因变量之间存在一定的空间依赖关系 [19] 。
空间误差模型则是空间依赖作用存在于扰动误差之中,它度量了邻近单元关于因变量的误差冲击对本单元观测值的影响程度,模型为:
 (2)
(2)
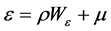 (3)
(3)
式中,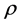 表示随机误差项向量;
表示随机误差项向量; 表示正态分布的随机误差向量 [18] 。
表示正态分布的随机误差向量 [18] 。
选择哪种模型,往往需要经过多次重复试验比较后才能够确定。一般情况下,可以从经典回归模型开始,综合软件输出的诊断信息后,再进行后续的模型调整。
此处采用OpenGeoDa 软件进行空间回归分析。先使用经典回归模型(OLS Regression)对以上指标进行分析得到空间滞后模型和空间误差模型的检验状况。
从表8中可以看出,空间滞后模型的Robust LM值0.0287103优于空间误差模型的0.1429699,所以进行云南彝语地名的空间回归分析应选择空间滞后模型。使用以上数据进行空间滞后模型分析,得到表9。
从表9中可以看出:
第一,空间滞后模型的拟合系数高于经典回归模型,为0.39273,提高了9.89%。可见空间滞后模型在此分析中确实优于经典回归模型。
第二,空间自回归系数(0.3532996)是统计显著的(概率值p < 0.05)。
第三,各变量的回归系数方向略有改变,且大部分值均有所上升,在一定程度上说明了空间上邻接关系影响了变量自身的解释力。
第四,2013年地区生产总值、2013年人均GDP、2013年年均温、2013年年降水量、2010年人均受教育年限、2010年文盲率、2010年成人识字率、2010年彝族人口数量与彝语地名数量成负相关。其取值从大到小依次为2010年文盲率、2010年成人识字率、2010年人均受教育年限、2013年年均温、2013年地区生产总值、2013年年降水量、2013年人均GDP、2010年彝族人口数量。2013年第一产业增加值、2013年第二产业增加值、2013年第三产业增加值、2013年医疗机构床位数、2013年总人口与彝语地名数量成正相关。其取值从大到小依次为2013年第二产业增加值、2013年第三产业增加值、2013年第一产业增加值、2013年医疗机构床位数、2013年总人口。
第五,以上指标中仅有2013年医疗机构床位数、2013年年降水量通过显著性检验(概率值p < 0.05),表明彝语地名数量多的县市区医疗机构床位数相对也多,医疗条件相对较好;而降水量方面,彝语地名数量多的县市区降水量相对较少。
7. 结论
通过以上点状和面状数据的相关分析和回归分析,可以得到以下结论:
Table 8. The test of OLS regression
表8.经典回归检验
Table 9. The result of spatial lag model
表9. 空间滞后模型结果
1) 基于点状数据的云南省彝语地名与自然社会因子的关系
第一,总体来看,彝语地名与各项自然社会因子的关系中正相关关系从强到弱的3个因子依次是高程、彝语地名与道路距离、彝语地名与主要城市距离,负相关关系从强到弱的4个因子依次是彝语地名与铁路距离、彝语地名与水系距离、彝语地名与农用地距离、坡度。从相关系数数据大小来看,与彝语地名关系最大的因子分别是彝语地名与铁路距离、高程、彝语地名与道路距离。
第二,回归分析结果可以看出,各项自然社会因子重要性从大到小依次排列为:彝语地名与铁路距离、高程、彝语地名与道路距离、彝语地名与农用地距离、彝语地名与主要城市距离、彝语地名与水系距离、坡度。
第三,从相关分析与回归分析结果来看,二者具有较好的一致性,表现为不同自然社会因子的正负相关性一致,各因子的重要性顺序也一致,表明分析结果具有很好的可信度。
但二者也有不一致性,例如方法不同,所以计算得到的数值必然不同,所以不同自然社会因子的重要性衡量数值有所差异,但顺序不变。
2) 基于面状数据的云南省彝语地名与自然社会因子的关系
第一,使用空间滞后模型进行空间回归,其空间自回归系数是统计显著的。
第二,2013年地区生产总值、2013年人均GDP、2013年年均温、2013年年降水量、2010年人均受教育年限、2010年文盲率、2010年成人识字率、2010年彝族人口数量与彝语地名数量成负相关。2013年第一产业增加值、2013年第二产业增加值、2013年第三产业增加值、2013年医疗机构床位数、2013年总人口与彝语地名数量成正相关。
第三,以上指标中仅有2013年医疗机构床位数、2013年年降水量通过显著性检验(概率值p < 0.05),表明彝语地名数量多的县市区医疗机构床位数相对也多,医疗条件相对较好;而降水量方面,彝语地名数量多的县市区降水量相对较少。
基金项目
云南省哲学社会科学基地课题(JD13YB17),云南省卓越青年教师特殊培养项目(自然地理学)。
文章引用
席武俊. 云南省彝语地名与自然社会因子的关系分析
Study on Relationship between Natural and Social Factors and Placenames Named in Yi Nationality Language in Yunnan Province[J]. 地理科学研究, 2016, 05(02): 105-123. http://dx.doi.org/10.12677/GSER.2016.52012
参考文献 (References)
- 1. 易谋远. 彝族史要[M].北京: 社会科学文献出版社, 2007.
- 2. 王冠雄. 基于GIS的广西壮语地名空间分布和历史变迁研究[M]. 北京: 首都师范大学, 2009.
- 3. 席武俊, 刘祖鑫. 云南省彝语地名命名方式分析[M]. 楚雄民族文化论坛, 第八辑, 昆明: 云南大学出版社, 2015.
- 4. 李建华. 基于GIS的宁夏中卫县地名文化景观分析[J]. 人文地理, 2011(1): 100-104.
- 5. 陈晨, 等. 基于GIS的北京地名文化景观空间分布特征及其成因[J]. 地理科学, 2014(4): 420-429.
- 6. 韩会庆, 郜红娟. 贵州地名景观的空间分布特点及作用机制分析[J]. 贵州商业高等专科学校学报, 2012(1): 58-60.
- 7. 姬炜. 基于国家地名数据库的空间分析[J]. 中国地名, 2011(6): 39-42.
- 8. 李艳萍. 基于地理学视角下山西省行政地名的研究[M]. 临汾: 山西师范大学, 2012: 56.
- 9. 李爱军, 司徒尚纪. 山西战争文化地名类型、空间分布特征及背景分析[J]. 太原理工大学学报(社会科学版), 2008(1): 43-48.
- 10. 郭艳丽. 中国建筑类行政地名空间分布及成因分析[J]. 城市地理, 2015(22): 57-58.
- 11. 陈友华. 江西历史行政区地名的时空分布与关联性特点及其影响因素新探[J]. 南昌航空大学学报(社会科学版), 2014(3): 98-105, 118.
- 12. 包苏日古嘎, 银山. 新巴尔虎右旗水域地名空间特征分析[J]. 内蒙古林业科技, 2015(2): 48-52, 56.
- 13. 王法辉, 王冠雄, 李小娟. 广西壮语地名分布与演化的GIS分析[J]. 地理研究, 2013(3): 487-496.
- 14. 朱惠荣. 中华人民共和国地名词典——云南省[M]. 北京: 商务印书馆, 1994.
- 15. 余建英, 何旭宏. 数据统计分析与SPSS应用[M]. 北京: 人民邮电出版社, 2003: 164.
- 16. 张文彤, 邝春伟. SPSS统计分析基础教程[M]. 第2版. 北京: 高等教育出版社, 2011: 327-335.
- 17. 张文彤, 董伟. SPSS统计分析高级教程[M]. 第2版. 北京: 高等教育出版社, 2013: 117-121.
- 18. Haining, R. (2004) Spatial Analysis: Theory and Pratice. Cambridge University, Oxford.
- 19. 王劲峰, 廖一兰, 刘鑫. 空间数据分析教程[M]. 北京: 科学出版社, 2010.