Modeling and Simulation
Vol.
12
No.
02
(
2023
), Article ID:
63476
,
14
pages
10.12677/MOS.2023.122157
古代玻璃制品的成分分析与鉴别
李怡霖,王梦佳,张琦,谢素霞
上海理工大学机械工程学院,上海
收稿日期:2023年2月5日;录用日期:2023年3月24日;发布日期:2023年3月31日

摘要
本文针对玻璃制品易受到环境因素而风化,探究了玻璃文物的表面风化与其玻璃类型、纹饰和颜色之间的关系;并结合玻璃的类型,对文物样品表面有无风化化学成分含量进行统计并分析其内在规律;根据风化点的检测数据,建立模型预测玻璃文物其风化前的各个化学成分的含量;分析了高钾玻璃、铅钡玻璃的分类规律,以及探讨分类结果的合理性和敏感性;对不同类别的玻璃文物样品,研究分析了其化学成分之间的关联关系,比较了不同类别之间的化学成分关联关系存在的差异性。
关键词
古代玻璃制品,鉴别,随机森林算法,多元线性回归方程,聚类算法

Composition Analysis and Identification of Ancient Glass Products
Yilin Li, Mengjia Wang, Qi Zhang, Suxia Xie
School of Mechanical Engineering, University of Shanghai for Science and Technology, Shanghai
Received: Feb. 5th, 2023; accepted: Mar. 24th, 2023; published: Mar. 31st, 2023

ABSTRACT
Aiming at the weathering of glass products by environmental factors, this paper probes into the relationship between the surface weathering of glass relics and the type, pattern and color of glass. Combined with the type of glass, the contents of weathering chemical components on the surface of cultural relics samples were counted and their internal rules were analyzed. According to the test data of weathering point, a model was established to predict the contents of each chemical component of glass relics before weathering. The classification rules of high potassium glass and lead barium glass are analyzed, and the rationality and sensitivity of the classification results are discussed. The correlation between the chemical components of different types of glass cultural relics samples was studied and analyzed, and the difference of the existence of the correlation between different types of chemical components was compared.
Keywords:Ancient Glass, Identification, Random Forest Algorithm, Multiple Linear Regression Equation, Clustering Algorithm

Copyright © 2023 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
科学数据表明,玻璃的主要原料是石英砂,主要化学成分是二氧化硅(SiO2)。在历史长期的演化中,这些玻璃制品易受到空气湿度、日照、风向风速等环境的干扰,导致这些玻璃制品出现不同程度的风化,在风化过程中,内部元素与环境元素进行大量交换,其成分比例发生变化,从而影响对其类别的正确判断。因此对风化程度进行分析处理和数据挖掘,一方面可以为玻璃制品的类别判断提供数据参考,另一方面对玻璃制品风化的预防和修护提供依据 [1] 。
目前已有电子探针、光谱分析仪等各类高精仪器能对古代文物的成分进行定量分析。本文研究内容是古代玻璃制品的属性及分类。
2. 玻璃属性相关联模型构建
2.1. 数据处理
玻璃文物纹饰、类型、颜色和表面风化这四个指标都是定类变量,并非连续变量,因此在进行差异化分析时,采用卡方检验对三组数据中的两个分组变量的显著性差异进行分析,比较计算得到的检验统计量 ,最终确定各个变量与有无风化之间的关系,并且画出卡方交叉热力图。其次,对呈现显著性的因素,根据效应指标对其差异进行深入量化分析,得到其对玻璃表面风化的确切差异程度,为了研究呈现显著性的两个变量的正负向关系,且考虑到两个定类变量的因素,故用斯皮尔曼相关系数对呈现显著性的变量和表面风化之间进行分析 [2] 。
根据表1现有玻璃化学成分,属性及分类情况数据的统计分析,预处理后的数据分为有无风化两组,本文仅考虑表面风化程度对化学成分含量统计规律的影响,并对其中检测到的同种化学成分累加,得到的各种成分占比,数值饼状图如图1所示。
由图1成分分析饼图得出重要变量为二氧化硅,氧化铅,氧化钾,使用多元线性回归模型对成分预测,将二氧化硅,氧化铅,氧化钾分别作为因变量,有无风化,种类,纹饰,颜色作为自变量,对于定性变量使用stata对其转化为虚拟变量,其对应表如表2所示。
玻璃文物的化学成分众多,样本的特征维度很高,采用随机森林模型仍然能够高效地训练,在选取特征数M时,因为高钾玻璃、铅钡玻璃中有部分化学成分含量较大,在分析特征数时含量较大的因子会淡化其他化学成分之间的差异性,以及不能忽略风化因素对化学成分改变所带来的两者之间的差异性,故需对数据进行处理。处理后得到的柱形图如图2所示。
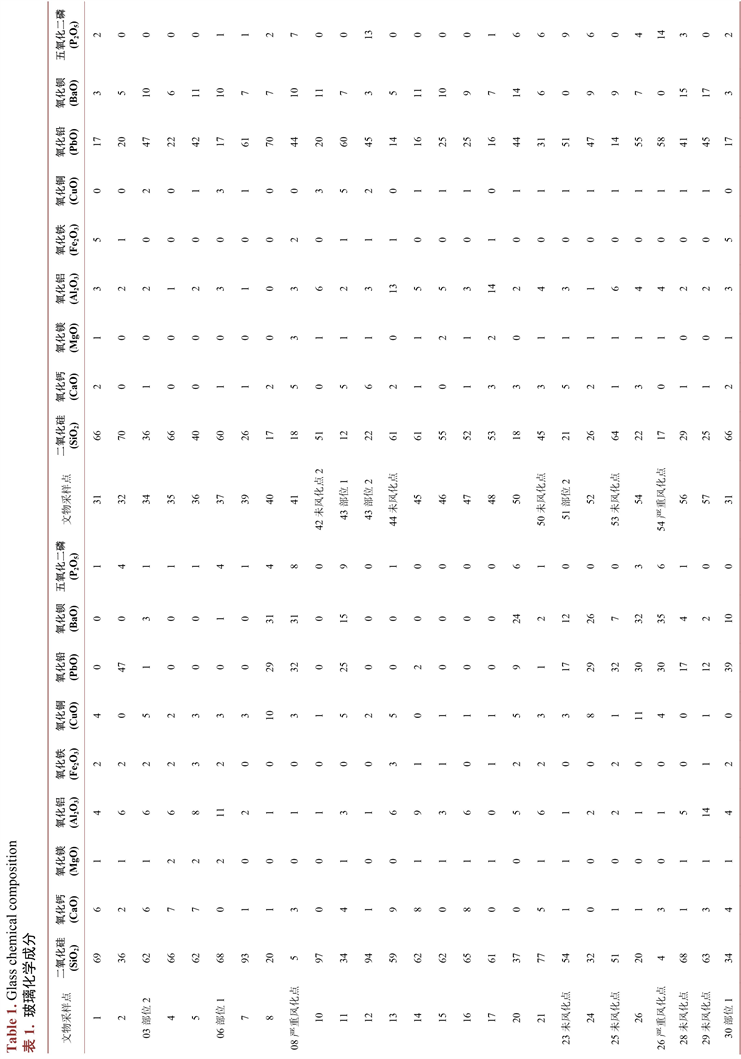
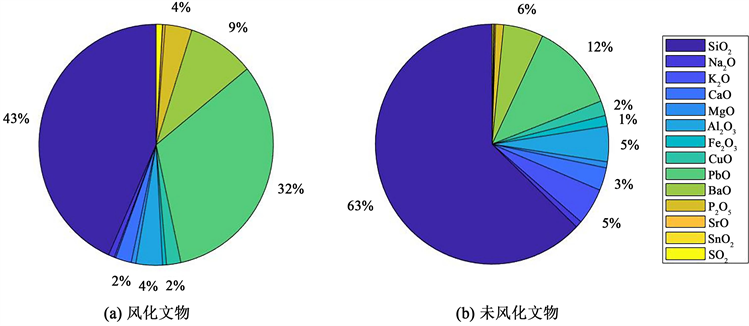
Figure 1. Pie chart of cultural relics composition
图1. 文物成分占比饼状图

Table 2. Table of virtual variable correspondence
表2. 虚拟变量对应表
 (a) 去除二氧化硅,高钾玻璃与铅钡玻璃化学成分比较
(a) 去除二氧化硅,高钾玻璃与铅钡玻璃化学成分比较
 (b) 高钾玻璃与铅钡玻璃化学成分比较
(b) 高钾玻璃与铅钡玻璃化学成分比较
 (c) 去除二氧化硅,风化的高钾玻璃与铅钡玻璃化学成分比较
(c) 去除二氧化硅,风化的高钾玻璃与铅钡玻璃化学成分比较
 (d) 风化的高钾玻璃与铅钡玻璃化学成分比较
(d) 风化的高钾玻璃与铅钡玻璃化学成分比较
 (e) 去除二氧化硅,无风化的高钾玻璃与铅钡玻璃化学成分比较
(e) 去除二氧化硅,无风化的高钾玻璃与铅钡玻璃化学成分比较
 (f) 无风化的高钾玻璃与铅钡玻璃化学成分比较
(f) 无风化的高钾玻璃与铅钡玻璃化学成分比较
Figure 2. Glass chemical composition comparison histogram
图2. 玻璃化学成分比较柱形图
减小特征选择个数m,树的相关性和分类能力也会相应地降低;增大m,两者也会随之增大,因此选择合适的M对于算法分类效果很重要,而通过两组图的比较得出两种玻璃文物之间的化学成分主要是二氧化硅,氧化钾,氧化钙,氧化铅,氧化钡,五氧化二磷之间有差异,因此将这六种化学成分作为变量X代入随机森林算法中 [3] 。
2.2. 模型流程图
Figure 3. Flow chart of glass type and property analysis
图3. 玻璃类型与属性分析流程图

Figure 4. Flow chart of glass classification analysis
图4. 玻璃分类分析流程图
3. 模型检验及应用
3.1. 玻璃类型与属性模型
3.1.1. 卡方检验分析
本文首先通过卡方检验,对纹饰、类型、颜色与表面风化进行差异化分析。在公式(1)中, 代表纹饰,类型,颜色, 代表表面风化。
(1)
计算结果详见下表3。
卡方检验分析的结果显示:
基于表面风化和纹饰,显著性P值为0.084*,基于表面风化和颜色,显著性P值为0.405,水平上不呈现显著性,接受原假设,因此对于表面风化和纹饰、颜色数据不存在显著性差异;基于表面风化和类型,显著性P值为0.009***,水平上呈现显著性,拒绝原假设,因此对于表面风化和类型数据存在显著性差异(图5)。

Figure 5. Chi-square analysis of ornamentation, type, color and surface weathering
图5. 纹饰、类型、颜色与表面风化的卡方分析结果
计算出卡方分析结果后,为了更加直观看出显著性差异,用热力图的形式展示交叉列联表的值,并且通过颜色深浅反应表示值的大小(图6、表3)。
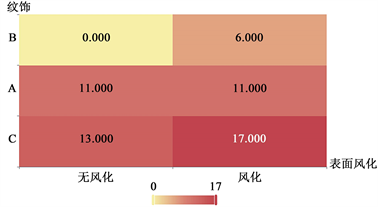 (a) 纹饰热力图
(a) 纹饰热力图
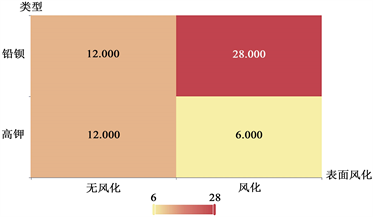 (b) 类型热力图
(b) 类型热力图
 (c) 颜色热力图
(c) 颜色热力图
Figure 6. Surface weathering heat map
图6. 表面风化热力图
Table 3. Quantitative analysis of effects
表3. 效应量化分析
由上述分析可知,表面风化与类型之间有着显著性差异,然后通过phi、Crammer’s V.列联系数、lambda对样本的相关程度进行分析,得到纹饰和表面风化的差异程度为中等程度差异;类型和表面风化的差异程度为中等程度差异;颜色和表面风化的差异程度为中等程度差异 [4] 。
3.1.2. 建立多元线性回归
利用多元线性回归模型对未风化前的成分预测,其一般公式为(2)所示,其中自变量和因变量已在step 1中转化为虚拟变量。
(2)
公式(2)中, 是偏回归系数,与 无相关性, 为随机误差项。
假设,因变量与自变量之间存在线性关系,那他们之间的线性总体回归方程可以表示为:
(3)
其中, 为随机误差项 。
回归系数分析如表4所示。
并且得到的多元线性回归模型可以表示为:
对回归模型进行怀特检验(表5):
Table 4. Regression coefficient analysis
表4. 回归系数分析
注:***p < 0.01 **p < 0.05 *p < 0.1。
Table 5. BP test results
表5. BP检验结果
得到结论二氧化硅,氧化钾,氧化铅回归进行BP检验P值分别为0.1784,0.2258,0.1777,P值均大于0.1,故不存在异方差。
3.2. 玻璃分类模型
3.2.1. 计算特征重要性
根据袋外误差率,对于特征M,首先用训练好的随机森林在对oob数据集D (二氧化硅,氧化钾,氧化钙,氧化铅,氧化钡,五氧化二磷)进行预测并求出误差率Error 1。然后对数据D (二氧化硅,氧化钾,氧化钙,氧化铅,氧化钡,五氧化二磷)中每个样本的特征m上加上随机噪音,然后再将m特征上带噪音的样本送入训练好的RF模型中训练得到新的误差率Error 2,则Error 2 - Error 1越大说明该特征越重要。计算得到的特征值重要性如图7所示,其中氧化铅的重要性最大,并且得到混淆矩阵热力图如图8所示:

Figure 7. Feature importance
图7. 特征重要性
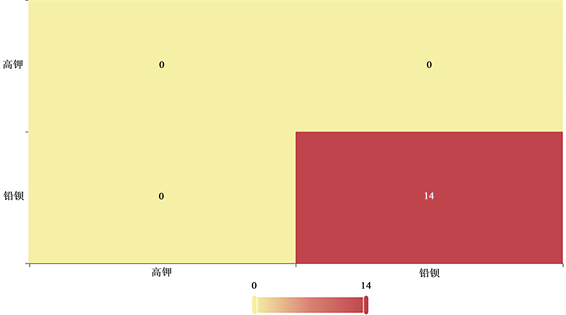
Figure 8. Confused rectangular heat map
图8. 混淆矩形热力图
将数据集分为训练集和测试集,由于本数据集样本过少,在训练时将数据的80%作为训练集进行分类的依据。剩下的20%作为测试集来验证模型的准确性,自然形成一个对照数据集,用于模型的验证,所以随机森林不需要另外预留部分数据做交叉验证。将通过量化指标来衡量随机森林对训练、测试数据的分类效果,得到的结果如表6、表7所示:
Table 6. Model evaluation results
表6. 模型评估结果

3.2.2. 玻璃类型亚分类本文采用的是K-Means聚类方法对文物进行亚分类 [3] ,但其受初始值和异常点影响,聚类结果可能不是全局最优而是局部最优,所以在开始前需要对数据预处理,先对采样数量半数以上的化学成分进行方差处理,方差大说明不稳定,可以挑选出主要变化的化学成分,经过分析将方差值以2为界限,大于2的化学成分将进行聚类分析(图9)。
Figure 9. Variance value and mean
图9. 方差值和平均值
经过数据分析将二氧化硅、氧化钾、氧化钙、氧化镁、氧化铝、氧化铁、氧化铜、五氧化二磷这八种化学成分进行下一步处理。
K- MEANS 聚类法:
算法输入:统计聚类个数K,以及包含n个数据对象的数据样本集U;
算法输出:满足方差要求且最小标准的聚类k个;
1) 选取初始聚类中心:从n个数据对象中任意选择k个对象将其作为初始聚类中心;
2) 欧氏距离划分:将每个聚类中所有对象的均值计算样本数据中每个对象与这些中心对象的欧氏距离,并根据最小距离重新对相应对象进行划分;
3) 重新计算每个聚类的中心对象(均值);
4) 循环步骤2到步骤3,直到每个聚类不再发生变化为止。
在K-MEANS聚类中,为了显现数据之间的相似度,常用的方法是通过欧氏距离表示,公式如(4)所示:
(4)
高钾玻璃模型求解与分析如表8所示:
Table 8. Differential analysis of high-potassium glass fields
表8. 高钾玻璃字段差异性分析
注:***、**、*分别代表1%、5%、10%的显著性水平。
上表展示了定量字段差异性分析的结果,包括均值 ± 标准差的结果、F检验结果、显著性P值,对于每个项分析是否小于0.05或者0.01,检验其是否符合标准,若呈显著性,拒绝原假设,说明两组数据之间存在显著性差异,可以根据均值±标准差的方式对差异进行分析,反之则表明数据不呈现差异性。对于本文而言,呈现显著性差异的有二氧化硅(SiO2)、氧化钾(K2O)、氧化钙(CaO)、氧化铝(Al2O3)、氧化铁(Fe2O3),仅有氧化铜(CuO)未显示出显著性差异。
通过聚类分析,用频数和百分比的形式显示聚类汇总结果,如表9所示:
Table 9. Summary results of high-potassium glass clustering
表9. 高钾玻璃聚类汇总结果
结果分为三类,用可视化的形式展示模型聚类的结果如图10所示:
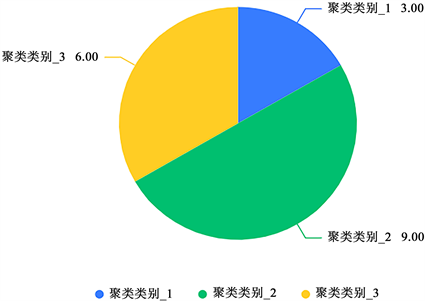
Figure 10. High-potassium glass clustering summary pie chart
图10. 高钾玻璃聚类汇总饼状图
铅钡玻璃模型求解与分析如表10所示:
Table 10. Field difference analysis of lead-barium glass
表10. 铅钡玻璃的字段差异性分析
注:***、**、*分别代表1%、5%、10%的显著性水平。
上表展示了定量字段差异性分析的结果,包括均值 ± 标准差的结果、F检验结果、显著性P值,对于每个项分析是否小于0.05或者0.01,检验其是否符合标准,若呈显著性,拒绝原假设,说明两组数据之间存在显著性差异,可以根据均值±标准差的方式对差异进行分析,反之则表明数据不呈现差异性。对于本文而言,所有的化学成分在聚类划分的类别中均存在显著性差异。
通过聚类分析,用频数和百分比的形式显示聚类汇总结果,如表11所示:
Table 11. Summary results of lead-barium glass clustering
表11. 铅钡玻璃聚类汇总结果
结果分为三类,用可视化的形式展示模型聚类的结果如图11所示:

Figure 11. Lead-barium glass cluster summary pie chart
图11. 铅钡玻璃聚类汇总饼状图
本文中在进行聚合分析时选用数据是附件已测的,为了更加清楚研究该模型对玻璃文物的亚类划分的敏感程度,我们将其中一种化学成分含量进行干扰,将氧化钙的含量每个增加10%到50%,继续对高钾和铅钡玻璃聚合分类,观察并分析得到的数据,且与未做干扰的原始数据进行比较。
本文对未知类别玻璃文物的化学成分进行分析,鉴别其所属类型,在基于建立的随机森林模型下,将表单三中未知文物的化学成分数据代入模型中,由于建立的模型选取的特征数仅有六个,故在对其类型鉴别忽略其他化学成分的影响,这个影响因子较低对于整体预测的准确性干扰不大。
对其类型的预测如表12所示:
Table 12. Prediction results for the type of unknown artifacts
表12. 对未知文物的类型预测结果
结果显示,通过比较预测结果的概率A1、A6、A7为高钾,其余文物类型为铅钡玻璃。
在进行随机森林的样本抽取中,对数据进行编号,并且使用随机抽样,抽取80%的数据集作为训练集;如果训练集大小为N,对于每棵树而言,采取随机且有放回地从训练集中的抽取N个训练样本,这两个随机性对随机森林的分类性能至关重要。由于它们的引入,使得随机森林不容易陷入过拟合,并且具有很好地抗噪能力,同时对缺省值不敏感。
4. 结论
本文中的特征很多,对于这种高维稠密型的数据在进行成分预测时,选用随机森林模型,无需做特征选择,本文中对古代玻璃制品的风化因素的研究,同样可以推广到更多非遗文物的保护和预防中,为建立数字文物保护机制提供了依据,也极大地促进了不同文化之间的交流和互动。
文章引用
李怡霖,王梦佳,张 琦,谢素霞. 古代玻璃制品的成分分析与鉴别
Composition Analysis and Identification of Ancient Glass Products[J]. 建模与仿真, 2023, 12(02): 1691-1704. https://doi.org/10.12677/MOS.2023.122157
参考文献
- 1. 阚颖浩. 山东博山元末明初玻璃作坊出土玻璃科技分析[D]: [硕士学位论文]. 济南: 山东大学, 2022. https://doi.org/10.27272/d.cnki.gshdu.2022.002831
- 2. 王祉皓, 赵芗溦, 李智群, 郭明, 肖琬玥, 刘志坚. 基于机器学习的风化硅酸盐玻璃原成分预测及亚分类方法[J/OL]. 硅酸盐学报: 1-11, 2023-02-05. https://doi.org/10.14062/j.issn.0454-5648.20220985
- 3. Scientific Platform Serving for Statistics Professional 2021. SPSSPRO (Version 1.0.11), Online Application Software. https://www.spsspro.com
- 4. 周志华. 机器学习[M]. 北京: 清华大学出版社, 2016.