Operations Research and Fuzziology
Vol.
13
No.
04
(
2023
), Article ID:
70914
,
16
pages
10.12677/ORF.2023.134403
基于指数平滑–回归模型及灰色–回归模型的长三角物流需求预测分析
李洋洲,李程*
上海工程技术大学航空运输学院,上海
收稿日期:2023年7月5日;录用日期:2023年8月13日;发布日期:2023年8月21日

摘要
随着全国经济运行整体好转,长三角作为我国经济水平最高的地区之一,科学预测长三角区域物流需求有助于把握物流业未来的发展变化,为政府部门制定区域经济发展政策以增强地区经济活力提供重要参考依据。文章从宏观经济、对外开放程度、人口发展水平和人民生活水平四个维度选取6个典型指标作为多元回归因子,并通过灰色关联分析法分析各指标与长三角物流需求之间关联的程度,采用指数平滑–回归模型与灰色–回归模型分别对长三角区域的物流需求进行预测。其预测精度分析表明:指数平滑–回归模型在MAPE、MSE、MAE三个精度指标上均优于灰色–回归模型,指数平滑–回归预测模型效果优于灰色–回归预测模型,更适合对长三角物流需求进行中短期预测。预测结果显示未来五年长三角区域物流需求平均增速约为2.2%。结合预测结果,文章提出了相关管理建议以更好地促进长三角区域经济与物流业高质量发展。
关键词
区域物流,灰色预测,指数平滑预测,多元线性回归

Logistics Demand Forecasting in Yangtze River Delta Based on Exponential Smoothing-Regression Model and Grey-Regression Model
Yangzhou Li, Cheng Li*
College of Air Transportation, Shanghai University of Engineering Science, Shanghai
Received: Jul. 5th, 2023; accepted: Aug. 13th, 2023; published: Aug. 21st, 2023

ABSTRACT
As a result of the overall improvement in national economic functioning as one of the areas with the highest economic level in the Yangtze River Delta, scientific forecasting of regional demand for logistics in the Yangtze River Delta is helpful for capturing the future development and change of the logistics industry and serves as an essential reference point for government departments in formulating regional economic development policies to enhance regional economic vitality. Six typical indicators are chosen here as multiple regressors from four dimensions of macroeconomics, the openness to the outside world, the level of population development and people’s standard of living, and the degree of correlation between each indicator and the logistic demand of the Yangtze River Delta are analyzed by grey correlation analysis method. Both the exponential smoothing regression model and the gray regression model are used to predict the logistics demand of the Yangtze River Delta. The prediction accuracy analysis shows that the exponential smooth-regression model is better than the gray-regression model in MAPE, MSE, and MAE, and the effect of the exponential smooth-regression model is better than the gray-regression model, which is more appropriate for short- and medium-term forecasting of Yangtze River Delta logistics demand. Based on the forecast results, the average rate of growth of logistics demand in the Yangtze River Delta over the next 5 years is approximately 2.2%. Taken together with the results of the forecasts, the paper advances some management suggestions to promote the high-quality development of the Yangtze River Delta’s regional economy and logistics industry.
Keywords:Regional Logistics, Gray Forecast, Exponential Smoothing Forecast, Multiple Linear Regression

Copyright © 2023 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
长江三角洲地区(以下简称长三角区域)作为我国经济最活跃的区域,也是我国综合实力最雄厚的地区,其经济发展水平高于其他地区,同时由于其人均GDP的快速增长,催生出巨大的物流需求。从2005年到2021年,长三角区域的货运量增长了约3倍,其年均增长率约7.74%。文章从区域物流需求端出发结合科学的分析手段,研究影响长三角区域物流需求的主要经济与社会因素,从而构建长三角区域物流需求的影响因素指标体系,进而构建精确与合理的预测模型,对长三角区域物流需求进行预测,可以避免区域物流基础设施建设与物流需求不匹配而产生资源浪费,有助于科学制定区域物流发展规划促进长三角物流业降本增效与行业健康发展。精确与合理的物流需求预测对于保证区域物流服务的供给与需求满足动态平衡,使长三角区域物流资源配置更加完善,实现区域经济与物流协调发展具有重要现实意义。
在对区域物流需求预测的研究方面:过秀成 [1] 等指出区域经济与社会因素对区域物流需求有很大影响,区域物流需求的研究应着重分析区域社会经济和物流供应条件的影响。丁红等 [2] 主要运用了灰色GM(1,1)模型对江西省物流发展情况进行了预测,并阐述了物流需求预测对于物流规划的作用。赵文等 [3] 构建了以物流消费及其基础能力与信息能力为影响因素指标的预测指标体系;主要运用BP神经网络模型对广东省物流能力展开预测与分析。黄勇福等 [4] 运用灰色GM(1,N)模型预测了广东省“十四五”期间的货运量,并分析了广东省物流需求量的发展规律。在预测方法方面:雷斌等 [5] 通过改进粒子群算法的灰色神经网络预测模型对铁路货运量展开预测结果表明该模型预测精度优于传统灰色神经网络;周文杰等 [6] 基于2001~2012年西北五省统计数据,选择货运量为指标,采用一元线性回归模型对2002~2020年间西北五省货运量和周转量规模进行了预测。龙忠芬 [7] 通过多元线性回归模型分析和检验,对影响广东省货运量的因素进行分析,得出地区生产总值等对广东省货运量有着显著影响;张岄 [8] 构建多个时间序列预测模型并且选择平均相对误差最小的四次多项式回归时间序列预测模型作为预测模型。通过最佳时间序列预测模型预测未来五年的铁路货运量。赵美珍等 [9] 指出单一的预测方法,包括:移动平均、灰色模型和随机时间序列等已经无法满足人们对于预测精度的要求。姜金德等 [10] 通过趋势外推法(TE)对各相关经济指标进行预测,将预测数据代入PCR模型得到了2020~2024年江苏省货运量数据。李思聪等 [11] 运用灰色–回归组合模型对我国农产品冷链物流市场需求进行预测,其研究结果表明:相比单一灰色预测和多元线性回归,灰色–回归预测组合模型预测精度较好。
综上所述,现有研究尚存在以下不足:一是从研究对象来看长三角作为我国经济发展最活跃的区域之一,但是对长三角的物流需求预测的研究较少,随着长三角一体化战略的深入推进,为更好地服务于长三角经济与物流高质量协调发展,应该重视对于长三角物流需求量的预测。二是对于区域物流需求影响因素方面,普遍从供给端出发结合水路、铁路、航空等不同的运输方式作为区域物流需求量的影响因素来开展物流预测。三是从方法来看,多数对于区域物流需求的预测多采用单一模型进行预测,存在一定局限性。如普遍采用的灰色GM(1,1)模型、多元回归预测模型、指数平滑预测模型在预测时往往只把自变量作为被预测主体,忽略物流需求量相关影响因素;其中LSTM等模型非线性拟性好,但需要大量的数据训练才能得到较为精确的预测结果 [12] 。本研究主要采用指数平滑–回归预测模型对长三角物流需求进行预测,同时引入灰色–回归模型进行精度对比分析,结合影响因素指标数据,在提高预测精度与考虑影响因素的同时,选择预测效果较好的指数平滑–回归模型对未来五年长三角区域物流需求进行预测。
2. 研究方法
2.1. 灰色关联分析
为了量化评价各指标对长三角物流需求量的影响程度,并识别最关键因素,文章通过构建灰色关联度模型计算长三角物流需求量与影响长三角物流需求量的指标的关联度,关联度越大,表示该指标对长三角物流需求量的影响程度越高。
灰色关联系数计算步骤如下:
1) 首先采用初值化处理方法,对变量进行无量纲化处理,处理方法为:用各数列的每一个数除以各列第一个。
2) 关联系数计算公式为:
(1)
其中 为关联系数; 表示母序列; 表示子数列;ρ表示分辨系数,取值范围为[0,1],常取0.5; 。
3) 关联度θ计算公式为:
(2)
2.2. 多元回归
多元线性回归分析主要用于研究X (自变量)对Y (因变量)的影响关系,其中通过R2值判断模型拟合情况,通过VIF值判断模型是否存在共线性问题,最后得出多元回归模型的方程。
多元回归的模型可表示为:
(3)
其中: 是常量,当 均为0时,这个常量表示Y的值。 为Y对应于每个自变量的偏回归系,e为残差。
2.3. 指数平滑
指数平滑由布朗提出常用于中短期经济发展趋势预测,其基本思想是不同的数据会被赋予不同的权数,新数据会比旧数据被赋予更大的权数,再通过逐层平滑计算消除掉随机因素造成的影响进而得出预测的基本变化趋势。当时间序列呈平滑趋势时可采用一次平滑法进行预测;当序列具有一定线性趋势往往需要对第一次平滑数据再次平滑提高预测精度这也被称为二次平滑法;而三次平滑法适用于曲线数据序列。
三类指数平滑公式为:
(4)
(5)
(6)
三类指数平滑式子中:Sk为第k期的预测值;yk为第k期的实际值;Sk−1为第k − 1期的预测值;a为平滑常数,其取值范围为[0,1]。
2.4. 灰色预测
灰色预测GM(1,1)模型的预测过程是将原始无规律数据通过累加而形成的一组有规律的累加数据序列进行建模,再将通过模型生成的数据通过累减还原得到预测值。
假设原始数列为 :
(7)
进行累加,生成累加序列为 :
(8)
(9)
构造序列级比检验:
(10)
如 序列通过级比检验,可构建一阶线性微分方程:
(11)
令
(12)
其中, 称为一阶线性微分方程的背景值, ,μ为权重系数。假定μ取值为0.5,则有:
(13)
在一阶线性微分方程公式(11)中,a为发展系数;u为灰色作用量。对累加生成数据做均值生成B与常数项向量Y,通过计算参数a,u,就能求出 ,进而求出 预测值。
(14)
由最小二乘法求解灰参数 得到:
(15)
将灰参数 代入公式(11)并对方程求解,可得:
(16)
将上述结果累减还原得到预测值:
(17)
(18)
2.5. 预测精度评价体系
研究从平均绝对百分比误差(MAPE)、均方根误差(MSE)和平均绝对误差(MAE)三方面评价长三角物流需求量预测精度的好坏,其中 为第i年的物流需求量实际值; 为第i年的物流需求量的预测值;M为预测的样本长度。
(19)
(20)
(21)
3. 指标选取及指标数据
3.1. 因变量与自变量指标选取
长三角地区物流需求量受很多因素的影响,主要包括宏观经济影响因素,对外开放程度,人民生活水平,人口发展水平这四个维度。通过查找大量国内外学者的文献,遵循重要与简洁性原则、经济与可得性原则、目标与适用性原则文章选取与长三角物流需求量相关性较高的指标如下:
选取货运量作为长三角的物流需求量的量化指标。货运量是最主要、最客观、最直接的反映物流需求量的指标。并通过对大量文献进行研究分析,研究者通常都将货运量作为物流需求量的衡量指标。所以选取货运量作为长三角物流需求量的量化指标 [13] 。选取生产总值与第三产业生产总值反映宏观经济水平,生产总值主要反映区域经济发展规模,第三产业生产总值侧重反映产业结构,经济的快速发展会带来更多的物流需求,以满足企业的生产需求和市场的供需平衡。而物流业属于第三产业,物流的需求规模、层次、结构与区域产业结构密切相关 [13] 。选取进出口额反映对外开放程度,2022年长三角进出口总值达15.07万亿元比2021年增长6.9%,占全国进出口总值比重为35.8%。而进出口贸易会在促进商品流通进而带动区域物流需求。选取常住人口与旅客发送量反映区域人口发展水平,一方面,常住人口数量增加,意味着消费市场和劳动力市场的扩大,从而催生了更多的经济活动和物流需求。同时旅客发送量较大的地区,区域的旅游产业发展态势较好,旅游产业带来的物流需求也在逐渐增加,这也带动了物流企业和供应链的发展。选取人均可支配收入反映区域人民生活水平,人均可支配收入是反映人民生活水平的重要指标之一,人均可支配收入对物流需求量产生了重要的影响。人均可支配收入的增加也会导致人们的购买能力和消费水平也随之提高,从而导致物流需求量的增加。
研究选取我国2005~2021年的相关指标数据作为长三角物流需求影响因素指标。预测指标为长三角区域物流需求总量Y1,影响因素Xi为自变量(i = 1,2, ∙∙∙, 6)指标如表1所示。

Table 1. Indicators of factors influencing logistics demand
表1. 物流需求影响因素指标
3.2. 指标数据收集
通过查找2006~2022年《上海市统计年鉴》《安徽省统计年鉴》《江苏省统计年鉴》《浙江省统计年鉴》,分别收集到2005~2021年长三角三省一市的进出口总额、常住人口、居民人均可支配收入等七个指标数据,最后通过计算求得2006~2022年长三角区域的生产总值、第三产生产总值、进出口总额、常住人口、旅客发送量、居民人均可支配收入指标数据如表2所示。
Table 2. Statistics on indicators of logistics demand and influencing factors in the Yangtze River Delta, 2005~2021
表2. 2005~2021年长三角物流需求及影响因素指标统计数据
3.3. 基于灰色关联分析的影响因素分析
由于各指标数据项在单位上不一致,选用初值法对2005~2021年长三角物流需求总量及影响因素指标统计数据进行无量纲化处理,以保证预测体系数量级与影响因素的数量级一致。再针对6个评价项(X1, X2, X3, X4, X5, X6),以及2005~2021年17项数据进行灰色关联度分析,并且以Y1作母序列,研究6个子序列与Y1的灰色关联关系,使用灰色关联度分析时,分辨系数取0.50,结合关联系数计算公式可得2005~2021年生产总值X1、第三产业生产总值X2、进出口总额X3、常住人口X4、旅客发送量X5、居民人均可支配收入X6与物流需求量Y1的灰色关联系数如图1所示。
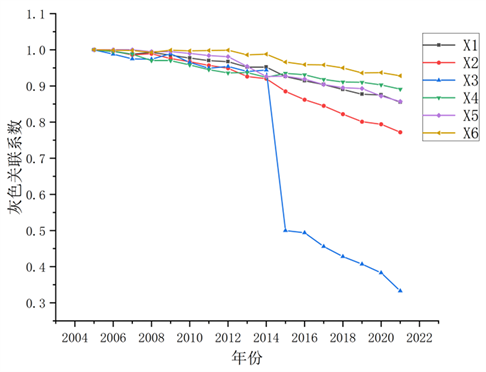
Figure 1. Gray correlation coefficients of influencing factors
图1. 影响因素灰色关联系数
根据上图的灰色关联系数进一步求出2005~2021年生产总值X1、第三产业生产总值X2、进出口总额X3、常住人口X4、旅客发送量X5、居民人均可支配收入X6与物流需求量Y1的灰色关联度并根据灰色关联度值的大小对其进行排序如表3,以关联度大于0.6作为较强关联关系的接受原则,文章选取的6个影响因素指标与长三角物流需求均存在较强的关联关系。
Table 3. Gray correlation of impact factor indicators
表3. 影响因素指标灰色关联度
4. 长三角物流需求量预测
4.1. 多元回归模型
通过上述灰色关联度分析(GRA)得出所选取的六个影响因素指标X1,X2,X3,X4,X5,X6与物流需求量均有较强的关联关系。因此将六个影响因素指标作为回归因子纳入多元回归方程,建立长三角物流需求多元回归初始模型,相关求解系数如表4所示。
Table 4. Table of coefficients for multiple linear regression analysis
表4. 多元线性回归分析系数表
*p < 0.05, **p < 0.01.
从上表可知,将X1,X2,X3,X4,X5,X6作为自变量,而将Y1作为因变量进行线性回归分析,从上表可以看出,模型公式为:
(22)
模型R2值为0.995,意味着X1,X2,X3,X4,X5,X6可以解释Y1的99.5%变化原因,表明该模型对于因变量有较好的解释度。但模型自变量的显著性检验值部分大于0.05,且模型中VIF值均大于10,意味着该多元线性回归模型存在着共线性问题。
为消除多元回归中存在的共线性问题选取逐步回归的处理方法对自变量进行筛选,通过逐步回归模型逐步stepwise法自动识别出有显著性的自变量,将X1,X2,X3,X4,X5,X6作为自变量,而将Y1作为因变量进行逐步回归分析,最终结果如表5所示,最终余下X4一共1项在模型中,X4的回归系数值为241.929 (t = 22.438, p = 0.000 < 0.01),意味着X4会对Y1产生显著的正向影响关系。R2 = 0.971意味着X4可以解释Y1的97.1%变化原因。调整R2 = 0.969,说明模型能较好拟合,VIF = 1小于10说明逐步回归后成功消除了共线性问题,而且模型通过F检验(F = 503.466, p = 0.000 < 0.05),说明模型有效。
Table 5. Table of coefficients of results of stepwise regression analysis
表5. 逐步回归分析结果系数表
*p < 0.05, **p < 0.01.
由此建立一元线性回归模型为:
(23)
4.2. 自变量预测
4.2.1. 自变量灰预测
通过GRA以及多元回归模型建立,对常住人口X4建立GM(1,1)灰色模型进行预测。如表6所示原始序列级比值均处于标准范围区间[0.895,1.118]内,意味原始值序列通过级比检验适合构建GM(1,1)模型 [14] 。
Table 6. Gray GM(1,1) model level ratios
表6. 灰色GM(1,1)模型级比值
构建模型后通过最小二乘法分别求得发展系数a、灰色作用量u;进一步计算的后验比C值和小误差概率p值如表7所示。
Table 7. GM(1,1) modeling results
表7. GM(1,1)模型构建结果
从上表可知,模后验差比C值0.014 < 0.35,小误差概率p值为1.000 < 1.0,结合表8,模型精度判定指标表判断该GM(1,1)灰色模型精度很好。
Table 8. GM(1,1) model accuracy determination index table
表8. GM(1,1)模型精度判定指标表
将灰参数a代入公式(11)并求解,可得:
(24)
再对计算结果进行累减还原可得2005~2021年常住人口X4拟合值如图2所示。
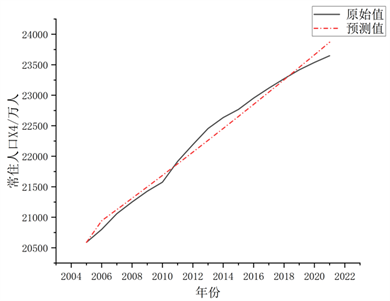
Figure 2. 2005~2021 resident population raw vs. GM(1,1) comparison of projected values
图2. 2005~2021常住人口原始值与GM(1,1)预测值对比
从以上计算结果可知,GM(1,1)灰色模型预测常住人口X4的拟合值与原始值的相对误差值最大值0.009 < 0.1,平均相对误差值为4.39%,级比偏差最大值0.007 < 0.1,意味着模型拟合效果较优。使用GM(1,1)灰色模型预测2022~2026年常住人口X4预测值如表9所示。
Table 9. GM(1,1) model X4 projections for 2022~2026
表9. 2022~2026年GM(1,1)模型X4预测值
4.2.2. 自变量指数平滑预测
指数平滑法适用于数据中短期预测;由于数据序列为17个(介于10~20个之间),因此选取自变量常住人口X4前2期数据的平均值20695.485作为指数平滑法的初始值。平滑系数alpha值介于0~1之间,为了提高模型拟合效果,平滑系数alpha值选取了0.05~0.95共11个值,并针对11个平滑系数alpha值分别选用三种平滑类型最终进行了33组测试,选取33组测试中RMSE值最小的一组作为当前筛选条件下的最佳模型参数。
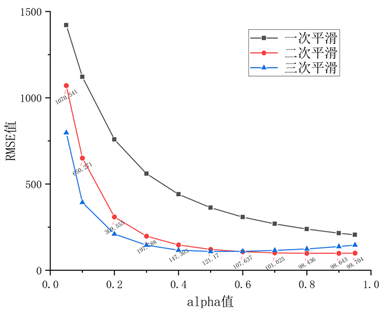
Figure 3. Test results of exponential smoothing parameter selection
图3. 指数平滑参数选取测试结果
如图3所示,测试结果表明当初始值为20695.485,alpha值为0.800,平滑类型为二次平滑,此时RMSE值为98.436。此为当前条件下最优的模型参数,并以此参数进行模型构建从而得到自变量X4拟合值。拟合值与原始值平均相对误差为3.01%最大相对误差为0.0094 < 0.1,说明该模型拟合效果好,因此使用指数平滑法得到2005~2021年常住人口X4拟合值如图4所示。

Figure 4. Comparison of raw and index-smoothed projections of resident population in 2005~2021
图4. 2005~2021常住人口原始值与指数平滑预测值对比
使用指数平滑法预测2022~2026年常住人口X4预测值如表10所示。
Table 10. Exponential smoothing model X4 Forecasts, 2022~2026
表10. 2022~2026年指数平滑模型X4预测值
4.3. 因变量预测
4.3.1. 因变量灰色–回归预测
将GM(1,1)灰色模型自变量X4预测数据带入一元线性回归模型公式(23)中,对2022~2026年长三角物流需求总量进行预测,并引入GM(1,1)模型对因变量Y1进行单一预测作为对照组,预测结果如表11所示,灰色–回归模型(GM(1,1)-回归模型)预测精度优于单一的GM(1,1)模型其平均相对误差为5.24%。
Table 11. GM (1,1)-regression model predictions
表11. GM(1,1)-回归模型预测值
4.3.2. 因变量指数平滑–回归预测
将指数平滑模型自变量X4预测值带入一元线性回归模型公式(23),得到2022~2026年长三角物流需求量,并引入指数平滑模型(初始值为393477.500,alpha值为0.500,平滑类型为二次平滑)对因变量Y1进行单一预测作为对照组,指数平滑–回归模型预测值如表12所示,指数平滑–回归模型预测精度优于单一指数平滑模型其平均相对误差为4.99%。
Table 12. Exponential smoothing-regression model predictions
表12. 指数平滑–回归模型预测值
4.4. 精度分析
为了验证模型的精度,选取精度较高的模型对长三角物流需求量进行预测,文章分别通过GM(1,1)灰色模型、指数平滑模型、灰色–回归模型(GM(1,1)-回归模型)、指数平滑–回归模型对长三角物流需求量进行预测,并将2005~2021年预测值与原始值进行比较,分别从平均绝对百分比误差(MAPE)、均方根误差(MSE)和平均绝对误差(MAE)三方面评价长三角物流需求量预测精度的好坏,精度分析结果如表13所示。
Table 13. Precision analysis error value
表13. 精度分析误差值
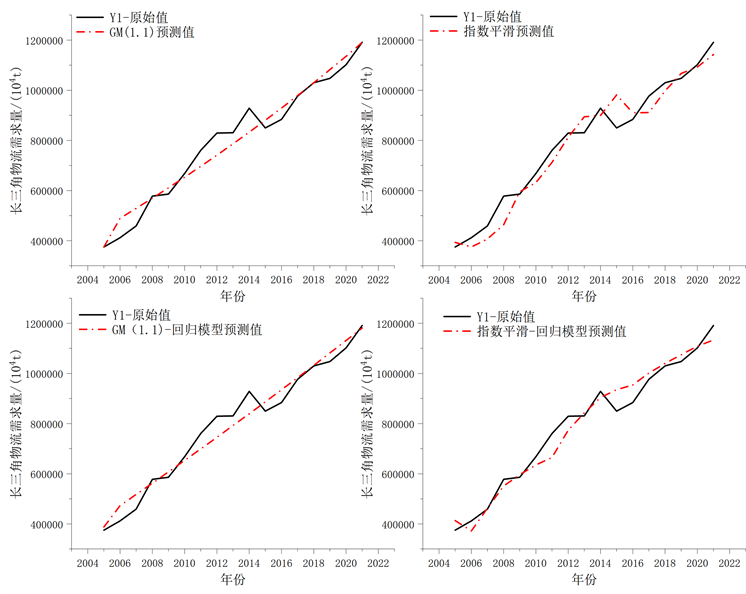
Figure 5. Comparison of predicted and original values of four types of models
图5. 四类模型预测值与原始值对比
通过对表13与图5分析可得:研究借助回归模型有效提高了GM(1,1)模型与指数平滑模型的预测精度,在平均绝对百分比误差(MAPE)层面回归模型对GM(1,1)模型与指数回归模型的精度提升率分别了2.77%和20.03%,回归模型对于指数平滑模型精度提升较大,且指数平滑–回归模型在MAPE、MSE、MAE三个精度指标层面均优于其他三类模型对于长三角物流需求量的预测其精度最高。
因此选取精度最高的指数平滑–回归预测模型作为长三角物流需求量预测模型,最终指数平滑–回归模型预测结果如表14所示,根据预测结果显示未来2023~2026年长三角区域的物流需求量增速维持在2.2%左右,物流需求量增速较为稳定,模型对长三角物流需求量的中短期预测也比较符合实际经济情况。
Table 14. Logistics demand in Yangtze River Delta, 2022~2026
表14. 2022~2026年长三角物流需求量
5. 结论
5.1. 政策建议
结合对长三角经济发展状况的分析及其物流需求预测研究,为更好地促进长三角经济与物流业高质量协调发展,文章提出以下三点建议。
1) 构造新形势下的长三角区域物流业发展战略
在当前世界经济增长动力略显不足,增速出现下降的背景下,长三角区域作为我国经济发展的重要驱动力量,促进其区域物流产业健康与可持续发展对区域的经济发展起到重要作用,地方政府应充分考虑当前的国内外经济形势,参考长三角物流需求预测值,并结合长三角内经济发展状况与国内外经济形势,合理规划长三角区域物流交通基础设施,避免区域物流基础设施建设与物流需求不匹配而产生资源浪费。调控区域物流服务的供给与需求以实现供需动态平衡 [15] 。
2) 成立长三角物流一体化发展组织
从2005年到2021年,长三角区域的货运量增长了约3倍,其年均增长率约7.74%,快速的物流需求增长下长三角物流一体化发展水平仍待提升,主要表现在:局部地区交通网络覆盖率不足、交通物流运行效率不佳,长三角区域物流一体化水平有待提升等方面。建议各地区政府应协同组建与支持长三角物流一体化发展组织,推进物流一体化发展、因地制宜制定长三角区域内物流相关的政策和法规实现制度层面上对物流业发展的促进和保障,着力推进物流信息技术标准制定,并构建长三角物流一体化大数据共享平台,打破技术壁垒保证物流信息安全、平稳运行。
3) 发挥长三角G60科创走廊人才优势
物流产业目前还没有完全摆脱传统的低附加值,劳动密集型产业,其中的一个主要原因就是缺乏物流规划和管理的高级人才,物流技术创新型人才。这一定程度上制约了部分地区物流业的发展。长三角G60科创走廊作为长三角一体化发展国家战略的重要平台之一,覆盖沪苏浙皖三省一市的九个主要城市。为解决长三角物流人才问题,地方政府可以充分发挥长三角G60科创走廊的人才优势,依托长三角G60科创走廊引进与培育物流技术创新型人才,提升区域物流产业附加值。
5.2. 创新与展望
研究对象方面本文提出的基于指数平滑–回归模型的长三角物流需求预测填补了国内对于长三角物流需求预测的空白。区别于传统的区域物流需求影响因素一般选取不同的运输方式作为影响因素,本文侧重从更宏观的维度选取典型指标作为多元回归因子。最后从预测方法来看,多数对于区域物流需求的预测多采用单一模型进行预测,存在一定局限性,并且容易忽略物流需求量相关影响因素;而精度较高的智能算法模型,需要大量的数据训练才能得到较为精确的预测结果;本研究从原始数据量较少的实际情况出发,借组多元回归考虑区域物流需求影响因素实现了对指数平滑预测模型与灰色预测模型的精度提升,并取得了良好的预测精度。
研究虽然考虑了区域物流需求影响因素,但是为了消除多元回归中多重共线性的干扰,通过逐步回归消除共线性提高了模型拟合效果,也剔除了大部分影响因素,只保留了主要影响因素。未来的研究需要着眼于在保留更多影响因素的前提下消除多重共线性,并进一步提高预测精度。
基金项目
上海高校市级重点课程项目(s202108002)。
文章引用
李洋洲,李 程. 基于指数平滑–回归模型及灰色–回归模型的长三角物流需求预测分析
Logistics Demand Forecasting in Yangtze River Delta Based on Exponential Smoothing-Regression Model and Grey-Regression Model[J]. 运筹与模糊学, 2023, 13(04): 4025-4040. https://doi.org/10.12677/ORF.2023.134403
参考文献
- 1. 过秀成, 谢实海, 胡斌. 区域物流需求分析模型及其算法[J]. 东南大学学报(自然科学版), 2001(3): 24-28.
- 2. 丁红, 王剑斌. 区域物流规划中的物流需求预测研究[J]. 科技广场, 2009(2): 76-77.
- 3. 赵文德, 黄丽娟, 胡子瑜. 基于BP神经网络组合模型的广东省区域物流需求能力预测[J]. 物流技术, 2020, 39(12): 49-56+66.
- 4. 黄永福. 高质量发展视角下广东省“十四五”物流需求量预测研究——基于GM(1, N)灰色模型[J]. 经营与管理, 2022(10): 174-179.
- 5. 雷斌, 陶海龙, 徐晓光. 基于改进粒子群优化算法的灰色神经网络的铁路货运量预测[J]. 计算机应用, 2012, 32(10): 2948-2951+2962.
- 6. 周文杰, 黄慧淼, 黄雪茜. 基于回归模型的西北五省区货运量预测[J]. 物流科技, 2014, 37(10): 142-145.
- 7. 龙忠芬. 货运量回归模型分析——以广东省为例[J]. 物流技术, 2015, 34(22): 130-132+136.
- 8. 张岄. 铁路货运量预测及影响因素研究[D]: [硕士学位论文]. 北京: 北京交通大学, 2016.
- 9. 赵美珍. 山西省工业物流需求预测[D]: [硕士学位论文]. 太原: 山西大学, 2016
- 10. 姜金德, 周海花. 基于区域经济指标的区域物流需求PCR预测研究——以江苏省为例[J]. 济南大学学报(社会科学版), 2021, 31(4): 124-132+160.
- 11. 李思聪, 叶静. 基于灰色回归模型的农产品冷链物流需求分析及预测[J]. 公路交通科技, 2022, 39(5): 166-174.
- 12. 孟建军, 陈鹏芳, 李德仓, 等. 铁路货运量预测研究综述[J]. 铁道标准设计, 2022, 66(10): 18-26.
- 13. 高爱霞, 满广富, 姚兴华. 基于主成分回归的区域物流发展预测模型构建与实证分析——以泰安市为例[J]. 山东工会论坛, 2018, 24(2): 68-76.
- 14. 史红伟, 陈家亮, 张继群, 等. 基于灰色系统理论的高校用水量预测[J]. 河北工程大学学报(自然科学版), 2022, 39(1): 78-83.
- 15. 孙战旗. 基于系统动力学的厦漳泉区域物流协同发展研究[D]: [硕士学位论文]. 厦门: 集美大学, 2015.
NOTES
*通讯作者。