Statistics and Application
Vol.
09
No.
02
(
2020
), Article ID:
35075
,
9
pages
10.12677/SA.2020.92028
PCA and CUR Decomposition Analysis in Dimensionality Reduction of High-Dimensional Data
Liping He
North China University of Technology, Beijing

Received: Mar. 26th, 2020; accepted: Apr. 9th, 2020; published: Apr. 17th, 2020

ABSTRACT
In the era of big data, there are many ways to reduce the dimension of high-dimensional data. Among them, the linear dimension reduction method is the most typical method in PCA and CUR decomposition method, but at present, using the two methods on the research achievements of high-dimensional data dimension reduction is not enough. Therefore, through the discussion and research of the principal component analysis and CUR decomposition method, this paper analyzes the use conditions and practical effects of the two methods. It is concluded that: with the traditional principal component analysis method of the matrix decomposition, in terms of feature selection, CUR decomposition method not only has high accuracy, but also has good interpretability. In terms of matrix recovery, CUR matrix decomposition method has high stability and accuracy, and its accuracy can sometimes reach more than 90%. Therefore, I think CUR matrix decomposition has good application value, and it is worth using CUR matrix decomposition method to reduce the dimension of high-dimensional data.
Keywords:Principal Component Analysis, Line and Column Joint Algorithm, Feature Selection, Matrix Recover

高维数据降维中的PCA与CUR分解对比分析
何丽萍
北方工业大学,北京

收稿日期:2020年3月26日;录用日期:2020年4月9日;发布日期:2020年4月17日

摘 要
在大数据的时代,使高维数据降低维度有很多种方法。其中,在线性降维方法中最典型的方法是PCA和CUR分解方法,但是目前我们利用这两种方法对高维数据降维的研究成果还不够,因此,本文通过对这主成分分析和CUR分解方法的探讨和研究,分析了这两种降维方法的使用条件和实际效果,得出:与传统的主成分分析的矩阵分解方法相比较,在特征选择方面,CUR分解方法不仅具有很高的准确度,而且还具有很好的可解释性;在矩阵恢复方面,CUR矩阵分解方法具有很高的稳定性同时还具有很高的准确度,其准确度有时候能够达到90%以上,因此我认为CUR矩阵分解具有很好的应用价值,值得我们利用CUR矩阵分解法去对高维数据进行降维。
关键词 :主成分分析,行列联合算法,特征选择,矩阵恢复

Copyright © 2020 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
在高维空间中,由于高维数据难以处理,所以表示数据之间相似性度量的L距离将会失去意义。在高维数据里存在很多空值,因此数据实际的维度比原始的数据维度小得多,我们可以通过降维的手段转换到低维空间进行处理。有很多种处理高维数据的方法,常见的方法有PCA分解、CUR分解和SVD分解等等,在传统的矩阵分解中,虽然能够将高维的数据分解成低维的数据,但是分解出来的结果可解释性不够,主要是因为分解出来的数据不是原始的数据,我们不能用现实生活中的概念去解释结果,只能理解为潜在语义空间,因此分解后矩阵解释性不高。除此之外,由于分解后矩阵的数值不是原来的数据,通过矩阵恢复来预测矩阵稳定性和准确性也很差。本文运用行列选择算法来实现特征选择算法,并且用改进的CUR算法来构造恢复矩阵,CUR分解是在原始数据矩阵中根据概率的大小来选取部分行和列,然后再构造矩阵的分解方法 [1]。CUR分解由原始数据构造而来,其得到的矩阵稀疏且物理意义明确,同时,CUR分解的算法较为简单,避免了对高维矩阵进行特征值求解,因此其效率也较高,本文主要对这两种降维方法进行对比分析。
矩阵恢复是最近几年非常流行处理高维数据的方法,在一些图像处理方面的应用是非常广泛的,通过分析这几年的大数据竞赛中我们可以发现,在进行用户偏好预测方面,应用最广泛的还是恢复矩阵,本文主要还是利用改进后的恢复矩阵来求解恢复矩阵,其预测的准确性和解释性相对于PCA和SVD传统的分解方法都很高 [2]。
本文有创新点也有不足,创新点在于通过改进的CUR分解方法和PCA分解方法对高维数据的处理结果可知,CUR分解方法解释性很高,而且对乳腺癌数据的良性和恶性肿瘤的发病率有很好的预测,可以帮助一些癌症患者去了解发病率以及自己恢复良好的概率,不足的就是数据不是最新的数据,结果相对于现实还是会存在一点误差,我认为其误差可以忽略不计。
2. 理论模型与方法论
2.1. 理论模型
本文所用的数据都是没有缺失值的数据,对有空值的数据去空值,然后对处理后的数据进行标准化处理。在完成上述两个步骤之后,为了防止建立的回归模型出现过度拟合现象,本次研究将数据按照3:1的比例分为训练集和测试集,其中训练集用来做回归模型,测试集用来交叉验证选择最终模型以及对模型进行评估,结合PCA算法可得。
针对一个给定的训练集,在给定的光滑系数下,Kaiser-Harris准则建议,选取不同的主成分进行拟合,得出一组模型,记号如式所示 [1]
(1)
其中n表示在Kaiser-Harris准则建议下可以保留的最大主成分个数,
(2)
表示对数据集的第j次划分(本次研究仅进行10次划分)下,第i种情况的拟合模型,此时光滑系数取分别计算出各个模型在验证集中预测的误判率作为经验损失,在经验损失的基础上对模型复杂度(即,采用的主成分个数)施加光滑系数为 的惩罚,得出模型的结构损失。此时对i求平均值,得出每种情况预测的平均结构损失,在对j取最小,选出平均结构损失最小的情况(即,得出在给定的,平均结构损失最小的模型),最后在测试集中对进行交叉验证选择出最优的拟合模型作为最终模型 [1] [2]。
2.2. 方法论
2.2.1. PCA方法论
PCA方法是一类经典的降维方法,其目的在于用一组较少的不相关变量来代替原始数据集中的变量(往往维数较高),同时保证原始数据集中的信息尽可能多的被解释,称这些提取出来的较少的不相关变量为主成分。其方法论为:最大方差理论。具体表现为寻找一组基,使得所有数据变换为在这组基上的坐标表示后,其方差值最大。形象的可以理解为数据在这组基上的投影尽可能的分能的分散,因此,方法论可以归纳为求解最优化问题:
约束优化问题 , (3)
其中l是特征根 所对应的单位特征向量, 为协方差矩阵,则最优化问题的解l是由协方差矩阵的前 个最大的特征值对应的特征向量构成的 [3]。从而PCA的输出结果可表示为:
(4)
即,数据维数降低到 维。其中X表示降维前的数据,Y表示降维后的数据。需要注意的是,在PCA分析的降维过程中,虽然尽可能的保留了原始信息,但是因为反复对矩阵进行变换,导致提取出的主成分往往难以解释其物理意义,也进一步导致得出的回归模型的解释性不强 [3] [4]。
2.2.2. CUR分析方法
CUR分解方法主要就是通过将一个矩阵变为三个矩阵CUR矩阵,CUR特征选择方法是计算统计影响力,先计算一下每一列和每一行特征的得分值,然后根据我们已知的得分的大小来决定是否选择这行(列),通过这一方法,我们可以将不需要的数据去掉,保留有用的数据,得到可以代表其特征的集合,通过这样的集合就可以快速且容易地的分析原数据所具备的特征,本文通过CUR矩阵得到恢复矩阵 ,恢复矩阵: 。
相似程度式 [5]:
(5)
3. 基本算法
3.1. PCA基本算法
主成分分析算法见表1所示:

Table 1. PCA algorithm
表1. PCA算法
3.2. CUR基本算法
对于给定特征矩阵 ,我们需要首先构建CUR分解中的低秩矩阵C,R。在选取过程中我们需要依概率选取更重要的行和列来构造我们的C,R,因此需要度量所有行和列重要性的指标,我们叫它原始矩阵 的每一列或行的影响力分数,第i列的影响力分数记为 ,第 行的影响力分数记为 ,下面我们给出原始矩阵 每一行和列的影响力分数的形式化度量:
(6)
(7)
其中 表示矩阵第i行第j列的元素值 [5]。
有了上述矩阵行和列的影响力分数的形式化描述,可以给出CUR算法第一步:行列选择算法,见表2~4所示:
Table 2. Row and row selection algorithm
表2. 行列选择算法
Table 3. Construction of algorithm 2 matrix U
表3. 算法2矩阵U的构造
Table 4. Algorithm 3 USES CUR for feature selection and recovery
表4. 算法3利用CUR进行特征选择和恢复
4. 实证分析
4.1. 研究对象选取
本文通过UCI网站收集到乳腺癌数据集(简称wdbc数据集),其中有569的观测值,30个预测变量,2个分类,B = 恶性,M = 良性,通过对数据进行处理,分为训练集,测试集,通过PCA和CUR分解进行降维处理。
4.2. PCA算法实现
本文选取原始数据的一部分作为训练集和测试集,对训练集做主成分回归得到:

Figure 1. Principal component diagram
图1. 主成分图
通过观察上图1可以发现有5个主分依据Kaiser-Harris准则建议保留特征值大于1的主成分,故而结合图1可知,本次研究选择5个主成分即可保留原始数据集的大部分信息,但是最终模型是否5个主成分均需要保留在回归模型中,则通过交叉验证选择结构损失函数最小的模型 [6]。
结构损失函数表示为在采取0-1损失函数的基础上,对模型采用主成分的个数进行惩罚,如式(5)所示:
(8)
其中n表示数据观测数,f表示拟合的模型,F表示所有可能模型构成的集合, 表示损失函数, 表示模型f中采用的主成分个数, 表示光滑系数,最终经过交叉验证选定的主成分个数为4,此时平均误判率为0.07511737。在将模型代入测试集进行预测后,得到在测试集的误判率为0.063388028,预测效果还可以,并且在对实验数据的解释度上85%,即对实验数据的信息丢失度较小 [7]。
实验数据的协方差矩阵特征值最大的两个变量对于数据的分类情况如图2所示:
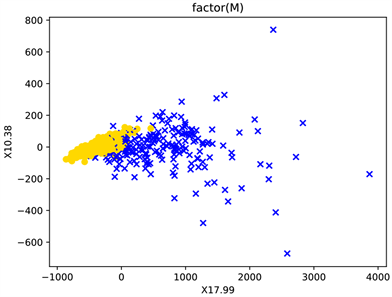
Figure 2. Classification of data by maximum two variables of covariance matrix eigenvalue of experimental data
图2. 实验数据协方差矩阵特征值最大两个变量对数据的分类情况
同时,第1主成分与第5主成分对实验数据的分类情况绘图如图3所示:
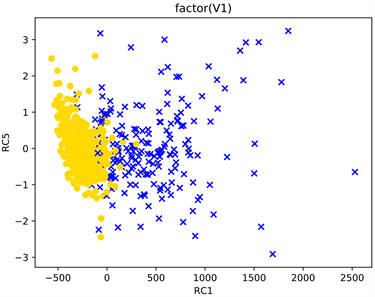
Figure 3. PCA classification of experimental data
图3. PCA对实验数据的分类情况
从图2与图3中可以看出对于本次研究的实验数据主成分分析在一定程度上达到了分类的效果,但是两种类别的分界线明显。
4.3. CUR矩阵恢复
该实验所用的wdbc数据集包含了569位患者的乳腺癌疾病诊断数据集,该数据集包含32列特征。我们的矩阵相似性评估方法用误差率来度量 [8],表示如下:
(9)
其中 。
4.3.1. 实验构造
通过对wdbc数据集进行CUR矩阵分解可以得到数据集的近似矩阵,我们首先统计wdbc数据集的32列特征的影响力评分,也就是观察乳腺癌有哪些主要特征,通过matlab程序计算出影响力评分见下图4、图5所示,图中横坐标表示特征,纵坐标表示影响力度量值 [9]。
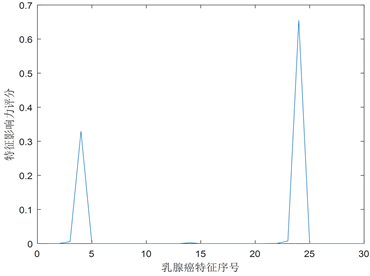
Figure 4. Influence distribution of 32 characteristics of breast cancer
图4. 乳腺癌疾病32列特征的影响力分布
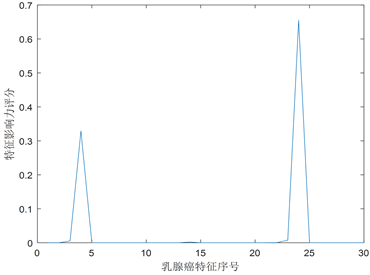
Figure 5. Influence distribution of 569 patients with breast cancer
图5. 乳腺癌疾病569位患者的影响力分布
4.3.2. c和r值的确定
通过cur算法总能算得给定c值和r值之后的恢复矩阵 ,再根据误差定量公式总能算得一个恢复矩阵与原始矩阵的误差值 [10],我们首先给定恒定的r值,遍历所有的 值,观察误差值的变化情况如下图所示,其中横坐标是c的取值,纵坐标是矩阵误差值:
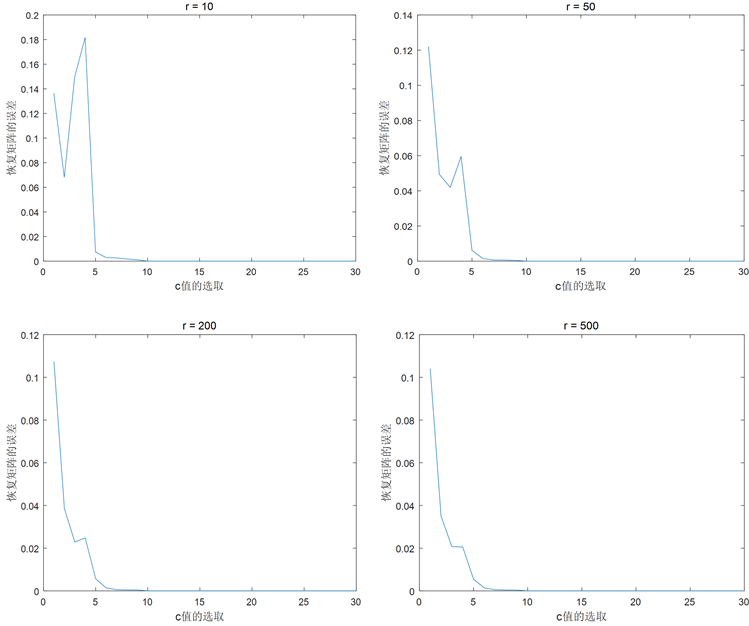
Figure 6. Influence of the selection of constant value on the error of response matrix
图6. r值恒定时c值的选取对回复矩阵误差的影响
见上图6发现r值在取不到15时,矩阵恢复误差接近0。通过上述实验探索我们给定 算得恢复矩阵误差值为0.000501456001661053%。
5. 结论
通过PCA和CUR降维方法对乳腺癌数据集进行分类处理,已知PCA方法是利用降维的思想,在损失信息很少的前提下,把多个指标转化为几个综合指标的多元统计方法,并且可以消除评价指标之间的相互影响,因为降维,所以也为我们减少了工作量,但是由于主成分不是从原始数据中提取出来的,所以解释性不够好,并且在乳腺癌数据集上进行降维处理发现CUR的误差率远小于PCA,所以在减低误差率这一块CUR要好于PCA。
CUR算法在选取行列的时候是根据行列的实际情况比较智能地进行选择,在研究大数据时,我们可以理解为在选择行和列的时候,CUR算法判断矩阵列的统计影响力来判断特征的显著程度,然后根据显著的特征从电影列中进行抓取,所以构造出的C(R)矩阵也反映了癌症良性恶性的现实特征,并且因为C(R)矩阵是由真实的行列构成,因此将C(R)矩阵中的行列数据和Wdbc数据集相比对就能够确定细胞核特征和良性恶性的具体特征,但是在软件操作上CUR比PCA复杂得多,所以如果不是研究高维稀疏的数据集建议用PCA降维方法,但在解释性方面,由于CUR分解方法是在原始数据集中提取出来的,所以其可解释性很强 [11]。
基金项目
北方工业大学毓优人才项目207051360020XN140/007。
文章引用
何丽萍. 高维数据降维中的PCA与CUR分解对比分析
PCA and CUR Decomposition Analysis in Dimensionality Reduction of High-Dimensional Data[J]. 统计学与应用, 2020, 09(02): 256-264. https://doi.org/10.12677/SA.2020.92028
参考文献
- 1. Bobadilla, J., Ortega, F. and Hernando, A. (2013) Recommender Systems Survey. Knowledge-Based Systems, 46, 109-132. https://doi.org/10.1016/j.knosys.2013.03.012
- 2. 林海明. 对主成分分析法运用中十个问题的解析[J]. 统计与决策, 2007(16): 16-18.
- 3. 雷恒鑫, 刘惊雷. 基于行列联合选择矩阵分解的偏好特征提取[J]. 模式识别与人工智能, 2017, 30(3): 279-288.
- 4. 雷恒鑫, 刘惊雷. 利用CUR矩阵分解提高特征选择与矩阵恢复能力[J]. 计算机应用, 2017, 37(3): 640-646.
- 5. Kumar, R., Verma, B.K. and Rastogi, S.S. (2014) Social Popularity Based SVD++ Recommender System. International Journal of Computer Applications, 87, 33-37. https://doi.org/10.5120/15279-4033
- 6. 张梦阳. 矩阵分解的常用方法[J]. 成才之路, 2012(36): 39-39.
- 7. Jia, Y., Zhang, C., Lu, Q., et al. (2014) Users’ Brands Preference Based on SVD++ in Recommender Systems. Proceedings of the 2014 IEEE Workshop on Advanced Research and Technology in Industry Applications, Ottawa, ON, 29-30 September 2014, 1175-1178.
- 8. 王群英. 矩阵分解方法的探究[J]. 长春工业大学学报, 2011, 32(1): 95-101.
- 9. Xu, F., Gu, G., Kong, X., et al. (2016) Object Tracking Based on Two-Dimensional PCA. Optical Review, 23, 231-243. https://doi.org/10.1007/s10043-015-0178-2
- 10. Drineas, P., Mahoney, M.W. and Muthukrishnan, S. (2008) Relative-Error CUR Matrix Decompositions. SIAM Journal on Matrix Analysis and Applications, 30, 844-881. https://doi.org/10.1137/07070471X
- 11. 李明. 基于矩阵分解理论学习的数据降维算法研究[D]: [硕士学位论文]. 大连: 辽宁师范大学, 2011.