Computer Science and Application
Vol.
09
No.
04
(
2019
), Article ID:
29951
,
9
pages
10.12677/CSA.2019.94091
House Price Forecast Based on Grey Fractional Markov Model
Yixuan Yang1, Lang Yu1, Hai Li2
1School of Science, Southwest University of Science and Technology, Mianyang Sichuan
2School of Civil Engineering and Architecture, Southwest University of Science and Technology, Mianyang Sichuan
![]()
Received: Apr. 10th, 2019; accepted: Apr. 19th, 2019; published: Apr. 26th, 2019

ABSTRACT
According to the nonlinearity and complexity of the house price data, this paper combines the fractional-order cumulative generation operator and the Markov correction model to establish the MKFGM(1,1) model, and forecasts and analyzes the house prices of Chengdu from April 2017 to May 1818. Firstly, the particle swarm optimization algorithm is used to search for the optimal order of the cumulative generation operator in the real number domain; combined with the GM(1,1) model, the FGM(1,1) model after changing the order can be obtained; and a preliminary prediction of Chengdu city’s house price is made. Secondly, the relative error between the predicted value and the actual value is divided depending on the states, then the Markov model is used for error correction, and finally the MKFGM(1,1) model is established. Comparing and analyzing the fitting and prediction results of GM(1,1), FGM(1,1) and MKFGM(1,1) models, it can be seen that the MKFGM(1,1) model has a higher accuracy in housing price forecasting.
Keywords:House Price Forecast, Fractional Gray Model, Markov, Prediction Accuracy, PSO
基于灰色分数阶马尔科夫模型的房价预测
杨羿轩1,于浪1,李海2
1西南科技大学理学院,四川 绵阳
2西南科技大学土木工程与建筑学院,四川 绵阳
![]()
收稿日期:2019年4月10日;录用日期:2019年4月19日;发布日期:2019年4月26日

摘 要
针对房价数据的非线性性和复杂性的特点,本文结合分数阶累加生成算子和马尔科夫修正模型建立了MKFGM(1,1)模型,并对成都市2017年4月~2018年5月房价进行预测分析。首先,利用粒子群算法在实数域内搜索累加生成算子的最优阶数r,结合GM(1,1)模型可以得到改变阶数后的FGM(1,1)模型,并对成都市房价数据做出初步预测。其次,将预测值与实际值的相对误差进行状态划分,然后使用马尔科夫模型进行误差修正,最终建立MKFGM(1,1)模型。对比分析GM(1,1)、FGM(1,1)和MKFGM(1,1)模型的拟合及预测结果,可以看出MKFGM(1,1)模型在房价预测方面有更高的精度。
关键词 :房价预测,分数阶灰色模型,马尔科夫,预测精度,PSO

Copyright © 2019 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
在许多国家和地区房地产业已成为国民经济的支柱产业,是经济发展的重要力量。随着我国市场经济的发展,房地产在国民经济中的地位不断提高,影响不断扩大。上世纪90年代中后期,政府明确提出把房地产业作为国民经济新的增长点。房价的高低、升降不仅对经济的发展有很大的影响,同时也影响着人们的生活水平。因而,如何预测房地产的走势,便成为了我们研究的重要问题。
中国对于房价研究起步较晚,主要基于灰色理论和神经网络模型。Zhang等运用GM(1,1)灰色预测方法,建立了沈阳房地产市场的需求和价格预测模型,具有较好的预测精度 [1] 。Sun等从房价的诸多影响因素中选取主要因子,结合GM(1,N)模型得出了昆明市房价的预测模型 [2] 。王钧甲全面考虑房价的影响因素,建立了基于混沌理论的BP神经网络模型 [3] 。王聪对比多元线性回归模型,建立了多因素LOGISTIC回归模型,提高了预测精度 [4] 。Tang等根据北京市二手房年房价指数非线性变化的特点,将BAT算法引入传统SVR模型,对模型的三个参数进行优化。结合Web搜索数据,建立了BA-SVRWSD混合模型 [5] 。郑永坤,刘春等利用差分自回归移动平均来排除其他对房价有影响的复杂因素,建立了ARIMA预测模型 [6] 。前人在房价预测上已经做了很多工作,提出了多种模型,但都存在着一些局限性。灰色GM(1,1)模型所需的样本数据少,但要求数据具有指数增长规律。BP神经网络模型通过输入与输出的非线性映射,对数据具有较高的处理能力,但其训练速率较低,且容易陷入局部最优解。回归预测模型预测过程简单,但预测精度不高,外推特性差。时间序列模型 [7] 原理简单,但难以反映数据内在因素的影响,容易存在较大的误差。
灰色预测模型作为主要的预测模型之一,还具有很多的研究价值。Wu等于2013年提出将分数阶累加生成算子与灰色预测模型相结合的理论,基于新信息优先原理,借助分数阶蕴含的“in between”思想,通过选择合适的累加阶数使得增高序列变平缓,从而提高预测精度 [8] 。Ma等使用grey wolf算法从实数范围内搜索最优累加生成算子,扩大了其取值范围,进一步完善了分数阶理论体系 [9] 。
本文将分数阶累加生成算子与GM(1,1)模型结合,对成都市房价进行短期预测,并借助马尔科夫模型对预测结果进行误差修正,最终建立灰色分数阶马尔科夫预测模型,以下简称MKFGM(1,1)模型。利用2017年4月~2018年3月成都市房价作为建模数据,2018年4、5月房价为预测检验数据。对比分析GM(1,1)模型、FGM(1,1)模型以及本文建立的MKFGM(1,1)模型。结果表明MKFGM(1,1)模型具有更好的拟合效果和更高的预测精度。
2. 灰色分数阶马尔科夫模型
2.1. 分数阶FGM(1,1)模型
定义1:设原始非负序列为 ,则 是 的r阶累加生成序列,其中:
(1)
这里 , , 。
定义2:设 与 如定义1所示, 是 的分数阶累加生成序列, ,其中:
(2)
称灰色微分方程 为r阶累加灰色GM(1,1)模型,即为FGM(1,1)模型。特别的,当阶数r = 1时为GM(1,1)模型。
FGM(1,1)模型 中 可以运用最小二乘法估计:
(3)
其中Y,B分别为:
(4)
其中, 。
定义3:参数如定义2所述,则称
(5)
为r阶累加灰色FGM(1,1)模型 的白化微分方程。设B,Y, 如定义2所述,则求解微分方程(3),可以得到模型 ,令 ,得到时间序列响应式为:
(6)
离散后的得到:
(7)
还原后的值为:
(8)
其中 。
2.2. 马尔科夫模型
马尔科夫过程是一类重要的随机过程。它通过对预测对象不同状态的初始概率和状态之间的转移概率的研究,确定预测对象未来状态的变化趋势。马尔科夫过程适合处理波动的数据且具有无后效性和短期预测效果良好的特点,已被广泛运用到军事、生物、气象等领域 [10] [11] [12] 。
本文运用马尔科夫模型对FGM(1,1)模型的预测值与实际值的相对误差进行状态划分。依据数据序列的状态可以构造状态转移矩阵,从而能够预测出后一个数据最可能所处的误差状态。根据误差状态划分的上下限,即可得到马尔科夫模型的修正值。马尔科夫模型可表示为:
(9)
其中, 分别为在 、h时刻的状态概率向量,P为一步状态转移概率矩阵。
2.2.1. 划分预测状态
根据原始数据与FGM(1,1)模型预测数据的相对误差,可以将误差划分为若干个状态。状态的数量没有严格的限制,一般由原始数据的多少和数据误差的范围大小来确定。状态区间为:
(10)
其中, 分别表示状态区间相对误差的上、下限,u为状态划分数量。
2.2.2. 构造状态转移概率矩阵
由状态 经过一个时期转移到 的一步转移概率为 ,将所有状态的一步转移概率构成一个矩阵,即:
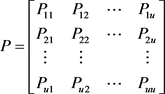 (11)
(11)
其v步转移概率矩阵为 , 。
2.2.3. 确定预测值
选取离预测数据最近的u组数据,按照由近到远的顺序确定步数t为 ,然后取各数据对应的t步状态转移矩阵的行向量构成新的矩阵,由新矩阵的列向量之和确定预测值最可能所处的状态。状
态确定以后,状态区间也就确定了,马尔可夫修正值为该区间的中点,即 ,最终得到的预测值为:
(12)
2.3. 模型误差检验准则
为了检验本文中模型的预测精度,本文采用平均绝对百分误差MAPE来描述拟合预测数据与真实数据的误差。根据模型得出的数据与实际数据可以计算出用于建模的拟合数据(Fitting data)的平均绝对误差(MAPEF),建模后预测数据(Predicted data)的平均绝对误差(MAPEP)和总数据(Total data)的平均绝对误差MAPET,其表达式分别如下:
(13)
(14)
(15)
其中,m是用于预测模型的样本个数,n是样本数据的总个数。
2.4. 最优阶数的确定
使用分数阶FGM(1,1)模型对原始数据进行预测时,首先要确定累加生成算子的阶数r,然后利用式(2)求出参数 。最后利用时间响应方程求出原始数据预测值 。为了找到最优阶数r,本文采用MAPET作为目标函数,形式如下:
(16)
由于以上公式具有非线性性,直接利用公式寻找最优阶数十分困难。为此,本文使用粒子群算法对分数阶算子进行计算。
粒子群算法(PSO)是一种模拟自然界中鸟集群飞行觅食的行为方式演化而来的随机搜索方法。它于1995年由James Kennedy和Russell Eberhart共同提出 [13] 。两人于2001年出版《群体智能》将粒子群算法的影响扩大,引起了国内外学者的广泛关注 [14] 。粒子群算法模拟鸟类的觅食行为,将求解问题的搜索空间类比成鸟类的飞行空间,将每一只鸟抽象成一个没有质量和体积的粒子,用来表征问题的一个可行解,最后将寻找最优解的过程看作鸟类寻找食物的过程,进而求解复杂的优化问题。
粒子群算法作为一种新兴的智能优化算法,主要优点是有很好的并行性和全局寻优能力,并且不存在求导和函数连续性的限定。粒子群算法参数少而容易实现,对于非线性问题和多峰问题都有很好的全局搜索能力。近年来,粒子群算法已被广泛应用于机器学习、函数优化、能源预测、模式分类、自适应控制等领域。本文粒子群算法以MAPET最小为目标,寻找最优阶数,其算法步骤如下:
1) 初始化群体粒子个数,粒子维数等。
2) 初始化种群粒子位置和速度,计算每个粒子的适应度值,分别与个体极值和全局极值的最优位置及最优值比较,择优选取。
3) 迭代更新粒子的速度和位置,进行边界条件处理。
4) 判断是否满足终止条件;若不满足,则继续搜索;若满足,则将该粒子作为粒子群算法的最优计算结果。
3. 成都市房价预测分析
3.1. 样本数据
本文实验所需的数据是通过python爬虫从中国各大房产网站爬取的。这些房产网站都是开放的平台,上面集合了各个地区的房源信息,过滤掉虚假和虚高的房价,最后得出的均价。经过笔者的对比观察,各房产网站的价格几乎一致,具有较高的可信度。最终,本文使用安居客房产网站上成都市2017年4月至2018年5月历史均价数据作为实验研究基础。
3.2. FGM(1,1)模型预测
将以上所得数据导入matlab程序中,利用粒子群算法得出累加生成算子的最优阶数为−0.37。则FGM(1,1)模型为GM-0.37(1,1)。并且,由最小二乘法得出参数a = −0.1513,b = 27912.0302,时间响应式为:
(17)
根据累减还原式(4),当 时,则可计算得到预测值。另外,可取阶数r为1,得到GM(1,1)模型的预测值。将GM(1,1)模型与FGM(1,1)模型的预测值和实际值相比,结果如表1所示:

Table 1. Comparison data between GM(1,1) and FGM(1,1) models.
表1. GM(1,1)和FGM(1,1)模型之间的比较数据
3.3. 马尔科夫模型修正
3.3.1. 对每个月进行状态区间划分
根据FGM(1,1)模型的相对误差划分状态区间,从表1可以看出FGM(1,1)模型的前12个拟合数据相对误差的最小值为−1.099%,最大值为2.169%。由此,根据等间距规则划分四个状态区间,分别为 , , , ,如表2所示:
Table 2. State partition
表2. 状态划分区间
3.3.2. 构建状态转移矩阵
根据每个数据所处的状态,以及由当前状态到下一个状态的概率,得到如下的1、2、3、4步状态转移概率矩阵:
,
,
3.3.3. 计算预测值
选择最近的几组数据构建新的状态转移矩阵,见表3:
Table 3. State transition matrix predicting the state of April 2018
表3. 预测2018年4月所属状态的状态转移矩阵
通过表3可知,2018年4月最有可能所属的状态是 ,并且本月FGM(1,1)模型的预测值为13,172.479,根据公式(12)可得马尔科夫模型预测值为13,487.499。
在进行2018年5月数据预测时,可以将2018年4月数据按已知量计算,按照上述方法,得出2018年5月预测值为13,487.499。MKFGM(1,1)模型2017.4~2018.5的拟合及预测数据见表4:
Table 4. Comparison data between FGM(1,1) and MKFGM(1,1) models
表4. FGM(1,1)和MKFGM(1,1)模型之间的比较数据
从表4可以看出FGM(1,1)模型已经具有一定的效果,预测结果良好,而本文建立的MKFGM(1,1)模型则更加精确。
为了比较GM(1,1)模型、FGM(1,1)模型、MKFGM(1,1)模型的预测精度,以表4中前12个数据为拟合数据,后2个数据为预测数据,根据式(6)、(7)、(8)分别计算3种模型的MAPEF、MAPEP和MAPET,结果见表5。另外,为了更直观地展示3种模型的预测效果,图1 (左图)绘制了GM(1,1),FGM(1,1)和MKFGM(1,1)模型的拟合预测曲线,图1 (右图)给出了3种模型的相对误差的绝对值的对比情况。
Table 5. The average absolute percentage error of the fitting, prediction and total data for the three models
表5. 三种模型的拟合、预测、总数据的平均绝对百分误差
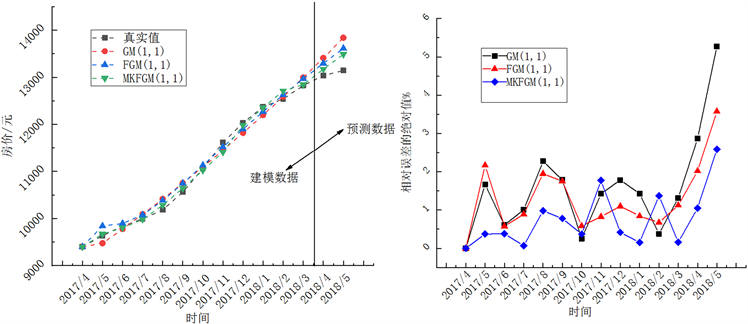
Figure 1. Three models fitting prediction comparison chart
图1. 三种模型拟合预测对比图
从表5可以看出,GM(1,1)模型的MAPEF、MAPEP、MAPET分别为1.161%、4.073%、1.577%,FGM(1,1)模型的MAPEF、MAPEP、MAPET较好,分别为1.041%、2.798%、1.292%,MKFGM(1,1)模型的MAPEF、MAPEP、MAPET分别为0.569%、1.818%、0.748%。其中,MKFGM(1,1)模型的MAPEF、MAPEP、MAPET均最低,说明MKFGM(1,1)模型的拟合数据波动最小,拟合程度最高,并且预测结果也最好。从图1的左图和右图也可以直观地看出MKFGM(1,1)模型的建模数据和预测数据均最贴合实际数据,并且其相对误差的绝对值波动范围最小。
4. 结论
灰色预测模型可以通过少量的、信息匮乏的数据进行建模,从而找出数据内部隐含的规律,并对数据进行短期预测。本文使用粒子群算法搜索FGM(1,1)模型的累加生成算子的最优阶数,初步改进了GM(1,1)模型。再使用马尔科夫模型对FGM(1,1)模型的预测结果进行误差修正,得到了本文的MKFGM(1,1)模型。对比分析GM(1,1)、FGM(1,1)和MKFGM(1,1)模型的拟合及预测结果,可以得到以下结论:
1) 三个模型的MAPEF、MAPEP、MAPET均在5%以下,说明这三个模型应用于房价预测都是切实有效的。
2) 本文建立的MKFGM(1,1)模型的预测精度最高,MAPET仅为0.748%,远低于GM(1,1)模型和FGM(1,1)模型,改进效果显著。
3) MKFGM(1,1)模型作为一种优秀且稳定的预测模型,可考虑将其进一步应用在金融、能源、交通运输等领域。
基金项目
西南科技大学理学院创新基金项目“基于scrapy的房地产数据爬虫系统”(项目编号:LXCX-19),主持人:杨羿轩。
文章引用
杨羿轩,于 浪,李 海. 基于灰色分数阶马尔科夫模型的房价预测
House Price Forecast Based on Grey Fractional Markov Model[J]. 计算机科学与应用, 2019, 09(04): 802-810. https://doi.org/10.12677/CSA.2019.94091
参考文献
- 1. Zhang, S., Gao, M. and Wang, X. (2010) The Real Estate Market Forecast of Shenyang Based on Gray System Theory. International Conference on Management & Service Science, Wuhan, 24-26 August 2010, 1-4.
- 2. Sun, Y.M. and Wu, L.G. (2013) Case Analysis of GM(1,N) Model in Predicting Kunming Real Estate Prices. Applied Mechanics and Mate-rials, 444-445, 1781-1786. https://doi.org/10.4028/www.scientific.net/AMM.444-445.1781
- 3. 王钧甲. 基于混沌理论的沈阳普通商品住宅价格研究[D]: [硕士学位论文]. 沈阳: 沈阳建筑大学, 2014.
- 4. 王聪. 基于多因素LOGISTIC的城市房地产价格预测模型研究[D]: [硕士学位论文]. 大连: 大连理工大学, 2008.
- 5. Tang, X., et al. (2018) Research on Forecast of Second-Hand House Price in Beijing Based on SVR Model of Bat Algorithm. Statistical Research, 35, 71-81.
- 6. 郑永坤, 刘春. 基于ARIMA模型的二手房价格预测[J]. 计算机与现代化, 2018(4): 122-126.
- 7. Box, G.E.P., Jenkins, G.M. and Reinsel, G.C. (2008) Time Series Analysis: Forecasting and Control. 4th Edition, Wiley, Hoboken.
- 8. Wu, L., Liu, S., Yao, L., et al. (2013) Grey System Model with the Fractional Order Ac-cumulation. Communications in Nonlinear Science and Numerical Simulation, 18, 1775-1785. https://doi.org/10.1016/j.cnsns.2012.11.017
- 9. Ma, X., Xie, M., Wu, W., et al. (2019) The Novel Fractional Dis-crete Multivariate Grey System Model and Its Applications. Applied Mathematical Modeling, 70, 402-424. https://doi.org/10.1016/j.apm.2019.01.039
- 10. Şahingil, M.C. and Yurttaş, R. (2012) The Determination of Flare Launching Programs to Use against Pulse Width Modulating Guided Missile Seekers via Hidden Markov Mod-els.
- 11. Krogh, A., Larsson, B., Von, G.H., et al. (2001) Predicting Transmembrane Protein Topology with a Hidden Markov Model: Application to Complete Genomes. Journal of Molecular Biology, 305, 567-580. https://doi.org/10.1006/jmbi.2000.4315
- 12. Thyer, M. and Kuczera, G. (2000) Modeling Long-Term Persistence in Hydroclimatic Time Series Using a Hidden State Markov Model. Water Resources Research, 36, 3301-3310. https://doi.org/10.1029/2000WR900157
- 13. Kennedy, J. and Eberhart, R. (1995) Particle Swarm Optimization. IEEE International Conference on Neural Networks, Perth, Vol. 4, 1942-1948.
- 14. Kennedy, J. and Eberhart, R.C. (2001) Swarm Intelligence. Academic Press, Cambridge.