Advances in Applied Mathematics
Vol.
12
No.
03
(
2023
), Article ID:
62489
,
11
pages
10.12677/AAM.2023.123099
结合特征金字塔网络的半监督AP聚类算法
文静,俞卫琴*
上海工程技术大学,数理与统计学院,上海
收稿日期:2023年2月13日;录用日期:2023年3月8日;发布日期:2023年3月15日

摘要
为使AP算法对图像进行聚类时充分考虑不同尺度的特征及有效利用未标记数据的特征,提出了结合特征金字塔网络的半监督AP聚类算法(Semi-supervised AP clustering Based on Feature Pyramid Networks, FPNSAP)。FPNSAP算法使用改进的特征金字塔网络来获得图像不同尺度的特征图,对不同大小的特征图进行融合,获得图像的高级语义特征,识别不同大小、不同实例的目标;k近邻标记更新策略可以动态增加标记数据集样本数量,充分利用未标记数据的特征,提高AP算法的聚类性能。FPNSAP算法与四个经典算法(FCH、SAP、DCN和DFCM)在Fashion-MNIST、YaleB和CIFAR-10数据集上进行实验对比,结果表明,FPNSAP算法具有较高的聚类性能,同时算法的鲁棒性更好。
关键词
特征金字塔网络,k近邻标记更新策略,半监督聚类,AP聚类算法

Semi-Supervised AP Clustering Based on Feature Pyramid Networks
Jing Wen, Weiqin Yu*
School of Mathematics, Physics and Statistics, Shanghai University of Engineering Science, Shanghai
Received: Feb. 13th, 2023; accepted: Mar. 8th, 2023; published: Mar. 15th, 2023

ABSTRACT
In order to make the AP algorithm fully consider the features of different scales and effectively use the features of unlabeled data when clustering images, a semi-supervised AP clustering based on feature pyramid network (FPNSAP) is proposed. FPNSAP algorithm uses an improved feature pyramid network to obtain feature maps of different scales, fuses feature maps of different sizes to obtain high-level semantic features of images and identify targets of different sizes and instances; The k-nearest neighbor label updating strategy can dynamically increase the number of labeled data sets, make full use of the characteristics of unlabeled data, and thus improve the clustering performance of AP algorithm. FPNSAP is compared with four classical algorithms (FCH, SAP, DCN and DFCM) on the Fashion-MNIST, YaleB and CIFAR-10 datasets. The experimental results show that FPNSAP has higher clustering performance and better robustness.
Keywords:Feature Pyramid Networks, K-Nearest Neighbors Label Updating Strategy, Semi-Supervised Clustering, AP Clustering

Copyright © 2023 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
数据挖掘技术在多个领域有广泛的应用,近些年来已成为研究者关注的领域。聚类分析作为数据挖掘的重要技术之一,也广泛应用于各种场景,如社交网络分析 [1] [2] 、计算机视觉 [3] 、自然语言处理和知识发现 [4] 等。一般的聚类算法只对未标记的数据进行聚类,这种聚类方法一般可以分为三种类型:1) 基于特征学习的方法。这类方法试图通过结合数据降维技术 [5] [6] 或子空间学习技术 [7] 来寻找更多的鉴别特征。2) 基于度量学习的方法。这些方法旨在为训练数据学习提供一个适当的距离度量 [8] [9] 。在学习到的距离度量下,它可以将相似的样本分在一组,同时将不同的样本分开。3) 基于图的聚类。这种方法先将数据表达为一个图,然后再将聚类问题转化为图划分问题。一般地,在没有任何监督信息的情况下提取足够的语义特征并在高维数据中学习适当的度量标准是一项具有挑战性的任务。因此,研究学者提出了半监督聚类算法来改进聚类性能。肖宇等 [10] 用成对约束信息调整数据形成的相似度矩阵改进了近邻传播(Affinity Propagation, AP)算法的聚类性能。Tuan等 [11] 提出了改进的半监督模糊C-均值聚类(SSFCM),通过使用多个模糊化分类器来提高聚类质量。Tao等 [12] 采用密度峰值聚类算法为标记和未标记数据生成伪聚类标签,然后探索生成的伪标签以构建两种正则化策略,以解决现有的半监督FISHER判别分析算法(FDA)不能有效地使用标记和未标记数据进行学习的问题。Zhao等 [13] 提出了一种基于密度峰值和自然邻域的自训练方法,解决大多数自训练方法受到初始标记数据分布的限制并且严重依赖于参数的问题。
为了在对图像数据集进行AP聚类时,充分提取图像的高层次语义特征,并且充分利用数据的特征,特别是未标记数据的特征,本文提出了一种结合特征金字塔网络的半监督AP聚类算法。首先利用特征金字塔网络作为网络的特征提取器提取不同尺度的特征并进行特征融合,确保聚类时已经得到了足够的语义特征,同时使网络在速度和准确性上得到平衡,接着对已经提取到的融合特征进行AP聚类,最后结合半监督思想使用k近邻标记更新策略动态增加标记数据集,进而提高AP聚类算法对图像的聚类性能。
2. FPNSAP算法
2.1. 特征金字塔网络
特征金字塔网络(Feature pyramid network, FPN) [14] 是根据金字塔的概念来设计的特征提取器,对不同尺寸的目标都有很好的检测效果,被广泛应用于图像的特征提取 [15] 。

Figure 1. Feature pyramid network
图1. 特征金字塔网络
本模型的特征金字塔网络主要由三部分组成,分别是自上而下(top-down)采样部分、自下而上(bottom-up)采样部分和横向连接(lateral connections)部分,网络架构如图1所示。自上而下采样是卷积神经网络对初始图像前向计算,图像输入大小为224 × 224,首先使用一个大的卷积核(5 × 5)对图像做初始卷积处理,之后使用Inception模块依次对图像进行下采样,使用两次辅助计算模块:Aux_Logits,得到图像的特征图大小分别为28 × 28和14 × 14,与上采样网络进行拼接处理,做不同尺寸的特征融合。自下而上采样是对具有高级语义特征的大小为7 × 7的特征图进行上采样,将上采样结果与下采样层输出的相同尺寸的特征图进行融合。其中横向连接是将相同尺寸的特征图按元素相加生成最终的融合特征图 [16] 。这样做是因为图像高层的特征语义多,低层的特征语义少但位置信息多,这样便可以在所有尺度上构建高级语义特征图。与FPN不同的是,本文没有分别利用融合后的特征进行聚类操作,而是通过双线性插值上采样和卷积层卷积操作将最后输出的融合特征图转化为既定大小。
本文使用GoogLeNet作为特征金字塔网络的主干网络。如图1的左侧“Conv + Maxpool + BN”表示第一个卷积模块。“Inception3、Inception4、Inception5”表示不同的卷积模块,每个Inception卷积块都是由不同数量的卷积层堆叠而成,每个Inception模块具体结构如图2所示。
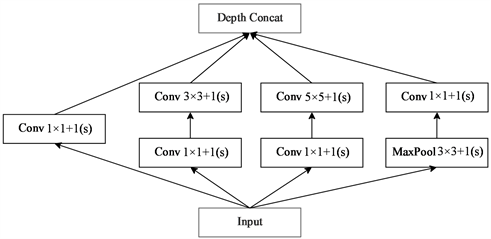
Figure 2. Inception convolution block
图2. Inception卷积块
两个辅助分类器“Aux_logits”的结构相同,但是输出的特征如的尺寸不同,第一层是一个平均池化下采样层,池化核大小为5 × 5,步长为3;第二层是全连接层,通道数是2048;第四层是全连接层,通道数是对应分类的类别个数,根据数据集动态调整。接着通过自上而下的网络将上层特征尺寸上采样,为了和对应下层特征尺寸相同,将对应元素相加“concat”获得融合特征。最后将融合后的特征图使用Conv进行通道改变适应不同的数据集样本分类数量。
2.2. K近邻标记传播策略
本文利用未标记数据通过k近邻标记传播策略对聚类结果进行优化,动态增加标记数据集,从而提高聚类度量学习的性能 [17] 。图3(a)展示了现有的半监督聚类模型架构,它用固定的数据集(标记数据和未标记数据)统一输入训练网络模型 [18] ,而在本文的网络模型中,将通过逐步更新标记数据来不断改进模型(标记数据逐步增加和未标记数据逐步减少),进而充分利用数据的特征,特别是未标记数据的特征,如图3(b)所示。
 (a) 现有的半监督模型
(a) 现有的半监督模型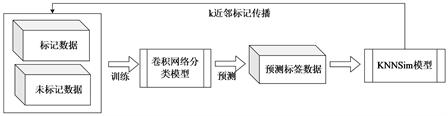 (b) 本文半监督模型
(b) 本文半监督模型
Figure 3. Semi-supervised clustering model
图3. 半监督聚类模型
AP聚类后所有的数据都被归为C个簇类,每个簇类包含有限的标记数据,而有大量的未标记数据。为了充分利用未标记数据的特征,我们每次都向标记数据集中添加k × C个新的未标记数据。K近邻标记更新策略的主要过程如下。
步骤1:根据标记的数据计算每个簇的中心。
(1)
其中, 代表已标记样本, 代表簇类 中标记样本的数量, 代表簇类的数目, 代表样本 的标签。
步骤2:从每个集群中已标记数据的中心搜索k个最近的未标记数据,然后将其属性从未标记数据更新为已标记数据。集群 中新添加的标记数据Δ可以通过以下方法计算:
(2)
其中, 表示第i个簇中未标记的样本 , 是距离函数, 表示对X个元素进行递增排序并返回前k个元素。
例如,在图4中,实心点表示已标记的数据,而空心点表示未标记的数据。在找到每个聚类的标记数据中心后,每个聚类生成四个新的标记数据,它们是距离该中心最近的未标记样本。随着标记数据数量的增加,我们可以学习更具鲁棒性和区分性的特征,这将进一步提高聚类算法的准确性。
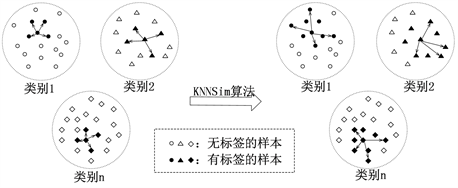
Figure 4. K-nearest neighbors label updating strategy
图4. k近邻标记更新策略
2.3. AP聚类算法
AP聚类算法的核心思想是通过在不同点之间不断的传递信息,根据数据点间的相似度信息进行更新迭代从而选出聚类中心完成聚类。AP算法是利用样本间负的欧几里得距离来计算样本间相似度,以所有相似度组成相似度矩阵为基础来聚类 [19] 。例如,点 和点 间的相似度为 。AP算法中把全部数据点都当作可能的候选类代表点,计算两两之间的相似度形成相似度矩阵网络,再通过网络中各条边上的信息 和 迭代计算出各样本的类代表点。用 代表“吸引度”信息,用 代表“归属度”信息。 与 的和越大,该候选类代表点作为最后类代表点的概率就越大。这样,每个样本点通过反复迭代和竞争就会得到最终聚类数据集的类代表点。AP算法的迭代过程如下:
1) 初始化:计算相似度矩阵 ,偏向参数p值,即相似度矩阵对角线上的值 。初始化R和A为0: 。
2) 更新迭代过程:
① 更新信息量R和A。对 的更新过程是所有数据点对候选类代表点的选择,可以理解为用 减去对候选类代表点最具竞争的类代表点;对 的更新过程对应候选类代表点对某一数据点的影响, 表明其他数据点选择该候选类代表点,那么这一数据点也更倾向于选择该候选类代表点。R和A的更新公式如下:
(3)
(4)
(5)
② 引入阻尼系数λ
阻尼系数是信息更新迭代步骤中的一个重要参数,使用阻尼系数衰减 和 ,针对上一次迭代的 和 进行加权更新,以免在更新的过程中出现数值振荡。加权更新公式如下:
(6)
(7)
(8)
其中 , 越大对 和 的衰减作用越明显。
③ 判断信息迭代是否满足终止条件:更新迭代次数超过第一次设置的最大迭代次数,信息变化小于某个阈值,在连续几次更新迭代中,选定的类代表点不会发生变化,满足条件之一即可 [20] 。
3) 判断最终得出的聚类数量是否符合样本的聚类要求,若不符合,则变化p值,重复进行迭代直到最后的聚类数量符合要求,最后输出最终的聚类结果。
2.4. 整体算法框架
如图5,本文首先利用标记样本训练特征金字塔网络,以提取图像不同层次的特征,得到不同尺度的特征图。金字塔网络的损失函数使用Focal Loss作为整个特征提取器的目标函数。损失函数计算如下:
(9)
令 , 为可调节因子,此处取 ,此时将(9)统一为:
(10)
然后利用AP聚类算法进行聚类。
最后,根据上述步骤的聚类结果,使用k近邻标记更新策略动态增加标记数据集对未标记数据进行分类,并将分类结果记录为未标记数据的标签。图5为整个FPNSAP网络的架构图。
3. 实验与分析
3.1. 实验数据集与比较算法
本文在三个公开数据集上进行了对比实验,包括:Fashion-MNIST、YaleB和CIFAR-10数据集。
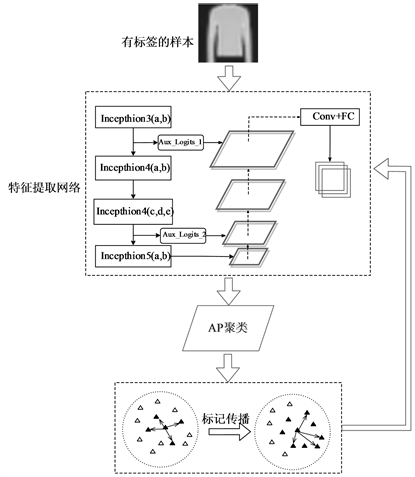
Figure 5. FPNSAP’s algorithm framework
图5. FPNSAP算法框架
Fashion-MNIST数据集由70000张共10个类别的图像组成,分别为t-shirt (T恤)、trouser (裤子)、pullover (套衫)、dress (连衣裙)、coat (外套)、sandal (凉鞋)、shirt (衬衫)、sneaker (运动鞋)、bag (包)和ankle boot (短靴);YaleB数据集由2414张灰度人脸图像,其中包括38人,每个人从5个不同的角度捕获的64张人脸图像;CIFRA-10数据集由60000张32 × 32彩色图像组成,有airplane (飞机)、automobile (汽车)、bird (鸟)、cat (猫)、deer (鹿)、dog (狗)、frog (蛙)、horse (马)、ship (船)和truck (卡车)一共10类,每个类别包含6000个样本。
为了评估本文所提出算法的有效性,将本文算法与以下相关算法进行了比较:
1) 传统的无监督算法,FCH [5] ;
2) 传统的半监督算法,SAP [10] ;
3) 基于深度学习的无监督算法,DCN [8] ;
4) 基于深度学习的半监督算法,DFCM [13] 。
3.2. 评价指标
为了评估本文算法与比较算法的性能,采用F-Measure [21] 。和归一化互信息(Normalized Mutual Information, NMI)这两种评价指标,这两种评价指标已广泛应用于评价聚类算法的性能 [22] 。
F-Measure指标既考虑了算法的查准率也考虑了算法的查全率,是分类问题中的常用的综合评价的指标。对于样本类t以及样本的聚类 ,查准率和查全率: , 。其中, :聚类得到的聚类簇k中类别为t的样本数; :聚类得到的聚类簇k中的样本总数 :样本集中类别t中的样本总数。那么,F-Measure可以表示为:
(11)
其中, 为参数变量,本文使用 进行计算。F-Measure的取值范围是[0, 1],F-Measure的值越大算法的聚类结果越准确。
NMI将度量两个聚类结果的相似度,即将聚类结果和真实标签相比较,值域是[0, 1],值越高表示两个聚类结果越相似,公式为:
(12)
其中,Y代表真实的簇类;C代表聚类结果; 代表交叉熵, ,log以2为底; 代表互信息, ,可以看成是一个随机变量由于已知另一个随机变量而减少的不确定性。
3.3. 实验与分析
1) 在Fashion-MNIST、YaleB和CIFAR-10数据集上比较实验算法与本文算法的聚类性能,设置半监督算法SAP、DFCM和FPNSAP标记数据的比例为10%,实验结果如下表1所示,最佳结果以粗体显示。可以看出,本文FPNSAP算法优于经典的比较算法。具体来说,与传统的聚类算法(FCH、SAP)相比,本文算法结合特征金字塔网络学习到了样本的深层强语义和更具鲁棒性的特征,而FCH算法是不利用标签信息无监督的聚类,进一步削弱了其聚类性能;与基于深度学习的聚类算法(DCN、DFCM)相比,本文FPNSAP算法充分提取了图像不同尺度的强语义特征,聚类性能更优越。

Table 1. Comparison of experimental results
表1. 对比实验结果
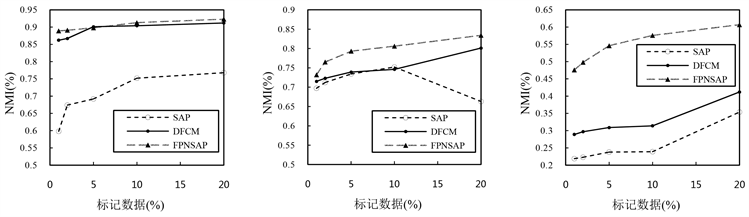
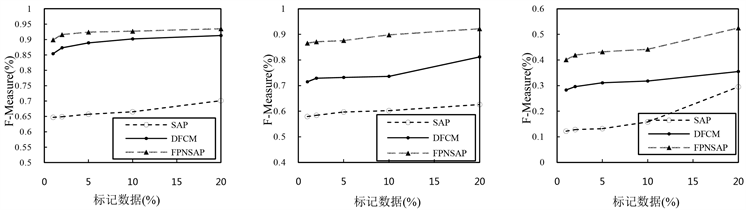
2) 本文FPNSAP算法与传统的半监督算法SAP和基于深度学习的半监督算法DFCM相比较,实验结果如表2、表3所示,最佳结果以粗体显示。可以看出,随着标记样本从1%增加到10%,SAP、DFCM和FPNSAP聚类算法性能逐步提升,FPNSAP算法聚类性能均优于SAP和DFCM这两种半监督聚类算法,聚类性能在图6、图7中可视化表示。
Table 2. NMI index
表2. NMI指标
Table 3. F-Measure index
表3. F-Measure指标
 (a) Fashion-MNIST (b) YaleB (c) CIFAR-10
(a) Fashion-MNIST (b) YaleB (c) CIFAR-10
Figure 6. NMI index
图6. NMI指标
 (a) Fashion-MNIST (b) YaleB (c) CIFAR-10
(a) Fashion-MNIST (b) YaleB (c) CIFAR-10
Figure 7. F-Measure index
图7. F-Measure指标
4. 结语
本文提出了一种结合特征金字塔网络的半监督AP聚类算法(FPNSAP)来解决利用深度度量学习网络提取更有区别的特征,并充分利用未标记数据特征的问题。首先输入少量标记样本,利用改进GoogLeNet主干网络搭建特征金字塔网络,提取图像不同尺度融合的特征图。然后利用提取的融合特征进行AP聚类,接着利用k近邻标记更新策略动态增加标记样本,充分利用未标记样本的特征。最后,将更新的标记样本再次输入特征金字塔网络,提取特征后进行AP聚类。在Fashion-MNIST、YaleB和CIFAR-10进行了实验,证明本文FPNSAP算法聚类性能更强且鲁棒性更好。
文章引用
文 静,俞卫琴. 结合特征金字塔网络的半监督AP聚类算法
Semi-Supervised AP Clustering Based on Feature Pyramid Networks[J]. 应用数学进展, 2023, 12(03): 969-979. https://doi.org/10.12677/AAM.2023.123099
参考文献
- 1. Chen, H., Yin, H.Z., Wang, W.Q., Nguyen, Q.V.H. and Li, X. (2018) PME: Projected Metric Embedding on Heteroge-neous Networks for Link Prediction. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, 19-23 August 2018, 1177-1186. https://doi.org/10.1145/3219819.3219986
- 2. Wang, Q.Y., Yin, H.Z., Wang, W.Q., Huang, Z, Guo, G.B. and Nguyen, Q.V.H. (2019) Multi-Hop Path Queries over Knowledge Graphs with Neural Memory Networks. 24th Interna-tional Conference, DASFAA 2019, Chiang Mai, 22-25 April 2019, 777-794. https://doi.org/10.1007/978-3-030-18576-3_46
- 3. Liu, G., Zheng, K., Wang, Y., Orgun, M.A., Liu, A., Zhao, L. and Zhao, X. (2015) Multi-Constrained Graph Pattern Matching in Large-Scale Contextual Social Graphs. IEEE 31st In-ternational Conference on Data Engineering, Seoul, 13-17 April 2015, 351-362. https://doi.org/10.1109/ICDE.2015.7113297
- 4. Zheng, B., Han, S., Wen, H., Kai, Z., Zhou, X. and Li, G. (2018) Efficient Clue-Based Route Search on Road Networks (Extended Abstract). IEEE 34th International Conference on Data Engineering (ICDE), Paris, 16-19 April 2018, 1783-1784. https://doi.org/10.1109/ICDE.2018.00249
- 5. Saha, A. and Das, S. (2018) Clustering of Fuzzy Data and Simul-taneous Feature Selection: A Model Selection Approach. Fuzzy Sets and Systems, 340, 1-37. https://doi.org/10.1016/j.fss.2017.11.015
- 6. Yuan, T., Deng, W., Hu, J., An, Z. and Tang, Y. (2019) Unsuper-vised Adaptive Hashing Based on Feature Clustering. Neurocomputing, 323, 373-382. https://doi.org/10.1016/j.neucom.2018.10.015
- 7. Abavisani, M. and Patel, V.M. (2018) Multimodal Sparse and Low-Rank Subspace Clustering. Information Fusion, 39, 168-177. https://doi.org/10.1016/j.inffus.2017.05.002
- 8. Bo, Y., Fu, X., Sidiropoulos, N.D. and Hong, M. (2017) To-wards k-Means-Friendly Spaces: Simultaneous Deep Learning and Clustering. Proceedings of the 34th International Conference on Machine Learning, 70, 3861-3870.
- 9. Zhou, P., Wang, N., Zhao, S. and Zhang, Y.P. (2022) Robust Semi-Supervised Clustering via Data Transductive Warping. Applied Intelligence, 53, 1254-1270. https://doi.org/10.1007/s10489-022-03493-5
- 10. 肖宇, 于剑. 基于近邻传播算法的半监督聚类[J]. 软件学报, 2008, 19(11): 2803-2813.
- 11. Tuan, T.M., Sinh, M.D. and Khang, T.D. (2022) A New Approach for Semi-Supervised Fuzzy Clustering with Multiple Fuzzifiers. Fuzzy Sets and Systems, 24, 3688-3701. https://doi.org/10.1007/s40815-022-01363-3
- 12. Tao, X.M., Bao, Y.X. and Zhang, X.H. (2022) Regularized Semi-Supervised KLFDA Algorithm Based on Density Peak Clustering. Neural Computing and Applications, 34, 19791-19817. https://doi.org/10.1007/s00521-022-07495-9
- 13. Zhao, S.W. and Li, J.N. (2021) A Semi-Supervised Self-Training Method Based on Density Peaks and Natural Neighbors. Journal of Ambient Intelligence and Humanized Computing, 12, 2939-2953. https://doi.org/10.1007/s12652-020-02451-8
- 14. Lin, T.Y., Dollar, P., Girshick, R., He, K.M., Hariharan, B. and Belongie, B. (2017) Feature Pyramid Networks for Object Detection. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, 21-26 July 2017, 936-944. https://doi.org/10.1109/CVPR.2017.106
- 15. 廖永为, 张桂鹏, 杨振国, 刘文印. 全卷积目标检测的改进算法[J]. 计算机工程与应用, 2022, 58(17): 158-164.
- 16. 毛君宇, 何廷年, 郭艺, 李爱斌. 基于全局注意力及金字塔卷积网络的表情识别[J]. 计算机工程与应用, 2022, 58(23): 214-220.
- 17. Arshad, A., Riaz, S., Jiao, L.C. and Murthy, A. (2018) Semi-Supervised Deep Fuzzy C-Mean Clustering for Software Fault Prediction. IEEE Access, 6, 25675-25685. https://doi.org/10.1109/ACCESS.2018.2835304
- 18. 王保加, 潘海为, 谢晓芹, 张志强, 马晓宁. 基于多模态特征的医学图像聚类方法[J]. 计算机科学与探索, 2018, 12(3): 411-422.
- 19. 唐丹, 张正军. 近邻传播聚类算法的优化[J]. 计算机应用, 2017, 37(S1): 258-261.
- 20. 战宇, 潘海为, 韩启龙, 谢晓芹, 张志强. 一种运用图熵的医学图像聚类方法[J]. 小型微型计算机系统, 2016, 37(7): 1594-1599.
- 21. 冯晓磊, 于洪涛. 基于流形距离的半监督近邻传播聚类算法[J]. 计算机应用研究, 2011, 28(10): 3656-3658+3664.
- 22. 李春忠, 靖稳峰, 徐健. 基于多尺度信息融合的层次聚类算法[J]. 工程数学学报, 2019, 36(3): 245-255.
NOTES
*通讯作者。