Computer Science and Application
Vol.
10
No.
02
(
2020
), Article ID:
34301
,
11
pages
10.12677/CSA.2020.102036
Research on Two-View Multi-Instance Image Classification Based on Similarity
Zijian Yin1, Yanshan Xiao1, Bo Liu2
1Department of Computer, Guangdong University of Technology, Guangzhou Guangdong
2Department of Automation, Guangdong University of Technology, Guangzhou Guangdong

Received: Feb. 3rd, 2020; accepted: Feb. 18th, 2020; published: Feb. 25th, 2020

ABSTRACT
In practice, some data contains a lot of privileged information, which can be used to train the classifier to improve classification performance. For example, in image classification, labels are used to describe images. These labels can be regarded as privileged information. The privileged information is complementary to the image and can be used for learning to improve the performance of image classification. The characteristics of multi-instance learning and two-view learning are suitable for image classification with privileged information. Therefore, a two-view multi-instance method based on similarity is proposed for image classification with privileged information. The proposed method considers one image as an instance, a collection of several images as a package, and privileged information as an instance. In order to solve the problem that the labels in the instances are unknown in practice, a similarity model is introduced. The proposed method first divides the image and privilege information into two different perspectives, then uses a clustering algorithm to construct the package, and finally trains a support vector machine classifier. The experimental results on four data sets show that the proposed method is more accurate than other similar models, and the two packet clustering algorithms are compared, and the sensitivity of each parameter is analyzed.
Keywords:Multi-Instance Learning, Two-View Learning, Image Classification, Support Vector Machine, Privileged Information

基于相似度的两视角多示例图像分类方法研究
尹子健1,肖燕珊1,刘波2
1广东工业大学计算机学院,广东 广州
2广东工业大学自动化学院,广东 广州

收稿日期:2020年2月3日;录用日期:2020年2月18日;发布日期:2020年2月25日

摘 要
在实际中,某些数据中包含许多特权信息,可用于训练分类器,从而提高分类性能。例如,在图像分类中,标签用于描述图像,这些标签可视为特权信息,特权信息与图像互补,可以用于学习以此提高图像分类性能。多示例学习和两视角学习的特性适用于带有特权信息的图像分类,因此提出了一种基于相似度的两视角多示例方法用于带有特权信息的图像分类。所提方法将一张图像视为一个示例,若干张图像的集合视为包,将特权信息视为示例。为解决实际中示例的标签是未知的问题,因而引入相似度模型。所提方法首先将图像和特权信息划分为两个不同的视角,然后使用聚类算法构造包,最后训练支持向量机分类器。在四个数据集上的实验结果表明,所提方法与其他相类似模型相比精确率更高,并比较了两种包的聚类算法,分析了各参数敏感度。
关键词 :多示例学习,两视角学习,图像分类,支持向量机,特权信息

Copyright © 2020 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
多示例学习是从监督学习算法的基础上进化而来的,是为解决包(多个示例的集合)的分类 [1]。在传统的多示例学习中,示例分为正示例和负示例,当包中至少有一个正示例时,该包的标签标记为正,称为正包;当包中的实例都是负示例时,该包的标签标记为负,称为负包。多示例学习的任务就是把已知标签的包进行训练,然后对未知标签的包的标签进行预测。
近年来,图像分类是计算机视觉领域的研究热点之一,也是其他图像应用领域的基础。因多示例学习二分类的特性,多示例学习也越来越多地应用在图像分类领域中,对于包与示例的定义有两种,一种定义是将一张图像视为一个包,对图像分割后的产生的每个区域视为一个示例 [2]。例如,Rao等人 [3] 提出一种基于多尺度块的情感分类方法,该方法首先使用不同的图像分割方法提取多个比例的图像块,然后用多示例学习对图像的主要情感类型进行分类。另一种定义是将一张图像视为一个示例,把多张图像的集合视为包 [4]。例如,Duan等人 [4] 提出GMI (generalized multi-instance)学习算法,该算法使用k-means聚类算法根据低级的视觉特征将相关的多张图像聚合成一个包,包中的图像视为示例,从而将图像分类问题转换成多示例学习问题。
尽管针对图像分类的多示例学习的研究有很多,但大多数都假设训练数据和测试数据具有相同数量的特征。但是,现实中可能会遇到这样的情况,即训练数据具有比测试数据更多的特征,而额外的特征通常称为特权信息 [5]。在图像分类中,特权信息可以用作训练期间可用的附加特征,这些附加特征可以帮助训练处更准确地分类器并提高识别性能和泛化能力。目前,特权信息学习已在许多领域得到了广泛的研究。例如,Guo等人 [6] 提出ESVDD-neg (extended support vector data description with negative examples)方法,该方法使用特权信息学习来解决雷达自动目标识别问题。Wu等人 [7] 提出MT-PSVR (multi-target support vector regression)模型,该模型在训练每个目标模型时通过将其他目标视为特权信息来显示探索目标之间的相关性。
两视角学习的提出主要用于解决二维数据的学习问题 [8]。这里的“视角”表示来自多个源或不同特征子集的数据,例如多媒体片段由视频信号和音频信号组成。Li等人 [9] 提出两视角TSVM (Two-view Transductive SVM),用于已标记数据和未标记数据的分类。特权信息具有很多维度和互补性,例如网页包含内容文本和图像,它们相互补充并能够完整地描述对象。
特权信息的概念最初由Vapnik等人提出 [10],现实世界中的数据通常与丰富的描述相关联,并且这些丰富的描述在学习任务中被视为特权信息。例如,网络图像通常包含辅助信息(例如,文本描述,注释等),这些信息被视为特权信息。实际中,特权信息可以是标签、属性、关键字等。随着在线图像共享平台(如Flickr、Instagram等)的发展,这些平台允许用户上传图像,并为图像贴上标签,如图1所示。这些标签(称为“特权信息”)能够描述图像内容,能提高图像检索的性能。这些图像和特权信息构成数据的二维性,因此可以应用于两视角学习。例如,Tang等人 [11] 提出了多视角特权SVM模型。该模型在两视角学习和特权信息的基础上进行扩展。该方法将两种互补的特权信息分成两个不同的视角,并在两个视角之间添加约束来补偿它们之间的差距。

Figure 1. Web images with privileged information
图1. 带有特权信息的Web图像
包和示例的特性适用于带有特权信息的图像分类,因此采用多示例学习来表示数据,采用两视角学习来划分数据并同时训练分类器。所提方法将一张图像视为一个示例,将若干图像的集合视为包,将一个关键词(特权信息)视为一个示例,将若干个关键词的集合视为包。使用特权信息提高图像分类的精确度的前提是包中示例的标签是已知的,但在现实中示例的标签是模糊的,而现有的研究较少提及这方面的处理,因此所提模型引入相似度模型来描述数据。所提模型可用于在线图像共享平台提高Web图像检索性能。
2. 基于相似度的两视角多示例模型
2.1. 相似度数据模型
在多示例学习中,每个正包至少包含一个正示例,负包里都是负实例。但是,正包中的示例标签是模糊的,即有可能是正的,有可能是负的。为此,引入相似度数据模型来描述多示例学习问题。
用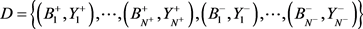 来表示训练包的集合。其中,
来表示训练包的集合。其中,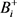 表示一个正包,
表示一个正包, 表示正包
表示正包 的标签,
的标签, ;
;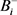 表示一个负包,
表示一个负包, 表示正包
表示正包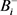 的标签,
的标签,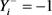 。
。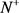 和
和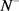 分别表示正包和负包的数量。该模型基于示例的相似度选择正候选,有以下定义:
分别表示正包和负包的数量。该模型基于示例的相似度选择正候选,有以下定义:
定义1:(基于单集的相似度):给出一个示例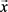 和一个子集S,示例
和一个子集S,示例 和子集S的相似度可以定义如下 [12] :
和子集S的相似度可以定义如下 [12] :
 (1)
(1)
其中,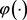 是一个非线性映射函数,将示例
是一个非线性映射函数,将示例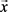 或
或 映射到特征空间中。于是,两类成员计算如下:
映射到特征空间中。于是,两类成员计算如下:
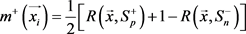 (2)
(2)
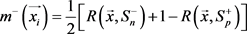 (3)
(3)
让多示例包里的示例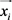 表示为
表示为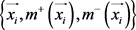 。分别
。分别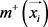 和
和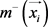 表示示例
表示示例 的趋近于正类和负类的相似度,有
的趋近于正类和负类的相似度,有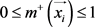 以及
以及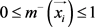 。如果示例
。如果示例 是正示例,则
是正示例,则 且
且 。如果示例
。如果示例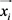 是负示例,则
是负示例,则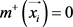 且
且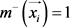 。如果示例
。如果示例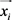 是模糊示例,其标签未知,用
是模糊示例,其标签未知,用 表示,有
表示,有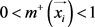 以及
以及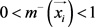 。其中,
。其中, 存储正包中的正候选,
存储正包中的正候选, 存储正包中除
存储正包中除 以外的示例,
以外的示例,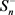 存储负包中的示例。对于
存储负包中的示例。对于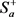 中的示例,有二成员
中的示例,有二成员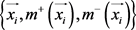 分别趋近于正类和负类。根据以上定义,设
分别趋近于正类和负类。根据以上定义,设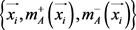 表示趋近于含有特权信息的正类和负类数据,简称为A视角。进一步让
表示趋近于含有特权信息的正类和负类数据,简称为A视角。进一步让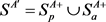 和
和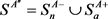 。类似的,设
。类似的,设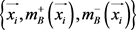 表示趋近于剔除特权信息的正类和负类数据,简称为B视角,有
表示趋近于剔除特权信息的正类和负类数据,简称为B视角,有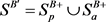 和
和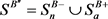 。
。
2.2. 对偶问题
所提方法分别对于A视角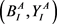 和B视角
和B视角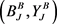 训练支持向量机。假设
训练支持向量机。假设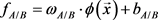 为上述两个视角的超平面。所提方法是基于多示例学习,引导出最小化问题,其目标方程:
为上述两个视角的超平面。所提方法是基于多示例学习,引导出最小化问题,其目标方程:
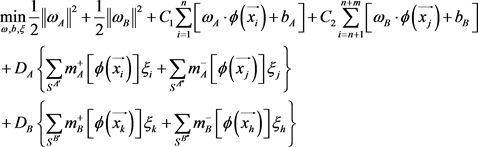 (4)
(4)
约束条件:

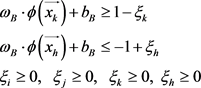
其中,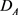 和
和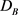 是控制两个视角的正则项。如果
是控制两个视角的正则项。如果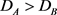 ,则A视角优于B视角,反之,B视角优于A视角。参数
,则A视角优于B视角,反之,B视角优于A视角。参数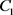 和
和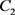 是平衡边距和误差的参数。
是平衡边距和误差的参数。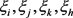 是松弛变量。在A视角中,对于
是松弛变量。在A视角中,对于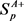 中的每个示例
中的每个示例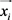 ,
,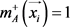 趋近于正类,又因为有
趋近于正类,又因为有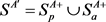 ,所以
,所以 有
有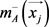 趋近于负类。B视角中的
趋近于负类。B视角中的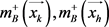 同理可得。约束
同理可得。约束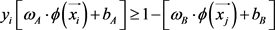 表示两视角间的约束。
表示两视角间的约束。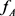 和
和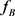 分别表示A视角和B视角的决策函数。
分别表示A视角和B视角的决策函数。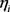 是两视角间的共识变量。
是两视角间的共识变量。 是是允许某些实例违反约束的松弛变量。此外,
是是允许某些实例违反约束的松弛变量。此外,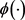 是映射函数,它将数据从输入空间映射到特征空间,可引入核函数来计算特征空间中两个向量的内积,即
是映射函数,它将数据从输入空间映射到特征空间,可引入核函数来计算特征空间中两个向量的内积,即 。
。
为解决公式(4)中的优化问题,用拉格朗日方法,引入拉格朗日乘子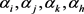 并对
并对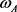 和
和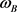 求偏导得:
求偏导得:
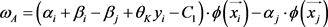 (5)
(5)
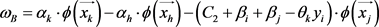 (6)
(6)
根据Kuhn-Tucker Theorem定理得:
 (7)
(7)
将公式(5)和(6)代入(7)得到对偶问题:
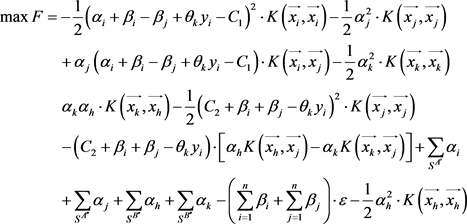 (8)
(8)
约束条件:
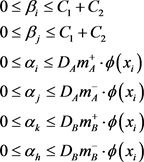
算法实现步骤如表1所示。

Table 1. Algorithm implementation steps
表1. 算法实现步骤
3. 实验与结果分析
3.1. 数据集
实验数据来自NUS-WIDE、Flickr30k、WebQuery和AwA2 (Animals with Attributes 2)这四个数据集:
l NUS-WIDE:该数据集包括来自Flickr的269648张图像的5018个唯一标签和相关标签。
l Flickr30k:该数据集已成为基于句子的图像描述的基准,包含31,783张日常活动、事件和场景的照片以及158,915句文字描述。
l WebQuery:该数据集包含从353个文本查询中检索到的71,478个Web图像。并且数据集中的每个图像都与多种语言的文字描述相关联。
l AwA2:该数据集由50个动物类别的37,322张图像组成,每个图像具有预先提取的特征表示,并带有85个语义属性进行注释。
该实验将一张图像视为一个示例,将一个标签、注释、一句文字描述视为一个示例,都使用聚类算法构造多示例包。
3.2. 实验设计
3.2.1. 两种多示例包的聚类算法
在机器学习领域,有很多聚类算法,如k-means [15],DBSCAN [16] 算法等,这些方法可以用来构造多示例包。实验中使用k-means和DBSCAN算法对于包进行构造。
k-means聚类算法:由于简单和效率高的特性,k-means聚类算法成为聚类算法中使用最广泛的算法。根据前人的经验,该实验设参数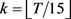 ,其中
,其中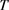 表示训练包的数量。该实验使用的k-means聚类算法是基于欧氏距离:
表示训练包的数量。该实验使用的k-means聚类算法是基于欧氏距离: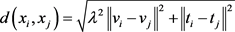 ,其中,
,其中,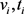 和
和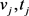 分别是第i张和第j张图像的视觉和文本特征。
分别是第i张和第j张图像的视觉和文本特征。 是两张图像之间的距离。
是两张图像之间的距离。
DBSCAN聚类算法:DBSCAN是基于密度的聚类算法,可以应用于凸样本集和非凸样本集。 DBSCAN将聚类定义为按密度连接的最大点集,将具有足够高密度的区域划分为聚类,并可以在噪声的空间数据库中找到任意形状的聚类。
3.2.2. 比较算法和参数设定
由于所提方法是多示例学习方法,因此将其性能与以下四种多示例学习方法进行比较:
l sMIL-PI:该方法将松散标记的Web数据合并到学习过程中,利用附加的文本特征来有效地处理相关训练图像的噪声标签。该方法基于最大平均差异准则添加了一个正则化器,以减少数据分布不匹配 [7]。
l PSVM-2V:该方法基于两视角学习用于特权信息学习,着重于将特权信息纳入多示例学习和训练SVM作为分类器 [11]。
l SVM+:该方法是一种基于特权信息的学习范式,用特权特征空间中定义的松弛函数替换标准SVM中的松弛变量 [13]。
l SVM-2K:该方法是最早提出的两视角学习方法,它构造两个带有标记和未标记数据的视角以训练分类器 [14]。
实验将所提方法与SVM+,SVM-2K,sMIL-PI和PSVM-2V比较,采用平均精确度(average precision)来衡量各方法的性能。在SVM-2K和PSVM-2V中,设其参数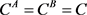 ;在sMIL-PI中,设其参数
;在sMIL-PI中,设其参数 。实验中将以上这些参数以及sMIL-PI、PSVM-2V、SVM+中的权衡参数γ的值均选自范围
。实验中将以上这些参数以及sMIL-PI、PSVM-2V、SVM+中的权衡参数γ的值均选自范围 。经验表明,
。经验表明, 越小,分类的性能通常越好,因此使参数
越小,分类的性能通常越好,因此使参数 。对于所提方法,设参数
。对于所提方法,设参数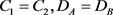 ,并且这些参数选自范围
,并且这些参数选自范围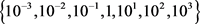 。
。
对于所有基于SVM的方法,实验中使用高斯径向核函数: ,核参数
,核参数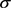 的值选自范围
的值选自范围 。
。
3.3. 实验结果与分析
3.3.1. 性能比较
实验使用NUS-WIDE、Flickr30k、WebQuery和AwA2数据集对SVM+,SVM-2K,sMIL-PI,PSVM-2V和所提方法进行测试与比较。首先将图像和特权信息划分成两个不同的视角,然后在每个视角中分别使用k-means和DBSCAN聚类算法构造多示例包,构造包的数量为300、600、900、1200和1500分别对各方法进行测试,结果如表2~6所示。
从表2~6可以看出,在NUS-WIDE、Flickr30k、WebQuery和AwA2数据集上,从整体上看所提方法略优于比其他多示例方法。随着包的数量从300到900的增加,SVM+、SVM-2K、sMIL-2V、PSVM-2V和所提方法的平均精确度都有所上升。其中PSVM-2V、SVM-2K和所提方法在包的数量为900时达到峰值,随后开始下降,SVM+和sMIL-2V在包的数量为1200时达到峰值,随后也开始下降。随着包的增加,噪声也有所增加,导致分类精确度也随之下降。由此可以得出结论:基于相似度的多示例学习方法分类精度更高。同时由结果可以看出,整体上看使用DBSCAN比k-means算法效果要更优。
Table 2. Average precision when the bag numbers is 300 (unit: %)
表2. 包的数量为300时的平均精确度(单位:%)
Table 3. Average precision when the bag numbers is 600 (unit: %)
表3. 包的数量为600时的平均精确度(单位:%)
Table 4. Average precision when the bag numbers is 900 (unit: %)
表4. 包的数量为900时的平均精确度(单位:%)
Table 5. Average precision when the bag numbers is 1200 (unit: %)
表5. 包的数量为1200时的平均精确度(单位:%)
Table 6. Average precision when the bag numbers is 1500 (unit: %)
表6. 包的数量为1500时的平均精确度(单位:%)
3.3.2. 参数敏感度分析
此外,在所提方法中有一些参数,实验分析了不同参数值下的性能变化。实验使用NUS-WIDE数据集做测试,实验结果如图2和图3所示。首先固定 测试参数
测试参数 。由实验结果可得,如图2所示,在范围
。由实验结果可得,如图2所示,在范围 中,参数
中,参数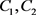 在10−3到1时,性能上升,在1到103时,性能下降,当参数
在10−3到1时,性能上升,在1到103时,性能下降,当参数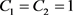 时,效果最优。接着固定
时,效果最优。接着固定 测试
测试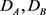 ,如图3所示,参数
,如图3所示,参数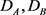 在10−3到10时,性能上升,在10到103时,性能下降,当参数
在10−3到10时,性能上升,在10到103时,性能下降,当参数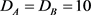 时,效果最优。
时,效果最优。
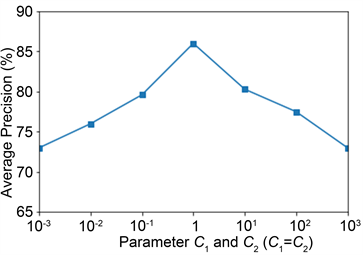
Figure 2. The Parameter Sensitiveness of C1 and C2
图2. 参数C1和C2的敏感度
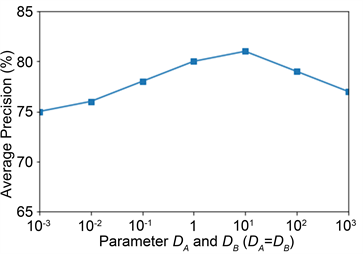
Figure 3. The Parameter Sensitiveness of DA and DB
图3. 参数DA和DB的敏感度
3.3.3. 噪声敏感度测试
实验还测试算法性能对输入数据噪声的敏感程度,使用NUS-WIDE数据集做测试。将噪声添加到数据示例中方法的基本思想如图4所示。首先计算整个数据沿第i个维度的标准差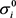 ,然后获得高斯噪声的标准偏差
,然后获得高斯噪声的标准偏差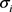 ,其范围随机选自
,其范围随机选自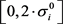 。然后,对于第i维,我们将随机分布的噪声与标准差
。然后,对于第i维,我们将随机分布的噪声与标准差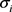 相加。这样,在数据示例
相加。这样,在数据示例 中添加了噪声,可以将其表示为向量:
中添加了噪声,可以将其表示为向量: ,其中
,其中 表示数据示例
表示数据示例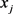 的维数,
的维数,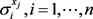 表示添加到数据示例第i维的噪声。
表示添加到数据示例第i维的噪声。
实验中使数据噪声的百分比在0%到30%之间变化。这里以向量加偏移常数方法生成的数据为例,并将噪声添加到每个包的示例中。不同比例的噪声对性能的影响如图5所示,随着噪声水平的提高,所有方法的性能都会下降。但是与其他方法相比,所提方法可以获得更高的精度,对噪声的敏感度较低。

Figure 4. Add the noise to a data example
图4. 将噪声添加到数据示例
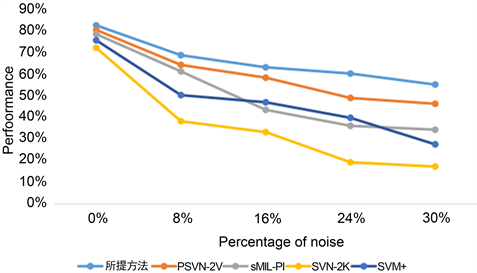
Figure 5. Effect of noise on algorithm performance
图5. 噪声对算法性能的影响
3.3.4. 算法运行时间
各算法的平均运行时间比重如图6所示,所提方法比其他所有方法的时间开销要大得多。这是因为所提方法考虑了示例的相似性,并且同时利用约束条件来拟合原始特征和特权信息。因此,所提方法比其他方法花费更多时间。
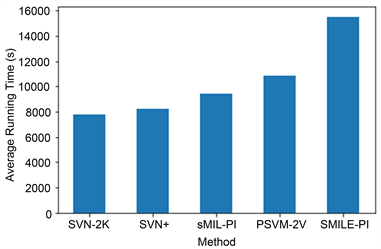
Figure 6. Average running time of different methods
图6. 不同算法的平均运行时间
4. 总结与展望
针对带有特权信息的图像提出一种基于相似度的两视角多示例图像分类方法,该方法考虑了示例的相似性以及具有特权信息特征和原始特征的约束,提出了一个迭代框架来解决使用特权信息进行多示例学习的问题,该方法可用于带有文本描述的图像分类。实验使用两种聚类算法(k-means和DBSCAN)来处理图像并比较其性能。实验结果表明,所提方法的性能明显优于其他方法。但是,所提方法的时间开销比其他方法都大,优化模型以降低时间开销和降低对噪声的敏感程度是未来的工作。
基金项目
本文得到国家自然科学基金资助项目(No.61876044)的资助。
文章引用
尹子健,肖燕珊,刘 波. 基于相似度的两视角多示例图像分类方法研究
Research on Two-View Multi-Instance Image Classification Based on Similarity[J]. 计算机科学与应用, 2020, 10(02): 350-360. https://doi.org/10.12677/CSA.2020.102036
参考文献
- 1. Dietterich, T.G., Lathrop, R.H. and Lozano-Pérez, T. (1997) Solving the Multiple Instance Problem with Axis-Parallel Rectangles. Artificial Intelligence, 89, 31-71. https://doi.org/10.1016/S0004-3702(96)00034-3
- 2. Lu, J. and Ma, S. (2009) Web Image Clustering Based-on Multiple Instance Learning. Computer Research and Development, 46, 1462-1470.
- 3. Rao, T., Xu, M., Liu, H., Wang, J. and Burnett, I. (2016) Multi-Scale Blocks Based Image Emotion Classification Using Multiple Instance Learning. 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, 25-28 September 2016, 634-638. https://doi.org/10.1109/ICIP.2016.7532434
- 4. Duan, L., Li, W., Tsang, I.W. and Xu, D. (2011) Improving Web Image Search by Bag-Based Reranking. IEEE Transactions on Image Processing A Publication of the IEEE Signal Processing Society, 20, 3280-3290.https://doi.org/10.1109/TIP.2011.2159227
- 5. Yao, Y., Shen, F., Zhang, J., Liu, L., Tang, Z. and Shao, L. (2018) Extracting Privileged Information for Enhancing Classifier Learning. IEEE Transactions on Image Processing, 28, 436-450.
- 6. Guo, Y., Xiao, H., Kan, Y. and Fu, Q. (2018) Learning Using Privileged Information for HRRP-Based Radar Target Recognition. IET Signal Processing, 12, 188-197. https://doi.org/10.1109/MSP.2018.2841413
- 7. Wu, G., Tian, Y. and Liu, D. (2018) Privileged Multi-Target Support Vector Regression. 2018 24th International Conference on Pattern Recognition, Beijing, China, August 2018. https://doi.org/10.1109/ICPR.2018.8545479
- 8. Wang, S., Lu, J., Gu, X., et al. (2015) Canonical Principal Angles Correlation Analysis for Two-View Data. Journal of Visual Communication and Image Representation, 35, 209-219. https://doi.org/10.1016/j.jvcir.2015.12.001
- 9. Guangxia, L.I., Hoi, S.C.H. and Chang, K. (2010) Two-View Transductive Support Vector Machines.
- 10. Vapnik, V. and Vashist, A. (2009) A New Learning Paradigm: Learning Using Privileged Information. Neural Networks: The Official Journal of the International Neural Network Society, 22, 544-557. https://doi.org/10.1016/j.neunet.2009.06.042
- 11. Tang, J., Tian, Y., Zhang, P. and Liu, X. (2017) Multiview Privileged Support Vector Machines. IEEE Transactions on Neural Networks and Learning Systems, 29, 3463-3477.
- 12. Xiao, Y.S., Liu, B., Hao, Z.F. and Cao, L.B. (2014) A Similarity-Based Classification Framework for Multiple-Instance Learning. IEEE Transactions on Cybernetics, 44, 500-515. https://doi.org/10.1109/TCYB.2013.2257749
- 13. Li, W., Dai, D.X., Tan, M.K., Dong, X. and Van Gool, L. (2016) Fast Algorithms for Linear and Kernel Svm+. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, 27-30 June 2016, 2258-2266. https://doi.org/10.1109/CVPR.2016.248
- 14. Farquhar, J.D.R., Hardoon, D.R., Meng, H., Shawe-Taylor, J. and Szedmak, S. (2005) Two View Learning: SVM-2K, Theory and Practice. Advances in Neural Information Processing Systems 18, Neural Information Processing Systems, NIPS 2005, Vancouver, British Columbia, Canada, 5-8 December 2005.
- 15. Hartigan, J.A. and Wong, M.A. (2013) A K-Means Clustering Algorithm. Applied Statistics, 28, 100-108.https://doi.org/10.2307/2346830
- 16. Louhichi, S., Gzara, M. and Ben Abdallah, H. (2014) A Density Based Algorithm for Discovering Clusters with Varied Density. 2014 World Congress on Computer Applications and Information Systems, Hammamet, Tunisia, 17-19 January 2014, 1-6. https://doi.org/10.1109/WCCAIS.2014.6916622