Statistics and Application
Vol.
09
No.
02
(
2020
), Article ID:
35081
,
11
pages
10.12677/SA.2020.92030
Factor Analysis and Cluster Analysis of Province Population under Multiple Development Indexes
Yuchen Jia, Jinhui Wen
School of Economics and Management, Beihang University, Beijing

Received: Mar. 29th, 2020; accepted: Apr. 10th, 2020; published: Apr. 17th, 2020

ABSTRACT
With the increasing concern of environmental issues, people begin to think about the “population size and structure change in each region”. This paper uses factor analysis and cluster analysis to classify the population of each province and municipality directly under the Central Government. In this paper, the factor analysis method is used to build a comprehensive scoring model, including data standardization, factor extraction, naming and building a comprehensive model. This paper will select 31 provinces (autonomous regions and municipalities) under the Central Government data for factor analysis, through factor extraction combined with the cumulative contribution rate to determine five factors. Then the factor score formula (the relationship between the extracted factor F and each index X) and the comprehensive model score formula (the relationship between the comprehensive score Y and each index X) are obtained by calculation. Then the data are substituted into the constructed comprehensive scoring model to get the comprehensive scoring of each province and municipality directly under the Central Government and rank the comprehensive scoring. Then, the K-means clustering method is used to cluster the comprehensive scores of each city in one dimension, and the final result is that 31 provinces (autonomous regions and municipalities) under the Central Government are divided into six categories.
Keywords:Factor Analysis, Cluster Analysis

多发展指标下的各省人口因子与聚类分析
贾宇尘,温锦辉
北京航空航天大学经济管理学院,北京

收稿日期:2020年3月29日;录用日期:2020年4月10日;发布日期:2020年4月17日

摘 要
随着环境问题日益受到关注,人们开始对“每个地区的人口规模与结构变化”进行思索,本文利用因子分析和聚类分析的方法对各个省及直辖市的人口进行一个综合排名分类。本文采用了因子分析的方法来构建综合得分模型,具体包括数据标准化处理、因子提取、命名以及构建综合模型。本文选取了31个省(自治区、直辖市)数据进行因子分析,通过因子提取结合得到的累计贡献率确定出5个因子。随后通过计算得出了因子得分公式(提取出来的因子F和各指标X之间的关系)和综合模型得分公式(综合得分Y和各指标X之间的关系)。然后将数据代入构建好的综合得分模型,得出每个省及直辖市的综合得分,进行综合得分排名。再利用K-means聚类的方法对各个城市的综合得分进行一维聚类,得到最终结果将31个省(自治区、直辖市)分为了六类。
关键词 :因子分析,聚类分析

Copyright © 2020 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 研究意义
中国自20世纪70年代以来,先是实施计划生育政策,使得当今的人口结构相比计划生育之初,有了一个翻天覆地的变化,但是政策的实施也意味着多年后的今天,中国再次面临了与之前完全不同的问题——人口老龄化,导致了去年又再次实施单独二胎政策。回看这几十年的变动,中国的人口结构起起伏伏,始终无法保持在一个较为稳定的状态,同时,多年来各省因种种原因,也是体现出了各不相同的人口以及人口带来的其他各种问题。因此,对于各个省份及直辖市面临的不同问题,已有人口规模和未来的变动趋势的研究是至关重要的,因为这些关系到省、市政府对于自己这个地区的经济文化、教育水平、综合素质的未来发展认知和规划。而我国城镇未来经济增长的整体动力和水平在很大程度上又取决于城镇中各个经济要素的健康与完备 [1]。因此,为了确保各个省份处于一个合理健康的人口规模和结构之下稳步发展,需要对其现状进行研究。
2. 人口发展水平因子分析
2.1. 数据标准化处理
本文选取了31个省(自治区、直辖市)包括消费指数、常住人口、道路面积等在内的19个指标 [2],由于各个指标不是同一个量纲和量纲单位,不能直接对不同量纲的指标进行比较。为了对整体指标进行综合评价,需要先对评价指标进行数学变换来消除指标量纲的影响,即进行无量纲化处理。标准化法是目前使用较为广泛的一种无量纲化方法,公式如下所示:
其中,Z为原始变量X标准化后的数值, 为X的期望值, 为X的标准差。
2.2. 提取因子
利用特征值作为保留主成分标准,可得主成分方差贡献率表,见表1。

Table 1. Explained total variance
表1. 解释的总方差
提取方法:主成份分析。
根据上表可知,选取特征根大于1的因子有5个,累计方差贡献率达到81.649%。相应的碎石图见图1。
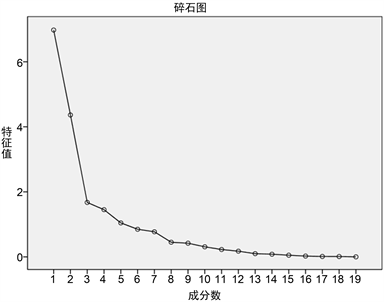
Figure 1. Scree plot
图1. 碎石图
由上图可以直观看出,因子4与因子5的特征值比较相近,因子数大于5之后特征值呈现缓慢降低的趋势,因此选择5个因子是科学可行的。
2.3. 因子命名
5个因子成分矩阵见表2。
Table 2. Composition matrix
表2. 成分矩阵
根据成分矩阵我们可以看到,第1主因子与所有变量均为正相关,且年末常住人口(万人)、全社会固定资产投资(亿元)、地方财政一般预算支出(亿元)、卫生机构床位数(万张)、医院床位数(万张)、社区服务机构数(个)及交通事故发生数总计(起)与第一主成分有较强的正相关性,因此,第1主因子主要代表的是“社会总体基础设施水平”。
第2主因子与每十万人口初中阶段平均在校生数(人)、每十万人口小学平均在校生数(人)及每十万人口高中阶段平均在校生数(人)呈较强的正相关,与每十万人口高等学校平均在校生数(人)呈较强负相关性,说明第2主因子反映的是“初等教育普及指数”。
第3主因子与人均日生活用水量(升)、固定资产投资价格指数(上年 = 100)及文化娱乐类居民消费价格指数(上年 = 100)这三个变量有较强的正相关性,因此第3主因子主要代表的是“人口总体生活水平指数”。
第4主因子主要与居民消费水平指数(上年 = 100)、每万人拥有公共交通车辆(标台)呈正相关,说明第4主因子可以代表“居民总体经济水平”。
第5主因子与人均城市道路面积(平方米)呈较强正相关性,因此第5主因子主要反映的是“人均交通发展水平指数”。
3. 各省份人口发展水平分析
3.1. 人口发展水平指标
因子分析结果中,因子得分系数矩阵如下(见表3):
Table 3. Factor score coefficient matrix
表3. 因子得分系数矩阵
3.2. 各省份各因子得分
各省各因子得分矩阵如下(见表4):
Table 4. Factor score matrix
表4. 因子得分矩阵
经过对样本在每个因子上的得分进行从大到小排序,可得到各个省份在每个因子上的名次,见表5:
Table 5. Ranking of various factors
表5. 各因子得分排序
公共因子F1 (社会总体基础设施水平)排名前五的城市分别是:广东省、山东省、江苏省、四川省和河南省。这几个省份除了省份本身人口规模十分庞大以为以外,政府预算支出也较高,累计基础设施建设也较高,因此人均占有资源指数比较高。北京和上海的名次分别为22和24,说明这两个城市和其他省份相比人口规模不够。
公共因子F2 (初等教育普及指数)排名前五的城市分别是:贵州省、西藏自治区、广西壮族自治区、新疆维吾尔族自治区、河南省。这或许和我们的日常观念相悖,但是由于这前四个省人口基数很小,加上政府多年来的教育投资,也是能够解释的,而河南省是教育大省这一观念还是符合常理的。北京在此排名上为第31名,多少有些让人意外。
公共因子F3 (人口总体生活水平指数)排名前五的城市分别为:西藏自治区、广东省、海南省、上海市、湖南省。说明这几个城市的在一定程度上总体生活水平较高,在娱乐方面的消费相对较多。
公共因子F4 (居民总体经济水平)排名靠前城市的为:贵州、北京、广东、青海省、重庆省。贵州和青海的入围主要是由于居民消费指数增速较快,剩下的省份由于本身经济水平较高,且均为各地区的政治文化中心,高等学府聚集,因此在此项指标上得分较高。
公共因子F5 (人均交通发展水平指数)排名靠前的城市分别为:江苏省、山东省、宁夏省、西藏自治区、安徽省。可以发现有三个省份交通发展水平本身较高,而宁夏和西藏省人口稀少,但国家大力投入交通建设,因此排名也比较靠前。
根据表可以得出:
可以得到5个主因子的表达式如下:
则各省份人口发展水平指标Y的表达式如下:
根据上文得出的公式对数据进行Y值计算,可得结果见表6。
Table 6. Province Y value
表6. 各省份Y值
4. 聚类分析
所谓聚类问题,就是给定一个元素集合D,其中每个元素具有n个可观察属性,使用某种算法将D划分成k个子集,要求每个子集内部的元素之间相异度尽可能低,而不同子集的元素相异度尽可能高。其中每个子集叫做一个簇。
K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
考虑到当k值确定时,聚类效果达到类间距比较大,组内元素聚集紧密时,k值为较优值。于是我们构建了一个比值μ描述聚类效果:
,,
当μ越大时,我们可以判断此次聚类的效果越好。求出所有μ值后,若是有的μ太小,则说明此次分类不合理,分类的结果当中存在较大的类间距和较分散的聚类。最终我们得到的结果见表7:
Table 7. Province clustering results
表7. 各省份聚类结果
根据上述结果,分析我国31个省份自治区直辖市的人口结构和规模预测:
第一类为人口数量一般但是增速较大的地区,主要代表省份为重庆市、甘肃省、青海省和贵州省。这些省份在之前的经济水平方向增长也位于中上水准,因此容易吸引一些人来这些省份定居,预测这些省份接下来的数年人口会有小幅的增速。
第二类为人口数量较大而且增速较快的地区,主要代表省份为广东,我们知道,广东作为中国人口最多的省份,同时又是南部经济中心,拥有很多沿海城市和经济特区,一方面人口基数很大,另一方面也吸引了大量的外来人口,预测广东省接下来的数年人口增速同样会较快。
第三类为人口较大但是增速一般的省份,主要代表省份有河北省、山西省、江西省、河南省、湖南省、四川省和云南省。这些省份大部分的因子得分除了第一项以外都较为一般,可见这些省份大部分本身人口基数比较大,但是由于区位因素,人口增速较慢,对于人才的吸引不如其他省份强,预测这几个省接下来的数年人口增速会比较稳定,可能会有小幅增长。
第四类为人口数量较小但是增速较快的省份,主要代表省份为广西、海南、西藏、宁夏和新疆。这些省份大部分位于我国西部的边境线上,由于历史原因可能人口基数较小,但是由于近年来的发展和国家政策的支持,人口数量发生了大幅度的增长,预测这些省份接下来的数年人口会有大幅的增速。
第五类为人口数量一般而且增速也一般的地区,主要代表省份为江苏省、浙江省、安徽省和山东省。这些省份你大部分位于我国的东部沿海地区,发展较为平均,人口结构较为合理,因此人口数量和增速都在一定的区间范围,预测这些省份接下来人口的增速会较为稳定。
最后一类第六类为人口数量一般同时增速很慢的地区,主要代表省份为北京市、天津市、内蒙古、辽宁省、吉林省、黑龙江省、上海市、福建省、湖北省和陕西省。造成这些省份人口数量一般同时增速很慢的原因主要有两类,其中北京、上海和天津三个直辖市受限于城市的规模,无法使得城市在长期有较为稳定的增速;剩下的省份大部分处于我国的内陆,经济发展相对于其他省份较慢,没有办法吸引更多的人,因此预测这些省份在接下来数年人口的增速会很慢。
5. 结论
本文的主要结论:基于国内各个省份不同维度的指标,本文对各个省份的人口结构和规模预测进行了一定的探讨,从社会总体基础设施水平、初等教育普及指数、人口总体生活水平指数、居民总体经济水平、人均交通发展水平指数等5个方面构建了符合各个省份的人口结构和规模预测的指标体系。对于每个方面都根据科学性、全面性、代表性、可操作性等原则选取指标。接着通过基于因子分析的综合得分模型以及聚类分析对省份进行排名和分类。总得来说,各个省份的人口结构和规模预测由很多方面决定的,因此衡量一个省份的人口规模与结构预测也需要很多数据共同的支撑,各个省份的人口结构和规模预测在某些程度上也代表了这些省份的综合水平,今后各个省份应更注重多方面的综合发展。这也启示不同省份的政府,应该如何发展自身的经济、教育等指标,从而达到更加合理健康的人口规模和结构。
本文数据主要来源于16年国家统计局发布出的数据,但是我们小组根据已知的数据得到的结论,对比获得的部分17年、18年的数据,发现很符合实际情况以及我们根据结论做出的预测,所以,我们相信16年的数据并不是一组特例,而是可以将结论应用到未来几年的相对普适性的例子。
本文的主要创新内容:1) 采用了因子分析的方法来构建综合得分模型,具体包括以下步骤,因子的提取、构建综合得分模型。2) 利用K-means聚类的方法对各个城市的综合得分进行一维聚类,得出最优分类结果。
文章引用
贾宇尘,温锦辉. 多发展指标下的各省人口因子与聚类分析
Factor Analysis and Cluster Analysis of Province Population under Multiple Development Indexes[J]. 统计学与应用, 2020, 09(02): 277-287. https://doi.org/10.12677/SA.2020.92030
参考文献
- 1. 路锦非, 王桂新. 我国未来城镇人口规模及人口结构变动预测[J]. 西北人口, 2010, 31(4): 1-6+11.
- 2. 国家数据[Z]. http://data.stats.gov.cn.