Statistics and Application
Vol.
09
No.
04
(
2020
), Article ID:
37078
,
12
pages
10.12677/SA.2020.94071
Analysis of Recent Grain Prices in Shanghai
Yutian Xue
Department of Statistics, School of Science, Donghua University, Shanghai

Received: Jul. 26th, 2020; accepted: Aug. 11th, 2020; published: Aug. 18th, 2020

ABSTRACT
This paper studies the recent changes of grain prices in Shanghai. By comparing and analyzing the recent 36 months’ grain consumer price index between Shanghai and the whole country, it is found that there is no obvious trend, and both curves are gentle and highly correlated. The real data were used to analyze the grain price of Shanghai in recent 96 weeks (taking the average transaction price of high-quality Rice in the wholesale market as an example) in Shanghai, and applied the white noise test to this time series. After one order differencing and 5-period moving average smoothing of the original series, the ARIMA (2,1,2) model is established and the price of the next 10 periods is predicted. After the optimization of the model, the heteroscedasticity problem in the residual sequence is solved, and finally a complete fitting model is obtained.
Keywords:Grain Price, ARIMA Model, ARCH Model, Hypothesis Test, R Language

上海市近期粮食价格分析
薛雨田
东华大学理学院统计系,上海

收稿日期:2020年7月26日;录用日期:2020年8月11日;发布日期:2020年8月18日

摘 要
本文研究上海市近期粮食价格变化情况。通过近期36个月的上海市和全国粮食消费价格指数进行对比和统计分析,发现曲线没有明显趋势且平缓,两者高度相关。利用真实数据对上海市近期96周的粮食价格(以重点监测的批发市场优质粳米成交均价为例)深入分析,并进行白噪声检验。原序列经过一阶差分和5期的移动平均平滑处理之后,继续模型识别,建立ARIMA(2,1,2)模型,并用ARIMA(2,1,2)预测未来10期的价格。模型优化后解决残差序列中存在的异方差问题,最终得到完整的拟合模型。
关键词 :粮食价格,ARIMA模型,ARCH模型,假设检验,R语言

Copyright © 2020 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
粮食对于国家来说是立足根本,对于个人来说是生存之本。粮食充足至关重要,我国划定了18亿亩的耕地面积的红线,积极培育优质苗种,保持国家粮食的自给自足,使得粮食安全有了基本的资源基础。粮食消费对于几乎所有居民是一种缺乏弹性的刚性需求 [1],因此充足的粮食供给是保持社会稳定的必要条件。
自古以来粮食拥有“兵马未动粮草先行”的军事战略作用,建国之后由依赖进口再到自给自足,逐渐树立“家里有粮心里不慌”的自信,老百姓解决温饱问题是振兴经济发展的基础,是一个国家稳定向前的动力。粮食,不仅是为个体提供能量的基本单位,更是提供再生能源、应用科学技术的基础!即使科技水平发展,大多数人已过上小康生活,人们开始追求更高层次的物质或者精神需求,粮食是否充足依旧时时刻刻牵动着人们的心弦。这次新冠疫情再次为人们敲响警钟,因为2020年1月新冠疫情的突然爆发对各行各业都造成了很大的冲击,出于对未来疫情风险,粮食匮乏与粮价暴涨的担忧,有不少市民在家中囤粮,粮食价格也开始出现大波动,不过最终疫情得到有效控制,粮油等物价得到稳定控制。
由此看来,粮食对维护社会稳定、军事战略、科技经济发展都有很重要的作用。上海是个特大型城市,常驻人口就已经达到2400万之多,还有许多的流动人口,居民对粮食价格更是敏感。所以,本文利用真实数据对上海市的粮食消费价格(以每周重点监测的批发市场优质粳米成交均价为例)进行分析,旨在探究上海市粮食价格情况。
2. 上海市粮食消费价格的相关性指数
本节讨论上海市粮食消费价格指数与全国的相关数据(上年同期=100)的对比。本文数据来源于国家统计局官网2017年7月到2020年6月的上海市粮食类居民消费价格指数(上年同期=100)月度数据、全国粮食类居民消费价格指数(上年同期=100)月度数据,以及上海市粮油市场流通信息监测周报中的2019年11月25日到2020年6月21日之间的上海市每周重点监测的批发市场优质粳米成交均价。按照统计制度要求,我国CPI每五年进行一次基期轮换,2016年1月开始使用2015年作为新一轮的对比基期。CPI基期轮换是一项国际惯例,目的是使CPI调查所涉及到的商品和服务更具有代表性,更及时准确反映居民消费结构的新变化和物价的实际变动。
利用excel表格绘图功能,图1是对近期36个月的上海市和全国粮食消费价格指数进行直观的对比。从总体趋势来分析,上海市和全国粮食消费价格指数没有明显趋势,曲线平缓。粮食价格指数基本在100以上,说明粮食价格三年期间缓慢上升,但上升幅度不大。在2019年初和2020年初,粮食价格指数较低,并且上海市的粮食消费价格指数明显低于全国水平。2018年虽然有自然因素导致的粮食减产,但是有去库存政策的影响,因此其价格也不会大幅度波动。2020年初受疫情影响,国家对粮油等物价和供给进行宏观调控,没有出现粮食价格指数的暴涨。从图上来看,两条时间序列曲线变化趋势基本相似,上海市粮食消费价格指数波动比全国粮食消费价格指数略大。
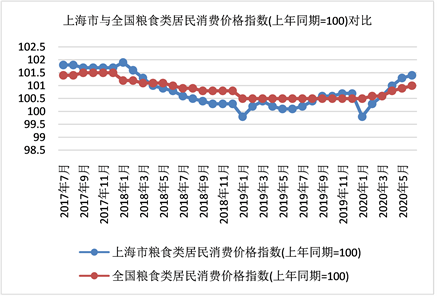
Figure 1. Comparison of consumer price index of grain between Shanghai and China (same period of last year = 100)
图1. 上海市与全国粮食类居民消费价格指数(上年同期=100)对比(注:上年同期=100:以上年同期为基数100,
今年和去年的比例就会是百分数)

Table 1. Descriptive statistics
表1. 描述性统计量
表1中,上海市粮食类居民消费价格指数比全国粮食类居民消费价格指数的均值低0.061,标准误差略高0.2702。符合上海市和全国粮食消费价格指数对比中曲线特征。样本量N都是36。
Table 2. Correlation
表2. 相关性
其中**表示:在0.01水平(双侧)上显著相关。
表2中,上海市与全国的粮食类居民消费价格指数Pearson相关性系数 [2] 是0.882,显著性(双侧)小于0.01,因此有显著的相关性。
因为粮食价格基本由国家控制,再加上上海市大多数土地已作为工业、商业、交通、居住等使用,自身所剩的耕地面积很少,主要依靠外省运输供给粮食,因此上海市的粮食价格与全国的粮食价格有密不可分的关系。经过计算,两组时间序列的欧式距离约是2.14,使用DTW方法求得相似距离约是1.99,两者都是个较小的数值,再次说明上海市的粮食价格与全国的粮食价格高度相关。
通过上面的数据,我们能发现上海市和全国粮食消费价格指数总体没有明显趋势,曲线平缓。上海市粮食类居民消费价格指数比全国粮食类居民消费价格指数的均值略低,标准误差略高,两者相关性显著。
3. 时间序列分析
现在,我们用2018年7月2日~2020年6月21日上海市每周重点监测的批发市场优质粳米成交均价数据,建立时间序列分析的数学模型来分析上海市粮食价格趋势及其特征。其中以2018年7月2日记为第1周,以此类推至2020年6月21日第96周,图2就是按照这96周的数据,得到的上海市每周重点监测的批发市场优质粳米成交均价时序图:

Figure 2. Time series chart of average transaction price of high quality japonica rice in wholesale markets monitored weekly in Shanghai
图2. 上海市每周重点监测的批发市场优质粳米成交均价时序图
从图2中,我们发现2018年7月2日~2020年6月21日之间,上海市每周重点监测的批发市场优质粳米成交均价(以下简称优质粳米均价)在第39周之前在4.5元/公斤左右且数据平稳。第39周时价格迅速升高,且在6元/公斤附近波动,第75周至第90周左右波动程度持续偏大,此时对应的时间正是中国武汉新冠疫情爆发至平息的时间。可见,疫情加剧了上海市优质粳米价格的波动。由于疫情造成的恐慌心理催生了居民囤粮的情况,以优质粳米为代表的粮食价格迅速抬高,最高价格达到6.74元/公斤。曲线中不能看出上海市批发市场优质粳米成交均价有明显的季节性波动。
根据2018年7月2日~2020年6月21日之间这96周的数据,我们获得如下一阶差分后的上海市每周重点监测的批发市场优质粳米成交均价时序图:
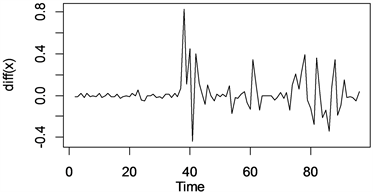
Figure 3. Time series chart of average price of high quality japonica rice after first order difference
图3. 一阶差分后的优质粳米均价时序图
从图3中,我们不难看出2018年7月2日~2020年6月21日之间,上海市每周重点监测的批发市场优质粳米成交均价一阶差分后的时序图,直观感受是一阶差分后数据大致平稳,但是存在异方差。后面我用ADF检验和异方差检验做具体分析。
3.1. 序列白噪声检验
本节中,我们将使用LB检验统计量,对2018年7月2日—2020年6月21日之间上海市重点监测的批发市场优质粳米成交均价一阶差分后数据进行白噪声检验。LB检验是由Box和Ljung建立 [3],弥补了Q检验在小样本场合不够精确的缺陷,LB统计量服从自由度为m的卡方分布。
原假设:延迟期数小于等于m期的序列值之间相互独立
备择假设:延迟期数小于等于m期的序列值之间有相关性
至少存在某个
其中n表示序列观测期数,m表示指定延迟期数。当LB统计量大于1-α置信水平自由度为m的卡方分布的分为点,或者P值小于α时,则以1-α的置信水平拒绝原假设,序列不是白噪声序列。
根据,2018年7月2日~2020年6月21日之间上海市重点监测的批发市场优质粳米成交均价一阶差分后数据,利用统计R程序运行结果如下:
Box-Pierce test
data: diff(x)
X-squared = 4.7806, df = 6, p-value = 0.5722
X-squared = 9.2365, df = 12, p-value = 0.6826
我们的检验结果如下:延迟阶数为6和12的LB统计量的P值显著大于显著性水平0.05,一阶差分后上海市每周重点监测的批发市场优质粳米成交均价数据可以看成白噪声。
3.2. 移动平均
因为短期内粮食市场的不确定性,为削弱短期随机波动对序列的影响,我们采用移动平均法 [3] [4] 处理上海市批发市场优质粳米成交均价数据后,可以认为在短期内均价的差异由随机波动造成,因此,可以用一定时间间隔内的平均值作为下一期的估计值。综合序列无明显周期性,趋势平滑的要求,以及趋势反映近期变化敏感度的要求,这三者因素,我用n = 5期的移动平均对数据做处理,可以获得如下图4,图5期移动平均平滑,一阶差分后的时序图如下图5。
我们对于5期移动平均数据,在一阶差分后的优质粳米成交均价数据,做了的白噪声检验,利用统计R程序运行结果如下:
Box-Pierce test
data: diff(x)
X-squared = 123.67, df = 6, p-value < 2.2e−16
X-squared = 145.59, df = 12, p-value < 2.2e−16
我们的检验结果如下:延迟阶数为6和12的LB统计量的P值远小于显著性水平0.05,5期移动平均数据,在一阶差分后的优质粳米成交均价序列不是白噪声。
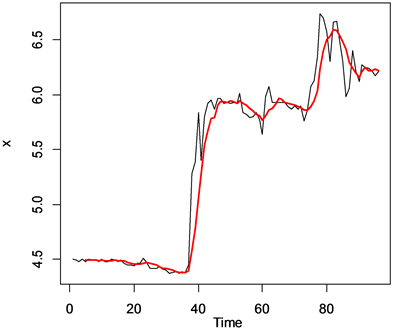
Figure 4. The red line is the sequence diagram after moving average smoothing of five periods, and the black line is the original sequence diagram
图4. 红线是5期移动平均平滑后时序图,黑线是原时序图
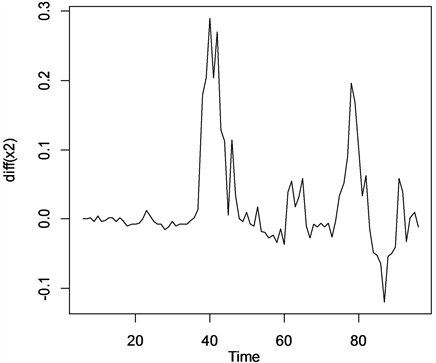
Figure 5. 5 phases moving average smoothing, sequence diagram after first-order difference
图5. 5期移动平均平滑,一阶差分后的时序图
3.3. 平稳性检验
接下来我们通过ADF检验来判断5期移动平均,一阶差分后优质粳米成交均价序列是否平稳。ADF检验就是所谓的单位根检验 [3] [5] [6],指检验AR(p)序列中是否存在单位根,若存在则序列不平稳。假设检验如下:
序列非平稳; 序列平稳。
ADF统计量为 其中 是参数 的样本标准差。
通过蒙特卡洛方法,可以得到统计量临界值表。
统计R程序运行结果如下:
Augmented Dickey-Fuller Test
data: diff(x2)
Dickey-Fuller = −4.4376, Lag order = 4, p-value = 0.01
alternative hypothesis: stationary
我们的检验结果如下:ADF检验P值是0.01,序列平稳。差分运算具有强大的确定性信息提取能力,优质粳米成交均价的序列是差分平稳序列。对差分平稳序列可以使用ARIMA模型进行拟合。
3.4. 模型定阶
图6与图7的直观意义是显示不截尾性。因此选择ARIMA模型拟合序列较合适。
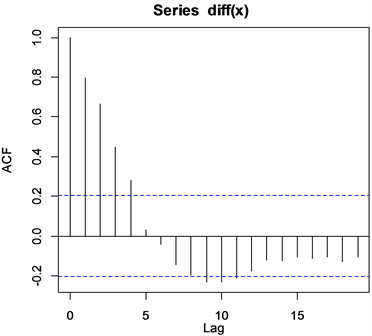
Figure 6. Auto correlation function graph
图6. 自相关函数图

Figure 7. Partial auto correlation function graph
图7. 偏自相关函数图
3.5. 建立模型
平稳时间序列的ARIMA(p,d,q)模型的一般表示方法为:
其中L是延迟算子。
白噪声序列需满足如下条件:
,,, ; ,。
此处的平稳是宽平稳,其特性是序列的统计性质不随时间改变 [7]。我们采用R软件提供的自动定阶系统进行参数估计,auto.arima函数 [3] 基于信息量最小原则识别模型阶数。统计R的运行结果如下:
ARIMA(2,1,2)
Coefficients:
ar1 ar2 ma1 ma2
−0.11570.6569 1.00220.2915
s.e. 0.1199 0.1049 0.20670.1977
sigma^2 estimated as 0.0016:log likelihood = 165.08
AIC = −320.16 AICc = −319.46 BIC = −307.61
我们的结果如下:
模型表达式:
我们的结果如下:AIC值是−320.16,残差平方和是0.0016。
用eviews软件建立模型 [2],使用函数方差最小准则,得到如图8所示结果:

Figure 8. Operation results of Eviews
图8. Eviews运行结果
我们的结果如下:
模型表达式:
AIC值是−3.53,残差平方和是0.139。
3.6. 参数显著性检验
参数显著性检验 [3] 是检验每一个未知参数是否显著非零,为了使得模型更精简。原假设:第j个系数为零。备择假设:第j个系数不为零。构造t检验统计量来检验参数显著性,t服从自由度为n − m的t分布。当检验统计量的绝对值大于自由度为n − m = 88的t分布的1-α分位点时,拒绝原假设,第j个系数显著,否则剔除不显著系数。
其中 是样本矩阵X, 的第j行第j列元素。
从Eviews运行结果t-Statistic一列可知, ,, 对应参数均显著非零。
与信息量最小原则下R软件算出的模型相比,两个模型的系数有少许差异。从AIC值和残差平方和比较来看,R软件得出的模型更加好,所以选择第一个模型。
3.7. 模型显著性检验
得到ARIMA(2,1,2)模型表达式后,进行模型检验。模型显著性检验为了检验模型的有效性,信息是否提取充分。检验方式是通过拟合残差项中不再蕴含任何相关信息,即检验残差序列是否为白噪声序列。残差序列白噪声检验统计R运行结果如下:
Box-Ljung test
data: m1$residual
X-squared = 16.086, df = 6, p-value = 0.0133
X-squared = 20.157, df = 12, p-value = 0.06417
残差检验结果如图9显示,在0.1置信水平下残差序列可视为白噪声序列,在0.05置信水平下残差序列不可视为白噪声序列。说明拟合ARIMA(2,1,2)模型中可能还有未完全提取的有效信息。
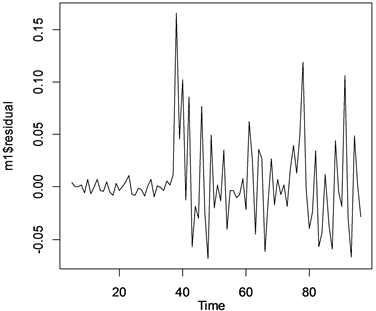
Figure 9. ARIMA(2,1,2) model residual sequence diagram
图9. ARIMA(2,1,2)模型残差序列图
3.8. 预测
用目前得出的模型ARIMA(2,1,2)预测之后10期的价格,统计R运行结果如表3和图10所示。比如,第97期上海市批发市场优质粳米的均价的预测值是6.20元/公斤,置信度为80%的置信区间为(6.14,6.25)元/公斤,置信度为95%的置信区间为(6.12,6.28)元/公斤。
Table 3. Forecast value of average price of high quality rice wholesale market in the next 10 periods
表3. 未来10期批发市场优质粳米的均价的预测值
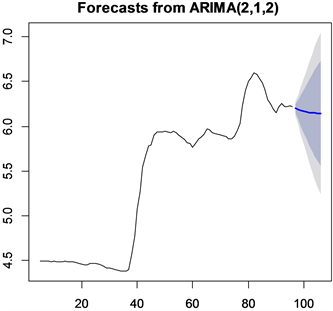
Figure 10. Forecast chart of average price of high quality japonica rice in the next 10 periods
图10. 优质粳米均价未来10期的预测图
图5与图9能直观显示序列和残差序列可能存在异方差,异方差的存在会使得方差齐性的假定不成立。
为了提高模型拟合精度,并且异方差函数形式未知的情况下,我选择用条件异方差模型对残差项序列进一步拟合。
3.9. 模型优化
在拟合新的模型前,首先先进行ARCH检验 [3],ARCH检验是一种特殊的异方差检验,要求异方差性由某种自相关关系所引起,我选择Portmanteau Q检验作为ARCH检验统计方法。Portmanteau Q检验构造思想是如果残差序列方差非齐,且具有集群效应,那么残差平方和序列通常具有自相关性,因此方差非齐检验可以转化为残差平方序列的自相关性检验。
残差条件异方差检验统计软件R运行结果如下:
Box-Ljung test
data: m1$residual^2
X-squared = 0.04742, df = 1, p-value = 0.8276
X-squared = 6.0874, df = 2, p-value = 0.04766
X-squared = 6.0998, df = 3, p-value = 0.1069
X-squared = 7.6767, df = 4, p-value = 0.1042
X-squared = 7.8183, df = 5, p-value = 0.1665
我们的结果如下:延迟阶数为2的P值小于显著性水平0.05,残差序列中存在异方差现象。
接下来,我尝试用ARCH(1),ARCH(2)模型拟合残差序列。从实验结果来看ARCH(1)更好。ARCH能够用自回归方法提取误差平反序列中蕴含的相关信息。ARCH模型实质是利用历史波动信息作为条件,采用自回归形式表达波动变化,得到条件方差信息。

所以用ARCH模型的完整结构是:
其中 是序列 的确定信息拟合模型。
统计软件R运行结果如下:
Model:
GARCH(0,1)
Residuals:
Min 1Q Median 3Q Max
−1.83348−0.32410−0.023180.276744.93080
Coefficient(s):
Estimate Std. Error t value Pr(>|t|)
a0 0.0010574 0.0001005 10.523 <2e−16 ***
a1 0.5494212 0.2650520 2.073 0.0382 *
---
Signif. codes:0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Diagnostic Tests:
Jarque Bera Test
data:Residuals
X-squared = 172.67, df = 2, p-value < 2.2e−16
我们的结果如下:残差最小值−1.83,最大值4.93,参数a0 = 0.0010574,a1 = 0.5494212在置信水平0.01下显著,p-value < 2.2e−16,模型显著,拟合结果良好。考虑异方差的残差序列波置信水平是95%动置信区间如图11所示。
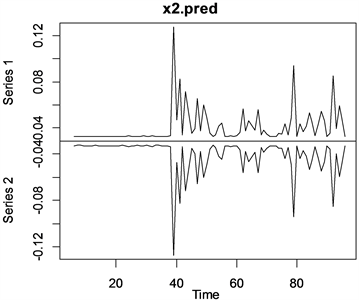
Figure 11. The confidence level of residual sequence wave is 95% dynamic confidence interval
图11. 残差序列波置信水平是95%动置信区间
4. 总结
2018年7月2日~2020年6月21日之间上海市每周重点监测的批发市场优质粳米成交均价时序图中序列有明显趋势,经过一阶差分后序列平稳,但白噪声检验接受原假设。经过5期移动平均处理,序列平稳,且不是白噪声。用ARIMA(2,1,2)模型拟合序列并进行预测,然而,发现模型的残差序列中仍有信息未充分提取,由于序列受异方差影响,所以用ARCH(1)模型拟合残差。分析上海市每周重点监测的批发市场优质粳米成交均价序列时,需要同时提取水平相关信息以及波动相关信息。水平相关信息的提取是通过ARIMA(2,1,2)模型的拟合完成。波动信息的提取先考察ARIMA(2,1,2)的残差平方序列的异方差性,检验异方差的存在,再构造ARCH(1)得出新的置信水平是95%的置信区间。
综上,完整的拟合模型是:
文章引用
薛雨田. 上海市近期粮食价格分析
Analysis of Recent Grain Prices in Shanghai[J]. 统计学与应用, 2020, 09(04): 684-695. https://doi.org/10.12677/SA.2020.94071
参考文献
- 1. 王松梅. 影响粮食消费的主要因素[J]. 当代经济, 2015(22): 40-42.
- 2. 王学民. 应用多元统计分析[M]. 上海: 上海财经大学出版社, 2017: 28.
- 3. 王燕. 时间序列分析——基于R [M]. 北京: 中国人民大学出版社, 2015: 35, 112, 141, 170.
- 4. 杨宏斌. 移动平均期数对农产品供应链成本及牛鞭效应的影响[J]. 统计与决策, 2018, 34(13): 64-66.
- 5. 李子奈, 潘文卿. 计量经济学[M]. 北京: 高登等教育出版社, 2000: 56.
- 6. 张鹤. 时间序列分析方法在粮食价格指数分析中的应用[J]. 统计与决策, 2004(9): 32-34.
- 7. 杨楠. 时间序列分析在我国人口预测中的应用探究[J]. 现代商业, 2018(2): 248-249.