Operations Research and Fuzziology
Vol.
08
No.
04
(
2018
), Article ID:
27636
,
10
pages
10.12677/ORF.2018.84019
TODIM Method Based on Probabilistic Linguistic Term Sets and Its Application in Enterprise Performance Evaluation of Strategic Emerging Industries
Xiaobing Mao, Na Shang, Rui Zhang, Min Wu
Jiangxi University of Finance and Economics, Nanchang Jiangxi

Received: Oct. 31st, 2018; accepted: Nov. 13th, 2018; published: Nov. 20th, 2018

ABSTRACT
The attribute weight determination method based on probabilistic linguistic term sets is proposed in the basis of the multi-criteria decision making with the evaluations in the form of probabilistic linguistic terms set. At the same time, a new function of probabilistic linguistic term set is presented, and the distance formula is also defined. Then, the traditional interactive multi-criteria decision method (TODIM) is extended to the probabilistic linguistic term environment to obtain the comprehensive value of each alternative. Finally a case study concerning enterprise performance evaluation of strategic emerging industries is used to verify the feasibility and effectiveness of this method.
Keywords:Multi-Criteria Decision Making, Probabilistic Linguistic Term Sets, TODIM
基于概率语言术语集的TODIM方法 及其在战略性新兴产业企业 业绩评价中的应用
毛小兵,商娜,张蕊,吴敏
江西财经大学,江西 南昌
收稿日期:2018年10月31日;录用日期:2018年11月13日;发布日期:2018年11月20日

摘 要
针对属性值为概率语言术语集的多属性决策问题,本文提出了基于概率语言术语集熵值的属性权重确定方法。同时,提出了一种新的概率语言术语集的得分函数,并定义了概率语言术语集的距离公式,以及各个方案的综合排序值,将传统的交互式多准则决策(TODIM)方法拓展到概率语言术语环境下,最后通过战略性新兴产业企业业绩评价实例验证了该方法的可行性和有效性。
关键词 :多属性决策,概率语言术语集,TODIM

Copyright © 2018 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
多属性决策是从具有多种属性的有限方案集中选择最优方案的过程,在经济、管理等领域具有广泛的应用。由于多属性决策的不确定性,决策者很难给出精确的评价值。模糊集理论 [1] 为描述复杂的信息提供了一个很好的工具,得到了很多学者的研究和拓展,如直觉模糊集 [2] 、Pythagorean模糊集 [3] 等。考虑到决策制定者在决策制定过程中的不确定性和有限理性,基于语言术语集,Pang等(2016)首次提出了概率语言术语集,并提出了概率语言术语集标准化方法。另外,还定义了概率语言术语集的得分函数和偏差函数,用来比较两个不同的概率语言术语集的大小 [4] 。Gou和Xu (2016)根据两个等价转换公式,重新定义了概率语言术语集之间的运算定律,新的运算法则能够保持运算结果的合理性,并且保证结果不超过所定义的语言术语集的边界 [5] 。Bai等(2017)根据一个算法理论分析了概率语言术语集的结构,并给出一个可能度公式对概率语言术语集进行排序 [6] 。Liao等(2017)应用线性规划模型来解决概率语言术语环境下的多属性决策问题,并基于此线性规划模型,定义了概率语言术语集的不一致度和一致度 [7] 。Cheng等(2017)将交互关系考虑在内,公式化交互方式,来解决概率语言术语信息下的风险投资多属性群体决策问题 [8] 。
TODIM [9] 是在前景理论 [10] 的基础上发展而来的一种多属性决策方法,它能够有效地刻画决策制定者有关风险的心理行为。目前,TODIM方法已被广泛地用于经济管理等多个领域中,也有许多学者对TODIM方法进行了不同角度的拓展。王坚强等(2015)将传统的TODIM拓展到属性值为多值中智数的环境中,来解决相应的多属性决策问题 [11] 。梁霞等(2015)基于传统的TODIM方法,考虑属性之间的关联性,提出C-TODIM决策方法 [12] 。除了考虑属性之间的关联性,梁霞等(2017)还考虑到多指标决策问题中评估值为Pythagorean不确定性语言变量的情况,基于广义Choquet积分,提出一种Pythagorean不确定性语言TODIM方法 [13] 。Ren等(2016)基于前景理论,首次将TODIM方法应用到属性值为Pythagorean模糊集的多属性决策问题中,并进行仿真测试来分析决策者的风险态度是如何影响多属性决策问题的结果,最后通过亚洲基础设施投资银行投资者的选择问题来验证该方法的有效性 [14] 。Qin等(2016)提出一种新的区间二型模糊集(IT2FSs)的距离公式,应用TODIM方法来解决评价信息区间二型模糊集的多属性决策问题,并将其应用到为绿色供应商的评估选择问题中 [15] 。Wang等(2016)根据语言尺度函数,提出多犹豫模糊语言术语集(MHFLTSs)的似然函数,将其嵌入到经典TODIM方法中,形成基于多犹豫模糊语言的似然TODIM方法,用来解决第三方物流服务提供者的选择问题 [16] 。Qin等(2017)针对属性值为三角直觉模糊数(TIFNs)且专家权重和属性权重都未知的多属性群体决策问题,拓展了经典的TODIM方法,将其应用到再生能源的选择问题中 [17] 。
本文将传统的交互式多准则决策(TODIM)方法拓展到概率语言术语环境下,并定义了概率语言术语集的得分函数以及距离公式,提出一种基于概率语言术语集的TODIM方法,并将该方法进一步应用于实例,验证该方法的可行性和有效性。
2. 预备知识
2.1. 语言术语集
为了方便语言信息的计算,Xu (2005)基于犹豫语言方法,定义了下标对称的加性语言术语集 [18] 。对于任意的两个语言术语 ,给定 ,有以下的运算定律:
1) ;
2) ;
3) ;
4) 。
Farhadinia (2016)提出了六种单个语言术语的熵值计算方法 [19] 。
定义1 [19] :假设语言术语集为 ,则语言术语的六种熵的计算公式定义为:
; (1)
; (2)
; (3)
; (4)
; (5)
其中, 。
。(6)
2.2. 概率语言术语集
为了体现专家给出意见时的不确定性和犹豫性,Pang等(2016)提出了概率语言术语集(PLTS),并对概率语言术语集进行了标准化 [4] 。
定义2 [4] :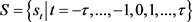 (
是正整数)是一个语言术语集,相应的概率语言术语集可以被定义为:
(
是正整数)是一个语言术语集,相应的概率语言术语集可以被定义为:
, (7)
其中, 是语言变量 与其概率信息 的组合, 是 中语言术语的个数。
定义3 [4] :给定概率语言术语集 , 是语言术语 的下标,则 的得分函数定义如下:
, (8)
其中, 。
根据 对两个概率语言术语 , 进行大小比较,如果 ,则称 优于 ,记作 ;如果 ,则称 劣于 ,记作 。
例1:假设 ,两个概率语言术语集分别为 和 ,计算其得分函数如下:
,
,
则 。
3. 新的概率语言基本理论
本节主要提出了关于概率语言术语集的一些新理论:概率语言术语集的得分函数、距离测度与熵测度。
定义4: 为一个概率语言术语集,则其得分函数的计算公式定义如下:
。 (9)
根据 对两个概率语言术语 , 进行大小比较如下:
1) 若 ,则称 优于 ,记为 ;
2) 若 ,则称 劣于 ,记为 ;
3) 若 ,则称 与 无差异,记为 。
相较于文献 [4] 中的得分函数,利用本文提出的得分函数来比较概率语言术语集的大小更为合理。
例2:根据例1,利用公式(9),计算两个概率语言术语集的得分函数如下:
,
,
可得 。
观察两个概率语言术语集, 体现的评估意见更为集中,且概率之和为1,表明专家比较确定给出的评估值;而 评估意见相较于 更离散,且概率之和为0.9,表明专家对于给出的评估值存在一定的犹豫性。综合以上两点,可以得出 的结论,则用本文提出的得分函数能更准确、更合理地比较概率语言术语集的大小。
定义5:设 和 是两个概率语言术语集,则 和 之间的距离定义如下:
, (10)
其中, 和 根据式(9)计算。
本文基于定义2,提出了概率语言术语集的熵值。
定义6: 是一个概率语言术语集,则其熵值的计算公式如下:
。 (11)
定义7:设概率语言术语集为 ,其补集定义如下:
。 (12)
4. 基于概率语言术语集的TODIM方法
本节首先提出基于熵值属性权重的确定方法,以此建立基于概率语言术语集的TODIM方法。
4.1. 属性权重的确定方法
基于熵值的属性权重确定方法具体步骤如下:
设有 个方案 , 个决策属性 ,对应的权重向量为 且 。方案 在属性 下的评估值为概率语言术语集 ,构成的决策矩阵记为 。
。 (13)
Step 1:计算每一个评估值的熵值,得到熵值矩阵 如下:
, (14)
其中,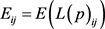 。
。
Step 2:标准化每一个熵值,得到标准化熵值矩阵 如下:
, (15)
其中, 。
Step 3:计算属性 的权重:
, (16)
其中, , 。
4.2. 概率语言术语TODIM
本节详细描述基于概率语言术语集的TODIM方法具体步骤。
Step 1:规范化决策矩阵 。对于效益型属性 ,相应的评估值不需要变动;对于成本性属性 ,取对应评估值的补集。即:
。 (17)
其中, 由公式(12)计算得出。规范化后的决策矩阵记为 。
Step 2:选择权重最大的属性作为参考属性,记为 ,并计算各属性的相对权重如下:
。 (18)
Step 3:计算方案 优于 的程度 ,得到方案之间的优势度,即:
, (19)
其中,
。 (20)
为损失的衰减因子,可根据决策者的偏好进行相应的调整。为简化计算,本文取 。其中距离公式 根据式(10)计算。
Step 4:计算方案 的综合值
。 (21)
Step 5:根据方案的综合值进行方案排序。综合值越大,代表该方案越好;综合值越小,代表该方案越差。
4.3. 决策步骤
根据上述分析过程,基于概率语言信息的TODIM方法决策步骤如下:
Step 1:由专家给出每个属性下的方案值,构建决策矩阵,并根据式(14)和(15)得到标准化熵值矩阵 ;
Step 2:根据式(16)计算得到属性权重 ;
Step 3:根据式(17)标准化矩阵;
Step 4:根据式(18)计算属性的相对权重 ;
Step 5:根据式(19)和(20)计算方案间的优势度 ,并构成优势度矩阵;
Step 6:根据式(21)计算方案的综合值 ,并根据综合值得到方案的排序。
5. 实例分析
业绩评价对企业的可持续发展具有至关重要的作用,能够帮助企业及时发现自身存在的优势和劣势。在国家的号召下,目前战略性新兴企业得以快速的兴起与发展。本文选取江西省的四家战略性新兴企业,即泰豪科技股份有限公司(
)、江西华伍制动器股份有限公司(
)、江西特种电机股份有限公司(
)以及江西联创光电科技股份有限公司(
),从创新能力(
)、政府支持力度(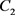 )、社会贡献能力(
)和市场应变能力(
)四个方面对其进行业绩评价,以帮助投资人、债权人等主要利益相关者做出更好的决策。基于评价语言术语集
,专家给出语言决策矩阵如表1所示。
)、社会贡献能力(
)和市场应变能力(
)四个方面对其进行业绩评价,以帮助投资人、债权人等主要利益相关者做出更好的决策。基于评价语言术语集
,专家给出语言决策矩阵如表1所示。

Table 1. Decision making matrix of PLTSs
表1. 概率语言术语集决策矩阵
上述问题的决策步骤如下:
Step 1:根据式(14)和(15)计算每一个评估值的熵值,并得到标准化熵值矩阵熵值如下:
;
。
Step 2:根据式(16)计算属性 的权重,得:
。
Step 3:规范化决策矩阵。由于本文选取的三个属性均为效益型属性,因此规范化后的决策矩阵与原决策矩阵相同。
Step 4:根据式(18)计算各属性的相对权重。选取 作为参考属性,则各属性的相对权重分别为:
。
Step 5:根据式(19)和(20)计算方案间的优势度 ,并构成优势度矩阵。
在属性 下,方案之间的优势度计算结果如表2所示。
Table 2. Dominance of alternatives under criterion C1
表2. C1下的方案优势度
在属性 下,方案之间的优势度计算结果如表3所示。
Table 3. Dominance of alternatives under criterion C2
表3. C2下的方案优势度
在属性 下,方案之间的优势度计算结果如表4所示。
Table 4. Dominance of alternatives under criterion C3
表4. C3下的方案优势度
在属性 下,方案之间的优势度计算结果如表5所示。
Table 5. Dominance of alternatives under criterion C4
表5. C4下的方案优势度
综上,得到方案之间的优势度如表6所示。
Step 6:根据式(21)计算方案的综合值 如表7所示。
根据方案的综合值进行方案排序,得到 。即江西华伍制动器股份有限公司的综合业绩最优,江西联创光电科技股份有限公司的综合业绩最差。在财务决策中,利益相关者可以参考业绩评价排序结果,做出更优决策。
Table 6. Dominance of alternatives
表6. 方案优势度
Table 7. Overall prospect value of alternative Ai
表7. 方案Ai的综合值
6. 结论
战略性新兴产业的企业业绩评价是一个典型的多属性决策问题,在评价过程中存在着很多定性指标,如上述非财务业绩,更适合用语言形式来进行评价。本文定义了概率语言术语集的得分函数、距离公式以及熵值,以熵值为基础提出了属性权重的确定方法,在此基础上,对传统TODIM方法进行拓展,提出基于概率语言术语集的TODIM方法,该方法充分考虑了决策者对风险的偏好,通过计算方案之间的优势度选出最优方案,最后通过业绩评价案例分析验证了本文提出的方法的可行性和有效性。此外,本文提出的方法具有计算简便、步骤清晰等优点。未来的研究中,可以对概率语言术语集的距离公式以及熵值做进一步的改进;另外,属性之间具有关联性也应该考虑在内,以使该方式更具普遍适用性,能解决更多的多属性决策问题。
文章引用
毛小兵,商 娜,张 蕊,吴 敏. 基于概率语言术语集的TODIM方法及其在战略性新兴产业企业业绩评价中的应用
TODIM Method Based on Probabilistic Linguistic Term Sets and Its Application in Enterprise Performance Evaluation of Strategic Emerging Industries[J]. 运筹与模糊学, 2018, 08(04): 151-160. https://doi.org/10.12677/ORF.2018.84019
参考文献
- 1. Zadeh, L.A. (1965) Fuzzy Sets *. Information & Control, 8, 338-353. https://doi.org/10.1016/S0019-9958(65)90241-X
- 2. Atanassov, K.T. and Rangasamy, P. (1986) Intuitionistic Fuzzy Sets. Fuzzy Sets & Systems, 20, 87-96. https://doi.org/10.1016/S0165-0114(86)80034-3
- 3. Yager, R.R. (2013) Pythagorean Fuzzy Subsets. 2013 Joint IFSA World Congress and NAFIPS Annual Meeting, Edmonton, 24-28 June 2013, 57-61. https://doi.org/10.1109/IFSA-NAFIPS.2013.6608375
- 4. Pang, Q., Wang, H. and Xu, Z. (2016) Probabilistic Linguistic Term Sets in Multi-Attribute Group Decision Making. Information Sciences, 369, 128-143. https://doi.org/10.1016/j.ins.2016.06.021
- 5. Gou, X. and Xu, Z. (2016) Novel Basic Operational Laws for Lin-guistic Terms, Hesitant Fuzzy Linguistic Term Sets and Probabilistic Linguistic Term Sets. Elsevier Science Inc., New York.
- 6. Bai, C., Zhang, R., Qian, L., et al. (2017) Comparisons of Probabilistic Linguistic Term Sets for Mul-ti-Criteria Decision Making. Knowledge-Based Systems, 119, 284-291. https://doi.org/10.1016/j.knosys.2016.12.020
- 7. Liao, H., Jiang, L., Xu, Z., et al. (2017) A Linear Programming Method for Multiple Criteria Decision Making with Probabilistic Linguistic Information. Information Sciences, 415-416, 341-355. https://doi.org/10.1016/j.ins.2017.06.035
- 8. Cheng, X., Gu, J. and Xu, Z. (2017) Venture Capital Group Deci-sion-Making with Interaction under Probabilistic Linguistic Environment. Knowledge-Based Systems, 140, 82-91. https://doi.org/10.1016/j.knosys.2017.10.030
- 9. Gomes, L.F.A.M. and Lima, M.M.P.P. (1991) Todim: Basic and Application to Multicriteria Ranking of Projects with Environmental Impacts. Foundations of Computing and De-cision Sciences, 16, 113-127.
- 10. Kahneman, D. and Tversky, A. (1979) Prospect Theory: An Analysis of Decision under Risk Title. Econometrica, 47, 263-291. https://doi.org/10.2307/1914185
- 11. 王坚强, 李新娥. 基于多值中智集的TODIM方法[J]. 控制与决策, 2015(6): 1139-1142.
- 12. 梁霞, 姜艳萍, 梁海明. 考虑属性关联的C-TODIM决策方法[J]. 运筹与管理, 2015, 24(2): 101-107.
- 13. 梁霞, 刘政敏, 刘培德. 基于广义Choquet积分的Pythagorean不确定语言 TODIM方法及其应用[J]. 控制与决策, 2018(7): 1303-1311.
- 14. Ren, P., Xu, Z. and Gou, X. (2016) Pythagorean Fuzzy TODIM Approach to Multi-Criteria Decision Making. Applied Soft Computing, 42, 246-259. https://doi.org/10.1016/j.asoc.2015.12.020
- 15. Qin, J., Liu, X. and Pedrycz, W. (2016) An Extended TODIM Multi-Criteria Group Decision Making Method for Green Supplier Selection in Interval Type-2 Fuzzy Envi-ronment. European Journal of Operational Research, 258, 626-638. https://doi.org/10.1016/j.ejor.2016.09.059
- 16. Wang, J., Wang, J.Q. and Zhang, H.Y. (2016) A Likelihood-Based TODIM Approach Based on Multi-Hesitant Fuzzy Linguistic Information for Evaluation in Logistics Outsourcing. Pergamon Press, Oxford.
- 17. Qin, Q., Liang, F., Li, L., et al. (2017) A TODIM-Based Multi-Criteria Group Decision Making with Triangular Intuitionistic Fuzzy Numbers. Applied Soft Computing, 55, 93-107. https://doi.org/10.1016/j.asoc.2017.01.041
- 18. Xu, Z. (2005) Deviation Measures of Linguistic Preference Rela-tions in Group Decision Making. Omega, 33, 249-254. https://doi.org/10.1016/j.omega.2004.04.008
- 19. Farhadinia, B. (2016) Determination of Entropy Measures for the Ordinal Scale-Based Linguistic Models. Information Sciences, 369, 63-79. https://doi.org/10.1016/j.ins.2016.06.002