Advances in Applied Mathematics
Vol.05 No.01(2016), Article ID:16960,7
pages
10.12677/AAM.2016.51002
An Adaptive Method for Choosing Collocation Points of RBF Interpolation
Yu Liu1, Guanglei Liu2, Ziwu Jiang1, Dianxuan Gong3
1School of Sciences, Linyi University, Linyi Shandong
2School of Informatics, Linyi University, Linyi Shandong
3College of Sciences, Hebei Polytechnic University, Tangshan Hebei

Received: Jan. 29th, 2016; accepted: Feb. 19th, 2016; published: Feb. 22nd, 2016
Copyright © 2016 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/



ABSTRACT
Radial basis function (RBF) is one of effective meshfree methods for interpolation on high dimensional scattered data. Since the approximation quality and stability seriously depend on the distribution of the collocation points, it is urgent to find algorithm of choosing optimal point sets for the reconstruction process. In this paper, we give a short overview of existing algorithms including thinning algorithm, greedy algorithm, and so on. A new adaptive data-dependent method is provided at the end with a numerical example to show its efficiency.
Keywords:Adaptive Method, Collocation Points, Radial Basis Function, Greedy Algorithm

径向基函数插值配置点的自适应选取算法
刘雨1,刘广磊2,姜自武1,龚佃选3
1临沂大学理学院,山东 临沂
2临沂大学信息学院,山东 临沂
3河北联合大学理学院,河北 唐山

收稿日期:2016年1月29日;录用日期:2016年2月19日;发布日期:2016年2月22日

摘 要
径向基函数是一种处理高维散乱数据插值的有效方法。由于逼近精度和稳定性都严重依赖于配置点的分布,因此在重建过程中如何设计配置点的优化选取算法成为一个迫切需要解决的问题。在本文中,我们将简要介绍已有的选取算法,例如:细化算法、贪婪算法等。文章的最后,我们给出一种新的自适应选取算法,并通过数值算例验证该方法的高效性。
关键词 :自适应算法,配置点,径向基函数,贪婪算法

1. 引言
依据大量的散乱数据通过插值方法重建一个光滑曲线或曲面,在反向工程、计算机图形学、计算机视觉等很多领域中有着重要的应用[1] 。由于原始数据的无规则性,在选取插值方法的时候,尽量使得逼近函数的产生不依赖于数据位置,即选择所谓的无网格方法。径向基函数插值方法作为一种常用的无网格方法,其实质是用一元函数来描述多元函数。由于在通常的方法中所有的原始数据均选取为径向基函数配置中心,这样导致了所求插值函数的不稳定性 [2] [3] 。因此众多的学者关注于如何从大量的原始数据中选择较少的配置点以使得所求的插值函数近似精度高并且稳定性好 [4] [5] 。在本文中,我们将给出一种新的一元自适应配置点优化选取方法。本文内容安排如下:在第二部分我们简要介绍径向基函数相关概念性质。第三部分概述诸如:细化算法、贪婪算法等已有的几类选取算法。在第四部分,介绍我们所设计出一种新选取算法,最后通过数值算例演示新算法的有效性。
2. 径向基函数
考虑一个定义在Ω上的未知函数f(x),其定义在离散样本集合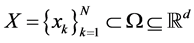 上的函数值集合为
上的函数值集合为 。给定一个一元函数
。给定一个一元函数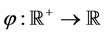 ,令
,令 ,其中
,其中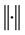 为欧几里得范数,则函数
为欧几里得范数,则函数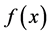 可以近似表示成如下线性组合形式
可以近似表示成如下线性组合形式
 (1)
(1)
其中: ,
,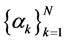 为待定系数,其值由如下的插值条件决定
为待定系数,其值由如下的插值条件决定

称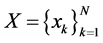 为径向基函数插值配置点集,由径向基函数
为径向基函数插值配置点集,由径向基函数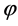 与配置点集
与配置点集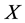 决定的矩阵记为
决定的矩阵记为
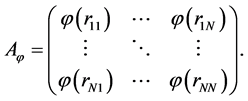
如果 非奇异,则线性方程组
非奇异,则线性方程组
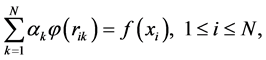
的解存在并唯一,其中 。
。
下面为常用的径向基函数:
多二次函数(MQ):
逆多二次函数(IMQ):
薄板样条函数(TPS):
高斯函数(Gauss):
大多数径向基函数不能保证插值矩阵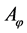 的非奇异性,此时应对插值函数进行处理,即为了保证插值问题解的存在唯一性,在式(1)中等号的后边添加多项式项
的非奇异性,此时应对插值函数进行处理,即为了保证插值问题解的存在唯一性,在式(1)中等号的后边添加多项式项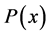 :
:
 ,
,
且满足条件
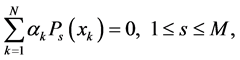 (2)
(2)
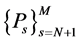 是
是 的一组基,
的一组基,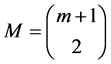 为
为 的维数。令
的维数。令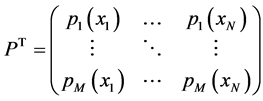 ,结合式(2),则插值条件可以写成如下形式:
,结合式(2),则插值条件可以写成如下形式:
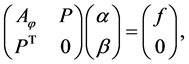
其中 ,
, ,
,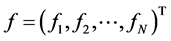 。
。
任给 上的一个径向基函数
上的一个径向基函数 ,对于任意选取的配置点集X,若矩阵
,对于任意选取的配置点集X,若矩阵 均为正定矩阵,此时我们可以定义一个由
均为正定矩阵,此时我们可以定义一个由 诱导的内积:
诱导的内积:

利用此内积可以定义如下的线性空间:
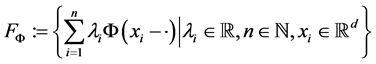
即 是有所有有限个
是有所有有限个 的线性组合构成的空间。取
的线性组合构成的空间。取 的闭包为
的闭包为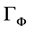 ,则
,则 是一个Hilbert空间,其上的内积仍然是
是一个Hilbert空间,其上的内积仍然是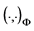 。并且任取空间
。并且任取空间 中的一个元素
中的一个元素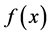 ,都有
,都有
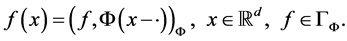
称 是
是 的本性空间 [6] 。为了给出径向基插值的误差估计,定义配置点分布的填充距离如下:
的本性空间 [6] 。为了给出径向基插值的误差估计,定义配置点分布的填充距离如下:

则对于任意的本性空间中的函数 ,有如下的误差估计
,有如下的误差估计
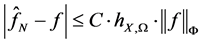 , (3)
, (3)
其中C为常数,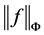 为函数在本性空间中的范数。一方面,从误差估计式中可以看出要使得近似精度高,应该尽可能多选取配置点。但另一方面,过多的选点将导致矩阵
为函数在本性空间中的范数。一方面,从误差估计式中可以看出要使得近似精度高,应该尽可能多选取配置点。但另一方面,过多的选点将导致矩阵 的条件数过大,从而导致求解插值函
的条件数过大,从而导致求解插值函
数的不稳定性 [7] 。若定义配置点分布的分散距离为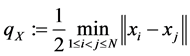 ,则配置点的选取应使得
,则配置点的选取应使得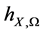 尽量小,并且
尽量小,并且 尽量大。
尽量大。
3. 配置中心的选取方法
通过前面的介绍可知,利用径向基函数插值方法对散乱数据进行处理,如果数据点非常多,为了降低插值矩阵条件数,节省运算成本,我们希望能够用尽量少的配置点并获得尽量高的近似精度。这个问题可描述为:给定了大量的原始散乱数据,要从中选取n个配置点进行插值,如何选择才能使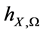 尽量小,并且
尽量小,并且 尽量大。M. S. Floater [8] ,A. Iske [9] 和S. D. Marchi [10] 及其合作者在此方面做了较多工作。到目前为止,这方面的研究成果主要可以分为两类:依赖数据的和不依赖数据的。
尽量大。M. S. Floater [8] ,A. Iske [9] 和S. D. Marchi [10] 及其合作者在此方面做了较多工作。到目前为止,这方面的研究成果主要可以分为两类:依赖数据的和不依赖数据的。
给定插值区域 和大量散乱数据,要在从中选取的一个包含n个配置点的集合X上插值并使得效果
和大量散乱数据,要在从中选取的一个包含n个配置点的集合X上插值并使得效果
最优,即应该使得所选结点的分散距离 尽量大的同时填充距离
尽量大的同时填充距离 尽量小。令
尽量小。令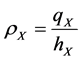 ,Iske指出对
,Iske指出对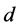
维有界区域做正单纯性剖分得到的顶点集满足 最大,且有
最大,且有
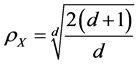 。
。
基于同样的思想,当给定了插值节点集 时,Floater和Iske通过添加点、细化点和交换点等方法构造分层点集序列
时,Floater和Iske通过添加点、细化点和交换点等方法构造分层点集序列 ,这里
,这里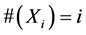 ,满足相应的
,满足相应的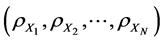 在某种意义下最大 [8] 。Iske将同样的想法也应用到了分片算法中。
在某种意义下最大 [8] 。Iske将同样的想法也应用到了分片算法中。
径向基函数插值可写成Lagrange形式
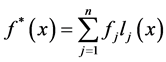 ,
,
其中 ,定义能量函数如下
,定义能量函数如下
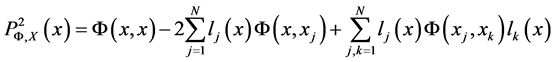
则 的大小直接反应了插值的误差,并且当
的大小直接反应了插值的误差,并且当 时,有
时,有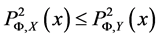 。
。
借助于能量函数,Marchi给出了下面的贪婪算法 [10] :
1) 初始步骤:有界区域 ,在
,在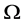 的边界上取一点
的边界上取一点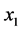 ,令
,令 ;
;
2) 迭代步骤:对于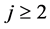 ,在
,在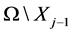 上选取点
上选取点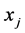 满足
满足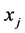 到
到 的距离最远,令
的距离最远,令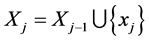 。
。
设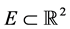 是一个有界区域,令
是一个有界区域,令 ,对
,对 ,定义
,定义 满足:
满足:
 ,
,
称这样的点列 为
为 上的Leja-Bos点列,显然通过贪婪算法选取的点列是一个Leja-Bos点列。
上的Leja-Bos点列,显然通过贪婪算法选取的点列是一个Leja-Bos点列。
另外,在径向基神经网络中常用K-均值聚类算法选取中心,K-均值聚类算法不仅简单而且性能良好,在模式识别中应用十分广泛。这种方法的选点过程与被插值数据无关,也是一种不依赖数据的选点方法 [11] 。
4. 我们的选取方法
从前面的分析可以看到,径向基插值精度与 有关,插值矩阵的条件数与
有关,插值矩阵的条件数与 关系密切,而
关系密切,而 和
和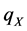 只与配置点的几何分布有关,而与要插值的函数或者数据没有关系。所以依据
只与配置点的几何分布有关,而与要插值的函数或者数据没有关系。所以依据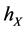 和
和 所得到的取点方法都是不依赖数据的,都是要使所选的点集在插值区域上的分布尽量均匀。这类算法所得到的配置点集都可以说是一种Leja-Bos点列。观察式(3)右端的误差函数,它不仅与分布密度有关,还与被插值函数
所得到的取点方法都是不依赖数据的,都是要使所选的点集在插值区域上的分布尽量均匀。这类算法所得到的配置点集都可以说是一种Leja-Bos点列。观察式(3)右端的误差函数,它不仅与分布密度有关,还与被插值函数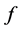 有关。被插值函数
有关。被插值函数 的性质由给定的散乱数据的性质反映,所以在选择插值中心的时候应该同时考虑散乱数据的值及其变化性质。基于此,我们希望找到一个依赖数据的自适应的选点方法,能够根据具体的数据选择最佳配置点。
的性质由给定的散乱数据的性质反映,所以在选择插值中心的时候应该同时考虑散乱数据的值及其变化性质。基于此,我们希望找到一个依赖数据的自适应的选点方法,能够根据具体的数据选择最佳配置点。
为了能够在选择配置点时同时考虑点集分布和具体数据的变化,我们定义广义的Leja-Bos点列:设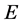 是给定原数据点集,
是给定原数据点集,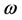 是定义在
是定义在 上的一个正定函数,令
上的一个正定函数,令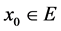 满足
满足
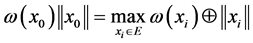 ,
,
其中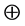 表示某种运算,并且当
表示某种运算,并且当 时,令
时,令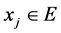 满足:
满足:
 ,
,
其中,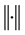 表示欧几里得范数。称
表示欧几里得范数。称 是
是 上的广义权函数,称如此选取的点列
上的广义权函数,称如此选取的点列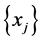 为
为 上的一个广义Leja-Bos点列。
上的一个广义Leja-Bos点列。
权函数 需要根据具体的数据点集来确定,不同的权函数对插值误差的影响比较明显,一般我将函数值的变化剧烈程度与广义权函数联系起来。在本文中,我们取广义权函数为最近3个点之间的二阶差商平方平均值
需要根据具体的数据点集来确定,不同的权函数对插值误差的影响比较明显,一般我将函数值的变化剧烈程度与广义权函数联系起来。在本文中,我们取广义权函数为最近3个点之间的二阶差商平方平均值

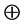 运算取两者的加权平均即
运算取两者的加权平均即 ,然后根据找出广义Leja-Bos点列即为所求的配置点集。
,然后根据找出广义Leja-Bos点列即为所求的配置点集。

Figure 1. The profile of the f(x)
图1. 曲线f(x)的形状
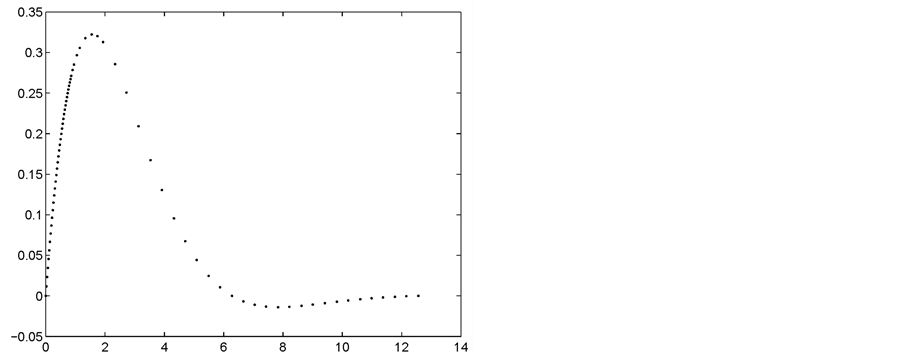
Figure 2. The distribution of chosen collocation points
图2. 配置点的分布情况

Figure 3. Error function corresponding to 527 equidistant nodes
图3. 均匀分布选取527个配置点的误差图形
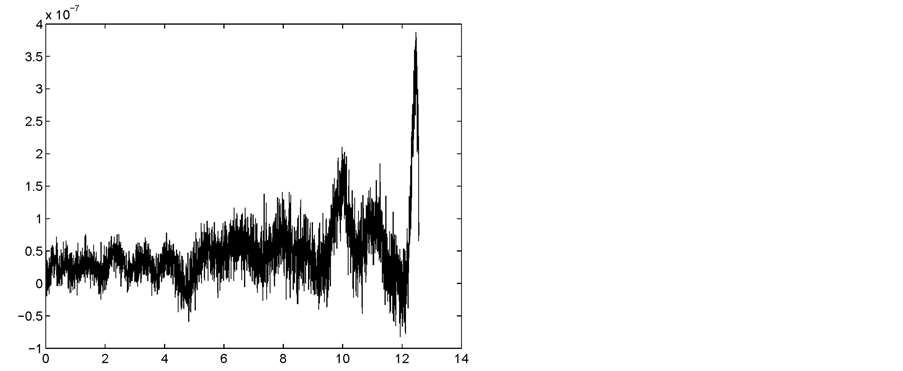
Figure 4. Error function corresponding to generalized-Leja-Bos sequence of 72 points
图4. 选取72个广义Leja-Bos配置点的误差图形
5. 数值算例
本数值算例中,我们选择函数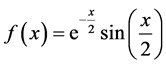 ,给定原始数据为区间
,给定原始数据为区间 的527等分点(包括端
的527等分点(包括端
点)及其函数值。径向基函数选择为MQ函数,其中的形状参数 。
。 点处的广义权值取该点与其最近3个点的平方平均值,权系数
点处的广义权值取该点与其最近3个点的平方平均值,权系数 ,配置点根据算法自适应取到72个。原函数图像如图1所示,从函数图像可以看出曲线兼具变化较为剧烈和平缓的部分。利用本文的方法所选取的配置点如图2所示。插值等分点的误差函数如图3所示,利用本文方法所做插值方法的误差图像如图4所示。从误差图像容易看出,得到同样近似精度,本文所采用的方法选取的配置点更少因而效率更高。
,配置点根据算法自适应取到72个。原函数图像如图1所示,从函数图像可以看出曲线兼具变化较为剧烈和平缓的部分。利用本文的方法所选取的配置点如图2所示。插值等分点的误差函数如图3所示,利用本文方法所做插值方法的误差图像如图4所示。从误差图像容易看出,得到同样近似精度,本文所采用的方法选取的配置点更少因而效率更高。
6. 结论
本文主要探讨了如何利用大量的原始数据,自适应选取较少的径向基函数插值配置点。我们利用配置点分布的分散距离并结合数据点处的二阶插商信息自适应选取了一列广义Leja-Bos点列,将此点列作为径向基函数插值配置点,从数值算例可以看出,利用本文给出的算法所得出的插值函数效率更高。
基金项目
大学生创新创业训练计划项目(编号:201410452002)、国家自然科学基金(项目编号:11301252)。
文章引用
刘雨,刘广磊,姜自武,龚佃选. 径向基函数插值配置点的自适应选取算法
An Adaptive Method for Choosing Collocation Points of RBF Interpolation[J]. 应用数学进展, 2016, 05(01): 8-14. http://dx.doi.org/10.12677/AAM.2016.51002
参考文献 (References)
- 1. 吴宗敏. 散乱数据拟合的模型、方法和理论[M]. 北京: 科学出版社, 2007.
- 2. Fasshauer, G.E. (2007) Meshfree Approximation Methods with Matlab. World Scientific, Singapore. http://dx.doi.org/10.1142/6437
- 3. Franke, R. (1982) Scattered Data Interpolation, Test of Some Methods. Ma-thematics of Computation, 38, 181-200.
- 4. Dyn, N., Floater, M.S. and Iske, A. (2002) Adaptive Thinning for Biva-riate Scattered Data. Journal of Computational and Applied Mathematics, 145, 505-517. http://dx.doi.org/10.1016/S0377-0427(02)00352-7
- 5. Iske, A. (2003) Progressive Scattered Data Filtering. Journal of Computational and Applied Mathematics, 158, 297- 316. http://dx.doi.org/10.1016/S0377-0427(03)00449-7
- 6. Wendland, H. (2005) Scattered Data Approximation (Cambridge Monographs on Applied and Computational Mathematics; 17). Cambridge University Press, Cam-bridge.
- 7. Schaback, R. (1995) Error Estimates and Condition Numbers for Radial Basis Function Interpolation. Advances in Computational Mathematics, 3, 251-264. http://dx.doi.org/10.1007/BF02432002
- 8. Floater, M.S. and Iske, A. (1998) Thinning Algorithms for Scattered Data Interpolation. BIT Numerical Mathematics, 38, 705-720. http://dx.doi.org/10.1007/BF02510410
- 9. Behrens, J. and Iske, A. (2002) Grid-Free Adaptive Semi-Lagrangian Advection Using Radial Basis Functions. Computers and Mathematics with Applications, 43, 319-327. http://dx.doi.org/10.1016/S0898-1221(01)00289-9
- 10. Marchi, S.D. (2003) On Optimal Center Locations for Radial Basisfunction Interpolation: Computational Aspects. Rendiconti del Seminario Matematico Università e Poli-tecnico di Torino (Splines Radial Basis Functions and Applications), 61, 343-358.
- 11. Xu, B.Z., Zhang, B.L. and Wei, G. (1994) Neural Network Theory and Its Application. South China University of Technology Press, Guangzhou.