Software Engineering and Applications
Vol.
09
No.
05
(
2020
), Article ID:
38005
,
7
pages
10.12677/SEA.2020.95039
污染源信息推荐的协同过滤算法应用 模型
王丽娜
海南师范大学经济与管理学院,海南 海口

收稿日期:2020年9月22日;录用日期:2020年10月5日;发布日期:2020年10月12日

摘要
在世界范围内,先进的信息系统被应用到各行各业。在环境保护领域,由于污染给社会生活带来了非常多的困扰,以及污染源的固有特性,作为污染源信息需求者的环境保护机构和个人,从大量污染源信息中找到自己关注的信息往往不是一件容易的事情。推荐系统就是解决这一矛盾的主要工具。通过建立分析用户喜好模型,采用UFTB算法从用户看过的污染源信息及其信息类型入手,对用户看过的污染源信息类型与评分数据进行分析。在建立分析污染源信息推荐模型中,采用协同过滤算法计算修正后的余弦相似度,对缺省值进行预测以优化算法。为防止过度优化,采取剔除用户非喜好类型污染源信息,得到优化缺省值预测矩阵,将相似度数据带入推荐公式,得出数值并使用排序,找出与目标用户相似度最高的N个用户,根据它们的喜好对目标用户进行污染源信息推荐。
关键词
协同过滤推荐算法,相似度,污染源信息
Application Model of Collaborative Filtering Algorithm Recommended for Pollution Source Information
Lina Wang
School of Economics and Management, Hainan Normal University, Haikou Hainan

Received: Sep. 22nd, 2020; accepted: Oct. 5th, 2020; published: Oct. 12th, 2020

ABSTRACT
In the world, advanced information systems are applied to all walks of life. In the field of environmental protection, because pollution has brought a lot of trouble to social life, as well as because of the inherent characteristics of pollution sources, as the source of pollution information needs, environmental protection institutions and individuals are often difficult to find their own concern of the information from a large number of pollution source information. The recommendation system is the main tool to solve this contradiction. By establishing the model of analyzing user preferences, UFTB algorithm is used to analyze the type of pollution source information and scoring data that users have seen. In establishing the recommendation model for analyzing pollution source information, the modified cosine similarity is calculated by using the co-filter algorithm, and the default value is predicted to optimize the algorithm. In order to prevent over-optimization, we should take the information of eliminating the user’s non-preferred type of pollution source, get the optimization default prediction matrix, bring the similarity data into the recommended formula to get the value and use the sort, find the N user with the highest similarity to the target user, and recommend the target user the pollution source information according to their preferences.
Keywords:Co-Filtering Recommendation Algorithm, Similarity, Pollution Source Information

Copyright © 2020 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
近年来,在世界范围内,先进的信息系统被应用到各行各业。在环境保护领域,由于污染给社会生活带来了非常多的困扰,以及污染源的固有特性,作为污染源信息需求者的环境保护机构和个人,如何从污染源信息中找到有用数据是一个经久不衰的课题 [1] [2] [3]。本文利用协同过滤推荐系统的理念和方法,采用UFTB算法从用户看过的污染源信息及其信息类型入手,对用户看过的污染源信息类型与评分数据进行分析。在建立分析污染源信息推荐模型中,为防止过度优化,采取剔除用户非喜好类型污染源信息,得到优化缺省值预测矩阵,将相似度数据带入推荐公式,得出相应的结果。
2. 建模思路
模型的基本假设如下:
用户对污染源信息的评分不受已有评分影响;用户在短时间的兴趣是不会改变的;用户感兴趣的污染源信息类型仅与用户评分高的污染源信息类型相同;年龄相似,职业相仿的人兴趣相同;年龄对观看污染源信息类型的影响度大于职业;年龄差相同的情况下,年龄越大,两个用户的相似度越高。
模型的符号说明如下表1:
要建立分析用户喜好的数学模型,根据协同过滤算法模型,首先分析u_item表与 矩阵,通过计算修正后的余弦相似度,对缺省值进行预测,得到经缺省值预测补全的 矩阵 [2],综合预测污染源信息间相似度。为防止过度优化,再根据用户喜好类型分析结果,将用户非喜好污染源信息类型从经缺省值预测补全的 矩阵中剔除(即相应元素置零),得到优化后的 矩阵。再使用修正后的余弦相似度算法获得用户间相似度矩阵,使用TOP-N算法,获取与目标用户相似度最高的N个用户,利用该N个用户的打分记录,获得目标用户喜好的TOP-N污染源信息编号,即推荐完毕。对此本文从四个步骤进行回答:

Table 1. Model symbol description
表1. 模型符号说明
步骤一:读取u_item表,对任意两行数据向量化,并求两向量夹角余弦值,结果记为 , 值越高,代表两部污染源信息相似度越大;对用户打分矩阵 利用修正后的余弦相似度算法,计算污染源信息间相似度,结果记为 , 越大代表两部污染源信息相似度越大。
步骤二:分析 与 ,将两种相似度加权平均得到预测相似度 ,然后对缺省值进行预测,得到经缺省值预测补全的 矩阵。
步骤三:为防止过度优化,根据用户喜好类型分析结果,将用户非喜好污染源信息类型从经缺省值预测补全的 矩阵中剔除(即相应元素置零),得到优化后的 矩阵。
步骤四:使用修正的余弦相似度算法对 矩阵计算获得用户间的相似度矩阵,使用TOP-N算法,获取与目标用户相似度最高的N个用户,利用该N个用户的打分记录,获得目标用户喜好的TOP-N污染源信息编号。
3. 污染源信息协同过滤算法模型的建立
污染源信息相似度的计算如下:
读取u_item表,将1682行数据任取两行数据并向量化得 与 ,则两向量代表两部污染源信息所属类型,根据协同过滤算法,两个污染源信息类型间的相似度 表达式如下,
读取 矩阵,设对项i和项j两者共同评分过的用户集合用 表示, 和 分别表示对项i和项j评分过的用户集合 [4],则项i与项j之间的相似性 表达式如下,
表示用户c给予项i的评分, 表示用户c给予项j的评分, 表示用户c给予所有项的平均评分值。
综合分析 与 可知, 对 值影响因子a较大,而 对 值影响因子b较小,经分析取 ,。即 。
设目标项TI的最近用户集合用 表示 [5],则用户对项TI的预测评分 可以借助用户u对最近邻居集合 中项的评分得到 [2],公式如下:
表示目标项TI与最近用户n之间的相似性, 表示用户u对项n的评分。 和 分别表示对项TI及项n的平均评分值。
运用预测后的 值补全原 矩阵,得经缺省值预测补全的 矩阵。图1为原 矩阵,图2为经缺省值预测补全的 矩阵。
Figure 1. Original matrix (part)
图1. 原始 矩阵 (部分)
Figure 2. Default value prediction completion matrix (partial)
图2. 缺省值预测补全矩阵(部分)
考虑到这种缺省值预测算法的过优化问题。即如果对每个未评分的污染源信息进行缺省值预测的话,用户评分表的稀疏程度将会是100%。针对这样的评分表,基于用户协同过滤推荐算法得到的最近邻将会和基于原有用户评分表的计算结果有着十分大的差别,甚至是完全相反的。我们可以假设用户原有的污染源信息评分表为用户喜好的真实情况,而这时计算得到的最近邻将会产生较大的反差,即过优化问题。因此,在对污染源信息进行缺省值处理时,我们应对污染源信息的相似度设置较高的阈值。只有高于设定阈值的相似度近邻才可被认可。选用Top N方法时,我们也采用了较小的N值。即只取预测分最高前几名作为推荐。目的是确保Null值处理后保证用户最近邻计算的可信度。经查阅文献可知,阈值取0.24时效果比较好。
图3为优化缺省值预测补全矩阵。使用修正后的余弦相似度算法对 进行计算获得用户间的相似度矩阵,设用户i与用户j共同评分的污染源信息集合用 来表示。 , 分别表示用户i与j评过分的污染源信息的集合。则用户i与用户j的相似度 为
其中 与 分别表示用户i和用户j对所有污染源信息评分的平均值。
Figure 3. Optimize the default value prediction completion matrix (partial)
图3. 优化缺省值预测补全矩阵(部分)
通过以上步骤,我们可以得到所有用户的近邻集合。设用户i的近邻集合为 ,可以得到针对特定污染源信息a,用户i的预测评分为
其中 为用户i对所有污染源信息的平均评分值。
得出用户针对未观看过污染源信息的预测评分后,再使用TOP-N算法,获得目标用户预测评分最好的N个污染源信息编号,即为目标用户喜好的TOP-N污染源信息编号。
此时考虑问题一中UFTB算法 [2],即
其中 是基于UFTB算法对用户u的第i个污染源信息的评测评分。 表示在用户喜好的污染源信息类型中,未评分污染源信息i所获得的评测分值。 中的x为用户对某类污染源信息的评分高低。y表示用户对这类污染源信息的评分个数。 可表示为 ,当x大于 ,且y大于 。其中 表示用户对所有污染源信息类型的平均评分值。 表示用户对所有污染源信息类型的平均评分值个数。即表明如果用户不喜欢某些类型的污染源信息,则该类型的污染源信息所在列 均为零(图4)。

Figure 4. The optimized default value prediction completion matrix after non-user preferences are eliminated (partial)
图4. 非用户喜好剔除后的优化缺省值预测补全矩阵(部分)
本文使用某数据网上的943个用户,1682个污染源信息的数据进行模拟。同时,18类主要污染源信息分别为:(1) 大气污染:I. 烟尘、II. 二氧化硫;(2) 水污染:III. 生活污水和其它耗氧废物、IV. 传染病菌和病毒、V. 植物营养剂——如氮和磷、VI. 有机化学合成剂-如杀虫剂、除锈剂和合成洗涤剂、VII. 来自工、矿、农业操作的其他矿物质和化学物质、VIII. 来自土地侵蚀的沉淀物、IX. 放射性物质、X. 热污染;(3) 土壤污染:XI. 化肥、农药、XII. 有机和无机污染物、XIII. 来自大气、水的污染物质迁移转化进入土壤的污染物质、XIV. 自然界或矿床周围元素富集形成的污染;(4) 其他污染源:XV. 光污染、XVI. 噪声、XVII. 电磁辐射、XVIII. 其他资料来源:http://mip.findlaw.cn/shpc/teshuqinquanjiufen/pcjf/1416533.html。下图5、表2以108号用户为例说明获得推荐的污染源信息的过程。
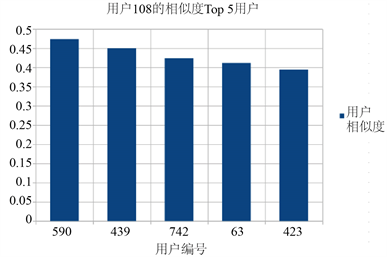
Figure 5. Top 5 users of similarity among users 108
图5. 用户108的相似度Top 5用户
Table 2. Recommended pollution source information number table for specific users
表2. 对特定用户的推荐污染源信息编号表
按照建立用户i对项j的评分矩阵 ,预测补全缺省值,优化缺省值,剔除用户不喜欢的污染源信息类型这一顺序,我们得出了用户的近邻集合,求出近邻集合所有人对所有污染源信息的评分和,再排序取TOP5即为最后结果。
4. 结论
本文建立了基于协同过滤算法的数学模型,借助修正后的余弦相似度公式与UTFB模型,针对传统协同过滤推荐算法中的局限性,本算法解决了针对高稀疏度和低准确度问题。针对相似度度量标准这一问题,我们对用户评分表中的Null值进行了缺省值预测 [2]。对于用户污染源信息喜好程度的修正与增强,在优化用户评分表的稀疏度同时,也增强了推荐系统的针对性。
文章引用
王丽娜. 污染源信息推荐的协同过滤算法应用模型
Application Model of Collaborative Filtering Algorithm Recommended for Pollution Source Information[J]. 软件工程与应用, 2020, 09(05): 345-351. https://doi.org/10.12677/SEA.2020.95039
参考文献
- 1. Hou, C.Q., Zhu, L.C. and Zhang, W.G. (2009) A Collaborative Filtering Algorithm That Compresses Sparse User Scoring Matrix. Xi’an University of Electronic Science and Technology Journal (Natural Science Edition), 36, 1-2.
- 2. Wang, Z.W. (2011) Collaborative Filtering Recommendation Algorithm Based on user Preference Type. Master’s Degree Thesis, East China Normal University, Shanghai, 21-25.
- 3. Collaborative Filter Baidu Encyclopedia. http://baike.baidu.com/
- 4. Wang, J. (2009) Personalized Recommendation System Design and Implementation of Library Sales Site Based on Associated Rules. Master’s Degree Thesis, University of Electronic Science and Technology, Chengdu, 1-5.
- 5. Zhuo, J.W. and Wei, Y.S. (2011) MATLAB Application in Mathematical Modeling. Beijing University of Aeronautics and Astronautics Press, Beijing, 104-108.