Open Journal of Circuits and Systems
Vol.07 No.03(2018), Article ID:26670,9
pages
10.12677/OJCS.2018.73010
A New Single Channel Speech Enhancement Algorithm Based on Improved A-Priori SNR
Chen Chen, Ying Gao, Shun Zhang, Ruirui Han, Shuo Zhang
School of Opto-Electronic Information, Yantai University, Yantai Shandong

Received: Aug. 11th, 2018; accepted: Aug. 24th, 2018; published: Aug. 31st, 2018

ABSTRACT
Aiming at the problem of “music noise residue” existing in most speech enhancement algorithms, a new a-priori SNR estimation algorithm is proposed. Since the accuracy of the a-priori SNR estimation determines the overall performance of the speech enhancement system, the Convex-Combination (CC) algorithm is the most widely used a-priori SNR estimation algorithm. Although its real-time performance and distortion are small, its ability to suppress music noise is lacking. In order to solve this defect, this paper will improve the part of the maximum likelihood estimation in a-priori SNR estimation, and recursively smooth the a-posteriori signal-to-noise ratio by incorporating smoothing parameters, instead of the a-posteriori signal-to-noise ratio in the maximum likelihood estimation. The simulation results show that the proposed algorithm has better music noise suppression ability than CC algorithm.
Keywords:Speech Enhancement, A-Priori Signal-to-Noise Ratio, Fusion Coupling Factor, Maximum Likelihood Estimation
基于改进先验信噪比的新型 单声道语音增强算法
陈晨,高颖,张顺,韩蕊蕊,张硕
烟台大学,光电信息科学技术学院,山东 烟台
收稿日期:2018年8月11日;录用日期:2018年8月24日;发布日期:2018年8月31日

摘 要
针对多数语音增强算法中存在的“音乐噪声残留”问题,提出一种新型先验信噪比估计算法。由于先验信噪比的估计准确度决定语音增强系统的整体性能,而融合耦合因子(CC, Convex-Combination)算法是应用最广的先验信噪比估计算法。虽然其实时性强且失真小,但其抑制音乐噪声能力欠缺。为解决这一缺陷,本文将改进先验信噪比估计中的最大似然估计部分,通过融入平滑参数将后验信噪比递归平滑,代替最大似然估计中的后验信噪比。经仿真实验结果证明,所提出的算法相对于CC算法具有更好的音乐噪声抑制能力。
关键词 :语音增强,先验信噪比,融合耦合因子,最大似然估计

Copyright © 2018 by authors and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
语音交流是人与人,人与机器之间沟通最方便快捷的媒介之一。但是移动通信过程中总是无法避免地出现由非交流者带来的外界噪音,如各种交通工具产生的交通噪声,工厂设备产生的工厂噪声,电子热噪声,环境噪声等等。正是由于这些形形色色的噪声干扰,使得接收端语音识别系统受到损伤,准确性大大降低,严重影响了语音通信系统的质量和可理解性。因此,在语音处理领域抑制噪声干扰的语音增强技术应运而生,不断受到学者的高度重视 [1] 。同时,在研究过程的深入渗透下,语音增强算法应用领域广阔延伸,如:移动电话,助听器设备,军事窃听技术,语音编码与合成技术等 [2] 。
在过去的五十年历史中,为了更好地适应科学领域发展,大量的短时频域语音增强算法已经逐渐衍生出来并得到了广泛应用。其中较为著名的算法有:谱减算法 [3] 、短时谱估计算法 [4] 、子空间算法 [5] 等。由于噪声信号的随机性和非平稳特性,很多算法在真实环境下的运行效果会受到阻碍,因此单声道语音增强算法面临着亟待攻克的问题。众多算法中,经研究发现几乎所有的语音增强算法都与增益因子息息相关,而增益因子又是先验信噪比和后验信噪比的二元函数 [6] ,由于后验信噪比在算法中是已知参数,因而一个准确的先验信噪比估计在增强结果中扮演着关键性的角色。应用性较广的先验信噪比估计算法有直接判决(DD,Decision-Directed)算法 [4] ,两步噪声消除(TSNR,Two-Step Noise Reduction)算法 [7] 、改进的直接判决(MDD,Modified Decision Directed)算法 [8] ,融合耦合因子(CC,Convex-Combination)算法 [9] 等。
DD算法由于计算简洁且容易实现,是迄今最为普及的先验信噪比估计算法。由于该算法中纯净语音谱与噪声谱相互正交的不合理假设,以及采用最大似然估计算法估计当前帧先验信噪比过程中在跟踪后验信噪比时引起一帧的时延,使得该算法音乐噪声较大。针对此缺点,后续有人提出一系列改进算法。其中运行效果较理想的是融合耦合因子算法。该算法在DD算法的基础上引入两个不同平滑参数取值的先验信噪比估计,融入一个耦合参数进行调和,在实际和估计的先验信噪比中建立代价函数求出耦合参数真实值,最终得到新的先验信噪比估计值。该算法有效避免了时延问题,能够实时跟踪信噪比的快速变化,同时失真程度大大降低。但是由于该算法在DD算法估计中采用最大似然法对后验信噪比估计,以此代替当前帧的先验信噪比估计。这使得在无语音活动区产生较大波动,输出的语音信号残留孤立峰值居多,继而产生“音乐噪声”。为了解决上述问题,本文将融合耦合因子算法进行改进,用递归平滑的方式计算后验信噪比,代替传统的瞬时后验信噪比并带入最大似然估计中,有效减少了信号的波动,同时音乐噪声抑制能力有所提升。
本文首先介绍了语音增强算法的基本理论,并对经典的融合耦合因子的先验信噪比估计算法进行了理论分析;其次,提出改进算法并做出理论和公式推导;最后,用Matlab进行实验仿真,分析实验结果验证理论部分,并作出总结。
2. 语音增强算法的基本理论
在语音信号的短时平稳特性下假设原始纯净语音信号与噪声信号是不相关的,则有 [10] :
(1)
其中,
代表带噪语音信号,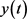 与
分别表示纯净语音信号和噪声。
与
分别表示纯净语音信号和噪声。
对等式两侧分别进行STFT变换,将其转换到频域中:
(2)
其中, , , 分别表示为带噪语音谱、纯净语音谱和噪声谱。m和k表示为帧数和频率。
任何语音增强算法均可以表示为增益因子与带噪语音谱的乘积,即为:
(3)
由于不同算法拥有不同形式的增益因子,而只有维纳滤波算法增益因子不受其他参数影响,仅与先验信噪比有关,为了方便且不失一般性,一般采用维纳滤波算法表示的增益因子 [11] :
(4)
最终结合带噪语音相位对纯净语音谱进行ISTFT变换可以得到估计的纯净语音信号。
先验信噪比估计通常采用DD算法,其定义为:
(6)
其中 表示平滑参数,取值范围在0到1之间。 表示前一帧先验信噪比估计值, 表示最大似然估计下的当前帧先验信噪比,表示为 , 为后验信噪比。
由上式可见,该估计值分为两部分:前部分是上一帧的先验信噪比估计值,后部分是当前帧先验信噪比的估计值,平滑参数在两部分中起到调节作用。当取值趋于1时,估计值由上一帧的估计结果决定,会出现帧延迟现象,并带来较为严重的语音失真。取值趋向0时,估计值则主要由最大似然方法的估值决定,此时在静音区波动剧烈,进一步引发音乐噪声。
由此可见,传统DD算法计算简单,能够很好地滤除背景噪音。但由于采用ML算法在追踪后验信噪比时产生一帧的延时,带来恼人的音乐噪声,导致估计效果准确性降低。为此,有学者提出一种融合耦合因子的先验信噪比估计算法,即将平滑参数取大值和小值的优点结合,融入一个耦合参数来达到实时性跟踪。
平滑因子取值分别为a和b (a > b)的两个DD算法估计的先验信噪比分别为:
(7)
(8)
其中 近似于DD算法对前一帧先验信噪比的估计值, 的取值近似于最大似然方法估计的当前帧先验信噪比估计值。在两个先验信噪比中加入一个取值范围在[0,1]之间的耦合因子,控制该算法的估计值取值情况,则CC算法定义如下:
(9)
为得到自适应耦合参数,在实际先验信噪比与先验信噪比估计值之间的最小均方误差准则下建立一个代价函数:
(10)
通过对代价函数求偏导数并运用最大似然估计方法得到的当前帧的先验信噪比估计代替先验信噪比真实值,得到该耦合参数 [12] :
(11)
将耦合因子带入定义式(9),可得到CC算法的先验信噪比估计,进一步求出增益因子,与带噪语音谱相乘后再进行IDFT变换即可得到增强后的时域语音信号。该算法通过自适应地结合两个具有不同平滑参数取值的DD算法,有效减少了失真,具有实时跟踪性能。但由于最大似然估计算法对当前帧先验信噪比估计,静音区波动较大,易产生音乐噪声。
3. 改进先验信噪比的新型算法
为解决上述缺点,可以在算法中使用平滑处理的后验信噪比来代替ML算法估计的后验信噪比。由于最大似然估计取决于后验信噪比的值,为了减少快速波动,将后验信噪比估计值进行递归平滑,即为:
(12)
其中,β代表经验平滑常数,取值为0.6, 表示前一帧的后验信噪比估计值, 表示瞬时后验信噪比,即为带噪语音功率谱与噪声谱估计的比值求得,最小值函数是为了限制后验信噪比估计值的上限,最大不能超过13 dB (=10lg(20)),同时避免信号的过度衰减 [13] 。过去的实验研究发现,后验信噪比的平滑处理了改进了带噪语音功率谱在均方误差意义下的估计 [13] 。
将平滑处理后的后验信噪比估计值带入ML算法后再代替公式(7)和(8)中的 ,即:
(13)
(14)
其中 为最大似然估计方法得到的当前帧先验信噪比估计值。
4. 仿真结果比较
为了进一步证明改进算法相对于传统算法的优越性,通过Matlab实验仿真得到语谱图和客观评价标准数据进行对比。纯净语音来自于语音库中选取的6段语音(其中3段男声;3段为女声),5种噪声(White, Pink, Buccaneer2, F16, M109)来自于Noisex-92噪声库,输入信噪比分别为0 dB,5 dB,10 dB,15 dB。实验中采用汉明窗进行加窗分帧处理,采样频率8kHz,帧长为256,重叠率50%,λ取0.98,a和b分别为0.99和0.60。
图1中(a)至(e)分别为纯净语音信号,带噪语音信号,DD算法,CC算法以及改进算法下增强的语音信号的语谱图对比,其中背景噪声为M109噪声,信噪比水平为10 dB。
针对以上仿真语谱图不难看出:三个算法都能有效消除背景噪声,但是DD算法在消除背景噪声的
 (a) 纯净语音
(a) 纯净语音
 (b) 带噪语音
(b) 带噪语音
 (c) DD算法增强语音
(c) DD算法增强语音
 (d) CC算法增强语音
(d) CC算法增强语音
 (e) 改进算法增强语音
(e) 改进算法增强语音
Figure 1. The spectrum of speech signal of different algorithms under M109 noise (SNR = 10 dB)
图1. M109噪声下不同算法的语音信号语谱图(SNR = 10 dB)
基础上语音失真更为严重,尤其是在信噪比水平较低的环境下失真更显著。CC算法语音失真情况虽然较之DD算法有所提升,但是最终效果不如改进算法理想。同时,三种算法都对原始语音造成不同程度的损伤,相较来说,改进算法与原始纯净语音语谱图更加接近,即改进算法对纯净语音损伤程度最小。即改进算法的去噪能力更彻底,因此验证了理论部分的分析。
为了客观定量比较分析三种算法的性能,对三种算法增强后语音的质量、失真程度和可懂度等各种标准进行测试,常用的评价标准有分段信噪比(SegSNR) [14] ,短时客观可懂度(STOI) [15] 和对数谱距离(LSD) [16] 等。分段信噪比大小表征算法滤除噪声的能力,数值越大说明算法残余音乐噪声越少。STOI是与人的听力特性最契合的评价标准,数值越大表明增强语音质量越好。LSD表明增强语音和原始纯净语音的接近程度,数值越小说明失真程度越小,即增强效果越好。表1~表3即为三个算法在四种信噪比水平和五种背景噪声下的客观评价数值情况。
通过三个表可得,在不同背景噪声环境和输入信噪比条件下,改进算法的SegSNR和STOI数据最高,CC算法次之,DD算法的数值最低。说明改进算法可以更大限制地抑制背景噪声,提高增强后语音的信噪比水平,增强后的语音可懂度更高。在LSD输出数据上,改进算法比其他两个算法数据值更小,说明改进算法增强后的语音与原始语音更接近,同时和语谱图的结果相吻合。综上所述,改进算法比CC算

Table 1. The SegSNR data comparison table of the four algorithms
表1. 四种算法的SegSNR数据对比表
Table 2. The STOI data comparison table of the four algorithms
表2. 四种算法的STOI数据对比表
Table 3. The LSD data comparison table of the four algorithms
表3. 四种算法的LSD数据对比表
法的增强效果更具有优越性,进一步证实了理论部分。
5. 结论
由于各种杂乱噪声的干扰,涌现出越来越多单声道语音算法,高精度的先验信噪比估计值对语音增强系统的性能好坏起到关键性作用。由于传统的先验信噪比估计算法在跟踪后验信噪比过程中采用极大似然估计方法会出现一帧的延时,并产生音乐噪声。为了切实解决这种弊端,本文通过递归平滑的方式对后验信噪比进行估计,得到新的增强算法。最后实验仿真结果证明了改进算法有更实时的跟踪信噪比变化的性能以及更好的增强效果。
文章引用
陈晨,高颖,张顺,韩蕊蕊,张硕. 基于改进先验信噪比的新型单声道语音增强算法
A New Single Channel Speech Enhancement Algorithm Based on Improved A-Priori SNR[J]. 电路与系统, 2018, 07(03): 75-83. https://doi.org/10.12677/OJCS.2018.73010
参考文献
- 1. 刘伟, 陈晨, 高颖. 一种融合相位信息先验信噪比估计算法的研究[J]. 电声技术, 2017, 41(11/12): 84-87.
- 2. Cho, J.W. and Park, H.M. (2016) Independent Vector Analysis Followed by HMM-Based Feature Enhancement for Robust Speech Recognition. Signal Process, 120, 200-208. https://doi.org/10.1016/j.sigpro.2015.09.002
- 3. Boll, S.F. (1979) Suppression of Acoustic Noise in Speech Using Spectral Subtraction. IEEE Transactions on Acoustics, Speech, and Signal Processing, 27, 113-120. https://doi.org/10.1109/TASSP.1979.1163209
- 4. Ephraim, Y. and Malah, D. (1984) Speech Enhancement Using a Minimum Mean-Square Error Short-Time Spectral Amplitude Estimator. IEEE Transaction on Acoustic Speech Signal Process, 32, 1109-1121. https://doi.org/10.1109/TASSP.1984.1164453
- 5. Ephraim, Y. and Harry, L.V.T. (1995) A Signal Subspace Approach for Speech Enhancement. IEEE Transactions on Speech and Audio Processing, 3, 251-266. https://doi.org/10.1109/89.397090
- 6. 孙海东. 基于新型先验信噪比估计的语音增强算法研究[D]: [硕士学位论文]. 烟台: 烟台大学, 2015.
- 7. Plapous, C. and Marro, C. (2006) Improved Signal-to-Noise Ratio Estimation for Speech Enhancement. IEEE Transactions on Audio, Speech, and Language Processing, 14, 2098-2108. https://doi.org/10.1109/TASL.2006.872621
- 8. Yong, P.C., Nordholm, S. and Dam, H.H. (2013) Optimization and Evaluation of Sigmoid Function with A Priori SNR Estimate for Real-Time Speech Enhancement. Speech Communications, 55, 358-376. https://doi.org/10.1016/j.specom.2012.09.004
- 9. Shen, S., Ou, S., Wei, J., et al. (2017) A Priori SNR Estimator Based on a Convex Combination of Two DD Approaches for Speech Enhancement. 2016 IEEE International Conference on Signal and Image Processing, Beijing, 13-15 August 2016, 750-754.
- 10. Hasan, T. and Hasan, Md.K. (2010) MMSE Estimator for Speech Enhance-ment Considering the Constructive and Destructive Interference of Noise. IEI Signal Processing, 4, 1-4. https://doi.org/10.1049/iet-spr.2008.0114
- 11. 陈国明. 语音增强技术研究[D]: [博士学位论文]. 南京: 东南大学, 2007.
- 12. 沈锁金. 语音增强技术中的先验信噪比估计算法研究[D]: [硕士学位论文]. 烟台: 烟台大学, 2017.
- 13. Lu, Y. and Loizou, P.C. (2008) A Geometric Approach to Spectral Subtraction. Speech Communication, 50, 453. https://doi.org/10.1016/j.specom.2008.01.003
- 14. Sun, H., Ou, S., Liu, R., et al. (2015) A Variable Momentum Factor Algo-rithm for a Priori SNR Estimation in Speech Enhancement. 2014 7th International Congress on Image and Signal Processing, Dalian, 14-16 October 2014, 888-892.
- 15. Taal, C.H., Hendriks, R.C., Heusdens, R., et al. (2011) An Algorithm for Intelligibility Prediction of Time-Frequency Weighted Noisy Speech. IEEE Transactions on Audio Speech & Language Processing, 19, 2125-2136. https://doi.org/10.1109/TASL.2011.2114881
- 16. Pei, C.Y., Nordholm, S. and Hai, H.D. (2013) Optimization and Evaluation of Sigmoid Function with A Priori SNR Estimate for Real-Time Speech Enhancement. Speech Communication, 55, 358-376. https://doi.org/10.1016/j.specom.2012.09.004