Modern Linguistics
Vol.
06
No.
05
(
2018
), Article ID:
28241
,
8
pages
10.12677/ML.2018.65096
A Corpus-Based Study on Improvement of Linguistic Sexism in English
Xiaojie Xu
Zhejiang University of Technology, Hangzhou Zhejiang

Received: Dec. 4th, 2018; accepted: Dec. 20th, 2018; published: Dec. 27th, 2018

ABSTRACT
With the rise of feminist movement in last 60s, more and more linguists and socialists have been attempting to improve, even eliminate linguistic sexism by reforming English language. However, it’s difficult to test the effects of reform because of little empirical study. While as an important tool used widely through Internet, the English corpus especially COCA, featuring in timelessness, big data and objectivity, helps a lot on studying the effects of improving English linguistic sexism.
Keywords:Linguistic Sexism, Sexist Language, Corpus, COCA
基于语料库COCA对英语语言性别歧视改善的实证研究初探
许晓洁
浙江工业大学,浙江 杭州
收稿日期:2018年12月4日;录用日期:2018年12月20日;发布日期:2018年12月27日

摘 要
上世纪60年代女权运动兴起之后,越来越多的语言学家和社会学家对英语语言性别歧视和性别歧视语言展开大量的研究,试图通过对语言形式的改革,改善甚至消除语言性别歧视现象。但是,对于这种改革结果和改善效果的检测一直是一大难题,缺少实证检验。英语语料库,尤其是美国当代英语语料库COCA,作为互联网信息数据时代语言研究的一大利器,它的强时效性、大数据性、语料客观性等特点和优势都为检验英语语言性别歧视改善效果提供了科学的帮助。
关键词 :语言性别歧视,性别歧视语,语料库,COCA

Copyright © 2018 by author and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
语言是人类交流的有效工具,是文化思想的直观载体,它直接反映和体现了人的社会态度和价值观。而性别歧视是一类性别成员对他类性别成员的贬低、歪曲或忽视的行为,是一种社会态度和价值观,它不可避免地体现在社会生活的直观载体――语言上。性别歧视体现的是一种社会不平等现象,尤其在当前父权为主的社会中,主要体现的是男尊女卑的不平等现象,而这种不平等也赋予了语言不平等色彩。语料库是人类在生活中各个领域使用的语言的集合,是依托计算机系统的语言数据库,是通过网络实时更新和修缮的,它能够相对全面直观地反映语言实际使用情况,并且客观地不带任何偏见地展示语言在实际生活中的应用,对于语言工作者和语言研究者都是一个非常实用有效的工具。当前,它作为一种新的研究范式,为语言研究者的实证研究,提供了很好的平台。
2. 语言性别歧视和消除
2.1. 性别歧视和语言性别歧视
根据维基百科的定义,“性别歧视(sexism)一般是指基于他人的性别差异而非他人优缺点所造成的厌恶或歧视,也可用来指称任何因为性别所造成的差别待遇。”而《美国传统词典》对性别歧视的定义更为浅显直白,性别歧视就是“一类性别成员对另一类性别成员,尤其是男性对女性的歧视”。无论如何定义,性别歧视是一种缺乏事实依据的偏见,它是一种偏离的、歪曲的社会态度,虽然它包括对男女两性的歧视,但主要体现在社会对女性的态度上。
语言性别歧视(linguistic sexism)是指在语言使用领域一类性别对他类性别的偏见和歧视态度,而这种偏见和态度往往被施加在女性身上,包括对女性社会地位的不平等定位和无理地忽视女性等等。英语作为性别无标记语言,相较于法语、德语等性别标记语言,性别歧视现象尤为明显。丹麦语言学家Jespersen [1] 在他的Growth and Structure of the English Language (《英语的发展与结构》)一书中就提到“英语是我所熟悉的语言中最具男性化的语言”。社会学家Benokraitis [2] 用英语中的三个单词概括了英语中存在的性别歧视问题,分别为dismissing (缺失)、defining (定位)、deprecating (轻视),利用首字母缩写命名为“3Ds”。具体含义包括英语词汇中相关女性用词的缺失,比如spokesman,layman,chairman等,均以男性后缀-man构词而成,但意义通指男女两性。女性的社会角色和社会地位附属于男性,比如男女称呼的差异,特别是婚后女性的命名权均归于男性。以及英语语言中各类轻视女性的表述,比如两性对应词bachelor和spinster均指到了结婚年龄而未结婚的人,但前者的涵义包括正派、独立和自由,而后者内涵为古怪、冷漠和不近人情,显然代表女性的词汇意义被人为降格了。
性别歧视语(sexist language)是相对于语言性别歧视应运而生的,指的是褒扬一类性别,贬低另一类性别的语言,通常会轻视甚至无视某一性别,标记的是性别歧视 [3] 。根据萨布尔–沃尔夫假说,语言不仅是社会的产物,同时还能影响人类的思维方式和行动方法。虽然语言本身不存在歧视现象,但是社会赋予了语言性别的色彩,性别歧视语的存在严重地影响了日常生活中人们的沟通和交流方式。尤其对于英语作为第二语言的二语学习者,受到大量性别歧视语的影响,在交流过程中存在误用和错用的现象,最典型的例子莫过于人称代词he和she的错用,而人称代词恰恰也是语言性别歧视现象的表现之一。在英语语言中,男性人称代词“he”往往被当成通用代词,当先行词不确定是男或女时,比如先行词为“each”,“everyone”,“anyone”,其后的代词均用“he”或“him、his”指称。虽然严格意义而言“he”是指男性“他”,但很多情况,它都被用来通指男性和女性,比如“Each person has his own duty。”“Anyone who wants to enter into this building must have his pass。”这种情况很大程度地混淆了二语学习者,尤其是二语学习水平相对比较薄弱的学习者正确掌握人称代词使用的能力,故而经常出现无原则、无条件地使用男性代词“he、his、him”替代女性代词“she、her”的错误。
2.2. 英语性别歧视语的消除
语言性别歧视和性别歧视语的普遍存在,引起了社会的广泛关注,尤其是上世纪60年代女权运动的高涨和大众媒体的普及,使人们对于这一现象投入了更多的关注,并且努力寻求改善的方式。1971年学术刊物Ms的出版,大量报导了女权运动和女性研究,其中不乏语言和性别的学术论文。同期,纽约时报和华盛顿邮报开设了讨论语言性别歧视和语言改革的专栏。21世纪初期开始,美国政府要求出版商使用非性别歧视语,而各类学术期刊要求作者使用非性别歧视用词 [3] 。“英国社会学学会也颁布了反性别歧视语言准则来帮助社会学学会的成员避免使用性别歧视语” (Baldwin E, 2005: 68. 转引 [4] )。改善的方法包括创造新词弥补女性词汇的缺失,比如创造spokeswoman对应spokesman;用中性词统称男女双方,比如用spokes person替代spokesman或spokeswoman;使用非性别歧视代词,比如用Ms.替代Miss.和Mrs.,用they/their替代he/his/him和she/her等。
但是语言毕竟是社会发展的产物,有延续性和稳定性,不是想改变就能改变的,事实证明女权主义者、语言研究者或社会学家创造出来的许多新词都没能得到广泛流传和应用。19世纪早期,一位音乐、法学家Charles Crozat Converse试图用“thon”替代“he”或“she”。这一举动直到1889才引起人们的注意,并且被第二版韦伯词典收录,定义为“a proposed genderless pronoun of the third person” (对于第三人称不含性别指向的代词)。然而,当韦伯词典第三版出版的时候,已经找不到“thon”这个词了 [5] 。可见,语言的变更和发展需要伴随历史、社会的变更和发展,尤其是人类世界观和价值观的变化对语言的发展会有深远的影响。笔者认为,即使大部分人已经认可语言性别歧视现象的存在和对有性别歧视的语言进行改善的意愿,在实际使用过程中还是会受到传统价值观和语言使用习惯的影响,相对于改善词汇,更倾向于使用歧视词汇。由此可以推测认知和意愿并不太能轻松改变习惯和现状,也未必能切实有效地根除语言性别歧视现象。故笔者试图利用美国当代英语语料库COCA的数字资源,实证检验语言实际使用过程中,歧视语和改善语的使用频率,以期初步探索语言性别歧视和性别歧视语的改善状况。
3. 基于语料库COCA的实证检验
3.1. 英语语料库COCA
COCA是美国当代英语语料库(Corpus of Contemporary American English)的缩写,它是美国杨伯翰大学(Brigham Young University)的Mark Davies教授开发的在线免费英语语料库。该语料库从2008年2月20日在互联网上推出至今,语料数据超过5.2亿,语料内容覆盖五大类型,分别为口语(spoken)、小说(fiction)、流行杂志(pop magazine)、报纸(newspaper)和学术期刊(academic),往下又具体细分为几十个领域 [6] 。该语料库每年至少更新两次数据,所收集的语料库数据,时间上可以追溯至1990年,到目前,该语料库时间跨度超过28年。相较于目前世界上存在的其他几个语料库,COCA具有语料规模大,时间跨度长,查询速度快,操作界面友好等特点。在此,笔者首先对COCA操作界面做个简单的介绍。COCA界面包括三大功能区,三大功能区分别为:1) 显示及查询条件界定区(处于界面左边区域),包括:显示方式区,字串查询区,语料库分类区,查询结果排列方式区。2) 查询结果数据显示区(处于界面右上部分区域)。3) 例句显示区(处于界面右下部分区域)。
以性别歧视语言为本,实证数据为纲,在语料库COCA提供的语料大数据基础上,通过搜索搭配使用频率变化的新型研究范式,达到初步探索语言性别歧视现象改善状况的目标,是笔者撰写本文的目的。故此,笔者根据以往对于性别歧视语言的研究,分别从三方面来实证检测性别歧视在英语语言中的消除和改善情况。
3.2. 人称代词
人称代词he和she的使用在性别歧视语言中是最具代表性的。对于不定代词(包括all,each,one,none,little,few,every等,以及由some-,any-,no-,every-和-one,-body,-thing所构成的复合不定代词,如somebody,someone,anything,anyone,nobody等)在指称为人的情况下,不论在语法基础上,还是在使用习惯上,都偏向于使用男性人称代词he/him和物主代词his。例如“Everybody has his right to vote”;“If anyone wants a copy, he can have one” [7] 。语言性别歧视改善的一个方面,就是试图在用人称代词指称不定代词的情况中,尽可能的用人称代词复数形式they/them/theirs来替代有性别倾向的单数形式he/him/his。就此,笔者通过COCA,分别查询了1995~2004和2005~2015两个时间段中,they与不定代词的搭配使用情况。在查询界定区的显示方式区选择list方式,字串查询区words框内输入“they”,在collocates框输入“[pn1*]”,上下文的两个框分别为左5和右0,在语料库分类区1选择“1995~1999”和“2000~2004”,在分类区2选择“2005~2009”和“2010~2015”。以上条件的含义是比较they在1995~2004和2005~2015两个时间段中,与上下文左边5单词位置内不定代词的搭配情况,按搭配词原始频数顺序排列截取的前10位的图数据,得到图1。SEC1是they在1995~2004年间与不定代词在上下文左边5个单词位的搭配搜索总词数206,387,893,SEC2是2005~1015年间的总词数223,609,936。选取图中的明确指向人物的不定代词someone/everyone/everybody/anyone/somebody为例,比较2005~2015和1995~2004两个时间段图的相对百分比,除了everybody,其他每个词的相对百分比都有所提升,也就是说,在人称代词指称不定代词的情况中,用人称代词复数形式they的情况明显增多。某种程度上,也意味着在人称代词中性别歧视语在某一方面得到了关注,语言性别歧视现象确实有所改善。
3.3. 称呼语
语言性别歧视改善的第二大代表就是女性称呼语Ms./Mrs./ Miss.的使用。在英语语言文化中,年龄和婚姻状态都被认为是隐私,不便谈论的事情。然而指称男性的称呼语和与其对应指称女性的称呼语显然存在形式和意义不对等现象。首先,表示男性的称呼语只有Mr.一个,对其进行语义分析只能确认得知动物和人类两个信息,而表示女性的称呼语有Mrs.和Miss两个,对它们进行语义分析,两者能确认得知的信息就比表示男性称呼语的Mr.多两个,分别是婚姻状态和年龄大小。显然,从语言性别歧视角度而言,女性这两方面的隐私就暴露无遗,完全得不到应有的尊重和保护。于是,用不带性别歧视的中性词Ms.替代有歧视倾向的Mrs./Miss,没有明确的婚姻和年龄指向,并能向Mr.一样得到广泛使用,是女权主义者,关注性别平等的语言学家和社会学家共同期望的。

Figure 1. Frequency of the use of “they” to refer to the indefinite pronouns (1995~2004 vs. 2005~2015)
图1. “They”指称不定代词频率比较(1995~2004和2005~2015)
基于COCA语料库平台,笔者比较了1995~2004和2005~2015两个时间段Ms.和Mrs.的使用频率。在查询界定区的显示方式区选择compare方式,字串查询区words框内分别输入“Mrs.”和“Ms.”,在collocates框输入“Mr.”,上下文的两个框分别为默认值4和4,在语料库分类区选择时间段,第一次查询选择“1995~1999”和“2000~2004”,第二次查询选择“2005~2009”和“2010~2015”。在查询结果排列方式区选择sort by frequency,同时min frequency接受默认设置10。以上条件的含义是指分别比较在1995~2004和2005~2015两个时间段中Mrs.和Ms.分别与Mr.在上下文左右4个单词位的搭配使用情况。点击查询按钮,两次查询的结果显示在界面右上区域的查询结果数据显示区。具体数据,如图2和图3所示。从图2中可见,在1995~2004年间,当与Mr.搭配使用时,每出现1个Ms.形符就有1.37个Mrs.形符出现,相反,每出现一个Mrs.形符只有0.73个Ms.的形符出现。Mrs.的使用频率明显高于Ms.。在此十年间,Mr.和Mrs.搭配使用的有1169例,而与Ms搭配使用的有467例。图3显示,在2005~2015年间,当与Mr.搭配使用时,每出现1个Ms.形符只有0.81个Mrs.形符出现,相反,每出现一个Mrs.形符就有1.24个Ms.的形符出现。Mrs.的使用频率明显低于Ms.,在此十年间,Mr.和Mrs.搭配使用与前十年相比减少了113例,而与Ms.搭配使用的增加了39例。由此可见,至少在美国,过去的二十年间,大众对于非歧视语Ms.的接纳度呈增长趋势,女性称呼语的性别歧视现象确实得到了较大程度的改善,女性在与男性就称呼的平等性上向前迈进了一大步。

Figure 2. Frequency of collocation between Mr. and Ms./Mrs. (1995~2004)
图2. Ms./Mrs.与Mr.的搭配频率(1995~2004)

Figure 3. Frequency of collocation between Mr. and Ms./Mrs. (1995~2004)
图3. Ms./Mrs.与Mr.的搭配频率(2005~2015)
3.4. 职业称谓语
英语语言中有一个很明显的语言不对称现象,这种不对称现象正是男性特权的最佳表征。以职业称谓为例,其中很多都是以男性为核心的。首先,有太多以-man为后缀的职业表述,如spokesman,businessman,postman,chairman等,显然当提及这些职业时,当不知从业人员的性别时,很容易把其假定为男性。其次,即便没有-man这个后缀,很多职业称谓的职业性别指向依然是男性,比如doctor,lawyer,professor,driver等等,为了避免性别错判的情况发生,通常当从业者为女性的时候,会在该类词汇前面加上lady或woman,比如lady doctor和woman driver。其三,当男女职业称谓成对出现的时候,通常指称男性的职业称谓语是不带标记的,而指称女性的职业称谓语却是有标记的,比如actor/actress, poet/poetess, hero/heroine。针对这一方面,各方媒体、专家和学者也做过很多努力,以这里所提的第一种现象为例。为了消除男性特权表征,中性词person被用来取代man,于是spokesman变成了spokesperson,chairman变身为chairperson。但是语言是文化和习俗的共同产物,是社会集体意识形态的显形,它的改变并非朝夕能够完成。所以同样,通过比较原有词汇和变更词汇的使用频率,能够检测语言性别歧视的改善状况。
同样基于COCA语料库平台,笔者分别比较了1995~2004和2005~2015两个时间段的两组词汇的使用频率变化。以查询spokesman和spokesperson为例,在查询界定区的显示方式区选择compare方式,字串查询区words框内分别输入“spokesman”和“spokesperson”,搭配查询区输入“[n*]”,上下文的两个框分别保留默认值4和4,在语料库分类区选择时间段,第一次查询选择“1995~1999”和“2000~2004”,第二次查询选择“2005~2009”和“2010~2015”。在查询结果排列方式区选择默认sort by relevance,同时min frequency接受默认设置10。点击查询按钮,两次查询的结果显示在界面右上区域的查询结果数据显示区。具体数据如图4和图5所示。
先看图4,1995~2004年间,每出现1个spokesperson的字符就会有6.41个spokesman的字符出现,相反,每出现1个spokesman字符,仅有0.16个spokesperson字符与之对应。按语义趋向排序,笔者发现,最趋向与spokesman搭配的三个名词是男性名字,而最趋向与spokesperson搭配的三个名词是女性名字。从这个角度出发,似乎spokesperson只是取代了另一个性别歧视词spokeswoman而已。于是笔者又以同样的方法检索了spokeswoman和spokesperson两者在同时期的使用频率,根据图6,我们可以看到,这一次两词之间形次比的差距减小了,而且按照语义趋向排序的结果,最趋向与spokesperson搭配的前三个名词出现了男性名字。再看图5和图7中2005~2015年间的数据,spokesman与spokesperson之间的形次比依然差距明显6.01和0.17,与1995~2004年间数据相差不大,但是根据语言趋向可见最趋向与spokesperson搭配的名词不再是女性名字了。同样,在与spokeswoman比较的时候,最趋向与它搭配的名词前三甲中也不见了女性名字,但它们两者的形次比差距却比过去加大了,从1995~2004年的1.95和0.51发展成为2005~2015年的2.58和0.39。可见,根据图显示数据的分析,当spokeswoman和spokesperson做互信息相关比较的时候,它们之间的差距明显小于spokesman和spokesperson之间的差距,同时再配以语义趋向的变化,我们可以获知职业称谓语在语义歧视改善方面,效果并不明显。中性词spokesperson不可能取代,也没有任何趋势可以表明它会取代歧义词spokesman。随着时间和社会的发展,三个词的定位日趋明显和稳定,spokesman在语言使用中的霸主地位并不会得到改变,而当名词性别指向明显为女性的时候,spokeswoman会越来越多的取代spokesperson的地位,不难想见,spokesperson一词很有可能会在未来的某个时候成为历史,退出历史舞台。

Figure 4. Frequency of collocation of spokesman/spokesperson (1995~2004)
图4. Spokesman/spokesperson搭配频率(1995~2004)

Figure 5. Frequency of collocation of spokesman/spokesperson (2005~2015)
图5. Spokesman/spokesperson搭配频率(2005~2015)
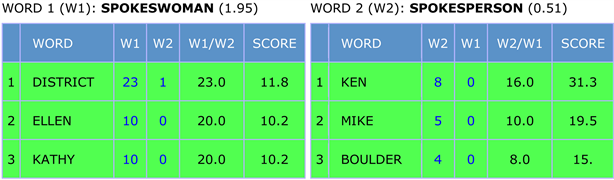
Figure 6. Frequency of collocation of spokeswoman/spokesperson (1995~2004)
图6. Spokeswoman/spokesperson 搭配频率(1995~2004)

Figure 7. Frequency of collocation of spokeswoman/spokesperson (2005~2015)
图7. Spokeswoman/spokesperson 搭配频率(2005~2015)
4. 结论
语言性别歧视现象以及性别歧视语是人类历史发展长河中必不可少的产物,可以从生物学,心理学,社会学,环境学,语言学多方面出发,研究其形成的原因和发展的趋势。20世纪六十年代开始的女权运动,推动了世人对于性别歧视在人类使用最广泛的语言——英语上的关注。基于前人在改善英语语言性别歧视方面所做的努力,越来越多人在意识形态上开始苏醒,在行为上开始践行,尽可能地使用非性别歧视语或中性词来替代原有的歧视性语言。但是要从实证的角度检测语言性别歧视改善状况,却一直以来具有比较大的难度。而美国当代英语语料库COCA作为世界范围内规模最大、时间跨度最长、更新最快的免费在线英语语料库,它的时效性和大数据使性别歧视语改善研究的数据实证检测成为了可能。当然,笔者在文中仅以个别具体词汇为证所做的分析未必能够宏观讨论英语语言性别歧视改善的整体状况,同时本文作为应用语料库研究性别语言歧视改善状况的初步探索,还有很多不完善且需改进的地方。但是,笔者希望这只是一个开始,在未来研究的道路上,能够更深入更全面地结合语料库的数据资源,发掘语言使用过程中各种歧视和改善状况。
文章引用
许晓洁. 基于语料库COCA对英语语言性别歧视改善的实证研究初探
A Corpus-Based Study on Improvement of Linguistic Sexism in English[J]. 现代语言学, 2018, 06(05): 819-826. https://doi.org/10.12677/ML.2018.65096
参考文献
- 1. Jespersen, O. (1923) Growth and Structure of the English Language. Basil Blackwell Ltd., Oxford, 37.
- 2. Benokraitis, N.V. (1993) Marriage and Families. Prentice Hall, Englewood Cliffs, New Jersey.
- 3. 杨永林. 社会语言学研究[M]. 上海: 上海外语教育出版社, 2004.
- 4. 王颖慧. 浅析性别歧视语的产生与发展[J]. 新一代, 2011(1): 245-246.
- 5. 白解红. 性别语言文化与语用研究[M]. 长沙: 湖南教育出版社, 2000.
- 6. 汪兴富, Mark Davies, 刘国辉. 美国当代英语语料库(COCA)——英语教学与研究的良好平台[J]. 外语电化教学, 2008(5): 27-33.
- 7. 黄兵. 英语中的性别差异及其文化内涵[J]. 湖北民族学院学报(哲学社会科学版), 2002, 20(2): 100-105.