Statistics and Application
Vol.
08
No.
01
(
2019
), Article ID:
28963
,
9
pages
10.12677/SA.2019.81021
Optimizing Multi-Factor Stock Selection System Using GBDT-SVM Multi-Level Model
Qingyan Meng
School of Mathematics, South China University of Technology, Guangzhou Guangdong

Received: Feb. 3rd, 2019; accepted: Feb. 15th, 2019; published: Feb. 22nd, 2019

ABSTRACT
In the field of quantitative investment, the multi-factor model is widely accepted and used by investors in A-share market because of its high stability and high capital capacity. But in recent years, model homogeneity has been getting worse and investment based on multi-factor model can hardly obtain a considerable rate of return. In this work, we presents GBDT-SVM multi-level model based on big factor database, hoping to promote the multi-factor model’s ability to acquire excess return in stock investment by optimizing factor selection and factor weight dynamic adjustment using machine learning techniques. Then, we conduct empirical research using China’s A-share market data from 2013 to 2017 and compare the model with the classical multi-factor model and its improved version. The research results show that the GBDT-SVM multi-level stock selection model has higher prediction accuracy and gains higher yields and Sharp ratio in historical backtesting.
Keywords:Quantitative Investment, Multi-Factor Model, GBDT, SVM
使用GBDT-SVM多层次模型优化多因子 选股系统
孟庆晏
华南理工大学数学学院,广东 广州
收稿日期:2019年2月3日;录用日期:2019年2月15日;发布日期:2019年2月22日

摘 要
在量化投资领域中,多因子选股模型凭借稳定性高、资金容纳量大等优势被A股市场的广大专业投资者接受和使用。但近年来,模型的同质化愈发严重,基于多因子模型的投资难以获取可观的收益率。本文提出了基于大量因子的GBDT-SVM多层次选股模型,希望使用机器学习技术对因子选取和因子权重动态调整方面进行优化,提高多因子模型对股票超额收益的获取能力。之后,使用2013年至2017年中国A股市场数据进行实证研究,并与经典多因子模型和其改进模型进行比较。研究结果表明,GBDT-SVM多层次选股模型具有更高的预测准确性,历史回溯测试中获得了更高的收益率和夏普比。
关键词 :量化投资,多因子模型,GBDT,SVM

Copyright © 2019 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY).
http://creativecommons.org/licenses/by/4.0/


1. 引言
多因子选股模型因为稳定性高、资金容纳量大等优势在A股市场投资中被广泛使用,其基本原理为选取若干可能对股票收益率产生影响的因子,之后对每支股票使用相同的方式对因子权重进行分配,得到每支股票的综合因子值,将综合因子值符合一定条件的股票买入,不符合条件的股票卖出,从而形成投资策略。目前,随着越来越多的机构投资者使用多因子模型以及A股投资市场的风格频繁变化,市场上许多常用的因子已经失效,众多使用多因子模型的资产管理产品近年来业绩表现不佳。因此,如何改进多因子选股模型,如何选择有效的因子、如何对因子权重分配将成为投资者和学者研究的热点问题。
目前多因子模型建模中,选择有效因子大多采用因子测试的方法 [1] ,通过分析夏普比率、收益率等评价指标,选取出在样本空间内表现较好的一批因子,再结合基金经理的经验从中选取若干因子建模,这种方法主观性强,并没有考虑到因子之间的相互作用。因子的权重分配主要采用打分法和回归法:打分法主要包括等权重法和专家打分法,这两种赋权方式没有从数据出发,很难反应因子的质量;回归法建立因子与股票收益率的线性模型,利用回归模型得到各个因子的权重,这种方法在因子较多时,往往很难排除因子间的相互干扰,模型准确度得不到保证。
机器学习方法可以从大样本中寻找可重现的规律,从而使用习得的规律来分类和预测。机器学习算法因为具有非线性、预测准确率高、泛化能力强等特点,而被广泛应用到量化投资各种生活场景中,且取得了一定的成果。陈荣达等(2014年)提出了基于启发式算法的支持向量机选股模型 [2] ,提高了支持向量机模型的训练精度和效率。He X,Pan J,Jin O等(2014年)使用GBDT解决了LR的特征组合问题 [3] ,在广告CTR预估中取得了不错的效果。李斌等(2017)建立了基于机器学习和技术指标的量化投资体系从而构建投资组合 [4] ,得出了收益和风险表现均优于大盘指数的策略。李文星等(2018年)使用半监督K-means核函数聚类方法应用于多因子选股模型中 [5] ,选出了较优的股票组合。吕凯晨等(2019年)使用多因子打分模型和支持向量机分类算法对沪深300成分股进行精选 [6] ,得到了远超同期沪深300指数的表现。
从目前的研究现状来看,机器学习方法在量化投资领域特别是多因子选股模型中取得了一定进展。但是,已有的研究主要是使用算法对多因子的权重分配进行改进,将打分法和回归法得到的线性模型优化为非线性模型,但是对于如何获得有效的因子和特征组合等方面的研究较少。随着常用因子的失效,因子的选择和特征提取将直接关系到后续选股模型的分类精度和泛化能力。基于此,在国内外已有研究的基础上,本文旨在完整地优化多因子选股过程,利用GBDT + SVM的两阶段综合模型对因子特征提取和因子建模展开研究:首先利用GBDT对备选因子库的批量因子进行特征提取并得到新的特征组合;再基于新的特征组合构建SVM股票分组模型。最后,利用A股市场日行情数据进行实证研究,并与经典多因子模型、支持向量机(SVM)优化的多因子模型等常见模型进行对比分析。
2. 选股模型因子库的建立
有效的因子是影响多因子模型效果的关键要素,为GBDT-SVM多层次选股模型选取适当的因子作为原始数据是模型有效性的前提。本文综合分析了各类学术论文和券商研究报告的因子研究成果,使用天软金融数据库和Wind金融数据库下载并计算百余个因子,并使用单因子测试的方法选出43个因子作为模型初始因子库。
本文建立了相关评价指标来判断因子的有效性,包括因子信息系数IC、因子信息比IR、夏普比率和股票组合年化超额收益率,这些指标从被选择股票的收益、波动性等来考察因子的有效性和持续性 [7] 。单因子测试的具体流程见图1。

Figure 1. The procedure of single factor test
图1. 单因子测试流程
信息系数(IC)指每个时间节点所有股票因子的值,与这些股票下个时间段收益率的相关系数。本文以一个月为一个周期,故某月的IC为月末每个股票因子值与下个月这些股票的收益率之间的相关系数。本文假设因子值和收益率均服从正态分布,使用皮尔逊相关系数进行计算。记股票在某月末的因子值为x,股票的下月收益率为y,则该月份IC为:
(1)
IC的取值在−1与+1之间,其绝对值越大,表明因子有效性越高,查阅相关文献得出,如果因子的IC绝对值大于2%,则认为该因子有比较好的效果。
信息比率(IR)指因子在历史测试期间投资组合相对于基准指数的平均年化超额收益率与年化平均标准差的比值,综合衡量了因子的收益与因子收益的稳定性。IR越大,则表明该因子选取具有alpha的股票的能力较强。其计算公式为:
(2)
其中 代表样本空间内的年化超额收益率, 代表因子超额收益的年化标准差,本文基准指数设定为沪深300指数。
股票组合年化超额收益率指股票组合在样本期内累计超额收益与测试年数之比,反应因子获取超额正收益的能力。
夏普比率指因子在历史测试期间投资组合相对于无风险资产的平均年化超额收益率与年化平均标准差的比值,综合衡量了因子的收益与收益的稳定性。
本文使用A股市场2005年至2012年的数据进行单因子测试,选取出IC绝对值大于2%,IR大于0.5,夏普比率大于1,组合年化超额收益率大于15%的43个因子,有关因子说明见表1。

Table 1. Factor description
表1. 因子说明表
Continued
多因子建模中可使用的因子较多,人为选取若干因子建模需要丰富的投资经验,同时容易因为市场风格的变化导致因子失效。本文利用GBDT在特征工程方面的优势,将整个因子库作为原始数据进行建模,使用GBDT模型从43个因子中提取有效信息,而不使用人工挑选的方法。
3. GBDT-SVM多层次选股模型理论
3.1. 使用GBDT构造特征组合
梯度提升决策树(GBDT)是一种泛化能力较强的迭代型决策树算法,被广泛应用于搜索排序等场景中。GBDT的训练过程使用了集成学习的boosting思想,多次迭代得到多颗决策树,从而给出预测和分类结果 [8] 。本文利用GBDT对原始因子库构造特征组合来代替主观选取因子的过程,针对每一条样本数据,提取GBDT模型的每一棵树作为该样本的一个特征,该特征的具体取值为样本在该决策树中所处的叶子节点的编号 [9] 。为便于数据对齐与后续模型的使用,本文将各特征值进行独热编码。
本文使用43个因子作为原始输入样本,则每个样本可表示为
,使用原始数据训练后的GBDT模型设为
,其中
为第i棵决策树,n为模型中决策树的总数,设
的叶节点序列为
,其中
表示样本是否落入
的第j个叶节点中,落入则
取1,否则取0,m为该树中叶节点的个数。故对于每个样本,GBDT构造的特征组合为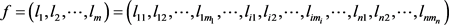 。由此可以得到因子数据特征提取的过程如图2所示。
。由此可以得到因子数据特征提取的过程如图2所示。

Figure 2. Feature structure using GBDT
图2. GBDT特征构造示意图
GBDT模型中决策树的个数n和深度d决定特征向量的维度。若特征向量f的维度过高,则容易出现过拟合的情况;若维度较低,则提取的特征不能充分涵盖有效信息,导致模型精度较低。本文建模过程中使用带交叉验证的网格搜索方法对n和d进行了参数优化 [10] 。
3.2. 基于SVM的股票分类模型
支持向量机(SVM)是1963年Vapnik等人提出的一种机器学习方法 [11] ,它基于VC维理论和结构风险最小化原则,能够较好地处理小样本和非线性问题。本文使用SVM模型对股票进行分类,对每只股票下月收益率从大到小排序:取前40%作为强势股,标记为1;后40%作为弱势股,标记为−1;中间20%的股票排出训练集,相当于噪声数据。故本文使用二分类SVM模型进行建模。
假设样本训练集 ,n为训练样本的总数, 为GBDT模型所得的特征向量, 为 对应的输出值,取值为1或者−1。设线性分类器为 ,且样本经过非线性函数 映射到高维空间后线性可分,则模型对应于求解最优化问题 [12] :
(3)
其中C为惩罚系数, 为松弛变量。上述最优化问题的对偶问题为:
(4)
其中 为拉格朗日因子, 为对应的核函数,可用 表示。根据Kuhn-Tucker定理,对偶问题的最优解即为原问题最优解。
参阅以前的研究成果发现,使用径向基函数作为本文多因子SVM模型的核函数能取得良好的效果。为了获得效果更优的SVM模型,本文需要调节参数惩罚系数C和径向基函数参数 。惩罚系数C表示对误差的宽容度,C过大则容易过拟合,C过小则容易欠拟合,C过大或过小,均会导致模型泛化能力变差。 隐含地决定了数据映射到新的特征空间后的分布, 越大,支持向量越少,支持向量的个数影响训练的速度和模型的泛化能力。本文使用S折交叉验证的方法选取较优的参数C和 [13] 。
构建好SVM模型后,将预测数据集带入模型中,选取预测结果为1的股票作为需要进行模拟投资的投资组合。
3.3. GBDT-SVM多层次模型的构建
本文使用GBDT构建因子的特征组合,再使用SVM对股票进行分类,从而优化经典多因子模型。为了模拟真实的投资过程,本文采用“滚动建模”的方式,模型每次只使用某个时间窗口内的数据进行训练,之后使用该时间窗口后的时间截面数据进行预测,得到该时间截面欲持有的股票。模拟投资完成后,将时间窗口向前移动,对下一个时间窗口和时间截面进行相同的操作 [14] 。
本文使用月度调换股票的方式,即每月月末确定下个月需要持有的股票。具体方法为使用该月前12个月的数据作为时间窗口对GBDT和SVM模型进行训练,之后将该月的数据带入模型,得到下个月应该持有的股票。滚动建模的过程如图3所示,其中每一格代表一个月的股票数据。

Figure 3. Rolling modeling diagram
图3. 滚动建模示意图
因此,GBDT-SVM多层次多因子选股模型的构建步骤如下:
步骤1:从原始的股票行情数据、财务数据和预期数据等构造出多因子模型的原始因子库。
步骤2:使用一个时间窗口的数据作为训练样本,训练GBDT模型,得到每只股票的特征组合。
步骤3:用步骤2得到的新特征组合数据作为训练集训练SVM模型,由此生成该时间窗口的GBDT-SVM综合模型。
步骤4:将预测样本带入训练好的GBDT-SVM综合模型,得出对股票下个月是否为强势股的分类,从而根据预测值选出相关股票,进行模拟投资。
步骤5:将时间窗口向前移动一个月,重复步骤2~5,直至到达规定的建模结束日期。
步骤6:计算模拟投资的结果,并根据夏普比、年化收益率等指标进行评价,并将该模型与经典多因子模型和只用SVM模型优化的多因子模型进行对比。
4. 实证分析
4.1. 数据处理和模型训练
本文使用2012年5月31日至2017年3月31日的股票月末数据进行建模和预测,其中2012年5月31日至2013年5月31日的数据只用于模型的训练,并不得出预测的投资组合。模型使用月度换股的方式,使用股票的日数据会带来数据冗余和计算量的增大等问题,故本文使用的数据为原始数据中每月最后一个交易日的数据。
在对模型进行训练之前,需要对原始因子数据先进行极值处理,再进行标准化处理,以去除各个因子数据极端值的影响和量纲的影响,保证建模效果。
其中极值处理的方法为:对同一日期若干股票的数据序列,先计算数据序列5%分位数和95%分位数的值,之后将序列中低于5%分位数的值均取5%分位数,将高于95%分位数的值均取95%分位数。
标准化处理采用标准差标准化法,对于同一日期若干股票的数据序列x,则该方法计算公式为:
(5)
其中 为序列第i个数据的值, 为序列的平均值, 为序列的标准差, 为序列第i个数据标准化之后的值。
本文使用滚动建模的方式建立每个交易月对应的模型,之后按照模型的结果建立投资组合,从而可以得到模拟的投资损益情况,所以本文使用模型分类效果和投资组合盈利效果来对模型进行评价。为了方便评估模型的分类效果,根据股票分类的实际需要,使用准确率作为模型评价的一个指标。定义模型某个时间窗口模型的准确率为:
其中强势股的定义见本文第3章,模型总的准确率定义为各时间窗口准确率的平均值。同时根据模型所要解决实际问题的特点,在评价体系中加入夏普比率、年化超额收益率、最大回撤率等指标,其中最大回撤率为:
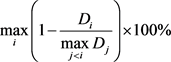 (6)
(6)
其中 为策略第i日的净值。夏普比率、年化超额收益率的指标定义见本文第2章。考虑到模型对股票的持仓周期较长,故计算收益率时不考虑手续费等交易成本以简化计算。
为了衡量GBDT-SVM多层次选股模型的优劣,将其与其他模型进行对比。定义GBDT-SVM多层次选股模型为模型A,用等权打分法构建的经典多因子模型为模型B,仅使用SVM进行滚动建模的选股模型为模型C。
4.2. 结果分析
GBDT-SVM多层次选股模型(模型A)所得到的投资净值情况如图4所示,该图反映了模型的收益与基准指数沪深300指数收益的对比,纵坐标为净值情况,初始值为1,代表投资的累计收益率。由图可以看出该模型效果显著,投资收益明显大于基准指数的收益。
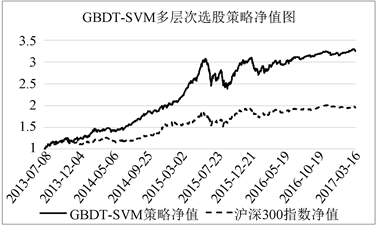
Figure 4. Net value chart of GBDT-SVM multi-level stock selection strategy
图4. GBDT-SVM多层次选股策略净值图
对GBDT-SVM多层次选股模型(模型A)、用等权打分法构建的经典多因子模型(模型B)、仅使用SVM进行滚动建模的选股模型(模型C)进行效果评价,结果如表2所示。
Table 2. Comparison of effects of three models
表2. 三种模型效果对比
由表2可以看出,从模型角度看,模型A预测准确率得到了提高;从投资角度看,模型A获得了更高的超额收益,并获得了更高的夏普比例值,是行之有效的模型,但应注意最大回撤率的增加会导致策略在某个时间段有亏损更大的可能。综合考虑,GBDT-SVM多层次选股模型相对于其他两个模型更适合用于投资过程,对投资决策有明显的现实指导意义。
文章引用
孟庆晏. 使用GBDT-SVM多层次模型优化多因子选股系统
Optimizing Multi-Factor Stock Selection System Using GBDT-SVM Multi-Level Model[J]. 统计学与应用, 2019, 08(01): 184-192. https://doi.org/10.12677/SA.2019.81021
参考文献
- 1. 赵胜民, 闫红蕾, 张凯. Fama-French五因子模型比三因子模型更胜一筹吗——来自中国A股市场的经验证据[J].南开经济研究, 2016(2): 41-59.
- 2. 陈荣达, 虞欢欢. 基于启发式算法的支持向量机选股模型[J]. 系统工程, 2014, 32(2): 40-48.
- 3. He, X.R., et al. (2014) Practical Lessons from Predicting Clicks on Ads at Facebook. Proceedings of the 8th International Workshop on Data Mining for Online Advertising, ACM, New York, 24-27 August 2014, 1-9. https://doi.org/10.1145/2648584.2648589
- 4. 李斌, 林彦, 唐闻轩. ML-TEA: 一套基于机器学习和技术分析的量化投资算法[J]. 系统工程理论与实践, 2017, 37(5): 1089-1100.
- 5. 李文星, 李俊琪. 基于多因子选股的半监督核聚类算法改进研究[J]. 统计与信息论坛, 2018, 33(3): 30-36.
- 6. 吕凯晨, 闫宏飞, 陈翀. 基于沪深300成分股的量化投资策略研究[J]. 广西师范大学学报(自然科学版), 2019, 37(1): 1-12.
- 7. 谢合亮, 胡迪. 多因子量化模型在投资组合中的应用——基于LASSO与Elastic Net的比较研究[J]. 统计与信息论坛, 2017, 32(10): 36-42.
- 8. Friedman, J.H. (2001) Greedy Function Approximation: A Gradient Boosting Machine. Annals of Statistics, 29, 1189-1232. https://doi.org/10.1214/aos/1013203450
- 9. 姚旭, 王晓丹, 张玉玺,等. 特征选择方法综述[J]. 控制与决策, 2012, 27(2): 161-166.
- 10. 黄卿, 谢合亮. 机器学习方法在股指期货预测中的应用研究——基于BP神经网络、SVM和XGBoost的比较分析[J]. 数学的实践与认识, 2018, 48(8): 297-307.
- 11. Vapnik, V.N. (1997) The Nature of Statistical Learning Theory. IEEE Transactions on Neural Networks, 8, 1564-1564. https://doi.org/10.1109/TNN.1997.641482
- 12. 张奇, 胡蓝艺, 王珏. 基于Logit与SVM的银行业信用风险预警模型研究[J]. 系统工程理论与实践, 2015, 35(7): 1784-1790.
- 13. Harris, T. (2015) Credit Scoring Using the Clustered Support Vector Ma-chine. Expert Systems with Applications, 42, 741-750. https://doi.org/10.1016/j.eswa.2014.08.029
- 14. 干伟明, 张涤新. 基于价值投资的多因子定价模型在中国资本市场的实证研究[J]. 经济经纬, 2018, 35(4): 136-140.