Statistics and Application
Vol.
12
No.
02
(
2023
), Article ID:
64716
,
12
pages
10.12677/SA.2023.122046
基于时间序列分析的云南省能源消费预测研究
路冉冉
云南财经大学统计与数学学院,云南 昆明
收稿日期:2023年3月24日;录用日期:2023年4月14日;发布日期:2023年4月27日

摘要
本文应用时间序列分析方法的理论基础,结合云南省1976年至2020年能源消费总量数据为样本,利用R软件对能源消费总量建立了ARIMA模型和Holt两参数指数平滑模型,将预测到的2016年至2020年能源消费总量的预测数据与其实际值做对比,根据相对误差绝对值取最小的选择原则,发现Holt两参数指数平滑模型预测的数据更加贴近实际值,于是将其作为最优模型进行预测。根据预测结果得出结论:2021年至2025年云南省的能源消费总量呈直线上升趋势。
关键词
ARIMA模型,Holt两参数指数平滑模型,云南省能源消费总量

Research on Energy Consumption Prediction of Yunnan Province Based on Time Series Analysis
Ranran Lu
School of Statistics and Mathematics, Yunnan University of Finance and Economics, Kunming Yunnan
Received: Mar. 24th, 2023; accepted: Apr. 14th, 2023; published: Apr. 27th, 2023

ABSTRACT
Based on the theoretical basis of the time series analysis method and the total energy consumption data of Yunnan Province from 1976 to 2020 as samples, this paper uses R software to establish ARIMA model and Holt two-parameter exponential smoothing model for the total energy consumption, compares the predicted total energy consumption data from 2016 to 2020 with the actual value, and takes the minimum absolute value of relative error as the selection principle, It is found that the data predicted by Holt two-parameter exponential smoothing model is closer to the actual value, so it is used as the optimal model for prediction. According to the prediction results, it is concluded that the total energy consumption in Yunnan Province will rise linearly from 2021 to 2025.
Keywords:ARIMA Model, Holt Two-Parameter Exponential Smoothing Model, Total Energy Consumption in Yunnan Province

Copyright © 2023 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
改革开放以后,我国经济快速发展。化石能源(煤炭、石油等)很大程度上推动了经济的发展。然而,经济的快速增长依赖了大量的能源消费,这也给环境状况带来了很大的负担。为了有效的缓解能源消费带来的环境污染,需要政府制定科学的能源管理政策。近日,云南省政府印发了《云南省“十四五”节能减排综合工作实施方案》。方案中明确提到云南将大力推动节能减排工作,深入打好污染防治攻坚战。到2025年,全省单位地区生产总值能源消耗比2020年下降13%以上,能源消费总量得到合理控制。做好能源消费总量的预测可以为政府部门制定合理的能源战略提供科学的依据,以保障云南能源的合理利用和经济的健康稳定的发展。
近年来,云南省的能源消费量在逐年递增。为了合理调整能源消费结构以及确保地方实现绿色可持续发展,需要对云南省能源需求进行准确预测以及分析预测结果。所以,本文选取了云南省的能源消费总量(1976~2020年)为样本,同时采用ARIMA、Holt两参数指数平滑模型预测云南省未来五年的能源需求。这为云南省未来的能源发展规划,政策制定和技术指导提供了参考价值,为能源结构的调整和能源供需水平的合理调整奠定坚实的基础。通过这些调整,云南省未来的能源发展将更加绿色和清洁。能源问题对一个省份的发展起着至关重要的作用,本文最终的预测结果对云南省未来的发展规划能够提供一定的借鉴,非常具有实际的意义。
2. 文献综述
关于我国能源消费总量的预测问题,我国学者做了很多的研究。近年来,我国的能源消费总量大体上在不断地增加,能源消费总量与我国经济发展息息相关。针对我国能源消费的预测问题,很多学者都是利用ARIMA模型进行预测。只是关于数据指标的选取上略有不同,张文斌 [1] 等选用了一次能源生产量的历史数据进行预测;杜雨潇 [2] 选择了我国能源消费总量这一指标数据进行了分析;周扬 [3] 则选择了以能源供需历史数据,即能源生产量(1949年至2008年)与消费量(1953年至2008年)数据对能源的供给与需求进行了预测及分析。针对省域的能源消费问题,很多学者也利用时间序列分析方法中的ARIMA模型进行预测。胡广阔 [4] 选用了甘肃省1985年至2007年能源消费总量的历史数据预测了甘肃省未来三年能源消费总量;程静 [5] 以广东省1979年至2006年能源消费总量数据为分析样本预测了当地2007年至2010年的能源消费总量。王新安 [6] 等选择了陕西省的能源消费(2003~2020年)状况和发展进行了预测。
在能源预测问题中,也有许多学者采用Holt两参数指数平滑这个模型。缪灵均等 [7] 选择了我国消耗的煤油和天然气数据(1995~2012年)。根据布朗(Brown)单一参数线性指数平滑和Holt双参数线性指数平滑模型,对未来几年的生活中消耗的煤油和天然气的量进行了预测。对比两个模型预测得出结论:Holt双参数线性指数平滑模型预测更准确。汪京徽等 [8] 选择了安徽省能源消耗量数据(1990~2017),选择了两种模型Holt线性趋势模型、ARIMA模型,预测了安徽省未来几年的能源消耗量。徐家鹏 [9] 选取了能源CO2排放系数、农业能源消费(1985~2012)这两个数据指标,解析了我国在农业行业的能源消耗状况和碳排放状况,然后根据Holt-Winter无季节性的模型对预测了我国农业行业的能源消耗和CO2排放的状况,然后讨论了农业行业的减排路径。
针对云南省的能源消费问题的研究,童祥轩等 [10] 选择了云南省能源消费(2000~2014年)作为样本,分析了该省该指标的增长路线和结构特点。黄宜等 [11] 采用云南省的能源消费,采用了指数平滑进行预测分析。同样,她也利用系统动力学模型进行预测分析,之后又更深一步的结合合作博弈Shapley值方法,根据总误差的分配以确定各个分预测模型的权重大小,重新建立组合模型,然后预测了云南省的能源消费总量。
综上所述,本文选取云南省的能源消费总量这一指标,利用ARIMA模型和Holt双参数线性指数平滑模型进行能源消费需求的预测具有可行性。且基于ARIMA模型和Holt双参数线性指数平滑模型对云南省能源需求的预测的研究相对较少。本文的研究可以为云南省的能源消费做出预测,丰富关于云南省能源消费预测的研究内容,为政府制定合理的能源政策提供参考,为云南省的绿色发展建言献策,助力实现碳达峰、碳中和目标。
3. 理论模型
3.1. ARIMA模型的基本理论
求和自回归移动平均模型,简记为ARIMA(p,d,q)模型的结构如下所示:
其中, , 为平稳可逆ARMA(p,q)模型的自回归系数多项式, ,为平稳可逆ARMA(p,q)模型的移动平滑系数多项式。
3.2. Holt两参数指数平滑的基本理论
Holt两参数指数平滑就是不断修匀截距项 和斜率项 ,递推公式如下:
式中, 为序列在t时刻得到的最新观察值; , 均为平滑系数,满足 。使用该法,向前k期的预测值为: 。
3.3. 纯随机性检验
对于ARIMA(p,d,q)模型,拟合的前提条件是差分后的的数据平稳,为了保证平稳序列有值得继续往下分析的价值,我们要针对平稳的序列执行纯随机性的检验。为证明是否为白噪声数据,本文选用LB统计量检验:
式中,n为观测序列,m为指定延迟阶数。该检验的假设:
H0:序列为纯随机序列;H1:序列非纯随机序列。
3.4. 模型的显著性检验
检验模型的残差序列是否是白噪声。因此,模型检验的假设为:
H0: ,
H1:至少存在某个 ,检验的统计量即为LB统计量。
如果拒绝原假设,即残差序列中还残留着相关信息,拟合的模型不是显著的。如果不能拒绝原假设,就认为拟合的模型是显著的。
3.5. 参数的显著性检验
为了使得模型更加简洁,需要检查每一个未知的参数是否显著非零。
参数检验的假设条件为:
检验统计量:
当P值小于 时,拒绝原假设,认为该参数显著非零。反之,则说明参数是不显著,则应该删除。然后用建立的ARIMA模型进行预测:如果通过上述的检验,判断出我们所建立的模型是合适的,那么就可以用该ARIMA进行短期的预测。
4. 数据来源和处理
本文选择了云南省的能源消费总量(1976~2020年)为样本数据,数据来源于2021年的《云南省统计年鉴》。根据样本数据构建模型并进行预测,分析了未来五年的云南省的能源消费需求。
5. 建模分析过程
5.1. ARIMA模型拟合
从“图1”云南省1976~2020年能源消费总量时间序列图来看,云南能源消费总量的时间序列随着时间的推移呈现明显的增长状态,可粗略的得出结论,即该序列不是平稳的时间序列。为了更准确的判断该时间序列,不是凭借图形直观的判断,而是有具体的数据指标来衡量其是否是不平稳的。本文选择单位根检验(ADF)方法进行精确衡量判断,结果如“图2”所示。
由下图ADF检验结果所示,类型一、类型二和类型三的模型的 统计量的p值均大于显著性水平( ),所以接受原假设是显著的。即存在单位根。因此,我们认为该时间序列,它不是平稳的时间序列。因为建立ARIMA模型,它的前提(或条件)是它必须是平稳的,所以我们要对它进行处理,使它平稳化。

Figure 1. Timing chart of total energy consumption in Yunnan Province
图1. 云南省能源消费总量时序图
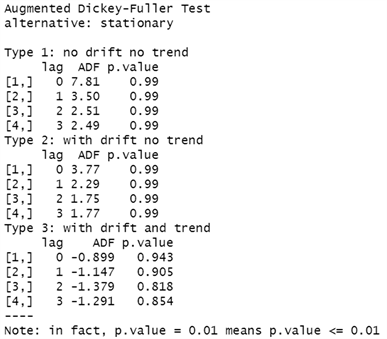
Figure 2. ADF test chart of original sequence (total consumption in Yunnan)
图2. 原始序列(云南消费总量)的ADF检验图
1) 平稳化处理
对云南省的能源消费总量(1976~2020年)序列进行一阶差分,然后观察一阶差分后序列的时序图(图3)。从时序图可以看出,该序列一阶差分后较平稳。为了更精确的判断其是否是平稳时间序列,本文仍选择单位根检验(ADF)方法进行精确判断,ADF的检验结果如“图4”所示。
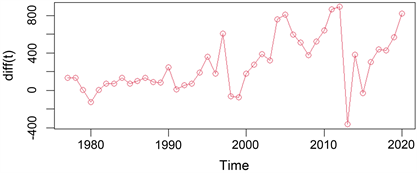
Figure 3. Time sequence diagram after first-order difference
图3. 一阶差分后的时间序列图
由下图ADF检验结果所示,类型三模型的 统计量的p值均小于显著性水平( ),即该时间序列数据,它不存在单位根。所以显著地拒绝原假设,关于1976~2020年云南省能源消费总量的时间序列为平稳时间序列。
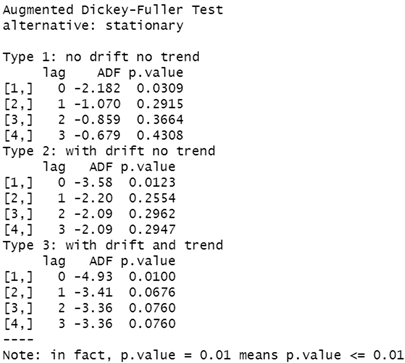
Figure 4. Statistical chart of ADF test results
图4. ADF检验结果统计图
2) 白噪声检验
如“图5”所示,关于1976-2020年云南省的能源消费总量数据的时间序列白噪声检验显示,延迟6阶的LB统计量的值只有0.000981,延迟12阶的LB统计量的p值只有0.001797,均小于显著性水平0.05,所以显著的拒绝关于1976~2020年云南省的能源消费总量数据的时间序列,它为纯随机序列的原假设。认为它为非白噪声序列。综上所述,1976~2020年云南省能源消费总量经过一阶差分后为平稳的非白噪声序列,故本文可建立云南省消费总量的ARIMA(p,1,q)模型。

Figure 5. White noise test of first-order difference sequence
图5. 一阶差分序列的白噪声检验
3) 模型阶数的确定
做出一阶差分后的时间序列自相关(ACF)和偏自相关(PACF)函数图如“图6”所示。
根据下图观察可知,发现一阶差分后的序列具有自相关系数二阶截尾的性质。而偏自相关系数具有一阶就截尾的性质,综上,拟合ARIMA(1,1,0)、ARIMA(0,1,2)、ARIMA(1,1,2)模型。拟合结果如“图7”“图8”“图9”所示。

Figure 6. Autocorrelation and partial autocorrelation diagram
图6. 自相关和偏自相关图
AIC准则是AIC值较小,模型较优。由“表1”所示,可知模型最优为模型一ARIMA(1,1,0);BIC准则是BIC值较小,模型较优。根据该准则,模型最优为模型一ARIMA(1,1,0)。现在根据参数的显著性来判断,如“图9”所示,由于模型三的三个参数t统计量的P值都大于0.05,所以我们可以判断我们为1976~2020年云南省能源消费总量的时间序列拟合的模型三ARIMA(1,1,2)三参数都显著为零,通不过参数的显著性检验。如“图7”所示,而模型一ARIMA(1,1,0)的参数t统计量的P值为0.0012。对于原假设是拒绝的,因为远远小于0.05。所以我们为1976~2020年云南省能源消费总量的时间序列拟合的模型一ARIMA(1,1,0)参数都显著非零,那么是可以通过参数的显著性检验。综上所述,ARIMA(1,1,0)为最优拟合模型。根据“图7”的拟合结果,可以得出云南省的能源消费总量的ARIMA(1,1,0)模型的表达式,见下式。

Table 1. AIC and BIC values of each fitting model
表1. 各拟合模型的AIC、BIC值

Figure 7. ARIMA(1,1,0) fitting results
图7. ARIMA(1,1,0)拟合结果

Figure 8. ARIMA(0,1,2) fitting results
图8. ARIMA(0,1,2)拟合结果

Figure 9. ARIMA(1,1,2) fitting results
图9. ARIMA(1,1,2)拟合结果
4) 模型的显著性检验
模型的显著性检验就是检验残差项是否为白噪声。如果关于1976~2020年云南省的能源消费总量数据的时间序列,它的模型的残差组成的序列认为是白噪声过程,则通过检验,可以该模型进行未来数据的直接预测;反之,则不是白噪声过程,就说明模型未通过检验,还需要修改。ARIMA(1,1,0)模型的残差的ACF图如图10所示。从下图中可以看出模型滞后16阶残差的自相关系数值都在正负2倍标准差之间,则表示模型能很好的展示原始数据中的具有很强相关性的信息,说明关于1976~2020年云南省的能源消费总量数据的时间序列的模型的残差为白噪声,通过模型的显著性检验。也可以看出在各阶延迟下的白噪声要检验的统计量,它的P值都大于0.05。我们可以认为这个拟合模型的残差构成的序列,它是属于白噪声,所以该拟合模型显著成立。
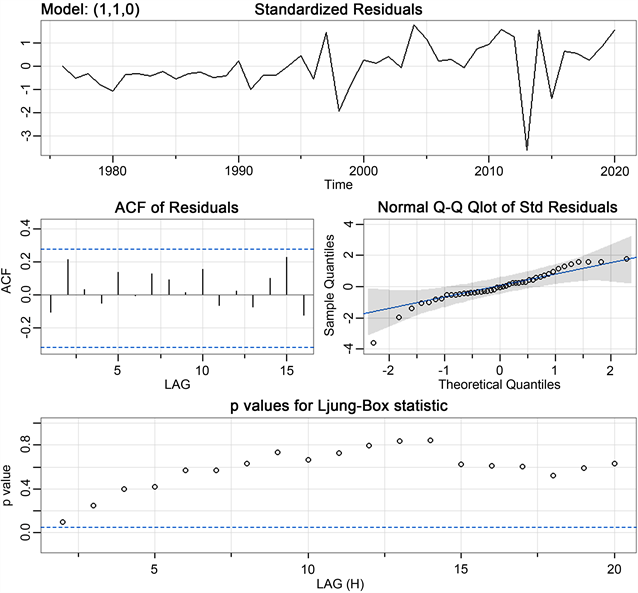
Figure 10. Significance test chart of ARIMA(1,1,0) fitting model
图10. ARIMA(1,1,0)拟合模型显著性检验图
5) 模型预测
我们选择ARIMA(1,1,0)模型进行拟合,做出拟合图如“图11”所示。从图中可以看出,该模型拟合实际数据的效果较好。选择2016~2020年这5年的数据,根据它们的实际值与预测值,计算其相对误差绝对值 = |实际值 − 预测值|/实际值,得到结果如“表2”。
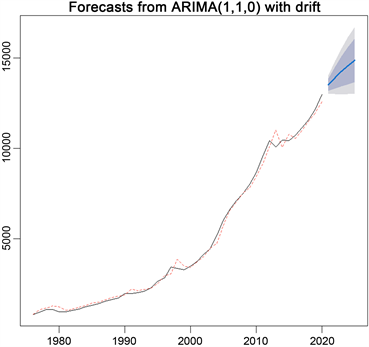
Figure 11. Fitting diagram of original sequence value and predicted sequence value based on ARIMA model
图11. 基于ARIMA模型的原序列值和预测序列值的拟合图
Table 2. Comparison between predicted value and actual value based on ARIMA model
表2. 基于ARIMA模型的预测值与实际值对照表
5.2. Holt两参数指数平滑
由上文可知,关于1976~2020年云南省的能源消费总量数据的时间序列有线性递增的发展趋势。所以我们采用Holt两参数指数平滑法去拟合数据,拟合结果如图12所示,并预测该序列的发展(图13)。本文,我们没有特别的指定平滑系数的值,所以R基于最优拟合原则计算出平滑系数: , ,通过Holt两参数指数平滑法,不断迭代,最后一期的参数估计值为: , ,则未来任意k期的预测值为: 。
我们采用Holt两参数指数平滑模型进行拟合,对预测值与实际值这两个指标做一个拟合图,如“图13”所示。本文选择了2016~2020年的实际值与预测值,计算其相对误差绝对值 = |实际值 − 预测值|/实际值,得到结果如“表3”。

Figure 12. Holt two-parameter exponential smoothing results
图12. Holt两参数指数平滑结果图
Table 3. Comparison between predicted value and actual value based on Holt two-parameter exponential smoothing model
表3. 基于Holt两参数指数平滑模型的预测值与实际值对照表
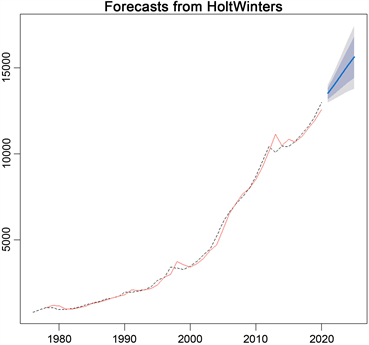
Figure 13. Fitting diagram of original series value and predicted series value based on Holt two-parameter exponential smoothing model
图13. 基于Holt两参数指数平滑模型原序列值和预测序列值的拟合图
5.3. 综合分析
根据上述ARIMA模型、Holt两参数指数平滑两种时间序列分析方法的实证分析,分别得到云南省2016~2020年能源消费量的预测值,通过与实际值做对比,得到相对误差绝对值,现将其相对误差绝对值统计结果汇总如“表4”所示。
Table 4. Statistical table of relative error based on different models
表4. 基于不同模型的相对误差统计表
根据统计结果来看,Holt两参数指数平滑模型的相对误差绝对值相对较小,被认为是最优模型,借此模型对云南省2021~2025年能源消费总量进行预测,预测结果如“表5”所示。
Table 5. Forecast Statistics of Total Energy Consumption in Yunnan Province from 2021 to 2025
表5. 云南省2021年至2025年能源消费总量预测统计表
6. 结论
本文应用时间序列分析方法的理论基础,结合云南省1976年至2020年能源消费总量数据为样本,利用R软件对能源消费总量建立了ARIMA模型和Holt两参数指数平滑模型,将预测到的2016年至2020年能源消费总量的预测数据与其实际值做对比,根据相对误差绝对值取最小的选择原则,发现Holt两参数指数平滑模型预测的数据更加贴近实际值,于是将其作为最优模型进行预测。我们可以得到2021年至2025年云南省能源消费总量,结果呈直线上升趋势。根据本文的预测结果,未来五年,云南省的能源消费的需求量大概率将进一步增大。为了适应日益增长的能源需求,政府应采取合理的政策措施,科学制定能源发展规划,调整能源结构和能源供需水平,使云南省未来的能源发展更加绿色和清洁,为有效促进全省经济社会全面绿色低碳转型,助力实现碳达峰、碳中和目标。
文章引用
路冉冉. 基于时间序列分析的云南省能源消费预测研究
Research on Energy Consumption Prediction of Yunnan Province Based on Time Series Analysis[J]. 统计学与应用, 2023, 12(02): 421-432. https://doi.org/10.12677/SA.2023.122046
参考文献
- 1. 张文斌, 霍敬伟, 马志锋, 种庆. 基于ARIMA模型的我国一次能源生产量时间序列分析[J]. 齐齐哈尔大学学报, 2010, 26(2): 71-73.
- 2. 杜雨潇. 基于ARIMA模型对我国能源需求的预测[J]. 统计教育, 2008(9): 59-61.
- 3. 周扬, 吴文祥, 胡莹, 章予舒. 中国能源供给与消费预测分析[J]. 能源与环境, 2010(3): 2-4.
- 4. 胡广阔, 王克振. 基于ARIMA模型的甘肃省能源消费预测[J]. 科学技术与工程, 2009, 9(20): 6002-6006+6037.
- 5. 程静, 郑定成, 吴继权. 基于时间序列ARMA模型的广东省能源需求预测[J]. 能源工程, 2010(1): 1-5.
- 6. 王新安, 张亚杰, 王羲. 基于ARIMA模型的陕西省能源消费及其控制研究[J]. 西安石油大学学报(社会科学版), 2018, 27(3): 8-14+19.
- 7. 缪灵均, 孙欣. 基于Holt双参数线性指数平滑模型生活能源消耗预测[J]. 贵州师范学院学报, 2015, 31(9): 43-47.
- 8. 汪京徽, 谷月, 徐子媛, 朱家明. 基于Holt线性趋势和ARIMA模型对安徽省能源消费的预测[J]. 齐齐哈尔大学学报(自然科学版), 2019, 35(2): 82-86.
- 9. 徐家鹏. 中国农业能源消耗与CO2排放: 趋势及减排路径——基于Holt-Winter无季节性模型和“十三五”的预测[J]. 生态经济, 2016, 32(2): 122-126.
- 10. 童祥轩, 林秀群, 梁超. 云南省能源消费分析及结构优化对策研究[J]. 江苏商论, 2016(11): 16-19.
- 11. 黄宜, 赵光洲, 王艳伟. 基于Shapley值的云南省能源消费综合预测方法研究[J]. 能源研究与信息, 2013, 29(1): 57-61.