Computer Science and Application
Vol.
12
No.
02
(
2022
), Article ID:
48981
,
12
pages
10.12677/CSA.2022.122049
基于经典进化策略的移动小车模型预测控制
陈肇江1,程良伦2
1广东工业大学自动化学院,广东 广州
2广东工业大学计算机学院,广东 广州
收稿日期:2022年1月22日;录用日期:2022年2月18日;发布日期:2022年2月25日

摘要
模型预测控制(model predictive control, MPC)已经被证明了在无人驾驶、移动机器人导航、机械臂路径规划、过程控制等诸多领域都拥有着出色的控制性能,然而传统的MPC控制不具有进化能力,在复杂的环境下系统往往很难得到最优的控制效果。因此,提出了一种结合经典进化策略(canonical evolution strategies, Canonical ES)的模型预测控制算法,并用于双轮差速移动小车的避障运动规划。在移动小车目标逼近运动规划的基础上,通过训练策略网络可以使得处于未知环境的移动小车快速有效地学习避障策略,并且对于局部最优陷阱拥有更优异的处理方法。仿真实验结果证明了该方法的可行性与高效性。
关键词
MPC,Canonical ES,移动小车,避障规划,运动规划

Model Predictive Control for Mobile Cart Based on Canonical Evolution Strategies
Zhaojiang Chen1, Lianglun Cheng2
1School of Automation, Guangdong University of Technology, Guangzhou Guangdong
2School of Computer Science and Technology, Guangdong University of Technology, Guangzhou Guangdong
Received: Jan. 22nd, 2022; accepted: Feb. 18th, 2022; published: Feb. 25th, 2022

ABSTRACT
Model predictive control (MPC) has been identified to have excellent control performance in many fields such as unmanned driving, mobile robots navigation, path planning of manipulators and process control, etc. However, traditional MPC does have no ability to evolve, for which is often difficult for the system to get the best effects in complex environments. Therefore, the MPC algorithm combining canonical evolution strategies is proposed. The algorithm contributes to obstacle avoidance motion planning of a two-wheel differential mobile cart. Based on the goal-approximation motion planning of the mobile cart, the mobile cart is able to learn the obstacle avoidance strategies effectively in unknown environment by training the policy network. Moreover, mobile cart will move better when facing local optimal traps. The feasibility and efficiency of the method are verified by experimental results.
Keywords:MPC, Canonical ES, Mobile Cart, Obstacle Avoidance Planning, Motion Planning

Copyright © 2022 by author(s) and Hans Publishers Inc.
This work is licensed under the Creative Commons Attribution International License (CC BY 4.0).
http://creativecommons.org/licenses/by/4.0/


1. 引言
模型预测控制(MPC)的强鲁棒性已为大量的系统仿真和工业实践过程所验证。相比于PID等经典控制算法,MPC可以轻松应对多输入多输出(Multi-Input and Multi-Output, MIMO)系统的挑战。然而随着工业生产的动态过程日益复杂化,对于性能非常依赖预测模型精度的MPC而言已无法满足日常工业生产需求。搭建更加复杂的物理模型,或者使用非线性的优化求解器是提高控制性能的常用做法,而这样的做法往往会面临过高的计算负荷和存储需求的问题,从而使得研究只能止步于计算机仿真,而无法大规模地投入生产实践。
为了改进MPC的性能,2012年,基于学习的模型预测控制(Learning-Based MPC, LBMPC)理论被提出,RL与MPC两种算法的结合成为可能。Zhong等人利用传统MPC运行所生成的大量数据全局逼近最优价值函数,并通过求解线性可解马尔科夫决策过程(LMDP)获得MPC控制策略 [1],然而该方法比较依赖函数逼近的精确度,在大部分时间所表现的性能不佳;Sun等人提出一种基于策略梯度(PG)的模型预测控制算法用于智能车辆的运动控制 [2],该方法是确定性策略梯度法(DDPG)的一个改进版,Rokonuzzaman等人则是提出一种LBMPC方法 [3],该方法从人类的驾驶经验中学习并逼近终端代价函数,从而优化无人驾驶车辆的行为,然而这些方法都需要一个参考轨迹,并不适用于本文所描述的移动小车对于任意目标点的逼近规划任务,而同样的问题也存在于文献 [4] 与 [5] 所介绍的迭代学习控制(Iterative Learning Control, ILC);Rosolia等人提出了一种不需要任何参考轨迹的ILC方法 [6],该方法给MPC的代价函数添加了一个价值函数,同样是LBMPC的一个变种,然而该方法需要一个控制器用于将系统驱动到任意过去已访问过的状态中,这对于本文的移动小车避障任务而言显然是不现实的。
应当指出,当今主流的LBMPC算法所使用的RL方法大多为基于PG的方法,而基于PG的方法可能会存在一些问题,例如采样效率低下、ICS [7] (Internal Covariate Shift)、梯度爆炸、梯度消失以及低精度梯度计算问题等等。针对上述问题,Salimans等人 [8] 和Chrabaszcz等人 [9] 分别使用进化策略(ES)代替RL算法,实验结果显示ES算法在大部分场景中(如Atari游戏、MuJoCo人形机器人行走等)表现出比基于PG的RL算法更为优异的性能;而Chrabaszcz等人还指出,即使是最为经典(Canonical)的ES算法也可以达到媲美Chrabaszcz等人所达到的效果,这证明了ES算法在解决RL问题时相较于传统RL算法所表现的优势。
基于Chrabaszcz等人所使用的ES算法,本文提出一种基于经典ES的MPC控制算法,并解决了双轮差速移动小车的避碰规划问题。一方面,将ES的进化性融入MPC,提高了移动小车对于未知环境的规划能力;另一方面将MPC的预测性融入ES,规避RL算法因缺少先验知识而导致的采样效率底下的问题。在实验的过程中,我们发现本文所提出的算法与文献 [10] 所提出的事后规划MPC算法(HI-MPC)在一般场景下所表现的性能不分伯仲,但在易失败的极端障碍场景下,本文的算法则表现得更为出色。
2. 基于MPC的小车运动控制问题建模
2.1. 小车运动模型建立
双轮差速移动小车的运动状态完全取决于双轮的转速,因此,可以建立如图1所示的小车运动模型。在图1中,px与py分别为小车在坐标轴x和坐标轴y方向上的位置量,θ为小车的航向角,l为小车的轮间距,r为车轮半径,wl与wr分别为小车左右轮的转速。由图1可知,在某t时刻,当小车的航向角为 ,双轮转速分别为 与 时,小车在坐标轴方向的速度分量与分别为
航向角的变化率为
此时,令状态量 ,控制量 ,并假设双轮与地面的接触运动均为纯滚动而无滑动,则可建立如下所示的小车运动控制模型:
(1)
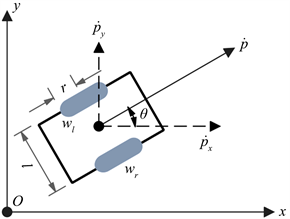
Figure 1. Kinematics model of vehicle
图1. 小车运动模型
2.2. 简化为线性模型
由式(1)可知,该系统为非线性动态系统,无法使用状态矩阵与输入矩阵的形式进行表达,因而需要使用非线性控制方法进行求解,而非线性控制往往会面临过高的计算量,不利于实时控制。现有的对于车辆的研究通常基于小航向角假设,由此可以将车辆的运动模型转化为线性模型进行求解 [11],然而在本文中小车的航向角是未知量,无法假设为小航向角,该方法自然不成立;另一种处理非线性系统的方法是利用泰勒展开将系统线性化,然而这种方法会导致模型精度降低,不利于控制。观察到在式(1)中,当 时,有
因此,航向角θ是一个独立可控的变量。基于这一点,将状态量x与控制量u重构为
则新的小车运动控制模型可以构建为
(2)
式(2)所示的状态方程具有可用状态矩阵与输入矩阵进行表达标准形式,为线性动态系统。此外,将系统重构为式(2)的形式的另一个优点是使用小车在坐标轴方向上的加速度作为控制量可以使得小车的运动更为平滑而不易发生抖动。
对于式(2)所表示的具有标准形式的时不变动态系统,可以使用前向欧拉法进行离散化,设采样时间为Ts,则其离散状态方程为
(3)
其中
2.3. 基于线性模型的MPC控制建模
对于任意第k个控制时刻,令预测步长与控制步长分别为Np与Nc,可以对离散状态方程(3)递推步长Np可得预测时域内的离散状态方程组
上式中, ,以保证最高精度的求解效果。将上述预测方程组结合起来,并以矩阵的形式表达可得如下预测模型:
(4)
其中
对于预测模型(4),为了优化预测状态量 并获得最优控制序列 ,对于任意第k个控制时刻的状态量 可以建立如下代价函数:
(5)
其中Xg为全局目标状态量,Qg、Qu分别为相应的权重矩阵。优化目标即是以最小的控制代价使当前状态渐进收敛到目标状态,并将最优控制序列 的首个时刻的控制量作用于系统。
3. 进化策略算法
3.1. 进化策略与强化学习
人工智能(AI)的目标是开发具有在复杂的不确定环境中完成富含挑战性的特定任务能力的智能体(Agents)。近年来,解决这类问题较为流行的方法是基于马尔科夫决策过程(MDP-Based)的强化学习(RL)算法,例如Q-Learning、策略梯度法(PG)等等。这类方法在游玩Atari游戏 [12]、机械臂规划 [13]、乒乓球机器人 [14] 等领域都取得了巨大的成功。
解决这类问题的另一种方法是采用以进化策略(ES)为代表的黑箱优化算法(Black-Box Optimization)。在RL中,ES常常被用于直接策略搜索。但一直以来,研究者们认为与Q-Learning、PG等算法相比,ES无法解决硬RL问题,或者在解决硬RL问题时效率较低。Salimans等人 [8] 和Chrabaszcz等人 [9] 的结果证明了ES可以可靠地训练神经网络,并具备与RL抗衡甚至取代RL的优异性能。与RL相比,ES具有以下优点:
1) ES对于奖励函数的分布并不敏感,因为ES通常会采用一整个episode的奖励总和,同时ES也无需折扣因子;
2) ES无需进行梯度反向传播,从而使得每一个episode的计算量大幅减少;
3) ES在参数空间中进行扰动,致使搜索空间增大,在训练过程中更容易收敛到可行解。
3.2. 经典进化策略
本文所使用的经典进化策略算法隶属于(μ, λ)-ES算法。(μ, λ)-ES算法是ES算法大家族中最为杰出的一类,它会强迫上一代种群中的所有个体全部离开种群,只留下少数优异的个体存活至下一代,从而规避某些适应度较好但并非最好的个体因变异率选取不当而进化失败,但却强行存活到下一代甚至几代从而浪费种群位置的问题 [15]。经典进化策略算法的步骤为:
Step 1:初始化种群数目λ,优异种群数目μ,变异率σ,初代个体θ0,适应度函数 ;
Step 2:利用标准正态分布函数产生扰动 ,令子代个体 (其中 );
Step 3:计算适应度函数值 ,并对所有的 进行排序,根据排序结果选取对应的最优的μ个个体 (其中 );
Step 4:将μ个个体 进行加权求和得到新个体θn,并将θn作为新一代的θ0;
Step 5:重复上述步骤Step 2~Step 4直到满足终止条件。
4. 基于经典进化策略的MPC控制
对于本文的小车避障运动控制问题,由于系统(3)为线性系统,故代价函数(5)是一个标准的二次规划问题。就理论上而言,在满足既定约束条件的前提下,可以快速实时地求解出最优控制序列 。然而随着障碍场景复杂化,约束条件的设置难度也随之增大,尤其是对于存在局部最优陷阱的障碍场景而言, 甚至无法求解。因此,本文在传统MPC的基础上引入经典进化策略算法,构建并离线训练策略网络,将策略网络的输出量与MPC的控制量进行叠加形成新的控制量U(k),使得小车在不同的环境下都可以快速成功地避开障碍物并导航至目标位置。
4.1. 网络结构
本文所构建的策略网络如图2所示,该网络以MPC的状态量 与小车航向角θ为作为输入,以MPC的控制量的调节量 为输出,输入层与输出层之间包含两个隐含层。层与层之间通过激活函数进行连接,其中隐含层之间的激活函数为ReLu函数,隐含层与输出层之间的激活函数为输出在−1到1之间的tanh函数,以使得策略网络的输出可以对MPC的控制量进行全覆盖的调节。当网络的输出为0时,控制器将输出原始MPC的最优控制量。

Figure 2. The policy network
图2. 策略网络
4.2. 网络训练
在每一个episode中,以初始网络参数θ0为基础通过变异产生λ个子网络并分别与原始MPC控制器结合成λ个ES-MPC控制器;在同一系统初始状态同时运行这λ个ES-MPC控制器;运行结束时每个控制器都对应产生一条数据轨迹(即小车的运动轨迹)。通过评估每一条轨迹的好坏程度就可以选出性能最为优异的μ个网络并产生下一个episode的初始网络参数θ0,由此不断更新网络从而完成网络的训练。
4.3. 代价评估
在策略网络的训练过程中,代价评估是最为关键的环节之一(这个环节相当于RL里的奖励函数设置),代价函数的设置体现了对小车期望动作的要求,因此将直接影响到网络的训练效率以及算法的性能。为了准确评估episode中每一个策略网络的优异程度,本节设置了如下的代价函数用于评估策略网络输出的好坏:
1) 碰撞代价Cc
避免小车在导航的过程中与环境中的障碍物发生碰撞,是ES-MPC算法设计中必须要遵循的重要原则,因此我们引入碰撞代价对ES-MPC运行过程中发生了小车碰撞的轨迹进行惩罚。ES-MPC中碰撞代价的设计也代替了原始MPC算法中障碍约束的设计。
引入状态布尔量 ,它的值代表第k个采样时刻小车执行控制序列 的前n个时刻的控制量 后小车的碰撞状态(其中 ),0代表未碰撞,1代表碰撞, 代表相应的代价值。当 为1时,轨迹的全局碰撞ColliState也设为1。状态 的具体值有如下定义:
其中ac为基础代价值,ε为介于0和1之间的衰减因子,则第k时刻 所对应的碰撞代价为
2) 路径代价Cp
路径代价Cp反映了小车对目标点导航效果的好坏,其意义与代价函数(3)相似,但是路径代价Cp反映了小车对目标点的全局导航效果,我们自然希望小车以最短路径逼近目标点。 代表第k个采样时刻小车执行控制序列 的前n个时刻的控制量 后的位置,并定义 为小车当前时刻的位置,路径代价 的具体值有如下定义:
其中kp与kg为惩罚系数,pg为目标位置,则第k时刻 所对应的路径代价为
3) 搜索代价Ce
以上两个代价函数——Cc与Cp的设置体现了小车运动规划的两个目标:避障,以及快速导航到目标位置;然而在策略网络训练的初期,Cc与Cp很有可能会导致矛盾。例如当种群内的所有策略网络所输出的策略都让小车发生碰撞,而路径代价Cp的存在又限制了种群进化的出路,导致优化陷入死胡同。因此,设置搜索代价Ce从而鼓励种群内个体进行广泛搜索。 的具体值有如下定义:
其中ke为搜索因子, 为小车初始时刻位置。由于该代价量为增益量,因此取负号。则第k时刻 所对应的搜索代价为
则长度为N的轨迹的总代价值为
5. 实验结果与分析
在本节中,我们在仿真实验中评估了ES-MPC算法的可行性。此外,我们还在不同的仿真场景中进行了与其他算法的对比实验,实验结果表明了ES-MPC的优越性。
5.1. 场景搭建
CoppeliaSim (原V-rep)是一款支持各类机器人运动学及动力学仿真的软件,提供有面向MATLAB的远程API函数接口,通过API函数接口可以从MATLAB脚本中调用相关函数获得机器人信息或控制机器人运动。因此我们在CoppeliaSim平台搭建了复杂障碍环境与小车物理模型并进行小车运动可视化,在MATLAB内搭建了相同的场景与小车动态模型并训练策略网络。图3展示了CoppeliaSim内的场景以及MATLAB内相应的场景,由于小车在仿真训练中被简化为一个质点,因此对障碍作了膨胀化处理。

Figure 3. Scenes for simulation experiments
图3. 仿真实验场景
5.2. 对比实验结果
在ES-MPC策略网络的训练过程中,全局目标Xg总是不变的,初始状态x0则是随episode的更替而随机生成,以实现在绝大部分初始状态下小车都能成功导航到目标位置。策略网络训练过程中的参数设置情况如表1所示。

Table 1. Parameter setting
表1. 参数设置
图4展示了在两个不同场景下,几类MPC算法所对应的小车运动轨迹。由图4可知在该场景1中,在不添加障碍约束的情况下,原始MPC、HI-MPC的事后预测步长N'为25时无法完成导航任务,而N'为50的HI-MPC与本文的ES-MPC都能提前预知障碍并导航至目标位置;而在场景2中由于存在局部最优陷阱,只有经过策略网络训练的ES-MPC能够寻找到一个好的避障策略并完成导航任务。
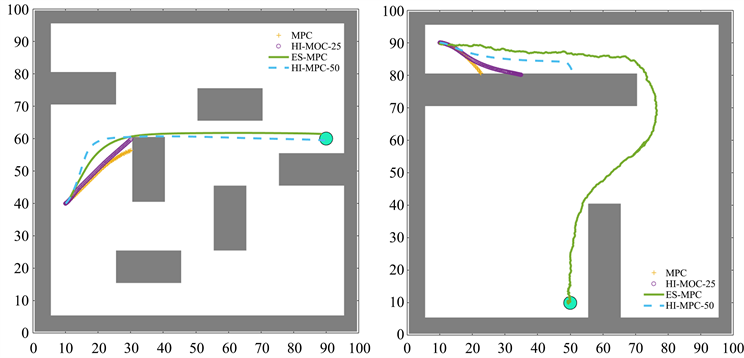
Figure 4. Figure of the comparison experiment
图4. 对比实验图
此外,我们还在不同的初始状态或目标状态下进行了多次实验,实验结果如表2所示。根据不同的状态,我们将场景分为“开放”与“封闭”两种类型。由表2可知,在开放场景中,由于任务难度不大,因此3种MPC算法都可以完成导航;然而在封闭场景中,N'为50的HI-MPC可以完成一部分任务,而本文的ES-MPC则可以完成全部任务,这充分体现了ES-MPC的可行性与优越性。
Table 2. Comparative experimental results
表2. 对比实验结果
5.3. 小车运动仿真结果
在上一节中我们成功训练了策略网络,在这一节中我们将使用策略网络控制小车在CoppeliaSim场景内运动。对模型(1)直接进行采样离散化可得
(6)
由此可得小车双轮转速与模型(2)中小车坐标轴方向上的移动速度以及航向角变化率之间的关系。航向角变化率并未显含于模型(2)中,但由几何关系,有
因此有
由此可以决定小车在k时刻的双轮转速。
图5展示了CoppeliaSim内小车的运动轨迹,对应于图4中ES-MPC的轨迹,由图5可知基于模型(2)所训练的策略网络可以顺利地控制基于物理模型(1)的小车进行运动,由此验证了本文所提ES-MPC方法的可行性。理论上只要有足够的训练代数,所有可以显式建模的系统都可以使用ES-MPC方法。

Figure 5. Cart trajectory in CoppeliaSim
图5. CoppeliaSim小车运动轨迹
6. 结论与展望
本文提出一种基于经典进化策略的模型预测控制方法(ES-MPC),并用于移动小车的无碰路径规划任务。ES-MPC通过种群进化训练策略网络,从而让小车在障碍环境中搜寻到避障策略。仿真实验结果显示,ES-MPC方法可以更好地训练小车在局部最优陷阱中的避障决策能力。
目前,本文的工作仅仅针对静态场景,而没有考虑包含动态障碍的更加复杂的场景,对于动态场景的策略网络训练将更为复杂,这是未来的工作。另外,我们还将探索本文方法对于高维机械臂规划的可行性。
文章引用
陈肇江,程良伦. 基于经典进化策略的移动小车模型预测控制
Model Predictive Control for Mobile Cart Based on Canonical Evolution Strategies[J]. 计算机科学与应用, 2022, 12(02): 486-497. https://doi.org/10.12677/CSA.2022.122049
参考文献
- 1. Zhong, M., Johnson, M., Tassa, Y., Erez, T. and Todorov, E. (2013) Value Function Approximation and Model Predic-tive Control. 2013 IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning (ADPRL), Sin-gapore, 16-19 April 2013, 100-107. https://doi.org/10.1109/ADPRL.2013.6614995
- 2. 孙浩, 陈泽宇, 吴思凡, 潘峰. 基于策略梯度的智能车辆模型预测运动控制算法[J]. 汽车技术, 2021(12): 10-15. https://doi.org/10.19620/j.cnki.1000-3703.20210494
- 3. Rokonuzzaman, M., Mohajer, N., Nahavandi, S. and Mohamed, S. (2020) Learning-Based Model Predictive Control for Path Tracking Control of Autonomous Vehicle. 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, 11-14 October 2020, 2913-2918. https://doi.org/10.1109/SMC42975.2020.9283293
- 4. Bristow, D.A., Tharayil, M. and Alleyne, A.G. (2006) A Survey of Iterative Learning Control. IEEE Control Systems, 26, 96-114. https://doi.org/10.1109/MCS.2006.1636313
- 5. Wang, Y., Gao, F. and Doyle, F.J. (2009) Survey on Iterative Learning Control, Repetitive Control, and Run-to-Run Control. Journal of Process Control, 19, 1589-1600. https://doi.org/10.1016/j.jprocont.2009.09.006
- 6. Rosolia, U. and Borrelli, F. (2018) Learning Model Predictive Control for Iterative Tasks. A Data-Driven Control Framework. IEEE Transactions on Automatic Control, 63, 1883-1896. https://doi.org/10.1109/TAC.2017.2753460 .
- 7. Ioffe, S. and Szegedy, C. (2015) Batch Normalization: Acceler-ating Deep Network Training by Reducing Internal Covariate Shift. International Conference on International Confer-ence on Machine Learning, Lille, 6-11 July 2015, 448-456.
- 8. Salimans, T., Ho, J., Chen, X., Sidor, S. and Sutskever, I. (2017) Evolution Strategies as a Scalable Alternative to Reinforcement Learning. https://arxiv.org/abs/1703.03864
- 9. Chrabaszcz, P., Loshchilov, I. and Hutter, F. (2018) Back to Basics: Benchmarking Canonical Evolution Strategies for Playing Atari. Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, 13-19 July 2018, 1419-1426. https://doi.org/10.24963/ijcai.2018/197
- 10. Tamar, A., Thomas, G., Zhang, T., Levine, S. and Abbeel, P. (2017) Learning from the Hindsight Plan—Episodic MPC Improvement. 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May-3 June 2017, 336-343. https://doi.org/10.1109/ICRA.2017.7989043
- 11. 邹凯, 蔡英凤, 陈龙, 等. 基于增量线性模型预测控制的无人车轨迹跟踪方法[J]. 汽车技术, 2019(10): 1-7.
- 12. Mnih, V., Kavukcuoglu, K., Silver, D., et al. (2013) Playing Atari with Deep Reinforcement Learning. https://arxiv.org/abs/1312.5602
- 13. Nguyen, H. and La, H. (2019) Review of Deep Reinforcement Learning for Robot Manipulation. 2019 3rd IEEE International Conference on Robotic Computing (IRC), Naples, 25-27 February 2019, 590-595. https://doi.org/10.1109/IRC.2019.00120
- 14. Mülling, K., Kober, J., Kroemer, O. and Peters, J. (2013) Learning to Select and Generalize Striking Movements in Robot Table Tennis. The 80 International Journal of Robotics Research, 32, 263-279. https://doi.org/10.1177/0278364912472380
- 15. Dan, S. (2013) Evolutionary Optimization Algorithms: Biologi-cally Inspired and Population-Based Approaches to Computer Intelligence. Wiley & Sons, Inc., Hoboken.